路网中位置不确定的二元反kNN查询
2017-04-20李文根张毅超关佶红
徐 伟,李文根,张毅超,关佶红
(同济大学 计算机科学与技术系,上海 201804)
(*通信作者电子邮箱jhguan@tongji.edu.cn)
路网中位置不确定的二元反kNN查询
徐 伟,李文根,张毅超,关佶红*
(同济大学 计算机科学与技术系,上海 201804)
(*通信作者电子邮箱jhguan@tongji.edu.cn)
针对路网限制和物体位置的不确定性,提出了路网中位置不确定的二元反kNN查询(PBRkNN),旨在查找一组位置不确定的点,使得每个不确定点的kNN包含给定查询点的概率大于一个阈值。为了解决该问题,首先提出一种基于Dijkstra进行剪枝处理的基本算法,即PE算法;接着在PE算法的基础上通过预处理计算出每个点的kNN从而加快查询速度,即PPE算法;而为了进一步减小PPE算法中范围查询的开销,提出PPEE算法,利用网格索引来索引范围查询中要查询的不确定空间点,从而提升算法的效率。最后,在北京和加州路网数据集上进行了大量实验,结果表明通过一些预处理的策略确实可以有效地处理路网中位置不确定的二元反kNN查询。
反kNN查询;路网;Dijkstra算法;不确定性
0 引言
随着空间定位技术和移动通信技术的发展,以及手机等智能设备的广泛使用,各种基于位置的服务(Location Based Service, LBS)得到了越来越广泛的应用。作为基于位置应用中重要的查询之一,反kNN查询(即寻找查询点是哪些点的k最近邻(k-Nearest Neighbor,kNN))[1]在现实生活中被广泛用于诸如决策系统[1]、超市的选址、出租车的调度[2]和龙卷风预测[2]等领域。
已有的关于反kNN查询的研究主要分为三类:基于欧氏距离的反kNN查询[1,3-6]、基于路网距离的反kNN查询[7-10]和不确定反kNN查询[2,11-15]。不确定性的引入主要由于物体位置更新的时间间隔、网络传输延迟、数据隐私保护和定位设备的误差等因素会导致物体位置存在必然的不确定性。目前,不确定反kNN研究主要集中在欧氏空间。考虑到物体的移动受限于实际的路网,有必要进行路网中不确定性的反kNN查询研究。
反kNN查询可以分为两类:一元反kNN查询和二元反kNN查询。其中一元反kNN查询中的候选集合只有一种类型,查询目标是计算查询点是候选集中哪些点的kNN;二元反kNN查询的查询集合则分为两类A和B,查询点与其中一个候选集A类型相同,查询目标是计算查询点是候选集B中哪些元素的kNN,值得注意的是,对于B中每个元素的kNN是指A中离其最近的k个元素。二元反kNN查询在实际生活中有着广泛的应用,特别是结合路网和位置不确定性的二元反kNN更加符合现实生活。如在出租车的派单系统中,对于每个乘客的订单派送选择就可以看成是以乘客为查询点的反kNN查询;另外因为出租车一直运动,实时位置必然存在一定的不确定性。本文结合路网和位置的不确定性,旨在研究路网中位置不确定的二元反kNN查询处理。
下面从欧氏空间中的反kNN查询、路网中的反kNN查询和不确定的反kNN查询这三个方面介绍反kNN查询的研究现状。
1)欧氏空间中的反kNN查询。现有的基于欧氏空间的反kNN查询的算法主要分为三步:1)建立索引;2)在已构建好的索引结构的基础上通过一些剪枝过滤策略,剪掉一些不可能的空间点;3)对剩下的候选点进行验证,得到最终满足条件的结果。具体地,索引主要有R树、R+-树和R*树;剪枝策略则主要分为基于自身限制的剪枝[1,3]和基于其他元素限制的剪枝[4-6];候选点的验证主要采用kNN查询或者range-k查询。但是这类查询没有考虑移动物体位置的不确定性。
2)路网中的反kNN查询。Yiu等[7]第一次提出了基于路网的反kNN查询,其处理流程与欧氏空间中的反kNN类似。不过,针对路网中的反kNN查询的特点,索引方面主要采用泰森多边形(Voronoi图)[8]和邻接表[9-10];剪枝则根据更近邻原则[8]实现;验证同样使用kNN查询。这类查询虽然将反kNN查询引入到路网中,但是没有考虑到路网中移动物体的不确定性问题。
3)不确定的反kNN查询。Lian等[11]第一次提出了基于位置不确定性的反kNN查询。这类问题的主要难点在于位置不确定性的表示和基于这种表示的高效索引与剪枝。这类问题主要分为四步:1)不确定性的表示,主要有最小边界圆[11]和最小边界矩形[2,11-15];2)基于空间位置的剪枝,即不考虑它们的概率分布,主要是基于半分策略[12-14];3)基于概率的剪枝,主要是划分圆[2,15];4)验证采用kNN查询。这类查询虽然引入了移动物体位置的不确定性,但是并没有考虑路网中位置不确定性的反kNN查询。
综上所述,已有的反kNN查询算法没有同时考虑路网限制和物体位置的不确定性,不能直接用于解决本文所提出的路网中位置不确定的反kNN查询问题。
1 问题定义
首先给出路网和空间点的定义。
定义1 路网(Road Network)。路网本质上一个图G=〈V,E〉。其中:V代表节点的集合,表示路网中道路的拐点或交叉点;E是边的集合,每条边连接两个节点。
定义2 空间点(PointOnNetwork,PON)。一个空间点表示为p=〈e,pos〉。其中:e表示空间点所在的边,pos表示空间点p到e的开始端的偏移。
在定义不确定空间点(UncertainPON,UPON)之前,先描述不确定空间点的表现形式。在欧氏空间中,物体的不确定位置表示为一个椭圆或多边形。如图1,物体在a处的不确定表示就是围绕a点的椭圆。然而,在路网中,物体运动受限于路网。例如,图1存在着实际路网bd和ce,欧氏空间中阴影的范围在路网中的不确定性表示就是4个路段即ab、ac、ad和ae。因此,在路网中UPON位置由多个路段来表示。把组成不确定空间点的路段称为不确定路段(UncertainSegment)。下面给出不确定路段和不确定空间点的定义。
定义3 不确定路段。不确定路段表示为us=〈edge,fromPos,toPos〉。其中:edge表示该不确定路段所在的边,fromPos和toPos分别表示该确定性路段首尾位置。

图1 不确定区域
定义4 不确定空间点。一个不确定空间点表示为up=〈us0,us1,…,usm-1〉,其中usi表示物体可能出现不确定路段。
定义5 不确定空间点的范围长度ul(UPONlength)。一个不确定空间点up=〈us0,us1,…,usm-1〉的范围长度ul为:
ul(up)=∑len(usi)
(1)
其中len(usi)=toPosi-fromPosi。
下面给出路网中位置不确定的二元反kNN查询的定义。
定义6 路网中位置不确定的二元反kNN查询(Probabilistic Bichromatic Reverse-kNN query on road network, PBR-kNN)。给定路网G,空间点PON集合A={p0,p1,…,pn-1},不确定空间点UPON集合B={up0,up1,…,upm-1},一个概率阈值∂ 和一个查询点q∈A,PBR-kNN查询的目标是查找B的一个子集Bp,满足:
Bp={up|P(q∈PkNN(up))≥∂,up∈B}
(2)
其中P(q∈PkNN(up))表示q为up的kNN概率,即:
(3)
其中,{p|q∈kNN(p),p∈up}得到的点集合刚好可以组成若干个连续的路段。在PBR-kNN查询中,集合A中的元素与查询点q是竞争关系,所以A的元素与q一样为PON。
2 PE算法
为了有效解决路网中位置不确定的二元反kNN查询,首先设计了Probabilistic Eager(PE)算法,作为解决此问题的一个基本方法。PE算法的思想是基于Dijkstra算法加剪枝。
2.1 索引结构
为了节省空间,便于每条边上的PON和UPON的索引,PE算法采取类邻接表的方法存储路网。在邻接表中每个节点都会有个邻接节点表,本文采用另外独立索引每条边的方式将邻接节点表变成邻接边表。如图2所示路网建立索引,其中:q1和q2为兴趣点,q为查询点,s1n7、s2n7、s3n7组成up1,s4n5、s5n5组成up2,q1n1=2,q2n2=3,qn2=2,s1n7=1,s2n7=2,s3n7=3,s4n5=1,s5n5=2。假设边n1n2、n1n6、n2n4和n2n7的ID分别为e1、e2、e3和e4,则n1、n2的邻接表如图3。
PE算法给每条边编一个ID,每条边会记录这条边两端节点的编号。对于每条边上的空间点,会有一个PONlist表按照距离边起始端的距离排序。对于每条边上的不确定路段,会有一个UncertainList表记录在这个边上出现过的不确定空间点。对于不确定空间点,用一个单独的链表来索引每个不确定空间点的路段。图2的索引结果如图4所示。
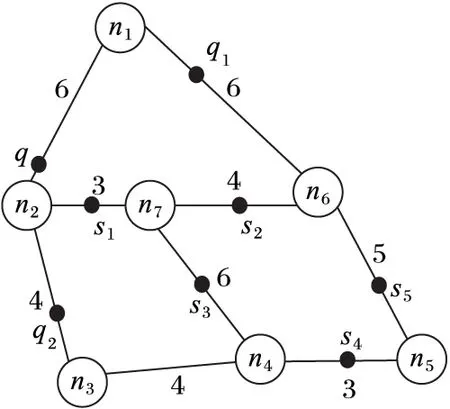
图2 一个路网的例子

图3 路网索引
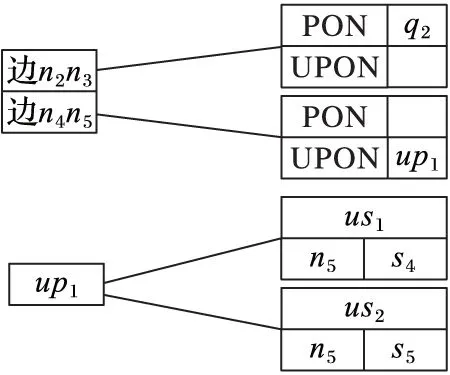
图4 边及不确定空间点索引
2.2 查询算法
引理1 对于不确定路段us(edge〈n1,n2,length〉,fromPos,toPos)和查询点q,如果n1∉BRkNN(q),n2∉BRkNN(q),则有:
P(us∈BRkNN(q))=0
(4)
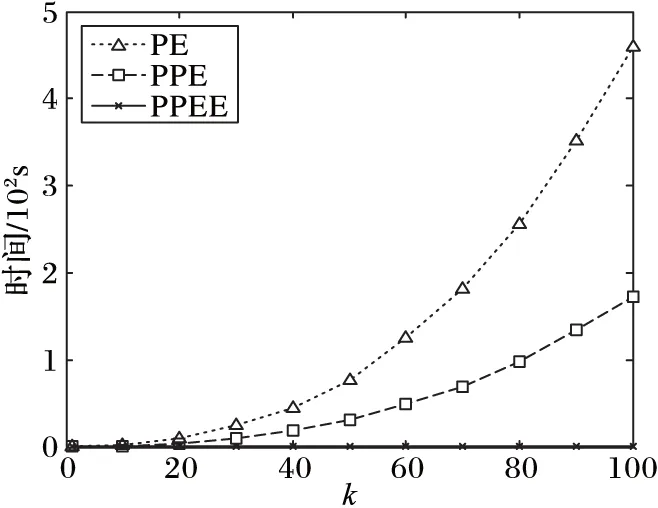
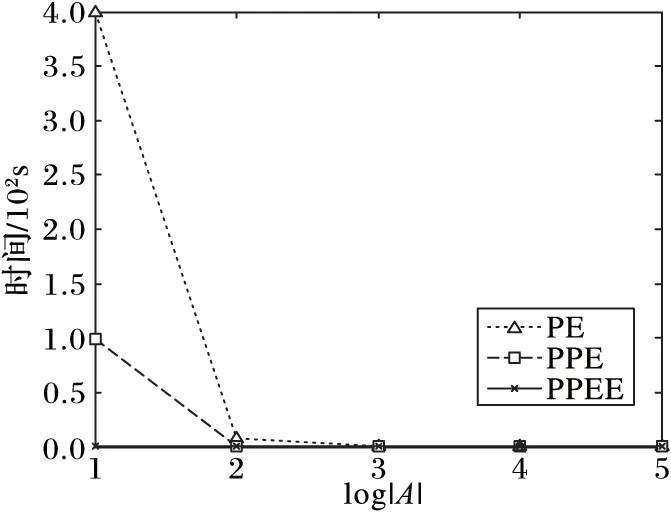
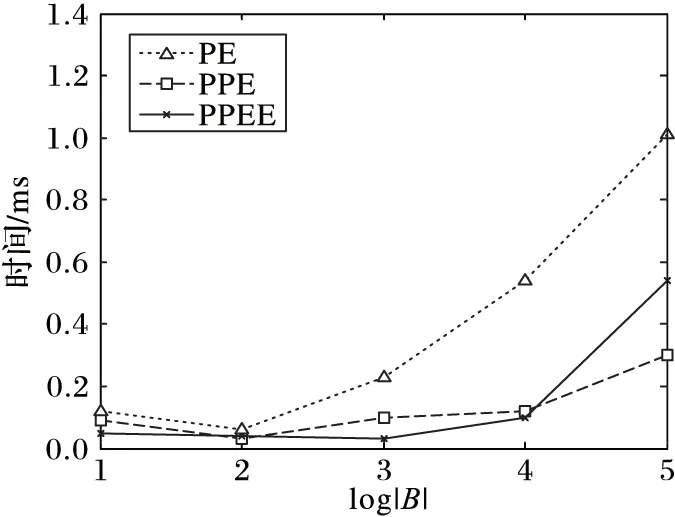
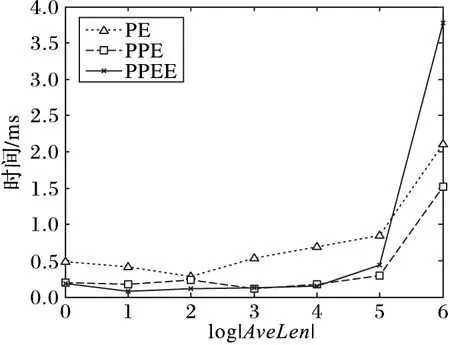
引理2 对于一条边(edge〈n1,n2,length〉),所有满足{p|q∈BRkNN(p),p∈edge}条件的PON构成的区域刚好是整个edge的所有范围或者两个分开的路段s1〈edge,fromPos1,toPos1〉,s2〈edge,fromPos2,toPos2〉满足fromPos1=0,toPos2=length,并且toPos1 证明 反证法:假设存在一个路段s〈edge,fromPos,toPos〉包含所有满足条件的PON点,且fromPos不等于0,toPos不等于length。假设d(q,n1) dist(p,p1)=min(dist(p,n1)+dist(n1,p1), dist(p,n2)+dist(n2,p1)) 情况一dist(p,p1)=dist(p,n1)+dist(n1,p1)。 dist(p,n1)+dist(n1,p1) dist(p,n1)=dist(p,p1)-dist(n1,p1)> dist(q,p1)-dist(n1,p1)=dist(q,n1) 所以n1也是满足条件的点,与fromPos=0矛盾。 情况二dist(p,p1)=dist(p,n2)+dist(n2,p1)。 dist(p,n1)+dist(n1,p1)>dist(p,n2)+dist(n2,p1) dist(p,n1)>dist(p,p1)-dist(n1,p1)> dist(q,p1)-dist(n1,p1)=dist(q,n1) 所以n1也是满足条件的点,与fromPos=0矛盾。 综上所述,不存在这样的路段s,所以问题得证。 推理1q为查询点,n为路网节点,由文献[7]中引理1和本文中引理1可以得到,如果存在k个空间点p0,p1,…,pk-1满足d(n,pi) P(us∈BRkNN(q))=0 (5) 证明 因为n1和n2到q点的最短路径都要经过n,由文献[7]中引理1得n1∉BRkNN(q),n2∉BRkNN(q),由本文中的引理1得P(us∈BRkNN(q))=0。 PE算法的基本逻辑其实非常简单,就是不停地在集合B中寻找可能是结果的upi,然后判断P(q∈PkNN(upi))的值是否大于∂。 1)寻找可能的upi。 最简单的办法就是根据距离q点的距离,由近及远进行遍历作为候选者upi,那么就可以使用Dijkstra算法进行扩展。但是由推理1,可以从节点n处剪枝掉很多不可能的节点,提高寻找候选者的效率。所以算法的主要流程如下: 1)初始化一个小顶堆。 2)将查询点q〈edge,pos〉所在边的两个端点加入堆中,即〈n1,pos〉和〈n2,edge.length-pos〉。 3)验证edge上是否有符合条件的不确定性路段。 4)基于Dijkstra算法对路网进行扩展,对符合推理1的节点进行剪枝。 假设访问到了节点n: a)计算n的kNN(n)={p1,p2,…,pk}; b)对于pi验证在range(n,q)范围内的边上是否有满足条件的us(实际上是再次计算pi的kNN)。 c)如果q∉kNN(n),根据推理1剪掉节点n,否则将n的邻接节点加入到堆中。 说明:PE算法以不确定性路段作为最基本的单位分开计算每个路段成为q的RkNN的概率,一个不确定性空间点的所有不确定性路网都计算完,或者程序结束前,就会计算每个被访问过的不确定空间点成为q的RkNN的概率,并筛选出概率值大于设定的概率阈值的。 2)验证候选者upi。 如前面所说,对于候选者upi的验证,先计算组成upi的usi0,usi1,…,usi(m-1)的概率,然后再验证upi是否满足要求。对于路网的同一条边上可能会有多个us,而对于每个us的验证都与该边的两个端点有关,所以对于同一条边上的us,它们的验证计算可能差不多。为了提高计算效率,PE算法先计算出us所在的边edge上哪些区域段中的点是满足为q点RkNN的,即 UAR={us|∀p∈us,q∈BRkNN(p),us∈edge} 然后再计算usij中有多少包含在集合UAR中。假设计算的边为edge〈n1,n2,len〉,计算UAR的算法主要包括以下步骤:计算kNN(n1)和kNN(n2);如果q不在kNN(n1)和kNN(n2)中,则返回空;根据引理2,UAR分成从n1起始的路段us1和从n2起始的路段us2计算;验证us1和us2是否要合并,并返回结果。 3.1 PPE算法 PE算法包含大量两个路网节点间的最短距离计算,而在路网上计算两点距离的算法比欧氏空间中的距离计算复杂很多。为了提高PE算法的效率,采用文献[7]的方法提前算出每个节点的kNN(这里的kNN是指k最近邻的PON点),称之为Pre-compute Probabilistic Eager (PPE)算法。这样,PE算法中寻找可能upi的第4.a)步和验证候选者upi的第4.b)步,每次计算节点的kNN就可以省去,能极大地提高算法效率。 在预处理中,k设为可能取到的最大值。在实际生活中,k一般取到20就可以了。为了实验需求,本文k取100。 3.2 PPEE算法 在寻找候选upi的过程中,第4)步中的a)、b)可以同时计算,但是经过PPE算法的改进,b)还需要重新独立地计算才能得到候选者。为此提出基于网格划分索引的策略,从快速计算出候选者的角度来进一步提高查询的效率,称为Pre-computeProbabilisticEagerExternal(PPEE)算法。 3.2.1 数据索引 1)网格划分。PPEE算法按照物体点的平面坐标划分网格,这样可以方便数据的管理和查询,便于数据的网格定位和快速找到每个网格四周的网格。对于一个不确定性路段可能出现在多个网格中的情况,PPEE算法采取多冗余化简便的办法,在包含该不确定性路段的所有网格中都添加该不确定性路段。如图5是图2路网的一个网格划分。 图5 网格划分 2)不确定性路段索引。因为一条边上可能会出现多个不确定性路段,而且在处理不确定性路段时,同一条边上的多个不确定性路段同时处理效率会更高,所以PPEE算法对不确定性路段的索引是对含有不确定性路段的边进行索引。这样既可以减小检索块的尺寸又可以提高索引查找的效率。使用图5的划分规则,得到的索引如图6。 3)不确定性索引的更新。由于不确定性索引的更新可能会很快也可能很慢,为此PPEE算法采取类似于内存管理的策略。针对每一条边,不确定性路段的更新包括以下四种情况: 1)该边上增加了新的不确定性路段,但增加之前该边上已有不确定性路段; 2)该边上增加了新的不确定性路段,但是增加之前该边上没有不确定性路段; 3)该边上减少了不确定性路段,但是减少之后该边上还有不确定性路段; 4)该边上减少了不确定性路段,减少之后该边上就不存在不确定性路段了。 对于情况1)和3),索引不需要作任何改变;对于情况2),则需要把该边添加到该边所在网格的索引表中;对于情况4),本来应该从该边所在网格的索引表中把该边删除,但是考虑到接下来可能还会有不确定性路段更新,因而采取延迟更新的策略,即在后来的查询算法中查找到该边时,如果该边上没有不确定性路段,就把它从索引表中删除。 图6 不确定性的索引 3.2.2 查询算法 PPEE算法在PPE算法的基础上对不确定性空间点作索引,它们的不同之处在于寻找候选不确定空间点集合。基于网格索引的寻找候选不确定空间点的算法如下: 输入 节点n; 输出 候选不确定空间点。 1)令d为kNN(n)中距离n点最远的距离。 2)定位n所在的网格为gridn。 3)计算到gridn的四边的距离小于等于d的所有网格集合Grids。 4)遍历Grids中所有的grid。对于gridi,遍历gridi索引中的每条边edgei中索引的不确定路段作为候选者。对于edgei如果不包含不确定路段,则从索引表中删除。 在PPEE算法中,每条边和每个划分网格都会记录是否被访问过,以防止重复访问。 4.1 实验数据 实验采用北京和加州的路网,其中北京路网的节点和边的数目分别为84 084和104 313;加州路网的节点和边的数目分别为21 048和21 693。 1)北京路网PON和UPON生成:实验采用北京出租车数据,包含11 716辆出租车2012年某个月的采样数据。将给定时刻叫车的乘客作为PON空间点集合,此时刻的空出租车则作为UPON集合。生成规则如下:选取一个打车比较多的时间点t,如果出租车在t时刻前后30min内有载新乘客的动作,说明这个点有一个乘客,则将其加入到A集合;如果在这个时间点前后两个采样点都是空车的状态,那就生成一个UPON,UPON的中心点就是距t最近的采样点的位置,范围为这两个采样点的距离。生成好之后就可以加入到UPON集合中。最终生成的空间点集合A共866个元素,不确定性区域集合B共3 994个元素,不确定性路段数为785 125。 2)加州路网上的PON和UPON生成:以加州路网为基础,运用随机函数根据一定的限制生成,生成方法则模拟前面北京路网真实数据的生成。首先,按照集合A要求的元素个数,对集合A中每个点p〈edge,pos〉,按照edgeId和pos随机生成。然后,按照集合B要求的元素个数,先按照生成集合A的办法,生成|B|个点p0,p1,…,p|B|-1;接着,按照平均不确定性长度ul,生成|B|个长度值ul0,ul1,…,ul|B|-1,使得它们的平均值为ul;最后,以pi为中心,不确定性长度为uli,按照前面真实数据的生成方法生成upi。该实验数据集如表1所示。 表1 实验数据集 实验参数设置如表2所示。 表2 实验参数设置 实验运行于配置为IntelCorei7- 4790KCPU@ 4.00GHz16GBRAM的计算机,采用Java环境。实验结果为100次实验的平均值。 4.2 实验结果分析 1)k值大小对算法查询时间的影响:本组实验分别在两个数据集上进行。从图7、8可以看出,当k较小时,三个算法的时间开销差异很小。随着k的增加,三种算法的时间开销均在增加,PE算法进行的range查询按照访问节点的平方数增长,而PPE算法是线性增长的,所以这两条线中PE算法曲线变化比PPE算法更明显;而PPEE算法进行range查询的花费为0,但随着k的增加,访问的grid数也随访问的节点数线性增长,而访问grid的花费明显比range查询少很多,所以PPEE算法的曲线变化更小。在实际的生活中,k可能只会取到40,由图7可以看出,在k<40时,最快的查询算法即PPEE算法可以在100ms之内计算出结果。 2)PON数量对算法查询时间的影响:本组实验使用加州路网的数据集C2。由图9可以看出,在PON数量(即集合A中元素的个数)比较小时,PON分布比较稀疏,这样利用推理1进行剪枝的效果会比较差,仍然需要进行多次range查询,所以PE算法和PPE算法的效果在A的个数小于100时并不明显;但对于PPEE算法,因为不需要进行range查询,所以影响不大。 3)UPON数量对算法查询时间的影响:本组实验使用加州路网的数据集C3。三种算法遍历的路网节点的个数没有变化,变化的只是需要验证的边的个数。由图10可以看出,在UPON的数量(即集合B元素中元素的个数)大于10 000时,PPEE算法的花费明显大于PPE,这是因为随着B中元素个数的增加,PPEE算法需要验证的UPON数量增长的速度比算法PE和PPE快很多。 注意:在图9~11中为了更好地展示结果,横轴都采用指数的形式来表示。 4)不确定路段范围长度对查询时间的影响:本组实验使用加州路网的数据集C4。集合B中UPON平均长度的增加不会显著影响三个算法访问的节点个数,但是会增加待验证的边上不确定性路段的个数。从图11可以看出,当平均区域长度大于100 000时,PPEE算法的时间曲线变化非常明显,查询时间比PE和PPE更长,这是因为PPEE算法采用划分网格的策略寻找那些需要验证的不确定性路段,这样使得需要验证的数量比另外两种算法大幅增加。 图7 北京路网数据集查询时间与k的关系 图8 加州路网数据集查询时间与k的关系 图9 集合A的个数与查询时间的关系 图10 集合B的个数与查询时间的关系 图11 UPON平均长度与查询时间的关系 本文结合路网和物体位置的不确定性研究了路网中位置不确定的二元反kNN查询问题。为了解决该问题,首先针对路网中位置不确定性提出了一个表示模型,并在此基础上提出了一个基本的查询处理算法即PE算法;在PE算法的基础上,又进一步提出了两种改进的处理算法,即PPE算法和PPEE算法。实验结果表明,PE算法适合处理k值较小的查询,因为它的时间开销随着k的增加呈现指数增长;PPE算法的时间开销则随着k的增加线性增长,适合处理具有较大k值的查询;PPEE算法性能最好,随着k的增加,它的时间开销增长非常缓慢,算法总的处理时间小于100 ms,能够很好地满足实时查询的要求。 References) [1] KORN F, MUTHUKRISHNAN S.Influence sets based on reverse nearest neighbor queries[J].ACM Sigmod Record, 2000, 29(2): 201-212. [2] NIEDERMAYER J, ZÜFLE A, EMRICH T, et al.Probabilistic nearest neighbor queries on uncertain moving object trajectories [J].Proceedings of the VLDB Endowment, 2013, 7(3): 205-216. [3] LU J, LU Y, CONG G.Reverse spatial and textualknearest neighbor search [C]// SIGMOD 2011: Proceedings of the 2011 ACM SIGMOD International Conference on Management of Data.New York: ACM, 2011: 349-360. [4] YANG S, CHEEMA M A, LIN X, et al.SLICE: reviving regions-based pruning for reverseknearest neighbors queries [C]// ICDE 2014: Proceedings of the 2014 IEEE 30th International Conference on Data Engineering.Washington, DC: IEEE Computer Society, 2014: 760-771. [5] WU W, YANG F, CHAN C-Y, et al.FINCH: evaluating reversek-nearest-neighbor queries on location data [J].Proceedings of the VLDB Endowment, 2008, 1(1): 1056-1067. [6] CHEEMA M A, LIN X, ZHANG W, et al.Influence zone: Efficiently processing reverseknearest neighbors queries [C]// Proceedings of the 2011 IEEE 27th International Conference on Data Engineering.Washington, DC: IEEE Computer Society, 2011: 577-588. [7] YIU M L, PAPADIAS D, MAMOULIS N, et al.Reverse nearest neighbors in large graphs [J].IEEE Transactions on Knowledge & Data Engineering, 2006, 18(4): 540-553. [8] SAFAR M, IBRAHIMI D, TANIAR D.Voronoi-based reverse nearest neighbor query processing on spatial networks [J].Multimedia Systems, 2009, 15(15): 295-308. [9] BORUTTA F, NASCIMENTO M A, NIEDERMAYER J, et al.Monochromatic RkNN queries in time-dependent road networks [C]// MobiGIS ’14: Proceedings of the 2014 ACM SIGSPATIAL International Workshop.New York: ACM, 2014: 26-33. [10] GAO Y, QIN X, ZHENG B, et al.Efficient reverse top-k boolean spatial keyword queries on road networks [J].IEEE Transactions on Knowledge & Data Engineering, 2015, 27(5):1205-1218. [11] LIAN X, CHEN L.Efficient processing of probabilistic reverse nearest neighbor queries over uncertain data [J].The VLDB Journal, 2009, 18(3): 787-808. [12] BERNECKER T, EMRICH T, KRIEGEL H-P, et al.Efficient probabilistic reverse nearest neighbor query processing on uncertain data [J].Proceedings of the VLDB Endowment, 2011, 4(10): 669-680. [13] YU G, GU Y, QIAO J, et al.Interval reverse nearest neighbor queries on uncertain data with Markov correlations [C]// ICDE ’13: Proceedings of the 2013 IEEE International Conference on Data Engineering.Washington, DC: IEEE Computer Society, 2013: 170-181. [14] EMRICH T, KRIEGEL H-P, MAMOULIS N, et al.Reverse-nearest neighbor queries on uncertain moving object trajectories [M]// DASFAA 2014: Proceedings of the 19th International Conference on Database Systems for Advanced Applications, LNCS 8422.Berlin: Springer-Verlag, 2014: 92-107. [15] JAMPANI R, XU F, WU M, et al.MCDB: a Monte Carlo approach to managing uncertain data[C]// SIGMOD ’08: Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data.New York: ACM, 2008: 687-700. This work is partially supported by the National Natural Science Foundation of China (61373036), the Program of Shanghai Subject Chief Scientist (15XD1503600). XU Wei, born in 1991, M.S.candidate.His research interests include spatial keyword query, data mining, LI Wengen, born in 1987, Ph.D.candidate.His research interests include spatial database, data mining. ZHANG Yichao, born in 1982, Ph.D., assistant professor.His research interests include complex network, data mining. GUAN Jihong, born in 1969, Ph.D., professor.Her research interests include spatial database, data mining. Probabilistic bichromatic reverse-kNN query on road network XU Wei, LI Wengen, ZHANG Yichao, GUAN Jihong* (DepartmentofComputerScienceandTechnology,TongjiUniversity,Shanghai201804,China) Considering the road network constraint and the uncertainty of moving object location, a new reverse-kNN query on road network termed Probabilistic Bichromatic Reverse-kNN (PBRkNN) was proposed to find a set of uncertain points and make the probability which thekNN of each uncertain point contains the given query point be greater than a specified threshold.Firstly, a basic algorithm called Probabilistic Eager (PE) was proposed, which used Dijkstra algorithm for pruning.Then, the Pre-compute Probabilistic Eager (PPE) algorithm which pre-computes thekNN for each point was proposed to improve the query efficiency.In addition, for further improving the query efficiency, the Pre-compute Probabilistic Eager External (PPEE) algorithm which used grid index to accelerate range query was proposed.The experimental results on the road networks of Beijing and California show that the proposed pre-computation strategies can help to efficiently process probabilistic bichromatic reverse-kNN queries on road networks. reverse-kNN query; road network; Dijkstra algorithm; uncertainty 2016- 08- 12; 2016- 09- 13。 国家自然科学基金资助项目(61373036);上海市优秀学术带头人计划项目(15XD1503600)。 徐伟(1991—),男,江苏淮安人,硕士研究生,CCF会员,主要研究方向:空间关键词查询、数据挖掘; 李文根(1987—),男,四川南充人,博士研究生,CCF会员,主要研究方向:空间数据库、数据挖掘; 张毅超(1982—),男,上海人,助理教授,博士,CCF会员,主要研究方向:复杂网络、数据挖掘; 关佶红(1969—),女,辽宁开原人,教授,博士生导师,博士,CCF高级会员,主要研究方向:空间数据库、数据挖掘。 1001- 9081(2017)02- 0341- 06 10.11772/j.issn.1001- 9081.2017.02.0341 TP311.13; TP392 A3 PPE算法和PPEE算法


4 实验结果与分析



5 结语
