基于查询概率的位置隐私保护方法
2017-04-20赵大鹏宋光旋靳远远王晓玲
赵大鹏,宋光旋,靳远远,王晓玲
(华东师范大学 上海市高可信计算重点实验室,上海 200062)
(*通信作者电子邮箱xlwang@sei.ecnu.edu.cn)
基于查询概率的位置隐私保护方法
赵大鹏,宋光旋,靳远远,王晓玲*
(华东师范大学 上海市高可信计算重点实验室,上海 200062)
(*通信作者电子邮箱xlwang@sei.ecnu.edu.cn)
现有的隐私保护技术较少考虑到查询概率、map数据、信息点(POI)语义等边信息,攻击者可以将边信息与位置数据相结合推断出用户的隐私信息,为此提出一种新的方法ARB来保护用户的位置隐私。该方法首先把空间划分为网格,根据历史查询数据计算出处于不同网格区域的用户提交查询的概率;然后结合相应单元格的查询概率来生成用户匿名区域,从而保护用户的位置隐私信息;最后采用位置信息熵作为隐私保护性能的度量指标。在真实数据集上与已有的两种方法进行对比来验证隐私保护方法的性能,结果显示该方法具体有较好的隐私保护效果和较低的时间复杂度。
基于位置的服务;位置隐私;边信息;查询概率;匿名
0 引言
随着全球定位系统(Global Positioning System, GPS)、蜂窝网等定位技术的快速发展,基于位置的服务(Location-Based Service, LBS)已经无处不在,例如,位置查询(查找距离某用户一定范围内的餐厅)、电子营销(发电子优惠券给附近的顾客)、社交网络(朋友间共享各自的地理位置信息)、交通状况监控(根据一段时间内车辆的位置和速度来推测交通拥堵状况)、路线查找应用(查找两地之间的最短路径)等。虽然LBS给用户提供了许多有价值的服务,同时也给人们带来了位置隐私泄露的问题。如果用户的隐私得不到妥善的保护,将会使用户的权益、安全面临严重的威胁。因此能否很好地解决隐私保护问题可以看作是公众可否放心地使用LBS 服务的前提。
现有的许多位置隐私保护文章[1-3]仅通过用户的位置信息来保护用户位置隐私,没能将位置信息与边信息相结合来保护用户信息,这样的隐私保护方法较容易受到攻击者的攻击,不能达到预期的隐私保护目的,而将边信息与位置信息相结合的隐私保护方法才能更好地保护用户的隐私。例如,某个匿名区域中大部分被湖泊所覆盖,攻击者就可以以很大的概率将湖泊所覆盖的区域排除,认为用户在剩余的区域内,从而缩小用户匿名区域的面积。
另外,很多现有的位置隐私保护工作[4-5]基于可信第三方服务器结构保护用户隐私。可信第三方服务器结构[6]中,用户完全信任可信第三方服务器,将准确位置信息告诉可信第三方服务器。但是,现实生活中完全可信的第三方服务器是不存在的,任何人或机构都有可能成为攻击者。即使数据拥有者不会成为攻击者,但他们的系统也会存在被攻击的可能,攻击者一旦攻破可信第三方服务器的数据库,用户的所有信息将完全暴露给攻击者。
为了解决上述讨论的问题,本文结合边信息(查询概率)保护用户位置的位置隐私,提出ARB(Anonymouse Region Building)算法。首先根据历史查询数据计算出每个网格提交查询的概率,然后根据查询概率选择满足用户要求的候选匿名区域集合,最后通过最大化熵选择最终的匿名区域。本文假设历史查询数据中查询点较少的网格用户提交查询的概率较小,即历史查询点较少的网格是用户真实位置的概率较小。所以,对于一个匿名区域,匿名区域中网格内查询点数量占匿名区域查询点数量比例越大,该网格查询概率越大。另外,在系统中采用半可信第三方服务器结构,用户提交给半可信第三方服务器的查询中不是准确位置坐标,仅需要根据自己的隐私偏好提交所在单元格坐标给半可信第三方服务器,即使攻击者从半可信第三方服务器中获得位置数据或者数据被数据拥有者公布,用户的位置隐私也不会完全暴露。并且,该系统中的用户端不需要大量计算,用户设备仅需要根据用户的隐私偏好和所在位置坐标计算出用户所在的网格坐标。将ARB算法在真实数据集上进行实验分析,与已有的两种方法对比,实验结果展示了ARB算法的性能。
1 相关工作
很多工作采用了匿名技术,Gruteser等[3]提出了位置k匿名的概念,最先把k匿名从关系数据库领域引入LBS隐私保护领域。位置k匿名要求当一个用户请求获得LBS服务时,用一个包含自己当前位置的匿名区域代替自己的准确位置上传给LBS服务器,并且匿名区域中必须包含该查询用户与其他至少k-1个用户。Mokbel等[4]最先提出的IntervalCloak的隐私保护方法,通过递归地划分整个系统空间,直到查询用户所在的最小矩形中用户数目小于k,将该区域的上一层矩形区域作为匿名区域传给LBS服务器。Pan等[5]将移动速度应用到隐私k匿名中,从而可以抵抗位置依赖攻击。Chen等[6]通过分析简单位置k匿名的缺点,然后提出了满足用户隐私偏好的度量指标,并根据该度量指标提出相应的隐私保护算法。Zhou等[7]在k匿名的基础上加入了多样性,使得每个匿名集合满足敏感性、多样性的要求,从而能更好地保护用户的位置隐私。
假位置技术是很多研究者所使用的隐私保护技术,如:Palanisamy等[8]将假名技术应用于路网中,提出Mix-zone的方法来保护用户的位置隐私;Guo[9]将动态假名转换机制与用户的个性化特征相结合来保护用户的位置隐私;Niu等[10]通过最大化熵和隐藏区域面积来选择假位置,达到保护用户隐私的目的。
加密技术也是常用的位置隐私保护方法,如:Ghinita等[11]借助隐私信息检索的方法隐私信息检索(PrivateInformationRetrieval,PIR)来保护用户的查询隐私,查询用户不需要将查询的具体信息发送给服务提供商,但用户需要根据当前位置推测出需要访问数据的位置,然后服务端将信息返回给用户;Papadopoulos等[12]对PIR方法作了进一步优化,提出了cPIR,使得计算开销大幅度下降;Schlegel等[13]通过引入半可信第三方服务器和加密技术保护用户查询隐私,系统中的半可信第三方服务器不知道用户的任何时空信息,仅用于验证查询结果;Khoshgozaran等[14]提出了基于Hilbert曲线的加密方法,将用户的位置与用户兴趣点从二维坐标转移到一维加密空间,通过两条不同参数的Hilbert曲线转化而来的一维加密空间仍然保持了二维空间中的邻近性,因此在一维加密空间中同样可以进行k邻近查询与范围查询;Lu等[15]提出PLAM隐私保护框架,通过使用同态加密技术保护用户隐私,但时间开销相对较大;Paulet等[16]通过PIR加密技术保护用户位置数据,从而达到保护用户隐私的目的,同时对数据进行加密使得用户不能访问未授予访问权限的数据。
2 技术准备
本文采用四叉树[4]的数据结构,将空间自顶向下逐层划分,直到网格边长小于阈值L(单位:m),本文实验中阈值的设置为25m。阈值根据位置隐私保护的需要进行选取,阈值越大表示用户隐私等级越高,本文则取一个人们觉得不是特别大的值,对实验对影响不大。四叉树最顶层为第0层,最底层为第H层,第i层的网格数为4i,例如,第H层的网格个数为4H。然后在第H层对每个网格内的历史查询进行统计,得到最底层网格内数据点个数,即四叉树叶节点的值,任一非叶节点的值等于其四个子节点值之和。
2.1 基本定义
本文系统中主要有两种服务请求:用户向半可信第三方服务器提交的查询请求QU和半可信第三方服务器向服务提供商提交的服务请求QS。
定义1 用户提交给半可信第三方服务器的服务请求QU(UID,h,(R,C),k,Con),其中:UID为用户身份标识;h为用户所在匿名层次,由于用户不完全信任半可信第三方服务器,不希望将自己的准确位置告诉它,h的值决定了用户向半可信第三方服务器暴露的位置信息量的多少,h越大,用户位置信息越具体,真实位置的隐藏粒度越小,反之亦然;(R,C)为用户所在行列坐标,R为行坐标,C为列坐标;k为用户的隐私保护程度,是位置k匿名的阈值(k为大于等于2的偶数);Con为查询内容,不是本文重点研究的内容。例如,某用户提交查询QU为(2,6,(4,5),4,con),表示用户2向半可信第三方服务器提交了一个匿名层次为第6层并且匿名区域大小为4的服务请求,用户2所在位置的网格编号为(4,5),查询内容为con。
定义2 半可信第三方服务器向服务提供商SP提交的服务请求QS((L,U),(R,B),h,Con)),其中:(L,U)为用户匿名区域的左上单元格行列坐标;(R,B)为用户匿名区域右下单元格行列坐标;h为用户所在四叉树的匿名层次;Con为查询内容。
定义3 存储相应网格区域内的历史查询点数目的四叉树称为历史查询点分布树。历史查询点分布树每层都存储着一个如图1的历史查询点统计分布矩阵,每个单元格中的整数表示历史查询点落在该单元格中的次数。例如,图1中灰网格(4,2)中整数是35,表示历史查询点落在网格(4,2)内的统计次数为35。
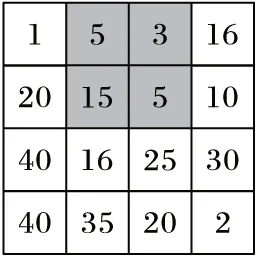
图1 历史查询点分布情况
定义4 逆向攻击是指攻击者不仅知道用户当前的匿名区域,而且知道历史查询点数据分布情况和隐私保护机制,从而根据用户的匿名区域推测出用户真实位置的攻击方法。
如图1所示的历史查询点分布情况,匿名机制是opt算法,计算出所有包含用户位置的大小为k的矩形区域的熵,将熵最大的矩形区域作为用户的匿名区域。当某用户U的隐私偏好为k=2,建立匿名区域为{(4,1),(4,2)}时,攻击者可以推测出用户的位置在(4,2)网格中。因为存在大小为2的匿名区域{(3,1),(4,1)}的位置熵值大小为1.0,用户的匿名区域的位置熵值小于1.0,若用户位置是在查询数量为40的网格内,则根据匿名机制将选择{(3,1),(4,1)}区域作为用户匿名区域,所以用户的位置不在历史查询点数目为40的网格中,而是在历史查询点数目为35的网格中。
定义5 矩形区域的宽度是指矩形区域的行数。例如,图1中阴影矩形区域的宽度为2。本文中的匿名区域不考虑不规则区域情况,所以生成的匿名区域均为矩形区域。
2.2 系统结构
在半可信第三方服务器结构中,用户仅有所保留地信任半可信第三方服务器,与传统的可信第三方服务器结构相比,本文中的用户不需要将自己的准确信息发送给半可信第三方,仅需要将匿名的单元格发送给半可信第三方服务器。并且,本文系统中的用户具有较高的自主选择权利。若用户需要隐私级别较高,用户可以选择较高的四叉树层次作为自己的匿名层次,使得半可信第三方服务器也无法确定用户的准确位置;相反,如果用户对当前位置不敏感,用户可以选择较低的四叉树层次作为自己的匿名层次。
如图2所示,本文中的半可信第三方服务器结构,不是完全依靠可信第三方匿名服务器完成匿名过程。系统主要由三部分组成:移动端、半可信第三方服务器和服务提供商。其中,用户端是携带移动设备的用户,移动设备配有定位功能,并具有简单的计算能力(如智能手机),可以通过用户的经纬度坐标计算出用户所在匿名层次的网格编号;半可信第三方服务器可根据用户提交的查询信息QU与查询概率生成用户的匿名查询QS, 并将匿名查询QS发送给服务提供商(ServiceProvider,SP);服务提供商SP根据半可信第三方服务器发送来的匿名查询QS查找相应的候选结果集,并返回给半可信第三方服务器。
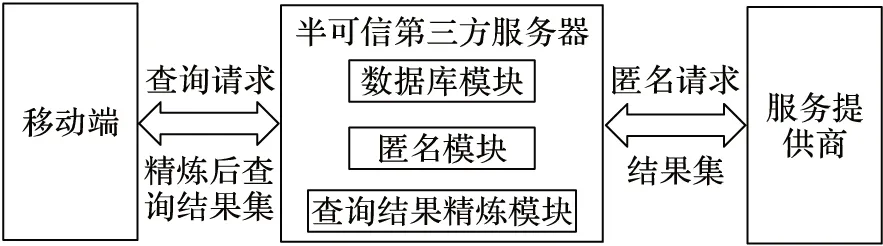
图2 半可信第三方服务器结构
在本文的系统中,用户可根据自己的隐私偏好选取匿名层次h以及匿名等级k,所在层次h的网格单元面积为用户的最小匿名区域大小即用户的最大暴露位置粒度,是任何其他实体所知道用户最详细的位置信息。所以,即使攻击者获得半可信第三方服务器的数据,也无法获得用户的准确位置信息。用户服务请求的过程分五步完成:1)用户首先根据自己的隐私偏好,选择在四叉树中的匿名层次h,然后用户根据移动设备定位功能得到自己当前位置坐标,计算出所在单元格坐标(R,C),将服务请求QU发送给半可信第三方服务器; 2)半可信第三方服务器根据用户所在的单元格坐标(R,C)和用户隐私偏好k对用户进行相应的区域模糊处理,从而得到用户的匿名区域,并将匿名服务请求QS发送给服务提供商,详细内容将在第2.6节中介绍;3)服务器根据用户请求进行查询,将得到的候选结果集返回给半可信第三方服务器,这部分不是本文研究重点;4)半可信第三方服务器根据用户所在网格编号对结果集进行初步筛选,并将筛选之后的结果集返回给用户;5)用户根据自己的准确位置坐标找到最终的结果。
2.3 度量指标
本文采用的度量指标主要是位置熵。位置熵指标最早由Chen等[6]提出,作用是衡量位置的不确定性,位置熵的值越大,不确定性就越高。基于位置熵的位置隐私评价标准的含义是:通过用户与查询位置之间的对应关系的不确定性来度量隐私保护的效果。攻击者将真实位置与请求者关联起来的概率越小,意味着熵就越大,用户位置隐私暴露的可能性也就越小;反之,如果攻击者关联真实位置与请求者之间的概率越大,熵越小,用户位置隐私暴露的可能性也就越大。若给定一个包含k个网格的匿名区域区域,用户在网格i的概率是pi,可以通过式(1)来计算矩形区域的熵值:
(1)
2.4 攻击模型
攻击者的目标是获得某用户的位置隐私,根据攻击者知道信息量的多少,将攻击者分为弱攻击者和强攻击者。弱攻击者是指仅知道用户匿名区域信息,希望获得用户准确位置信息的攻击者;强攻击者是指攻击者不仅知道用户当前匿名区域信息而且知道历史查询点分布情况和位置隐私保护机制的攻击者。目前很多未结合边信息的位置隐私保护技术[2-4]已经可以很好地抵制弱攻击者,因此本文仅考虑强攻击者,并且将LBS服务商作为强攻击者,因为LBS服务提供商知道查询概率和位置隐私保护机制。
2.5 半可信第三方服务器的结构
如图2所示,半可信第三方服务器包括三个模块:数据库模块、匿名模块和查询结果精炼模块。数据库模块根据历史查询数据中历史查询点的分布情况建立历史查询点分布树,并将它存储在数据库模块中,当用户提交所在匿名层次h后,数据库模块会将相应层次历史查询点分布矩阵传输给匿名模块,供匿名模块构建匿名区域使用;匿名模块结合历史查询点分布矩阵数据与用户的隐私偏好k值,利用ARB算法生成相应的匿名区域(2.6节具体介绍),从而获得匿名查询QS,并将QS发送给LBS服务提供商;查询结果精炼模块根据用户所在单元格位置采用文献[2]中的基于匿名区域的最邻近查找算法对从SP返回的候选结果进行筛选,删除部分候选结果,并将筛选之后的结果发送给用户端。
2.6 ARB算法
对于某用户U,其真实位置坐标(C,R),隐私偏好k,所在匿名层次为h,包含用户真实位置网格的匿名区域有很多。如图1所示,灰色阴影网格为用户的位置,用户隐私偏好k=4,则满足此要求的匿名区域还有很多,将在2.8节中进行详细分析,本文提出的ARB算法就是为了解决如何选择匿名区域的问题。对于每个包含用户位置的矩形区域可以根据式(2)计算出每个网格i的查询概率pi。攻击者可以根据查询请求概率推断出用户的位置会以较大概率落在概率较大的网格内,从而排除查询概率较小的区域,减小用户的匿名区域网格数量,使得匿名区域不能满足用户隐私偏好k的要求,所以若图1中阴影区域为某用户的匿名区域,则攻击者可以以很大概率推断用户在值为15的网格中。在考虑了查询概率时,不同矩形区域的熵是不同的,若仅选择熵最大的区域作为匿名区域,就容易受到逆向攻击,本文采用ARB算法寻找匿名区域,可以很好地抵抗逆向攻击。
(2)
对于一个服务请求QU,用户隐私偏好为k,ARB算法首先计算出所有包含用户位置并且大小为k的矩形区域的熵,将熵值最大的k个区域取出,然后随机从这k个区域中选择一个作为用户的匿名区域。算法1为ARB算法的伪代码,算法的输入是历史查询点分布数据、用户位置(C,R)和用户的隐私偏好k,输出为用户的匿名区域CloakRegion。第1)行将计数变量count赋值0,count用于统计k的因数个数,包含用户位置且大小为k的区域个数为Count×k;第2)~8)行计算出所有包含用户位置且大小为k的矩形区域的熵,其中,第3)、4)行排除区域宽度不是n(n为k的因数)的情况,第7)、8)行计算区域宽度为n(n为k的因数)的矩形区域的熵;第9)行将长度为k的数组Number初始化为0,Number[i]用于记录熵值第i大的矩形区域位置;第10)行将Max置0,用于记录每一轮选择的最大熵值;第11)~15)行执行top-k算法选择熵值最大的k个矩形区域;第16)、17)行随机选择熵最大的k个矩形区域中的一个作为用户的匿名区域;第18)行返回结果。
算法1ARB(生成匿名集合)。
输入 历史查询点分布数据,用户所在位置(C,R),用户隐私偏好k;
输出 用户的匿名区域CloakRegion。
1)
Count←0
2)
Forifrom1:k
3)
Ifk%i==0then
4)
Continue;
5)
Else
6)
Count++;
7)
Forjfrom1tok
8)
计算宽度为i的包含用户位置的第Count×k+j区域的熵Entropy[Count*k+j]
9)
Number[1:k]←0
10)
Max←0
11)
Forifrom1:k
12)
Forjfrom1:Count*k
13)
Ifentropy[j]>Maxthen
14)
Max=entropy[j];
15)
Number[i]=j;
16)
随机产生一个小于等于k的正整数n
17)
CloakRegion←第Number[n]个匿名区域;
18)
returnCloakRegion
2.7 时间复杂度分析
时间复杂度也是本文用来衡量系统性能的一个重要指标,ARB的算法时间复杂度仅与k值有关系。任一整数k可分解为式(3)的形式:
k=r1q1r2q2…riqi…rmqm
(3)
其中:ri是素数,qi是相应素数的指数。则k的因数个数N为(q1+1)(q2+1)…(qm+1)(N≤k),例如,18=2×32,18的因数个数为(1+1)(2+1)=6,即1、2、3、6、9、18。
对于任意一个k的因数n,矩形区域宽度为n的区域有k个。例如,图1中包含用户位置的大小为4,且矩形区域宽度为2的区域数量为4。所以ARB算法中计算熵的次数仅与用户的隐私偏好k值有关,且为N×k次(N为k的因数个数)。ARB算法需要从N×k(N为k的因数个数)个熵中选取熵值最大的k个矩形区域,时间复杂度为O(N×k2)。由于k的值较小,所以ARB的计算复杂度较低,时间开销较小。
2.8 安全性分析
本文系统结构是半可信第三方服务器结构,用户可以根据自己的隐私偏好选择自己的匿名层次h,不会将其准确位置坐标发送给任何其他实体。所以,即使半可信第三方服务器与服务提供商SP串谋,也不能获得用户的准确位置。本文中仅考虑攻击能力较强的强攻击者,他希望根据已获得的查询概率数据推测用户的真实位置,面对强攻击者本文方法仍然可以抵抗推理攻击。
一个隐私保护方法能够抵抗推理攻击当且仅当匿名算法生成的匿名区域中每个网格是用户真实位置的概率是相同的。pi和pj分别表示ci和cj是用户真实位置的概率,其中ci和cj表示匿名区域中任意两个网格,则本文方案能够抵抗推理攻击当且仅当pi=pj。根据本文方法最大化匿名区域熵的步骤可知所选择匿名区域中每个网格的查询概率是非常相近的,所以pi=pj。
但当查询概率的数据分布极度不均匀时,本文方法将难以找到合适的匿名区域,即使给定一个满足用户要求的大小为k的区域,攻击者也将能够以大概率推断出用户的真实位置。
3 实验结果与分析
3.1 实验设置
采用真实数据来对算法进行评测。该真实数据采用合肥市中心5.5km×3.5km范围内的历史GPS采样点数据,其包含3万多个人产生的60多万个采样点,此处,把采样点作为查询点。数据包括用户ID、时间和经纬度坐标。为了方便,实验选取其中3.2km×3.2km的空间进行实验,边长阈值为25m将目标空间划分为128×128的网格空间,空间层次为8层,分别为第0层到第7层。
本文实验代码采用Java编写,运行在配置2.4IntelCoreQuadCPU,4GB内存的64位Windows7操作系统中。本文主要使用匿名区域的位置熵和建立匿名区域所需时间来评测ARB算法。
3.2 实验结果
图3表示历史查询点个数为6万,用户匿名层次h=6时,四种算法生成匿名区域的平均熵值随用户隐私偏好k值增加的变化情况。其中:ARB为本文提出的基于查询概率构建匿名区域的算法;dummy[17]为不考虑查询概率,通过随机游走的方法选择匿名区域的算法,是本文的baseline算法;IClique[5]是基于速度信息实现位置隐私保护的方法;opt是理论上熵的最大值。可以看出生成匿名区域的熵值随用户隐私偏好k值增加而增加,从而表明用户隐私偏好k值越大,熵值越大,用户真实位置所在网格的不确定性也越大。从实验结果可以看出,ARB算法达到的位置隐私保护效果较好。
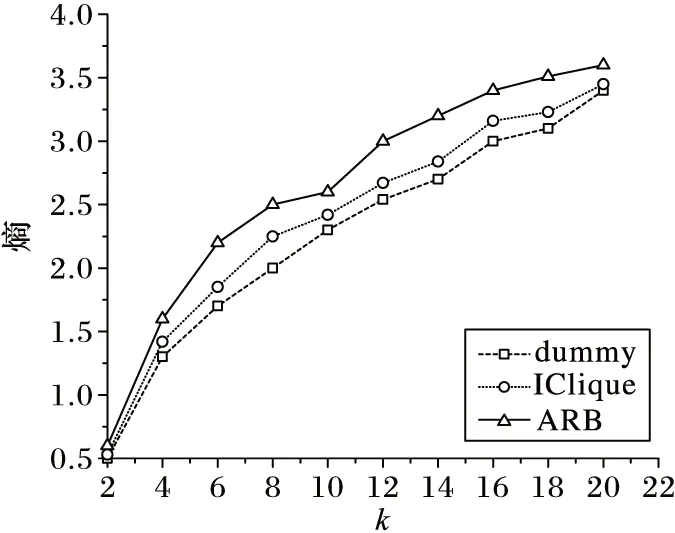
图3 熵 vs.k
图4表示用户隐私偏好k=10,用户匿名层次h=6时,四种算法生成匿名区域的平均熵值随着历史查询点数据量增加的变化情况。可以看出,四种算法随着历史查询数据量的增加,匿名区域熵值也随之增加,并且随着历史查询数据量的增加熵的增长速率越来越缓慢,当历史查询数目增加到36万以上时,熵几乎不再增长,ARB算法的熵明显大于IClique和dummy两种算法。这说明本文设计的系统隐私保护效果与历史查询数据量成正比,但是达到一定数量之后,隐私保护效果几乎不变,历史查询数据量的增加反而会带来系统开销的增加。

图4 熵vs.历史查询数据量
表1表示用户的隐私偏好k=10,历史查询点个数为6万时,随着用户所在匿名层次h的变化,ARB算法生成的匿名区域熵的变化情况。从表中可以看出,随着用户所在层次的不断上升(h减小),用户的位置熵越大,用户真实位置不确定性越大,从而攻击者获得用户位置信息难度也增加,这与我们设立用户隐私偏好的初衷是一致的。所以,对于隐私要求较高的用户,可以选择较高的隐私层次,从而更好地保护用户的位置隐私。
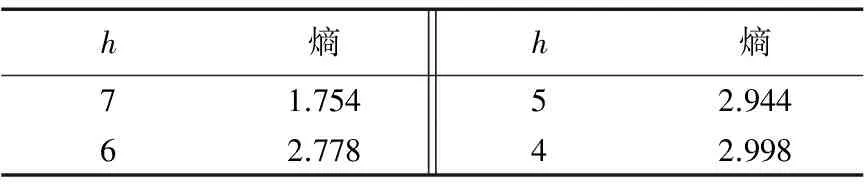
表1 熵值随着用户匿名层次h的变化情况
表2表示历史查询点个数为6万,用户匿名层次h=6时,ARB算法生成匿名区域的时间随用户隐私偏好k值增加的变化情况。可以看出随着用户隐私偏好k值的增加,ARB算法生成匿名区域时间也增加,ARB算法计算开销较小,可以达到微秒级,并且当k×N(N为k的因数个数)相近时生成匿名区域时间也相近,与2.7节中的时间复杂度分析相吻合。

表2 ARB算法运行时间随k的变化情况
4 结语
本文提出了一种采用半可信第三方服务器结构的隐私保护方法,用户可以根据自己的隐私偏好选取空间划分粒度,从自身需求出发完成个性化的位置隐私,该方法所产生的用户匿名区域难以被攻击者所缩小。但是,当数据分布极不均匀时,会出现ARB算法无法找到熵较大的匿名区域来完成用户位置匿名的情况;另外,ARB的主要应用场景是在单次查询中,在将来的工作中我们将研究连续查询的位置隐私保护方法。
)
[1]XUN,ZHUD,LIUH,etal.Combiningspatialcloakinganddummygenerationforlocationprivacypreserving[C]//ADMA2012:Proceedingsofthe8thInternationalConferenceonAdvancedDataMiningandApplications,LNCS7713.Berlin:Springer-Verlag, 2012: 701-712.
[2]ASHOURI-TALOUKIM,BARAANI-DASTJERDIA,SELÇUKAA.Thecloaked-centroidprotocol:locationprivacyprotectionforagroupofusersoflocation-basedservices[J].KnowledgeandInformationSystems, 2015, 45(3): 589-615.
[3]GRUTESERM,GRUNWALDD.Anonymoususageoflocation-basedservicesthroughspatialandtemporalcloaking[C]//MobiSys’03:ProceedingsoftheFirstInternationalConferenceonMobileSystems,Application,andServices.NewYork:ACM, 2003: 31-42.
[4]MOKBELMF,CHOWC-Y,AREFWG.ThenewCasper:queryprocessingforlocationserviceswithoutcompromisingprivacy[C]//ICDE2007:Proceedingsofthe23rdInternationalConferenceonDataEngineering.Washington,DC:IEEEComputerSociety, 2007: 1499-1500.
[5]PANX,XUJ,MENGX.Protectinglocationprivacyagainstlocation-dependentattacksinmobileservices[J].IEEETransactionsonKnowledgeandDataEngineering, 2012, 24(8): 1506-1519.
[6]CHENX,PANGJ.Measuringqueryprivacyinlocation-basedservices[C]//CODASPY’12:ProceedingsoftheSecondACMConferenceonDataandApplicationSecurityandPrivacy.NewYork:ACM, 2012: 49-60.
[7]ZHOUC,MAC,YANGS,etal.AlocationprivacypreservingmethodbasedonsensitivediversityforLBS[C]//NPC2014:Proceedingsofthe11thIFIPWG10.3InternationalConferenceonNetworkandParallelComputing,LNCS8707.Berlin:Springer-Verlag, 2014: 409-422.
[8]PALANISAMYB,LIUL.Attack-resilientmix-zonesoverroadnetworks:architectureandalgorithms[J].IEEETransactionsonMobileComputing, 2015, 14(3): 495-508.
[9] GUO M, PISSINOU N, IYENGAR S S.Pseudonym-based anonymity zone generation for mobile service with strong adversary model [C]// CCNC 2015: Proceedings of the 2015 12th Annual IEEE Consumer Communications and Networking Conference.Piscataway, NJ: IEEE, 2015: 335-340.
[10] NIU B, LI Q, ZHU X, et al.Achievingk-anonymity in privacy-aware location-based services [C]// Proceedings of the IEEE INFOCOM 2014.Piscataway, NJ: IEEE, 2014: 754-762.
[11] GHINITA G, KALNIS P, KHOSHGOZARAN A, et al.Private queries in location based services: anonymizers are not necessary [C]// SIGMOD ’08: Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data.New York: ACM, 2008: 121-132.
[12] PAPADOPOULOS S, BAKIRAS S, PAPADIAS D.pCloud: a distributed system for practical PIR [J].IEEE Transactions on Dependable and Secure Computing, 2012, 9(1): 115-127.
[13] SCHLEGEL R, CHOW C-Y, HUANG Q, et al.User-defined privacy grid system for continuous location-based services [J].IEEE Transactions on Mobile Computing, 2015, 14(10): 2158-2172.
[14] KHOSHGOZARAN A, SHIRANI-MEHR H, SHAHABI C.Blind evaluation of location based queries using space transformation to preserve location privacy [J].GeoInformatica, 2013, 17(4): 599-634.
[15] LU R, LIN X, SHI Z, et al.PLAM: a privacy-preserving framework for local-area mobile social networks [C]// Proceedings of the IEEE INFOCOM 2014.Piscataway, NJ: IEEE, 2014: 763-771.
[16] PAULET R, KAOSAR M G, YI X, et al.Privacy-preserving and content-protecting location based queries [J].IEEE Transactions on Knowledge and Data Engineering, 2014, 26(5): 1200-1210.
[17] SATOH T, KIDO H, YANAGISAWA Y.An anonymous communication technique using dummies for location-based services [C]// ICPS ’05: Proceedings of the 2005 International Conference on Pervasive Services.Washington, DC: IEEE Computer Society, 2005: 88-97.
This work is partially supported by the National Natural Science Foundation of China (61170085, 61472141), Shanghai Leading Academic Discipline Project (B412), Shanghai Knowledge Service Platform Project (ZF1213).
ZHAO Dapeng, born in 1988, M.S.candidate.Her research interests include location privacy protection, data mining.
SONG Guangxuan, born in 1992, M.S.candidate.Her research interests include distributed data base, query optimization.
JIN Yuanyuan, born in 1995, M.S.candidate.Her research interests include location privacy protection, data mining.
WANG Xiaoling, born in 1975, Ph.D., professor.Her research interests include location privacy protection, data mining.
Query probability-based location privacy protection approach
ZHAO Dapeng, SONG Guangxuan, JIN Yuanyuan, WANG Xiaoling*
(ShanghaiKeyLaboratoryofTrustworthyComputing,EastChinaNormalUniversity,Shanghai200062,China)
The existing privacy protection technologies rarely consider query probability, map data, semantic information of Point of Information (POI) and other side information, so the attacker can deduce the privacy information of the user by combining the side information with the location data.To resolve this problem, a new algorithm was proposed to protect the location privacy of users, namely ARB (Anonymouse Region Building).Firstly, the space was divided into grids, and historical statistics were utilized to obtain the probability of queries for each grid of space.Then, the anonymous region for each user was obtained based on query probability of corresponding grid to protect the user’s location privacy information.Finally, the location information entropy was used as a measure of privacy protection performance, and the performance of the proposed method was verified by comparison with the existing two methods on the real data set.The experimental results show that ARB obtains better privacy protection effect and lower computation complexity.
Location-Based Service (LBS); location privacy; side information; query probability; anonymity
2016- 08- 12;
2016- 09- 30。 基金项目:国家自然科学基金资助项目(61170085,61472141);上海市重点学科建设项目(B412);上海市可信物联网软件协同创新中心资助项目(ZF1213)。
赵大鹏(1988—),男,安徽滁州人,硕士研究生,主要研究方向:位置隐私保护、数据挖掘; 宋光旋(1992—),男,山东青岛人,硕士研究生,主要研究方向:分布式数据库、查询优化; 靳远远(1995—),女,河南驻马店人,硕士研究生,主要研究方向:位置隐私保护、数据挖掘; 王晓玲(1975—),女,山东烟台人,教授,博士,CCF会员,主要研究方向:位置隐私保护、数据挖掘。
1001- 9081(2017)02- 0347- 05
10.11772/j.issn.1001- 9081.2017.02.0347
TP391
A
