基于Lucene和协同过滤算法的知识推送
2016-12-13唐东凯孙境棋刘泽豪
肖 巍,唐东凯,孙境棋,刘泽豪
(长春工业大学 计算机科学与工程学院,吉林 长春 130012)
基于Lucene和协同过滤算法的知识推送
肖 巍,唐东凯,孙境棋,刘泽豪
(长春工业大学 计算机科学与工程学院,吉林 长春 130012)
将Lucene检索技术、IKAnalyzer分词器以及Tika文本提取技术相结合进行智能文件检索及分类。然后根据用户的检索结果对文件关键字进行权值设置,用户关注度越高,则关键字权值越大。使用协同过滤算法根据用户查找的内容对用户关注度高的文件进行推送。
Lucene; IKAnalyzer; Tika; 协同过滤算法
0 引 言
互联网上的学术论文、期刊文献、专利数据库、网络媒体、社交平台(微信、微博、博客、论坛)等载体上蕴藏着大量的专家研究成果、学术观点、工作动态及最新言论等信息。在知识的不断增加过程中,由于知识的来源不同、用途不同、载体不同等,往往导致知识的时间链条错乱、关联知识无法有效检索、各类知识无法综合运用等问题的出现,伴随知识的持续积累,这种问题愈发突出。如何能够在快速有效地检索出所需知识的同时推送相关知识内容已经成为目前研究的重点。
1 智能知识检索(LUCENE+IKAnalyzer+TIKA)
智能检索采用Lucene搜索技术、IKAnalyzer分词器以及Tika文本提取三大技术相结合,提高了检索精度,节省了检索时间。Lucene是一个高性能的全文检索工具[1]。Lucene包含了两个主要的服务:索引和检索。
1.1 Tika文本提取
文本索引是Lucene重点构造的一个索引区域,为高性能内容查询而创建的知识库,并提供了丰富的API,可以与存储在索引中的内容交互,但是Lucene在创建索引时无法满足深入到文件内容中建立文件内容的索引[2-3]。
使用Tika文本提取技术对文件内容进行索引。当一个文件传到Tika检测文件类型时,一旦文档类型是已知的,从解析器库中选择合适的解析器解析文件内容,提取文本。通过使用Tika文本提取技术,Lucene就可以对文件里面的内容创建索引,提高了检索的精度。
1.2 检索过程
Lucene技术中存在着大量的检索方式,可以进行精确搜索以及模糊搜索[4-5]。采用Lucene中的BoolenQuery()为整体框架,通过向其中传入BooleanClause.Occur.MUST,BooleanClause.Occur.SHOULD,BooleanClause.Occur.MUST_NOT等参数,控制搜索结果中是否包含所输入的关键字,同时在BoolenQuery()中嵌入TermQuery()搜索,根据选择的范围进行精确搜索,例如文章的标题、作者、内容等。BoolenQuery()中又嵌入了FuzzyQuery(),选择模糊搜索时,通过调节模糊的程度,自动向FuzzyQuery()中传递两个参数,分别控制搜索关键字的至少匹配字数和文字间的间隔,从而实现模糊搜索。在BoolenQuery()中加入了TermRangeQuery(),通过向其中传入上限及下限两个数值来控制搜索某一区间的文件,如文件大小、日期等。
1.3 IKAnalyzer分词器
Lucene中自带了多种分词器,但是对于中文来说效果并不是很好[6]。WhitespaceAnalyzer仅仅是去除空格,对字符没有lowcase化,不支持中文,并且不对生成的词汇单元进行其他规范化处理;SimpleAnalyzer会去掉数字类型的字符;StopAnalyzer不支持中文。基于上述问题,选择IKAnalyzer分词器对中文分词效果比较好。具体如下:
IKAnalyzer分词器采用了特有的“正向迭代最细粒度切分算法”,具有60万字/s的高速处理能力;采用了多子处理器分析模式,支持中文等多种分词处理;支持用户词典扩展定义。针对Lucene全文检索优化的查询分析器IKQueryParser;采用歧义分析算法优化查询关键字的搜索排列组合,能极大地提高Lucene检索的准确率。
1.4 知识图谱
对所有知识进行分类,根据不同分类画出知识图谱,如图1所示。
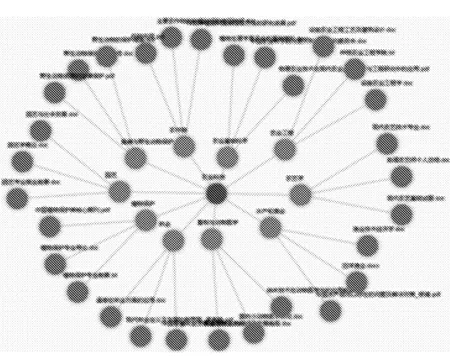
图1 知识图谱
根据用户的检索结果对文件关键字进行权值设置,用户关注度越高,则关键字权值越大。在用户检索某一关键字时,先根据知识分类在该领域内判断,然后再根据关键字的用户关注度进行推送。
2 协同过滤算法
协同过滤算法是推送系统领域最著名的算法[7-8]。简单来说,就是当一个用户A需要个性化推送时,先找到和他兴趣相似的用户群体G,然后把G关注的、并且A没有关注过的知识推送给A[9-10]。
可以将该算法分为两个步骤进行:
1)发现兴趣相似用户。使用余弦相似度计算两个用户之间的相似度。设N(u)为用户u关注的知识集合,N(v)为用户v关注的知识集合,那么u和v的相似度可以用下式计算:
(1)
假设目前共用4个用户A、B、C、D;共有5条知识a、b、c、d、e。用户与知识的关系(用户关注知识)如下:
A:abc
B:ac
C:be
D:cde
为了能更好地计算用户之间的相似度,需要建立“知识-用户”的倒排:
a:AB
b:AC
c:BD
d:AD
e:CD
然后对于每条知识,关注他的用户两两之间相同知识加1。例如关注知识a的用户有A和B,那么在矩阵中他们两两加1,即
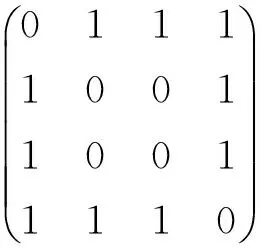
计算用户两两之间的相似度,上面的矩阵仅仅代表公式的分子部分。整体矩阵表示为:
计算所有用户的相似度,找到与目标用户兴趣相似的用户集合。
2)推荐知识。首先需要从矩阵中找出与目标用户u最相似的K个用户,用集合S(u,K)表示,将S中用户关注的知识全部提取出来,并去除u已经关注的知识。对于每个知识i,用户u对它感兴趣的程度按下式计算:
(2)
式中:rvi——用户v对i的关注程度。
假设现在要给A推荐知识,选取K(K=3)个相似用户,相似用户则是B、C、D,那么他们关注过并且A没有关注过的知识有c、e,分别计算p(A,c)和p(A,e):
得出用户A对c和e的关注程度一样,根据得分排序,找出K个与目标用户最相似的邻居。
在这些邻居关注的知识中,根据邻居与用户的远近程度算出每一条知识的推荐度。根据每一条知识的推荐度高低给目标用户推送知识。
3 实验结果
使用30万条数据对Lucene+IKanalyzer+Tika和Lucene检索的准确度和速度进行测试,测试结果见表1。

表1 检索准确度及速度结果
使用30万条数据对检索后进行推送和未经过检索处理进行推送测试,测试结果见表2。

表2 推送准确度结果 %
实验结果表明,使用Lucene+IKanalyzer+Tika三种技术比使用Lucene的准确度更高,速度更快。检索后使用协同过滤算法进行推送比不进行检索使用协同过滤推送的准确率高。
4 结 语
使用Lucene检索技术、IKAnalyzer分词器以及Tika文本提取三种技术相结合的方式进行智能检索并对文件进行分类,分类后根据用户的检索结果对文件关键字进行权值设置,用户关注度越高,则关键字权值越大。实验结果表明,使用三种技术结合比只使用Lucene一种检索速度更快,准确度更高。基于三种技术结合检索后的结果,并根据用户查找的内容和知识的关注度,使用协同过滤算法进行推荐,推荐的结果更满足用户的需求。
[1] 李永春,丁华福.Lucene的全文检索的研究与应用[J].计算机技术与发展,2010,20(2):12-15.
[2] 郑榕增,林世平.基于Lucene的中文倒排索引技术的研究[J].计算机技术与发展,2010,20(3):80-83.
[3] 王欢,孙瑞志.基于领域本体和Lucene的语义检索系统研究[J].计算机应用,2010,30(6):1655-1657.
[4] 高文举,李晓伟,孙春燕,等.基于全文检索Apache Lucene引擎的原理与流程研究[J].长春工业大学学报:自然科学版,2008,29(4):424-427.
[5] 张俊,李鲁群,周熔.基于Lucene的搜索引擎的研究与应用[J].计算机技术与发展,2013,23(6):230-232.
[6] 义天鹏,陈启安.基于Lucene的中文分析器分词性能比较研究[J].计算机工程,2012,38(22):279-282.
[7] Zhao X,Niu Z,Chen W. Opinion-based collaborative filtering to solve popularity bias in recommender systems[C]//International Conference on Database and Expert Systems Applications. Springer Berlin Heidelberg,2013:426-433.
[8] Yoshida T,Irie G,Satou T,et al. Improving item recommendation based on social tag ranking[C]//International Conference on Multimedia Modeling. Berlin:Springer Berlin Heidelberg,2012:161-172.
[9] 孙光福,吴乐,刘淇,等.基于时序行为的协同过滤推荐算法[J].软件学报,2013,24(11):2721-2733.
[10] 刘青文.基于协同过滤的推荐算法研究[D].合肥:中国科技大学,2013.
Knowledge push based on Lucene and collaborative filtering algorithm
XIAO Wei,TANG Dongkai,SUN Jingqi,LIU Zehao
(School of Computer Science & Engineering,Changchun University of Technology,Changchun 130012,China)
Combing Luceneindexing with IKAnalyzer and Tika,intelligent document retrieval and classification is realized. The document keyword weight is setaccording to the classification. The higher the user attention degree,the greater the weight of the keywords. With the collaborative filtering algorithm,the knowledge with more attention will be pushed forward.
Lucene; IKAnalyzer; Tika; collaborative filtering algorithm.
2016-06-20
国家自然科学基金资助项目(61303132)
肖 巍(1980-),女,汉族,吉林长春人,长春工业大学讲师,硕士,主要从事数据挖掘与人工智能方向研究,E-mail:xiaowei@ccut.edu.cn.
10.15923/j.cnki.cn22-1382/t.2016.5.18
TP 316
A
1674-1374(2016)05-0503-04
