Heritrix主题爬虫设计
2016-12-13张亚凤郑山红
张亚凤,郑山红
(长春工业大学 计算机科学与工程学院,吉林 长春 130012)
Heritrix主题爬虫设计
张亚凤,郑山红*
(长春工业大学 计算机科学与工程学院,吉林 长春 130012)
通过扩展Heritrix相应组件来抓取特定网页,实现预定的抓取策略,并加入APHash算法对URL进行散列,达到了多线程抓取网页的目的,极大地提高了抓取数据的效率。
垂直搜索引擎;主题爬虫;Heritrix;APHash算法
0 引 言
近年来,现代信息技术和网络技术正以惊人的速度发展,Internet网络上的数据也呈指数级趋势增加。全球前几年网络搜索引擎仅仅包括几千万页的网页量,但现在它已经达到了惊人的数十亿页。数量的迅速增加带来了搜索服务的效率严重下降,查询的结果集也是大规模的,常常数以十万笔的数据,这些结果集里有大量冗余和无用信息,很难找到符合用户自身需求的信息。因此,需要改进现有的一般搜索引擎技术,垂直搜索引擎便在此时应运而生。
垂直搜索引擎是专门给某一特定领域、某一特定人群或某一特定需求提供的有一定价值的信息和有关服务。“专、精、深”是其显著的特点,且行业色彩鲜明[1]。它不同于一般的通用搜索引擎,无论是用于专业知识的查询,或是解决日常生活中的资讯,它的专业性是很清楚的,此时,通用搜索引擎不能实现快速且准确的检索,尤其是对专业知识或学科的某些区域,这些弊端比比皆是。因此,人们倾向于使用个性化、专业化的垂直搜索来找到您所需要的信息。
主题爬虫是垂直搜索引擎服务的关键技术和核心部分,它的优劣直接影响用户对所得信息的满意度,它将网页采集到本地服务器后,对该网页的主题相关度值进行计算,较低的将不被进一步处理而被丢弃[2]。优先搜集主题相关度高的网页是垂直搜索引擎一个显著的特点,在尽少耗费网络流量的情况下,尽可能地多发现、采集主题相关度高的网页。
1 Heritrix的架构及工作流程
1.1 Heritrix简介
Heritrix是一个完全开源的、由Java开发的优秀的可扩展的Web网络爬虫项目,它采用了模块化的设计,主要由一些核心类和插件模块组成。开发者可以利用Heritrix优良的可扩展性对它的插件模块进行扩展,来实现自己预期的抓取逻辑[3]。
1.2 Heritrix系统结构
Heritrix的系统框架如图1所示。
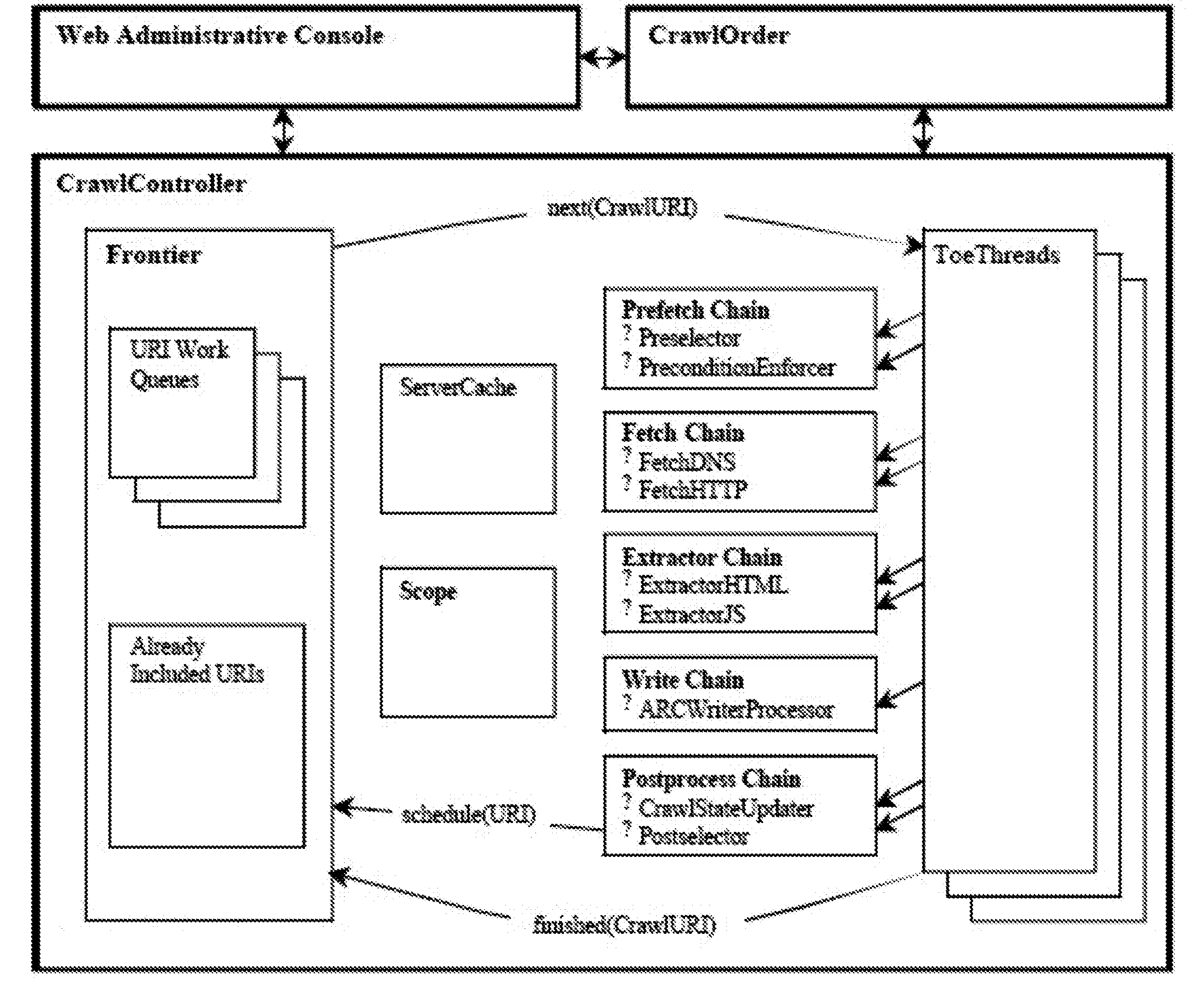
图1 Heritrix的系统框架
其主要模块及功能如下:
1)CrawlOrde:抓取任务的配置,它是抓取任务的起点,默认情况下通过配置order.xml文件对起始Urls、线程数等信息进行配置。
2)CrawlController:抓取的核心程序,控制着每次抓取工作的开始和结束。
3)Frontier:链接制造工厂,也可以把它当作一个调度器,首先提供了特定算法去处理网页中的URL地址,然后把处理后的地址送给处理线程,进行后续操作。
4)ToeThreads:这组线程才是实际的工作线程,每个线程处理一个URL,它们实现URL的爬行操作和一系列的后续操作,具体流程如图2所示。
2 面向特定主题的主题爬虫设计
2.1 为Heritrix定制自己的QueueAssignmentPolicy
Heritrix采用Berkeley DB建立链接队列。这些队列放置在BdbMultipleWorkQueues中时,总是先赋予一个Key,然后再把那些链接键值相同的放在一起,成为一个Queue(队列)[4]。在Heritrix中,是它的queue-assignment-policy为每个队列赋上Key值。Heritrix默认使用的queue-assignment-policy是HostnameQueueAssignmentPolicy,它继承QueueAssignmentPolicy抽象类,主要负责队列的分配策略。正像其名称所暗示的那样,它与Host名值来解决这个问题。换言之,也就是所有的相同的URL的Host名会被放置在同一队列的中间。
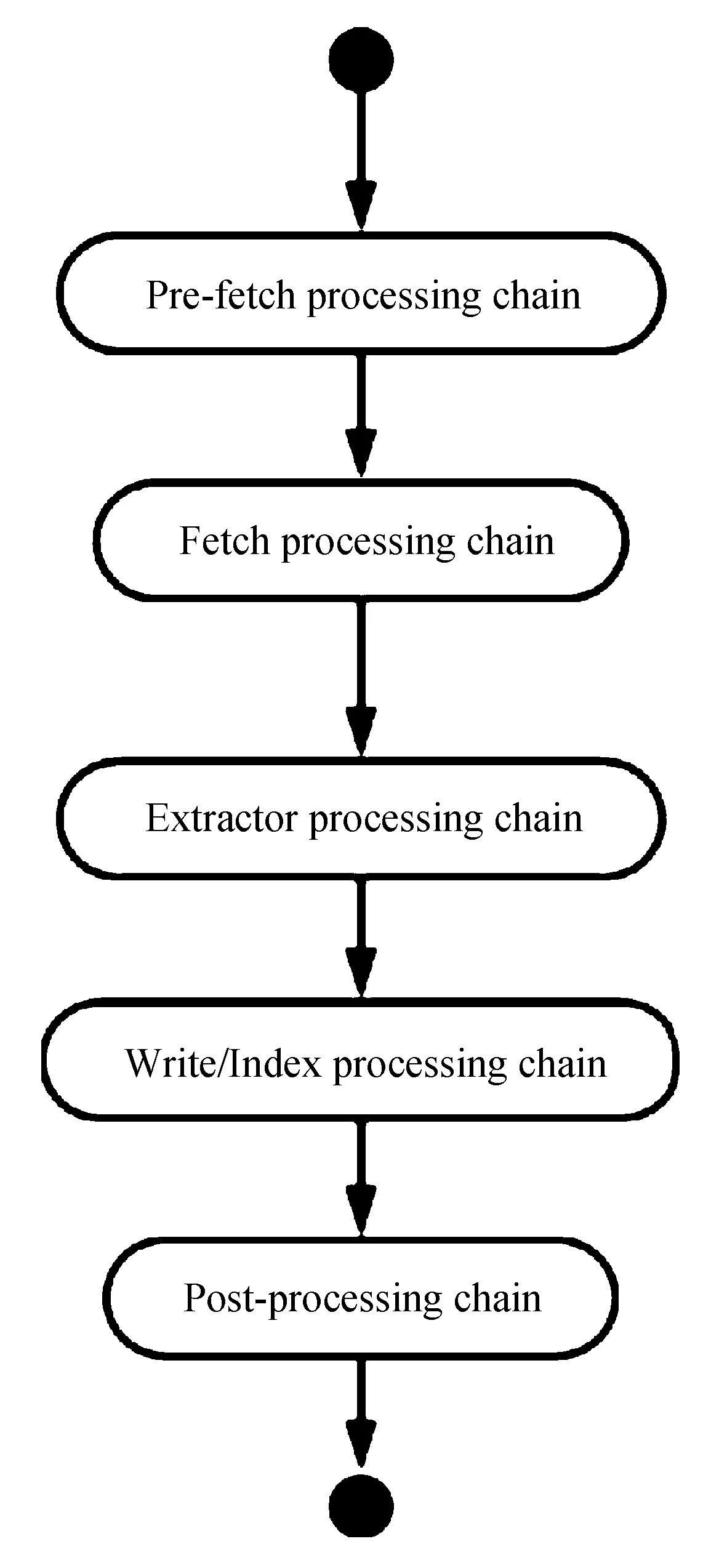
图2 heritrix处理一个url的流程
HostnameQueueAssignmentPolicy存在这样一个缺陷,对某个具体站点的网页抓取时,某一个队列的长度会出现极度长的现象,有的则是在排队等待中几乎是闲置的,这样就造成多线程抓取的效率极其低下。文中实验抓取对象为新方向体育用品购物网站,通过自定义QueueAssignmentPolicy来解决这个缺陷,这样也就改变了Key值的生成方式,从而所有的URL能够比较平均地散列到不同的队列中,从而改善了抓取效率。
在Heritrix中扩展queue-assignment-policy,通过继承包org.archive.crawler.frontier下的QueueAssignmentPolicy类,重写其getClassKey()方法。此方法先处理一个连接对象,再使用散列算法生成一个Key值,最后把相同Key值的链接放置在同一个队列[5]。常用字符串哈希算法有BKDRHash,APHash,DJBHash,JSHash,ELFHash,PJWHash等,文中使用APHash算法生成Key值。自定义的APHashQueueAssignmentPolicy类的关键代码如下:
public class APHashQueueAssignmentPolicy extends QueueAssignmentPolicy {
@Override
public String getClassKey(CrawlController controller,CandidateURI cauri) {
eturn this.APHash(cauri.getUURI().toString(),50) + "";
}
/**
* APHash算法
*/
public long APHash(String str,int number) {
long hash = 0;
for(int i = 0; i < str.length(); i++) {
hash ^= ((i & 1) == 0) ? ( (hash << 7) ^ str.charAt(i) ^ (hash >> 3)) :(~((hash << 11) ^ str.charAt(i) ^ (hash >> 5)));
}
long result = hash % number; //模number,即对应的线程数
return result;
}
}
还得通过配置APHashQueueAssignmentPolicy类才能正常工作,才能用来生成Key值。配置成功后,使用Heritrix抓取网页的时候,Heritrix就变成默认使用APHashQueueAssignmentPolicy来分配链接队列了。
2.2 扩展FrontierScheduler
Heritrix默认使用FrontierScheduler来抓取网页,它不能实现对特定网页内容进行抓取[6-7],因此,需要对FrontierScheduler进行扩展,才能使抓取策略控制在新方向体育网站下的体育用品。在MyHeritrix项目的包org.archive.crawler.postprocessor下新建类FrontierSchedulerForXfxty,它继承FrontierScheduler类,重写父类的schedule()方法,只有符合特定的URL才会加入到等待队列中。关键实现代码如下:
protected void schedule(CandidateURI caUri) {
String uri = caUri.toString();
//只抓取包含"xfx-ty"和"product"的URL,控制抓取范围在www.xfx-ty.com域名下且包含体育用品的URL
if(uri.contains("xfx-ty") && uri.contains("product")) {
getController().getFrontier().schedule(caUri);
}
}
3 实 验
本次实验开发环境使用MyEclipse 8.6开发工具,JDK 1.6和Heritrix 1.14.4平台进行开发;机器配置为:Win7系统,内存4 G,酷睿2.5 GHz,500 G硬盘,10/100 M以太网。
扩展后的Heritrix运行中的截图如图3所示。

图3 扩展后的Heritrix运行状态
图中显示的50个线程只有12个处在工作状态,这是由于只设置了一个种子地址,这也说明了加入APHash散列算法后,Heritrix可以更好地支持多线程,从而很大程度上提高了抓取效率。
抓取的部分体育用品页面截图如图4所示。
图4 抓取的部分体育用品页面
这些页面是使用php写的,页面中包含了具体体育用品的详细信息。
4 结 语
对于垂直搜索引擎,主题爬虫采集信息的效
率起着决定性的作用。垂直搜索引擎中只有加入设计优良的主题爬虫,才能提高查全率和准确率,才能给用户带来更优质的服务。开发者可以利用Heritrix其优良的可扩展性来扩展它的相应组件,实现自己期望的爬行策略[8]。
通过加入APHash散列算法扩展Heritrix中默认的QueueAssignmentPolicy策略,实现了在同一主机域名站点下的多线程抓取网页信息,极大地提高了采集信息的效率。
[1] 邵温.垂直搜索引擎技术的研究和应用[D].北京:北京工业大学,2009.
[2] 陈丛丛.主题爬虫搜索策略研究[D].济南:山东大学,2009.
[3] 东兴.垂直搜索引擎关键技术研究[D].杭州:浙江理工大学,2012.
[4] 朱敏,罗省贤.基于Heritrix的面向特定主题的聚焦爬虫研究[J].计算机技术与发展,2012(2):65-68.
[5] 刘育莲.手机产品垂直搜索引擎的设计与实现[D].西安:西安电子科技大学,2012.
[6] 刘高军,夏景隆.基于Heritrix的网络爬虫研究与应用[J].软件导刊,2013(5):123-125.
[7] 白万民,苏希乐.Heritrix在垂直搜索引擎中的应用[J].计算机时代,2011(9):7-9.
[8] 孔祥春,李义杰,郑凯明.垂直搜索引擎应用研究[J].计算机系统应用,2009(7):150-152.
Heritrix based theme crawler design
ZHANG Yafeng,ZHENG Shanhong*
(School of Computer Science & Engineering,Changchun University of Technology,Changchun 130012,China)
By extending related components of Heritrix to crawl a specific page,some predetermined crawling strategies can be realized. The APHash algorithm is introduced to hash the URL for multi-threaded web page crawling,so the efficiency of data capture is improved.
vertical search engine; theme crawler; Heritrix; APHash algorithm.
2016-03-01
张亚凤(1990-),男,汉族,河南平顶山人,长春工业大学硕士研究生,主要从事信息检索及搜索引擎方向研究,E-mail:fengyuzhe320@163.com. *通讯作者:郑山红(1970-),女,朝鲜族,吉林长春人,长春工业大学副教授,博士,主要从事智能系统与语义网方向研究,E-mail:1668277288@qq.com.
10.15923/j.cnki.cn22-1382/t.2016.5.19
TP 31
A
1674-1374(2016)05-0507-05
