张量分解在用户影响力度量中的应用
2016-05-26唐昌宏
唐昌宏, 刘 月
(1. 福州大学数学与计算机科学学院, 福建 福州 350116;2. 福建省网络计算与智能信息处理重点实验室, 福建 福州 350116)
张量分解在用户影响力度量中的应用
唐昌宏1, 2, 刘 月1
(1. 福州大学数学与计算机科学学院, 福建 福州350116;2. 福建省网络计算与智能信息处理重点实验室, 福建 福州350116)
摘要:提出一种基于张量分解的有影响力用户识别算法. 该算法首先构建基于查询主题的用户交互关系张量, 接着利用张量分解算法对用户行为进行预测, 最后融合各种交互关系和用户的主题信息给出用户影响力的综合评判. 实验结果表明, 与非负矩阵分解相比, 张量分解的挖掘精度提升了约10%, 而与PageRank相比, 张量分解的挖掘精度提升了约20%.
关键词:用户影响力; 主题相关度; 互关系; 张量; 社交媒介
0引言
社会影响力已成为制约社交网络的动态演化过程、 社交网络结构以及用户行为的至关重要的因素[1]. 研究网络中用户的社会影响力有着十分广阔的应用前景, 如: 用户分类[2]、 个性化推荐[1, 3]等. 当前的研究工作主要有两大类: 基于PageRank的方法[2, 4-5]、 基于矩阵[1, 3, 6]或张量的方法[7-9]. 基于PageRank的方法假设用户的影响力由好友的影响力所决定, 认为好友的影响力大, 则该用户也可能有较大影响力. 基于矩阵或张量的方法则把用户的交互行为用潜在的公共行为来描述, 通过解析潜在行为来推测用户的交互关系强度. 然而, 社交网络上, 用户与用户之间往往具有多种交互关系, 并且不同用户关注的领域是不同的, 当前的方法没有充分利用社交媒介上用户的各种交互关系信息以及用户的主题信息. 针对当前方法的不足, 我们将考虑用户的交互信息以及用户与查询主题之间的相关度, 以期望提高用户挖掘的精度. 本研究提出一种基于张量分解的用户影响力度量方法. 该方法将用户的多种交互关系行为表示成几个公共的潜在行为, 提取用户潜在行为结构, 而且具有直观的行为解释.
1相关工作
社交媒介上用户影响力分析是通过利用社交媒介上的用户信息来推断用户在网络上的影响力. 当前的研究工作主要有两大类:
1) 基于PageRank的方法. N Agarwal等[10]关注有影响力博主的识别, 通过考虑用户内容的评论数量、 内容发起的讨论规模、 出链数、 入链数以及内容的长度等因素, 以PageRank算法为基础, 建立一个有影响力博主的识别模型. K K Cai等[2]利用用户回复信息中的观点倾向性, 将用户的影响力分为积极、 消极和中性, 通过用户间的回复关系建立图模型, 并用迭代方式确定出用户的影响力大小. 张碉等[4]以主题为单位, 提取用户间的回复关系, 构建用户对话关联图, 在PageRank算法基础上, 提出基于多属性的用户影响力排序算法, 并进一步分析了用户影响力的演化趋势.
2) 基于矩阵或张量的方法. P Cui等[3]则利用用户的点击以及用户间的好友关系与内容分享关系构造用户-帖子关系矩阵, 并利用概率混合因素矩阵分解(PHFMF)的方法, 实现对用户影响力的挖掘. S Moghaddam等[7]利用产品的评论评级信息挖掘产品评论的质量, 作者通过“评级—评论者—产品”交互信息构建三阶张量, 并利用张量分解技术实现对产品评论质量的估计. M Nickel等[8]主要介绍融合多种交互关系的张量模型, 并通过矩阵分解技术对原始张量进行降维处理, 减小了计算时的数据规模.
针对融合多种交互关系信息度量用户影响力的问题, 本研究提出一种基于张量分解的影响力用户识别方法. 首先, 将社交媒介上用户的多种交互关系表示成张量. 其次, 用融合多种用户交互关系的RESCAL张量分解算法[8]给出用户交互行为强度的预测. 最后, 融合用户主题与交互关系信息, 对用户影响力进行综合评价, 并实现对用户的排名.
2基于张量分解的用户影响力度量模型
2.1问题描述
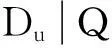
2.2基于多种交互关系的三阶张量模型
社交媒介中, 用户的影响力可以由一些潜在的行为来刻画, 本研究将介绍一种基于RESCAL张量分解的方法来预测用户之间的交互关系强度.
首先, 使用RESCAL张量分解必须满足以下两个条件:
条件1: RESCAL张量分解方法要求被分解的三阶张量的前两维的维数必须相同. 张量所描述的必须是同一个实体集合中两两实体间的若干种关系. 而本研究要描述的恰恰是同一批用户集合中两两用户之间的多种交互关系.
条件2: 张量中每一个元素的取值是非负的. 本研究处理的是用户之间的交互关系, 即: 粉丝数、 评论数、 主题相关度等, 这些取值均满足非负条件.
其次, 社交网络上用户的信息除了自身的微博内容信息外, 还有很多交互信息, 如: 用户之间的粉丝关系、 关注关系、 用户对用户微博的转发、 评论关系等. 这些用户之间的交互信息一定程度上隐含了用户影响力的信息. 为充分利用这些用户之间的交互信息, 并对这些信息进行量化表示, 引入三阶张量. 三阶张量在形式上类似于三维数组, 可以形式化地写为Z=(zijk)N×N×M, 其中:N为用户数量,M为用户之间的交互关系数量. 张量中的每一个元素zijk可以解释为: 第i个用户和第j个用户在第k种交互关系上的取值. 因此, 三阶张量对用户之间的各种社交关系有较强的解释性.
将社交媒介上多种用户交互关系构建成基于查询主题的用户交互关系张量; 接着利用融合多种交互关系的RESCAL张量分解算法[7]对用户的社交行为强度进行预测; 然后, 融合用户的各种交互关系强度和用户的主题信息给出用户影响力的综合评判, 并利用影响力评判值给出用户的排序列表.
2.2.1RESCAL张量分解原理
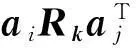
根据上述的说明, 张量的第k层矩阵可近似表示为: Zk≈ARkAT. 因此, 整个张量的估计问题可以转化为如下的优化问题:
(1)
进一步地, 为了避免优化过程中出现的过拟合问题, 可以将上述优化问题修正为如下形式:
(2)
2.2.2融合多种交互关系的用户张量
设Z∈RN×N×M表示用户交互关系张量,N为用户数,M为交互关系数, 张量元素zijk表示用户ui与uj在第k种关系上的强度. 为构建融合多种社交关系的用户张量, 首先给出用户交互关系的度量:
1) 粉丝、 评论关系. 如果网络中的用户数量为N, 则令: IA=(Iij)N×N为用户粉丝关系指示矩阵, 即:
(3)
2) 用户关注关系. 假定用户U(i)的粉丝数用F(i)来表示, 则U(i)在粉丝关系上对U(j)的影响可用如下公式来衡量:
(4)
如果U(i)是U(j)的粉丝, 且U(i)的粉丝数很大, 那么U(j)也很有可能有较大的粉丝数.
3) 用户微博的评论关系. 如果用户U(i)的微博收到的评论数为review(i), 则U(i)在评论关系上对U(j)的影响可用如下公式来衡量:
(5)
4) 用户间的主题关系. 以“篮球”这一主题为例, 提取用户常用的144个篮球词汇, 如表1所示.

表1 篮球相关的部分关键词
利用BM25模型[11]确定用户和主题间的相关度. 计算方法如下:
设Q={q1, q2, …, qm}为查询主题, D={d1, d2, …, dN}为文档集合,BM25算法就是计算中每个文档dj与查 询主题之间的相关性.BM25算法公式如下:
(6)
假定用户U (i)的主题相关度记为topic(i), 则U (i)在主题关系上对U (j)的影响可用如下公式来衡量:
(7)
5) 基于多种交互关系用户张量. 用户张量由三个关系矩阵组成, 分别用Y1, Y2, Y3表示, 含义如下:
粉丝层:
(8)
评论层:
(9)
主题层:
(10)
为了统一张量的量纲, 可以对张量进行归一化处理, 处理方法如下:
(11)
2.2.3融合多种交互关系的RESCAL张量分解
根据RESCAL张量分解算法原理, 用户张量就可以近似地表示为: Z≈ARAT.
上述分解式中, A与R的估计等价于如下优化问题:
(12)
张量分解算法如图1所示.
图1张量分解算法
Fig.1Tensorfactorizationalgorithm
2.2.4基于张量分解的用户综合影响力度量
根据上述定义, 张量Z=(zijk)N×N×3每层的含义不同, 要针对每一层张量的含义逐层定义用户的影响力.
令ufjk表示U(i)在第k种关系下的影响力. 根据J S Weng等[5]的观点, 用户影响力取决于好友的总影响力. 因此, 用户影响力可按如下方式定义:
好友的粉丝数总和(ufi1) :
(13)
好友的评论数总和(ufi2):
(14)
好友的主题相关度总和(ufi3):
(15)
可以定义用户在查询主题下的综合影响力得分如下:
(16)
由公式可知, 只有用户的主题相关度和交互关系强度均比较大时, 用户的综合影响力得分才会比较大.
3实验结果与分析
3.1实验设计
实验数据来自新浪微博, 共采集了624个用户, 50 219条评论, 包含523对评论关系和777对粉丝关系.
首先, 先对基准方法的选择给出说明:
1)PageRank算法.PageRank用于衡量特定网页相对于搜索引擎索引中的其他网页而言的重要程度, 实现了将链接价值概念作为排名因素.PageRank是目前度量影响力比较热门的方法, 如:KKCai[2]、 张碉[4]、NAgarwal等[10]都以PageRank算法为基础度量网络用户影响力.
2) 非负矩阵分解算法(NMF). 目前矩阵分解方法已在用户或产品推荐领域得到了广泛的应用. 主要是利用用户—产品、 用户—用户或者产品—产品之间的交互信息来确定推荐项目.PCui[3]、SMoghaddam[7]、MNickel等[8]已经在这方面做了很多有价值的工作.
然后, 人工筛选了与篮球有关的前15名有影响力的用户. 并以PageRank、 非负矩阵分解为基准方法, 分别计算出PageRank、 非负矩阵分解和张量分解方法给出的有影响力用户的列表; 将PageRank、 非负矩阵分解和张量分解方法得到的用户列表分别与人工排序的结果进行比较.
3.2评价指标
1) 张量分解精度指标RMSE.
(17)
该指标反映了原始数据与张量分解后的预测数据之间的平均偏差.
2) 用户排序精度指标.
(18)
其中: Ak为人工排序中的前名用户集; Bk为实验排序中的前名用户集. 该指标反映了前名实验排序与人工排序的吻合程度.
3.3实验结果及分析
1) 在探索不同用户主题信息间的差异时, 我们画出了用户主题相关度的分布图, 如图2所示. 其中: 横坐标表示主题相关度, 纵坐标表示用户数.
从图2可以看出, 社交网络中真正与查询主题相关的用户仅占全部用户的极少部分. 因此, 通过考虑查询主题来挖掘用户影响力是有意义的.
2) 在图1所述的张量分解算法中, 最优潜在特征数需要根据实际情况来确定. 现有文献中对于这个参数的一般确定方法如下:
Step1: 取K=1, 2, 3, …, 利用分解算法, 分别计算出不同潜在特征数对应的用户潜在特征矩阵A(1), A(2), A(3), …, 以及中心张量R(1), R(2), R(3), …;
Step2: 分别计算不同潜在特征数下的张量预测值Xpredict(K)=A(K)TR(K)A(K);
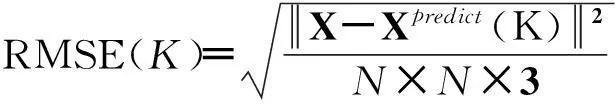
由上述步骤, 可得到K值(横坐标)与RMSE(纵坐标)之间的关系, 如图3所示. 可见, 随着K的增大, 误差RMSE不断减小, 当K=4时模型误差达到最小值. 因此, 对于这批数据而言, 应该取4个潜在特征最为合适.
3) 利用人工筛选的列表, 将张量分解方法得到的用户列表与PageRank以及NMF方法得到的用户列表进行比较, 结果如图4所示. 由结果可知: 用张量分解方法做影响力用户的挖掘任务时, 结果优于NMF方法及PageRank方法.
4结语
针对融合多种交互关系度量用户影响力的问题, 提出一种基于张量分解的影响力用户识别方法. 首先, 利用张量来描述用户间的各种交互关系. 其次, 利用RESCAL分解算法对用户交互行为进行解构. 最后, 给出融合多种交互关系和主题信息的影响力公式, 并给出用户排序列表. 实验表明, 与PageRank和非负矩阵分解相比, 融入主题的张量分解方法在影响力用户挖掘问题上更加有效.
参考文献:
[1]CUIP,WANGF.Item-levelsocialinfluencepredictionwithprobabilistichybridfactormatrixfactorization[C]//Twenty-FifthAAAIConferenceonArtificialIntelligence.NewYork:ACM, 2011: 331-336.
[2]CAIKK,BAOSH,YANGZ, et al.Anopinionorientedlinkanalysismodelforinfluencepersonadiscovery[C]//ProceedingsoftheFourthACMInternationalConferenceonWebSearchandDataMining.NewYork:ACM, 2011: 645-654.
[3]CuiP,WANGF,LIUSW, et al.Whoshouldsharewhat,Item-levelsocialinfluencepredictionforusersandpostsranking[C]//Proceedingsofthe34thInternationalACMSIGIRConferenceonResearchandDevelopmentinInformationRetrieval.NewYork:ACM, 2011: 185-194.
[4] 张碉, 张宏莉, 张伟哲, 等. 识别网络论坛中有影响力用户[J]. 计算机研究与发展, 2013(10): 2 195-2 205.
[5]WENGJS,LIMEP,JIANGJ, et al.TwitterRank:findingtopic-sensitiveinfluentialtwitterers[C]//ProcofWSDM.NewYork:ACM, 2010: 261-270.
[6]JAMALIM,ESTERM.Amatrixfactorizationtechniquewithtrustpropagationforrecommendationinsocialnetworks[C]//ProceedingsoftheFourthACMConferenceonRecommenderSystems.NewYork:ACM, 2010: 135-142.
[7]MOGHADDAMS,JAMALIM,ESTERM.Extendedtensorfactorizationmodelforpersonalizingpredictionofreviewhelpfulness[C]//ProceedingsoftheFifthACMInternationalConferenceonWebSearchandDataMining.NewYork:ACM, 2012: 163-172.
[8]NICKELM,TRESPV,KRIEGELHP.FactorizingYAGOscalablemachinelearningforlinkeddata[C]//Proceedingsofthe21stInternationalConferenceonWorldWideWeb.NewYork:ACM, 2012: 271-280.
[9]WEIJJ,TANGCH,LIAOXW, et al.Miningsocialinfluenceinmicrobloggingviatensorfactorizationapproach[C]//ProceedingsoftheInternationalConferenceonCloudComputingandBigData.Fuzhou: [s.n.], 2013: 583-591.
[10]AGARWALN,LIUH,TANGL, et al.Identifyingtheinfluentialbloggersinacommunity[C]//ProceedingsoftheInternationalConferenceonWebSearchandDataMining.NewYork:ACM, 2008: 207-218.
[11]ROBERTSONS,ZARAGOZAH,TAYLORM.SimpleBM25extensiontomultipleweightedfields[C]//ProceedingsofthethirteenthACMInternationalConferenceonInformationandKnowledgeManagement.NewYork:ACM, 2004: 42-49.
(责任编辑: 沈芸)
The application of tensor factorization on user influence measure
TANG Changhong1, 2, LIU Yue1
(1. College of Mathematics and Computer Science, Fuzhou University, Fuzhou, Fujian 350116, China;2. Fujian Provincial Key Laboratory of Network Computing and Intelligent Information Processing, Fuzhou, Fujian 350116, China)
Abstract:This paper proposes a method for identifying influential users based on tensor factorization (TF). This method fitst constructs interaction tensor based on the topic. Then, we extract the user behavior by factorizing the tensor. Finally, the users’ influences are evaluated by comprehensively considering the topic and interaction information between users. The experiments shows that, compared with NMF and PageRank method, the accuracy of TF method can increase by 10% and 20%, respectively.
Keywords:user influence; topic relevance; interactive relationship; tensor; social media
中图分类号:TP391
文献标识码:A
基金项目:国家自然科学基金资助项目(61300105); 教育部博士点基金资助项目(2012351410010); 福建省科技重大专项基金资助项目(2013H6012); 福州市科技计划资助项目(2012-G-113, 2013-PT-45)
通讯作者:刘月(1984-), 副教授, 主要从事矩阵论研究, liuyue@fzu.edu.cn
收稿日期:2014-05-14
文章编号:1000-2243(2016)02-0176-06
DOI:10.7631/issn.1000-2243.2016.02.0176
