大数据环境下企业知识管理聚合研究
2016-11-16杨海锋
杨海锋
(1.武汉大学信息管理学院,430072;2.江西理工大学应用科学学院,赣州 341000)
大数据环境下企业知识管理聚合研究
杨海锋1,2
(1.武汉大学信息管理学院,430072;2.江西理工大学应用科学学院,赣州 341000)
文章借鉴馆藏资源聚合的研究成果,尝试在大数据环境下对企业知识管理进行聚合研究,提出元数据聚合、本体聚合、引证关系聚合三种聚合模式。同时对聚合结果可视化进行了探讨,并在此基础上架构了企业知识管理聚合系统模型,将聚合过程分为数据层、知识采集层、本体构建层、资源聚合层和应用可视化层等五层。研究表明,知识管理聚合研究能对企业的知识传播和创新提供很好的指导作用,为企业知识管理系统的升级和改造提供借鉴意义。
大数据;知识管理;资源聚合;元数据;本体
1 引言
在以用户生成内容(User Generated Content)为主要特征的Web2.0时代,网络数据量以爆炸式的态势增长,其数据量、多样性以及实时性都是以往传统数据无法比拟的。大数据时代已悄然来到了我们身边,对社会各方面产生了巨大的影响,它改变着个人的行为方式,促使企业在信息获取、知识传播、协同创新等方面不断思变。在知识经济时代,知识管理显得异常重要,许多企业都在开展自己的知识管理工作,并且取得了一定的成绩。但在大数据环境下,知识管理在知识的收集、加工、储存、分享和创造价值的过程中也有其自身的一些特性,本文即以此作为研究背景。在贺德方(2012)、邱均平(2013)、张玉峰(2014)等学者的研究中,馆藏资源的深度聚合研究能更好地组织、揭示和展现知识,以利于用户能有效地获取知识和对知识的共建共享。那么,企业中所产生的各类数字资源是否也可从此角度来展开研究,以便更好地满足企业对各类知识的需求呢?据此,笔者将以大数据环境为背景,在充分挖掘企业内外信息资源的基础上进行知识管理聚合,以便能为传统的企业知识管理系统的升级和改造提供借鉴意义。
2 相关分析与研究
大数据时代,企业应该积极地拥抱和融入其中。首先,应该具备大数据思维。企业高层要具备大数据的思维,不能躺在数据“金矿”上睡大觉,要积极促进数据的流动,挖掘数据中的价值。第二,重视企业的大数据分析技术。企业要对原有的系统进行升级改进,引进大数据分析模块或工具。第三,促进“群众”的参与。Web2.0时代,应充分调动企业的员工参与到企业的决策制定、流程改造、知识分享过程中。第四,建立企业制度和相关软环境等。这里主要指以企业文化为主要内容的企业制度和相关软环境的配套。
和传统知识管理不同,大数据时代给知识管理提出了新的课题:(1)数据量大,结构关系复杂,数据源多,语义内容丰富,对传统知识系统提出了挑战;(2)动态的竞争环境要求对数据进行及时(实时)分析;(3)对结果特别是隐性知识的发现和分析需要更多的工具和专业知识。为了让员工能在适当的时间和地点及时找到所需的知识,并且能更好地学习、创造和分享知识,我们这里用到了“聚合”的概念。
数字资源整合一直是学者们研究的热点,这一概念由学者马文峰2002年提出,他认为数字资源整合是将以前孤立的数字资源系统有机地整合,形成效率较高的资源服务体系,具体可涉及到各异构资源系统格式转化、内容结构组织和显示、用户检索界面和过程的改善等[1]。随着信息环境的变化,数字资源聚合的概念逐渐被学者们使用。目前数字资源聚合研究主要可分为两个方面:一方面是基于本体来揭示数字资源的语义并以生动可理解的方式呈现给用户,贺德方、李劲、张玉峰等学者的研究[2-5]是其典型代表;另一方面利用计量方法来挖掘数字资源之间的关联或者引证关系,邱俊平等学者从共现关系、引文耦合、同被引等方面进行了深入探讨[6-9]。但对于数字资源中的整合和聚合概念的区分方面还研究得不是很多,有的学者认为整合就是聚合[9,10],有的学者则提出整合是聚合的基础,两者相互区别又交叉融合,聚合是揭示数字资源之间的深层语义关联,识别不同对象的主题内容并进行内容的标识和关联,最终形成一个多学科多属性维度的立体知识网络[2,4,5,11]。张云中[11]对数字资源整合和聚合在背景、目标、理念、内容和方法等方面进行了区分探讨,并提出数字资源从整合到聚合是数字资源的新变革。笔者认为数字资源聚合相对于整合具有几个特点:(1)面向用户服务的意识和功能增强;(2)更加注重深层知识情报的挖掘和知识多样化的呈现方式;(3)是对学科知识不断紧密融合和大数据环境的积极应对。
综合上述讨论,在大数据环境下,将数字资源聚合思想和方法应用到企业知识管理过程中将能更加突出知识资源的战略地位,提高企业知识共享共建的热情,增强企业的核心竞争力。接下来,本文在分析知识管理相关研究的基础上提出了几种知识管理聚合方式,并讨论了其具体过程,然后架构了5层知识管理聚合模型,最后对本文的研究进行了总结。
3 知识管理现状及存在问题
不同学者从不同侧重点提出了知识管理的定义,其内涵就是用户能方便快捷地获得自己所需要的知识,具体涉及到知识的收集、加工、存储、分享和增值等过程。在专门提出知识管理之前,企业中已存在一些辅助企业进行决策和管理的知识系统,但各系统依据不同的目的建立,缺少知识管理统一的解决方案。企业将多源的知识集成后经由相关渠道传播,通过相关机制整合到企业的产品和服务中去,最终提高企业的知识创新能力。不管各知识管理系统在解决方案上有何异同,他们的过程模型都是从知识资源、知识生产以及知识应用这三个层面展开,只是在提供的功能服务上有所侧重[12]。
数据仓库是处理数据进行知识发现的有效手段,它将各数据库中相关主题的数据抽取清洗后,装载到数据仓库中进行隐性知识的挖掘。虽然也能对各数据库中的资源进行整合,但数据仓库是面向主题、集成的、相对稳定的、反映历史变化的数据集合,其产品开发周期长,投入大,见效慢,往往为高层决策提供服务。而在大数据环境下,知识管理是为了满足各类人员的知识需求,其过程和内涵要比数据仓库复杂和深入得多。比如,语义检索克服了传统检索中关键词匹配的不足,能结合用户的查询意图更精确地匹配用户的知识需求,还能借助用户近期内的查询特征和信息浏览轨迹对知识进行主动推送。因此,为了应对动态的发展环境,有必要对传统的知识管理系统重新认识和思考。
描述数据资源的元数据的种类多样,但对不同系统间语义异构问题,元数据还不能得到很好的解决。因此,必须在不同元数据上建立某种机制,来实现不同系统之间的互操作,这就常用到知识本体。知识本体的本质是促进知识共享和重用,能表述不同系统间的语义关系,并具有强大的逻辑推理能力。
在大数据环境下,爆炸式增长的数字资源淹没了所需要的知识和专家团队,如何将知识特别是隐性知识以及所涉及专家团队挖掘出来显得比以前更加困难。隐性知识大多存在于相关专家的头脑中,在以前“师傅带徒弟”的传统模式中,难免会有留一手的想法,为了发现专家并将其头脑中的知识主动地分享出来,应采取主动的策略和适当的培育环境。同时,大数据环境下多学科的交叉融合日益紧密,可视化的知识呈现能为用户在获取、理解和利用知识的过程中提供更加丰富全面的信息。
4 聚合策略研究
4.1 基于元数据的聚合研究
元数据是对信息资源的结构性描述,用简练的逻辑结构来描述尽可能详细的资源信息,是信息资源的一种外在表现形式。大数据环境下相对于以往数据仓库静态的数据,企业产生依附于不同载体的大量和动态的数据,元数据方案在此方面的应用已较为成熟。由于在不同领域应用的元数据不尽相同,比如Dublin Core(适合网络资源)、EAD(适用于档案和手稿资源,包括文本和电子文档、可视材料和声音记录)、TEI(对电子形式全文的编码和描述)[13],所以数字资源的元数据描述有多种格式,这将导致元数据之间无法紧密关联和扩展。同时,元数据是知识信息资源的外在表现,用户的检索仍然是传统关键词匹配的硬检索,不能真正从基于语义的软检索来更好地满足用户的需求。元数据主要侧重于资源体系分类和资源自身描述等外部特征,难以对不同系统架构和不同“粒度”的资源进行较满意的描述,为解决在元数据上实现不同资源对象的相互通信和互操作,这里用到了知识本体。知识本体在不同元数据上创建了相互映射机制,实现了异构系统之间的互通,为信息系统之间高层次互操作提供了很好的条件。
4.2 基于本体的聚合研究
Studer等[14]认为本体是共享概念模型的明确的形式化规范说明。 企业要根据自己所涉及的产品和服务来构建自己的领域本体,在领域专家参与下,构造出适合企业自身特点的领域本体。大数据环境下,随着信息资源不断大量地涌现,相关人员将已经建立的领域本体作为基础,利用本体已经形成的概念及概念之间的关系、函数、推理机制和实例等,通过概念相似度的计算来对信息资源进行标注,为实现语义层面的服务提供基础。同时,本体库要及时进行内容的更新和实例的添加,通过各种映射机制实现不同领域本体之间的互联互通互操作,构造复杂的语义网络关联结构。本体构建的目的是实现知识的共享和重用。因此在构建企业领域本体的时候,要积极汲取前人研究的丰硕成果为我所用。比如世界上最大的多领域知识本体之一的DBpedia,从维基百科和其他资源抽取而来的YAGO,多语言的词汇语义网和本体BabelNet等。
虽然在本体构建过程中提出了本体构造元素,但并不需要严格遵守。因此,本体的构造目前没有一个标准的方法,对于不同的问题域和具体实践环境,各专家构造本体的过程不尽相同,要实现不同领域小本体之间的互通互联互操作,不仅要屏蔽其底层物理架构,更重要的是要实现不同领域之间知识的关联。比如不同领域对同一词不同的释义。Gruber提出了本体应用于知识管理的5个原则:明确性(Clarity)、一致性(Coherence)、可扩展性(Extendibility)、最小编码偏差(Minimal encoding bias)、最小本体承诺(Minimal ontology commitment)[15]。
目前,许多企业信息系统对数据的组织和操作都基于以前的元数据方案,如果对企业的知识系统重新架构和对大量的历史数据进行重新组织,这将为企业带来沉重的经济负担。那么,如何将知识本体嵌入到以前的元数据系统中,实现不同数据资源描述方案的协同工作,这越来越受到人们的关注。文献[16]将元数据的部分元素和知识本体的相关概念进行了联系,创建了政务信息资源语义检索系统;文献[17]将元数据建模技术与本体相结合建立基于元数据的产品数据本体,并在某汽轮机产品模型上进行了应用。文献[18]运用元数据和本体相结合的思想来解决异构数据库的集成问题,通过分层思想来管理元数据达到屏蔽底层数据库异构的问题,通过本体处理不同领域中语义异构的问题。
4.3 基于引证关系的聚合研究
目前,引证关系聚合研究主要应用在馆藏资源或者学术资源的知识管理中,在企业知识管理中还不多见。和馆藏资源相比,企业知识管理中的资源具有如下特点:资源类型多,结构复杂,多以数字化和web形式呈现。因此,引证关系聚合在企业知识管理中的运用环节较多且复杂。同时,引证关系的聚合是笔者借鉴而来,其研究范围可能不仅仅是引证本身。
在引证关系的聚合研究中,可以从以下方面着手考虑:(1)专家团队的发现。除了通常的工作硬性约束外,用户自发的浏览行为以及企业虚拟社群的讨论等多由其兴趣爱好决定,对涉及到的相关资源,分析其来源、作者、主题以及关键词等指标,借鉴信息计量学相关知识,通过聚类分类方法能将企业中的多数隐形专家粗略地挖掘出来,为让潜在的专家充分贡献其知识和组建专家团队奠定了基础。(2)领域情报及轨迹发现。通过信息资源中相关主题的统计和计算,能使企业了解自己所处领域的国内外发展现状以及竞争对手目前的一些新的发展动向,这是企业制定战略和采取市场策略的重要参考依据。在大数据环境下,企业绝对的商业机密是不存在的,主要的竞争对手不仅受到各大同行的严密监视,而且专业的数据分析公司会更加敏锐地观察企业的一举一动,通过关联时间和数据的分析获得更加有参考价值的信息。(3)信息资源的整合和知识的发现。基于引证关系的聚合研究目的是对现有信息资源的整合,以存在的现有信息资源为研究对象,利用信息计量学和社会网络分析等理论技术,通过对对象的某些外部特征之间的关联来构造一张巨大的信息资源网络,将更有价值的资源及时迅速地推送给特定用户。
4.4 结果可视化
在大数据时代,知识管理过程中可视化技术的使用将能为知识的理解、知识的增值创新提供更好的工具。结果可视化是利用可视化相关技术将用户查询结果以不同视角呈现给用户,其中可包括文本、图表、模型和数字等形式。检索结果的可视化将能揭示出隐性知识及其关联关系,促进语义内容的更好呈现,使不同学科背景的用户能进行具体内容的理解和有效的学习交流。目前结果可视化呈现方式主要有知识地图、主题图、概念图、思维导图等[4]。在企业的知识管理聚合中,聚合结果可视化应满足以下几个条件:(1)结果中知识的关联;(2)满足不同用户知识需求;(3)注重隐性知识的发现和语义的呈现;(4)结果可视化与用户的深度交互。
5 知识管理聚合系统模型
图1给出了大数据环境下企业知识管理聚合的系统架构,该模型自下而上分为数据层、知识采集层、本体构建层、资源聚合层和应用可视化层5层结构[4,19,20]。
数据层:该层是数据资源层,数据来源主要包括各数据库、数据仓库、正式和虚拟社群、现存的知识信息、专家头脑中知识、现成(如DBpedia、YAGO等)的或已构造的领域本体、文档资料以及与领域相关的爬虫数据等。形式上包含文本、图片、视频资源;结构上包括结构化数据、半结构化数据和非结构化数据;网页类型包括动态网页和静态网页,其中也不乏已标注过的网页;内容上和企业性质相关,其中包含多领域数据;功能上大多为以前与知识管理相关的系统,比如客户管理系统,供应链管理系统,邮件系统等。该层数据能被计算机记录和处理,但不能被理解。
知识采集层:知识的获取是知识管理系统关键的一步,但也一直被视为知识系统运行的“瓶颈”所在。从知识获取的策略看,可分为人工知识获取、半自动知识获取和全自动知识获取。人工知识获取是领域专家主导下的知识获取方式,该方式对知识内容理解准确性高,但要求领域专家经验丰富且费时费力;半自动知识获取方式是鼓励普通员工参与的一种知识获取机制,其思想是鼓励全员参与知识创新,但该方式需要精心设计的人机交互界面和辅助的技术手段;全自动知识获取是通过机器学习、自动抽取等技术获取知识的过程,其所采集的知识通常隐藏在大量的数据背后,不易被发现,需要借助一定的知识发现工具,获取的具体知识需要经过抽象、归纳、泛化成抽象的知识,一般可分为概念知识、概念关系、公理、推理规则[20]。通过上述过程,采集到的知识最终被存放在知识库中。
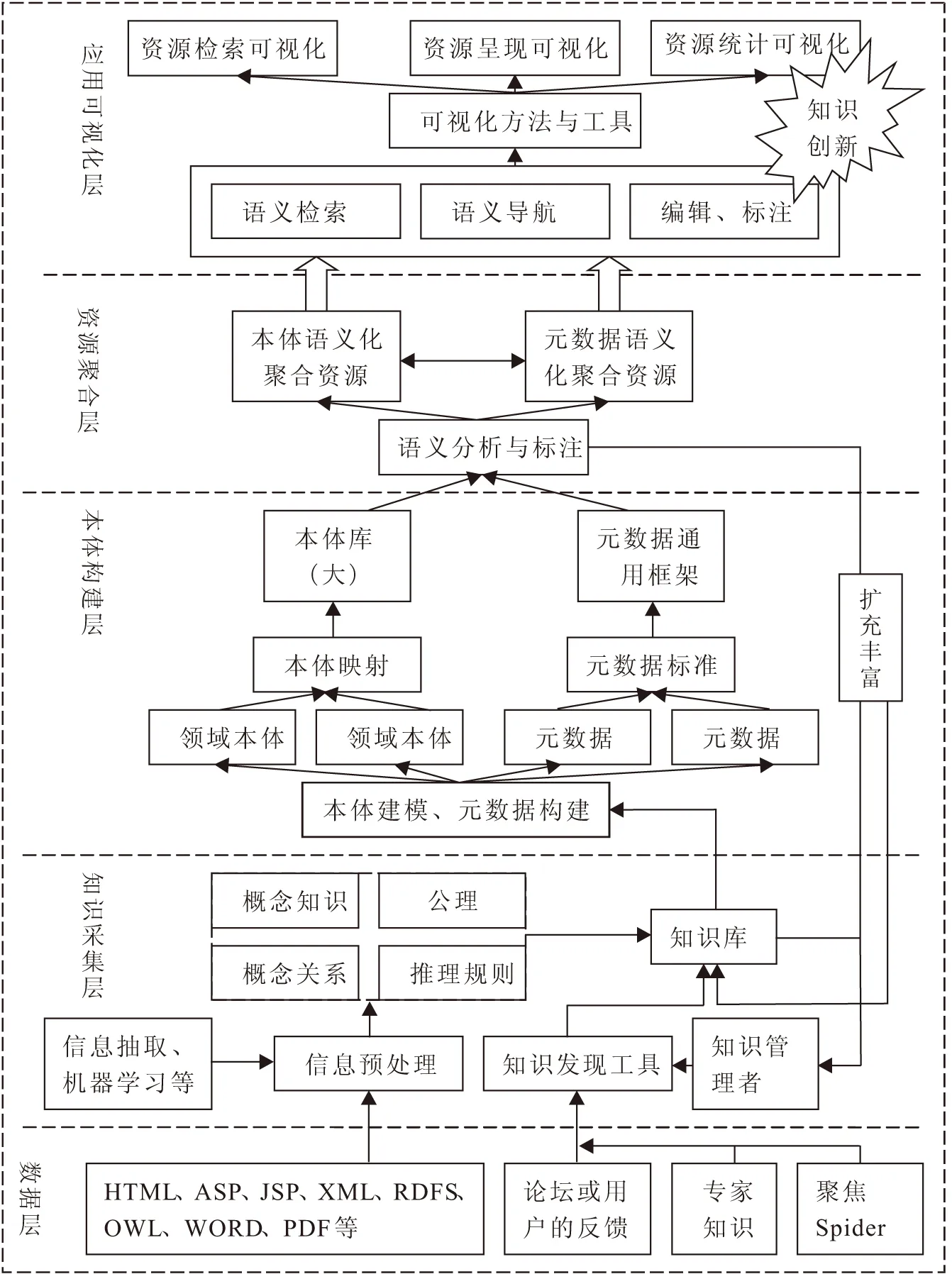
图1 企业知识管理聚合系统模型
本体构建层:知识本体库的构建过程主要为各(小)领域本体的构建、领域本体映射机制的建立和(大)知识本体库的生成。为了解决不同本体的异构问题,人们提出了本体映射的概念,目的是促成不同本体的语义关联,通过通用的接口实现知识在不同本体间的访问,并将检索的结果集成后以特定的方式呈现。目前的本体映射方法主要有基于信息流的方法、基于相似度的方法、基于统计学的方法、基于机器学习的方法以及上述方法的综合使用[21]。对于描述资源的不同元数据方案,可通过元数据复制、元数据转换和元数据开放搜寻等方法实现互操作[22]。在此基础上,寻找某种机制(前面3.2中已提到),实现元数据标准和知识本体的关联,提高其语义表达和检索功能。
资源聚合层:该层通过已经构建的本体库对知识资源进行语义分析和语义标注,同时也对聚焦Spider(抓取特定领域的网络数据)采集的网络资源进行标注。知识资源进行语义标注通常分为发布文档用户自己标注和专业机构进行标注两种方式,但由于标注的随意性和对语义理解的不同,常常导致标注质量不高。在知识资源的语义标注过程中,Uren等[22]提出了7点要求:(1)标注的规范化;(2)标注系统设计利于调动不同领域专家参与;(3)对不同本体的支撑;(4)异构文档的支持;(5)文档和标注的一致性;(6)标注的存储;(7)标注的自动化。目前,用于人工标注的工具有Amaya、Annozilla、Mangrove等,用于自动化标注的工具有Lixto、MnM、Melita等[23]。
应用可视化层:该层是用户与系统的交互接口,根据用户的请求,系统经过语义解析,发送请求至各相关领域本体,最终将集成的结果以多种可视化的方式呈现给用户,用户在知识的使用过程中促发知识的创新,并将新知识反馈来更新知识库。可视化工具比较丰富,可以是本体构建工具Protégé提供的插件OntoViz,也可以是通用的可视化插件Piccolo、Swoop,以及和该层API连接的UCINET等(引证聚合部分已提到)可视化软件[4]。
6 结语
知识管理的目标是实现知识的共享和流动,促进知识增值,提高组织的核心竞争力。在大数据环境下,由于数据量大、数据类型多样、价值附着度低等特点,企业知识管理聚合研究显得尤为重要,它将为企业知识生态的形成提供有利条件,促进数据流到知识流的转变和增值。本文中元数据聚合是基础(传统聚合模式),本体聚合研究是深入(深度聚合),而引证关系的聚合是深度聚合的延伸。对于其他学者提到的深度聚合模式,比如关联聚合、主题聚合等[24],本文没有专门单独列出,期待后期继续细化和研究。
知识管理系统的良好运行还需要领导层、知识管理专家、普通员工的广泛参与,领导要重视,普通员工要聚“才”,知识管理专家要营造知识分享和传播的氛围,改进知识管理系统的架构和内容组织,为知识分享提供便利的条件。
[1] 马文峰.数字资源整合研究[J].中国图书馆学报,2002(4):64-67.
[2] 贺德方,曾建勋.基于语义的馆藏资源深度聚合研究[J].中国图书馆学报,2012(4):79-87.
[3] 李劲,程秀峰,宋红文等.基于语义的馆藏资源深度聚合模型探析[J].湖北民族学院学报,2013,31(2):212-215.
[4] 张玉峰,曾奕棠.语义环境下馆藏资源深度聚合结果可视化框架研究[J].图书情报知识,2014(5):65-71.
[5] 张玉峰,何超.馆藏资源聚合结果的层次可视化方法研究[J].情报理论与实践,2013,36(8):41-44.
[6] 邱均平,刘国徽.基于共现关系的学科知识深度聚合研究[J].图书馆杂志,2014,33(6):14-23.
[7] 邱均平,周毅.基于作者共被引的馆藏资源深度聚合模式与服务探析[J].图书情报工作,2014,58(7):19-24.
[8] 杜晖.基于耦合关系的学术信息资源深度聚合研究[D].武汉:武汉大学,2013.
[9] 李星星.馆藏资源深度聚合及应用研究[D].武汉:华中师范大学,2013.
[10] 梁慧.基于语义的馆藏资源深度聚合与可视化展示的保障机制研究[D].武汉:华中师范大学,2013.
[11] 张云中.从整合到聚合:国内数字资源再组织模式的变革[J].数字图书馆论坛,2014(6):16-20.
[12] 夏敬华,金昕.知识管理[M].北京:机械工业出版社,2003:157.
[13] 刘炜.数据图书馆的语义描述和服务升级[M].北京:国家图书馆出版社,2010:7.
[14] Studer R, Benjamins V R, Fensel D.Knowledge engineering: principles and methods[J].Data & knowledge engineering, 1998, 25(1): 161-197.
[15] Gruber T R.Toward principles for the design of ontologies used for knowledge sharing?[J].International journal of human-computer studies, 1995, 43(5): 907-928.
[16] 花开明,陈家训,杨洪山.基于本体与元数据的语义检索[J].计算机工程,2007,33(24):220-221,224.
[17] 顾巧祥,祁国宁,纪杨建,等.基于元数据的产品数据本体建模技术[J].浙江大学学报,2007,41(5):736-741.
[18] 贾琦,郭绍忠,丁志芳.基于本体的元数据管理系统的研究[J].计算机工程与设计,2009,30(1):116-119.
[19] 董金祥.基于语义面向服务的知识管理与处理[M].杭州:浙江大学出版社,2009:357.
[20] 王昊,谷俊,苏新宁.本体驱动的知识管理系统模型及其应用研究[J].中国图书馆学报,2013,39(204):98-110.
[21] 赵中英,梁永全,纪淑娟.本体工程中的本体映射机制[J].情报杂志,2008(8):23-27.
[22] 韩夏,李秉严.元数据的互操作研究[J].情报科学,2004,22(7):812-815.
[23] Uren V, Cimiano P, Iria J, et al.Semantic annotation for knowledge management: Requirements and a survey of the state of the art[J].Web Semantics: science, services and agents on the World Wide Web,2006,4(1):14-28.
[24] 赵蓉英,王嵩,董克.国内馆藏资源聚合模式研究综述[J].图书情报工作,2014,58(18):138-143.
(责任编辑:孟凡胜)
Research on Aggregation of Knowledge Management in Enterprises Under the Big Data Environment
YANG Hai-feng1,2
(1.Wuhan University, Wuhan 430072, China; 2.Jiangxi University of Science and Technology, Ganzhou 341000, China )
Based on the research of the aggregation in Library resources, this paper attempts to make research on aggregation of knowledge management in enterprises under the big data environment.Three aggregation models, meta-data aggregation, ontology aggregation and citation relationship aggregation, are put forward in this paper.And the visualization results are discussed.On the basis, the aggregation system model of knowledge management is constructed, which divides the aggregation process into data layer, knowledge collection layer, ontology construction layer, resources aggregation layer and application visualization layer.This research can provide a better guide to knowledge dissemination and innovation and the reference for the upgrading and transformation of knowledge management system in enterprise.
big data; knowledge management; resource aggregation; meta-data; ontology
F270.7
A
1006-1525(2016)05-0095-06
杨海锋,男,讲师,博士研究生。
2016-04-11
