纪念我的恩师沃古瓦教授
2016-12-03冯志伟


1985年9月30日,我突然接到法国格勒诺布尔大学同事的电报(当时电子邮件还不普及,也没有微信),我的导师沃古瓦(Bernard Vauquois)教授不幸患白血病去世,时年56岁。这个晴天霹雳把我轰得大脑都麻木了。
沃古瓦身体健康,我在法国学习时曾和他一起去滑雪,他的滑雪技术极为高超,滑起来像燕子一样地在白雪皑皑的高山上飞,他还这么年轻,怎么就去世了呢?我简直不敢相信这个噩耗。
后来我才知道,沃古瓦在1985年初到马来西亚槟榔大学研制机器翻译系统,他亲临第一线参与编程,日夜工作,积劳成疾,1985年8月只好回法国休息,但几天后就与世长辞。
今天是沃古瓦教授去世31年的日子,我特地写下这篇文章,以此作为对我的恩师的追念。
沃古瓦(1929-1985)
沃古瓦是法国数学家、物理学家、天文学家、计算机科学家和计算语言学家,于1929年6月14日生于法国[1]。
沃古瓦天资聪颖,早年学习数学、物理学和天文学,于1952年至1958年在法国国家科研中心(CNRS)所属的默东(Meudon)天文台天体物理学研究所工作。
从1957年开始,他的研究兴趣逐渐转向了物理学的应用方面,开始关注当时刚刚兴起的电子计算机的新技术,从电子计算机的角度来研究物理学问题,并在天体物理学研究所给物理学家们讲授电子计算机程序设计课程。沃古瓦对于天体物理学和电子计算机的双重爱好反映在他当时发表的物理学论文中。此后,他的研究兴趣逐渐地从天体物理学转向了计算机科学。
1960年,沃古瓦刚满31岁就成为了法国格勒诺布尔理科医科大学计算机科学系教授,他与该大学的昆茨满(Jean Kuntzmann,法国)教授和伽斯提讷(No?l Gastinel,法国)教授一起开创了该大学的计算机科学研究。在这个时期,他同时还参与了国际上对于算法语言ALGOL60的研制工作,于1963年与巴库斯(John W.Backus,美国)和瑙尔(Peter Naur,美国)等学者合作发表了《关于算法语言ALGOL60的报告》(1960)和《关于算法语言ALGOL60的修订报告》(1963),这两个报告是关于计算机程序语言研究的奠基性文献[2]。沃古瓦是计算机高级程序设计语言的开创者之一。不久,他的兴趣就从程序设计语言转到了更加复杂的自然语言方面,他立志要用计算机来处理人类的自然语言,造福人类。
为了研究自然语言的计算机处理,沃古瓦于1960年在格勒诺布尔大学建立了自动翻译研究中心(法文:Centre d'?tude pour la Traduction Automatique,简称CETA),这个中心后来改名为自动翻译研究组(法文:Groupe d'?tude pour la Traduction Automatique,简称GETA),现名叫作自动翻译与语言语音自动处理研究组(法文:Groupe d'?tude pour la Traduction Automatique et le Traitment Automatique de Langue et Parole,简称GETALP)。这个研究组属于格勒诺布尔信息实验室(法文:Laboratoire dinformatique de Grenoble),其目的在于使用计算机技术来克服人类的语言障碍,突破人类的语言藩篱。从此,沃古瓦便全身心地投入了自然语言计算机处理的研究。
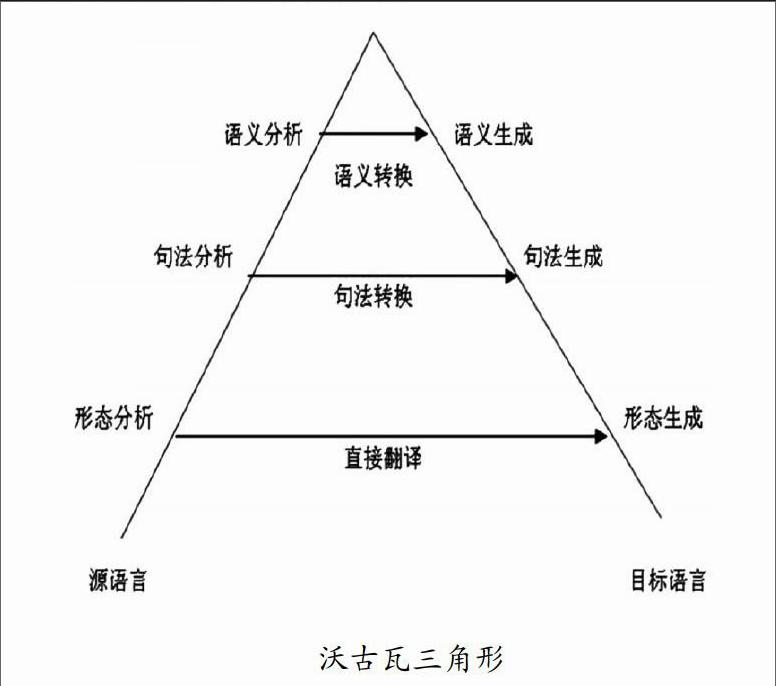
在此期间,沃古瓦非常关注国际上自动翻译的研究,在访问了美国等国家的一些自动翻译研究中心之后,他认为这些自动翻译系统的设计思想比较落后,理论基础比较单薄,他把这些系统称为第一代自动翻译(first generation of automatic translation)系统,而他则要研制第二代自动翻译(second generation of automatic translation)系统。他明确指出,第二代自动翻译系统的研制应当另辟蹊径,应当建立在形式语言和形式语法理论的基础之上,于是他提出了“枢轴语言”(pivot language)的理论,主张在自动翻译中按照“分析-转换-生成”的步骤分层次地进行源语言的分析、源语言-目标语言的转换、目标语言的生成,他还提出了自动翻译三角形来描述自动翻译的全过程,这种机器翻译三角形后来叫作“沃古瓦三角形”(Vauquois triangle)。沃古瓦三角形又叫作机器翻译金字塔(pyramid of machine translation)。如下图所示:
沃古瓦三角形
在“沃古瓦三角形”中,机器翻译从源语言开始,首先进行源语言形态分析,接着进行源语言句法分析,然后进行源语言语义分析,分析完成后就进行目标语生成,首先进行目标语语义生成,接着进行目标语句法生成,然后进行目标语形态生成,产生出目标语言。“沃古瓦三角形”的顶端是中间语言(interlingua),这是独立于源语言和目标语言规范的语义表达形式。
在“沃古瓦三角形”中,如果从源语言出发,经过形态分析就直接进行目标语的形态生成,产生出目标语言,这样的方法叫作直接翻译方法(direct approach);如果从源语言出发,经过源语言形态分析和源语言句法分析,然后在句法层面进行源语言和目标语的句法转换,再进行目标语的句法生成和形态生成,最后产生出目标语言,这样的方法叫作句法转换翻译方法(syntactic transfer approach);如果从源语言出发,经过源语言形态分析和源语言句法分析,再进行源语言语义分析,然后在语义层面进行源语言和目标语的语义转换,再进行目标语的语义生成、句法生成和形态生成,最后产生出目标语言,这样的方法叫作语义转换翻译方法(semantic transfer approach);如果从源语言出发,经过源语言的形态分析、句法分析和语义分析,一直分析到“沃古瓦三角形”的顶端,得到源语言的中间语言表示,然后从中间语言表示出发,经过语义生成、句法生成和形态生成,最后产生出目标语言,这样的方法叫作中间语言翻译方法(interlingua approach)。endprint
在直接翻译方法中,源语言文本中的词是一个接一个地进行处理的,这种方法要使用一部较大的双语词典,词典中的每一个条目相当于翻译每一个词的小程序。在转换翻译方法中,首先对输入文本进行解析,然后利用规则将源语言的解析结果转换到目标语言的解析结果,再利用这个解析结果得到目标语言句子。在中间语言翻译方法中,首先对源语言文本进行分析,得到抽象的意义表示,这种表示形式称为中间语言(interlingua),目标语言句子要根据这种中间表示来生成。
从“沃古瓦三角形”中可以看出,从直接翻译方法到转换翻译方法到中间语言翻译方法,对语言的分析程度不断加深,在目标语言的另一端,对应的层次是对语言的生成程度不断提高。此外,“沃古瓦三角形”还表明了不同方法对转换知识的依赖程度。在直接翻译方法中,需要大量的转换知识(对每个词来说,几乎所有的翻译知识都是转换知识)。在转换翻译方法中,转换规则仅用于句法分析树或者是语义角色(thematic role)。在中间语言翻译方法中,不需要特定的转换知识。随着三角形的斜边的上升,所需要的转换知识程度递减,到了三角形顶端,就不需要进行转换了。
1962年到1971年期间,沃古瓦领导自动翻译研究中心,开发了俄-法自动翻译系统,达到了实用化的水平,国际领先。
经过多年的自动翻译实践,沃古瓦清楚地认识到自动翻译研究中的陈述式方法和中间语言方法的缺陷,因而他采用启发式程序设计技术,开发了语言处理程序设计专用语言(法文:Langages Spécialisés pour la Programmation Linguistique,简称LSPL),并用这种专用语言建立了自动翻译软件系统ARIANE-78。
这个软件系统分为ATEF,ROBRA,TRANSF和SYGMOR四个部分。语言工作者可以利用这个软件来描述自然语言的各种规则。其中,ATEF是一个非确定性的有限状态转换器,用于原语形态分析,它的程序接收原语文本作为输入,并提供出该文本中每个词的形态解释作为输出;ROBRA是一个树形图转换器,它的程序接收源语言形态分析的结果作为输入,借助语法规则对此进行运算,输出能表示句子结构的树形图;ROBRA还可以按同样的方式实现源语言到目标语言的结构转换和目标语言的句法生成;TRANSF可借助双语词典实现源语言到目标语言的词汇转换;SYGMOR是一个确定性的树—链转换器,它接收目标语言句法生成的结果作为输入,并以字符链的形式提供出目标语言的译文。
沃古瓦的思维敏捷,他每接受一个研究课题,都会提出一种新的概念和方法。1974年,他提出了“多层次描述程序”(法文:descripteurs de structures multiniveaux),试图把自动翻译的研究层次从短语层次单位提升到比短语更高的层次单位。他的这种思想成为格勒诺布尔大学GETA开发自动翻译系统的理论基石。1982年至1983年间,在研究法国自动翻译国家课题ESOPE的过程中,他又提出了“静态语法”(法文:grammaire statique)这一创新性概念。
沃古瓦是计算语言学领域的知名学者。早在1963年,他就担任了法国国家科研中心(法文:Centre National de la Recherche Scientifique,简称CNRS)的普通语言学、现代语言和比较文学(法文:Linguistique générale, langues moderne et littérature comparée)分部的委员,1969年,他又担任CNRS的普通语言学、外国语言文学(法文:Linguistique générale,langues et littératures étrangères)分部的委员。1965年,他担任语言自动处理学会(法文:Association pour le traitement automatique des langues,简称ATALA)的副主席,1966年至1971年间担任ATALA的主席。1965年,沃古瓦主持成立了计算语言学国际委员会(International Committee on Computational Linguistics,简称ICCL),成为ICCL的创始人。他还组织召开国际计算语言学会议COLING,从1965年到1984年担任COLING主席。沃古瓦主持召开的历届COLING会议如下:
·1965 纽约(New York)
·1967 格勒诺布尔(Grenoble)
·1969 斯德哥尔摩(Stockholm)
·1971 德布勒森(Debrecen)
·1973 比萨(Pisa)
·1976 渥太华(Ottawa)
·1978 卑尔根(Bergen)
·1980 东京(Tokyo)
·1982 布拉格(Prague)
·1984 斯坦福(Stanford)
至今COLING已经召开了26届,成为最具权威性的、顶级的国际计算语言学会议。沃古瓦对COLING有开创之功,他功不可没。
在计算语言学研究中,沃古瓦与加拿大、美国、俄罗斯、捷克、日本、中国、马来西亚、泰国等国家的学者都建立了密切的联系,他经常到这些国家讲学和交流。
沃古瓦重视计算语言学跨学科人才的培养,他先后培养了布瓦戴(Ch.Boitet,法国)、辻井润一(Tsujii Junichi,日本)等兼通语言学和计算机科学的新一代计算语言学家。
1985年9月30日,沃古瓦病逝于法国,年仅56岁。
沃古瓦的主要著作有:《在机器翻译中的识别转换算法与形式语法概览》(1968),《语言的自动翻译》(1970),《自动翻译的模型》(1971),《GETA的自动翻译方法:与其他方法相比较》(1985),《格勒诺布尔大学的自动翻译》(1985)。endprint
沃古瓦是我的导师,是我研究计算语言学的引路人。
1978年我由文科改学理科,考入中国科学技术大学研究生院,接着被选送到法国格勒诺布尔理科医科大学应用数学研究所(法文:Institut Mathematique Appliquée de Grenoble,简称IMAG)自动翻译中心(GETA)学习,师从沃古瓦教授,专门研究自动翻译和数理语言学问题。沃古瓦教授是国际计算语言学委员会的创始人,是当时国际计算语言学的领军人物,他领导的GETA在机器翻译的理论和实践上都做出了出色的成绩,我在GETA良好的学习环境中,可以了解到机器翻译发展的最新情况,可以学习到当代机器翻译最前沿的技术。我本人喜欢数学,而沃古瓦教授是数学家,我们都深知自然语言的形式理论对于构建机器翻译系统的重要性。
在法国留学期间,我的主要工作是进行汉语与不同外语的机器翻译研究。开始时,我使用的自然语言形式理论是乔姆斯基(Chomsky)的短语结构语法,我试图使用短语结构语法来进行汉语的自动分析。早在1957年,我就接触到乔姆斯基的形式语言理论,对于乔姆斯基的理论,特别是对于这种理论的数学原理,我是有深入了解的。乔姆斯基根据形式语法的原理,提出了短语结构语法作为自然语言形式描述的一种手段,这种语法在自然语言处理中得到了广泛的应用。国内外的许多机器翻译系统都采用乔姆斯基的短语结构语法作为系统设计的基本理论依据。根据乔姆斯基的短语结构语法,表示句子结构的树形图中的每一个结点只有一个相应的标记,结点与标记之间的这种关系是一种单值标记函数的关系。这种单值标记函数表示的语言特征是十分有限的,因而在机器翻译中进行汉语的自动分析时,会出现大量的歧义问题,难以区分句法结构相同而语义结构不同的汉语句子,这种分析法是短语结构语法在分析汉语时的一个致命的缺点。
当时我在法国研制开发机器翻译系统的实践中,就敏锐地认识到短语结构语法的这种致命缺点。我试图根据短语结构语法来编写汉语分析程序,但是困难重重,步履维艰,屡遭失败。
1980年夏天的一个早上,沃古瓦教授与我讨论汉语自动分析的问题。我坦率地向沃古瓦教授说:“乔姆斯基的短语结构语法对于法语和英语的分析可能没有多大问题,可是,用这种语法来分析汉语,几乎寸步难行。”
沃古瓦教授用好奇的目光看着我,他希望我进一步阐述自己的看法。
我举例对沃古瓦教授作了如下的说明:
在汉语中可以说“点心吃了”,实际上是“点心被吃了”,但汉语中一般不用“被”字;汉语中还可以说“张三吃了”,实际上是“张三把点心吃了”。“张三”是个名词短语NP(Noun Phrase),“点心”也是个“NP”,“吃了”是个动词短语VP(Verb Phrase)。这两个句子的规则都是:“SNP+VP”,其中,S(Sentence)表示句子,它们的层次相同,词序相同,词性也相同,但它们却有截然不同的含义,一个是被动句,一个是主动句。我们怎么来解释这样的差异呢?如果我们使用乔姆斯基的短语结构语法,用计算机来分析这两个不同的句子,计算机最后做出来的肯定是一样的树形图,它们的差别只是在叶子结点上的词不一样,整个树形图的上层都是同样的“SNP+VP”,这样在结构上相同的句子为什么会有不同的语义解释,从而产生不同的含义呢?使用短语结构语法显然是解释不了的,而中文里到处都是这样的句子,因为中文里的被动关系有不同的表示方法,有时主动和被动在形式上没有明显的区别,可以从句子的上下文和意念上来加以区分。在这种进退两难的局面下,唯一的出路就是根据汉语语法的特点改进乔姆斯基的短语结构语法,使用一种新的方法来描述汉语。
沃古瓦教授耐心地听完了我的说明,他从沙发上站起来惊叹地说:“汉语真是一种langue terrible(法语:糟糕的语言)。”他说:“哪种语言能够不分主动和被动,人吃了和被人吃了怎么能是一样?怎么这么乱?”
我笑着向沃古瓦教授解释道:其实中国人一点儿也不感觉到乱,我们中国人在说话时是分辨得很清楚的,因为我们知道在一般情况下,人是不能被吃的。所以“小王吃了”的语义不会是“小王被吃了”,而“点心”不吃东西,所以“点心吃了”必定是“点心被吃了”。汉语是靠词汇的固有语义来解决语法问题的,但是对于你们法国人来讲,并不存在这样的问题。所以,我们不能按照法语的思考方法来处理汉语的问题,我们必须另辟蹊径!
沃古瓦教授是一个知识广博、眼界开阔的学者,他鼓励我沿着这个思路继续探索。他对我说:“乔姆斯基的短语结构语法也不一定永远正确嘛!”
在告别时,沃古瓦教授兴奋地对我说:“我相信,你一定能找出一种汉语自动分析的新方法。”
这次和沃古瓦教授的谈话使我深刻地认识到,乔姆斯基的短语结构语法在汉语自动分析中确实出现了极大的困难。这种困难甚至连沃古瓦教授这样世界第一流的计算语言学家也承认了。作为中国的科学工作者,我必须想出一种新的办法,来克服短语结构语法的缺点。不然,我正在进行的汉语自动分析就很难搞下去了。
这一天夜里我很不平静,翻来覆去总在思考这个问题。第二天清早,我走进沃古瓦教授的办公室,明确地向沃古瓦教授提出:我们正面临一个新的挑战,我们必须要思考一种新的语法理论来解决这个问题。沃古瓦教授完全同意我的意见,他进一步鼓励我探索新的理论和方法来解决汉语自动分析中出现的这个问题。
在沃古瓦教授的鼓励下,我对这个问题反复进行了思考。我观察到:“小王吃了”和“点心吃了”这两个貌似相同的句子在词汇的语义上有很大的不同,“小王”在语义上是一个“人”,在一般情况下,“人”是“吃了”这个行为的主动者,而“点心”在语义上是“食品”,在一般情况下,“食品”是“吃了”的被动者,是“吃了”的对象。在短语结构规则“SNP+VP”中,或许可以不把“NP”看成一个不可分割的单元,而把“NP”进一步加以分割,使用若干个特征来代替“NP”这个单一的特征。例如:在“小王吃了”中,我们把“NP”分解为“NP|人”两个特征,在“点心吃了”中,我们把“NP”分解为“NP|食品”两个特征,这样一来,就有可能在计算机上把它们分解开来了。在计算机处理语言时,特征也就是“标记”,我认为,如果我们使用“多标记”来代替短语结构语法中的“单标记”,就有可能大大地提高短语结构语法描述语言的能力,我们就可以使用改进后的这种语法来描述汉语,实现汉语的自动分析。这就是我提出的关于“多标记”(multiple-label)的最初设想。endprint
我对于短语结构语法的另一个改进是使用多叉树代替短语结构语法的二叉树。乔姆斯基曾经提出“乔姆斯基范式”,他认为自然语言的结构具有二分的特性,因此他主张在自然语言处理中使用“二叉树”(binary-tree)。我则认为,在汉语中存在着“兼语式”和“连动式”等特殊句式,它们都不具备二分的特性,因此,我主张使用“多叉树”(multiple-branched tree)来代替“二叉树”,从而提高短语结构语法描述汉语的能力。例如:“请小王吃饭”是一个兼语式的句子,其中的“小王”作前一个动词“请”的宾语,又作后一个动词“吃饭”的主语,在计算机处理时,究竟是分析为“请/小王吃饭”,还是“请小王/吃饭”,我们将处于进退维谷的境地。如果我们采取三分,把这个句子分析为“请/小王/吃饭”,可以避免分析树的交叉,得到唯一的分析结果。沃古瓦教授对我的多叉树设想也给予鼓励,表示赞同。
经过在计算机上编写程序进行潜心的钻研和反复的试验,在沃古瓦教授的指导下,我提出了“多叉多标记树模型”(Multiple-labeled and Multiple-branched Tree Model,简称MMT模型)。在MMT模型中,采用多值标记函数来代替短语结构语法的单值标记函数,使得树形图中的一个结点,不再仅仅对应于一个标记,而是对应于若干个标记。我还使用多叉树来代替二叉树,这样便大大地提高了树形图的标记能力,使得树形图的各个结点上,都能记录足够多的语法语义信息,把句子中所蕴含的丰富多彩的信息充分地表示出来。这种多值标记函数的理论实质上是一种复杂特征(complex features)的理论,它从根本上克服了乔姆斯基的短语结构语法在描述自然语言时的严重缺陷,提高了其有限的分析能力,限制了其过强的生成能力。显而易见,MMT模型是对乔姆斯基短语结构语法的一个带有实质意义的重要改进[3]。
根据MMT模型,我设计了汉—法、英、日、俄、德多语言机器翻译系统,这个系统叫作FAJRA。F-A-J-R-A这5个字母分别表示法语(法语为Francais)、英语(法语为Anglais)、日语(法语为Japonais)、俄语(法语为Russe)和德语(法语为Allmand)的法语首字母,这是一个基于规则的机器翻译系统(rule-based MT System),基于规则的机器翻译系统把翻译看成符号的转换过程。
这是世界上第一个用计算机自动地把汉语翻译为多种外语的机器翻译系统,这个系统是我于1981年在GETA使用IBM-4331大型计算机研制并试验成功的。计算机宽行打印机上输出多语言机器翻译结果的日期是“1981年11月4日”。沃古瓦教授高兴地对我说:“这是值得你记住的一个日子。”
根据独立分析、独立生成的原则,FAJRA的总体结构如下图所示:
FAJRA多语言自动翻译系统
从图中可以看出,在FAJRA系统中,汉语的形态分析和句法分析是独立于法、英、日、俄、德等5种语言的,而法、英、日、俄、德等5种语言的句法生成和形态生成是各自独立的,只有词汇转换和结构转换是与汉语相关的,所以,这是一个“独立分析-独立生成-相关转换”的机器翻译系统。
就在我提出MMT模型的同时,国外一些计算语言学家也看到了短语结构语法的局限性,分别提出了各种方法来改进它。例如1983年卡普兰(R.M.Kaplan,美国)和布列斯南(J.Bresnan,美国)提出的“词汇功能语法”,1983年马丁·凯依(Martin Kay,美国)提出的“功能合一语法”,1985年盖兹达(G.Gazdar,英国)等提出的“广义短语结构语法”,1985年珀拉德(C.Pollard,美国)提出的“中心语驱动的短语结构语法”等,都采用了复杂特征来描述自然语言。他们所谓的“复杂特征”实际上也就是我提出的“多值标记”,名异而实同。所以,MMT模型是世界计算语言学者对乔姆斯基的短语结构语法进行改进的一个重要方面和不可分割的组成部分,MMT模型是20世纪80年代较早提出的一个旨在改进短语结构语法的形式化模型,当时我国学者对于这方面的研究在国际上是处于前沿地位的。
沃古瓦教授去世已经31年了,但是他的音容笑貌仍然留在我的心中,回首往事,历历在目,就像在昨天一样,令人难以忘却。
我今年已经77岁了,早已年逾古稀,并且还在一天天地变老。是沃古瓦把我引进了计算语言学这个新兴的学科,尽管沃古瓦教授已经英年早逝,尽管我已经白发苍苍,但是我们毕生钟爱着的这个学科还非常年青,仍然充满了青春的活力。我们个人的生命是有限的,而科学知识的探讨和研究却是无限的。我们个人渺小的生命与科学事业这棵常青的参天大树相比较,显得多么微不足道,有如沧海之一粟。想到这些,怎不令我们感慨万千!
我虽已年老,还应当自强不息,努力创新,继承沃古瓦的未竟之业,以此来纪念我的恩师沃古瓦教授。
参考文献:
[1]Bernard Vauquois,Christian Boitet.Automated Translation
at Grenoble University[J].Computational Linguistics,1985,(1):28-36.
[2]John W.Backus,Friedrich L.Bauer,Julien Green,C.Katz,
John McCarthy,Alan J.Perlis,Heinz Rutishauser,Klaus Samelson,Bernard Vauquois,Joseph Henry Wegstein,Adriaan van Wijngaarden,Michael Woodger,Peter Naur.Revised Report on the Algorithm Language ALGOL60.Commun[J].ACM,1963,(1):1-17.
[3]冯志伟.汉语句子的多叉多标记树形图分析法[J].人工智能学
报,1983,(2).
(冯志伟 浙江杭州 杭州师范大学外国语学院 311121)endprint
