基于类信息的TF-IDF权重分析与改进①
2021-10-11姚严志李建良
姚严志,李建良
(南京理工大学 理学院,南京 210094)
随着网络的普及,网络上时刻都在产生大量的文本信息,为了满足用户面对海量文本时多样化的需求,对文本信息进行有效的分类就显得至关重要.在文本分类领域中,用向量空间模型表示文本的方法应用尤为普遍.用向量空间模型表示文本,需经过分词、特征选择、权重计算等步骤,而权重计算方法的优劣直接影响着分类算法的性能表现.权重计算的方法多种多样,常用的包括文档频率、信息增益、互信息、卡方分布、TF-IDF 等[1].
TF-IDF 算法自提出以来,因其算法相对简单和有较高的准确率及召回率,一直受到广泛应用[2].但该算法的权重计算仅考虑了特征词的词频和逆文档频率等,仍还有许多可改进的空间.因此,很多学者分析TFIDF的缺陷,对其进行了相应的改进.How 等[2]提出利用Category Term Descriptor (CTD)来改进TF-IDF,考虑不同类别的文档数可能存在数量级的差距,以改善类别数据集偏斜所引起的误差;徐冬冬等[3]引入逆类频率因子和类别比率因子用以修正TF-IDF 权重算法,得到基于类别描述的TF-IDF-CD 方法,叶雪梅等[4]针对新词识别对分类结果的影响,提出了基于网络新词的改进文本分类TF-IDF 算法;许甜华等[5]通过引入去中心化词频因子和特征词位置因子以加强特征权重的准确性.
本文使用TF-IDF 算法计算特征词权重,对特征词在不同规模文档集中的权重加以比较,具体分析了特征词的类信息对于权重的影响,并在此基础上提出一种新的衡量特征词的类间、类内分布信息的改进方法.改进方法增加两个新的权值,类间离散因子和类内离散因子,将其与经典的TF-IDF 算法结合,进而提出了改进的TF-IDF-DI 算法.改进的权重计算方法有效改善了TF-IDF 算法对类信息不敏感的问题.本文通过朴素贝叶斯模型对改进后的算法的分类性能进行验证.实验证明,改进后的权重算法在测试数据集上的表现,在准确率、召回率和F1 值上均优于经典的TF-IDF 算法.
1 经典的TF-IDF 算法及权重分析
1.1 经典的TF-IDF 算法
TF-IDF 算法作为计算特征项权重的算法,在文本分类中的应用极为广泛,其主要思想为:在某一特定文档中,某词语的出现频率越高,且数据集中包含该词语的文档数越少,说明该词语越是能标志文档内容的属性,其权重自然也就越大[6-9].计算公式如下:
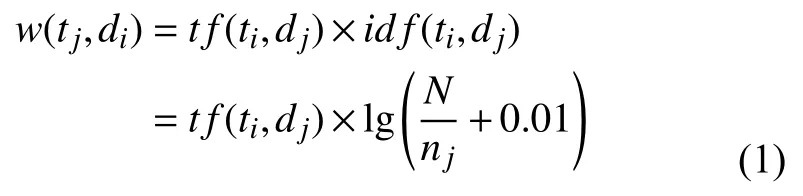
其中,w(tj,di) 表示特征词权重;id f(tj,di)表示特征词在文档di中的出现频率;N表示文档集中的文档总数;nj表示文档集中出现特征词tj的文档数.
在使用时考虑到文档长度不同对权值计算的影响,我们通常会对公式做归一化处理[10],得到公式如下:
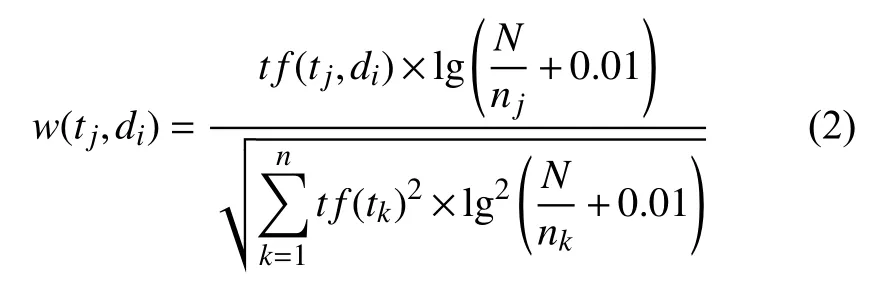
1.2 TF-IDF 算法的权重分析
传统TF-IDF 并不能很好的区分类间和类内分布所带来的影响.类间分布指的是特征词在不同类别间的分布情况,通常认为集中分布于某个类别的特征词,相比于在各个类别均匀分布的特征词,更能体现该类别的内容属性;类内分布指的是特征词在某类别内的分布情况,通常认为在某类别内各文档均普遍出现的特征词能够更好的表现该类别的内容属性,反之对于仅出现于类别内一小部分文档的特征词,往往特征词只是体现了该小部分文档的内容属性,我们应适当降低其权重.
我们使用IMDB 语料库进行实验来说明以上问题.IMDB 语料库收集了50 000 条来自互联网的严重两极分化的电影评论,我们从中分别随机抽取200、500、1000 条评论,根据式(2) 计算特征词的TFIDF 权重,并进一步计算特征词在正类评论、负类评论中的平均TF-IDF 权重.为保证实验的随机性,我们重复以上实验多次,并计算特征词的平均TF-IDF 权重.表1是部分特征词在不同文档集的权重.
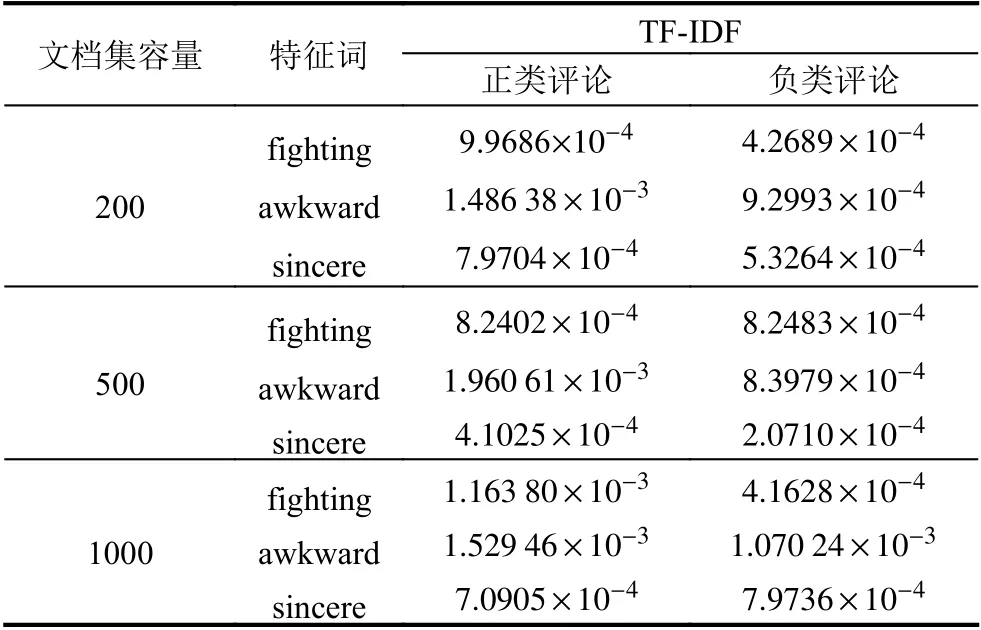
表1 部分特征词在不同文档集的平均TF-IDF 权重
在实验中我们发现大部分特征词在不同的文档集中使用TF-IDF 算法计算的权重均有较大差别,能够较好的体现特征词的内容属性,如表1中的特征词“awkward”.但是我们也发现部分特征词在有些文档集中的TF-IDF 十分接近,如特征词“fighting”在样本容量为500的文档集和特征词“sincere”在样本容量为1000的文档集中,它们在正类和负类的评价中的TFIDF 权重都极为接近.我们进一步统计分析了此类权重接近的特征词在正类评论和负类评论中的词频和文档频率.表2从不同容量的文档集中选取了部分TF-IDF权重接近的特征词,并分别比较了其在正类评论和负类评论中的词频、文档频率信息.
通过表2可以发现部分特征词的TF-IDF 权重极为接近,但其在不同类别的词频、文档频率却有着较大的差异.这说明在该情况下TF-IDF 算法并不能很好的反映特征词的类间、类内的分布信息,因此提出一种新的衡量特征词的类间、类内分布信息的方法就显得尤为重要了.
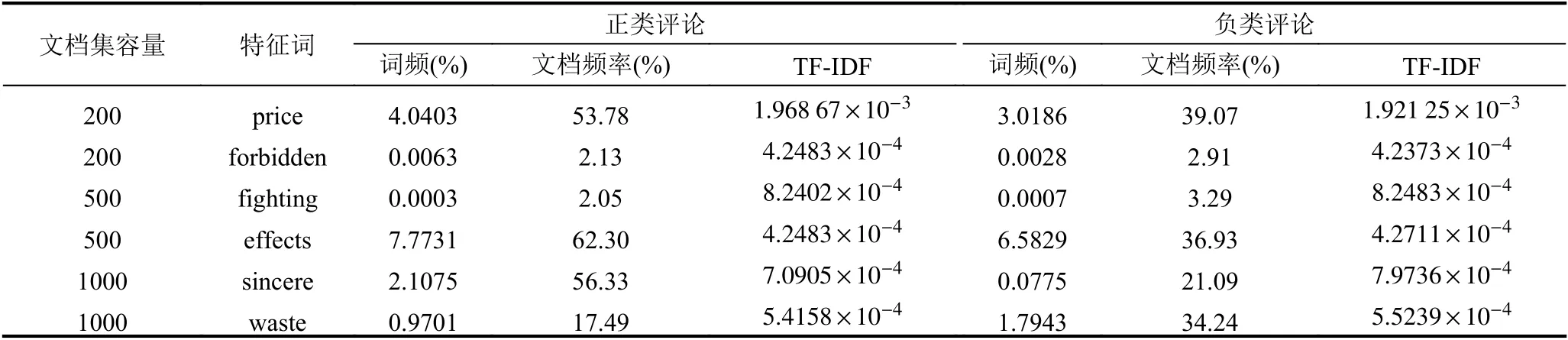
表2 部分TF-IDF 权重接近的特征词在正类评论和负类评论中的词频、文档频率
2 改进的TF-IDF 算法
文献[11]提出了改进的TF-IDF-DI 方法通过变异系数,即特征词词频在类间、类内的分布标准差与均值之比来描述其类间、类内离散程度,但仍有其缺陷:当特征词在各类别中的平均出现频率或特征词在某类别中的各文档的平均出现频率较小,以至趋近于0 时,即使微小的扰动也会导致也会对系数产生巨大的影响,不利于准确描述特征词的类信息.
本文提出一种新的类间、类内离散程度的描述方法,进而提出了改进的TF-IDF-CI 算法.我们引入特征词的类间离散度因子CIac和类内离散度因子CIic.CIac通过特征词在不同类别文档集的词频的分布标准差来描述特征词的类间分布信息;CIic通过特征词在类别ck内的词频与类别ck内实际包含该特征词的文档的词频之差描述特征词的类内分布信息.通过类信息的引入,改进的算法加强了区分特征词类别分布信息的能力.下面分别给出衡量类间离散度CIac和类内离散度CIic的方法:
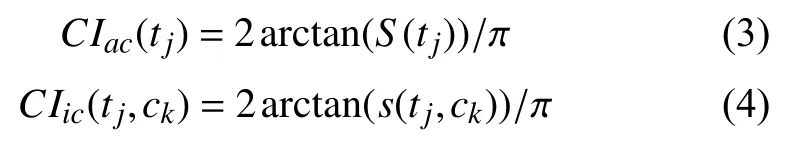
其中,S(tj) 指 特征词tj在各类别之间的词频的分布标准差;s(tj,ck)指 特征词tj在类别ck的词频与类别ck中实际包含该特征词的文档的词频之差,计算方法如下:

其中,TF(tj,ck) 表示特征词tj在类别ck中的出现频率;表示特征词tj在各类别中的平均出现频率;N(ck)表示类别ck中的文档数;n(tj,ck) 表示类别ck中包含特征词tj的文档数;C为文档集的总类别数.
在式(3)-式(6)中,我们给出了类间离散因子CIac和类内离散度因子CIic的计算方法.易发现特征词tj在不同类别中的分布标准差越大时,特征词tj越能体现不同类别的内容属性,分类能力越强;特征词tj在类别ck中的词频与特征词tj在类别ck中实际包含该特征词的文档中的词频,两者之差越大时,说明特征词tj是更突出表现了类别ck中部分文档的内容属性而不是类别ck的整体的内容属性,分类能力越弱.可见特征词的分类能力与CIac成正比,与CIic成反比.基于此我们得到了改进的TF-IDF-CI 算法:

其中,W(tj,di,ck)是改进的特征权重;w(tj,di)为式(2)中计算所得的特征词tj在文档di中的权重.
同样采用表1中所使用的文档集进行实验,表3给出部分特征词根据改进的TF-IDF-CI 算法在不同文档集中计算所得的特征权重,并与TF-IDF 算法计算的权重进行对比.
通过表3的对比容易发现,改进的TF-IDF-CI 算法有效改善了TF-IDF 算法并能很好的反映特征词类间、类内的分布信息的问题.如特征词“fighting”在样本容量为500的文档集和特征词“sincere”在样本容量为1000的文档集中,使用TF-IDF 算法的计算的特征权重极为接近,但使用TF-IDF-CI 算法则得到了有效的改善.同时,通过实验也可发现如“awkward”等使用TF-IDF 算法可以很好区分的特征词,在使用TF-IDF-CI 算法计算特征权重时亦不会有很大的偏差.
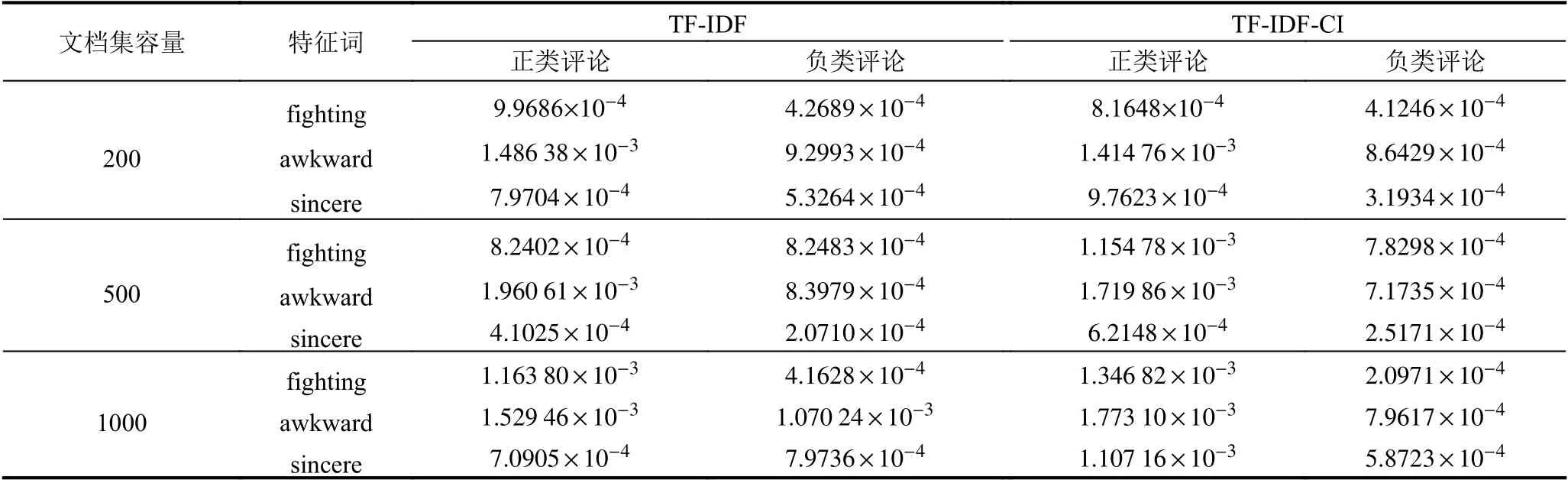
表3 部分特征词在不同文档集的TF-IDF 权重与TF-IDF-CI 权重对比
3 实验分析
实验使用的语料库是搜狗新闻数据语料库,该语料库包含来自搜狐新闻的健康、体育、社会、娱乐等18 个频道的新闻数据.实验选取了健康、教育、军事、汽车、体育5 类共5000 篇文档作为训练样本,另选取500 篇文档作为测试样本.
分词使用的是Hanlp的StandardTokenizer 分词器.同时还对分词后的数据集进行去体停用词的处理,将常用的停用词(的,并不,而且等) 进行过滤.为验证改进的TF-IDF-CI 算法对分类性能的影响,实验分别采用经典的TF-IDF 算法、TF-IDF-DI 算法、改进的TFIDF-CI 算法计算特征词的权重,并使用朴素贝叶斯算法进行文本分类,评估指标使用准确率(Precision,P)、召回率(Recall,R)、F1 值3 个指标[12].分类器在测试集上的分类性能分别如表4所示.

表4 不同权重算法的分类性能对比(%)
通过实验结果,可以发现使用改进的TF-IDF-CI 算法对特征词权重进行计算,并使用朴素贝叶斯算法对文本进行分类,准确率、召回率和F1 值都相比于经典的TFIDF 算法有了一定的提升,其中类别“健康”的提升最为明显,F1 值较TF-IDF 提升了约6.42%,较TF-IDF-DI 提升了约3.23%.这说明改进的TF-IDF-CI 算法相比于TF-IDF 算法,较好的考虑了特征词的类间、类内的分布信息,能很好的分辨出集中分布于某类别且在该类别内相对均匀出现的特征词,从而达到了提升分类性能的效果.
4 总结与反思
本文以特征词权重的计算方法为研究对象,总结了现有的一些方法,并着眼于使用相对广泛的经典的TF-IDF 算法,对国内外研究者在TF-IDF 算法的研究成果进行了介绍.本文对TF-IDF 算法在不同的文档集中的表现做了具体的分析对比,针对TF-IDF 算法未能很好区分特征词类间、类内分布的问题,做了详细的研究.基于此本文提出了一种新的衡量特征词类间、类内分布信息的方法,提出了基于类信息的改进的TFIDF-CI 算法.最后通过朴素贝叶斯模型对改进后的算法的分类性能进行验证.实验发现,改进的TF-IDFCI算法不论在准确率、召回率、F1 值上,均优于经典的TF-IDF 算法,由此证实了改进算法的有效性.
当然本文仍有不足之处:首先本文的实验均在均衡的数据集上进行实验,改进的TF-IDF-CI 算法在数据集偏斜时的表现还需要进一步实验,以验证其性能[2];同时TF-IDF-CI 算法仍还有改进空间,如将特征词在文本内的分布信息,即其位置信息进一步纳入特征权重的考虑范畴,这也是笔者今后要研究的内容.
