基于VPMELM的滚动轴承劣化状态辨识方法
2017-04-21郑近德潘海洋童宝宏张良安
郑近德, 潘海洋,2, 童宝宏, 张良安,2
(1.安徽工业大学 机械工程学院,安徽 马鞍山 243032;2.马鞍山市安工大工业技术研究院 工业机器人研究所,安徽 马鞍山243000)
基于VPMELM的滚动轴承劣化状态辨识方法
郑近德1, 潘海洋1,2, 童宝宏1, 张良安1,2
(1.安徽工业大学 机械工程学院,安徽 马鞍山 243032;2.马鞍山市安工大工业技术研究院 工业机器人研究所,安徽 马鞍山243000)
针对变量预测模型模式识别方法(VPMCD)仅仅包含几种简单数学模型的问题,所建立的预测模型不足以反映特征值之间的复杂关系;极限学习机(ELM)回归模型是一种复杂且被广泛应用的模型,其模型可以反映特征之间的相互关系。结合极限学习机回归模型和VPMCD方法的优点,提出了一种基于极限学习机的变量预测模型(VPMELM)模式识别方法,并将该方法应用于滚动轴承劣化状态实验中。实验表明,基于VPMELM的辨识方法可以有效地对滚动轴承的劣化状态进行识别。
极限学习机;变量预测模式识别方法;基于极限学习机的变量预测模型;滚动轴承
当机械正常运行时,需要定期或者不定期进行检修,目的就是为了避免事故的发生。但是有些零部件出现故障时,工作呈现正常状态,实际是安全隐患,需要及时排除。滚动轴承作为旋转机械的主要零部件,其诊断也主要是对滚动轴承的滚动体、内圈和外圈故障等进行识别,而很少有对某一特定故障类型的劣化(损坏)程度进行辨识[1]。因此,如何检测出这种劣化程度,成为相关学者研究的热点。人工神经网络和支持向量机作为常用的模式识别方法[2],可以辨识劣化程度,且在工程中得到了一定的应用,取得了较好的应用效果。但是上述方法还不够完善,或多或少存在一定的缺陷[3-4]。因此,探索一种训练速度快、获得全局最优解,且具有良好的泛化性能的训练算法是模式识别发展的主要目标。
极限学习机(Extreme Learning Machine,ELM)回归[5-6]是一种基于神经网络的学习回归算法,该回归算法随机产生输入层与隐含层间的连接权值及隐含层神经元的阈值,且在训练过程中无需调整,只需要设置隐含层神经元的个数,便可以获得唯一的最优解。与传统的回归训练方法相比(BP(Back Propagation)回归),该方法具有学习速度快、泛化性能好等优点,且具备支持向量机的优点[7]。但是对于大中型数据集的系统辨识和分类问题,易于出现最优节点数难于确定等问题。
特别注意的是,上述模式识别方法并没有考虑分类特征之间的联系,而实际上提取的分类特征之间确实存在某种特定的联系。基于此,RAGHURAJ等[8-9]提出了变量预测模型的模式识别(Variable Predictive Mode Based Class Discriminate, VPMCD)方法。VPMCD方法首先采用固有的四种模型建立预测模型,接着以最小二乘回归作为参数拟合方法得出模型参数,然后通过回代特征选出最优预测模型,最后利用选择的最优预测模型完成分类。虽然该方法已在生物学和机械学中得到应用,但是VPMCD中包含的四种模型比较简单,不足以反映特征值之间的复杂关系。另外,VPMCD预测模型的建立其实是不同的特征值组合建立四种VPM模型,即线性、二次、交互和二次交互模型。特征值之间的关系较为简单时,用这四种模型足以完成建模及分类,但是当特征值之间的关系较为复杂时,特征值之间的关系不是特别有规律(工程实际中由于外部因素的存在,特征值之间的关系确实不明显),这时用原VPMCD方法中的四种数学模型建立预测模型就很难满足分类的需要。因此,鉴于VPMCD对复杂数据的建模缺陷性,拟对VPMCD建模方法进行改进。
因此,本文拟调用ELM建立预测模型,以及采用ELM非线性回归拟合出模型参数,ELM回归令隐含层的激活函数为无限可微函数,从而可以随机选择和调整隐含层节点的参数[10],消除了模型简单性的缺陷,建立能反应特征值之间复杂关系的非线性高斯函数模型,提出了基于极限学习机的变量预测模型(Variable Predictive Mode based Extreme Learning Machine, VPMELM)模式识别方法,该方法克服了VPMCD固有的建模缺点,建立比较成熟的ELM模型,从而提高了预测模型的分类效果和精度。
1 基于极限学习机的变量预测模型模式识别方法
1.1 ELM回归方法理论
ELM回归方法的目标就是寻求变量x和变量y之间的相互关系,即寻找一个最优函数能使预测的曲线拟合误差最小为原则。选出一定量的训练样本为
P={xi,y}xi∈Rd,y∈R,i=1,2,…,n
xi=[xi1,xi2,…,xim]∈R,y=[y1,y2,…,ym]∈R
ELM回归模型包含三个层次,即输入层、输出层和隐含层。设定输入层为n个神经元,也就是对应着n个变量,选择隐含层为a个节点。
设输入层第个变量i与隐含层各个节点间的连接权值为w=[wi1,wi2,…,wia]T;设隐含层神经元的阈值为b=[b1,b2,…,ba]T,隐含层节点与输出变量的连接值为βk=[β1,β2,…,βa]T,隐含层神经元的激活函数为g(x)。则具有a个隐含节点的ELM模型的决策函数可以表示为
(1)
式(1)还可以表示为
Hβ=T′
(2)
式中:T′为对实际输出的一个估计;H为神经网络隐含层的输出矩阵。
综上所述,当激活函数g(x)无限可微时,ELM的参数无需全部调整,即输入连接权值和隐含层节点阈值在训练开始时可随机选择,且在训练过程中可固定不变,只需在训练前设置隐含层节点的个数和激活函数即可。隐含节点与输出点的连接权值可通过求解以下线性方程组的最小二乘解来获得
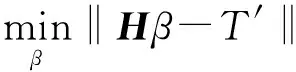
(3)
式中,β的解具有唯一性,可使网络的训练误差最小,并使网络模型具有较好的泛化性能。
1.2 VPMELM方法
VPMELM方法采用了VPMCD的分类原理和ELM回归模型的建模思想。首先对信号提取特征值,并建立特征矩阵;然后对特征矩阵建立模型,由于同一样本特征值之间或多或少存在一定的关系,这种依赖关系可能是线性的或者非线性的,但是其中的具体关系不得而知,只是选择一种或者几种代理模型进行建模,寻找最接近这种真实关系的代理模型;最后根据建立的代理预测模型完成分类。对于一种状态的特征值X=[X1,X2,…,Xp],可以建立的代理模型为
Xi=f(Xj,b0,bj,bjj,bjk)+e
(4)
式(4)是对Xi建立的数学模型VPMi。
式中:特征量Xi为被预测的变量;Xj(j≠i)为预测变量;e为预测误差;b0,bj,bjj,bjk为模型参数。
VPMELM分类方法:
(1)拾取振动信号样本,并提取振动信号特征值组成特征向量;
(2)把特征值样本分为训练和测试样本;
(3)采用ELM回归模型对训练样本建立预测模型;
(4)用建立的ELM预测模型以预测误差平方和最小为依据对测试样本完成分类。
1.3 比较分析
为了验证VPMELM中ELM回归的优越性,现采用美国西储大学的滚动轴承振动信号数据[11],选取其中的正常信号数据,其滚动轴承试验参数如表1所示。实验拾取20组振动信号,由于振动信号常表现为非线性和非稳定性,以及拾取的振动信号中可能包含大量的背景信号和噪声,如果直接提取数据的特征值,使得原本具有复杂关系的特征值更加复杂。为了最大限度的削弱这种复杂性,提取特征值之前,拟采用信号处理方法进行处理。目前常用的信号处理方法有小波、EMD(Empirical Mode Decomposition)、LMD(Local Mean Decomposition)和ITD(Intrinsic Time-scale Decomposition)等[12-13],但是这些方法都存在一些致命的缺点,严重制约着分解的效果,进而影响特征的提取。鉴于上述几种信号处理方法的缺点,程军圣等人于2012年提出了局部特征尺度分解方法(Local Characteristic scale Decomposition,LCD)[14],并取得了较好的分解效果,克服了上述几种方法的缺陷,得到更加真实的分量信号。因此,本文首先采用LCD方法对振动信号进行处理,得到该非平稳信号在时域和频域的局部化信息,然后提取前四个分量的奇异值作为特征向量,因此每组数据有四个值,从而可以得到具有复杂关系的20×4矩阵。其特征值如表2所示(取Y为待预测值;X1、X2、X3为预测数据)。

表1 滚动轴承参数
首先把提取的特征值进行分类,分为预测变量(Y)和被预测变量(X1、X2、X3);然后利用预测变量和被预测变量分别建立不同的预测模型(线性模型、二次模型、交互模型、二次交互模型和ELM模型);最后用建立的预测模型分别对预测值Y进行预测(回代),其预测结果图及预测误差图如图1和图2所示。
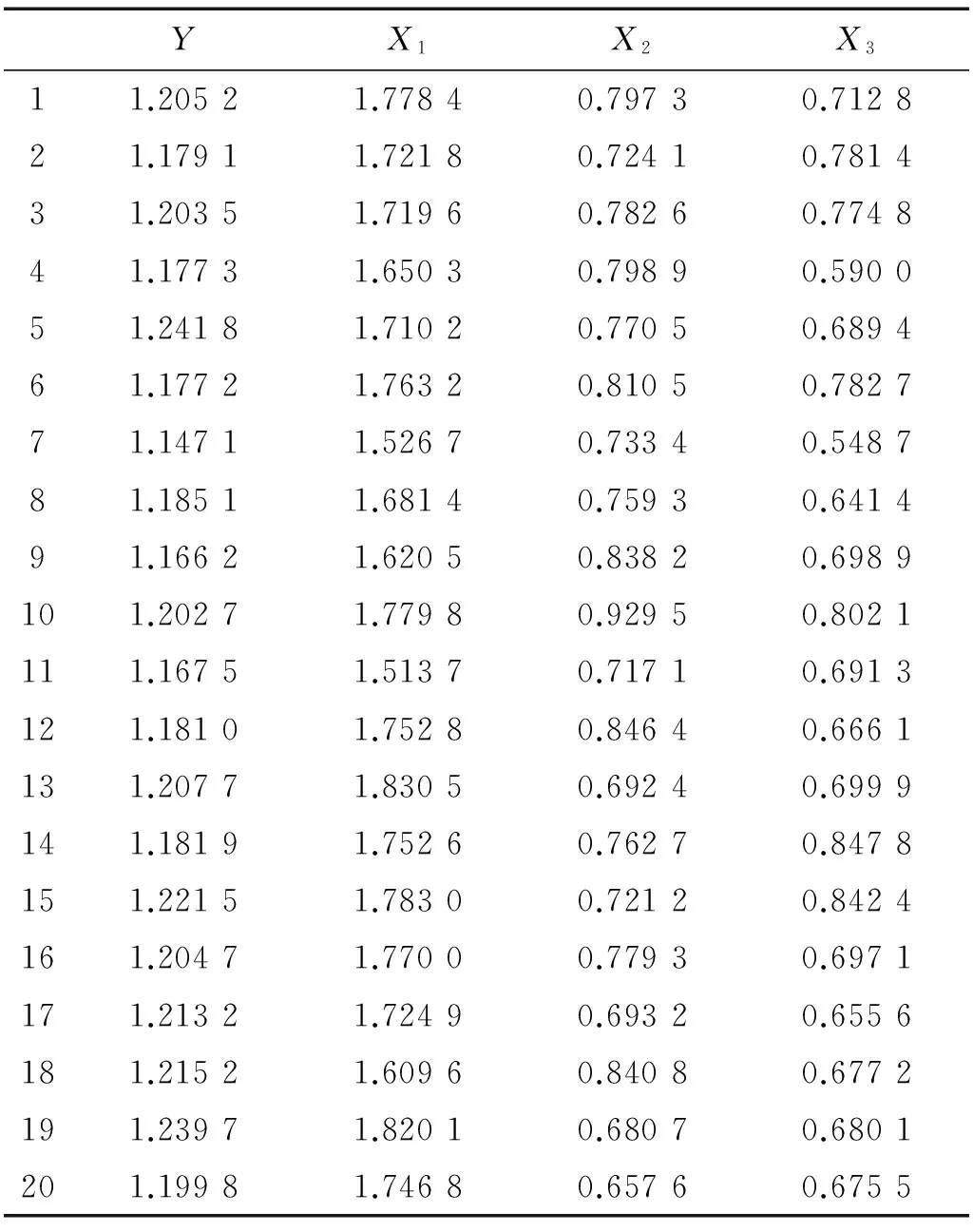
表2 提取的信号特征值
从图1和图2可知,ELM预测模型的预测结果最为理想,其预测值几乎等于真实值,预测误差很小,直观上看并没有太大偏差。而另外几种模型的预测结果就不尽理想,其绝对误差值甚至超过0.2,偏离真实值较为严重,其中最为理想的是线性模型,但与ELM模型相比,还是存在一定的差距。究其原因,由于实际情况中,提取的特征值之间关系非常复杂,简单的二次交互模型、线性模型等等并不能反应这种关系,利用这20个样本建立的模型不能准确的估计出回代变量,导致预测结果不甚理想。
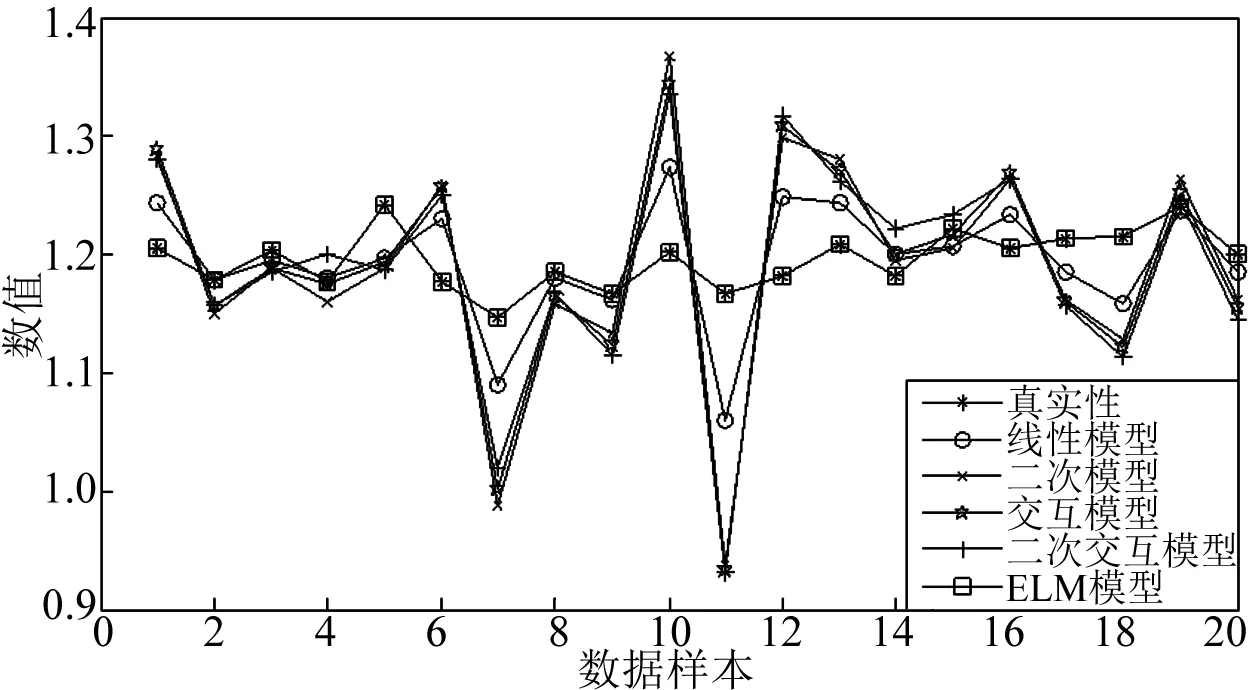
图1 五种模型的预测结果Fig.1 The prediction results of five kinds of models
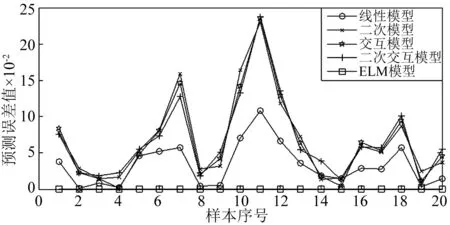
图2 五种模型的预测误差值Fig.2 The prediction error values of five kinds of models
2 实例应用
为了验证ELMVPM的实用性,将基于VPMELM模式识别方法应用于滚动轴承内圈故障程度预测。同样采用美国西储大学的滚动轴承数据,由于滚轴轴承内圈、外圈和滚动体随着工作时间延续,都会发生不同程度的损坏,本文仅选择内圈不同故障程度下的振动信号数据。分别拾取不同故障程度下的内圈振动信号为200组(故障直径为0.178 mm和故障深度为0.279 mm的轻度故障、故障直径为0.356 mm和故障深度为0.279 mm的中度故障、故障直径为0.533 mm和故障深度为0.279 mm的重度故障、正常状态轴承)。
由于正常信号和内圈故障信号均表现为非线性及非稳定性,且测取信号时,也包含了大量的噪声信号和背景信号。因此,首先采用LCD分解,得到的分量在时域和频域同时具有局部化信息,减弱了非稳定性及非线性的影响;接着对各分量进行分析,发现信号的重要信息主要集中在前几个分量,而噪声信号和背景信号则分布在后几个分量及余量上,因此本文只对前四个分量进行分析并提取分量奇异值作为特征值;然后把样本分为训练样本和测试样本,训练样本通过VPMELM训练,得到ELM预测模型;最后把训练得到的ELM预测模型作为分类模型对测试样本进行分类。为了避免偶然因素的存在,每种劣化状态随机取出80组作为测试样本,然后把训练样本随机分为30组、40组、50组、60组、70组、80组、90组、100组、110组和120组,同时与VPMCD分类方法进行对比,不同训练样本下得到的识别率如图3和图4所示。
从图3和图4可知,不论训练样本为多少组,VPMELM的准确识别率总保持在98.4%~100%,而VPMCD的准确识别率只保持在96%~98.4%,VPMELM的识别率平均比VPMCD高出两个百分点,这是由于VPMELM建立了更能反映特征值之间复杂关系的预测模型,使得特征预测值更加接近真实值,因此具有很高的识别率。
图3和图4表明了不论训练样本的个数是多少,VPMELM的识别率总高于VPMCD。为了更好地说明VPMELM方法的优越性,将对每种状态的识别结果和识别精度进行分析。每种状态随机选取100组作为训练样本,其余100组作为测试样本,用VPMCD和VPMELM同时进行分类识别,两种方法的识别结果如图5和图6所示(纵坐标数字1、2、3和4分别表示真实的轻度内圈故障类型、中度内圈故障类型、重度内圈故障类型和正常类型)。
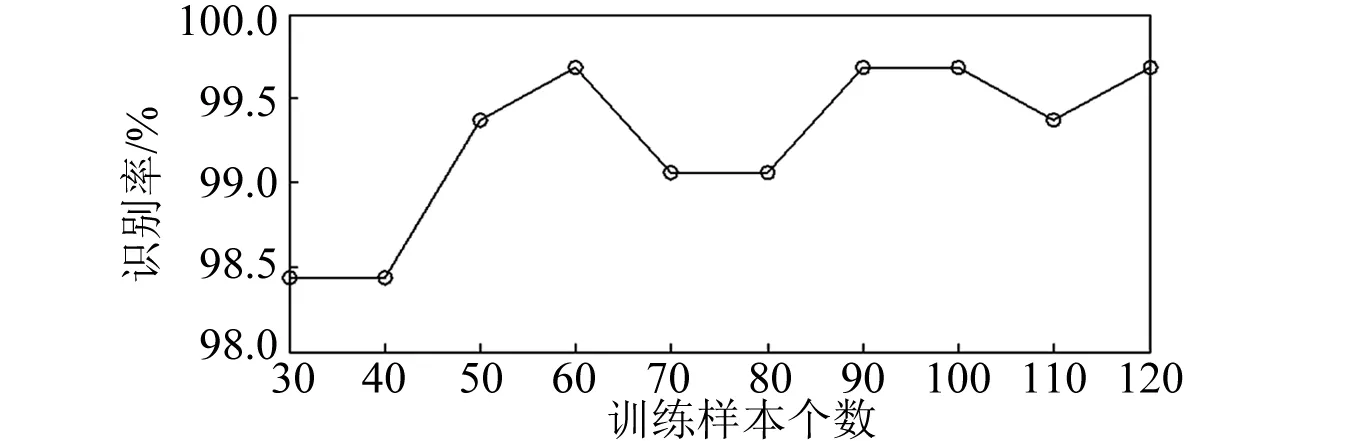
图4 VPMELM在不同训练样本得出的识别率Fig.4 The recognition rate of VPMELM in different training sample
从图5和图6可知,由于工程实际情况的复杂性,对每一组数据完全诊断出来是不现实的,只需要最大限度的减少误判。因此在用VPNCD和VPMELM进行识别测试样本时,都出现了不同程度的错误分类,但是从图中可以直观的看出,VPMELM识别结果远比VPMCD识别方法要好。VPMCD能准确识别出的样本,VPMELM完全能够识别出来,而VPMCD不能识别出的样本,VPMELM也能大部分识别出来,对于400组测试样本,VPMELM方法只错误识别一个,具有较高的识别率。这是由于VPMELM方法融合了ELM模型和VPMCD的优点,建立的ELM特征预测模型能够更加准确的反映各个特征值相互之间的复杂关系,从而利用VPMCD理论及判别方法准确识别待测试样本。
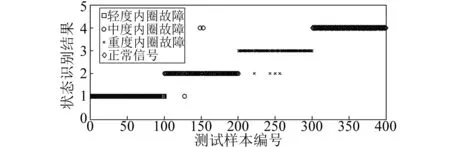
图5 VPMCD劣化状态识别结果Fig.5 Deterioration state identification result for testing samples with VPMCD
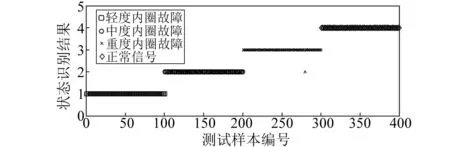
图6 VPMELM劣化状态识别结果Fig.6 Deterioration state identification result for testing samples with VPMELM
VPMCD和VPMELM的判别原理一样,都是预测特征值的大小,根据预测误差平方和的大小判断滚动轴承内圈最终的损害程度。方法步骤同上,也是100组训练,100组测试,由于判别依据是每个样本的预测误差平方和,然而预测误差平方和数量级相差过大,不易直观展示,因此,对每个样本的预测误差平方和作对数处理,如图7和图8所示,由于篇幅限制,只显示正常样本的20个预测误差平方和对数值。
图7和图8从识别精度方面阐述两种方法的优劣,当分类方法是VPMCD时,用正常信号特征值建立的模型去完成测试样本特征预测,全部完成准确分类,预测的正常样本数据与其他三种状态的数据预测误差平方和对数值最小相差5~6。当分类方法是VPMELM时,用正常信号特征值建立的模型去完成测试样本特征预测,也全部完成准确分类,预测的正常样本数据与其他三种状态的数据预测误差平方和对数值最小相差10~15,更易完成分类,精度更高。因此,从图7和图8可知, VPMELM模式识别方法比原VPMCD方法有更高的识别精度。
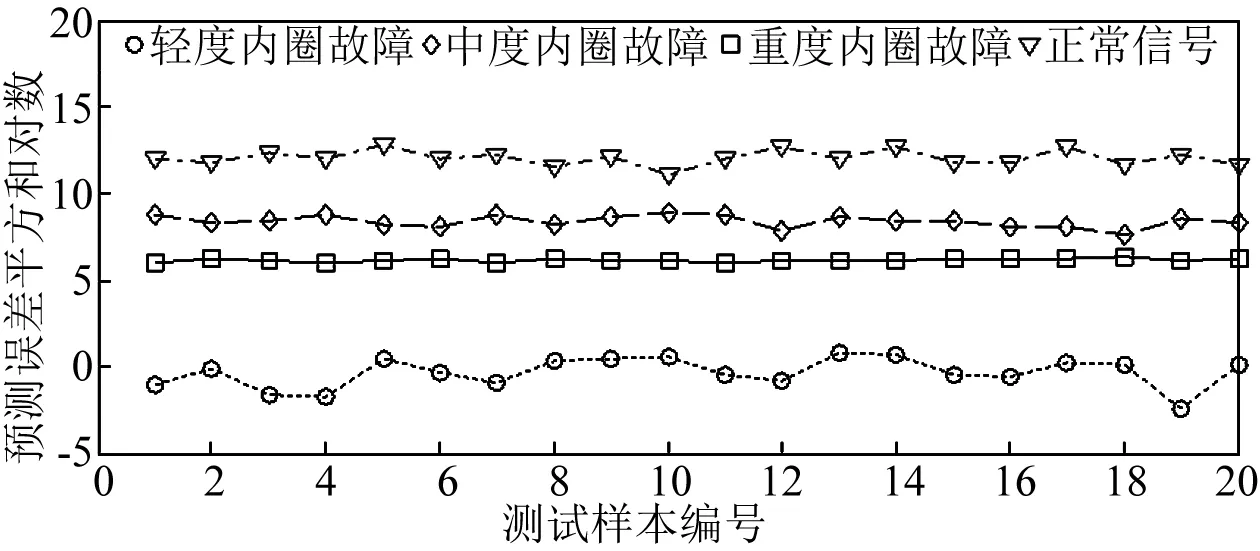
图7 VPMCD在滚动轴承各种劣化状态下的识别精度Fig.7 The recognition accuracy of VPMCD in various deterioration state of rolling bearing
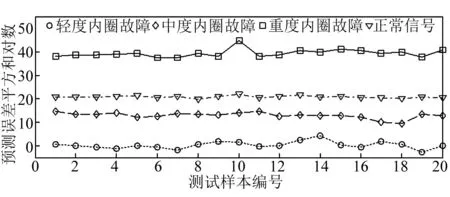
图8 VPMELM在滚动轴承各种劣化状态下的识别精度Fig.8 The recognition accuracy of VPMELM in various deterioration state of rolling bearing
综上所述,通过对滚动轴承内圈不同劣化程度数据分类的实验可知,VPMELM模式识别方法在识别率和识别精度都展示了其优越性。这是由于VPMELM分类器建立了更加准确的模型,该模型能反应特征值相互之间的复杂关系,进而可以对待测样本的特征值进行更加准确的预测。
3 结 论
本文将ELM回归模型和VPMCD方法相结合应用于滚动轴承劣化程度的检测,通过实验分析可以得出:
(1)ELM回归模型是克服了BP神经网络人为设置参数的缺陷,通过逼近优化得出更加真实的回归模型,同时与线性、二次、交互和二次交互模型相比较,具有明显的优势。
(2)采用ELM回归模型建立预测模型,代替原VPMCD方法中的固有简单模型,同时以预测误差平方和最小为依据,可以预测出更加真实的特征值,进而完成准确辨别。
[ 1 ] 张进,冯志鹏,褚福磊.滚动轴承故障特征的时间—小波能量谱提取方法[J].机械工程学报,2011,47(17):44-49. ZHANG Jin, FENG Zhipeng, CHU Fulei. Extraction of rolling bearing fault feature based on time-wavelet energy spectrum [J]. Journal of Mechanical Engineering, 2011, 47(17):44-49.
[ 2 ] MORETTI F, PIZZUTI S, PANZIERI S,et al. Urban traffic flow forecasting through statistical and neural network bagging ensemble hybrid modeling [J]. Neurocomputing, 2015,167(1):3-7.
[ 3 ] SIMISTIRA F, KATSOUROS V, CARAYANNIS G. Recognition of online handwritten mathematical formulas using probabilistic SVMs and stochastic context free grammars[J]. Pattern Recognition Letters,2015,53(1):85-92.
[ 4 ] YANG Yu, PAN Haiyang, MA Li, et al. A roller bearing fault diagnosis method based on the improved ITD and RRVPMCD [J]. Measurement, 2014,55:255-264.
[ 5 ] YANG Yu, WANG Huanhuan, CHENG Junsheng. A fault diagnosis approach for roller bearing based on VPMCD under variable speed condition [J]. Measurement, 2013,46:2306-2312.
[ 6 ] BUENO A, GARCIA P J, SANCHO J L. Neural architecture design based on extreme learning machine [J]. Neural Networks, 2013, 48(6):19-24.
[ 7 ] HORATA P, CHIEWCHANWATTANA S, SUNAT K. Robust extreme learning machine[J]. Neurocomputing, 2013, 102(2):31-44.
[ 8 ] HUANG G B, ZHOU H M, DING X J, et al. Extreme learning machine for regression and multiclass classification[J]. IEEE Transactions on Systems Man and Cybernetic Part B, 2010, 42 (2):513-529.
[ 9 ] RAGHURAJ R, LAKSHMINARAYANAN S. VPMCD: Variable interaction modeling approach for class discrimination in biological systems[J]. FEBS Letters, 2007, 581(5/6):826-830.
[10] RAGHURAJ R, LAKSHMINARAYANAN S. Variable predictive model based classification algorithm for effective separation of protein structural classes[J]. Computational Biology and Chemistry, 2008, 32(4):302-306.
[11] BENOIT F, HEESWIJK M V, MICHE Y, et al. Feature selection for nonlinear modes with extreme learning machines[J]. Neurocomputing, 2013, 102 (2):111-124.
[12] Case Western Reserve University Bearing Data Center. Bearing Data Center Fault Test Data.[EB/OL].[2009-10-01].http://www.eecs.case.edu/laboratory/bearing.
[13] 杨宇,李杰,潘海洋,等. VPMCD和改进ITD的联合智能诊断方法研究[J].振动工程学报,2013,26(4):608-616. YANG Yu, LI Jie, PAN Haiyang,et al. A fault diagnosis approach of roller bearing based on VPMCD and improved ITD algorithm [J].Journal of Vibration Engineering, 2013, 26(4): 608-616.
[14] 程军圣,郑近德,杨宇.一种新的非平稳信号分析方法——局部特征尺度分解[J].振动工程学报,2012, 25(2):215-220. CHENG Junsheng, ZHENG Jinde, YANG Yu. A nonstationary signal analysis approach—the local characteristic-scale decomposition method[J]. Journal of Vibration Engineering, 2012, 25(2): 215-220.
Deterioration state identification method for rolling bearings based on VPMELM
ZHENG Jinde1, PAN Haiyang1,2, TONG Baohong1, ZHANG Liang′an1,2
(1. School of Mechanical Engineering, Anhui University of Technology, Ma’anshan 243032,China;2. Institute of Industrial Robots, Anhui University Industrial Technology Research Institute,Ma’anshan 243000,China)
Aiming at the problem that only four simple mathematical models in the variable predictive mode based class discriminate(VPMCD)method can not reflect complex relationships among eigenvalues,it is found that the extreme learning machine (ELM) regression model, a complex and widely used one, can reflect relationships among eigenvalues. Here, combining with the advantage of ELM regression model and VPMCD method, a variable predictive mode-based extreme learning machine (VPMELM) method was proposed. It was applied to identify the deterioration state of rolling bearings. The test results showed that the identification method based on VPMELM can effectively to identify the deterioration state of rolling bearings.
extreme learning machine; variable predictive mode based class discriminate(VPMCD); variable predictive mode-based extreme learning machine(VPMELM); rolling bearing
国家自然科学基金(51505002); 安徽高校自然科学研究项目资助(2015A080)
2015-11-25 修改稿收到日期:2016-02-22
郑近德 男,博士,讲师,1986年生
潘海洋 男,硕士,助教,1989年生
TH113
A
10.13465/j.cnki.jvs.2017.07.009
