新型超字级并行改进算法
2017-04-20张素平丁丽丽王鹏翔
张素平,韩 林,丁丽丽,王鹏翔
(数学工程与先进计算国家重点实验室(信息工程大学),郑州 450001)
(*通信作者电子邮箱892841546@qq.com)
新型超字级并行改进算法
张素平*,韩 林,丁丽丽,王鹏翔
(数学工程与先进计算国家重点实验室(信息工程大学),郑州 450001)
(*通信作者电子邮箱892841546@qq.com)
对于超字级并行(SLP)算法不能有效地处理大型程序中并行代码率较小,且可向量化的代码中可能存在对向量化不利的代码的问题,提出了一种新型的SLP改进算法NSLPO。首先,将程序中不能向量化的非同构语句进行同构化处理,定位SLP丢失的向量化机会;然后,通过冗余节点添加构建最大通用子图,通过冗余删除等优化过程得到同构化之后的补充SLP图,提高程序中代码的并行性;最后,运用节流法将对向量化有害的代码摒除在向量化之外,仅对它们进行标量处理,通过只向量化处理那些向量化有收益的代码以尽可能地提升程序效率。在一组广泛使用的内核测试集中进行实验,结果显示,与SLP算法相比,NSLPO算法性能更优,其执行时间比SLP平均减少9.1%。
同构;节流法;向量化;超字级并行;补充图
0 引言
高性能计算的迅猛发展使得能耗、访存和通信等技术面临发展瓶颈,自动并行化软件的发展是当下解决此问题的关键所在。1996年,Intel在其Pentium处理器上集成了MMX(Multi-Media Extension)之后,大多数处理器都开始集成单指令多数据(Single Instruction Multiple Data, SIMD)扩展部件[1],以充分发掘处理器的计算和图形处理能力。SIMD不仅可以提升特定应用程序的性能,还可以提高大多数程序的效率。当前向量化的方法一般分为两种:一种是人为地将串行代码改为单指令多数据的向量化代码的手工向量化;另一种是运用编译器对代码进行自动向量化处理,即分析编译器,在编译器中增加代码自动向量化的模块,使其可以自动地实现向量化的功能。第一种方法要求程序员对应用程序的结构和数据布局有深刻认识,而且还要掌握目标平台所支持的扩展体系结构和指令集的特点,才能够正确地修改程序结构和数据布局使之适合利用SIMD来提取并行性。这个过程较为复杂且容易出错,效果并不完美。在这个转换的过程中有很多数据访问模式不易被转换,而且要想完美地实现代码转换,必须要对数据依赖和数据重用模型有很深入的理解。所以,现在比较通用且流行的方法是自动向量化。目前自动向量化的方法主要有借鉴向量机上的传统向量化和面向基本块的超字级并行(Superword Level Parallelism, SLP)向量化。传统的向量化方法主要是发掘最内层循环中语句级别的并行性,一般情况下,最内层循环向量化易实现,代价小,但当最内层循环存在依赖环、归约或者数组引用相对于最内层循环索引不连续时,内层向量化代价较大甚至无法向量化。
Larsen等[2]在2000年提出了SLP的概念,此算法是从直线型标量代码开始进行自动向量化,而且在大多数编译器如GCC、LLVM、icc等主流编译器中均已实现。其基本过程主要是从store指令开始沿着数据依赖图向上直到达到load指令或者不能向量化的指令才停止,运用贪婪算法的方式将标量指令打包成向量指令。但对于大型应用来说,这个过程存在两个问题:1)利用SLP进行向量化的前提是语句同构,因为现存的SLP算法只能够打包同构的语句,对于结构相异的语句则只能跳过,不予处理。然而,大型应用程序中并行化代码即同构的语句所占比例相对于程序庞大的代码来说非常小,这样就可能大大地降低向量化的效率。2)程序中可以进行向量化处理的代码中可能存在对向量化有害的代码,即对这部分代码进行向量化处理有可能损害整体代码的效率,这些代码可能需要将代码从标量寄存器移进向量寄存器中而增加代价,从而损失向量化收益。因为SLP处理针对的是整体代码,不能单独处理局部,即使有些代码对向量化有害,仍旧会对其进行向量化从而可能极大地损害整体的效率。为了解决这两个问题,本文提出一种改进的SLP算法——NSLPO(New Superword Level Parallel Optimization)。首先,对于结构相似的语句进行同构化处理,增加其向量化的可能性;然后运用节流法,一步步判断每一组包形成时的向量化收益,寻找向量化最优子图,在向量化还有收益时尽早停止向量化,阻止那些不利于向量化的代码进行向量化处理,最大可能地保持整个代码的收益。实验结果显示,在一组广泛使用的内核测试集中,NSLPO比SLP的执行时间平均减少9.1%。
1 直线型SLP及相关研究
1.1 直线型SLP
SIMD扩展是当下主要的并行化处理技术之一,先前的多媒体扩展只能够支持数据长度较短的数据类型,目前新的扩展可以支持128位甚至Intel的AVX可以支持256位,AVX2可以支持512位的超字操作。为满足实际需要,2000年Larsen等[2]首先提出了面向基本块的SLP向量化方法,用以处理较宽数据类型的数据并行。
SLP算法的过程如下:首先利用相邻的内存访问作为打包的种子,然后通过定义-使用链和使用-定义链启发式的扩展包,最后利用依赖关系调度包。
1.2 相关研究
SLP向量化经常需要用到打包、解包操作。在使用SLP时,为了满足SIMD操作超字的要求,超字语句中的操作需要以特定的顺序放入向量寄存器中。如果超字中的原操作在向量寄存器中不可用,就需要使用昂贵的访存指令和额外的向量寄存器重排序指令来从内存中引入数据并按照要求在向量寄存器中对它们进行重新组织,这个过程叫作超字打包。同样地,为了满足后续的使用,将超字中的操作分散开来时仍然会有额外的开销,这个过程叫作超字解包。先前的研究显示由于超字打包/解包的开销太高以至于可能超出SLP所带来的性能优化。因此,在应用SLP时尽可能地减少打包/解包的开销相当重要。打包冲突图提供了更多包重用的机会,在包调度时决定包的执行顺序和包内语句的顺序,以减少拆包的次数[3]。采用多元决策图可以有效地表示包内的数据,减少拆包的次数[4]。SLP算法只能处理同构语句,所以,代码中含有足够的同构语句对代码效率的提高相当重要。对于循环来说,为了得到足够多的地址连续的同构语句,在SLP打包前先作循环展开。对外层作循环展开和压紧、对内层作循环展开的包转置,可以解决内层循环携带依赖、外层循环可以向量化但是数组引用相对于外层循环索引不连续的问题[5]。将标量打包为向量需要将数据从标量寄存器转入或者转出向量寄存器,在这个过程中,较好的处理向量寄存器可以尽可能地减少开销,Shin等[6-7]开发了一种策略来管理向量寄存器文件,使之作为编译控制缓存,以提高对本地数据的管理效力;不仅如此,他们还在文献[8-9]的研究中使用控制流指令断言时派生出了一种识别更多的超字级并行的大型基本块。Nuzman等在文献[10]中给出了一种支持插入数据的高效向量化编译技术,在文献[11]中则提出了短SIMD框架的外层循环向量化技术。Barik等[12]提出在接近机器层的底层IR上进行自动向量化,能在动态编译时获得更高的编译效率。侯永生等[13]针对不能正规化的循环提出了一种展开压紧算法,并用超字级并行向量化方法发掘展开压紧从而提高程序的效率。徐金龙等[14]提出了一种分段约束的SLP发掘路径优化算法,采用段间的SLP发掘来约束循环展开所带来的过多的发掘路径。魏帅等[15]提出了一种面向SLP的多重循环向量化方法。索维毅等[16]对SLP自动向量化中的指令分析和冗余优化算法进行了添加和改进,解决了由于依赖关系或者数据非对齐而使向量化效率不高的问题。每一种算法都从不同的角度对SLP算法进行改进以提升不同应用程序的效率。本文主要是针对大型应用中并行代码的占有率较低,且向量化代码中可能含有对向量化不利的代码的问题进行改进,首先尽可能地同结构化非同构语句,增强代码的并行性,然后通过节流的方法尽可能地保证程序的收益。
2 NSLPO算法
NSLPO算法首先对需要向量化的循环作一些通用的预处理,如循环展开,然后将结构相似但非同构的语句进行冗余节点添加,使得其结构相同[17];接着用节流法[18]迭代地对每组可以向量化处理的指令包进行收益分析,对于每一组包,如果向量化处理其收益为正,则证明该包对向量化有利,否则有害。为保证整体代码的效率,对于那些向量化有害的代码就停止向量化,进行标量计算。
算法具体思路如下:
1)对标量代码中需要的循环进行循环展开等预处理,尽可能地增加程序的并行性。
2)对那些结构相似但非同构的语句进行同结构化处理[17]。
3)用SLP算法寻找向量化种子指令,构建SLP图。
4)用节流法计算所有的有效节流点[18]。
5)根据有效节流点对SLP图进行处理,生成优化节流子图。
6)运用精确的代价模型计算并保存各个节流子图的收益。
7)对所有节流点进行上述4)~6)处理,找出最优节流子图,并按照最优节流子图所示用向量代码代替标量代码。
3 非同构语句同结构化
SLP算法处理的都是同构指令,所以其前提是需要语句同构,但是大型应用程序中同构语句的比例有限,所以为了尽可能地提高程序的并行性,增加向量化的可能性,提高程序效率,可以先将非同构语句进行同结构化处理[17],处理步骤如下:
2)通过添加尽可能少的冗余节点构建SLP的补充依赖图。
3.1 定位SLP可能丢失的向量化机会
因为在代码进行SLP处理之前已经经历过很多优化,如冗余节点删除等,很可能将本来可以同构的依赖图变成异构的依赖图,从而在SLP算法处理同构语句时被SLP排除在外,使得其丢失了这些本来可以向量化的机会。所以,首先要构建语句依赖图,尝试拟组建超字语句组,尽可能地定位这些丢失的向量化机会。
3.2 构建SLP补充依赖图
定位到SLP丢失的向量化机会后,通过在依赖图中添加尽可能少的冗余节点同结构化非同构语句,构建SLP补充依赖图。一般需要如下步骤:
1)构建最大通用子图。寻找两个图的最大通用子图一般被认为是一个NP问题,由于现实中图都较小,文献[19]中提出用接近于最优算法的快速backtracking算法来解决这个问题。
2)构建最小通用超图。比较最大通用子图与原图的差异,可以得到最小通用超图。例如,如果g1和g2是原图,MCS是g1和g2的最大通用子图,那么最小通用超图MinS=MCS+dif1+dif2,其中:dif1=g1-MCS,dif2=g2-MCS。
3)经过插入节点选择、冗余删除等步骤得到SLP补充依赖图。
北辰教堂不仅在教牧人员内部组织对十九大精神、党的宗教方针政策、《宗教事务条例》等法律法规的学习,更通过“北辰教堂宣传文化走廊”、一年一次的“爱国爱教、遵纪守法”宣传周等活动,对广大信众进行宣传教育,教导广大信众,做爱国爱教、知法守法的好公民。
针对如下所示源码,先构建其数据依赖图如图1(a)所示。如果按照SLP算法,则图1(b)为其SLP依赖图,从数据依赖图中可得其可向量化处理的指令组有2组。因为SLP算法是从store指令开始,自底向上地搜索同类型的指令组,如果遇到load指令或者不能向量化的指令(如图1(c)中两指令类型不同)时就停止,最终只得到2个SLP指令组。而运用同结构化算法可得图1(d)的SLP补充图,此算法通过给依赖图添加尽可能小的冗余节点来实现语句非同构语句同结构化处理,最终将图1(a)的异构依赖图补充为图1(d)的同结构化数据依赖图,由此补充依赖图可以得到5组SLP指令组如图1(e)所示。由此可以看出,在进行SLP处理之前,先将非同构语句进行同结构化处理可以大大地提高程序的并行性,从而达到提高程序效率的目的。
Float B[N]; Float C[N]; ⋮ C[i]=B[i]*3.0+2.0; C[i+1]=B[i+1]+1.0; ⋮
4 节流优化
当要处理的语句已进行同构化处理后,即基本上很多语句都可以进行向量化处理了,但是,由于SLP算法向量化处理代码是以代码的整体来计算收益的,不能分别计算每个语句中的操作组的收益,所以,代码中可能含有对向量化有害的部分不能被它发掘出来,从而可能降低向量化的收益。本文采用节流优化处理,即对每一个打包指令集分别计算其向量化收益,如果向量化处理该指令集收益为正,则进行向量化处理,否则按照标量处理。
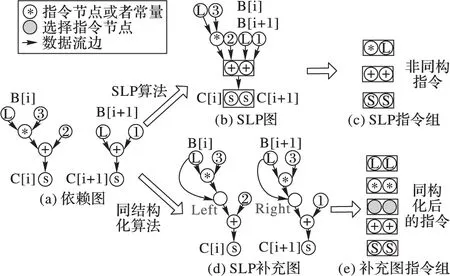
图1 同构化异构语句
4.1 节流处理过程
节流优化处理过程如下,它前面的处理跟SLP算法相同,只是在后面计算指令代价时进行不同处理。
1)按照SLP算法的思路向量化种子指令集。这些指令一般包括:非依赖的内存指令,访问相邻内存地址;归约指令;无依赖的简单指令。由于相邻内存访问指令是最有优势的种子指令,所以大多数编译器都首选此类指令作为种子指令。
2)从种子指令开始根据数据依赖图构建最初的向量化指令组。一般都是从Store指令开始沿着数据依赖图自底向上直到load指令或者不能向量化的指令为止。每一组首先要指出可以被向量化的标量指令,以及它的相关辅助数据,如该组的代价。
3)当数据依赖图构建完毕时,SLP会运用特定平台的代价模型静态评估代码性能,评估每条指令的向量代价Vcost和标量代价Scost,代价差异用Dfcost表示,如式(1)所示。
Dfcost=Vcost-Scost
(1)
4)如果Dfcost为负数,则表明该指令向量化对这个组来说是有收益的,否则为有害的。为了得到一个精确的代价,算法会将标量与向量之间的数据转换所需要的额外指令(收集和扩散指令)计算在内,用SGcost表示(一般用一个收集或者扩散指令,其值就加1)。然后计算出总的代价Tlcost,它包括所有组的代价以及额外代价,如式(2)所示。
(2)
如果Tlcost<0,则说明向量化是有收益的,否则没有。只有当向量化形式的代价比标量形式代价小时,向量化才是有收益的。
5)根据节流法计算每个节流子图所有指令的总的代价差异,选择代价差异最小图的来作为最优节流子图,然后用SLP向量化最优节流子图,其余部分则标量处理,尽可能地保证向量化的收益。
SLP算法对实现程序完整向量化效用良好,但是它忽略了另一种收益形式,即代码中部分代码向量化有收益,其他部分则没有收益的情况。SLP算法将代码依赖图当作一个独立的不可分割的区域,它只能对其整体作向量化性能评估,从而确定对该代码向量化是否有性能提升。但是如果代码中部分向量化有收益,另一部分则对性能有损害,从而可能造成整体向量化性能为无收益的结果,就表示该代码不能进行向量化处理或者最终的向量化结果非最优状态。图2针对下述代码展示了一个新型SLP改进算法的实现过程。
FloatA[N],B[N],C[N],D[N],E[N]; ⋮E[i]=(A[i]+(B[2*i]*(C[2*i]+ (D[2*i]*B[2*i]))))*3.0+1.0;
E[i+1]=(A[i+1]+(B[3*i]*(C[3*i]+ (D[3*i]*B[3*i]))))+2.0;
⋮
图2(a)是上述代码的数据依赖图。数组E[]存储数组A[]、B[]、C[]和D[]的计算结果。其中,E[i]和E[i+1]是连续的内存地址,与A[i]和A[i+1]中的load相同,但是来自于另外几个数组的load则是非连续的(由数组的索引2*i和3*i可知)。图中单独的圆形load为非连续的load,大多向量化方法都不能实现这些非连续load的向量化处理。现在对这些代码进行SLP处理:因为图2(a)所示两个数据依赖图不是同构的,所以应用异构语句同构化方法[17]对其作同构化处理得到图2(b)。接着用SLP算法对其进行向量化处理:首先定位种子指令,即相邻内存访问指令,图中E[i]和E[i+1]中的stores,它们形成一个个打包组g1(即图2(c)中SLP图的根);然后算法根据依赖图自底向上,尝试把相同类型的指令构成更多的指令组;其他的乘指令、加指令以及来自A[]的指令也分别构成不同的指令组(从g2到g11),而来自于非连续内存地址访问的load(数组B[]、C[]和D[]的loads)则保持标量执行。每一个标量节点的数据如果被向量组使用则需要一个额外的插入指令将标量数据插入向量寄存器中,其代价会变大,因为每一个标量load的向量化代价都加1,所以如图2(c)所示每一个圆形的load上该节点的代价差异都有一个+1的标识。一旦数据被插入向量寄存器中,它就可以在任何需要的时候从向量化寄存器中被读出从而被重用,如图2(c)中的g9和g11都可以重用数组B[]的数据。
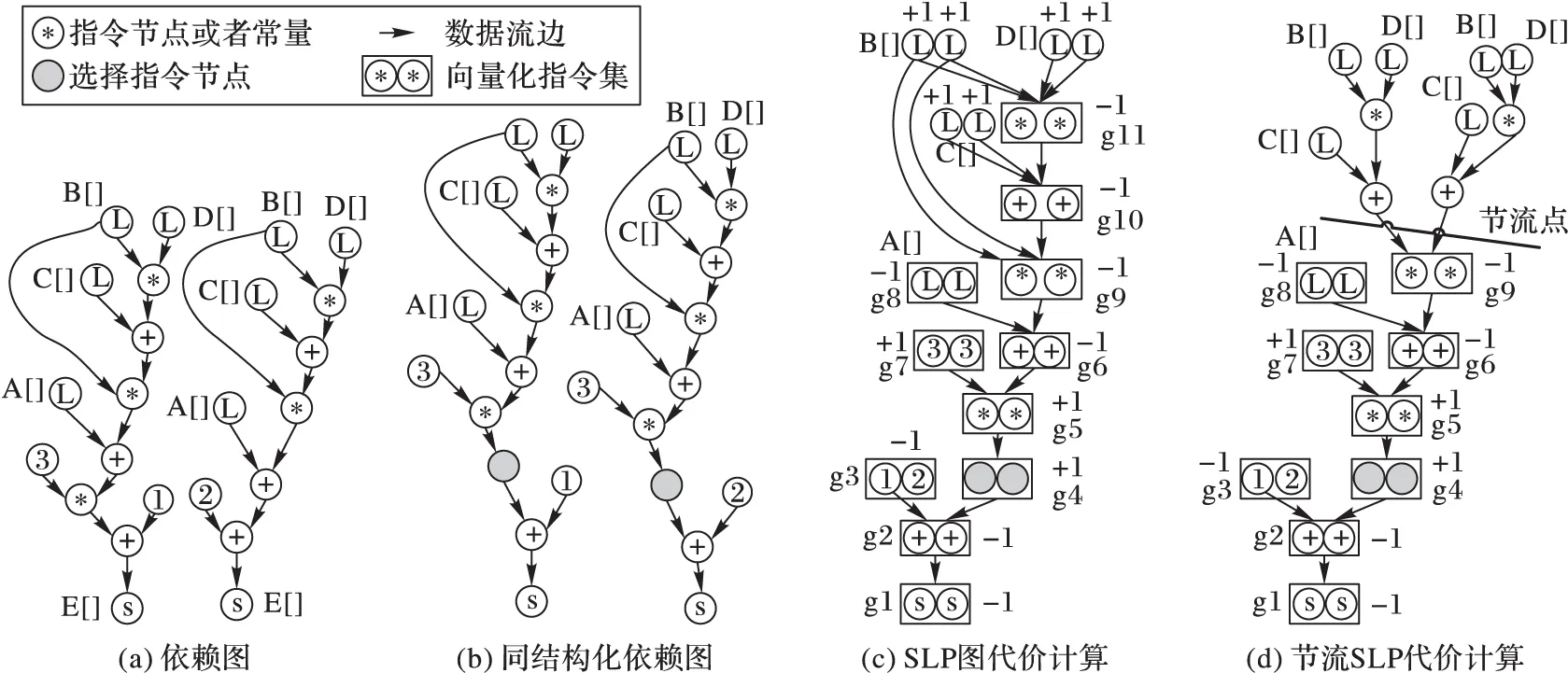
图2 新型SLP改进算法实现过程
算法向量化处理的性能由编译器的代价模型来评估,代价模型可以评估出每条指令的代价。在我们使用的目标编译器GCC代价模型中,每条指令代价显示为1。图2(c)中依赖图节点都标有代价差异,组g1的差异代价Dfcost为-1,表示如果两个stores指令向量化处理,其代价为1;但如果依然按标量处理,其代价为2,保持标量处理的指令代价差异为0。任何用来支持向量化处理的额外的指令,如插入指令,还有同构化处理时的选择指令,都有一个正数的代价差异,因为如果保持标量状态的开销就不会使用它们。然后计算整体代价Tlcost,图2(c)的整体代价为1,意味着向量化处理这段代码没有收益(只有当整体代价为负时,才表示向量化有收益)。
图2(c)向量化处理之所以没有收益主要是因为以g10为根的子图对向量化来说是有害的(它的总代价为正4)。因为SLP算法将代码看作一个整体,所以它不能识别出这些问题。为了改进这个状况,在此处运用节流法将那些向量化处理时损害大于收益的代码子区域分割出来,单独计算其代价,如图2(c)所示,在组g10处将其分割,以g10为根的子图进行标量处理,而下面的部分则向量化处理,此时总代价Tlcost为-3,说明向量化是有收益的。
而Vanilla提出的SLP[2]只评估一次数据依赖图的代价,而且评估的是它的整体代价,它不会以任何方式来改变图,其缺点之一就是它不会移除图中的任何一部分,即使这些部分向量化处理时对整体向量化性能有所损害。
4.2 计算有效节流点
要得到最优节流子图,首先需要计算出有效节流点。针对图2以每个节点为根的子图如图3所示,根据每个子图中的指令代价计算出其总代价,找出代价最小的子图,即最优子图。根据图2(c)中所标示的差异代价计算其代价得到表1数据。表1中:RootNode表示节点;SubTlcost表示以该节点为根的子图向量化的总代价;Tlcost表示对子图标量处理,对剩余图进行向量化处理的总代价。由表1可以看出g4和g10为最优节流点,由于后续处理的原因,需要尽可能多地向量化代码,所以在同样代价时,选择g10作为节流点,在向量化处理时,对g10子图作标量处理,对剩下的部分进行向量化处理。
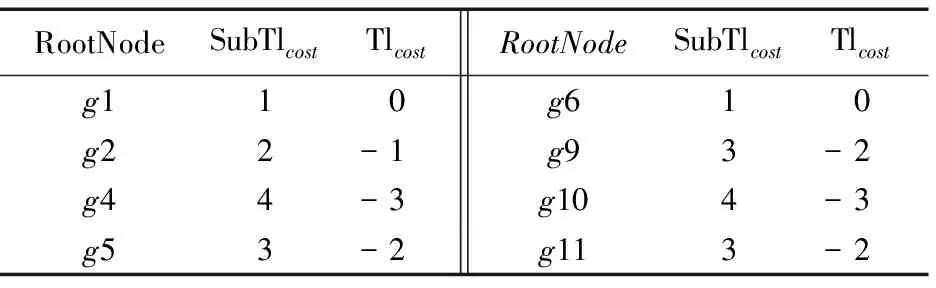
表1 节流点子图代价

图3 节流子图
5 算法伪代码
构建节流SLP子图集的伪代码如下:
1)
输入:SLP依赖图
2)
输出:SLP依赖图的节流子图集
3)
if(st==samestruct);
//判断SLP图是否同构
4)
Cutsubgraph();
//若返回true,直接调用节流函数;
5)
else
6)
{
7)
Samestruct(g1,g2)
//若返回false,则表示非同构,调用同结构化函数
8)
{
9)
insertMinNodes();
//根据需要计算插入最小冗余节点
10)
creatMaxS();
//构建最大通用子图
11)
deletenodes();
//进行冗余删除等处理
12)
returng3;
//返回同构化数据依赖图g3;
13)
}
14)
}
15)
Cutsubgraph()
//对g3进行节流处理
16)
{
17)
Firstcut_subgraphs(g3)
//首先进行首处理函数,初始化依赖图
18)
{
19)
root=g3.getroot();
20)
init_g();
21)
init_g.addnode(root);
22)
Latercut_subgraphs();
23)
}
24)
Latercut_subgraphs(sg)
//递归调用后处理函数
25)
{
26)
if(sgingset)
//sg在节流子图集gset
27)
return;
28)
gset.insert(sg);
//将子图插入节流子图集中
29)
for(子图的邻近节点neighbor)
30)
{
31)
if(neighbor在sg中)
32)
Continue;
33)
sg_cp=copysg(sg);
//复制子图
34)
sg_cp.addnode(neighbor);
35)
Latercut_subgraphs(sg_cp)
//递归调用后处理函数
36)
}
37)
}
38)
}
算法给出了生成有效节流子图集的核心函数的输入是依赖图,输出是节流子图集(gset),即包含根节点的相关子图。算法包含两个主函数:同结构化函数Samestruct()和节流函数Cutsubgraph()。同结构化函数包含插入最小冗余节点insertMinNodes()、构建最大通用子图creatMaxS()以及冗余删除deletenodes()等内容。节流函数则主要包含两个函数,首处理函数Firstcut_subgraph()和后处理函数Latercut_subgraphs()。这两个函数分别可以递归的调用本身,首处理函数创造一个初始化图init_g,它只包含初始化根节点,然后把它作为参数调用递归函数,递归函数是算法的计算核心,即将输入子图保留,然后每次增加一个相邻节点并递归处理来扩展它,如果该图已在有效节流子图集中,则退出计算,否则将子图插入到子图集中。下面函数迭代地遍历子图中所有相邻节点并逐一将它们插入子图中,如果该节点已存在于子图中,则跳过它;否则,创建一个包含邻近节点的子图副本(sg_cp),然后将结果子图作为一个递归的参数继续调用后处理函数,直到所有的节点都遍历完毕,得到所有的节流子图。
得到子图后,必须知道子图中的代码应该被向量化还是串行执行。为了得到更好的性能提升,算法需要一个精确的代价模型,该模型能够评估每种情况下的反应时间。GCC中的代价模型计算的代价等于所有单个指令代价的总和,每个指令的代价等于其花费在目标机器(比如x86/AVX2)上的执行时间,但是如果存在流入或流出向量代码的标量数据流,或者流入或流出标量代码的向量数据流,则还需要把执行数据移动的指令花费的时间添加到总的代价中。这些代价均和目标相关,并能够通过代价模型计算出来。该代价模型简单易懂,对目标流水的指令调度也能够作精准的计算,特别是简单有序的结构。
6 实验评估
6.1 实验环境
实验平台CPU主频为2.10GHz,内存为2GB,L1数据cache为32KB,L2数据cache为256KB,基本页面为8KB的E5- 2620v2型处理器,有6个处理器核。 操作系统内核为Linux2.6.18,版本为RedhatEnterpriseAS5.0,目前可以支持256位的向量计算。
6.2 实验结果及分析
在GCC5.1.0编译器上进行了实验,用本文算法对现存的SLP算法作了一个扩展处理,用SPEC2006(StandardPerformanceEvaluationCorporation2006)[20]和NPB(NASparallelbenchmarksuite)[21]的以及MediaBenchII[22]和Polybench[23]的一些标准对本文算法进行了实验评估,表2中给出了所用数据的详细信息。

表2 实验所用数据信息
在GCC中,-O3选项可以默认将向量化打开,所以在测试时最基本的选项就是-O3,然后在此基础上再添加其他优化选项,如循环展开、循环分布等,因为在预处理时可能用到循环展开,所以在测试时,把-O3、-funroll-loops(循环展开)等作为基础的编译选项,对基础选项、以及基础选项加SLP优化、基础选项加本文算法优化三组数据作对比,结果如图4所示。在实验中,将只加基础选项的组叫作基础优化,在图中用Base来表示;加SLP优化的称为SLP优化,在图中用SLP表示;而本文算法优化称作新型SLP优化,在图中用NSLPO表示。实验结果显示,本文算法的执行时间比基础优化减少了17.6%,比SLP减少了9.1%。
图4显示了在X86平台上GCC编译器中在基础选项、SLP优化以及新型SLP优化三种优化的性能对比,为了方便处理,computerhs、multsu3matvecsum4dir、ewaldLRcorrection、computertrianglebbox、lbmhandlelnOutFlow、su3-adjoint、jdct-ifast、floyd-warshall程序分别用数字1~8代表。由图中可以看出,对大多数程序来说,新型SLP优化性能都优于SLP以及基础优化。新型SLP优化最高能优于基础优化49%(如jdct-ifast),速度超出SLP优化15%(computetrianglebbox)。computerhs和multsu3matvecsum4dir在新型SLP改进算法下有收益,但是在SLP算法下则没有,这是因为SLP依赖图中含有对向量化有害的代码,所以代价模型评估时会得出这些代码的向量化代价大于标量执行代价;而SLP改进算法则可以将这些对向量化有害的代码从整体中移除,只向量化那些向量化处理后有收益的代码,对于有害的代码则保持标量执行,从而可以很大程度上提高向量化代码的比率,提高程序的执行效率。
ewald-LRcorrection和computetriangle-bbox无论是在SLP优化下还是SLP改进算法优化下性能都优于基础优化,在这两个程序中,由GCC代价模型评估出的向量化的代价都小于标量执行的代价,所以,它们对程序来说有性能提升。从图4可以看出,SLP改进算法性能优于SLP算法。
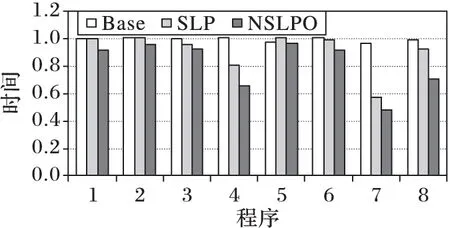
图4 基础优化、SLP优化、NSLPO性能对比
核心jdct-ifast包含两个不同类型的代码,它们均在NSLPO中有收益。jdct-ifast源码中包含同构计算,这些同构计算在经过高级优化时变成了非同构的计算,如图5所示,它的优点是实现了归约。jdct-ifast源码实现了一系列的数组常量的乘计算,有些值在数组中是平方数,这些特定值的乘指令归约主要归功于逻辑左移,因此打破了同构,所以,SLP算法不能对其实现向量化处理,然而本文的NSLPO算法由于包含同结构化异构语句这一模块,所以可以实现它的向量化,从而能提高程序的处理效率。

图5 由高级优化引发的非同构(jdct-ifast)
尽管以上整体性能测试结果已经能很好地说明NSLPO效果良好,但是,静态测试结果也相当重要,因为静态结果可以很好地展示在没有其他干扰的情况下,一个精确的代价模型对该算法的性能评估,静态结果是基于每一个向量化图的整体代价,显示了在一个特定代价模型下SLP和NSLPO的结果比较。NSLPO经常可以最小化一个图的代价,而SLP则只能用整体图的代价来决定是否对代码实行向量化处理。
图6显示了标量、SLP优化、NSLPO优化的整体静态代价,应用GCC的代价模型,为了得到一个更加有意义的测试,这个代价是每一个工作的标量代价总和的形式化图,由图可以看出,就算不考虑真正的性能提升,NSLPO也成功地降低了向量化的代价。平均看来,NSLPO降低了约23%的代价,SLP也降低了约12%的代价。
所以,不论从整体性能还是静态代价分析来看,本文的改进算法NSLPO性能都优于SLP算法;而且本文方法应用了多种通用测试集中的程序进行了实验,其结果显示了应用有普遍性和可适用性。
7 结语
本文提出了一种SLP算法的改进算法NSLPO,该算法首先通过将非同构的语句进行同结构化处理,增加并行化代码的比率;然后运用节流法对同构图中的指令进行处理,消除那些能够被向量化但是阻碍程序性能提升的代码。该算法从原始SLP图中生成各种子图集合,并通过代价模型找出向量化性能最好的子图,最后只向量化子图中的语句,其他对向量化不利的语句则进行串行执行的方式。SLP算法只能整体处理代码,如果部分代码向量化有收益,另一部分向量化有损害,也可能导致整体代码向量化有损害,经过SLP的代价分析,该代码最后则不能进行向量化处理;而本文提出的算法可以很好地解决这个问题,不仅可以增加代码向量化的效率,也可以提升程序的性能。从实验结果来看,本文算法的性能良好,再加上它的适用性较为广泛,虽然它的实现还需要较为精确的代价模型来配合,但是像GCC和LLVM这些通用的大型编译器本身都具有一个较为好的代价模型,所以该算法具有一定通用性。
)
[1] 高伟,赵荣彩,韩林,等.SIMD自动向量化编译优化概述[J].软件学报,2015,26(6):1265-1284.(GAOW,ZHAORC,HANL.ResearchonSIMDauto-vectorizationcompilingoptimization[J].JournalofSoftware, 2015, 26(6): 1265-1284.)
[2]LARSENS,AMARASINGHES.Exploitingsuperwordlevelparallelismwithmultimediainstructionsets[J].ACMSIGPLANNotices, 2000, 35(5): 145-156.
[3]TOUMAVITISG,WANGZ,FRANKEB,etal.Towardsaholisticapproachtoauto-parallelization:integratingprofile-drivenparallelismdetectionandmachine-learningbasedmapping[J].ACMSIGPLANNotices, 2009, 44(6): 177-187.
[4]HIROAKIT,AKEUCHIY,SAKANUSHIK,etal.Packinstructiongenerationformediaprocessorsusingmulti-valueddecisiondiagram[C]//Proceedingsofthe4thInternationalConferenceonHardware/SoftwareCodesignandSystemSynthesis.NewYork:ACM, 2006: 154-159.
[5]TENLLADOC,PIUELL,PRIETOM,etal.Improvingsuperwordlevelparallelismsupportinmoderncompilers[C]//CODES+ISSS’05:Proceedingsofthe3rdIEEE/ACM/IFIPInternationalConferenceonHardware/softwareCodesignandSystemSynthesis.Piscataway,NJ:IEEE, 2005: 303-308.
[6]SHINJ,CHAMEJ,HALLMW.Compiler-controlledcachinginsuperwordregisterfilesformultimediaextensionarchitectures[C]//PACT’02:Proceedingsofthe2002InternationalConferenceonParallelArchitectures&CompilationTechniques.Piscataway,NJ:IEEE, 2002: 45-55.
[7]SHINJ,CHAMEJ,HALLM.Exploitingsuperword-levellocalityinmultimediaextensionarchitectures[J].JournalofInstruction-LevelParallelism, 2003, 5: 1-28.
[8]SHINJ.Compileroptimizationsforarchitecturessupportingsuperword-levelparallelism[D].LosAngeles,CA:UniversityofSouthernCalifornia, 2005.
[9]SHINJ,HALLM,CHAMEJ.Superword-levelparallelisminthepresenceofcontrolflow[C]//CGO’05:Proceedingsofthe2005InternationalSymposiumonCodeGenerationandOptimization.Washington,DC:IEEEComputerSociety, 2005: 165-175.
[10]NUZMAND,ROSENI,ZAKSA.Auto-vectorizationofinterleaveddataforSIMD[J].ACMSIGPLANNotices, 2010, 41(6): 132-143.
[11]NUZMAND,ZAKSA.Outer-loopvectorization:revisitedforshortSIMDarchitectures[C]//PACT’08:Proceedingsofthe2008InternationalConferenceonParallelArchitecturesandCompilationTechniques.NewYork:ACM, 2008: 2-11.
[12]BARIKR,ZHAOJ,SARKARV.EfficientselectionofvectorInstructionsusingdynamicprogramming[C]//MICRO’43:Proceedingsofthe2010IEEE/ACMInternationalSymposiumonMicroarchitecture.Washington,DC:IEEEComputerSociety, 2010: 201-212.
[13] 侯永生, 赵荣彩, 高伟.非正规化循环的单指令多数据向量化[J].计算机应用,2013,33(11):3149-3154.(HOUYS,ZHAORC,GAOW.Singleinstructionmultipledatavectorizationofnon-normalizedloops[J].JournalofComputerApplications, 2013, 33(11): 3149-3154.)
[14] 徐金龙,赵荣彩,韩林.分段约束的超字并行向量发掘路径优化算法[J].计算机应用,2015,35(4):950-955.(XUJL,ZHAORC,HANL.Vectorexploringpathoptimizationalgorithmofsuperworldlevelparallelismwithsubsectionconstraints[J].JournalofComputerApplications,2015, 35(4): 950-955)
[15] 魏帅,赵荣彩,姚远.面向SLP的多重循环向量化[J].软件学报,2012,23(7):1717-1728.(WEIS,ZHAORC,YAOY.Loop-nestauto-vectorizationbasedonSLP[J].JournalofSoftware, 2012, 23(7): 1717-1728.)
[16] 索维毅,赵荣彩,姚远,等.面向DSP的超字并行指令分析和冗余优化算法[J].计算机应用,2012,32(12):3303-3307.(SUOWY,ZHAORC,YAOY,etal.SuperwordlevelparallelisminstructionanalysisandredundancyoptimizationalgorithmonDSP[J].JournalofComputerApplications, 2012, 32(12): 3303-3307.)
[17]PORPODASV,MAGNIA,JONESTM.PSLP:paddedSLPautomaticvectorization[C]//CGO’15:Proceedingsofthe13thIEEE/ACMInternationalSymposiumonCodeGenerationandOptimization.Washington,DC:IEEEComputerSociety, 2015: 190-201.
[18] PORPODAS V, JONES T M.Throttling automatic vectorization: when less is more [C]// Proceedings of the 2015 International Conference on Parallel Architecture & Compilation.Piscataway, NJ: IEEE, 2015: 432-444.
[19] WOLFE J M.High Performance Compilers for Parallel Computing[M].Boston, MA: Addison-Wesley, 1995: 225-231.
[20] Spec cpu2006 [EB/OL].[2016- 04- 06].http://www.spec.org/cpu2006/.
[21] NAS parallel benchmark suite [EB/OL].[2016- 04- 06].http://www.nas.nasa.gov/ Resources/Software/npb.html
[22] FRITTS J E, STEILING F W, TUCEK J A, et al.MediaBench Ⅱ video: expediting the next generation of video systems research [J].Microprocessors & Microsystems, 2005, 33(4): 301-318.
[23] POUCHET L N.PolyBench: the polyhedral benchmark suite [EB/OL].[2016- 04- 06].http://www.cs.ucla.edu/?pouchet/software/polybench/, 2012.
This work is partially supported by the National High Technology Research and Development Program (HeGaoJi Program) of China (2009ZX01036- 001- 001- 2).
ZHANG Suping, born in 1991, M.S.candidate.Her research interests include HPC, advanced compiler technology.
HAN Lin, born in 1978, Ph.D, associate professor.His research interests include HPC, advanced compiler technology.
DING Lili, born in 1992, M.S.candidate.Her research interests include HPC, advanced compiler technology.
WANG Pengxiang, born in 1988, M.S.candidate.His research interests include HPC, advanced compiler technology.
New improved algorithm for superword level parallelism
ZHANG Suping*, HAN Lin, DING Lili, WANG Pengxiang
(StateKeyLaboratoryofMathematicalEngineeringandAdvancedComputing(InformationEngineeringUniversity),ZhengzhouHenan450001,China)
For SLP (Superword Level Parallelism) algorithm cannot effectively process the large-scale applications covered with few parallel codes, and the codes which can be vectorized may be adverse to vectorization.A new improved algorithm for SLP was proposed, namely NSLPO.First of all, the non-isomorphic statements which cannot be vectorized were transformed to isomorphic statements as far as possible, thus locating the opportunities of vectorization which SLP has lost.Secondly, the Max Common Subgraph (MCS) was built by adding redundant nodes, and the supplement diagram of SLP was got by using some optimization such as redundancy deleting, which can greatly increase the parallelism of program.At last, the codes which are harmful to vectorization were exclued out of vectorization by using cutting method and executed in serial, only the valuable codes for vectorization were vectorized to improve the efficiency of programs as far as possible.Experiments were conducted on widely used kernel test sets.The experimental results show that compared with the SLP algorithm, the proposed NSLPO algorithm has better performance and its running time was reduced by 9.1%.
isomorphism; cutting method; vectorization; Superword Level Parallelism (SLP); supplement diagram
2016- 07- 31;
2016- 10- 24。 基金项目:“核高基”国家科技重大专项(2009ZX01036- 001- 001- 2)。
张素平(1991-),女,河南禹州人,硕士研究生,主要研究方向:高性能计算、先进编译技术; 韩林(1978-),男,山东临沂人,副教授,博士,主要研究方向:高性能计算、先进编译技术; 丁丽丽(1992-),女,河南商丘人,硕士研究生, 主要研究方向:高性能计算、先进编译技术; 王鹏翔(1988-),男,河南安阳人,硕士研究生, 主要研究方向:高性能计算。
1001- 9081(2017)02- 0450- 07
10.11772/j.issn.1001- 9081.2017.02.0450
TP314
A
