利用实体与依存句法结构特征的病历短文本分类方法
2016-02-09吕愿愿邓永莉刘明亮崔宇佳陆起涌
吕愿愿,邓永莉,刘明亮,崔宇佳,陆起涌
1 复旦大学信息科学与工程学院,上海市,200433
2 复旦大学信息学院智慧网络与系统研究中心,上海市,200433
利用实体与依存句法结构特征的病历短文本分类方法
【作者】吕愿愿1,邓永莉1,刘明亮1,崔宇佳1,陆起涌2
1 复旦大学信息科学与工程学院,上海市,200433
2 复旦大学信息学院智慧网络与系统研究中心,上海市,200433
近年来,电子病历文本的分类、挖掘成为医学大数据研究的基础。该文提出一种利用实体与依存句法结构分析构特征集的电子病历短文本分类方法。首先对病历文本进行自然语言处理,包括分句、分词、词性标注以及实体提取,构建实体词典,利用TF-IDF方法构建词-文本矩阵并利用潜在语义分析LSA方法进行词汇特征的选择,然后分析病历文本的依存句法关系,挖掘出词汇之间的依存关系并构建特征三元组作为分类特征的扩展,最后构建出分类特征向量集对病历短文本进行分类。实验证明,相比于未进行特征扩展的短文本分类,所提方法能有效地提高分类器的分类性能,其分类的准确率与F值均有明显的提高。
电子病历;短文本;TF-IDF;LSA;依存句法结构分析;特征三元组
0 引言
现代医学的快速发展产生大量有价值的临床医学数据,从临床医学文本中挖掘出隐含的生物医学与临床医学知识对于医学领域信息抽取、医学大数据挖掘以及现代医学的发展具有十分重要的意义。临床数据主要以非结构化或者半结构化的形式存在于病人的病历之中。对电子病历文本(Electronic Medical Record, EMR)进行信息抽取,将EMR中数据进行结构化的展示,是进行医学大数据挖掘的基础。一份病历主要是从症状、检查化验、用药、疾病变化情况、病人查房记录等几个方面记录病人的情况。对病历中的内容根据其描述的对象进行短文本分类对进行病历信息抽取与数据挖掘具有重要的意义。
短文本的特点是词数少、描述信息能力弱、特征稀疏、语义离散,传统的适用于长文本分类的方法已不能满足短文本分类的需要。构建合适的分类特征矢量,是短文本分类面临的重要考验。目前提出的很多方法均通过对短文本的特征进行扩展来进行。如王盛、樊兴华等[1]提出利用“知网”确定训练集中概念对的上下位关系,以此来扩展短文本分类的特征向量;杨天平、朱征宇[2]提出构建全局语义概念词表,利用概念词表对训练短文本以及预测短文本进行概念化描述并使预测短文本在训练集中找出相似的短文本组合成长文本后转换为长文本分类问题;秦添轶、林蝉等[3]提出短文本间语义相似度部分和短文本分类相结合的实体描述短文本间相似度的计算方法。
这些方法对短文本的分类起到了一定的作用,但运用于病历短文本分类则存在一些问题。主要表现在:
(1) 病历中含有大量医学专用实体词汇,且同一词汇具有不同的存在形式,一义多词或者一词多义现象较多;
(2) 病历中存在的字符形式较多,包括中文、英文缩写、阿拉伯数字、科学计数法等等,使特征抽取变难;
(3) 病历文本中不同类别的短文本存在一定程度上的重叠,如何确定其语义上的类别成为一大难题。
本文提出了一种基于实体与依存句法结构进行特征扩展的病历短文本分类方法。该方法首先建立病历文本的分词与实体标注模型,利用得到的模型与词典处理待分类的病历文本,建立实体词典,对文本中的词汇进行TF-IDF(Term Frequency - Inverse Document Frequency)计算,并结合实体词典筛选出对文本分类有显著区分能力的词语作为文本分类的词汇特征(Vocabulary Feature ),构建词—文本矩阵,并使用潜在语义分析(Latent Semantic Analysis, LSA)对词文本矩阵进行降维。同时,通过有监督的学习算法提取训练样本的依存句法结构特征(Dependency Relation Feature)作为分类特征的扩展。在此基础上对病历文本进行短文本分类。特征集构建示意图如图1所示。

图1 特征集构建示意图Fig.1 Construction of feature set
1 词汇特征的提取
本文采用的文本分类特征融合了文本的词汇特征以及词语间的依存关系特征。文本词汇特征的提取详细介绍如下。
1.1 病历文本NLP处理
自然语言处理[4](Natural Language Processing, NLP)近年来在国内外均取得了很大的进展[5],被广泛应用于文本挖掘、语音识别、智能问答等领域。目前发展较好的中文NLP系统主要有复旦大的FudanNLP[6]、中科院的ICTCLAS、哈尔滨工业大学的LTP[7]语言云平台等等。当使用这些NLP平台处理本文研究所用的风湿免疫科病历文本时会出现以下两个问题:
(1) 分词问题,实体词汇不正确切分;
(2) 实体识别问题,专业词汇识别困难。
为了解决以上问题,本文采用有监督的学习算法,建立学习样本,利用最大熵模型(Maximum Entropy, MaxEnt)[8]进行训练,构建适用于病历文本的分词、词性标注与实体标记模型。本文提供了200份由专业医生与笔者共同合作分工标记的风湿免疫科病历文本作为训练样本。分词与标注的原则如下:
(1) 分词时对于医学专有名词如药品名称、疾病名称、化验项名称等不进行切分,并使用不同的实体标签对其进行标记;
(2) 词性标注采用“863词性标注集”,在此基础上对于没有进行切分的粒度较大的实体的词性标注,采用统一的专有名词的标注;
(3) 标记的实体类别包括:症状、部位、用药、检查化验、诊断。
除此之外,本文还向系统内添加了医学专用词典文件,用于配合实现命名实体的识别。词典文件主要来源于搜狗细胞词库[9],并对词汇库进行了分类与整理。
模型利用开源OPENNLP[10]中的最大熵模型进行训练得出,在训练的过程中采用5折交叉验证进行参数的调整与优化。利用得到的模型对500份完整的风湿免疫科病历进行NLP处理后得出实体词典信息如表1所示。

表1 实体词典信息表Tab.1 Entity dictionaries
本文使用训练的分词模型与结巴分词系统[11]分别对随机抽取的20份完整病历做了分词。二者对每一份病历的分词时间如图2所示。
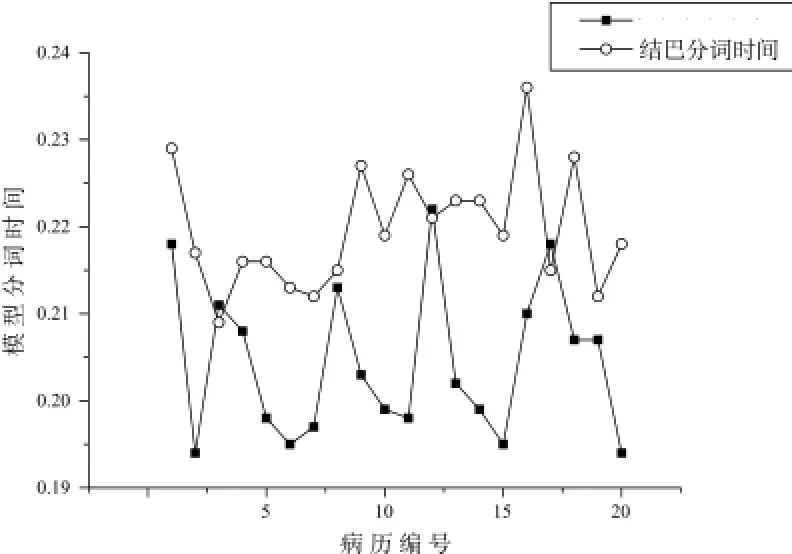
图2 分词速度对比Fig.2 Comparison of speed of tokenization
从图2可以看出,本文建立的分词模型在对病历的分词速度上明显优于结巴分词系统。从实际应用来说,本文采用的模型是基于病历文本训练的,因此分词精度远远大于结巴分词。
1.2 病历文本词汇特征选取
本文对于病历短文本中词汇特征的提取的步骤如图3所示。
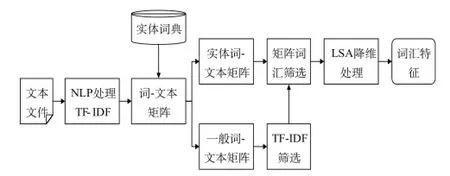
图3 词汇特征提取流程Fig.3 Extraction of vocabulary feature
TF-IDF[12]理论认为特征词汇的权重不仅与词汇在语料库中出现的频率有关,同时与词汇在文档中出现的频率有关。TF-IDF的计算公式可以表示为:

其中,D为语料库包含的文件总数,ni,j为文档j中词汇i出现的次数,∑knk,j为文档j中出现的总的词汇数目。
通过TF-IDF计算可以得出一个高维稀疏的词—文本矩阵,然后对该矩阵进行潜在语义分析[13]。LSA认为文本中词与词之间存在某种潜在的语义结构。通过对具有相同语义结构的同义词与不同语义结构的非同义词进行处理,将高维的词文本矩阵映射到低维空间,从而降低向量维度,化简文本词汇特征。
LSA的原理是利用矩阵奇异值分解对词文本矩阵进行计算,提取出前k个最大奇异值及其对应的奇异矢量构成一个秩为k的近似矩阵表示原高维矩阵。本文在进行TF-IDF之后、LSA之前对词—文本矩阵进行了筛选与删减。一般认为,如果一个词条在某一类文档中出现的概率远远大于其在其他类别文档中出现的概率,则该词条保留,否则删除。如实验用病历文本症状描述中常出现“出现”、用药中常出现“予”、“口服”、检查中常出现“查”、“提示”等词汇,这些词汇具有很强的文本分类能力,因此予以保留。
2 依存三元组特征提取
2.1 病历依存关系标注与分析
依存句法分析[14]通过对语言单位内成分之间的依存关系的分析揭示句子的语法结构以及词语之间的搭配关系。本文在分析了病历依存句法结构的基础上提出了利用依存关系进行三元特征组构建对分类特征进行扩展。本文中对病历文本采用LTP平台标注集进行标注。结合病历语法特点将LTP体系中将24种依存关系简化为10种,包括:SBV(主谓关系)、VOB(动宾关系)、ATT(定中关系)、HED(核心关系)、ADV(状中关系)、COO(并列关系)、POB(介宾关系)、DBL(兼语关系)、CMP(动补关系)以及IS(独立结构)。
本文在使用LTP标注集进行句法标注的过程中对分词做出了修改。主要是利用建立的实体词典,使实体词典中出现的词汇作为整体进行句法标注。这样做既简化了句法树结构,又可以使后续得到的依存关系三元组保持一定完整的语义信息。
根据以上标准,对句子“病程中患者出现视物模糊,考虑羟氯喹副作用引起,故暂停用。”的句法分析结果如下图4所示。
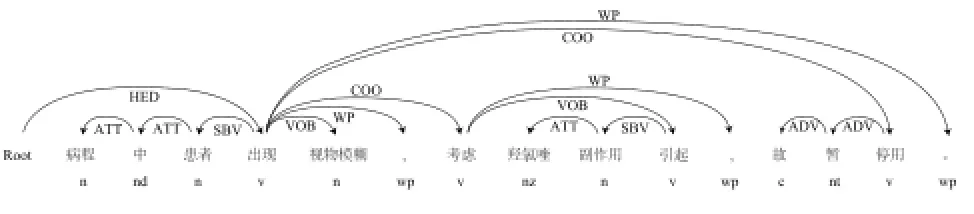
图4 LTP进行依存句法分析示例Fig.4 Examples of dependency parser with LTP
2.2 病历依存关系三元组选择
假设文档D={s1, s2, …, sn},其中s为文档中的一个句子。对于其中任意一个句子sl,经过分词与去停用词后有sl={w1, w2, …, wm},其中w为句子中的词。对句子sl进行依存句法分析后得到图G=(sl, El),其中El为图中所有边的集合。本文通过将图中一条边连接的两个词语与这条边对应的关系构成三元组来表示语句中的特征。如假设图中一条边为eij,eij的两个端点为词汇wi、wj,边eij表示的依存关系为rij,其中wi为支配词,wj为依存词,则将该三元关系表示为(wi,rij,wj)。
按照对三元依存关系组[15]的定义,对于图4中的例子进行三元关系组构建,总共可以构建15个三元关系组。从中对较好的依存关系三元组进行筛选,原则如下:
(1) 选取依存关系较强的三元组,如HED、SBV、VOB以及COO,不考虑WP、ADV等等;
(2) 优先考虑含有实体词汇的依存三元组。
依据以上原则对图4中的例子进行依存三元关系组提取可得以下关系组集合:{(Root,HED,出现),(出现,SBV,患者),(视物模糊,VOB,出现),(考虑,COO,出现),(引起,VOB,考虑),(引起,SBV,副作用),(副作用,ATT,羟氯喹)}
2.3 依存关系三元组的处理
为了使得到的特征更加具有普遍性,要对特征进行一般化处理。处理的原则如下:
(1) 除HED三元组关系之外,对于三元组中属于实体词典中的词,使用词典的名称如“symptom”、“medicine”代替;
(2) 对于三元组中只有一个实体词汇,而另一个为非实体词汇的,则将非实体词汇采用通配符“*”表示,当替代后有多个一样的三元组时对该三元组特征进行加权;
(3) 对于三元组进行优先级排序,支配词与被支配词均属于实体词典的三元组与HED三元组关系优先级最高,有一个词为实体词的三元组次之,其余的最低。
根据以上三元组关系处理的原则对于图3中例句的三元组关系进行处理得到三元组关系集合为:
{(Root,HED,出现),(symptom,VOB,*),(*,ATT,medicine),(考虑,COO,出现),(引起,VOB,考虑),(出现,SBV,患者),(引起,SBV,副作用),}
再如,对于例句“伴干咳、痰少、乏力,无咽干”进行三元组特征抽取,得到依存句法解析树如图5所示。根据三元组提取规则得到依存三元组集合为:{(Root,HED,伴),(symptom,COO,symptom),(*,VOB,symptom),(伴,COO,无)}。

图5 依存关系示例Fig.5 Example of dependency parser
3 实验与实验结果分析
3.1 数据来源
实验所用数据来源于上海翼依信息技术有限公司,总共为700份完整风湿免疫科电子病历。
实验中对于NLP训练分词与实体标注部分,使用了200份完整的病历作为训练样本,模型测试与实体词典抽取则使用另外500份病历进行。对于分类实验,使用与NLP训练中相同的200份病历中的入院记录、病程记录和出院记录,根据其描述的类别拆分成长度为150字左右的短文本,并分为表3中所列五类进行实验训练,其中一般描述类指的是病历中对病人既往史、家族史以及个人史的描述。分类训练数据与测试数据情况见表3。

表3 实验数据概览Tab.3 Data used in the experiment
3.2 实验设计与评价指标
为了证明对分类特征利用依存句法关系进行扩展的有效性,本实验分两组进行,一组的分类特征仅仅使用提取的词汇特征集,记为V,另外一组使用词汇特征与依存句法特征集,记为V+P。
本实验以张知临编写的TMSVM文本分类系统(http://code.google.com/p/tmsvm/)为基础,将其中引用的第三方分词工具替换成OPENNLP训练后的分词工具,引入依存句法分析得到依存关系三元组进行特征扩展,采用默认参数进行文本分类模型的训练与测试。
实验评价指标采用目前文本分类领域常用的评价指标,采用宏平均与微平均分别计算比较分类正确率(P)、召回率(R)以及F值,计算公式定义如下:
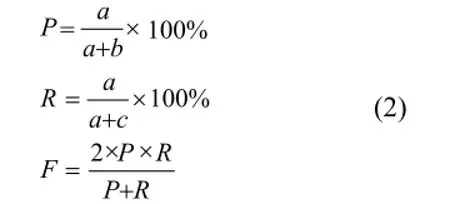
其中,a表示分类器将输入文本正确地分类到某个类别的个数;b表示分类器将输入文本错误地分类到某个类别的个数;c表示分类器将输入文本错误地排除在某个类别之外的个数。
除此之外,实验还统计了各类文本分类的误判率与漏判率。其中误判率指不是某一类别却错误地判断为该类别的概率,漏判率指属于某一类别却被判断为其他类别的概率。
3.3 实验结果与分析
实验中测试文本分词后共得到词汇12 577个,经过筛选后保留特征词汇780个经过LSA分析,最终保留词汇特征360个,简单依存关系三元组特征45个。经分类以及计算统计后得到的宏平均与微平均统计结果分别如表4与图6中所示。

表4 分类宏平均统计结果Tab.4 Macro-average result of text classification

图6 特征扩展前后分类微平均结果比较Fig.6 Comparison of micro-average result
从宏平均与微平均的结果来看,加入依存关系进行特征扩展后进行的文本分类相比于仅用词汇特征做分类在类别以及整体准确率、召回率、F值上都有不同程度的提高。
对比表4中不同类别的误判率可知,症状描述类的误判概率远远大于其他类别的误判概率。原因在于病历中在进行以其他四个类别为主题的描述时总会或多或少带上一些症状的叙述,导致该类别的词汇特征中出现症状类的实体数目,干扰了分类的进行。
4 总结展望
本文结合分类的实际应用,从病历文本的特点出发,提出给予实体词典与依存句法关系构建分类向量进行病历短文本分类的方法。所有研究过程中使用的电子病历均经过去身份化的操作,对病历的所有操作均以保护病人隐私为前提下进行。实验结果充分证明了利用依存三元组进行特征扩展后文本分类的准确率、召回率以及F值均有明显的提高。
近年来文本挖掘、文本分类渐渐朝着纵向领域发展,因此结合领域特性,建立领域专业词典与知识库对于特定领域的文本挖掘、文本分类具有深远的意义。本文提出的方法仅仅在医学领域内的一个科室病历中做了探索,对于该方法在其他领域的扩展应用还有待于进一步的研究。
鸣谢
笔者感谢上海翼依信息技术有限公司提供电子病历文本,并联系风湿病领域专业医生与相关从业人员与笔者共同进行训练文本的标注与词典的建立,对文章中分词与标注模型的建立给予了无私的帮助。
[1] 王盛, 樊兴华, 陈现麟. 利用上下位关系的中文短文本分类[J]. 计算机应用, 2010, 30(3): 603-606.
[2] 杨天平, 朱征宇. 使用概念描述的中文短文本分类算法[J]. 计算机应用, 2012, 32(12): 3335-3338.
[3] 秦添轶, 林蝉, 宋博宇, 等. 一种实体描述短文本相似度计算方法[J]. 智能计算机与应用, 2015,5(2):34-37.
[4] Meystre S, Haug PJ. Automation of a problem list using natural language processing[J]. BMC Med Inform & Deci Mak , 2005, 5(21):1-14.
[5] 刘向威. NLP技术在中文信息检索中的应用研究[D]. 天津: 天津大学, 2005.
[6] Qiu X, Zhang Q, Huang X. FudanNLP: a toolkit for chinese natural language processing[J]. Proc Acl, 2013:49-54.
[7] http://www.ltp-cloud.com/ [R/OL].
[8] 周雅倩, 郭以昆, 黄萱菁,等. 基于最大熵方法的中英文基本名词短语识别[J]. 计算机研究与发展, 2003, 40(3):440-446.
[9] http://pinyin.sogou.com/dict/[R/OL].
[10] Savova GK, Masanz JJ, Ogren PV, et al. Mayo clinical Text Analysis and Knowledge Extraction System (cTAKES): architecture, component evaluation and applications[J]. J Am Med Inform Assoc, 2010, 17(5):507-513.
[11] https://github.com/fxsjy/jieba[R/OL].
[12] 施聪莺, 徐朝军, 杨晓江. TFIDF算法研究综述[J]. 计算机应用, 2009, 29(S1):167-170.
[13] 王永智, 滕至阳, 王鹏,等. 基于LSA和SVM的文本分类模型的研究[J]. 计算机工程与设计, 2009, 30(3):729-731.
[14] 穗志方, 俞士汶. 基于骨架依存树的语句相似度计算模型[C]// 1998中文信息处理国际会议, 1998: 458-465.
[15] 张庆庆, 刘西林. 基于依存句法关系的文本情感分类研究[J]. 计算机工程与应用, 2015, 51(22): 28-32.
Short Text Classifcation of EMR Based on Entities and Dependency Parser
【Writers】LV Yuanyuan1, DENG Yongli1, LIU Mingliang1, CUI Yujia1, LU Qiyong2
1 School of Information Science and Technology, Fudan University, Shanghai, 200433
2 Research Center of Smart Networks and Systems, School of Information Science and Technology, Fudan University, Shanghai, 200433
Nowadays, text classification and text mining of Electronic Medical Record(EMR) have become the basis of the Big Data research in biomedical fields. This paper proposes a method using entity dictionaries and dependency parser as the feature to do the classification of short texts in EMR. It used NLP to preprocess the texts first including sentence segmentation, word segmentation, part of speech and entity extraction. Then several entity dictionaries were built according to the result of NLP. After that the TF-IDF and LSA were deployed to select the vocabulary feature. Then considering the characters of EMR, dependency parser was done to the texts and triple dependency relation features would be used as the expanding feature for text classification. The result of the experiment shows that comparing to the classification which used vocabulary features only, the proposed method can effectively improve the performance of classifier and the precision and F-value are obviously higher.
EMR, short texts, TF-IDF, LSA, dependency parser, triple dependency relation feature
TP311.13
A
10.3969/j.issn.1671-7104.2016.04.003
1671-7104(2016)04-0245-05
2016-03-08
吕愿愿,E-mail: 13210720033@fudan.edu.cn
