基于用户协同过滤的电子商务推荐算法
2015-12-28杨登
杨 登
(吉林化工学院经济管理学院,吉林吉林 132022)
一、研究背景
现今正从信息时代迈向推荐时代。明尼苏达大学教授John Riedl提出“推荐系统将成为未来十年里最重要的变革,社会化网站将由推荐系统所驱动”。作为电子商务先驱者,Amazon实现了35%的销售额来自其推荐系统。美国ChoiceStream公司调查显示:普通消费者中的45%、高端消费者中的69%更更愿意选择有推荐功能的网站;消费者购物前平均查看的商品个数在推荐系统帮助下由11.7下降到6.6;有推荐系统时选择更优的产品的消费者占比从65%上升到93%;有推荐系统的帮助消费者将更改初始选择的比率从60%下降到2l%。
二、电子商务个性化推荐系统
(一)定义
Resnick和Varian在1997年提出了个性化推荐系统定义:“个性化推荐系统是利用电子商务网站向客户提供商品信息和建议,帮助用户决定应该购买什么产品,模拟销售人员帮助客户完成购买过程”。
(二)用户偏好数据
推荐系统要想推荐结果能够反映出用户的偏好,需要用户偏好数据的支撑。收集用户偏好数据是个性化推荐系统的重要工作,用户偏好数据的质量决定推荐的质量。用户偏好数据可分为显式数据和隐性数据两类。
1.显式数据。显式数据要求用户主动地向系统提供本人的各种信息包括偏好信息,主要是通过特定的网页直接请求用户显式输入一些个人信息,包括对某些商品的数值评分,也包括用户注册的个人基本信息,如姓名、性别、年龄、生日、背景等。用户不情愿的输入个人信息数据导致用户评分数据的极为稀疏,这是显式评分方式的明显缺点。稀疏的评分数据导致推荐系统推荐质量的下降。
2.隐性数据。隐性数据的收集方式主要是从系统的服务器上收集访问日志和各类网络资源的过程,数据的获取过程其实是采用网络数据挖掘的方法,以网络内容挖掘和网络使用挖掘为主,然后进行数据的预处理。
用户兴趣偏好的收集过程是学习、分析、明确用户的需求的过程。用户的的需求会表现在与系统进行交互的浏览行为,比如用户经常访问的页面集,用户的点击,收藏历史,浏览时间,拉动滚动条的次数,鼠标点击区域,键盘输入输出等有关操作等,推荐系统将这些用户行为信息记录并转化为反映用户兴趣偏好的数据模型,再应用于推荐生成。隐式数据依靠行为科学的研究结论,其优势在于:①数据获取的自动化程度高,用户在访问系统时不需要做其额外的事情,降低了用户与系统交互的工作量。②数据收集的“成本”较低。③各种隐式数据能结合起来生成更精确的偏好信息。
但是相对于显式数据,隐性数据的缺点也非常明显,就是对它的获取难度大、对用户偏好进行模型化的可信程度偏低。一般情况下,用户的兴趣偏好表现的多样性和动态性,所以为了提高收集数据的质量,在很多实际应用中都采用混合式,即显示数据和隐性数据混合收集,优势互补,目的是为了更加真实、全面地获取用户的偏好信息。
三、电子商务推荐算法的研究
(一)基于内容的推荐算法
基于内容的推荐算法需要分析电子商务网站的资源内容信息,根据用户兴趣建立用户档案,用户档案中包含了用户的品位、偏好和需求信息。然后根据资源内容与用户档案之间的相似性向用户提供推荐服务。在一个这样的系统中,通常采用相关特征来定义所要推荐的物品。
(二)基于规则的推荐算法
随着数据挖掘的兴起,关联规则被应用于推荐系统,形成了一种新的推荐技术基于规则的推荐技术。基于规则的推荐技术在评价表上挖掘项目间的关联规则(项目关联)和用户间的关联规则为当前用户进行推荐。使用项目关联进行推荐时,每条项目关联的前件相当于一个兴趣组,而规则的后件则相当于这个兴趣组的推荐。如果当前用户对该规则前件中的所有项目都喜欢,那么就把规则的后件以一定可信度推荐给当前用户。而使用用户关联进行推荐时,用户关联的后件必须是当前用户,使用用户关联的前件中的用户的共同兴趣模拟当前用户的兴趣,模拟的可信度就是用户关联的可信度,以此作为推荐的依据。
(三)协同过滤推荐算法
协同过滤主要是以属性或兴趣相近的用户经验与建议作为提供个性化推荐的基础。透过协同过滤,有助于搜集具有类似偏好或属性的用户,并将其意见提供给同一集群中的用户作为参考,以满足人们通常在决策之前参考他人意见的心态。协同过滤推荐是迄今为止最成功的个性化推荐技术,被应用到很多领域中,协同过滤相当突出的优点是其决策基础是“人”而不是“内容的分析”,能针对任何形态的内容进行过滤,更能处理相当复杂和艰难的概念呈现,以获得意料之外的结论。
四、基于用户的协同过滤
基于用户的协同过滤推荐根据相似用户群的观点来产生对目标用户的推荐。基本思想是如果某些用户对部分项目的评分趋于一致或是很接近,可以认为他们对其他项目的评分差异就比较小,进一步,可以使用这些相似用户的项目评分值对目标用户的未评分项目进行估计。
基于用户的协同过滤使用数理统计的方法来寻找与目标用户有相似兴趣偏好的最近邻居用户集合,再以最近邻居用户对特定项目的评分为基础使用一定的数学方法来预测目标用户对该特定项目的评分,而预测评分最高的前N个商品可以看作是用户最有可能感兴趣top-N商品返回给目标用户(这就是所谓的top-N推荐)。
基于用户的协同过滤推荐算法的核心思想是利用数理统计的方法为目标用户寻找他的最近邻居用户集,再以最近邻居用户对特定项目的评分为基础使用一定的数学方法来预测目标用户对该特定项目的评分,最终产生推荐结果。通过最近邻居用户对目标用户未评分项目的评分值进行加权平均来逼近,这是该算法思想的关键。基于用户的协同过滤推荐算法的主要工作有:用户之间相似性的衡量、最近邻居集的查找和评分预测值的计算。
由上引入,这里对基于用户的协同过滤推荐算法过程进行分析,该过程大致可以划分成以下三个阶段。
(一)数据表示
按用户对项目的评分情况进行建模,有效度量用户之间的相似性。在基于用户的协同过滤推荐算法中,数据源是用户对商品的评分信息。算法必须在所有的用户对每一种商品的评分信息的数据基础上产生推荐结果,用一个m×n阶矩阵,Rmn来表示用户评分数据。这里,m行代表m个用户,n列代表n个项目,矩阵中的第i行第j列的元素Rij代表用户i对项目j的评分。
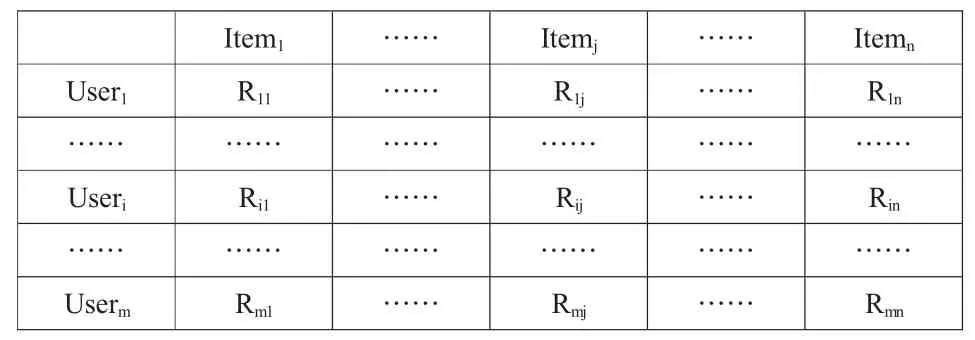
表用户评分数据矩阵
(二)查找目标用户的最近邻居用户集
最近邻居用户的意思就是若干个在购买行为或评分行为上与当前用户比较一致的用户。整个基于用户的协同过滤推荐算法的核心部分就是最近邻居的查询。最近邻居查询本质上是对评分数据进行建模,然后计算用户模型的相似度,相似度高的用户就是邻居用户。计算过程就是先收集用户i和j评分过的项目集合,再计算他们之间的相似性程度,相似性程度记为sim(i,j)。相似性程度主要有以下三种计算方法。
余弦相似性(Cosine):将用户对所有项目的评分看作为n维项目空间上的向量,用这些用户评分向量构建用户的数据模型,用户间的相似度就是通过向量间的余弦夹角来度量,设用户i和用户j在n维项目空间上的评分向量分别表示为,则用户i和用户j之间的相似性sim(i,j)可按下面公式一计算。
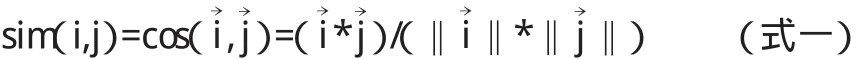
相关相似性:设用Iij表示用户i和用户j共同评分过的项目集合,则用户i和用户j之间的相似性sim(i,j)可以采用Pearson相关系数计算,如公式二所示。
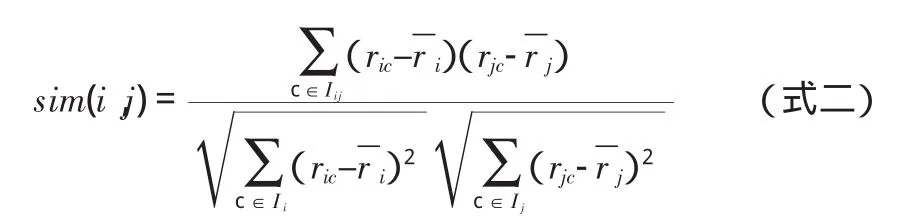
修正的余弦相似性:由于没有考虑不同用户的评分尺度的问题,余弦相似性方法存在缺陷。对余弦相似性方法的修正,主要通过减去用户对项目的平均评分来实现。用Iij表示用户i和j都评分的用户集合,用Ii、Ij分别表示用户i和用户j评分的项目集合,则修正的余弦相似性计算sim(i,j)方法可用公式三表示。
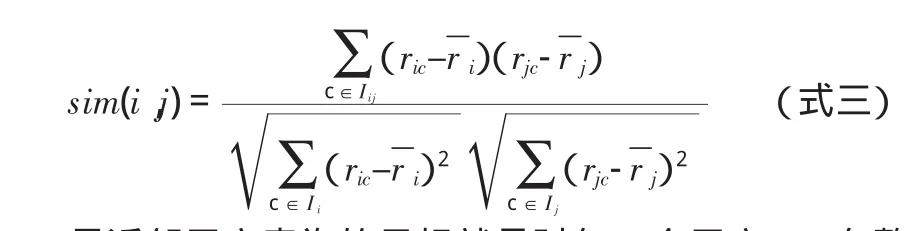
最近邻用户查询的目标就是对每一个用户u,在整个用户空间中查找与他相似的用户集合 U={u1,u2,...,uk},并且u1到uk按相似度由高到低排序。
(三)推荐产生
根据目标用户的最近邻居用户对项目的评分信息通过相应的数学公式计算目标用户对未评分项目的评分,取评分最高的N个项目进行推荐(Top-N商品推荐)。
根据过程2的相似性度量方法计算得到目标用户的最近邻居用户集,然后需要根据这些邻居用户的项目评分数据通过一定的算法产生相应的推荐结果。设用户u的最近邻居用户集合用U表示,则用户u对未评分项目i的预测评分Pui,可以通过用户u对最近邻居用户对该项目的评分得到,计算方法如下公式。
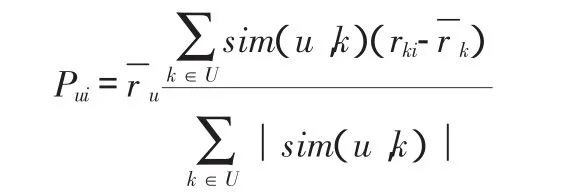
通过上面的计算方法预测用户对所有未评分项目的评分,然后再选择预测评分数值最高的N个项目(top-N)作为推荐结果反馈给目标用户。
一般情况下,电子商务网站的交易数据量是比较大,而且利用价值较高。当使用交易数据作为输入数据时,基于用户的协同过滤推荐算法就无法计算出用户对项目的评分,进而算法就不能进行下去,为解决这个问题。可以把问题简化,即只扫描目标用户最近邻集合中每个用户的购买数据,统计这些最近邻用户所购商品的购买次数,然后将购买次数最高且目标用户还未购买过的前N项商品作为推荐结果,这就是最频繁项推荐。
