基于隐马尔科夫模型与语义融合的文本分类
2017-08-12高知新徐林会
高知新 徐林会
(辽宁工程技术大学理学院 辽宁 阜新 123000)
基于隐马尔科夫模型与语义融合的文本分类
高知新 徐林会
(辽宁工程技术大学理学院 辽宁 阜新 123000)
提出一种融合语义的隐马尔科夫模型用于文本分类的方法。将特征词的语义作为先验知识融合到隐马尔科夫分类模型中。通过信息增益提取特征词,用word2vec提取特征词语义,将每一个类别映射成一个隐马尔科夫分类模型,模型中状态转移过程就是该类文本生成过程。将待分文本与分类模型做相似度比较,取得最大类别输出概率。该方法不仅考虑特征词、词频、文档数量先验知识,而且将特征词语义融合到隐马尔科夫分类模型中。通过实验评估,取得了比原HMM模型和朴素贝叶斯分类模型更好的分类效果。
隐马尔科夫模型 语义融合 word2vec 信息增益 文本分类
0 引 言
近年来随着Web和移动互联网的广泛使用,各种信息的增长速度越来越快,其中文本信息占有重要地位。如何快速而有效地进行文本的组织、管理以及使用是当今信息处理的一个重要课题,而这也促进了文本分类技术的发展。文本分类就是将未分类的文本根据一定的分类算法分配到正确的类别中,它广泛应用在搜索引擎、信息过滤、文本识别、数字图书馆等方面。为了快速高效的处理海量文本数据集,基于统计的分类模型被应用到文本分类中。文献[1]将文本利用向量空间模型表示成空间向量,利用TF-IDF表示文本权重,对文本进行分类;文献[2]讨论了统计模型在文本分类中的应用;文献[3]将支持向量机应用与文本分类,因为其坚实的理论基础和良好的分类性能成为一经典的分类算法。除此以外,最大熵模型、模糊理论和二维文本模型等方法也被应用于文本分类,同样也取得了不错的效果[4-6]。
由于隐马尔科夫模型(HMM)可以用来描述序列化随机过程的统计特性,文本处理作为随机过程统计特性一种,如何将HMM模型更好地应用到文本处理中,成为当下的研究热点之一。文献[7]利用HMM模型作为信息检索模型,给定一个查询系列,输出一个和查询相关的文档。文献[8]利用HMM模型用于文本分类,将每一个预定义的类映射为一个HMM模型,给定一篇待分类的文档表示成词序列,计算属于该类别的可能性大小。文献[9]将卡方一致性检验和TF-IDF方法结合提取特征词向量,在此基础上建立HMM分类模型。
本文提出了一种文本分类方法,将文本的特征词,特征词词频,文档数量以及特征词语义作为先验知识融合到HMM分类模型当中。通过信息增益方法提取特征词,利用TF-IDF算法约束特征词权重,利用word2vec提取特征词的语义信息,将语义相似度较高特征词合并,为每一个类别建立HMM分类模型。对于待分类的文本,本文提出通过与分类模型中特征词向量做交集,交集集合特征词作为观察序列输入到HMM分类模型中,通过前进算法取得各个类别输出概率,选取其中最大的作为分类依据。
1 基于HMM的分类模型
文本分类任务是指将待分类的文本自动分配到预先定义好的类别集合当中。本文中,给定一个训练集合T={(d1,c1),(d2,c2),…,(dn,cn)},包含预定义的文档类别,HMM分类模型目标挖掘待分文档和类别之间的关系,高效准确地将文档分配到某一类别中。
1.1 隐马尔科夫模型
HMM模型(如图1所示)建立在状态和观察独立性上的统计模型,主要应用于解决评估问题、学习问题和解码问题。一个HMM模型λ一般由5个部分组成,记为λ={S,V,A,B,Π},其中[10]:
(1)S是一组状态的集合,设模型中共有N个状态,则状态集记为:
S={s1,s2,…,sN}
(2)V是一组输出符号的集合,设模型中共有M个输出符号,则符号集记为:
V={v1,v2,…,vM}
(3)A是状态转移概率分布矩阵,记为A={aij},aij表示从状态si转移到sj的概率,其中:
aij=p(qt+1=sj|qt=si)
(1)
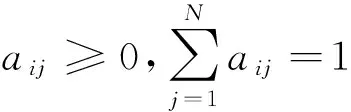
(4)B是符号输出概率分布矩阵,记为B={bi(k)},bi(k)表示在状态si时输出符号vk的概率,其中:
bi(k)=p(ot=vk|qt=si) 1≤j≤N1≤k≤M
(2)
(5)Π是初始状态概率分布,记为Π={πi},πi表示状态si作为初始状态的概率,其中:
πi=p(qi)=si1≤i≤N
(3)

图1 HMM模型图
1.2 word2vec词向量模型
word2vec是Google在2013年开源的一款将词语表征为实数值向量的高效工具。本文训练词向量采用的skip-gram模型,经测试,在小规模样本集上skip-gram模型要比cbow模型效果要好。从图2中看skip-gram应该预测概率p(wi|wt),其中t-c≤i≤t+c且i≠t,c是决定上下文窗口大小的常数,c越大则需要考虑的上下文语境就越多,一般能够带来更精确的结果,但是训练时间也会增加。假设存在一个w1,w2,…,wT的词语序列,skip-gram的目标是最大化:
(4)
基本的skip-gram模型定义p(wo|wI)为:
(5)
skip-gram是一个对称的模型,如图2所示,如果wt为中心词时wk在其窗口内,则wt也必然在以wk为中心的同样大小窗口内,即:
(6)
实现此模型的算法分别为层次Softmax和Negative Sampling两种算法[15]。
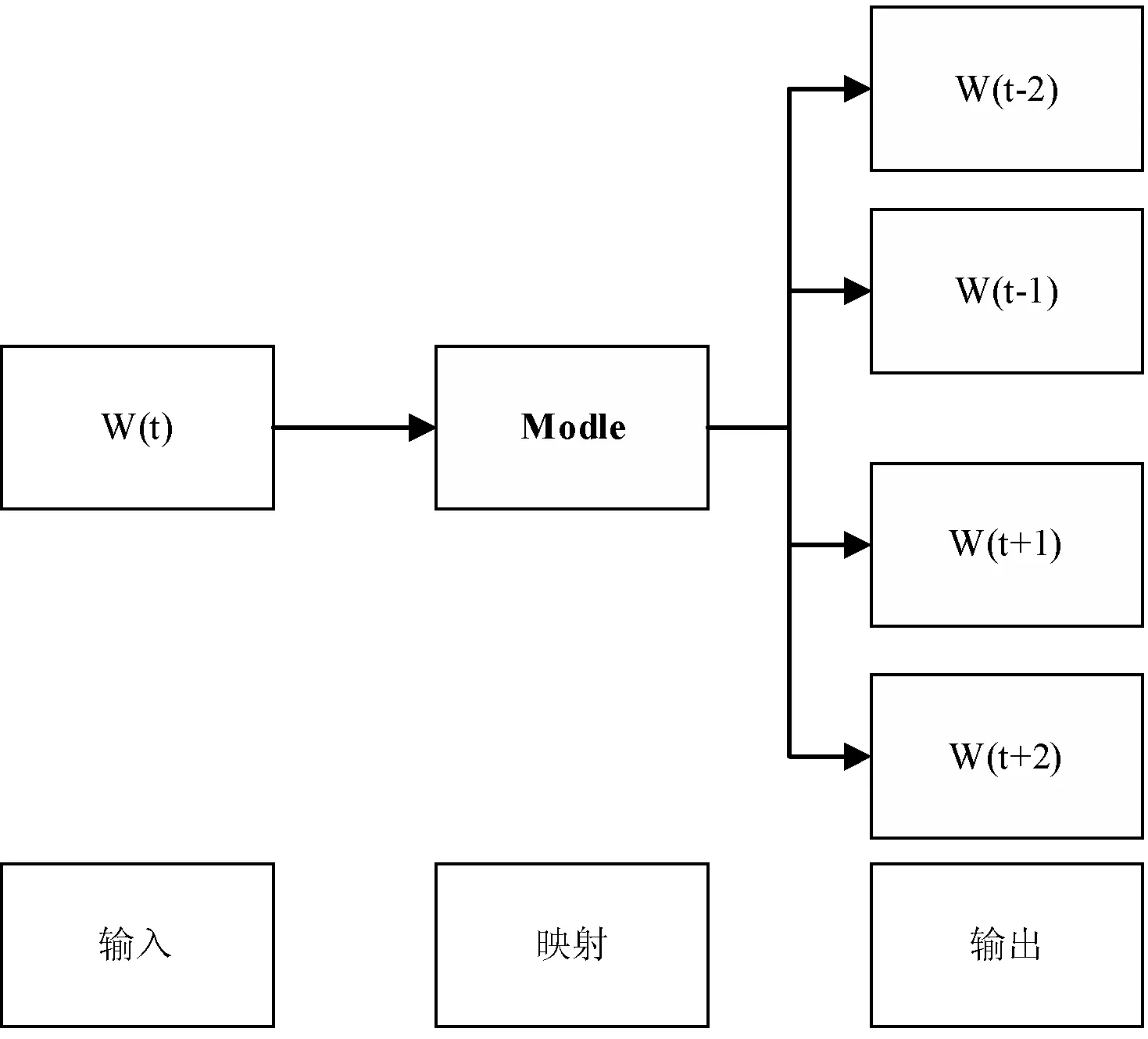
图2 skip-gram模型图
1.3 HMM分类模型
每一篇文档di都有一个类别ci属性,目标建立基于训练集的分类模型,完成新文本的分类。本文利用HMM模型作为文档生成器,如图3所示,每一个类映射成一个HMM模型,模型参数通过属于本类的数据集训练而得。当一篇待分类的文档,先计算属于当前类别的概率分布大小,再作为属于当前类别的依据。
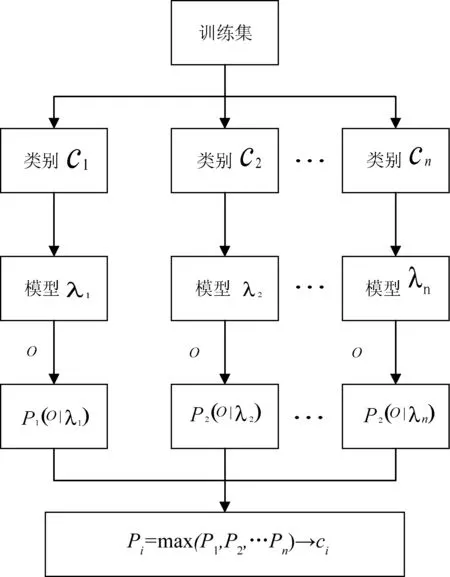
图3 HMM文本分类模型
2 融合语义隐马尔科夫分类模型的建立
在隐马尔科夫分类模型基础上,融合特征词语义、词频、特征词本身等先验知识,建立高效快速文本分类模型。将文本信息表示成词向量能够让模型就行数据化处理,本文采用word2vec模型,融合上下文语义,将文本映射到向量空间模型中,进行内积计算,通过设定阈值,将相似特征词进行合并。例如“文化”和“艺术”就可以合并为同一类别的特征词。为了去除文本中噪声,处理以前进行文本数据已处理。包括分词、去除停用词、去除词频相对文本数目较小的词等。
2.1 特征词提取
文本处理中时间复杂度和空间复杂度依赖于文本特征向量的维度。为了提高模型分类效果准确性,需要对文本进行降维处理,最终选择特征词表示文档。本文中采取信息增益算法,可以计算当前类别平均信息量。对于每一个w,信息增益G(w):
(7)

2.2 隐马尔科夫分类模型建立及参数训练
文本是由一些列的词汇组成,在具体的不同文本中词汇及其词频都不同。所以HMM分类模型的建立在特征词本身和特征词词频基础上,而在特征词提取过程中已将语义信息融合到特征词当中。类别特征词集是构建HMM分类模型的基础,词向量作为隐马尔科夫模型的隐藏状态,而将词向量对应的词频作为对应状态的观察序列。
对每一个隐马尔科夫分类模型,定义状态集合S={s1,s2,…,sT},每一个si对应着类别特征词的第个特征词。状态集由特征词的顺序构建。状态转移过程即为特征词遍历过程,特征词遍历过程即为隶属于该类别文档生成过程。特征词输出序列为特征词的词频用k表示,k为符合一定相似度阈值的特征词之和。所以得到在中间状态si下,ck类中对应特征词的观察值分布为:
(8)
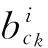
(9)
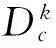
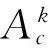
(10)
指定初始状态s0的概率π={1,0,…,0}。对于类别ck的隐马尔可夫模型可以表示为:
λk={Π,Ack,Bck}
(11)
2.3 待分文本相似度比较
对于一个待分类的文本,进行如下步骤进行分类:
(1) 对文本d按照预处理的方法,然后统计词频,得到词向量和词频集合,并将wd表示为词向量的形式。
(2) 将wd的词向量分别与各类别特征词做交集,选取其中k个特征词作为隐藏状态。给定隐马尔科夫模型λk和k个特征词对应的词频观察序列即为od,利用前向算法[10]求解该观察序列输入该分类模型的概率分布值p(od|λk)。
(3) 计算wd与所有HMM分类模型的p(od|λk),待分文本的类标号就是max{p(od|λk)}。
对于待分文本不仅将词汇本身,词汇词频和词汇的上下文语义融合到其中,所选取的k个特征词更具代表性,能够映射出该文本和该类别的关联程度。对于HMM分类模型的构建考虑到词汇本身属性以及词汇语义等先验性知识,构建的模型不仅在数据维数上减少了,而且将相似度较高的特征词进行合并,也是根据语义信息对特征词进一步提取,得出的特征词更好的代表这个类别属性信息。可以把HMM分类模型作为该类文本生成器,待分文本可以看作是它状态转移过程生成的样本。
3 实验结果与分析
为验证模型的有效性,本文采用三组实验对模型进行验证。实验数据集来源于复旦大学文本分类语料,采用C3、C7、C11、C32、C38、C39共6个类别数据集。分词采用HanNLP开源工具,进行分词、去停用词,利用word2vec进行特征词语义合并,提取特征词。实验结果从准确率、召回率、F-Score三个方面进行评价。其中,word2vec 训练语料来自于人民日报2014 。模型参数如表1所示。
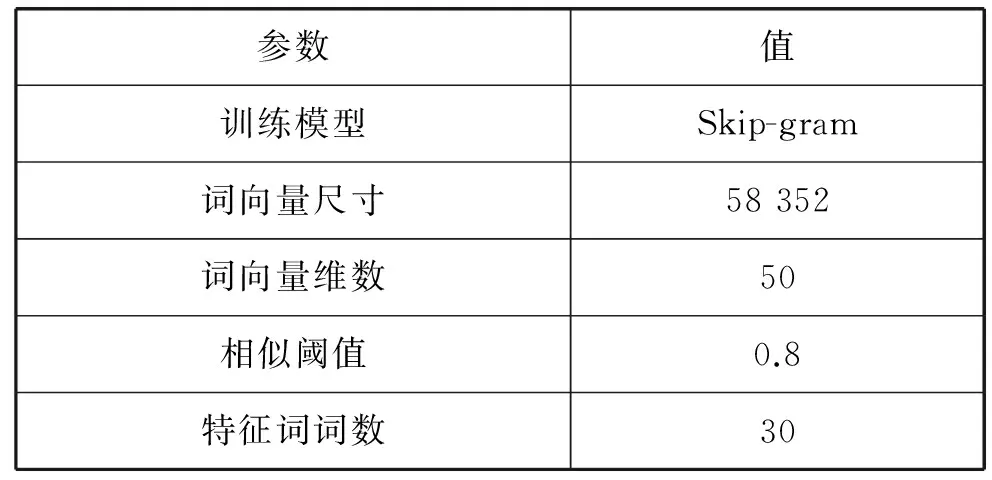
表1 word2vec模型参数
3.1 HMM 模型试验对比
为验证模型有效性,将本文模型和不融合语义合并的模型对比。实验结果如表2所示。模型在三个指标方面有显著的提高。说明了融合语义特征能够提高HMM模型在文本处理中的有效性。其中文献[1]中说明了原模型的处理文本的方法。
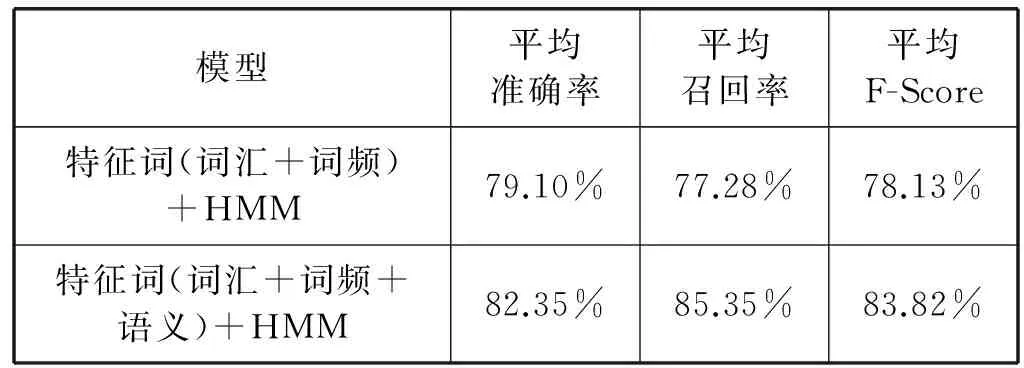
表2 试验结果
3.2 交叉模型对比
为验证模型的可行性,本文建立的HMM模型和传统的朴素贝叶斯模型[13]进行对比。试验结果如表3所示。朴素贝叶斯作为文本分类中的重要方法,广泛应用在自然语言处理领域当中。本实验在准确率、召回率和F-Socre三个方面对比取得了和朴素贝叶斯模型相当的效果,进一步说明模型的有效性。

表3 交叉模型对比结果
3.3 训练样本的数量对模型影响
统计模型,训练样本的规模尺寸对模型的评估结果又很大影响。本文设计如下实验特征词数为30。如图4所示:水平轴表示每个类别的样本数,垂直轴表示“词汇+词频+语义+HMM”模型的平均准确率。随着训练样本的增加,该模型的平均准确率有显著增加,可以解释为随着训练样本的增加,通过文档的词汇、词频、语义,代表文档的特征词特征属性提取的更充分,所以准确率显著增加,当到达[700,800]区间到达顶峰。随着训练样本进一步增加,准确率有下降的趋势,随着样本递增,word2vec进行语义合并时,融合语义噪声,使得特征词代表性有所下降,准确率会有所下降。
本文测试数据采用复旦大学文本分类语料,测数据中最大数量1 000多篇,对于大样本数据或者不均衡语料数据需要应用过采样或欠采样方法[15]。将本模型应用到其他大规模文本数据,采用更为有效的评价指标进行评测也是接下来需要研究问题。

图4 训练样本的数量对模型影响
4 结 语
本文提出一种基于HMM模型和融合语义分析的文本分类方法。模型建立在特征词基础上,融合特征词本身内容,特征词的词频以及特征词的语义等先验知识,将每一个类别映射成隐马尔科夫模型。本文对模型结构和参数的训练进行阐述,对比其他文本分类统计模型,模型结构简单,参数训练复杂度依赖于特征词的维数,然而语义分析起到特征词降维的作用,而且根据语料的增加,特征词的维度可以调整,这也是本模型特点。通过实验分析的三组实验可以说明模型的有效性,取得了与朴素贝叶斯相当的结果。如何针对具体领域更加有效地进行特征提取和观测值概率分布计算是今后研究的方向。
[1] Turney P D, Pantel P. From frequency to meaning: vector space models of semantics[J]. Journal of Artificial Intelligence Research, 2010, 37(1):141-188.
[2] Pelikan M, Goldberg D E, Lobo F G. A Survey of Optimization by Building and Using Probabilistic Models[J]. Computational Optimization and Applications, 2002, 21(1):5-20.
[3] Pal M, Foody G M. Feature Selection for Classification of Hyperspectral Data by SVM[J]. Geoscience & Remote Sensing IEEE Transactions on, 2010, 48(5):2297-2307.
[4] Kazama J, Tsujii J. Maximum Entropy Models with Inequality Constraints: A Case Study on Text Categorization[J]. Machine Learning, 2005, 60(1):159-194.
[5] Nunzio G M D. A Bidimensional View of Documents for Text Categorisation[M]// Advances in Information Retrieval. Springer Berlin Heidelberg, 2004:112-126.
[6] Liu W Y,Song N.A fuzzy approach to classification of text documents[J].Journal of Computer Science and Technology,2003,18(5):640-647.
[7] Miller D R H, Leek T, Schwartz R M. A hidden Markov model information retrieval system[C]//International Acm Sigir Conference on Research & Development in Information Retrieval. 2000:214-221.
[8] Yi K, Beheshti J. A hidden Markov model-based text classification of medical documents[J]. Journal of Information Science, 2009, 35(1):67-81.
[9] Li K, Chen G, Cheng J. Research on Hidden Markov Model-based Text Categorization Process[J]. International Journal of Digital Content Technology & Its Applications, 2011, 5(6):244-251.
[10] 杨健,汪海航.基于隐马尔科夫模型的文本分类算法[J].计算机应用,2010,30(9):2348-2350.
[11] 罗双虎,欧阳为民.基于Markov模型的文本分类[J].计算机工程与应用,2007,43(30):179-181.
[12] 宗成庆.统计自然语言处理[M].北京:清华大学出版社,2013.
[13] 杜选.基于加权补集的朴素贝叶斯文本分类算法研究[J].计算机应用与软件,2014,31(9):253-255.
[14] 邓力.深度学习方法和应用[M].北京:机械工业出版社,2015.
[15] Chawla N V, Bowyer K W, Hall L O, et al. SMOTE: synthetic minority over-sampling technique[J]. Journal of Artificial Intelligence Research, 2011, 16(1):321-357.
TEXT CLASSIFICATION BASED ON HIDDEN MARKOV MODEL AND SEMANTIC FUSION
Gao Zhixin Xu Linhui
(CollegeofScience,LiaoningTechnicalUniversity,Fuxin123000,Liaoning,China)
In this paper, a text classification method based on Hidden Markov Model and semantic fusion is proposed. The semantics of the feature words are integrated into the hidden Markov model as a priori knowledge. Then, the characteristic words were extracted by information gain, and the feature words semantics were extracted by the word2vec. Each class was mapped into a hidden Markov model, and the state transition process in the model was the text generation process. The similarity between the text to be classified and the classification model was compared to obtain the maximum class output probability. This method not only considers the prior knowledge of feature words, word frequency and document quantity, but also integrates the semantic of feature words into hidden Markov classification model. Through the experimental evaluation, we got better classification result than the original HMM model and Naive Bayes classification model.
Hidden Markov model Semantic fusion word2vec Information gain Text classification
2016-07-20。高知新,副教授,主研领域:最优化与应用。徐林会,硕士生。
TP3
A
10.3969/j.issn.1000-386x.2017.07.056
