领域驱动的高效用co-location模式挖掘方法
2017-04-20江万国王丽珍陈红梅
江万国,王丽珍,方 圆,陈红梅
(云南大学 信息学院,昆明 650091)
(*通信作者电子邮箱lzhwang2005@126.com)
领域驱动的高效用co-location模式挖掘方法
江万国,王丽珍*,方 圆,陈红梅
(云南大学 信息学院,昆明 650091)
(*通信作者电子邮箱lzhwang2005@126.com)
空间并置(co-location)模式是指其实例在空间邻域内频繁共现的空间特征集的子集。现有的空间co-location模式挖掘的有趣性度量指标,没有充分地考虑特征之间以及同一特征的不同实例之间的差异;另外,传统的基于数据驱动的空间co-location模式挖掘方法的结果常常包含大量无用或是用户不感兴趣的知识。针对上述问题,提出一种更为一般的研究对象——带效用值的空间实例,并定义了新的效用参与度(UPI)作为高效用co-location模式的有趣性度量指标;将领域知识形式化为三种语义规则并应用于挖掘过程中,提出一种领域驱动的多次迭代挖掘框架;最后通过大量实验对比分析不同有趣性度量指标下的挖掘结果在效用占比和频繁性两方面的差异,以及引入基于领域知识的语义规则前后挖掘结果的变化情况。实验结果表明所提出的UPI度量是一种兼顾频繁和效用的更为合理的度量指标;同时,领域驱动的挖掘方法能有效地挖掘到用户真正感兴趣的模式。
空间模式挖掘;co-location模式;高效用co-location模式;有趣性度量指标;领域驱动;语义规则
0 引言
与传统的事务数据相比,空间数据具有海量性、高维性和语义信息更加丰富等特点,这些特点使得空间数据的知识发现比传统数据更具挑战性。空间数据往往具有较强的地理相关性,即两个空间对象所处位置越近,就越有可能具有相同的性质。空间co-location模式是空间特征集的一个子集,子集中特征的实例频繁地在空间邻域共现。空间co-location模式广泛存在于实际生活中,例如疟疾往往发生在蚊虫泛滥和水污染严重的区域。
在现有的大量空间co-location模式挖掘研究中, 一般将模式中特征的最小参与率(即参与度(Participation Index, PI))作为模式有趣性的度量指标,仅关注了模式中特征实例共现的频繁性,忽略了特征之间和同一特征中不同实例之间可能存在的差异。而已有的空间高效用co-location模式挖掘研究中,虽然引入了模式效用率(Pattern Utility Ratio, PUR)作为模式有趣性的度量指标,将模式中不同特征对模式的兴趣性贡献区分对待,但在实际中我们还注意到相同空间特征中不同实例对模式兴趣性的贡献仍然存在差异,而相关研究未见报道。
另一方面,以数据为中心的空间co-location模式挖掘通常忽略了数据特定的领域背景和用户偏好等约束信息,挖掘结果往往针对性差、数量大,并包含了大量无用或用户不感兴趣的结果,这样的挖掘结果通常是不可行动的。因此,考虑数据来源和应用背景的领域知识,在空间co-location模式挖掘过程中引入基于领域知识的语义规则是有益的。
在本文中,我们充分考虑了特征之间和实例之间的差异性,以及数据和应用的领域知识,最终能得到更有针对性的挖掘结果。
1 相关工作
空间co-location模式挖掘是空间关联规则挖掘的一个特例,最早在文献[1-2]中被提出。文献[3]中提出了co-location模式的有趣性度量指标——最小参与率(PI)。PI的定义满足向下闭合性(先验原理),所以能够利用这一性质有效地进行候选模式剪枝。空间co-location模式挖掘大体包括两大主要工作:产生候选模式和计算候选模式的表实例,其中计算表实例是时间复杂度最高的部分,此后的很多研究都集中在候选模式的剪枝和表实例的计算优化两个方面。文献[3-5]中分别提出了经典的join-based(全连接)算法、partial-join(部分连接)算法和Join-less(无连接)算法,这些算法都是类Apriori的。Join-less算法采用了新颖的物化模型——星型邻居,在计算表实例时通过查询操作来代替连接操作。与上述的类Apriori算法不同,文献[6]中提出了新的空间邻近关系的物化模型,并给出了类似于FP-growth(Frequent-Pattern growth)的CPI-tree(Co-location Pattern Instance tree)算法。文献[7]中又提出了一种结合“候选-测试”方式和CPI-tree模型优势的新物化模型——iCPI-tree,基于该模型的算法具有更高的效率。文献[8]中系统地总结了空间co-location模式挖掘的方法和研究现状。
文献[9]首次提出了基于“特征外部效用(单价)”和“特征在模式中的内部效用(数量)”的空间高效用co-location模式挖掘方法,给出了高效用co-location模式的有趣性度量指标——PUR(模式效用率)。文献[10]则进一步提出了扩展模式效用率的概念,并出了一个扩展剪枝算法EPA。但文献[9]和[10]的研究中没有考虑同一特征不同实例的效用差异。
文献[11]中提出了领域驱动数据挖掘的方法论来缩小学术研究和商业应用的差距。在领域驱动数据挖掘中,需要重点考虑领域知识的表示以及如何在挖掘中使用领域知识。文献[12-13]中提出了基于语义网络的知识表示技术;文献[14]提出了基于本体的领域知识表示技术;文献[15]详细介绍了基于领域驱动的知识发现方法,提出了获取专家领域知识的算法和领域驱动的Semantic-Apriori算法;文献[16]首次提出了一个基于本体的空间co-location规则挖掘的一般框架,通过引入约束规则和多次过滤得到了精简有效的空间co-location挖掘结果;本文则简化了文献[16]的方法,分类基于领域知识的语义规则并应用到挖掘过程中。
2 相关概念和定义
2.1 Co-location相关概念
不同的空间特征代表了不同类别的空间数据,通常也称为空间对象(spatial object),常用f表示。比如房子、超市、学校、人等在概念上可以形成一个类别,都可以称为一个空间特征。空间特征集是所有空间数据划分类别的集合,常用F表示,记为F={f1,f2,…,fn}。一个空间co-location模式c是F的一个子集,c中的特征个数|c|称为模式c的阶数。空间区域中一个具体位置上的一个空间数据称为一个空间实例,为了区分不同特征的不同实例,给每个特征中的每个实例一个唯一的编号。于是,每一个空间实例被记为“特征名.实例编号”,如图1所示,图中共有4个空间特征A、B、C和D,空间特征A有4个实例A.1、A.2、A.3和A.4,B有5个实例B.1、B.2、B.3、B.4和B.5,C有3个实例C.1、C.2和C.3,D有2个实例D.1和D.2。如果两个空间实例之间的欧氏距离不大于用户给定的一个距离阈值d,那么称这两个空间实例满足空间邻近关系。为了便于描述,将满足邻近关系的空间实例在图中用实线连接。

图1 空间特征及其实例示例
如果一个空间实例集合I中,两两实例均满足空间邻近关系,则称I是一个团。如果团I包含了co-location模式c中的所有特征,并且I的任何一个子集无法包含c中的所有特征,那么I被称为c的一个行实例。例如,在图1中,实例集合{A.3,B.3,D.1}是模式{A,B,D}的一个行实例。一个模式c的所有行实例的集合称为c的表实例,记为T(c)。例如,图1中,T({A,B,C})={{A.2,B.4,C.2},{A.3,B.3,C.1}}。
在co-location模式挖掘中,采用参与度PI来衡量模式的有趣性(频繁性),PI被定义为模式中所有特征的参与率(ParticipationRatio,PR)的最小值[1-7]。对于一个k阶模式c={f1,f2,…,fk},特征fi(1≤i≤k)在c中的参与率PR被定义为fi在T(c)中不重复出现的实例个数与fi的总实例个数的比值。如果模式c的参与度PI不小于用户给定的阈值min_prev,那么称模式c是频繁的(有趣的)。
在图1中,对于模式c={A,B,C},其表实例为{{A.2,B.4,C.2},{A.3,B.3,C.1}},由PR和PI的定义可得PI(c)=min{2/4, 2/5, 2/3}=2/5。若min_prev=0.3, 那么{A,B,C}是一个频繁的co-location模式。
2.2 领域驱动相关概念
领域知识通常是领域内主体(专家、用户)对经验、规律和喜好的自然表达,在实际应用中需要将它们转换为计算机可以理解的形式,也就是领域知识的形式化表达。目前对于领域知识的形式化表达的研究相对较成熟,常见的方法有:
1)基于产生式规则的表达(或基于条件式规则的表达), 其基本形式为p→q。基于产生式规则的知识表达具有自然、灵活、通用性强和易维护等优点。
2)基于语义网络的表达。语义网络通过图(Graph)的方式刻画领域知识中概念之间的关系、约束或者相关行为[15]。语义网络能够清晰直观地将领域知识表达出来,易于理解和沟通,同时具有较好的可扩展性,在目前的知识图谱构建中使用较多。
3)基于本体的表达。本体是针对领域实体的本质抽象,关注领域实体的属性、实体之间的关联、约束和层次关系等。通常一个完整的本体包括类(概念)、关系、函数、公理系统和实体这五个部分。
数据挖掘过程可以分为挖掘前、挖掘中和挖掘后三个阶段,领域知识可以应用于任何一个阶段。在挖掘前可以通过领域知识进行数据预处理,比如应用在数据的获取、转换和加载(ExtractionTransformationLoading,ETL)过程中;在挖掘中,利用领域知识过滤无效候选;在挖掘后,可以利用领域知识进行冗余模式的剔除,对挖掘结果进行分类和排序等操作。
2.3 高效用co-location相关定义
在实际中,不同特征的价值(效用值)往往是千差万别的,比如天然水晶和玻璃。有时候,同一种特征中不同实例的价值也存在较大的差异,比如10克拉的水晶和100克拉的水晶。
在本文中,考虑更为复杂的空间实例作为研究对象——带效用值的空间实例。图2是六种不同植被的空间分布示例,表1是图2中每种植被的总效用值,图2中实例的上标数据代表该实例的效用值。
在考虑特征中实例效用差异的情况下,采用传统的PI度量指标,可能会遗漏一些有意义的模式或者挖掘出一些没有意义的模式。
在图2中,以co-location模式c1={A,B,C}为例,其表实例为{{A.110,B.48,C.29},{A.37,B.58,C.29}}, 其参与度为PI(c1)=1/4。特征A的实例在模式c1中参与的效用占A总效用的17/28,类似,特征B在c1中的实例效用占比为16/25,特征C的实例效用占比为9/12。若min_prev=0.3,那么模式c1被识别为非有趣的模式。但是,模式c1中每个特征参与的效用都超过了自身总效用的50%,所以c1应该是一个有意义的模式。同样,对于模式c2={E,F},PI(c2)=2/3,若min_prev=0.5,那么c2是一个有趣模式。但是特征E在c2中的实例效用仅占其总效用的4/14,特征F为3/18,在c2中的每个特征参与的效用占比都很少,不应该被识别为有趣模式。
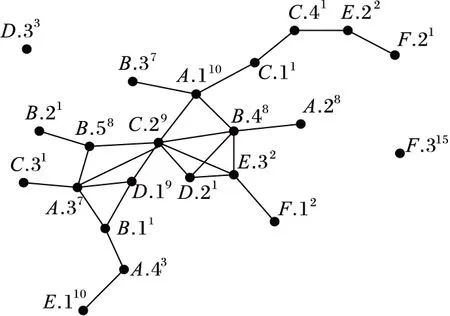
图2 带效用值的空间实例示例
表1 图2中每种植被的实例和总效用
Tab.1InstancesandtotalutilityvalueofeachvegetationinFig.2

特征实例总效用AA.110 A.28 A.37 A.4328BB.11 B.21 B.37 B.48 B.5825CC.11 C.29 C.31 C.4112DD.19 D.21 D.3313EE.110 E.22 E.3214FF.12 F.21 F.31518
定义1 带效用值的空间实例。带有效用值为v的空间特征fi的第j个实例记为fi.jv,或将实例fi.jv的效用记为:u(fi.j)=v。
例如,特征A代表水晶,A.110代表一颗10克拉水晶,其效用为u(A.1)=10。
定义2 特征的总效用。给定空间特征fi及其实例集si,fi的总效用定义为其所有实例的效用之和,形式化描述为:
定义3 特征在模式内的参与效用。给定一个k阶co-location模式c={f1,f2,…,fk},特征fi∈c在模式c中的参与效用记为u(fi,c),形式化为:
定义4 特征在模式中的内效用率(Intra-Utility Ratio, IntraUR)。给定一个k阶co-location模式c={f1,f2,…,fk},特征fi∈c在模式内的参与效用占其总效用的比值被定义为特征fi在模式c中的内效用率,形式化为:
IntraUR(fi,c)代表特征fi对模式c的直接贡献或者影响。例如,在图2中,特征A在模式c={A,B,C}中的内效用率为:
定义5 特征在模式中的间效用率(Inter-Utility Ratio, InterUR, InterUR)。给定一个k阶co-location模式c={f1,f2,…,fk},特征fi∈c在模式c中的间效用率定义为:
InterUR(fi,c)代表特征fi对模式c内其他特征的影响程度(或贡献程度),代表特征的一种间接影响。比如,电子产品促销活动中,电脑的销售会对鼠标、键盘等外部设备的销售有一定的影响。在图2中,特征A在模式c={A,B,C}中的间效用率为:
定义6 特征的效用参与率(Utility Participation Ratio, UPR)。给定一个k阶co-location模式c={f1,f2,…,fk},特征fi∈c在模式c中的效用参与率UPR(fi,c)定义为特征在模式c中的内效用率(IntraUR)和间效用率(InterUR)的加权和,形式化为:
UPR(fi,c)=w1×IntraUR(fi,c)+w2×InterUR(fi,c)
其中:0≤w1,w2≤1,w1+w2=1。
UPR考虑了特征在模式中的直接影响(内效用率)和间接影响(间效用率),综合地评价了特征在模式中的重要程度。w1、w2分别代表IntraUR和InterUR的权重,通常由用户指定。以图2为例,设w1=0.7,w2=0.3, 对于模式c={A,B,C},特征B的效用参与率计算如下:
UPR(B,c)=0.7×IntraUR(B,c)+
0.3×InterUR(B,c)=0.643
定义7 模式的效用参与度(Utility Participation Index, UPI)。给定一个k阶co-location模式c={f1,f2,…,fk},模式c的效用参与度UPI(c)被定义为c中所有特征的UPR值中的最小值,形式化描述如下:
由定义7可知,UPI的取值范围为[0,1]。当忽略特征之间和同一特征的不同实例之间的差异性以及特征之间影响时,UPI就等于PI。所以,基于PI的co-location模式挖掘是基于UPI的模式挖掘的一种特例。当一个模式c的UPI(c)≥λ(用户指定的效用参与度阈值)时,称c是一个高效用co-location模式。
传统的频繁co-location模式不一定是高效用模式;同样,高效用co-location模式未必是频繁模式。例如,在图2中,当w1=w2=0.5,λ=0.5时,模式{E,F}的表实例为{{E.22,F.21}, {E.32,F.12}},PI=0.67>λ,UPI({E,F})=0.23<λ;模式{C,D}的表实例为{{C.29,D.19}, {C.29,D.21}},PI({C,D})=0.25<λ,UPI({C,D})=0.76>λ。
同时,与PI不同,UPI并不满足向下闭合性质,例如在图2中,设w1=w2=0.5,模式{A,D}的表实例为{{A.37,D.19},UPI({A,D})=0.47;模式{A,C,D}的表实例为{{A.37,C.29,D.19},UPI({A,C,D})=0.485>UPI({A,D})。不满足向下闭合性质意味着挖掘基于UPI的高效用co-location模式比挖掘基于PI的频繁co-location模式的难度更大。
不过,根据UPI的定义,可以证明以下引理:
引理1 若co-location模式c的表实例为空,那么c的所有超模式c′⊇c的UPI(c′)=0。
证明 假设模式c的表实例为空,则c的任意超集c′⊇c的表实例一定为空,所以,对于任意fi∈c′有UPR(fi,c′)=0,则UPI(c′)=0。
根据引理1,如果一个模式c的表实例为空,那么它的所有超集c′⊇c都是非高效用co-location模式。
本文采用语义约束规则来形式化表达高效用co-location模式挖掘中涉及到的领域知识。结合co-location模式的挖掘目标,定义了三种语义规则,分别为:抽象语义规则、分类语义规则和互斥语义规则,具体如下:
定义8 抽象语义规则。给定空间特征集F={f1,f2,…,fn}, 将m(m 例如:在植被分布数据集中,可以将“青冈林、石栎林、润楠林、木荷林、白克木林和蚊母树林”等特征抽象为“常绿阔叶林”。抽象语义规则有助于获取更高层次的知识。 定义9 分类语义规则。给定空间特征集F, 根据特征fi∈F的某个属性取值将特征fi具体细分为m(m≥1)个特征,形式化定义如下: 在植被分布数据集中,可以根据植被实例的位置信息对植被进行细分。比如对松树根据实例所在位置细分为三叶松(秦岭地区)、白皮松(关山林区)和云南松(川滇地区),即: 分类语义规则可以有效地细分空间特征,使挖掘结果更加具有可行动性,通常这些结果对具体事务的执行者或者实施者可能更加有效。 定义10 互斥语义规则。给定空间特征集F,若特征fi,fj∈F不能同时出现,则称fi与fj互斥,形式化表述为: 例如,在植被数据集中,耐旱植物和喜湿植物不会生长在一起,如鸭跖草和仙人掌。互斥语义规则能够有效地排除异常数据导致的错误挖掘结果。 下面是一条分类语义规则的XML信息示例: … 其中:rule标签代表一条规则;type属性表示语义规则的类型,取值空间为“AR”(抽象语义规则)、“CR”(分类语义规则)或“MR”(互斥语义规则);location子标签规定了该条规则作用的空间区域。 对于基于UPI的空间高效用co-location模式挖掘,可以采用“生成-测试”形式的类Apriori方法。整个挖掘过程主要包含三个阶段: PhaseⅠ: 数据预处理、空间邻近关系计算; PhaseⅡ: 候选模式的生成以及候选剪枝; PhaseⅢ: 候选模式的表实例计算,UPI值计算,以及筛选高效用co-location模式。 将领域知识作为一种额外的数据资源,进行形式化表示并应用于空间高效用co-location模式的挖掘过程中。图3给出了一个领域驱动的空间高效用co-location模式挖掘的一般框架。 在图3的挖掘框架中,将抽象语义规则和分类语义规则作用于PhaseⅠ阶段,将互斥规则作用于PhaseⅡ阶段,通过互斥规则来提前剪枝候选模式。一次挖掘工作结束后,如果专家从挖掘结果中获取了新的领域知识,算法利用扩增后的领域知识再次进行挖掘;反复执行此过程,直到没有新的领域知识加入。 图3 一个领域驱动的高效用co-location挖掘框架 下面给出领域驱动的空间高效用co-location模式挖掘的基本算法: 输入: F={f1,f2,…,fn}:空间特征集; S:带效用值的空间实例集; R:空间邻近关系(实际中用距离阈值d来度量); w1:特征的IntraUR权重; w2:特征的InterUR权重; λ:高效用模式的UPI阈值; ARs:抽象语义规则集; CRs:分类语义规则集; MRs:互斥语义规则集。 输出: UPI值大于等于λ的高效用co-location模式。 变量: SN={SNf1,SNf2,…,SNfn}:所有空间特征的星型邻居; k:co-location模式的阶数; Ck:k阶候选高效用co-location模式; CTIk:k阶候选高效用co-location模式的表实例; Hk:k阶高效用co-location模式集; H:所有高效用co-location模式集; NonHk:k阶非高效用co-location模式集; new_DK_flag:代表是否有新的领域知识加入。 过程: 1) new_DK_flag=true; //当有新的领域知识加入时需要反复挖掘 2) while(new_DK_flag) do //利用抽象规则,分类规则进行预处理 3) abstract_features(F,S,ARs); 4) classify_features(F,S,CRs); //生成星型邻居集合 5) SN=gen_star_neighborhoods(F,S,R); 6) H1=F;k=2; //判断是否还能够生成k+1阶候选模式 7) while (not emptyHk-1and not emptyNonHk-1) do //通过k-1阶模式生成k阶候选模式 8) Ck=gen_candidate_colocations(Hk-1,NonHk-1); //利用互斥规则和引理进行剪枝 9) Ck=mutex_rules_pruning(Ck,MRs); 10) Ck=other_pruning(Ck); //计算未被剪枝模式的表实例 11) CTIk=gen_table_instance(Ck,SN); //计算模式的效用参与度 12) compute_UPI(Ck,CTIk); 13) Hk=select_high_utility_colocations(Ck,λ); 14) NonHk=U(Ck-Hk); 15) k=k+1; 16) End do 17) ReturnH=∪(H1,H2,…,Hk); 18) new_DK_flag= update_domain_knowledges(ARs,CRs,MRs,H); 19) End do 算法第3)~6)行属于Phase I阶段, 利用抽象语义规则对多个特征进行抽象,利用分类语义规则对特征进行细分,这个过程会调整空间数据中的特征集和特征实例的分布。然后,采用网格划分或者平面扫描的方式[3]计算出所有空间邻近关系,将空间邻近关系物化为星型邻居模式[5],初始化所有1阶模式的UPI为1.0,并将其放入H1。 第8)~10)行属于PhaseⅡ段,第8)行主要负责从k-1(k≥2)阶模式(高效用Hk-1和非高效用NonHk-1)中扩展生成k阶候选高效用co-location模式。生成候选模式的方式为: Ck={c′|c′=c∪{fk}, c∈Hk-1∪NonHk-1,fk>fi∈c} 其中Ck是候选模式,特征按照字典序有序。当k=2时,直接从星型邻居模型中产生二阶候选模式。该方法不会遗漏任何候选模式,同时也不会重复生成候选模式。接着,在第9)行采用互斥语义规则,过滤同时包含互斥语义规则中的特征的候选模式。第10)行采用前文介绍的引理过滤候选模式。 第11)~14)行属于PhaseⅢ阶段,第11)行主要通过扩展k-1阶模式的表实例来计算k(k≥2)阶候选模式的表实例。当k=2时,可以直接从星型邻居模型中查找2阶候选模式的表实例;当k>2时,通过扩展k-1阶模式的表实例,计算表实例方式采用join-less算法的方法[5]。然后在第12行)根据候选模式的表实例计算UPI值,在第13)~14)行将UPI大于等于λ的模式放入Hk中,将其余模式放入NonHk中。 第15)行执行k=k+1,代表接下来的循环中将挖掘k+1阶模式。随着co-location模式阶数的增长,重复执行第8)~10)行,直到无法生成更高阶模式为止。 第18)行执行和用户的交互,若用户有新的领域知识加入,则重新执行整个挖掘过程,直到没有新的规则加入为止。 4.1 实验数据集 实验中采用的数据为人工合成数据,所有人工合成数据分布在1 000×1 000的区域中,特征实例的效用在服从正态分布情况下随机产生,特征的实例个数和特征的总效用均为随机生成。在实验部分,F代表空间特征集,d代表空间邻近关系距离阈值,n代表实例个数,w1代表IntraUR的权重,w2代表InterUR的权重,λ代表UPI阈值,ARs代表抽象语义规则集,CRs代表分类语义规则集,MRs代表互斥语义规则集。 4.2 实验运行环境 实验中涉及的所有算法均用Java语言实现,硬件环境为:IntelCorei3 2.13GHz,4GB内存;软件环境为:Windows10,JRE1.8。 4.3 效用占比评估 为了验证本文提出的度量指标UPI相比传统的PI[3]和PUR[9-10]兴趣度度量更为合理,设置实验数据集信息为:|F|=15,d=30,n=10 000;实验参数为:w1=0.9,w2=0.1,λ=0.01,语义规则集为空。图4(a)展示的是在PI、PUR和UPI三种不同兴趣度度量指标下挖掘到的top-k有趣模式的Q(c)值之和,而图4(b)则展示了三种不同度量指标挖掘结果中不同阶数的top-20有趣模式的平均效用。结果表明,基于UPI的挖掘结果在上述两方面的值均高于基于PI和PUR的结果,反映了基于UPI度量挖掘到co-location模式的总效用和平均效用均更高。 4.4 频繁性评价 模式的频繁性代表了模式存在的普遍性,其对挖掘结果的可用性具有重要意义。PI(参与度)是模式频繁性的经典衡量指标,本节在实验数据集及参数信息设置不变的情况下,对比基于不同兴趣度度量的挖掘结果的频繁性。 图5(a)显示了三种度量指标下的挖掘结果中top-k模式的频繁性之和;图5(b)显示了三种度量指标下挖掘到的有趣模式中各阶的top-20有趣模式的平均频繁性。由于基于PI度量指标的目标是挖掘频繁性高的模式,基于PI的挖掘结果总是具有最高的频繁性。实验结果表明,基于UPI的结果的频繁性在各阶上都高于基于PUR的结果,并且仅仅略低于PI的结果。 图4 三种度量指标的效用占比评估 图5 三种度量指标的频繁性评估 4.5 领域知识对挖掘过程的影响 本节的实验在模拟数据上加入了一些领域知识,以对比加入领域知识以后高效用模式的数量变化。数据集和参数信息为:|F|=15,n=20 000,d=20,w1=0.9,w2=0.1,λ=0.7,ARs语义规则集减少了5个特征,CRs语义规则集新增了5个特征,MRs语义规则定义了3对特征集。表2给出了单独使用每个规则集对高效用模式数量的影响。在表2中,ARs规则集减少了特征,但是增加了抽象特征实例数和分布范围,所以增加了部分高效用模式;CRs规则集增加了空间特征,将特征的实例划分到不同的新特征,降低了新特征实例的部分范围,从而会减少高效用模式的数量。对于MRs规则集,互斥规则使得原来可能高效的模式由于保存了互斥特征而直接变为无效模式。在实际情况中,尤其是在植被数据中,互斥的植物在自然条件下基本不会出现在同一邻域内,所以可以通过互斥规则剔除异常模式。由于领域知识会改变数据集中的特征和实例的分布情况,所以实验中发现领域知识对算法效率的影响是不确定的。 表2 不同语义规则对高效用模式数量的影响 在实际中,不同空间特征和同一特征的不同实例的价值(效用)存在差异性,因此,本文提出研究带效用值的空间实例,同时,提出了IntraUR(内效用率)和InterUR(间效用率)分别衡量特征对模式的直接影响和间接影响,通过UPR(效用参与率)来衡量特征对模式的综合影响,提出的度量指标兼顾了模式的普遍性和效用两方面。另一方面,通过引入语义规则将领域背景知识和约束条件等用于挖掘过程,以挖掘用户真正感兴趣的模式。在未来研究工作中需要进一步研究高效的剪枝策略;在领域驱动挖掘方面,将考虑基于本体的高效用co-location模式挖掘。 ) [1]MORIMOTOY.Miningfrequentneighboringclasssetsinspatialdatabases[C]//KDD’01:Proceedingsofthe7thACMSIGKDDInternationalConferenceonKnowledgeDiscoveryandDataMining.NewYork:ACM, 2001: 353-358. [2]SHEKHARS,HUANGY.Discoveryspatialco-locationpatterns:asummaryofresults[C]//SSTD2001:Proceedingsofthe7thInternationalSysmposiumonAdvancesinSpatialandTemporalDatabases,LNCS2121.Berlin:Springer-Verlag, 2001: 236-256. [3]HUANGY,SHEKHARS,XIONGH.Discoveringcolocationpatternsfromspatialdatasets:ageneralapproach[J].IEEETransactionsonKnowledgeandDataEngineering, 2004, 16(12): 1472-1485. [4]YOOJS,SHEKHARS,SMITHJ,etal.Apartialjoinapproachforminingco-locationpatterns[C]//GIS’04:Proceedingsofthethe12thAnnualACMInternationalWorkshoponGeographicInformationSystems.NewYork:ACM, 2004: 241-249. [5]YOOJS,SHEKHARS,CELIKM.Ajoin-lessapproachforspatialco-locationpatternmining:asummaryofresult[C]//ICDM’05:Proceedingsofthethe5thIEEEInternationalConferenceonDataMining.Washington,DC:IEEEComputerSociety, 2005: 813-816. [6]WANGL,BAOY,LUJ,etal.Anewjoin-lessapproachforco-locationpatternmining[C]//CIT2008:Proceedingsofthe8thIEEEInternationalConferenceonComputerandInformationTechnology.Piscataway,NJ:IEEE, 2008: 197-202. [7]WANGL,BAOY,LUZ.Efficientdiscoveryofspatialco-locationpatternsusingtheiCPI-tree[J].TheOpenInformationSystemsJournal, 2009, 3(2): 69-80. [8] 王丽珍,陈红梅.空间模式挖掘理论与方法[M].北京:科学出版社,2014: 4-13.(WANGLZ,CHENHM.TheoryandMethodofSpatialPatternMining[M].Beijing:SciencePress, 2014: 4-13.) [9] 杨世晟,王丽珍,芦俊丽,等.空间高效用co-location模式挖掘技术初探[J].小型微型计算机系统,2014,35(10):2302-2307.(YANGSC,WANGLZ,LUJL,etal.Primaryexplorationforspatialhighutilityco-locationpatterns[J].JournalofChineseComputerSystems, 2014, 35(10): 2302-2307.) [10]YANGS,WANGL,BAOX,etal.Aframeworkforminingspatialhighutilityco-locationpatterns[C] //FSKD2015:Proceedingsofthethe12thInternationalConferenceonFuzzySystemsandKnowledgeDiscovery.Washington,DC:IEEEComputerSociety, 2015: 631-637. [11]CAOL.ZHANGC.Domain-drivenactionableknowledgediscoveryintherealworld[C]//PAKDD2006:Proceedingsofthe10thPacific-AsiaConferenceeonAdvancesinKnowledgeDiscoveryandDataMining,LNCS3918.Berlin:Springer-Verlag, 2006: 821-830. [12]SIMMONSRF.Storageandretrievalofaspectsofmeaningindirectedgraphstructures[J].CommunicationsoftheACM, 1966, 9(3): 211-215. [13]QUILLIANMR.Semanticmemory[M]//ReadingsinCognitiveScience.SanFrancisco,CA:MorganKaufmannPublishersInc., 1968: 80-101. [14]GRUBERTR.Atranslationapproachtoportableontologyspecifications[J].KnowledgeAcquisition—SpecialIssue:CurrentIssuesinKnowledge, 1993, 5(2): 199-220. [15] 朱正祥.领域驱动知识发现方法研究[D].大连:大连理工大学,2010:23-56.(ZHUZX.Researchonthemethodofdomain-drivenknowledgediscovery[D].Dalian:DalianUniversityofTechnology, 2010: 23-56.) [16] 包旭光,王丽珍,方园.OSCRM:一个基于本体的空间co-location规则挖掘框架[J].计算机研究与发展,2015,52(S1):74-80.(BAOXG,WANGLZ,FANGY.OSCRM:Aframeworkofontology-basedspatialco-locationrulemining[J].JournalofComputerResearchandDevelopment, 2015, 52(S1): 74-80.) ThisworkispartiallysupportedbytheNationalNaturalScienceFoundationofChina(61472346, 61662086),theNaturalScienceFoundationofYunnanProvince(2016FA026, 2015FB114, 2015FB149). JIANG Wanguo, born in 1990, M.S.candidate.His research interests include spatial data mining, knowledge discovery. WANG Lizhen, born in 1962, Ph.D., professor.Her research interests include data mining, database. FANG Yuan, born in 1990, Ph.D.candidate.Her research interests include spatial data mining, knowledge discovery. CHEN Hongmei, born in 1976, Ph.D., associate professor.Her research interests include data mining, knowledge discovery. Domain-driven high utility co-location pattern mining method JIANG Wanguo, WANG Lizhen*, FANG Yuan, CHEN Hongmei (SchoolofInformationScienceandEngineering,YunnanUniversity,KunmingYunnan650091,China) A spatial co-location pattern represents a subset of spatial features whose instances are frequently located together in spatial neighborhoods.The existing interesting metrics for spatial co-location pattern mining do not take account of the difference between features and the diversity between instances belonging to the same feature.In addition, using the traditional data-driven spatial co-location pattern mining method, the mining results often contain a lot of useless or uninteresting patterns.In view of the above problems, firstly, a more general study object — spatial instance with utility value was proposed, and the Utility Participation Index (UPI) was defined as the new interesting metric of the spatial high utility co-location patterns.Secondly, the domain knowledge was formalized into three kinds of semantic rules and applied to the mining process, and a new domain-driven iterative mining framework was put forward.Finally, by the extensive experiments, the differences between mined results with different interesting metrics were compared in two aspects of utility ratio and frequency, as well as the changes of the mining results after taking the domain knowledge into account.Experimental results show that the proposed UPI metric is a more reasonable measure in consideration of both frequency and utility, and the domain-driven mining method can effectively find the co-location patterns that users are really interested in. spatial pattern mining; co-location pattern; high utility co-location pattern; interesting metric; domain-driven; semantic rule 2016- 08- 12; 2016- 09- 11。 国家自然科学基金资助项目(61472346, 61662086);云南省自然科学基金资助项目(2016FA026, 2015FB114, 2015FB149)。 江万国(1990—),男,陕西汉中人,硕士研究生,主要研究方向:空间数据挖掘、知识发现; 王丽珍(1962—),女,山东博兴人,教授,博士,CCF高级会员,主要研究方向:数据挖掘、数据库; 方圆(1990—),女,云南丽江人,博士研究生,主要研究方向:空间数据挖掘、知识发现; 陈红梅(1976—),女,重庆人,副教授,博士,主要研究方向:数据挖掘、知识发现。 1001- 9081(2017)02- 0322- 07 10.11772/j.issn.1001- 9081.2017.02.0322 TP311.13 A
3 领域驱动挖掘的一般框架

4 实验评估与分析


5 结语
