基于K-Means的软子空间聚类算法研究综述*
2016-06-21李俊丽
李俊丽
(晋中学院信息技术与工程学院 晋中 030619)
基于K-Means的软子空间聚类算法研究综述*
李俊丽
(晋中学院信息技术与工程学院晋中030619)
摘要随着数据挖掘技术的发展,聚类分析算法越来越多,由于分析高维数据有时会陷入所谓维灾难,传统的聚类算法在聚类高维数据时性能会降低很多。针对这种情况,提出了子空间聚类算法,极大地改善了这个问题。K-Means算法是一种应用很广泛的聚类算法,与子空间聚类算法结合可以应用于高维数据聚类。介绍了三类基于K-Means的软子空间聚类算法,并对每种算法进行了描述和分析,最后指出了进一步的研究方向。
关键词K-Means算法; 软子空间聚类; 高维数据聚类
Class NumberTP301
1引言
聚类分析[1~2]将数据划分成有意义或有用的簇,是解决数据汇总问题的起点,在广泛的领域扮演重要角色。这些领域包括心理学和其他社会科学、生物学、统计学、模式识别、信息检索、机器学习和数据挖掘。在过去的几十年中,将聚类的不同类型区分为:层次的(嵌套的)与划分的(非嵌套的),互斥的、重叠的与模糊的,完全的与部分的等。 K-Means算法[3]是一种基于原型的、划分的聚类技术,由于其算法思想比较简单,聚类速度较快,且方便处理大量数据而得到了广泛的应用。但是随着数据发展的维数越来越高,K-Means聚类算法和其他传统的算法一样,在聚类高维数据时性能会降低很多。
在高维数据中,簇通常是嵌入在原始数据空间的子空间,且不同的簇可以嵌入到不同的子空间中,所以子空间聚类方法在高维数据聚类中是必需的。子空间聚类算法是从高维数据空间中发现隐藏在不同低维子空间中的簇类。很多文献提出了许多子空间聚类算法来处理高维数据,旨在从子空间而不是整个数据空间发现簇类[4~5]。此类算法能有效减少数据冗余和不相关属性对聚类过程的干扰,从而提高在高维数据集上的聚类结果。将K均值聚类算法与子空间聚类相结合能够更好地应用在高维数据聚类中,从而克服了传统聚类技术的不足之处。
2K-Means算法与软子空间聚类
2.1K-Means算法
K-Means算法具有很长的历史,但是仍然是当前研究的重要课题。最早的K-Means算法由MacQueen提出。K-Means算法是一个经典的聚类算法,其算法基本思想:首先,从原始目标数据集合中,随机选择k个数据点作为初始的k个簇的中心,其中k是用户指定的参数,即所期望的簇的个数。然后,计算其他非中心的数据点到k个簇中心的距离,根据其与中心的距离,选取距离最近的簇类,然后把该数据点分配到这个簇中,不断重复这个过程。最后当所有的点都被划到一个簇后,重新更新簇中心点,直到簇不发生变化为止。
K-Means算法的基本步骤如下:
输入:簇的个数k以及数据集合D
输出:满足条件的k个簇
step1. 从数据集D中随机选择k个点作为初始簇中心;
step2. repeat;
step3. 计算每个点与各个中心点的距离,把对象指派到最近的簇中心,形成K个簇;
step4. 重新计算每个簇的均值,作为新的簇中心;
step5. until簇中心不再发生变化为止。
K-Means算法需要事先确定k的大小以及初始聚类中心,而且只能发现超球状的簇,对初始中心非常敏感。对K-Means算法的改进主要从确定k的大小以及k个初始中心的选择等方面进行。
Bradley和Fayyad以某种方式处理了K-Means算法的初始化问题[6],Anderberg[7]、Jain和Dubes[8]的书详细地介绍了K-Means算法和它的一些变形。
2.2软子空间聚类
软子空间聚类算法是通过对各个数据簇类中的单个特征加权,获得每个数据特征的重要性,从而发现大权重的特征所在的子空间[9~11]。相比较于硬子空间聚类算法来说,由于对数据的处理有更好的灵活性与适应性,人们对软子空间聚类算法的关注越来越多。
为了更好地获得每个簇类所在的最佳子空间,人们将K-Means聚类算法与软子空间聚类算法相结合,采用了经典的K-Means型算法的结构,并且在其基础之上增加了一个迭代的步骤来计算加权公式,从而得出每个簇类及其相关联的维度的权重集合,然后更新权值向量。
3基于K-Means的软子空间聚类算法
3.1模糊加权软子空间聚类算法
2004年,E.Y. Chan等通过引入模糊权重指数和模糊加权指数,提出了模糊加权软子空间聚类算法[12],其目标函数定义如下:

JAWA =∑Ci=1∑Nj=1uij∑Dk=1wτikd(xjk,vik)
(1)
subject to

利用Lagrange乘子优化方法最小化公式得到算法模糊隶属度和特征加权系数的迭代公式。这是提出的第一个模糊加权软子空间聚类算法。根据公式可以看出,若某个维度的距离为零时,上式就会失去意义。因此,2005年Jing L等给出了FWKM(Feature Weighting K-Means)算法[13],算法中提出了一个估算参数σ的公式,该算法在以上目标函数中加了一个取值足够小的估算参数σ,通过给维度的距离增加一个大于 0 的参数σ,避免了当距离为零时,计算中出现的不便。后来, Gan G等又提出了FSC( A fuzzy subspace algorithm for clustering high dimensional data),给出了另一个模糊加权软子空间聚类算法[14],该算法发现在子空间聚类中,每个维度的原始数据与每个簇以不同权重相关联。而且密度越高,分配到该维度的权重越大。也就是说,所有维度的原始数据与每个簇相关联,但他们关联的程度不同。此算法增加了设置参数,用来控制在计算距离中的关键程度。
模糊加权软子空间聚类算法运用模糊优化技术对目标函数优化,对于不同的数据集,根据需要对模糊指数的取值进行调整。因此,相比较于经典加权算法,模糊加权算法具有很好的适应性。
3.2熵加权软子空间聚类
熵加权软子空间聚类算法是通过将信息熵概念引入到软子空间聚类算法中,在一定程度上由信息熵控制聚类中的各权向量[15]。2006年,Carlotta Domeniconi等提出LAC(Locally adaptive metrics for clustering high dimensional data)算法[16],此算法在各个簇中给每个特征分配一个权值,使用一个迭代算法来最小化其目标函数,通过用一个固定的常量取代最大平均距离证明了算法的收敛性。2007年Jing L等提出EWSC(entropy weighting Subspace Clustering)算法[17],此算法是熵加权软子空间聚类算法的典型代表,其目标函数定义如下:
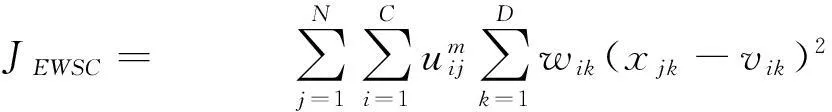
JEWSC= ∑Nj=1∑Ci=1umij∑Dk=1wik(xjk-vik)2
(2)
subject to

此算法扩展了K-Means聚类过程,在聚类过程中增加了一个额外的步骤,自动计算每个簇类的所有维度的权重。在大多数的软子空间聚类方法中,只考虑了类内信息,很少有算法考虑到软子空间聚类的类间信息。因此,2010年Deng ZH等提出 ESSC(Enhanced soft subspace clustering)算法[18],与其它软子空间聚类算法相比,该算法在聚类过程中采用了类内和类间两种信息,对于高维数据可以得到更好的聚类结果。
现有的子空间聚类算法仅对特征子空间进行聚类,没有考虑特征组权重的问题,在聚类高维数据时没有使用特征组的信息,以下介绍特征组加权,在加权子空间聚类的基础上,融入更多的特征组信息对改进现有的算法是很有意义的。
3.3特征组加权软子空间聚类
如果软子空间聚类在特征子空间上直接进行,特征组差异往往被忽略,而且特征子空间权重对噪声和缺失值比较敏感。此外,对于特征较少的特征组,特征较多的特征组将获得更多的权重。为了解决这个问题,X.Chen等引入了给特征组分配权值的概念,进而提出了一种新的子空间聚类算法称为FGKM算法[19]。此算法将相关特征聚集为特征组,在子空间同时进行特征组和单个特征的聚类,特征组加权减少了权重对噪声和缺失值的敏感性,通过引入特征组加权,能够消除特征组中的总体差异引起的不平衡现象。
这种算法中,高维数据基于它们的自然特性被分为特征组。算法给出一个新的优化模型定义优化过程。其目标函数定义如下:
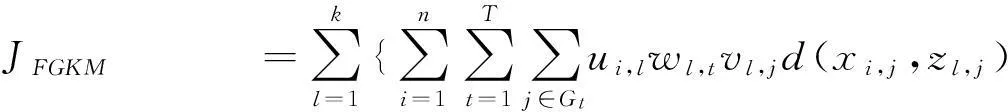
JFGKM =∑kl=1{∑ni=1∑Tt=1∑j∈Gtui,lwl,tvl,jd(xi,j,zl,j)
(3)
subject to
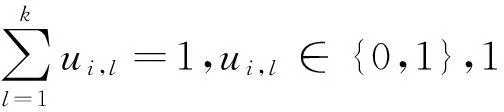

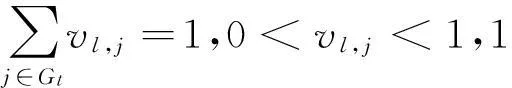
该算法通过在子空间中对特征组和单个特征进行加权,自动计算出两种类型的子空间熵。但是,FGKM算法的缺点是要求在聚类之前就确定特征组信息,而且在聚类过程中要作为输入给出。在大多数情况下,我们无法确定一个高维数据集特征组的信息。因此,G. Gan等在FGKM算法的基础上提出了AFGKM软子空间聚类算法[20],此算法能够在聚类迭代过程中自动确定特征组信息,通过加入特征组自动选择功能从而扩展了FGKM算法,AFGKM算法会产生比FGkM算法更准确的聚类结果。
4基于K-Means的软子空间聚类进一步研究方向
基于K-Means的软子空间聚类算法的共同特点是:首先定义目标函数,利用一些优化方法求出最小化的解;其次,经过推导得出权值向量的迭代计算公式;最后,目标函数是否有效决定了聚类结果的好坏。基于K-Means的算法都具有较好的扩展性,在计算高维数据时,具有较好的适用性。但是,其也继承了K-Means 算法的缺点,为了进一步提高算法的稳定性,选择适当的初始簇中心是其关键步骤。
因而进一步的研究工作归纳如下:
1) 对于高维数据而言,目前尚缺乏有效的初始簇中心选择的方法,选择初始簇中心的方法不同,聚类结果反差会很大。
2) 现有的算法在定义加权方式时都引入了一些难以确定的参数,需要用户提供专门的领域知识来设置它们的输入参数,而且不同簇使用了相同的参数,这样对于不同结构的簇,参数不能自动调节,致使算法的适用性降低了很多,算法对于不同聚类问题的泛化能力也降低了很多。
3) 现有的软子空间聚类算法大多数是不完备的,没有考虑到子空间的优化问题,而只是过多关心数据集划分的优化问题。
4) 现有的软子空间聚类算法都是基于批处理技术的聚类算法不能很好地应用于高维数据流。
5) 以上提到的算法还存在很多需要改进的地方,如参数设置的合理性,算法效率的提高等等。
5结语
软子空间聚类算法受到越来越多的关注,文中首先介绍了传统的K-Means聚类算法,然后在此基础上结合子空间聚类算法给出了几种基于K-Means的软子空间聚类算法,通过对每种算法进行了综述和分析,指出了一些不足之处,最后确定了进一步研究的方向,对以后的子空间聚类的研究有一定指导意义。
参 考 文 献
[1] Jiawei Han, Micheline Kamber.数据挖掘:概念与技术[M].范明,孟小峰,译.北京:机械工业出版社,2006.
[2] D.Hand, H.Mannila, P.Smyth.数据挖掘原理[M].张银奎,廖丽,宋俊,等译.北京:机械工业出版社,2003.
[3] J.MacQueen. Some methods for classification and analysis of multivariate observations[C]//Proc. of the 5th Berkeley Symp. On Mathematical Statistics and Classification, pages 345-375.World Scientific, Singapore, January,1996.
[4] L. Parsons, E. Haque, H. Liu, Subspace clustering for high dimensional data: a review[J]. ACM SIGKDD Explorations Newsletter,2004,6(1):90-105.
[5] H. Kriegel, P. Kroger, A. Zimek, Clustering high-dimensional data: a survey on subspace clustering, pattern based clustering, and correlation clustering[J]. ACM Transactions on Knowledge Discovery from Data,2009,3(1):1-58.
[6] P.S.Bradley and U.M.Fayyad. Refining Initial Points for K-Means Clustering[C]//Proc. of the 15th Intl. Conf. on Machine Learning, pages 91-99, Madison, WI, July 1998. Morgan Kaufmann Publishers Inc.
[7] M. R. Anderberg. Cluster Analysis for Applications[M]. New York: Academic Press, New York,1973.
[8] A. K. Jain and R. C. Dubes. Algorithms for Clustering Data. Prentice Hall Advanced Reference Series[M]. New York: Prentice Hall,1988.
[9] C. Bouveyron, S. Girard, C. Schmid, High dimensional data clustering[J]. Computational Statistics & Data Analysis,2007,52(1):502-519.
[10] C.-Y. Tsai, C.-C. Chiu, Developing a feature weight self-adjustment mechanism for a k-means clustering algorithm[J]. Computational Statistics & Data Analysis,2008,52(10):4658-4672.
[11] G. Milligan, A validation study of a variable weighting algorithm for cluster analysis[J]. Journal of Classification,1989,6(1):53-71.
[12] E.Y. Chan, W.K. Ching, M.K. Ng, and J.Z. Huang, An Optimization Algorithm for Clustering Using Weighted Dissimilarity Measures[J], Pattern Recognition,2004,37(5):943-952.
[13] L. Jing, M.K. Ng, J. Xu, J.Z. Huang, Subspace Clustering of Text Documents with Feature Weighting k-Means Algorithm[C]//Proc. Ninth Pacific-Asia Conf. Knowledge Discovery and Data Mining,2005:802-812.
[14] G.J. Gan, J.H. Wu, A convergence theorem for the fuzzy subspace clustering (FSC) algorithm[J]. Pattern Recognition,2008,41:1939-1947.
[15] H. Cheng, K.A. Hua, K. Vu, Constrained locally weighted clustering[C]//Proceedings of the VLDB Endowment, vol. 1, Auckland, New Zealand,2008:90-101.
[16] C. Domeniconi, D. Gunopulos, S. Ma, B. Yan, M. Al-Razgan, and D. Papadopoulos, Locally Adaptive Metrics for Clustering High Dimensional Data[J]. Data Mining and Knowledge Discovery,2007,14:63-97.
[17] L.P. Jing, M.K. Ng, Z.X. Huang, An Entropy Weighting k-Means Algorithm for Subspace Clustering of High-Dimensional Sparse Data[J], IEEE Trans. on Knowledge & Data Eng,2007,19(8):1026-1041.
[18] Z.H. Deng, K.S. Choi, F.L. Chung and S.T. Wang, Enhanced soft subspace clustering integrating within-cluster and between-cluster information[J], Pattern Recognition,2010,43:767-781.
[19] X. Chen, Y. Ye, X. Xu, J.Z. Huang. A feature group weighting method for subspace clustering of high-dimensional data[J]. Pattern Recognition,2012,45(1):434-446.
[20] Guojun Gan, Michael Kwok-Po Ng. Subspace clustering with automatic feature grouping[J]. Pattern Recognition,2015,48:3703-3713.
Summary of Soft Subspace Clustering Algorithm Based on K-Means
LI Junli
( School of Information Technology and Engineering, Jinzhong College, Jinzhong030619)
AbstractWith the development of data mining, clustering algorithm is becoming more and more. The difficulties associated with analyzing high-dimensional data are sometimes referred to as the curse of dimensionality. So the performance of traditional clustering algorithm in high-dimensional data clustering will reduce a lot. For this situation, subspace clustering algorithm greatly improves the problem . K-Means algorithm is a widely used clustering algorithm. Combined with subspace clustering algorithm it can be applied to high-dimensional data clustering. This paper introduces three kinds of soft subspace clustering algorithm based on K-Means, then each algorithm is summarized and analyzed. Finally it points out the future research direction.
Key WordsK-Means algorithm, soft subspace clustering, high-dimensional data clustering
* 收稿日期:2015年11月7日,修回日期:2015年12月23日
作者简介:李俊丽,女,讲师,硕士,研究方向:数据挖掘。
中图分类号TP301
DOI:10.3969/j.issn.1672-9730.2016.05.011
