基于关键句的K-means算法在热点发现领域的研究与应用
2016-07-28顾俊
顾 俊
(贵州师范大学数学与计算机科学学院,贵州 贵阳 550001)
基于关键句的K-means算法在热点发现领域的研究与应用
顾俊
(贵州师范大学数学与计算机科学学院,贵州贵阳550001)
摘要:由于“互联网+”提出的,网络信息呈现爆炸的趋势。面对海量数据如何准确找到热点事件成了网民关注的话题。文章从实际应用出发,首先对每一篇文本选取5句话作为该文本关键句,然后用TF-IDF计算特征词值,特征向量选择时不考虑单个字的权重,再用K-means算法进行聚类。以新浪新闻为例,将环境、住房和违法三类话题共322篇文本作为测试语料进行聚类,聚类准备率达到70 %以上,说明选取关键句比将整个文本作为聚类对象的聚类效果好。
关键词:文本挖掘,TF-IDF,聚类,K-means
0引言
随着互联网+的出现,网络数据迅速增长,面对海量数据,如何快速有效地发现热点信息成了人们日益关注的话题。网络舆情[1][2]已经对社会的稳定和网民造成一定的影响。与一般舆情不同,网络舆情具有传播速度快、涉及范围广且不易被发现等特点,因此实现网络舆情的实时监控有一定的难度。本文利用k-means聚类[3]算法,充分发挥文本中关键句的作用,从而达到热点发现[4]的目的,为舆情监控提供可能。
1相关研究
文本聚类的研究方法比较多,但相对来讲这些方法主要用于实验室研究阶段,在实际商业应用中还是一些简单大众的方法。目前的聚类方法分为是基于语义相似度[5]聚类的研究和基于关系聚类[6]的研究。
基于语义相似度聚类[7]的研究方法主要有两种:一种是利用语义词典将相关词放在一个树形结构中来计算其权重;另一种是综合考虑文本上下文语境的信息,利用统计学的方法来计算词的权重。前一种权重的计算方法相对来说比较成熟,文献[8]和[9]都是基于树型结构的语义网络权重计算方法。上下文语境的统计方法是对基于语料库的词语相似度的计算方法,不同词语语义相近当且仅当它们处在相似的上下文语境里,因此对语料库具有较强地依赖性并伴有噪声。
基于关系聚类[10][11]的研究,不同词之间相似度的确定不仅要考虑词的属性还要考虑它们之间的相互联系。2001年,Taskar等人提出了基于似然关系聚类方法的模型;2003年,Neville等人又提出了基于图形分解和数据聚类相结合的关系聚类模型;2006年,Bhattacharya等人将实体识别也归为关系聚类问题,基于层次的聚类算法[12]在聚类过程中除了要计算属性边之外,还利用关系边来表示不同实体间的关系。
2文本预处理
文本预处理是聚类中重要环节之一,它的目的是尽可能的消除文本中的垃圾词,提高文本的质量,它是后期文本能否准确聚类的前提。
预处理的第一步是对文本进行分词。中文分词与英文分词不同,英文单词之间有间隔可以以此为依据进行分词,而中文没有这一特性因此中文分词相对来说比较麻烦。本文采用ansj分词系统来对文本进行分词。
其次,去掉分词后文本中的标点符号。因为在聚类过程中不考虑文本情感方面,故这些标点符号在后面的处理过程中没有实际作用。
最后,停用词的去除。如:的、此外、啊、呀、以前、几个……之类的词,这些虚词在文本会多次出现而且对文章来说没有实际意义,如果不进行处理,在后期特征选择时不仅增加文本计算量,而且得到的特征不具有代表性,直接影响聚类的效果。
3特征获取
TF-IDF[13]是数据挖掘[14]中常用的加权技术,用来评估字词在语料中的重要程度。字词的重要性与它在文本中出现的次数成正比,与它在整个语料中出现的次数成反比。如果一个字词在一篇文本中出现的频率高并且在其它文档中出现少,那么, 该字词在聚类算法中就是很好的特征词。
为了提高聚类的准备性和特征词效果,本文两次应用TF-IDF,先从每篇文本中选出权重最大的5个句子作为该文本的关键句,再从有关键句中选择特征词。在特征词选择方面,因为单个字的意义不大,因此即便算出来权重很大,本文也不将其作为特征词。
4模型选择
聚类是一个无监督的过程,因此并不需要训练数据,只要知道如何计算相似度将相似的东西聚到一起就可以了。K-means算法较成熟、易于实现且聚类效果也较好,本文采用K-means模型聚类。其中心思想是:首先随机选取K个点作为中心点,依次计算其余各点到它们的距离,将所有的点分别归到最靠近它们的中心点所在的类;然后利用迭代的方法,计算出新的K个中心点,重新聚类,直到收敛为止。
5实验过程
1)语料获取。利用爬虫程序从新浪网获取数据,然后人工进行过滤、筛选,得到想要的理想数据。
2)预处理。利用分词模块和停用词表对获取的语料集进行预处理,去掉预料中的噪声。
3)文本表示。用向量空间模型(SVM)将文本以形式化的方式表示出来,以便计算机识别处理。
4)计算每篇文本中的句子权重,从每一篇文本中提取权重最大的五句话作为该篇文本的代表,以句号、感叹号、问号、省略号表示文本中一句话的结束,M表示该文本中的总句数。对预处理后的文本用局部TF-IDF计算每个词的权重,文本中每一句话中的每个词的权重相加后再除以词的数量为该句权重的计算的一部分,即
W(第i句中单词)=(w1+w2+……+wn)/n
(1)
其中,tf(i)表示词i在整个文本中出现的词数,df(i)表示出现词i的文本数,D表示文本总数,n表示该句中出现的词数;同时考虑句子在文本中出现的位置,一般说来文本开头和结尾的句子比较重要赋予权重为1,首尾依次递减1 /M。即
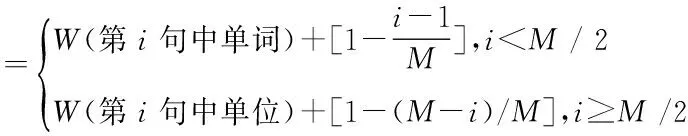
(2)
5)特征选择。根据步骤4可以得到的每篇文本权重最大的五个句子,再从全局考虑用TF-IDF计算单词权重,从而选出特征词。
(3)
其中N表示句中的总词数,nt表示词t出现的次数,D表示文本总数,dt表示出现词t的文本数。
6)利用K-means聚类。文本集合为{X1,X2,…… ,Xn},其中Xi代表一个d维向量的文本。类别质心的计算方法是根据欧式距离对给定的聚类数K通过不断迭代直到质心不变,即将文本分为K类S={S1,S2,……,Sk}需要满足的终止条件是:
(4)
其中ui表示Si的平均值。
6实验结果及分析
6.1评价指标
本文主要通过以下四种方法来评估[15]聚类性能的好坏:准确率(Precision)、召回率(Recall)、Rand Index和F1值。
准确率反映的是聚类模型能正确发现热点的能力,召回率反映的是聚类模型发现热点的文本数与文本库中所有相关热点文本数的比例。
(5)
RI利用排列组合的原理对聚类算法性能进行评价。公式如下:
(6)
其中TP指同类文本正确地聚在一起;TN指不相同类文本正确地聚成了不同的类;FP指不相同类文本被错误地聚在一起;FN指同类文本错误地聚成了不相同类。与F1值不同,RI将准确率和召回率看的同等重要。
F1值也称调和均值,是准确率和召回率的平均值。公式如下:
(7)
6.2结果分析
本实验使用的文本是爬虫程序从新浪网上获取的有关环境、住房和违法三类新闻事件,然后经过人工过滤筛选出的322个文本作为本实验的测试数据,并做文本关键句提取前、后实验对比。
表1为直接对这322篇文章所有内容在不同特征维数上聚类的结果。从表中可以看出虽特征维数为100时,聚类效果最好,但F1值也只60 %。由于文本中包含许多噪声句从而导致聚类结果不是很理想。
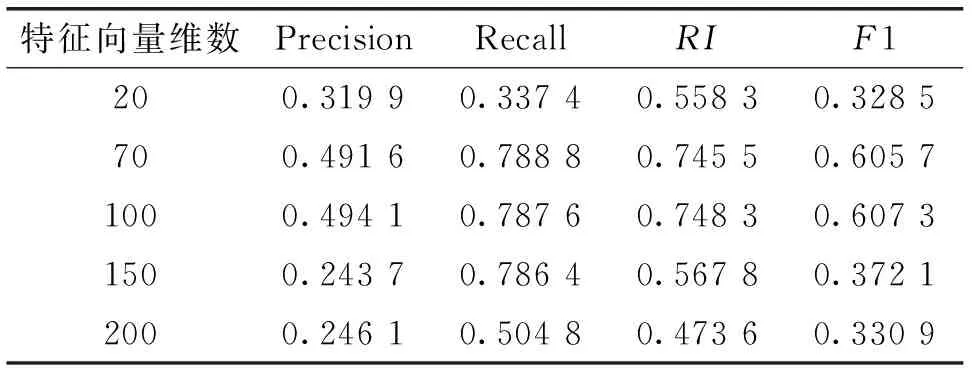
表1 基于全文的聚类结果
表2 为对这322篇文本提取文本关键句后,不同特征维数上的聚类结果。从表中可以看出:提取文本关键句后再聚类,特征向量维数明显降低,提高了计算速度;当特征向量取50维时,聚类准确率高达80.53 %,F1值也明显高于前者达77.9 %,聚类的性能和稳定性得到了提升。
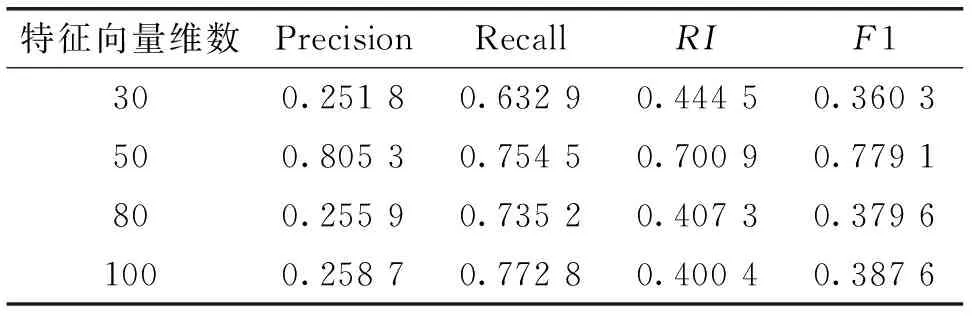
表2 基于关键句的聚类结果
通过以上两个实验可以知道:在热点发现方面,先提取文本的关键句后再聚类比直接对文本进行聚类的效果要好,并且随着特征向量维数的增加聚类准确率也随之增加;但是当特征向量维数增加到一定数量的时候,聚类的准确率不仅没有增长,反而下降。
6.3误差分析
主要从文本和关键句两个方面分析误差:
1)训练文本分布不均匀。三个类别的文本数不相等,而且这些数据是人工进行标注的,难以避免主观思想的左右,导致标类时就不准确。
2)文章关键句选择上的误差。在提取文本关键句时选出的句子并不是很理想,包含噪声而且每篇文本的长短不一,具体取多少句子能恰到好处地表示文本,这些方面有待进一步深度思考。
以上就是为什么本文聚类的准确率只有70 %左右的原因之一。
7总结
本文从新浪网获取的环境、住房和违法三类数据出发,分析聚类在热点发现领域中的应用。以文本的关键句作为核心数据分析K-means聚类的准确性。从结果可以看出用文本的关键句进行聚类比直接用全部文本内容进行聚类的效果要好。在未来的工作中,将从以下几个方面来改进:第一,在数据获取方面,尽量获取比较纯的文本而且文本类别分类很清楚,不存在类别模棱两可的文本。第二,对于每一篇文本,怎样才能取到合适的句子准确的表达该篇文本的内容?第三,在特征选择方面,如何降低噪声词的影响,使用更低维特征向量就能把表示不相同类的文本信息。
参考文献【REFERENCES】
[1]王伟,许鑫.基于聚类的网络舆情热点发现及分析[J].现代图书情报技术,2009(03)74-79.
WANG W,XU X.Online public Opinion hotspot detection and analysis based on document clustering[J].New Technology of Library and Information Service,2009(03)74-79.
[2]郑军.网络舆情监控的热点发现算法研究[D].哈尔滨工程大学,2007.
[3]王千,王成,冯振元,等.K-means聚类算法研究综述[J].电子设计工程,2012(07)21-24.
WANG Q,WANG C,FENG Z Y,et al.Review of K-means clustering algorithm[J].Electronic Design Engineering,2012(07)21-24.
[4]盛宇.基于微博的学科热点发现、追踪与分析——以数据挖掘领域为例[J].图书情报工作,2012(08)32-37.
SHENG Y.Subject hotspots discovery,tracking and analysis based on microblog-take the field of data mining as an example[J].Library and Information Service,2012(08)32-37.
[5]刘宏哲.文本语义相似度计算方法研究[D].北京交通大学,2012.
LIU H Z.Research on semantic similarity measurement for text[D].Beijing Jiaotong University,2012.
[6]高滢.多关系聚类分析方法研究[D].吉林大学,2008.
GAO Y.Research on Multi-relational clustering analysis approaches[D].Changchun:Jilin University,2008.
[7]焦芬芬.基于概念和语义相似度的文本聚类算法[J].计算机工程与应用,2012(18)136-141.
JIAO F F.Clustering method based on concept and semantic similarity[J].Computer Engineering and Applications,2012(18)136-141.
[8]冯永,李华,吴中福,等.基于扩展语义网的知识资源组织技术研究[J].计算机科学,2008(03)139-141+185.
FENG Y,LI H,WU Z F,et al.Knowledge resources organization technology research based on expended semantic web[J].Computer Science,2008(03)139-141+185.
[9]姜洪强.基于语义Web文档的索引技术研究[D].北京工业大学,2010.
[10]WANG J D,ZENG H J,CHEN Z,et al.ReCoM:reinforcement clustering of multi-type interrelated data objects[C] // Proceeding of the 26th annual international ACM SIGIR conference on Research and development in information retrieval.New York:ACM Publisher,2003:274-281.
[11]LONG B,ZHANG M,WU X,et al.Spectral clustering for multi-type relational data[C] // Proceedings of the 23rd International Conference on Machine Learning.New York:ACM Publisher,2006:585-592.
[12]段明秀.层次聚类算法的研究及应用[D].中南大学,2009.
[13]韩敏,唐常杰,段磊,等.基于TF-IDF相似度的标签聚类方法[J].计算机科学与探索,2010(03)240-246.
HAN M,TANG C J,DUAN L,et al.TI-IDF similarity based method for tag clustering[J].Journal of Forntiers of computer science & Technology,2010(03)240-246.
[14]申彦.大规模数据集高效数据挖掘算法研究[D].江苏大学,2013.
SHEN Y.The research of high effcient data mining algorithms for massive data sets[D].Xhenjiang:Jiangsu University,2013.
[15]李航.统计学习方法[M].北京:清华大学出版社,2012.
收稿日期:2016-03-31;修回日期:2016-04-13
作者简介:顾俊(1989-),男(汉族),安徽马鞍山人,贵州师范大学,研究生,主要从事自然语言处理研究。
中图分类号:TP391.1;N37
文献标识码:B
文章编号:1003-6563(2016)03-0093-04
The research and application of K - Means algorithm based on key sentence in the field of hot spots
GU Jun
(GuiZhouNormalUniversity,MathematicsandComputerScience,Guiyang550001,China)
Abstract:Due to the proposing of Internet +,network information shows the tendency of explosion.How to accurately find a hot issue in the face of massive data has become a concern of Internet users.This paper starts from the practical application,firstly five sentences are selected from every text as the key sentences;then TF-IDF is used to calculate the weight of characteristic words and the weight of a word wouldn’t be taken into account when selecting feature vectors;Lastly it utilizes K-means algorithm for clustering.Taking Sina News as an example,three kinds of topics including Environment,Housing and Illegitimacy contain 322 texts totally,which are clustered as test corpus,and clustering preparation rate reaches more than 70 %.The result shows that the key sentence extraction is better than that of the whole text as hot spot of clustering object.
Keywords:text mining,TF-IDF,cluster,K-Means
