基于文本挖掘技术的客服投诉工单自动分类探讨
2017-02-06张吉皓
李 颢,张吉皓
(1.上海邮电设计咨询研究院有限公司,上海 200092;2.中国电信集团公司客服运营支撑中心,上海 200040)
1 引言
在日常生产经营中,运营商每天都能获取几百TB的各类数据。这些数据日积月累,形成了一座巨大的“数据宝库”。借助传统的数据挖掘技术和工具,已经可以实现针对结构化数据的挖掘和分析,为生产经营活动提供准确、实时、有效的技术支持(如市场预测、业务预警、精准营销等)。而针对非结构化数据(如投诉内容等文本、图片等)的大量分析仍需要依靠人工配合开展,此外还缺少有效的方法和工具,从而容易造成大量数据沉淀在各个平台和系统中的状况,数据价值难以得到体现。在这种背景下,利用文本挖掘技术,充分挖掘出文本内容等非结构化数据背后所蕴含的信息,将有助于发挥出数据的价值,从而更好地服务于日常工作。
基于海量的客户投诉工单,借助大数据工具构建基于非结构化数据的文本分类模型,可实现投诉文本的自动分类应用。此外,利用热词可进一步挖掘投诉工单中具有普遍性,且客户关注度高的热点问题,及时获知用户对产品、业务和服务的感知,提炼体验主题。

表1 常见的开源文本分类工具
2 文本挖掘的定义及工具
文本挖掘是对于非结构化数据进行处理、分析及应用的技术的统称。一般来说,首先利用文本切分技术,抽取文本特征,将文本数据转化为能描述文本内容的结构化数据,然后利用聚类、分类和关联分析等数据挖掘技术,形成结构化文本,并根据该结构发现新的概念,获取相应的关系。目前在新闻媒体、电子商务等领域,文本挖掘技术已得到了广泛的应用[1]。
随着技术的发展,市面上出现了众多文本分类工具,常见的开源文本分类工具如表1所示。
3 文本分类的应用实践
本文将结合运营商的投诉工单,进行文本自动分类模型的构建以及应用探索。
3.1 文本分类应用的总体实施路径
总体而言,此次文本分类应用的实施路径分为标签设计、模型构建以及实例应用3个阶段,如图1所示。
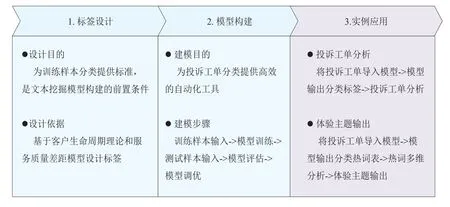
图1 文本挖掘及分类应用总体实施路径
首先基于客户生命周期以及服务质量差距模型设计投诉分类标签,然后将投诉工单样本打上相应的标签,形成模型构建所需的训练样本集,通过多次迭代优化,完成分类模型的构建。(注:文中涉及建模所用到的投诉工单为某运营商的“宽带服务”投诉工单,投诉工单量为5 757条,其中训练样本4 665条,测试样本1 092条。基于多次文本挖掘项目经验,为保证模型分类效果,每个分类的最小训练样本量为200个,此次文本挖掘对训练样本量进行了适度扩展)
后期将该模型部署上线,可用以辅助投诉工单的分析和体验主题的输出。
3.2 标签设计
投诉标签设计是为了便于后期分析,重新定义投诉原因的过程。从宽带服务的了解、购买、交付、使用、付费、求助和终止七大服务环节入手,聚焦用户感知与感知期望的差距,提炼并重新设计了12项分类标签,具体如表2所示。宽带服务分类标签定义如表3所示。
3.3 文本分类模型构建
(1)分类算法选择
选择朴素贝叶斯算法来实现对于给定投诉工单的分类。朴素贝叶斯算法具有算法简单、分类速度快、开发难度小、适应性强等特点,用通俗的语言可解释为:
1)对于一条待分类的投诉工单x,对其进行分词,假设该投诉工单有300个字,可分拆成100个分词。
2)标签体系的集合包含多个分类标签,本文中体验分类标签有12项,则分类标签为y1,y2,…,y12。
3)投诉工单内每个分词对应这12项体验分类标签各有一个概率,其概率即为分词的特征属性。将投诉工单所包含的100个分词对应于某一个分类标签y1的概率加总,得到投诉工单x对应于该分类标签y1的概率P(y1|x)。同理可以得到P(y2|x),…,P(y12|x)。
4)选择概率值最大的P所对应的那个标签y作为投诉工单所属的分类标签。
在实际应用的过程中,通常用TF-IDF(Term Frequency-inverse Document Frequency,词频-逆文档频率)权重来代表分词对分类的贡献度,近似地替代分词的分类概率[2-3]。
(2)分类模型构建
基于宽带投诉工单,通过选定的朴素贝叶斯算法构建分类模型,最终实现给定投诉工单的自动分类。整个模型构建分为模型训练以及测试两个步骤:
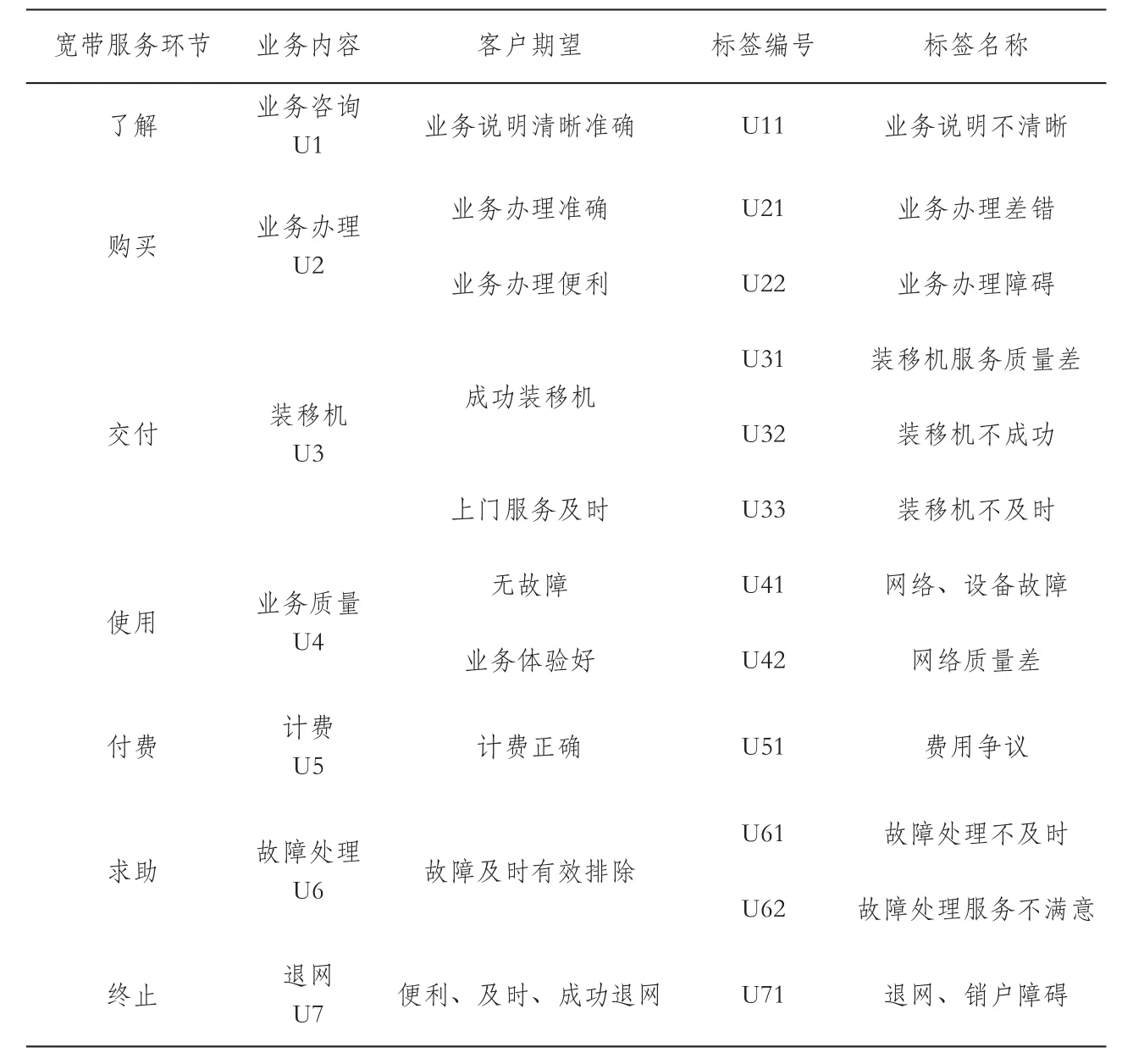
表2 宽带服务分类标签
首先,通过人工识别的方式,根据设定的标签体系分类,给2 545个投诉工单样本打上体验标签,形成训练集。运用textgrocery软件,对训练文本进行中文分词和文本预处理,然后基于朴素贝叶斯算法自动计算特征向量和分类贡献度(TF-IDF值),最终输出形成分类规则表。则得到共约64万条规则(53 297分词×12分类×1个TF-IDF值=639 564条规则),模型的初步构建完成[4]。模型训练流程如图2所示,分类规则示意如表4所示。
其次,将1 092条投诉工单的测试集(测试样本量与训练样本量之比一般在1:3到1:4之间,此次文本挖掘采用的测训比为1:4)导入模型,将模型分类结果与人工分类结果进行比对,初建模型的准确率为49%。

表3 宽带服务分类标签的详细定义
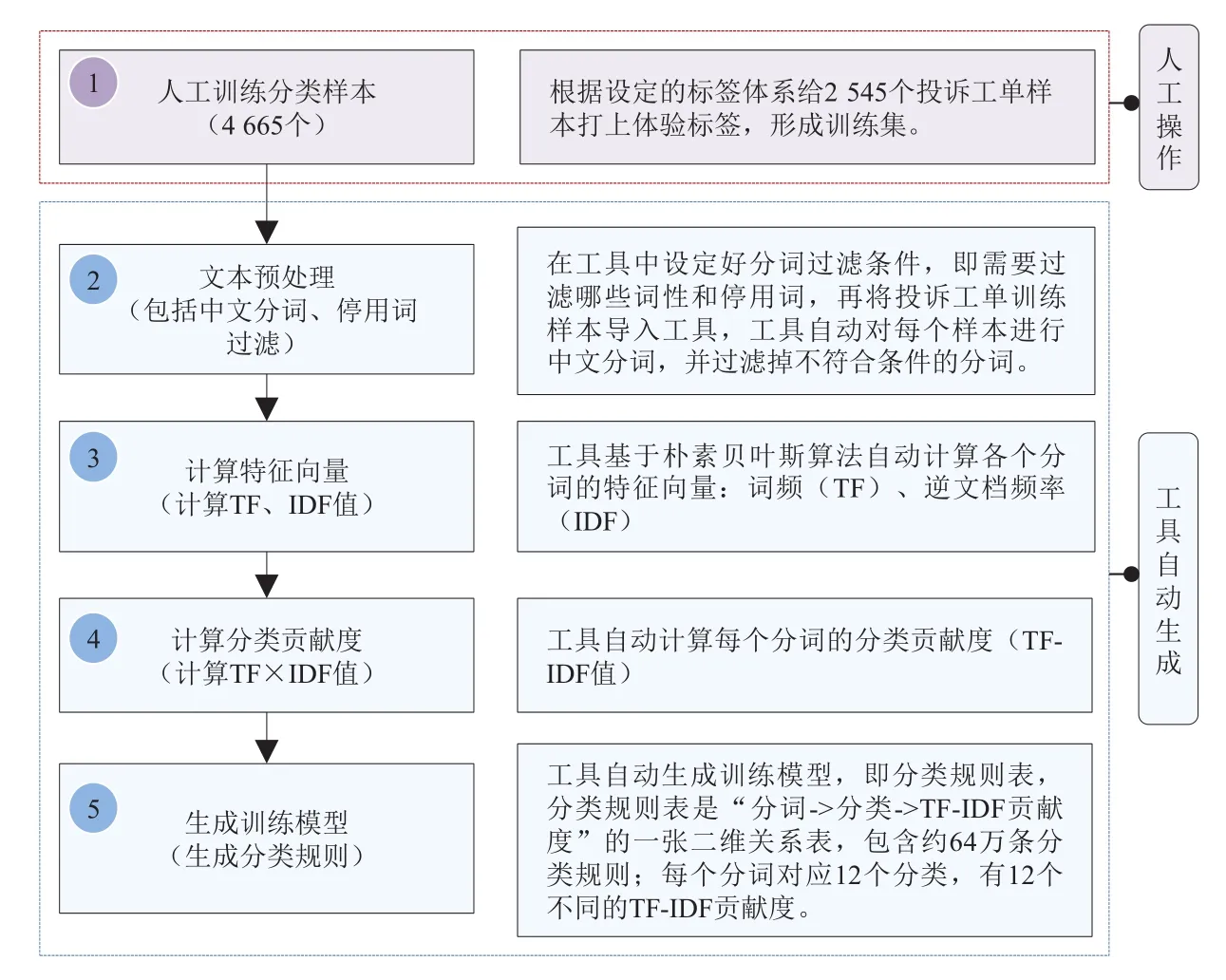
图2 模型训练流程
影响模型准确率的因素主要有3类:体验标签的质量、训练样本的质量和待预测文本的质量。
◆体验标签的质量:包括完整性、独立性和复杂性3个维度。
完整性:标签是否覆盖所有的文本,完整性越好,模型分类越准确;
独立性:分类之间语义逻辑不交叉,独立性越好,模型分类越准确;
复杂性:分类是否复杂,分类越简单,模型分类越准确。
◆训练样本的质量:包括准确性、规模性、完整性和平衡性4个维度。
准确性:人工训练样本分类越准确,模型分类越准确;
规模性:各分类的训练样本数量越多,模型分类越准确;
完整性:训练的文本是完整的文本,不存在文本截断现象,导致语义逻辑缺失;
平衡性:各分类的样本量越均衡,模型分类越准确。
◆待预测文本的质量:主要指差异性。
差异性:待预测文本与训练样本的分词差异越小,模型分类越准确。
为了进一步提升模型自动分类的准确性,采取了调整分类体系、扩充分类样本、增加停用词以及调整底层算法等方法。其中调整分类体系是为了保证体验标签的独立性,从而提升体验标签的质量。扩充分类样本是为了增加训练样本的规模,从而提升训练样本的质量。增加停用词库是通过减少无意义的分词,从而提升训练样本的质量,以减少对模型的干扰。调整底层算法是通过在原有分类之上增加分类层级,从而使得大类与大类之间、小类与小类之间的样本量更加均衡,从而提升训练样本的质量。
经过8次不同方面的调整优化,最终使模型准确率达到61%(具体调优过程如表5所示),但相较于其他文本挖掘模型,还有一定的提升空间[5-7]。
3.4 应用实例
在此基础上,还自主开发了文本挖掘应用工具,该工具目前已支持通过账号远程登录网页界面进行操作,可用于辅助投诉工单分析和体验主题输出。
(1)辅助投诉工单分析
通过分类模型输出给定分类下的投诉工单数量统计,如表6所示。一方面,可有效减少人工投入,另一方面实现了对分服务环节进行月度投诉量的监控。同时,在发现数据异常后,还可以通过分析该分类下的关键词,快速定位投诉原因。
(2)体验主题输出
根据分类标签和热点关键词的变化趋势发现新增投诉、异常投诉和高比例投诉,从而确定体验主题,具体操作步骤如图3所示。
4 结束语
本文结合现有的大数据以及语义分析技术,明确了总体实施路径,通过设计分类标签,探索并构建了文本挖掘模型,初步实现了基于客户投诉工单中的非结构化数据文本的自动分类应用。
但在对投诉工单进行挖掘的过程中,仍有一些问题值得研究和探讨,具体如下:
(1)现有模型的准确率仍有提升的空间
现有模型准确率为61%,仍具有一定的提升空间。可以在样本、工具和算法3个方面对模型进行优化。具体来说,在样本优化方面,增加某一分类下的训练样本的数量,进而提升模型对于这类分类下的文本识别能力,进而帮助提升整体的模型准确率。在工具优化方面,可以在textgrocery基础上继续进行二次开发[8]。在算法优化方面,可以尝试其他分类算法,如支持向量机(Support Vector Machine)算法应用于文本挖掘等[9]。
(2)模型具有快速复制的优势
现有模型所涉及的分类算法以及原理对于非结构化(文本)数据的自动分类具备一定的通用性,因此可以通过重新定义分类标准,制作训练及测试样本集,快速实现对于某一特定分类标准下的文本自动分
类。这将有助于最大程度地发挥出模型效能,为企业的提质增效提供有力的工具支撑,这是企业在人工智能落地应用的一次探索。

表6 2016年投诉工单自动分类结果
(3)基于客户投诉的文本挖掘应用可以进一步优化
目前,自主开发的文本挖掘应用功能相对单一,后续可将文本聚类、实体识别、情感识别等功能补充到现有的文本挖掘应用中,届时应用范围将扩展到舆情分析[10-11]、热点话题识别、自动摘要和趋势分析方面;同时,充分利用数据可视化技术,将文本分析结果通过标签云、关联关系、时间序列的形式进行呈现[12],提高将文本数据转化为价值的效率,更好地支撑企业运营。
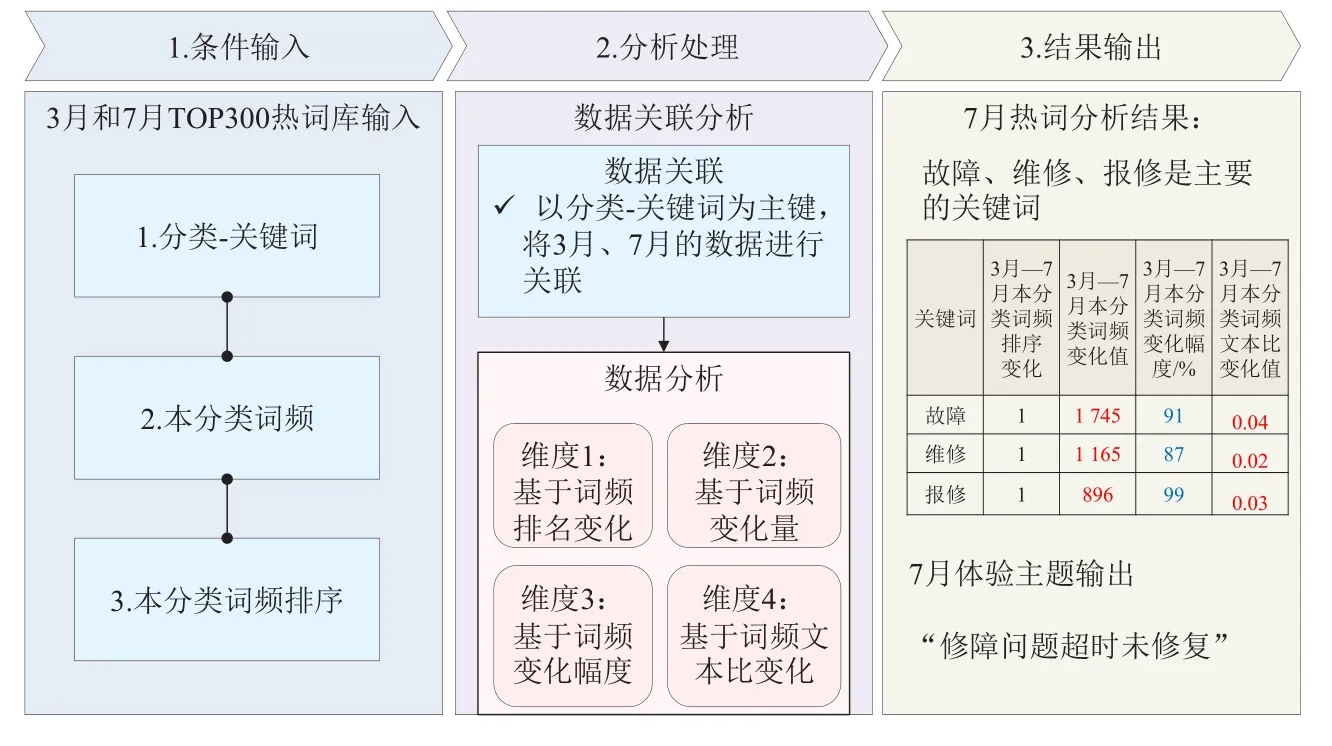
图3 体验主题输出流程
[1] 王国平,郭伟宸,汪若君. IBM SPSS Modeler数据与文本挖掘实战[M]. 北京: 清华大学出版社, 2014.
[2] 李丹. 基于朴素贝叶斯方法的中文文本分类研究[D]. 保定: 河北大学, 2011.
[3] 华秀丽,朱巧明,李培峰. 语义分析与词频统计相结合的中文文本相似度量方法研究[J]. 计算机应用研究,2012,29(3): 833-836.
[4] 刘怀亮,杜坤,秦春秀. 基于知网语义相似度的中文文本分类研究[J]. 现代图书情报技术, 2015,31(2): 39-44.
[5] 张键锋,王劲. 基于文本挖掘与神经网络的音乐风格分类建模方法[J]. 电信科学, 2015,31(7): 80-85.
[6] 叶明. 智能手机电子取证中文本分析的研究[D]. 武汉:武汉邮电科学研究院, 2014.
[7] 彭杰,石永革,高胜保. 基于对话内容的交互型文本会话主题挖掘[J].电信科学, 2016,32(9): 139-145.
[8] 张雯雯,许鑫. 文本挖掘工具述评[J]. 图书情报工作, 2012,56(8): 26-31.
[9] 崔建明,刘建明,廖周宇. 基于SVM算法的文本分类技术研究[J]. 计算机仿真, 2013,30(2): 299-302.
[10] 黄晓斌,赵超. 文本挖掘在网络舆情信息分析中的应用[J]. 情报科学, 2009,27(1): 94-99.
[11] 琚春华,鲍福光,戴俊彦. 一种融入公众情感投入分析的微博话题发现与细分方法[J]. 电信科学, 2016,32(7): 97-105.
[12] 袁海,陈康,陶彩霞,等. 基于中文文本的可视化技术研究[J]. 电信科学, 2014,30(4): 114-122. ★
