一种基于二部分图的推荐算法
2015-12-31宋中山,王晓华
一种基于二部分图的推荐算法
宋中山,王晓华
(中南民族大学 计算机科学学院,武汉430074)
摘要在对基于二部分图网络结构的推荐算法NBI和基于Pearson系数的协同过滤推荐算法CF,以及当前广泛应用的完全排序算法GRM进行详细分析的基础上,针对这些算法的局限性,提出了一种基于二部分图的推荐算法.采用Movielens数据库对NBI、CF和GRM以及文中所提算法用2个不同的参数进行了比较.实验结果表明:除了当向每个用户推荐50个电影这一种情况外,文中给出算法的推荐准确率均高于其他3种推荐方法.
关键词个性化推荐;数据挖掘;二部分图;推荐算法
收稿日期2015-01-10
作者简介宋中山(1963-) ,男,副教授,研究方向:数据挖掘,E-mail: songzs2005@ tom.com
基金项目国家民委科研基金资助项目(CMZY13010)
中图分类号TP399文献标识码A
Based on a Bipartite Graph of Recommendation Algorithm
SongZhongshan,WangXiaohua
(College of Computer Science, South-Central University for Nationalities, Wuhan 430074, China)
AbstractThe foundation of this paper is the recommendation algorithm based on bipartite graph network structure, the collaborative filtering recommendation algorithm (CF) based on Pearson coefficients, and the fully sorting algorithm (CRM) that is most widely used. After the detailed analysis of these algorithms, in consideration of their limitations, a new recommendation algorithm based on bipartite graph is proposed. Movielens database is drawn upon to compare NBI, CF, GRM and the proposed algorithm with two parameters. The results show that the accuracy of the recommendation produced by the proposed algorithm is higher than that of the other three algorithms except when recommending 50 movies to users.
Keywordspersonalized recommendation;data mining;bipartite graph;recommendation algorithm
个性化推荐是数据挖掘领域研究的热点问题之一, 它依据用户的兴趣特色和购置活动,向用户推荐能够感兴趣的消息或商品[1,2].
1995年Robert Armstrong等人在美国人工智能协会上提出了个性化导航系统Web Watcher;斯坦福大学的Marko Balabanovic等人在同一会议上推出了个性化推荐系统LIRA[3,4],在文献[5]中杨铭等人对在线商品评论的效用进行了分析,这为推荐提供了依据.1994年明尼苏达大学Grouplens实验室Resink教授的团队创建了第一个自动推荐系统Grouplens ,最初只是做Usenet新闻、文章推荐的研究.在1997年又建立了以学术研究为目的的Movielens网站,主要技术是通过获取用户对电影的评价信息,利用协同过滤算法[6]和关联规则算法相结合[7],向用户推荐电影,该网站面向用户的信息资源是公开的.
本文通过对基于二部分图网络结构的推荐算法[8]、基于Person系数的协同过滤算法[9]、全局排序算法的分析,针对这些算法的局限性,给出了基于二部分图的推荐算法.该算法不仅能够清晰地获得用户和信息之间的映射关系,而且可以通过分析用户的历史信息,发现用户选择电影的喜好,能够将信息准确地推荐给用户,提高算法的准确性.
1相关算法分析
1.1基于二部分图网络结构的推荐算法
基于二部分图网络结构的推荐算法NBI[10],是基于对象的,而不是针对客户的.它是把对象和用户抽象成2类节点,并且把这2类节点之间用边进行连接,这样便构成了2个节点之间的关系图.它的具体思想是:在任意X节点的资源都应该有可以分配给其它的与它有关联的节点的资源,类似的,资源在任意的Y节点也应该具有可以分配给与它有关联的资源.具体的实施思想,如图1所示.
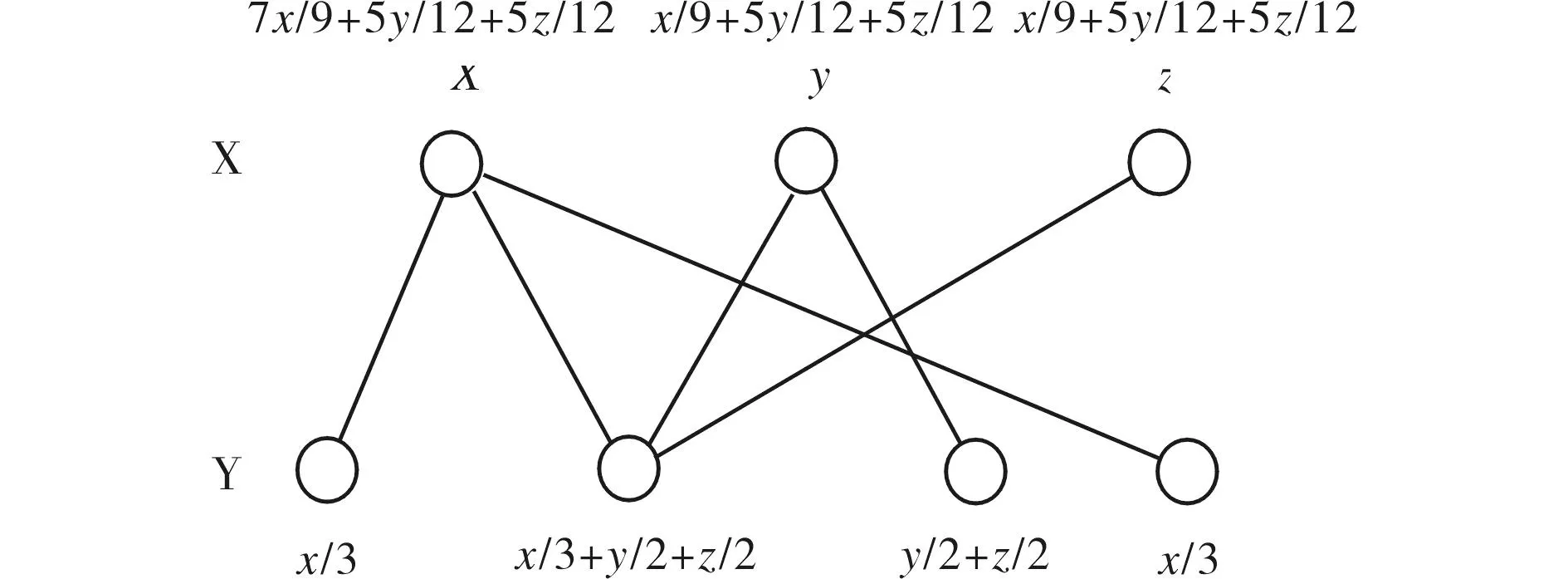
图1 二部分图的构造 Fig.1 Bipartite graph structure
以此得出项目和项目之间的关联指数.具体的基于项目的关联网络图如图2所示.

图2 基于项目的关联网络 Fig.2 Based on project of associated network
根据上面的推荐,我们可以得出对于每个用户i和未分配的项目j都有一个排名,用公式(1)表示.

(1)
1.2基于Pearson系数的协同过滤推荐算法
协同过滤技术[11],首先,要计算出用户与目标项目的相似性.其次,根据用户和目标用户的相似性、对项目的评价以及这些评价的分数预测出对用户的推荐分数.最后,从预测的推荐分数值中选取最大的n项作为推荐结果,即通过用户之间的相似性来推荐商品项目[12],进行相应的比较.具体的算法思想如下.
用户i和j之间的相似性(用户i和j同时爱好的电影的数量)由公式 (2) 进行推测.

(2)
根据公式(2)得出的用户之间的相似性,也就是权值的大小,就可以算出推荐给某一用户i的电影的推荐分数,计算由公式 (3) 表示.

(3)
1.3完全排序算法
完全排序算法(GRM)是对用户没有看过的所有的电影根据某一个条件进行排序,计算由公式(4)表示.
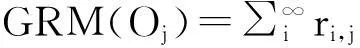
(4)
根据公式(4)得出计算结果,然后按照从高到低的顺序排列,并且把排名较高的电影推荐给相应的用户.
2本文算法
2.1算法思想描述
本文是基于二部分图的基础上,给出用户和用户关联的推荐算法,具体的算法思想如下:若user1和user2共同选择了10部相同的电影[13],user1和user3 共同选择了5部相同的电影,user1和user4 共同选择了10部相同的电影,user2和user3共同选择了15部相同的电影,并且他们对这些电影的评分≥3(代表该用户喜欢该电影),那么得出用户与用户之间的网络结构图如图3所示.
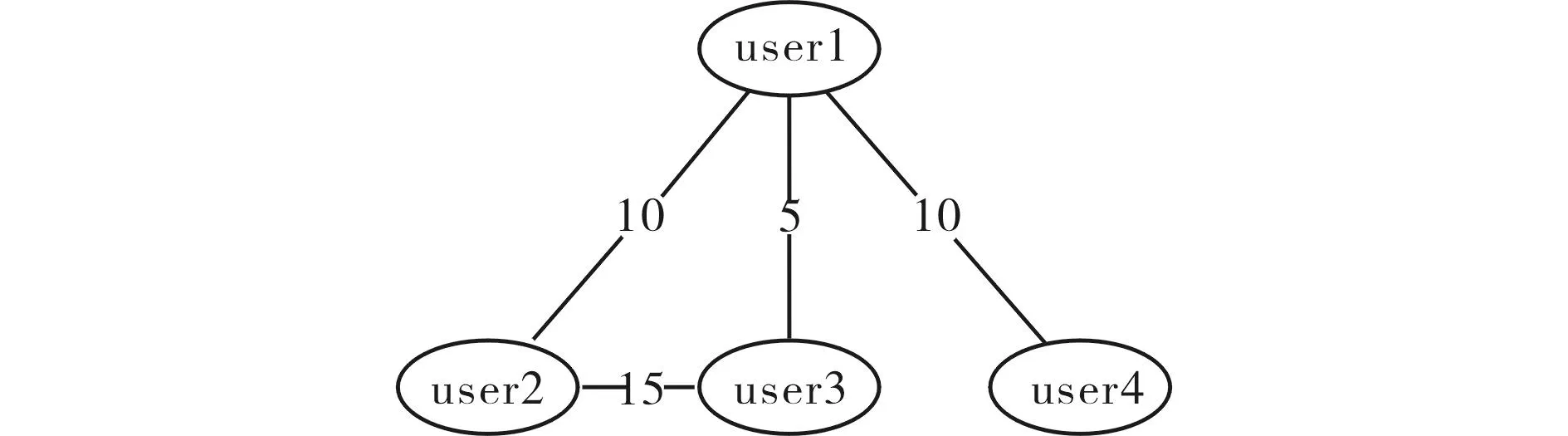
图3 用户与用户之间的网络结构图 Fig.3 Network structure between user and user
以user1为例,根据算法思想就可以把user2、user3、user4喜欢的电影根据他们之间的关联关系都推荐给user1, 并且对这些推荐的电影以推荐分数做一个降序排名.
如果user2、user3、user4分别喜欢的电影是2部、2部、3部,并且这几个用户都和用户user1有关联,那么就把这7部电影都推荐给用户user1.其结构如图4所示.
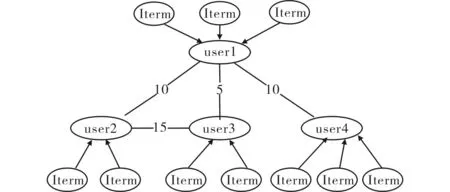
图4 用户和电影的网络结构图 Fig.4 Network structure between user and movie
然后计算出推荐给用户的电影的推荐分数,并将其按推荐分数(定义为W(i,j))进行一个降序的排名,W(i,j1)≥W(i,j2)…≥W(i,jk)根据这个排名做相关的推荐,并进行实验的验证和分析,得出该算法的优劣评价.
3实验设计
实验环境如下.
硬件环境:CPU:2.83GHz,内存:4GB.
软件环境:Win7(32)、数据库 SQL Server 2008 R2.
本文使用Movielens(http://www.movielens.org)数据集的数据进行算法的验证,实验步骤如下.
(1) 从用户对100000条电影的评论中筛选出评分≥3的所有评论,共有82520条记录,并且以9∶1的比例分别存放于表T_Training和T_Test中,用来作为训练集和测试集,分别有74268和8252条记录.训练集中的数据用来构造用户与用户之间的关联,并且根据相应的关联做出推荐,测试集中的数据则是用来验证推荐算法的准确性.
(2) 对训练集T_Training 中的数据进行分析,建立用户和电影之间的二部分图映射关系,然后根据用户共同喜欢的电影找出用户与用户之间的关联,存放在表T_SameID3中.
SELECT T_Training.UserID AS UserID1, T2.UserID AS UserID2
INTO T_SameID3
FROM T_Training, T_Training AS T2
WHERE(T_Training.ItermID= T2.ItermID)
AND (T_Training.UserID <> T2.UserID)
(3) 根据以上的结果,找出用户与用户之间关联权值的大小,也就是用户与用户之间喜欢相同电影的数目.存放在表T_Weights中.
SELECT UserID1, UserID2, COUNT(*) AS Weights INTO T_Weights
FROM T_SameID3
GROUP BY UserID1, UserID2
(4) 在测试数据集 T_Test 表中,找出所有电影编号不重复的记录,在这些记录中找出满足T_Training 表中被选择电影的编号ItemID与测试数据集中电影的编号ItemID相等的记录保存到T_InTest 表中,也就是找出既在训练集也在测试集中的电影.
SELECT B.UserID, B.ItermID
INTO T_InTest
FROM(SELECT DISTINCT ItermID
FROM T_Test ) AS A, T_Training AS B
WHERE A.ItermID = B.ItermID
(5) 计算推荐分数,即把所有与某一个用户的某一个电影有关系的用户的权值进行累计.
SELECT ItermID,UserID2,
COUNT(Weights) AS CommScore
INTO Comm
FROM T_InTest , T_Weights
WHERE T_InTest.UserID=T_Weights.
UserID1
GROUP BY ItermID, UserID2
(6) 根据测试集和推荐分数的集合找出推荐给用户的电影在测试集中也存在相应的电影的用户集合,保存在UserINTest 表中,方便以后根据用户做电影的推荐,并且分别排名,为求平均相对位置做准备.
SELECT DISTINCT UserID2
INTO UserINTest
FROM Comm ,T_Test
WHERE T_Test.UserID=Comm.UserID2
AND T_Test.ItermID=Comm.ItermID
(7) 计算出所有用户看过的电影的数量,保存在表T_Watch中.
SELECT UserINTest.UserID2 ,
COUNT(*) AS Watch INTO T_Watch
FROM T_Training,UserINTest
WHERE(T_Training.UserID=UserINTest.UserID2) GROUP BY UserINTest.UserID2
根据上面的实验步骤得到的数据表,即可以求出推荐准确的电影的平均相对位置,来验证我们算法的准确率.
3.1实验结果
(1) 找出推荐给每一个用户的电影,并且根据推荐分数进行降序排名.执行以下代码,可以得出推荐给该用户的电影的排名信息记录.
CREATE PROCEDURE[dbo].[Pro_数据整理]
AS
declare @max int--用来做循环条件的.
declare @rowNo int--用来逐一读取用户ID
declare IDSet CURSOR LOCAL SCROLL FOR SELECT UserID FROM UserINTest
BEGIN
SELECT @max=0
--如果表T存在则首先删除
if exists (SELECT 1 FROM sysobjects
WHERE id = object_id('T')
AND type = 'U') DELETE FROM T
Open IDSet
fetch next FROM IDSet into @rowNO
--循环开始
while @@FETCH_STATUS = 0 --对每一个rowNumber进行循环操作
BEGIN
--这儿对每一行要进行的操作的代码
IF @max=0
BEGIN
SELECT ItermID ,UserID2,CommScore, DENSE_RANK()
over(order by CommScore desc) as 排名
INTO T FROM Comm
WHERE UserID2=@rowNo
SET @max=1
END
ELSE
BEGIN
INSERT INTO T
SELECT ItermID ,UserID2,CommScore, DENSE_RANK()
over(order by CommScore desc) as 排名
FROM Comm
WHERE UserID2=@rowNo
END
Fetch next FROM IDSet into @rowNO
END
close IDSet
deallocate IDSet
--循环结束
END
(2) 求平均相对位置.找出推荐给用户的电影,并且这些电影既在测试集中,也在推荐集中,查出他们在推荐集中的排名,以及相应的用户看过的电影数量.将结果保存在Result表中.
SELECT T.UserID2 ,T.ItermID ,排名,
T_Watch.Watch INTO Result
FROM T ,T_Test ,T_Watch
WHERE T_Test.UserID=T.UserID2
AND T.ItermID =T_Test .ItermID
AND T_Watch.UserID2 = T.UserID2
ORDER BY T.UserID2
根据Result中电影的排名信息,和用户看过的电影数量求出平均相对位置.

其中,推荐准确的电影指的是推荐给用户的电影既在测试集中也在训练集中.得出的平均相对位置的结果是:0.073120024.
(3) 求命中率的结果.根据推荐给用户的电影在测试集中也存在相应的电影的用户集合UserINTest,找出在测试集中对应的用户的电影在测试集中的个数,保存在T_TestNumberOfUser中.
SELECT UserINTest.UserID,
COUNT(ItermID) AS 测试集中个数
INTO T_TestNumberOfUser
FROM T_Test,UserINTest
WHEREUserINTest.UserID=T_Test.UserID
GROUP BY UserINTest.UserID
根据对应的表筛选出用户在测试集中的电影在推荐集中的排名信息,以及对应的用户在测试集中包含电影的个数.
接下来就可以计算命中率,为了比较这里以10、20、50、100为长度.分别求出每一个阶段命中的个数来计算命中率.

例如计算长度为10 的命中率.
SELECT UserID2 ,T_TestNumberOfUser.测试集中电影个数,
COUNT(排名) AS 长度10
FROM Result,T_TestNumberOfUser
WHERE Result.UserID2=T_TestNumberOf
User.UserID AND 排名<=10
GROUP BY UserID2 ,
T_TestNumberOfUser.测试集中电影个数
ORDER BY UserID2
同理,分别计算出长度为20、50和100的命中率,结果如表1所示.

表1 命中率的结果
结合上面分析的几种推荐算法和本文算法得出的结果给出比较.
平均相对位置的结果比较,如表2所示.

表2 平均相对位置的比较
命中率的结果比较,如表3所示.

表3 命中率的比较
从表2和表3可以看出,基于二部分图的推荐算法的准确率是最高的,但是在长度为50的时候基于二部分图的推荐算法的命中率是38.05%,而基于二部分网络结构的推荐算法(NBI)的命中率是41.20%,很显然在这一个阶段我们的算法的准确率还是没有NBI的高,经过分析和比较,出现这种现象可能的原因有很多,其中包括我们算法的准确率有待于提高,其次,也是因为我们推荐的准确率高,所以在10、20的长度时命中率是明显地高出其他的算法,而在长度增加时,命中率就不会有明显的提高,甚至还会降低,因为我们推荐命中的电影都比较靠前.还有也可能受用户主观因素的影响,比如电影的评价不当等等,所以以后在这一方面还有待于改进.
4结语
本文给出了一种基于二部分图的推荐算法,该算法结合了二部分图的映射关系,分析了用户与用户之间的关联,使得推荐给用户的电影更加准确.经过实验的验证,对比了基于二部分图网络结构的推荐算法、基于Person系数的协同过滤算法、全局排序算法和本文算法的准确性,实验结果显示,在相同数据条件下,基于二部分图推荐算法的准确率是最高的.
参考文献
[1]宋中山,杨敏,周易.基于模糊集的时序关联规则的度量准则[J] .中南民族大学学报:自然科学版,2014,33(1):86-90.
[2]宋中山,周腾,周晶平.一种改进的蚁群聚类算法在客户细分中的应用[J].中南民族大学学报:自然科学版,2013,32(3):77-81.
[3]王国霞,刘贺平.个性化推荐系统综述[J] .计算机工程与应用,2012,48(7):66-76.
[4]Linyuan Lü,Matúš Medo,Chi Ho Yeung,et al. Recommender systems [J].Physics Reports, 2012, 519(1) : 1-49.
[5]杨铭,祁巍,闫相斌,等.在线商品评论的效用分析研究[J].管理科学报, 2012,15(5):65-75.
[6]Zan-HUANG, ZENGD, CHENG. Comparisi-on of collaborative filtering recommendation algorithms for E-commerce [J] . IEEE Intelligent Systems, 2007, 22(5):68 -78.
[7]Preeti Paranjape-Voditel, Umesh Deshpande . A stock
market portfolio recommender system based on association rule mining [J] .Applied Soft Computing Journal, 2013, 13(2) :1055-1063.
[8]Yuchen Fu,Quan Liu,Zhiming Cui,et al. A collaborative
recommend algorithmbased on bipartite community [J] .The Scientific World Journal, 2014,20(14) :430-452.
[9]Yehuda Koren. Collaborative filtering with temporal
dynamics [J] . Communications of the ACM , 2010 (4): 89-97.
[10]Liu Jianguo, Zhou Tao,Che Hongan, et al . Effects of high order correlations on alized recommendation for bipartite networks [J] . Physica A, 2010,3(89) : 881- 886.
[11]Jian-guo LIU, Bing-hong WANG,Qiang GUO.Improved collaborative filtering algorithm via information transformation [J]. International Jouranal of Modern Physics C,2009, 20(2):285-293
[12]冷亚军,陆青,梁昌勇. 协同过滤推荐技术综述[J].模式识别与人工智能, 2014,7(8):720-734.
[13]Sang-Min Choi .A movie recommendation algorithm based on genre correlations[J] .Expert Systemswith Applications, 2012, 39 (9) :8079-8085.
