基于EmpowerStats的混杂因素筛选及其校正方法
2017-06-21施红英陈常中毛广运黄陈平杨新军
施红英,陈常中,毛广运,黄陈平,杨新军
(1.温州医科大学 公共卫生与管理学院预防医学系,浙江 温州 325035;2.美国哈佛大学医学院Dana.Farber癌症研究所,马萨诸塞州 02115)
基于EmpowerStats的混杂因素筛选及其校正方法
施红英1,陈常中2,毛广运1,黄陈平1,杨新军1
(1.温州医科大学 公共卫生与管理学院预防医学系,浙江 温州 325035;2.美国哈佛大学医学院Dana.Farber癌症研究所,马萨诸塞州 02115)
目的:介绍和演示一种新的混杂因素筛选和校正方法。方法:从原理简介、实例讲解、软件操作多角度全面介绍如何根据粗效应值和调整效应值的变化实现混杂因素的筛选以及独立效应评价。结果:EmpowerStats统计软件能够按照一定的标准,科学、简便地实现混杂因素的识别、筛选及其控制,得到对效应值的最优估计,优于传统的逐步回归法。结论:基于效应估计值的改变进行混杂因素的识别和筛选,可以更合理地获得研究因素的效应估计值。
混杂因素;偏倚;协变量;统计学
众所周知,一种疾病的预后、一个药物的疗效、一项指标的大小往往是多因素共同作用的结果。当研究某因素(x)与结局变量(y)之间的关联性或研究某因素(x)对于结局变量(y)的效应大小时,由于某个既与y有关,又与x有关的其他因素(z)的影响,扭曲(夸大、缩小甚至掩盖)了x与y之间的关系,这种现象就称为混杂(confounding),因此而产生的系统误差称为混杂偏倚(confounding bias),而引起该混杂偏倚的因素(z)为混杂因素(confounding factor)。简单地说,混杂因素就是会扭曲疾病和暴露之间的关联性或扭曲某研究因素效应大小的所有因素[1]。例如,在比较不同治疗方案(x)的治疗效果(y)时,如果不同治疗组之间病情、年龄等z变量不均衡,就会导致两组之间的疗效比较存在问题。所以,混杂因素是必须尽量避免和控制的,否则其研究结果可能是有偏甚至是错误的。
然而,有学者对具有同行评议的英文医学期刊中10万余篇观察性研究论文进行分析,发现仅9%的论文提及混杂评估问题,即便是一些最为权威的医学期刊,该比例也只有40%[2]。可见,混杂因素的识别和控制还是一个被学术界忽视的统计学问题。随着大数据时代的到来和临床研究的日益增多,尤其是基于真实世界的观察性临床研究数量的激增,混杂因素的识别和控制方法成为流行病学和统计学研究热点之一。如何快速、有效地识别和筛选需要控制的混杂因素,进而更加客观科学地评价某治疗方案的疗效或某因素对于结局变量的效应,成为很多临床医师或科研工作者统计分析时遇到的最棘手问题之一。
1 传统协变量筛选方法及存在的问题
假设我们要研究x对于y的影响,是否需要调整若干个z的影响呢?一般地,我们会先进行单因素分析,然后基于各个z因素与y变量是否有关系即P是否小于0.05决定是否需要调整该z变量。该方法存在两个问题:①z和y的关系受到其他因素的混杂作用,不一定是他们的真实关系;②P值会受到样本量或者说检验效能的影响,样本量大得到的P值就会小,反之P值就会大。
第二种做法,很多科研人员会直接采用逐步回归法,将最后留下来的所有变量所组成的回归模型中x的效应值,直接作为其对于y的独立效应值。这样的做法也是不科学的。比如,一个数据库中有1个y、5个x,通过后退法依次得到下面3个多重线性回归方程,表1中数据表示的是3个方程中各个x的偏回归系数及其可信区间和P值。
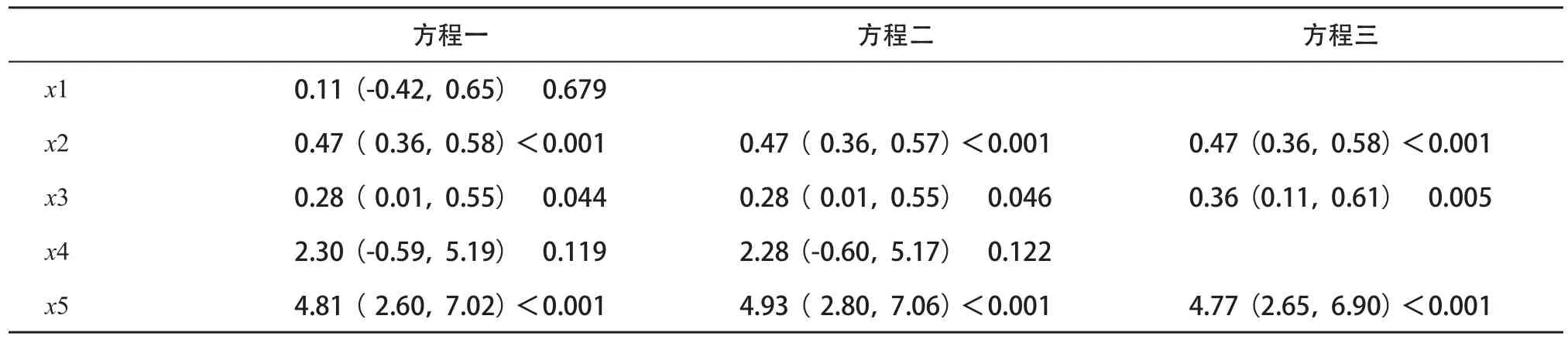
表1 3个回归方程中各个x的效应值[ b(95%CI)P]
根据后退法,首先纳入所有5个x拟合方程一,发现x1无统计学意义且P值最大,因此剔除x1,得到方程二;方程二中,x4无统计学意义且P值最大,所以又剔除x4,得到方程三;剩下的3个自变量全部有统计学意义,这是后退法最终得到的结果。据此,如果研究目的是分析x3对于y的作用,那么其独立效应的最终分析结果就是0.36(此时调整了x2和x5的混杂效应)。
但是,仔细考察3个方程会发现,在调整x4前后,x3的偏回归系数变化很大,这是为什么?由于x3与x4关系较大,不调整x4,x4的作用就加到x3身上去了;调整了x4,就是把x4的作用从x3中剥离出来,这时看到x3的偏回归系数就变小了。所以,如果分析目的是确定x3对y的作用,就应该选方程二,因为方程二中的偏回归系数更确切地表达了x3对y的作用;而不能因为x4的P值大于α,就不调整x4,因为P值会受到样本量的影响。
因此,目前一些研究认为,在分析x对于y的效应时,是否调整潜在混杂变量z的作用,其更合理的做法应该是根据调整各个z变量前后看x对于y的效应值是否发生了足够大(通常是10%)的改变[3]。这里,我称之为基于效应值改变的协变量筛选方法。该方法已在The New England Journal of Medicine、BMJ等权威期刊中使用[4-5],并得到大家一致认可。
2 基于效应值改变的协变量筛选方法
如何基于效应值改变进行协变量筛选呢?我们可以分两步进行分析。步骤1,运行基本模型即然后在基本模型中引入待考察的zi得到模型步骤2,运行完整模型即然后在完整模型中剔除zi得到模型
分别根据两个步骤中效应估计值b1到b1’的变化,决定是否需要调整zi的作用。但是,x的两个效应估计值之间变化到多大才能判为混杂、才需要控制呢?不同文献采用的标准略有不同,多数研究以效应值改变大于10%为标准[6],也有研究以改变大于5%为标准[5]。
然而,在实际医学科研数据中,需要筛选的z变量往往比较多,此时需要按照上述步骤依次判断各变量引入模型前后效应估计值的改变情况,其工作量和难度很大。尤其是采用传统统计软件比如SPSS、SAS等实现上述过程的筛选和判定,过程较为复杂,并且容易出错,更是非统计专业人员难以完成的。
基于数据分析思路而设计开发的EmpowerStats软件,可以采用菜单对话框式操作,非常方便地根据上述标准自动筛选出这些需要控制的混杂因素,为后续多因素分析及独立效应评价提供基础。该软件中的“协变量检查与筛选”模块,专门用于筛选哪些协变量应该包括在回归模型中进行调整、控制,解决了上述难题。其分析结果主要包括:①逐个查看各个协变量和y的关系,看P是否小于检验水准α;②调整与不调整这些因素情况下x对于y的效应值有何改变;③汇总在分析x对y的效应时需要调整哪些z因素的作用。
3 实例分析和软件操作
案例:为了研究川崎病(Kawasaki diseaes,KD)疾病类型(1=不完全KD,0=完全KD)对于患者预后y即冠状动脉损害(coronaryartery lesions,CAL)(1=有,0=无)的独立效应,课题组记录了近6年共930例患者的疾病类型和CAL情况,同时还收集了月龄、性别(1=男,0=女)、分娩方式(1=自然分娩,2=剖宫产)、体质量指数(body mass index,BMI)(kg/m2)、治疗时机(1=延误治疗,0=及时治疗)、治疗前CA(1=是,0=否)、血钠(1=低,2=高)等7个变量信息。现拟筛选其中哪些变量是需要控制的,并在此基础上估计KD类型对于CAL的独立效应。
软件操作:在EmpowerStats软件的主界面中,选择“数据分析”菜单下的“协变量检查与筛选”模块,按照图1设置好结局变量、暴露因素和拟筛查的协变量,点击“查看结果”按钮即可。
软件会自动采用两种方法对协变量进行筛查:①逐个分析协变量与y的关系;②在基本模型中引进协变量与在完整模型中剔除协变量,观察x的偏回归系数的变化。随后列出详细分析结果。
最后,软件会根据两种标准汇总筛选出协变量。本例,根据标准1即基于效应值改变筛选出来的变量有:月龄、治疗时机、治疗前CA、血钠;而根据标准2即基于效应值改变结合单因素分析结果筛选出来的变量有:月龄、性别、BMI、治疗时机、治疗前CA、血钠。
筛选好协变量后,我们可以采用该软件“数据分析”菜单下的“多个回归方程”模块,根据前述分析结果结合既往研究和专业知识设置调整不同协变量组合下的各种模型,分析查看x对于y的独立效应,结果见表2。
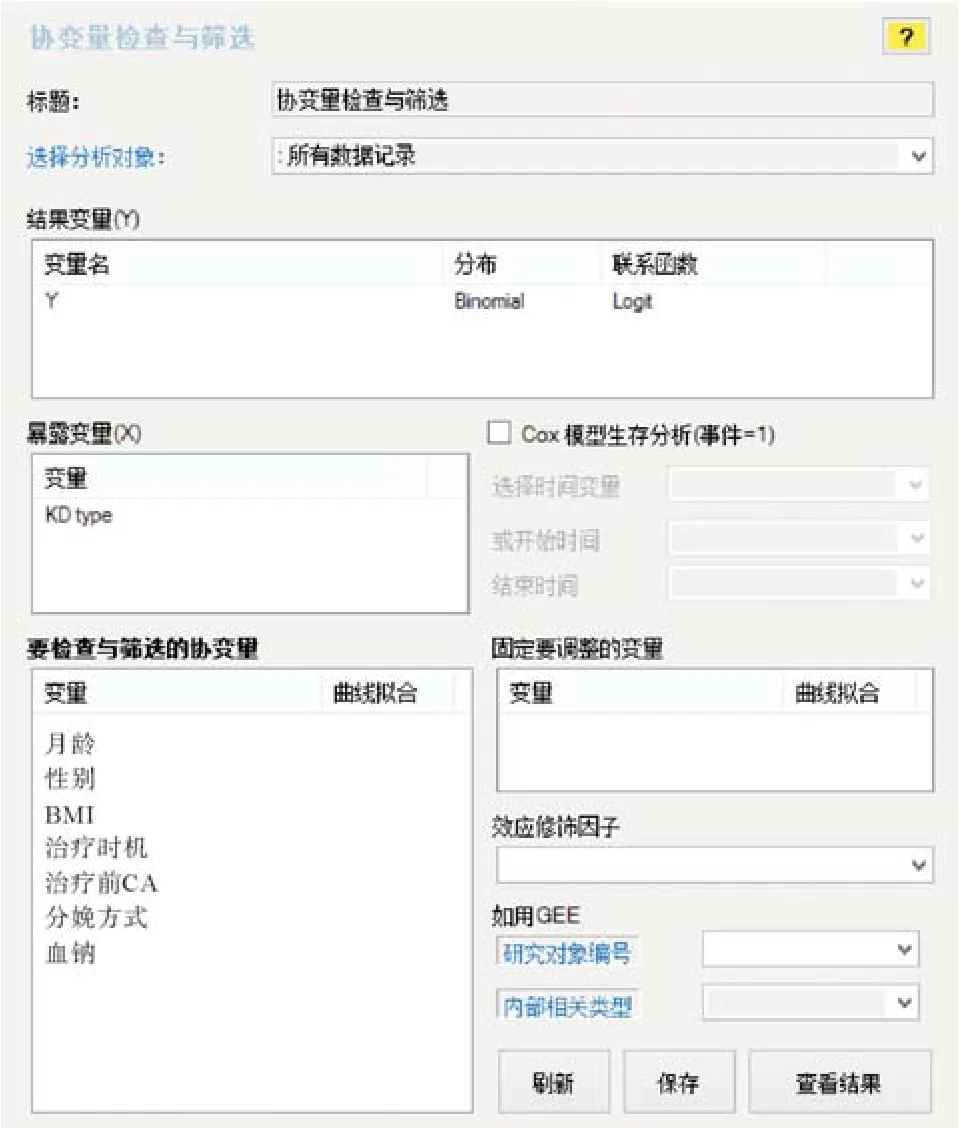
图1 协变量检查与筛选主界面

表2 多个回归方程分析KD类型对于CAL的独立效应
软件自动列出了三种模型中x对于y的效应分析结果。可见,在不调整任何协变量或只调整年龄和性别的情况下,KD类型的OR值都大于1,而且有统计学意义,不完全KD发生CAL风险高于完全KD;但是当调整治疗时机、治疗前CA等其他混杂因素后,KD类型对于CAL的独立效应变得无统计学意义了。而表2也正是很多SCI论文中核心结果的表达方式。
值得一提的是,EmpowerStats软件会自动根据y变量的类型,选择相应的回归模型并估计x的效应量。比如本例中y为是否发生CAL即二分类变量,所以软件选择的是logistic回归模型,得到的效应估计值是OR值及其可信区间。如果y是定量变量,软件自动选择多重线性回归模型,并呈现偏回归系数及其可信区间。如果y是生存资料即包括结局和生存时间,则软件会自动选择Cox回归模型,并呈现危险比(hazard ratio,HR)及其可信区间等分析结果,非常灵活方便。
4 注意事项
一项好的科学研究,首先在科研设计时,就必须明确研究中的结局变量y和重点关注的研究因素x,也就是要有一个明确的科研假设,比如体育锻炼是否会影响血压值、经常饮酒是否会导致脂肪肝、某个基因多态性是否会影响一个疾病的发生等,这是开展一项研究的首要前提,也是科研设计或复习文献时非常关键的第一步[7],决定研究设计的类型和统计分析方法。有了研究假设之后,不管你采用的是病例对照研究、队列研究还是实验研究,接下来的第二个关键点,就是要尽可能全面地考虑所有潜在的混杂因素,特别是既往研究已经发现的重要混杂因素,以免造成结果无法解释等局面。这是进行科研假设探索或验证性研究中首先要树立起来的意识。然后,才是想方设法控制和减少这些混杂因素的影响,可以在设计和分析阶段分别进行控制。
首先,在设计阶段,我们可以采用限制、匹配和随机化分组等方法避免或减少混杂因素的影响。例如,为了研究吸烟对于肺癌的影响,我们只选择男性作为研究对象,就可以控制性别的混杂效应。但是这种方法会导致研究对象的代表性受限制,研究结论的外推性受影响。再比如,为了研究A型行为模式对于心梗的影响,选择340例心梗患者作为病例组,同时选择与之年龄、性别和社区相同的340例无心梗者作为对照组,进行病例对照研究,就可以消除年龄、性别和社区不同导致的混杂效应,提高检验效率;但是也失去了分析该因素的机会,不仅不能分析该因素的单独效应,也无法分析该因素和其他因素之间的交互作用。所以,要注意避免匹配过度。此外,在实验研究中,我们通常采用随机分组的方法,使得研究对象具有同等的机会被分到各个处理组,从而让一些潜在的混杂因素或主要非处理因素在各组间分布均衡。不过,这三种方法通常只能控制少数混杂因素的干扰。而在医学研究中,尤其是大数据时代的到来,临床研究的题目越来越大,涉及的混杂因素也越来越多,如果研究者设计时未考虑和收集一些重要的混杂因素,其研究质量就会大打折扣。在既往很多医学论文的审稿过程中以及诸多医务人员科研数据的统计咨询中,我们发现,国内很多医务人员往往忽视了混杂因素尤其是重要混杂因素的收集。
其次,如果设计阶段已经考虑并收集了可能的混杂因素,那么混杂因素的校正和控制问题就进入了数据分析阶段。此时,混杂因素的控制方法可谓是多种多样,经典的方法包括分层分析、协方差分析、标准化法、多因素回归模型等。近些年又逐步兴起一些新的协变量控制方法,比如倾向性评分法(propensity score,PS)[8-11]、工具变量[12]等,但多适用于统计学专业人员,不能被临床医师等广泛使用。所以,分层分析和多因素回归模型依然是目前最为常用、最容易理解的控制混杂因素的方法。分层分析,就是将资料按照拟控制的混杂因素进行分层,然后估计某暴露因素和疾病之间关联性或评价某处理因素的效应大小。如果各层间研究因素与疾病间的关联性一致,即不存在交互作用,计算调整的效应值即可;如果各层间研究因素与疾病间的关联性不一致,即存在交互作用,则后续的分析都应该按此分层因素分别进行分析,也就是要分析单独效应。分层分析容易理解和实现,是论文中控制混杂的最常用方法之一[13];但是,分层分析不能得到一个总的x对于y的独立效应,而这又是很多研究中需要的核心结果,此时多因素回归模型成为最重要的替代方法。但是,如前所述,既往人们在使用多因素回归模型进行混杂的控制时存在一定误区,导致其往往没有用好、用巧回归模型。
最后,为了更有效地控制混杂因素,还需要特别注意混杂变量尤其是定量的混杂变量引入模型的方法。假设年龄是混杂因素,是直接将年龄作为定量变量引入模型?还是将年龄分组后作为等级变量引入模型?或者分类后作为哑变量引入模型?甚至是否需要将年龄的二次项引入模型?都需要考虑各个混杂变量与结局变量的关联形态等进行综合确定,而不是随意引入模型:当年龄对结局变量的影响是线性时,可直接引入模型;但是如果年龄对于结局指标的影响是U型趋势或不同年龄组对于结局的影响不等比例增加时,则可能需要将其分组后作为哑变量形式引入模型,甚至引入二次项纳入模型[14]。
在多因素回归模型中,采用基于“效应估计值改变量的方法”对潜在混杂因素进行筛选和控制,弥补了传统方法的不足,不失为较好的混杂因素控制方法之一。本研究详细介绍了该方法的原理以及采用EmpowerStats软件实现协变量筛选的具体操作过程,简单、实用,弥补了传统方法单纯依赖于P值或逐步回归法筛选混杂因素的局限性,从而使研究中的效应估计值更加科学和准确;而且该软件无需编写程序,只需菜单对话框式操作,并根据y变量类型自动选择统计模型和效应量,直观方便,可以说是科研人员尤其是临床医生在科学研究中实现混杂因素筛选和校正的优选软件。
[1] KROUSEL-WOOD M A, CHAMBERS R B, MUNTNER P. Clinicians’ guide to statistics for medical practice and research: Part II[J]. Ochsner J, 2007, 7(1): 3-7.
[2] GROENWOLD R H, HOES A W, HAK E. Confounding in publications of observational intervention studies[J]. Eur J Epidemiol, 2007, 22 (7): 413-415.
[3] LEE P H. Is a cutoff of 10% appropriate for the change-inestimate criterion of confounder identi fi cation?[J]. J Epidemiol, 2014, 24(2): 161-167.
[4] KERNAN W N, VISCOLI C M, BRASS L M, et al. Phenylpropanolamine and the risk of hemorrhagic stroke[J]. N Engl J Med, 2000, 343(25): 1826-1832.
[5] BAGLIETTO L, ENGLISH D R, GERTIG D M, et al. Does dietary folate intake modify effect of alcohol consumption on breast cancer risk? Prospective cohort study[J]. BMJ, 2005, 331(7520): 807-810.
[6] LIU T, DAVID S P, TYNDALE R F, et al. Associations of CYP2A6 genotype with smoking behaviors in southern China[J]. Addiction, 2011, 106(5): 985-994.
[7] KROUSEL-WOOD M A, CHAMBERS R B, MUNTNER P. Clinicians’ guide to statistics for medical practice and research: part I[J]. Ochsner J, 2006, 6(2): 68-83.
[8] 赵晓蒙, 李炳海, 王素珍, 等. 经倾向指数匹配后的gp方案与np方案治疗非小细胞肺癌的疗效评价[J]. 中国卫生统计, 2014, 31(1): 34-36.
[9] 王永吉, 蔡宏伟, 夏结来, 等. 倾向指数第一讲倾向指数的基本概念和研究步骤[J]. 中华流行病学杂志, 2010, 31 (3): 347-348.
[10] 王永吉, 蔡宏伟, 夏结来, 等. 倾向指数第二讲倾向指数常用研究方法[J]. 中华流行病学杂志, 2010, 31(5): 584-585.
[11] ELLIS A R, DUSETZINA S B, HANSEN R A, et al. Confounding control in a nonexperimental study of STAR*D data: logistic regression balanced covariates better than boosted CART[J]. Ann Epidemiol, 2013, 23(4): 204-209.
[12] STUKEL T A, FISHER E S, WENNBERG D E, et al. Analysis of observational studies in the presence of treatment selection bias: effects of invasive cardiac management on AMI survival using propensity score and instrumental variable methods[J]. JAMA, 2007, 297(3): 278-285.
[13] VOLPP K G, TROXEL A B, PAULY M V, et al. A randomized, controlled trial of fi nancial incentives for smoking cessation[J]. N Engl J Med, 2009, 360(7): 699-709.
[14] LEE C C, LEE M T, CHEN Y S, et al. Risk of aortic dissection and aortic aneurysm in patients taking oral fluoroquinolone[J]. JAMA Intern Med, 2015, 175(11): 1839-1847.
(本文编辑:丁敏娇)
Selection and adjustment of potential confounders based on changes of effect size using EmpowerStats
SHI Hongying1, CHEN Changzhong2, MAO Guangyun1, HUANG Chenping1, YANG Xinjun1.
1.Department of Preventive Medicine, School of Public Health, Wenzhou Medical University, Wenzhou, 325035; 2.Dana Farber Cancer Institute, Medical College of Harvard University, Massachusetts, 02115
Objective: To introduce a new method for selecting and adjusting confounding factors. Methods: The disadvantage of traditional method for selecting confounders including methods based on P value or stepwise regression was analyzed was analyzed, and a new method based on the change of effect size was proposed to select the potential confounders which need to be controlled. And the study also demonstrated the application of EmpowerStats software using the new method. Results: EmpowerStats statistical software could automatically choose right regression methods and select the appropriate confounding factors based on the change of effect size conveniently. Conclusion: Selecting confounding factors based on the change of effect size is a better choice, and can give a more accurate independent effect, and has been widely used and accepted worldwide.
confounding factors; bias; covariate; statistics
R195.1
A
10.3969/j.issn.2095-9400.2017.05.010
2016-12-15
国家自然科学基金青年基金资助项目(81502893);浙江省公益性技术应用研究计划项目(2014C33160);浙江省教育厅科研基金资助项目(Y201327770)。
施红英(1980-),女,浙江丽水人,副教授,在职博士生。
