基于Hadoop的分布式搜索引擎设计与实现*
2016-04-12柏雪桂林理工大学图书馆广西桂林541004
柏雪(桂林理工大学图书馆,广西桂林541004)
基于Hadoop的分布式搜索引擎设计与实现*
柏雪
(桂林理工大学图书馆,广西桂林541004)
[摘要]针对分布式搜索引擎的研究现状和技术背景进行分析,提出基于Hadoop的分布式Lucene搜索引擎的功能模型与系统构架。从系统实现的分布式索引、分布式检索和第三方分词器3个方面的关键技术进行详细叙述,搭建具体实验实施的软件、硬件环境,并运用对比的方法,进行分布式搜索引擎的性能测试分析。实验结果表明:基于Ha⁃doop的分布式Lucene搜索引擎,在信息搜索的效率、可靠性、稳定性和可扩展性等方面,具有很强的优势。
[关键词]分布式Hadoop Lucene搜索引擎
[分类号]TP393
*本文系2015年度广西教育厅项目“随书光盘资源云服务平台开发应用研究”(项目编号:KY2015YB138);2013年度广西哲学社会科学规划研究课题基金项目“基于HADOOP大数据技术分布式信息检索系统的研究与实现”(项目编号:13FTQ003)阶段性成果。
1 引言
中国互联网络信息中心(CNNIC)的中国网民搜索行为研究报告指出,现今我国的搜索引擎用户规模达4.9亿。搜索引擎作为互联网的基础应用,已成为广大用户获取信息的重要工具。搜索引擎是指为用户提供检索服务,并将与检索信息相关的结果显示给用户的系统,即用户按照一定的策略使用网页抓取程序从互联网中采集信息,然后其进行分类组织和处理,用户仅需提交检索关键词等信息即可进行检索。搜索引擎能很好地解决用户对需要的数据资源进行快速且准确的检索,减小开发成本,提升信息服务的效益,提高信息资源的利用效率[1]。
然而,目前大部分查询检索系统是建立在数据库系统自带的查询命令基础上的,当数据量很大时,查询的响应效率会大幅下降,如何建设一个高效、有针对性的通用搜索引擎,是一个亟待解决的问题。笔者结合Hadoop[2]分布式平台的高可靠性、高可扩展性、高效性、高容错性,以及Lucene全文检索引擎的框架层次分明、应用程序接口简单、功能强大、可扩展性强的优势,设计一种基于Hadoop的分布式Lucene搜索引擎,并应用到馆内随书光盘应用服务系统,效果良好。
2 现状及技术背景
2.1国内外研究现状
关于搜索引擎的研究早在2000年就已经起步,一经提出,就迅速成为研究热点。搜索引擎分类方法有很多种[3],按运行机制分有集中式搜索引擎、分布式搜索引擎、代理搜索引擎等;按应用范围分有综合搜索引擎、垂直搜索引擎等。
国外关于搜索引擎的研究起步早、起点高、功能强大、系统完善,其中比较有代表性的有:①Elsevier公司开发的Sci⁃rus系统(学术信息搜索引擎),Scirus收录与科技相关的网站超过1.05亿个,包括9000万个网页,以及1700万个来自其他信息源的记录。②Melodis公司开发的Midomi系统(语音搜索引擎),采用了哼唱搜索技术,用户只需唱歌、哼歌(或者吹口哨)就可以方便地通过数据库检索到匹配的乐曲。③Zil⁃low系统(房地产垂直搜索引擎),免费向用户提供地产评估服务的房地产信息查询,用户可以通过卫星地图来查询目标,也可以使用邮编和街道地址进行搜索。
国内搜索引擎的研究起步则相对较晚,2005年之后才逐渐开始。近年来发展迅速,在旅游、求职、购物、家电、建材、家居、医疗健康、视频等各个领域都有所发展。如淘宝网推出购物搜索引擎——“一淘”,优酷推出视频搜索引擎——“搜库”等。搜索引擎的发展,也正向细分化、行业化的方向迅速发展,但所涉及的领域范围仍比较小,且在资源共享、接口开放、数据挖掘等技术层面与国外的研究还有很大差距。
2.2MapReduce编程模型
笔者的相关研究,需要使用Hadoop平台的MapReduce编程模型[4],故在此单独进行描述。MapReduce是一种数据处理的分布式编程模型,它在互联网应用、科学数据处理、商业智能数据分析等具有海量数据需求的领域,应用得越来越广泛。Hadoop可以运行各种语言编写的MapReduce程序,其在大规模数据集的处理方面具有绝对优势。MapReduce借鉴了Lisp函数式语言中的思想,用Map和Reduce两个函数提供高层的并行编程抽象模型和接口,其采用的是分而治之的处理思想和策略。MapReduce以数据为中心,把数据分割成小块供集群中的计算机分别计算,而后对计算结果进行汇总得出最终结论。MapReduce模型的输入和输出均为< key,value>集合,利用Map函数和Reduce函数处理数据,Map函数将一组
2.3Lucene搜索引擎
Lucene是Apache基金会研发的一个高度优化的开源全文搜索引擎工具包,虽然它并不是一个完整的搜索应用程序,但是它专注于文本的索引和搜索,提供了完整的索引引擎、查询引擎以及部分的文本分析引擎[5-6],并且为数据访问和管理提供简单的函数调用接口[7],因此能够方便地在此基础上进行研究和二次开发。该搜索引擎包含两个核心部分,即索引模块和搜索模块。当工作的准备阶段,需要对来自于Web、文件、数据库等数据源的结构化和非结构化数据进行文本提取将其转换成文本数据流;当文本数据流送入搜索模块时,调用文本分析工具对其进行分词,生成索引文件;当客户端提交查询关键字后,搜索模块调用文本分析工具对关键词进行分词,并生成数个或关系的查询请求,通过访问索引文件进行查询,返回满足查询条件的经过相关度排序的命中结果集。
3 功能模型与系统架构
3.1功能模型
分布式搜索引擎的设计目标是实现海量信息资源快速的、精确的分布式检索[8],该模型的功能主要包括:文本提取、分布式索引、分词、分布式检索、用户界面5个部分组成。其具体功能模型,如图1所示。
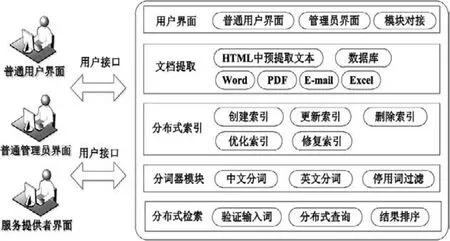
图1 分布式搜索引擎的功能模型
①文本提取:实现各种格式数据的预处理。由于Lucene只能处理文本文件,所以需要实现从HTML文件和非HTML文件(如数据库、PDF、Word、Excel、E-mail等)中提取文本的功能。
②分布式索引:实现索引的创建、更新、删除、优化和修复功能。搜索引擎建立在Hadoop分布式系统上,所以要考虑Lucene索引的分布式实现,需要重写接口和考虑索引的分布式存储和分发问题。
③分词器模块:针对中文,因为中文文本中词和词之间并不像英文那样存在着天然的分隔符,所以需要分词程序来解决中文分词准确度问题。
④分布式检索:首先对用户输入的关键词进行简单的合法性验证,然后进行分布式检索,对检索的结果进行分类和排序。
⑤用户界面:实现普通用户、管理员用户、服务提供者等,与相应的功能模块进行功能对接。
3.2系统架构
基于Hadoop的分布式搜索引擎的系统构架,本质上是借鉴Hadoop的分布式基础构架,并在此基础上进行利用和改进。主要是将数据存储在Hbase数据库中,索引文件分布式存储在集群中的HDFS分布式文件系统上,其具体的系统构架如图2所示。
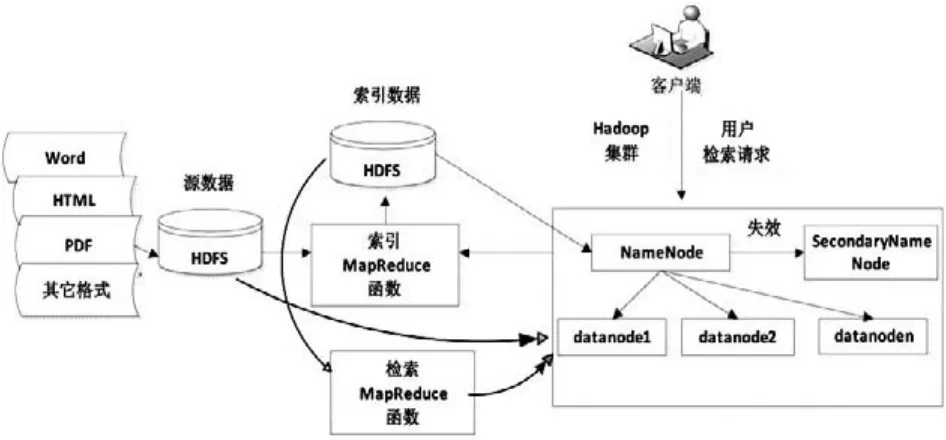
图2 基于Hadoop的分布式搜索引擎系统构架
基本原理是:搜索引擎运行在Hadoop分布式集群上,当对源数据进行预处理时,需要将其从数据库中取出,从中提取文本信息,然后将文本信息分布式存储在HDFS上,利用索引MapReduce函数为这些源文件批量建立分布式倒排索引,倒排索引文件同样存储在HDFS上;当客户端向NameNo⁃de提交检索请求时,通过检索MapReduce函数对索引文件进行分布式检索从而快速检索到用户所需要的数据然后返回给客户端[9]。
由信息存在诸多不同的格式,如HTML、Word、PDF、E-mail等,甚至有些信息形式是专有的,所需要检索的数据源既有结构化的,也有非结构化的,为了方便读写大数据内容,需将源数据存储在Hbase数据库中,生成的索引文件存储在HDFS分布式文件系统上。同时,需要注意的是Lucene只提供了一个通用的结构(Document对象)来接受索引的输入,所以,需要设计相应的解析转换函数,将数据库中Word文档、PDF文档、HTML文档等数据源构造成Lucene所支持的Document对象。
4 系统实现的关键技术分析[10-11]
4.1分布式索引
就集中式索引而言,当索引的数量太大时,索引更新和搜索效率会非常低。而基于Hadoop的分布式Lucene搜索引擎可以很好地解决这一问题。它利用MapReduce函数为经过文本提取模块所提取出的Document文档建立倒排索引。由于Lucene中的Document并不支持MapReduce输出类型的Writable接口,无法直接使用Document作为MapReduce的输出类型。所以,需要自定义了一个HDFSDocument类,来实现在Hadoop上建立Lucene索引的功能。
采用倒排索引建立索引的过程为:①读取数据,并对其进行解析,按照IndexMetaRule类所描述的Lucene的Docu⁃ment与Hbase的列的对应机制,将每个字段和值生成Field对象。②创建Document对象,并将生成的Field对象添加到Document中。③将文档加入索引器IndexWriter,利用索引器IndexWriter中的addDocument方法将文档加入索引器;利用DocumentWriter来完成索引的写入。
笔者基于Hadoop的分布式Lucene搜索引擎,对原有的索引方法进行了改进。Lucene中定义了抽象类Directory用于存储索引,Directory包含RAMDirectory和FSDirectory两个子类。RAMDirectory方式在内存中建立索引,写入速度快效率高,但关机后索引会丢失,且由于受内存容量的限制,无法一次性对所有文件进行索引,需要分批进行;FSDirectory方式在硬盘目录中创建索引文件,其优点是可以长期保存,缺点是需要与磁盘进行交互,频繁地I/O操作会导致索引速度较慢。通过将这两种方式相结合,先在内存中的RAMDirec⁃tory目录中建立索引,当索引数达到最大值时,对内存进行刷新,将内存中的索引文件批量的写入到磁盘中的FSDirec⁃tory目录中,这样既能够对索引进行长期存储,又能够大大减少对磁盘的访问,从而提高索引效率。
4.2分布式检索
分布式检索模块中的检索方法,与在单机上用Lucene进行检索的方法基本相同。不同点在于传统的搜索引擎在检索时,使用的是FSDirectory类来构建IndexReader,而分布式检索的过程,使用FSDirectory类,这个类封装原有检索类的方法,同时还支持HDFS系统。
分布式检索步骤为:①用户提交检索词,解析器QueryP⁃arser对检索词进行解析生成Query对象;②分别计算出每个检索关键词的文档频率DF和逆文档频率IDF;③根据IDF计算出其结果得分。这一步主要是由IndexSearcher来实现,但对IndexSearcher中的docFreq()和maxDoc()进行了继承和覆盖,返回值为DF和Document数量;④根据相关度排序算法将检索结果集Hits进行归并排序后显示给用户,并将结果写入缓存系统中。
4.3分词器工具包
Lucene自身提供的分词器中支持中文分词的有Standar⁃dAnalyzer分词器和CJKAnalyzer分词器。StandardAnalyzer分词器将每个字作为一个词,这样会出现分出来的词比较全面,但会产生大量的索引文件大大降低检索速度;CJKAna⁃lyzer分词器,按每两个字进行切分,会造成分词不准确问题。虽然这两个分词器都能实现基本的简单分词功能,但无法满足分布式搜索引擎实现的功能[12]。
基于Hadoop的分布式搜索引擎使用的第三方分词器工具包为mmseg4j。mmseg4j使用MMSeg算法是实现中文分词,MMSeg的算法是基于正向最大匹配,且已实现了Lucene 的analyzer,其词语的正确识别率达到了98.41%。同时,在文本的提取方面,分布式搜索引擎使用Apache POI工具包实现Word、Excel、Powerpoint格式的文本提取,利用PDFBox工具包提取PDF格式的文档文本,运用JTidy工具包来对HTML进行文本提取。
5 实验与性能测试分析
5.1实验硬件与软件环境设置
基于Hadoop的分布式搜索引擎的实验搭建环境为8台PC机:其中1台为NameNode和MapReduce编程模型的Job⁃Tracke;1台为SecondaryNameNode,6台作为DataNode和Ma⁃pReduce编程模型中的TaskTracker;同时,还配备了1台集中式的专业存储阵列,进行性能对比测试。涉及两个不同的硬件存储设备,其具体的参数如表1所示。
选取数据测试的软件环境为:
应用服务系统名称:CDBOOK随书光盘管理系统;网址:http://202.193.80.185;数据总量:5TB;光盘总数:14378种;网站访问量:483643人次;下载总量:4250534次。
5.2网络拓扑结构
应用平台的软硬件环境的网络拓扑结构,如图3所示。
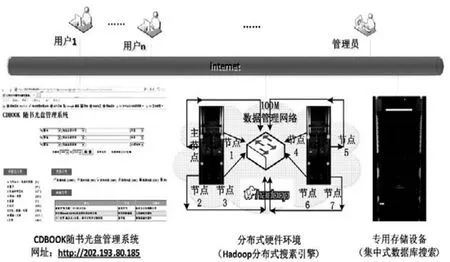
图3 网络拓扑结构
5.3测试分析与实验结论
实验的硬件与软件环境搭建完成后,分别用5TB的随书光盘数据对专用存储上的集中式搜索和多台PC组成的Ha⁃doop集群上的分布式搜索引擎之间的文件处理性能进行对比测试[13]。在测试的过程中,同时依次启动Hadoop集群的5个节点、6个节点和7个节点。其性能测试的结果如图4所示。
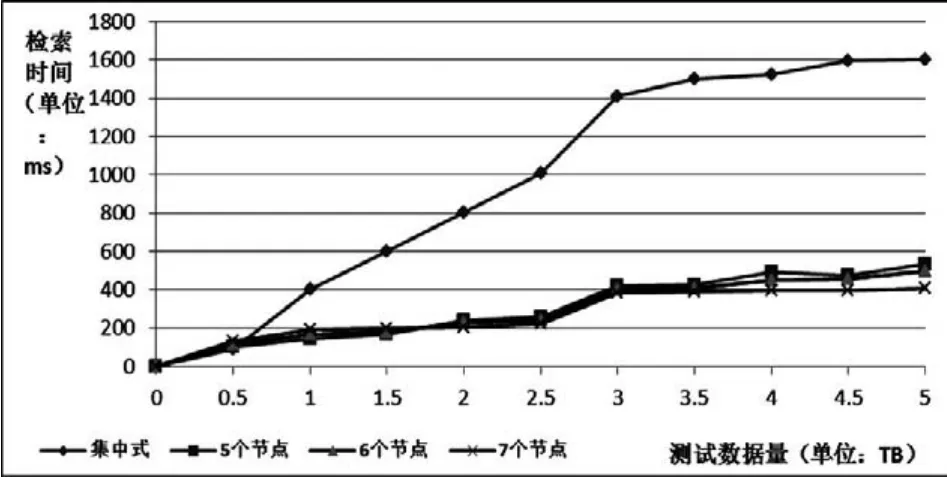
图4 分布式搜索引擎与集中式搜索检索性能对比
实验结论[14]:
①基于Hadoop的分布式搜索引擎在检索数据的过程中,启动不同的节点,或集群中有某个节点失效时,分布式的搜索引擎仍可以稳定地进行数据处理,这说明分布式的搜索引擎具有很高的可靠性能和稳定性能。同时,该搜索引擎也具有高可扩展性,集群可以很方便地进行节点扩展。
②当文件搜索的数据量较少时,分布式搜索引擎几乎和集中式搜索引擎性能几乎一样,甚至集中式要比分布式速度更快一些,这是由于分布式需要进行数据分块且节点间进行通信也需要耗费时间。但随着数据量的增加,分布式的优势逐渐显现出来,且数量级越大、分布的节点越多,分布式搜索引擎的性能优势也就越明显。特别是当文件量达到一定数量级时,单机的集中式检索会出现性能瓶颈,但对于分布式检索依然可以稳定运行,而且节点数量越多,数据处理速度越快。
6 结语
笔者建立的基于Hadoop的分布式Lucene搜索引擎,实现了图书馆随书光盘的高效、快速、精准、稳定的分布式搜索,大大提升了用户的应用体验,提高了信息服务的水平和质量。同时,该分布式的搜索引擎具有很好的二次开发和应用性;其自身搜索的可靠性、稳定性、可扩展、分布式等特点,也使得该引擎能很好地在其他应用服务系统的搜索中使用,并进行再开发与再移植,有很广阔的应用前景。
参考文献:
[1]张伟哲,等.分布式搜索引擎系统效能建模与评价[J].软件学报,2012(2):253-265.
[2]陈嘉恒.Hadoop实战[M].北京:机械工业出版社,2011.
[3]印鉴,邹胜.一种分布式搜索引擎设计[J].计算机科学,2001(10):74-77.
[4]Apache Hadoop[EB/OL]http://hadoop.apache.org/.
[5]Liu Chun,Guo Qing Ping.Analysis and Research of Web Chinese Retrieval System Based Lucene[J].Computer soci⁃ety,2009(12):1051-1055.
[6]Zhang Yong,Li Jian- lin.Research and Improvement of Search Engine Based on Lucene[C]∥International Confer⁃ence on Intelligent Human-Machine Systems and Cyber⁃netics.Zhejiang:[s.n.],2009:270-273.
[7]管建和,甘剑峰.基于Lucene全文检索引擎的应用研究与实现[J].计算机工程与设计,2007(2):12-16.
[8]夏敏捷,李娟.基于Lucene的电子文件全文检索系统研究[J].兰台世界,2015(3):25-26.
[9]陈艳春,李双平.基于Lucene的企业级搜索引擎的设计与实现[J].现代图书情报技术,2007(8):63-66.
[10]曹强.基于Lucene的Web站点站内全文检索系统的设计与实现[J].图书情报工作,2007(9):124-144.
[11]姚树宇,赵少东.一种使用分布式技术的搜索引擎[J].计算机应用与软件,2005(10):127-129.
[12]周敬才,胡华平,岳虹.基于Lucene的全文检索系统的设计与实现[J].计算机工程与科学.2015(2):252-256.
[13]夏天,等.Lucene全文检索软件及其在学科信息服务平台中的应用[J].图书情报工作,2011(11):106-109,87.
[14]彭哲,陈敬文.Lucene全文检索的应用及检索效率测试研究[J].图书馆杂志,2009(8):63-67.
柏雪1988年生。研究方向:分布式检索、云计算。
收稿日期:(2015-12-10;责编:姚雪梅。)
