基于IRAM和半监督的谱聚类图像分割
2016-10-22龚文文葛玉荣
龚文文,葛玉荣
(中国海洋大学信息科学与工程学院,山东青岛266100)
基于IRAM和半监督的谱聚类图像分割
龚文文,葛玉荣
(中国海洋大学信息科学与工程学院,山东青岛266100)
谱聚类判别割(Dcut)计算正则化相似度矩阵及其特征向量比较耗时,对于大规模矩阵特征值问题,隐式重启动Arnoldi方法(IRAM)能够快速收敛到模值最大的k个特征值(即主导特征值)。因此本文采用IRAM算法计算相似度矩阵的主导特征值,减小运算时间。为解决谱聚类敏感于尺度参数的问题,提出利用少量监督样本求取每幅图像特有的尺度参数,进行半监督图像分割。通过对UCI数据集和自然图像的仿真实验表明,本文算法能有效提高Dcut的运算速度,同时性能稳定,分割结果优于Dcut和PCA-Dcut。
判别割;隐式重启动Arnoldi;尺度参数;半监督;图像分割
谱聚类[1]视图像每个像素为加权无向图的一个顶点,像素间的相似度为边的权重,将聚类问题转化为图的划分问题,能够在任意形状的样本空间上聚类且收敛到全局最优解,因此被广泛应用于图像分割。目前常用的划分准则包括Shi等提出的正则割准则(Normalized cut,Ncut)[2]、Ng等提出的k-way划分的Ng-Jordan-Wesis(NJW)算法[3]以及判别割准则(Discriminant cut,Dcut)[4]。
谱聚类Dcut采用正则化相似度矩阵,在聚类个数比较大或数据轻微重叠时分类结果优于Ncut,但同时存在两个缺陷:其一,算法敏感于尺度参数σ[5-7],只能在较小的一个参数范围内才能取得较好的聚类效果。其二,计算正则化相似度矩阵及其前p个最大特征值对应的特征向量比较耗时,为此邹小林、陈伟福等[8]提出基于子空间的判别割算法(Dcut based Subspace,SDcut)减小了计算时间,但性能不够稳定;邹小林又提出基于主成分分析的判别割算法(PCA-Dcut)[9],利用PCA计算相似度矩阵的前p个最大特征值对应的特征向量,具有较好的稳定性,但PCA是一种线性变换,需要计算相似度矩阵的协方差矩阵的特征向量,矩阵维数并未减小,未减少求解特征向量的时间。
针对谱聚类敏感于尺度参数的问题,本文提出利用少量监督样本求取尺度参数。针对判别割求解正则化相似度矩阵及其特征向量比较耗时的问题,提出利用隐式重启动Arnoldi算法计算相似度矩阵的前p个最大特征值对应的特征向量,进而在子空间计算正则化相似度矩阵。
1 隐式重启动Arnoldi算法
基于Krylov子空间正交投影的Amoldi方法[10-11],其基本思想是通过Arnoldi分解产生正交矩阵,将原矩阵约化为一个上Hessenberg矩阵,使大规模矩阵特征值问题约化为中小规模特征值问题,通过求解中小规模特征值问题所产生的Ritz值来逼近原问题的解。实际应用中,为了满足精度要求,正交矩阵维数m可能会非常大,计算量和存储量变得不可接受,采用隐式重启动[12]来解决这一问题,即当m达到设定值时,如果Ritz值仍不收敛,就重新构造启动向量,用新的启动向量进行Amoldi分解。
隐式重启动Arnoldi方法[13,14]对于大规模矩阵特征值问题收敛迅速,易于收敛到模值最大的几个特征值,因此适合求解相似度矩阵的前p个最大的特征值及其特征向量,实现降阶。
隐式重启动Arnoldi算法的基本步骤[14]如下:
输入:Krylov子空间维数m,所需求的特征值和特征向量的个数k(k<m),收敛精度tol,单位长初始向量v0。
输出:k个特征值及其对应的特征向量。
1)Arnoldi过程:以v0为启动向量,产生一个k步Arnoldi分解AVk=VkH+fk;
2)按照p步Arnoldi扩展算法,扩展k步Arnoldi分解至m=k+p步Arnoldi分解:AVk+p=Vk+pHk+p+fk+p;
3)计算近似特征值和特征向量:计算出Hk+p全部的特征值和特征向量,将Hk+p的特征值按规则排序选取其中k对作为要求的特征对(λi,φi)的近似值。
4)检验是否收敛:判断Ritz估计值是否收敛。若均小于tol则停止算法,否则继续。
5)重启动:由已计算出的近似对的信息,将p步位移μi,i=1,2,…,p应用于Hk+p,形成新的k步Arnoldi分解
2 基于IRAM和半监督的谱聚类图像分割
2.1尺度参数的求取
针对谱聚类敏感于尺度参数的问题,利用少量的监督样本求取尺度参数。具体算法步骤如下:
1)提取图像每一个像素点的特征,构成点集V={v1,v2,…,vn},v1∈Rd,Rd为d维实数空间,n为像素个数
2)从图像的每一类中随机取出少量像素并指定其类别作为u个监督样本v1,v2,…,vu
3)令同类样本间的相似度为0.99,同类样本间的尺度参数

其中vi和vj属于同一类(i≠j,i,j=1,2,…u),d(vi,vj)为欧式距离,并取平均值作为同类尺度参数σs。
4)令不同类样本间的相似度为0.01,不同类样本间的尺度参数
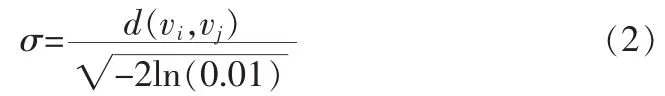
其中vi和vj属于不同类(i≠j,i,j=1,2,…u),d(vi,vj)为欧式距离,并取平均值作为不同类尺度参数σd。
5)尺度参数σ

6)重复以上步骤3次,取3次的平均值作为最终的尺度参数值。
2.2算法步骤
Dcut算法在对Laplacian矩阵求逆和计算正则化相似度矩阵的特征向量这两步比较耗时。采用文献[9]提出的子空间方法,利用IRAM算法求解相似度矩阵A的前p个最大的特征值对应的特征向量,大大提高了Dcut算法的运算速度。
具体步骤如下:
输入:原始图像
输出:原始图像的分割结果图
1)按照2.1节所述步骤计算尺度参数σ。
2)计算相似度矩阵A=(aij)∈Rn×n,其中aij=exp(-d2(vi,vj)/ 2σ2)。
3)计算度矩阵D和Laplacian矩阵L。
4)采用隐式重启动Arnoldi算法求相似度矩阵A的前p个最大的特征值对应的特征向量ξ1,ξ2,…,ξp,设VA=[ξ1,ξ2,…,ξp]。
6)求W*的k个最大特征值对应的特征向量
7)矩阵U0的每一行单位化处理,得矩阵U。
8)矩阵U的每一行视为Rk中的一个点,用K均值算法将其分为k类。
9)确定原顶点vi属于第j类当且仅当U的第i行分在第j类。
3 实验与分析
通过UCI数据集和自然图像进行仿真实验验证本文算法。实验中将本文算法与Dcut、PCA-Dcut进行比较。计算机的配置如下:双核3.20 GHz,Pentium(R)处理器,2.52 GB内存,Window7操作系统,Matlab R2012b编程。实验中自然图像大小均为110×73。
3.1UCI数据集上的实验
选取UCI数据库中的3个数据集Iris、Sonar、Balancescale。该数据库中的每个样本均有明确的类别,因此可以使用正确率来评价算法的聚类效果。正确率越高,表示聚类结果越好。表1给出了3个数据集的数据属性,表2给出了各算法的运行时间,表3给出了各算法的正确率。

表1 数据属性

表2 各算法的运行时间
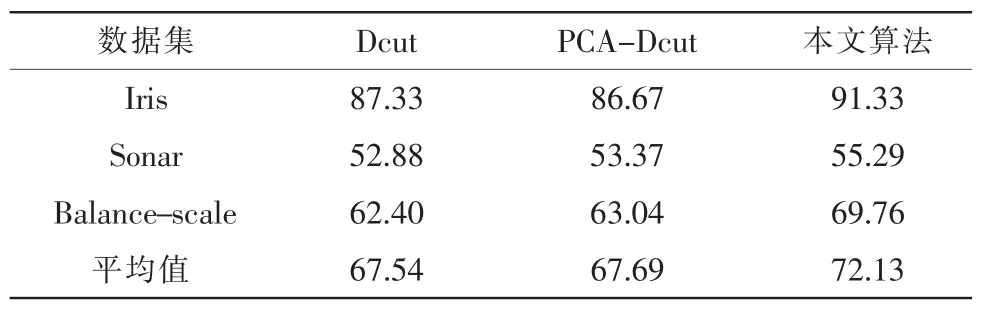
表3 各算法的正确率
根据2.1节所述步骤求取3个数据集的尺度参数依次为0.265 1,6.462 8,12.632 8。从表2看出本文算法的平均运行时间最短,如表3所示,Dcut和PCA-Dcut的正确率相当,但均低于本文算法。
3.2自然图像分割实验
选取Berkeley图像库中的3幅自然图像,并采用均匀性U(Uniformity)[15]评价算法的分割效果:
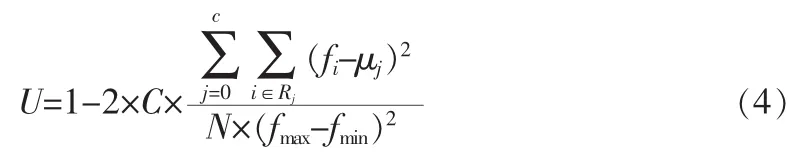
其中:c代表阈值个数,Rj为分割区域j,fi为像素点i的灰度,μj表示Rj区域中所有像素点的灰度均值,N为图像的像素个数,fmax和fmin分别是图像的最大和最小灰度值。均匀性的取值为0~1的实数,值越大,表示图像分割的效果越好。
从视觉上看,图1(a)、图2(a)、图3(a)分别分为2类、3类、3类比较合适。Dcut分别分为2类、4类、4类才能得到好的视觉效果。而PCA-Dcut和本文算法均分别分为2类、3类、3类就能得到好的分割效果。从表4也可以看出,本文算法的均匀性平均值最高。这说明本文算法的分割效果要优于算法Dcut和PCA-Dcut,而PCA-Dcut要好于Dcut。根据2.1节所述步骤求取3幅自然图像的尺度参数依次为0.108 3、0.124 5、0.187 9。

图1 对自然图像1的分割结果图

图2 对自然图像2的分割结果图

图3 对自然图像3的分割结果图
如表5所示,Dcut分割图像的平均时间为326.037 5s,PCA-Dcut为83.317 5s,本文算法为31.446 7s。因此可以得出本文算法采用IRAM方法计算相似度矩阵的前p个特征值对应的特征向量能有效减少计算量,提高运行速度。

表4 各算法图像分割的均匀性值

表5 不同算法图像分割时间
4 结论
谱聚类用于图像分割时是一个大规模矩阵特征值问题,本文结合子空间方法采用IRAM算法求解相似度矩阵的前p个主导特征值对应的特征向量,有效缩短了算法运行时间。同时利用监督信息求取的尺度参数,解决了谱聚类敏感于尺度参数的问题,多幅自然图像的分割结果表明本文算法性能稳定,具有更好的分割效果。
[1]Fiedler M.Algebraic connectivity of graphs[J].Czechoslovak Mathematical Journal,1973,23(98):298-305.
[2]Shi J,Malik J.Normalized cuts and image segmentation[J].IEEETransactionsonPatternAnalysisandMachine Intelligence,2000,22(8):888-905.
[3]NG A Y,Jordan M I,Weiss Y.On spectral clustering: analysisandanalgorithm[C]//AdvancesinNeural Information Processing Systems.Cambridge:MIT Press,2002:849-856.
[4]CHEN Wei-fu,FENG Guo-can.Spectral clustering with discriminant cuts[J].Knowledge-Based Systems,2011,(28): 27-37.
[5]Malik J,Belongie S,Leung T,et al.Contour and texture analysis for image segmentation[J].International Journal of Computer Vision,2001,43(1):7-27.
[6]Ng AY,Jordan MI,Weiss Y.On spectral clustering: Analysisandanalgorithm[A].AdvancesinNeural Information Processing Systems(NIPS14)[C]//Cambridge,MA:MIT Press,2002:894-856.
[7]Zelnik-Manor L,Perona P.Self-tuning spectral clustering[A].AdvancesinNeuralInformationProcessingSystems(NIPS17)[C]//Cambridge,MA:MIT Press,2005.1601-1608.
[8]邹小林,陈伟福,冯国灿.判别割(Dcut)的图像分割及其快速分割算法[J].中国图象图形学报,2012,17(2):222-228.
[9]邹小林.改进的判别割及其在图像分割中的应用[J].计算机应用,2012,32(8):2291-2295,2298.
[10]Arnoldi W E.The Priciple of Minimized Iteration in the Solution of Matrix Eigenvalue Problems.Quart.J.Appl.Math,1951(9):17-29.
[11]Huckle,Thomas.The Arnoldi Method for Normal Matrices[J].SIAM Journal on Matrix Analysis and Applications,1994,15(2):11.
[12]Sorensen D C.Implicit Application of Polynomial Filters in a k-step Arnoldi Method[J].SIAM Journal on Matrix Analysis and Applications,1992,13(1):357-385.
[13]Dookhitram K.,Boojhawon R.,Bhuruth M.A new method for accelerating Arnoldi algorithms for large scale Eigenproblems[J].Math.Computer.SImul,2010(2):387-401.
[14]Sorensen D C.Implicitly Restarted Arnoldi/Lanczos Methods for Large Scale Eigenvalue Calculations.In:Keyes,D.E.,Sameh,A.,Venkatakrishnan,V.(eds.):ParallelNumer-ical Algorithms[M],1997:119-166.Kluwer,Dordrecht(1997).
[15]Levine M D,Nazif A M.Dynamic measurement of computer generated image segmentations[J].IEEE Transac-tions on Pattern Analysis and Machine Intelligence,1985,7(2): 155-164.
Image segmentation by spectral clustering based on IRAM and semi-supervised
GONG Wen-wen,GE Yu-rong
(School of Information Science and Engineering,Ocean University of China,Qingdao Shandong 266100,China)
Spectral clustering discriminant cut(Dcut)is time consuming to calculate the normalized similarity matrix and its eigenvectors.For large scale matrix eigenvalue problem,implicitly restarted Arnoldi method(IRAM)is easy to converge to the k largest magnitude eigenvalues(i.e.,dominant eigenvalues).Therefore,the paper uses the IRAM algorithm to calculate the dominant eigenvalues of similarity matrix to reduce runtime.To solve the problem of spectral clustering sensitive to the scale parameter,the paper proposes to calculate the scale parameter unique to each sample set by using a few supervised samples,and do semi-supervised image segmentation.The experiments on UCI data set and natural images show that the algorithm of this paper can effectively improve the running speed of Dcut with stable performance,and the results are better than Dcut and PCA-Dcut.
discriminant cut;implicitly restarted Arnoldi;scale parameter;semi-supervised;image segmentation
TN911.73
A
1674-6236(2016)17-0156-04
2016-01-11稿件编号:201601072
国家国际科技合作专项(2012DFG22080)
龚文文(1990—),女,山东枣庄人,硕士研究生。研究方向:图像处理与模式识别。
