一种基于MapReduce 的粗糙集并行属性约简算法
2015-12-15杨勇,朱影
杨 勇,朱 影
(重庆邮电大学计算智能重庆市重点实验室,重庆400065)
0 引言
粗糙集理论[1]是1982年由Z.Pawlak教授提出的,它可以有效地处理分析各种不完备信息,并能找出其潜在规律,所以近年来被广泛应用在数据挖掘、机器学习等多个领域[2],属性约简则是其中一个重要的研究内容。随着科学技术的飞速发展,各行业的数据都在急剧增长,如何处理这些大数据,并从中挖掘出有用的信息就变得非常重要。
近年来,为了能够适应大数据的不断增长,许多学者为得到高效的属性约简算法进行了大量研究,文献[3]将分治法的思想和粗糙集算法相结合,在属性序给定的条件下,提出基于分治策略的属性约简算法,文献[4]则是将并行思想与基于粗糙集理论的快速属性约简相结合,提出了一种基于Rough集理论的快速并行属性约简算法,然而,这些算法在处理实际大数据时,效率并不理想。由此看出,并行地处理大数据进行属性约简成为一种主流的方法。文献[5]提出将MapReduce和Rough集理论相结合,主要对基于MapReduce的并行正区域计算、并行属性核计算和并行属性约简进行研究,在处理大数据的同时得到了较为良好的约简结果,但是该算法的计算过程较为繁杂。
差别矩阵浓缩[6]是杨明于2006年提出的一种高效的基于差别矩阵的改进算法,考虑到决策表相容不相容2种情况,针对Skowron可辨识矩阵算法在求解约简过程中的不足,有效地作出了改进;而浓缩布尔矩阵[7]是殷志伟于2009年在浓缩差别矩阵基础上所提出的,通过使用布尔代数形式有效地降低了存储空间,提高了效率。
因此,本文将浓缩布尔矩阵[7]和MapReduce并行模型相结合,采用基于MapReduce的浓缩布尔矩阵并行约简算法,同等条件下,可以更为方便地得到属性核及约简结果。本文的创新点主要是利用云计算的MapReduce编程模型对基于浓缩布尔矩阵的约简算法的各个步骤并行化,这个过程更加简单和直观,提高了算法的效率,实验证明了算法的有效性和高效性。
1 基本概念
1.1 Rough 集的基本概念
定义1 决策表[8]。一个决策表,其S=〈U,A=C∪D,V,f>中,A=C∪D是属性集合,子集C={ai|i=1,…,m}和D={d}分别称为条件属性集和决策属性集,D≠∅,V是属性值的集合,f:U×A→V是一个信息函数,它指定了U中每个对象的属性值。
定义2 可辨识矩阵[2]。给定一个决策表S=〈U,A=C∪D,V,f>,F(xi,a)是样本xi在属性a上的取值,F(xi,D)是样本xi在属性D上的取值。Mij表示矩阵中第i行j列的元素,(其中i,j=1,…,n),则可辨识矩阵元素Mij定义为

定义3 相对正区域[8]。设U为一个论域,P,Q为定义在U上的2个等价关系簇,则Q的P正域记为POSP(Q),并定义为

定义4 属性核[8]。设U为一个论域,P,Q为定义在U上的2个等价关系簇,若POSP(Q)=POSP-{r}(Q),则称r为P中相对于Q是不必要的,否则称r为P中相对于Q是必要的。P中所有相对于Q必要的属性组成的集合称为P的Q核,记为COREQ(P)。
1.2 MapReduce介绍
MapReduce[9-10]是Google于2004年提出的一种编程模型,作为Google云计算技术的核心之一,能够在大规模分布式集群上并行计算处理海量数据。其概念和思想主要来自矢量编程语言和函数式编程语言,极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。
Map(映射)和Reduce(化简)的概念及他们的主要思想都是从函数式编程语言借来的,还有从矢量编程语言借来的特性。基于这种特点,MapReduce将复杂的并行计算过程高度地抽象成为2个函数,即Map和Reduce。
MapReduce的具体工作流程如图1所示。

图1 MapReduce工作流程Fig.1 MapReduce work flow
2 基于MapReduce的粗糙集并行属性约简算法
浓缩布尔矩阵算法是在文献[7]中提出的一种改进的矩阵属性约简算法,主要使用布尔代数代替传统的字符串进行运算,大大地减少了计算量,提高了算法的效率;使用二进制位进行存储也在很大程度上减少了存储的代价;此外,它是基于浓缩差别矩阵算法[6]改进所得,因此,对于相容和不相容决策表的属性约简同样适用;其计算属性核及约简结果的过程更为简单明了,可以有效地减少不必要的计算量,提高算法的效率。因此,本文基于浓缩布尔矩阵算法,分析其并行性,提出了基于MapReduce的粗糙集并行属性约简算法。
2.1 浓缩布尔矩阵算法及其并行性分析
2.1.1 浓缩布尔矩阵定义
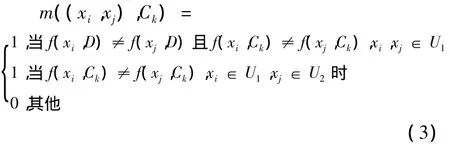
定义5 布尔矩阵[7]。布尔矩阵BM中的每个元素定义为为条件属性集合POS(D),U2=U-U1,即U1表示为相容对象的集合,U2表示为不相容对象的集合。
定义6 浓缩布尔矩阵[7]。由定义5可得,浓缩布尔矩阵IME(BM)可以表示为IME(BM)={m|m(m≠0)∈BM},且不存在m'(m'≠0)∈BM使得m'⊂m。
2.1.2 浓缩布尔矩阵算法
命题1[7]在浓缩布尔矩阵中,若某行只有一位元素为1,则该元素所在列属性为核属性。
由命题1可得算法1,如下所示。
算法1[11]浓缩布尔矩阵算法。
输入:决策表S=(U,C∪D)。
(3)中,k=1,2,…,n;集合(xi,xj)(xi∈U1,xj∈U1∪U2)表示xi和xj进行属性比较后的结果,表示
输出:浓缩布尔矩阵IME(BM)。
1)计算U1及U2;U1={x1,x2,…,xs},U2={y1,y2,…,yt},置Core=∅;
2)置IME(BM)=∅;
3)遍历集合U1中对象,对任意xi∈U1,xj∈U1(i<j),若f(xi,D)≠f(xi,D),则将xi,xj的各属性对应进行“异或”操作,相同属性为0,不同为1,所得结果存入数组array中;
4)若IME(BM)=∅,将array添加到IME(BM)中;若IME(BM)=∅,扫描矩阵,将array与矩阵中各元素进行“或”运算,若 ∀a∈IME(BM)存在a与array中各位相“或”所得结果与a的各位相同,则从IME(BM)中删除a,添加array;若相“或”后,结果与array各位相同,则不做任何操作;其他情况下,在IME(BM)中添加array。
5)遍历集合U1和U2中对象,对任意(xi,yj),其中U2={y1,y2,…,yt},将xi,yj的各个属性依次进行“异或”操作,得出结果并存入数组array中;再进行步骤4)操作,并最终得到IME(BM)。
6)判断矩阵中每一行的元素值,如果为1的元素值只有一个,则对值为1的元素进行以下操作:将其所在列对应的属性添加到核属性集中。
2.2 基于MapReduce的决策表相容性判断算法
由上述浓缩布尔矩阵算法步骤可知,在得到矩阵之前很重要的一个步骤就是区分决策表中的相容对象以及不相容对象。由定义可知,判断决策表中对象的相容性,需要两两对比决策表中对象的条件属性和决策属性值;若2个对象的条件属性值不完全相同,或者条件属性值和决策属性值完全相同,则表示2个对象相容,属于U1;若2个对象对应条件属性都相同,而决策属性值不同,则表示2个对象不相容,属于U2。而判断的过程中,可以先按照条件属性对对象集进行划分,然后再判断决策属性值的一致性,由此判断过程可以看出,决策表中对象划分的过程是相互独立可并行的。
而我们只需要知道每条记录是否属于相容对象集合,而不需要输出具体结果,所以在此基础上,引入一个标志,记为CS_flag,若对象属于相容对象集,则标志为true,否则为false,最后输出一个决策表CS,这样可以缩短计算时间,提高效率。
在MapReduce并行模型中,Map的过程是将原始输入数据拆分成key/value对,然后MapReduce框架将相同key值的value分到一起,传递给Reduce进行处理。其中key和value都是偏移量,value这个值是用来进行分割处理的值。
由此可以看出,若将U中每个对象在属性集C上的属性值看成是Map过程中的key,那么,判断决策表相容性的过程与MapReduce中的Map过程是一致的,则可以通过Map的过程实现对决策表相容性判断的并行计算。
由此提出算法2。
算法2基于MapReduce的决策表相容性判断算法。
输入:决策表S=(U,C∪D)。
输出:带有CS_flag标志的新决策表CS。
Map阶段。
Map输入:〈x_No,x_C+x_D〉。
其中,x_No为决策表中的记录编号;x_C为xi在条件属性集C上的值;x_D为xi在在决策属性集D上的值。
Map输出:〈x_C,x_D+x_No〉。
Map阶段操作如下。
1)将决策表S中的对象拆分成key/value对,按照编号依次输入。
2)利用MapReduce框架对中间结果进行排序,将具有相同key的value分为一组,得到C对论域U的划分U|IND(C)={X1,X2,…,XN},并将Xi传递给Reduce任务。
Reduce阶段。
Reduce输入:〈C,Xj〉,(Xj∈U|IND(C))。
Reduce输出:〈x_No,x_C+x_D+CS_flag〉。
Reduce阶段操作如下。
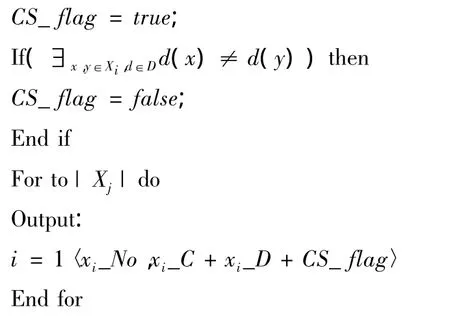
2.3 基于MapReduce的浓缩布尔矩阵算法
算法2可生成一个新的决策表CS,里面每条记录最后都添加了CS_flag的标志位,来识别该条记录是属于相容或者不相容对象集合;而根据算法1[11]可以得到,矩阵是由决策表CS中的记录两两比较所得,结合MapReduce并行模型,可得并行浓缩布尔矩阵的计算算法。
在Map实现过程中,首先为了实现记录的两两比较,将新决策表内记录拆分成多个key/value对作为Map输入,而在Map输出时,则将每条记录输出为多条,即若当前记录编号为1,则只需输出〈1,C1+D1〉,若记录编号为2,则输出〈1,C2+D2〉,〈2,C2+D2〉,以此类推;再按照key值将输出的记录进行中间合并;在Reduce过程中,通过将key值相同的记录两两进行比较,可得到IME(BM)。
算法3基于MapReduce的并行浓缩布尔矩阵算法。
输入:决策表S=(U,C∪D)。
输出:浓缩布尔矩阵IME(BM)。
1)调用算法2对原始决策表进行判断,并输出新决策表CS;
2)创建一个MapReduce任务并行计算得出浓缩布尔矩阵里的每一项,其中Map和Reduce阶段具体工作如下。
Map阶段。
Map输入:〈xi_No,xi_C+xi_D+CS_flag〉。
Map输出:〈xs_No,xi_C+xi_D+CS_flag〉。(其中,s=1,…,i)
Map阶段操作如下。

中间结果的合并由MapReduce框架完成。
Reduce阶段。
Reduce_intput:〈xs_No,xi_C+xi_D+CS_flag〉。(其中,s=1,…,i)
Reduce_output:〈x_No,x_C〉
Reduce阶段操作如下。

3)结束。
2.4 基于MapReduce的并行属性核计算算法
要得到约简结果,首先需要求出原决策表的属性核。由浓缩布尔矩阵定义可知,若矩阵中只有一个属性值为1,则该值对应的条件属性为核属性。
由于属性核的计算过程符合并行条件,因此可以结合MapReduce作并行约简。
算法4基于MapReduce的并行属性核计算算法。
输入:决策表S=(U,C∪D)。
输出:Core。
1)初始化Core=∅,调用算法3对原始决策表进行计算,并输出浓缩布尔矩阵IME(BM)。
2)创建一个MapReduce任务对所得矩阵中对象进行计算处理,其中Map和Reduce阶段过程如下。
Map阶段。
Map输入:〈x_No,x_C〉。
Map输出:〈x_One_Index,x_C〉。
Map阶段操作如下。

其中,Map的输入x为矩阵IME(BM)中的每一行记录,x_No为每行记录的编号,x_C为该行记录在所对应条件属性集C上的值。Map的输出x_One_Index为该行记录中唯一值为1所在列的编号。
中间结果合并由MapReduce框架完成。
Reduce阶段操作如下。

即是将Reduce输出存入核属数组Core中。
3)结束。
2.5 基于MapReduce的并行属性约简算法
计算决策表CS、计算浓缩布尔矩阵IME(BM)和最终结果化简是本文约简算法的3个关键步骤。本文在基于MapReduce的决策表相容性判断算法(算法2)、基于MapReduce的浓缩布尔矩阵算法(算法3)、基于MapReduce的并行属性核计算算法(算法4)基础上,提出基于MapReduce的并行属性约简算法。其中对于所得矩阵的合取析取操作采用文献[15]中赵荣泳等所提出的直接搜索算法,其过程也是可并行的。
算法5基于MapReduce的并行属性约简算法。
输入:决策表S=(U,C∪D)。
输出:决策表S的属性约简R。
1)调用算法2对决策表S相容性进行判断,得出新决策表CS;
2)调用算法3得到浓缩布尔矩阵IME(BM);
3)调用算法4并行计算属性核Core;
4)初始化一个数组R'=∅,并创建一个MapReduce任务计算约简,过程如下。
Map阶段。
Map输入:〈x_No,x_C〉。
Map输出:〈1,x_No+array(值为1所在列)〉。
Map阶段操作如下。

//对每一行记性扫描,得到所有值为1所在列编号,并构造上述输出。
其中Map的输入为矩阵IME(BM)中的每一行记录,x_No为每行记录的编号,x_C为该行记录在所对应条件属性集C上的值。Map输出的key值为该行记录中值为1所在列的编号。
Reduce阶段操作如下。

5)将输出结果放入数组R'中,则R'与Core相或可得最后约简结果。
6)结束。
文献[5]亦采用基于MapReduce的并行约简算法,其算法采用计算正域进而求得核属性的方法得出最终约简结果,算法5在计算步骤上更加简练和直观,在各个步骤都并行实现的前提下,直接通过求得浓缩布尔矩阵并进一步进行化简即可得出约简结果。
3 实验结果与分析
3.1 实验环境
为了验证本文算法的有效性以及处理大数据的能力,本文设计了以下3个实验:1)通过与传统算法对比,测试本文算法的约简效果;2)测试本文算法的大数据处理能力;3)测试本文算法在云计算环境中的加速比系数。
实验环境如表1所示。

表1 实验环境Tab.1 Experimental environment
3.2 算法约简效果的测试
3.2.1 实验目的及设置
为测试本文算法的约简效果,本文选取了UCI经典数据库中的Zoo,Glass,Chess,Heart和Iris 5个数据集,并分别采用本文算法、基于信息熵的属性约简算法[8]、归纳属性约简算法[8]、MIBARK算法[12]和MR-sAR算法[5]进行测试并对比约简效果。而针对数据集中的连续属性,均采用基于属性重要性的离散化算法[4]进行离散化。
实验分为2个部分:1)分别测试5种算法在5个数据集上的约简结果,并统计约简之后所剩条件属性的个数;2)5种算法的识别率测试(识别率=正确识别样本数/测试样本总数之比),对每个数据集,将随机抽取每个数据集的50%数据用作训练集,剩下的一半用作测试集。对训练集分别采用5种算法进行属性约简,并用归纳值约简[4]方法进行规则提取,然后对测试集进行测试,依次统计5种算法的识别率。
3.2.2 实验结果对比及分析
实验结果如表2所示,N是约简后所剩条件属性个数,P是识别率。

表2 约简效果对比Tab.2 Reduction effect contrast
从表2可以看出,本文算法在Chess数据集上,本文的算法识别率比MR-AR算法高,而在其他4个数据集上的约简结果和其他几种算法是一致的,说明本文算法的约简效果与其他算法是相当的,证明了本文算法是有效的。
3.3 并行属性约简算法的运行效率测试
3.3.1 实验目的及设置
在并行计算环境下,为了验证本文算法在处理实际大数据集的效率及有效性,本文将采用包含有4 898 432条记录的KDDCUP99[14]数据集对其进行测试,并将同时采用文献[5]中所提MR-AR算法对相同数据集在同等情况下进行算法效率的比较。数据集中每条记录都有41个条件属性和1个决策属性。实验中所采用的环境同表1,仅1个计算机节点:包括4个map和2个reduce任务。
实验过程中,把数据集等分成10份,编号1到10,每次抽取其中的9份作为训练集进行实验,保证10组数据集每组轮空一次,如此重复做10次实验,即每次实验数据集都包含4 408 588条记录,其中数据集采用等频率离散化方法[8]进行离散化处理。对比实验将分别对本文算法及MR-AR算法[5]在相同实验环境下进行测试。对比实验结果如表3所示。
3.3.2 实验结果对比及分析
实验结果如表3所示,其中列出了本文算法和MR-AR算法[5]的运行时间。

表3 运行时间统计Tab.3 Run-time statistics
从表3中可以看出,本文算法的运行时间有一定的波动,这主要是因为每次数据集虽然大小一样,但是具体记录并不相同,且系统可能出现误差;通过求运行时间方差可得MR-AR算法方差为3.3,而本文算法为2.1,可见本文算法在稳定性上要优于MR-AR算法。
从表3中还可以看出,本文算法运行时间比MR-AR算法要少,在时间效率上整体要优于MRAR算法,这是因为MR-AR算法首先需要求正区域进而再求核属性,再采用基于属性重要性求约简,需要计算属性重要性参数,再通过比较参数值将属性一一添加到核属性里,进而得到约简结果,过程较为繁杂;而本文算法在生成矩阵后,求得核属性,删除包含核属性的记录后,将矩阵中所剩记录进行合取析取操作,所得结果再跟核属性进行或操作,即可得最终约简,上述逻辑操作过程简明直观,两者相比,本文算法耗费时间更少,因而本文算法比MR-AR算法效率更高。
3.4 算法的性能测试
为了进一步对本文提出的基于MapReduce的浓缩布尔矩阵并行算法的性能进行评价,本文对并行算法的加速比(speedup)及可扩展性(scaleup)2个指标进行了测试。
1)加速比实验。
加速比是衡量并行算法性能的一个重要指标,是数据规模一定的条件下,增大计算机节点的个数时,并行算法的性能,其计算为

(4)式中:t1表示一个计算节点上该算法的运行时间;tn表示n个计算节点上该算法的运行时间。实验中,随机生成2×107,1×107条记录,其中每条记录包含10个条件属性和1个决策属性,属性值在0—9间随机取值,这些自定义数据集分别称为D1,D2。在该2个数据集上,分别在采用1—5个计算节点的情况下,对本文算法的运行时间进行测试,并计算其加速比系数,结果如图2所示。
从图2可以看出,随着计算节点的增多,加速比系数趋于缓和,这是由于各节点间通信开销、任务启动、任务调度和故障处理等时间消耗会随着节点个数增加而变多,而对于较大的数据集,其加速比系数曲线近似成线性增长,算法效果更明显,说明在云计算环境下,本文算法具有良好的加速比。
2)可扩展性实验。
可扩展性(scaleup)是指按照比例增加计算节点的个数与数据规模时并行算法的性能。其计算公式为

(5)式中:t1·DB表示在DB数据上使用1个计算节点运行该算法所用的时间;tn·n·DB表示在n·DB规模的数据上使用n个节点运行该算法所用的时间。实验依然采用数据集D1和D2,结果如图3所示。实验结果表明,算法效率整体上呈下降趋势,但是D1的曲线较D2要平稳一些,说明在数据集规模越大时,算法效率曲线越平稳,说明了本文算法具有比较良好的可扩展性。

图2 加速比系数曲线Fig.2 Speedup coefficient curve

图3 不同数据集下可扩展性对比Fig.3 Different data set scalability contrast
4 结束语
本文以浓缩布尔矩阵属性约简算法为基础,结合MapReduce并行计算模型,设计并实现了一个并行的粗糙集属性约简算法。在算法实现过程中,通过对每个步骤实现并行化,使其能在大数据环境下进行属性约简,提高了属性约简的效率。实验结果表明,本文算法在进行属性约简时是有效以及高效的,同时具有良好的并行性能。
[1]PAWLAK Z.Rough set[J].International Journal of Com-puter and Information Science,1982,11(5):341-356.
[2]SKOWRONA.RAUSZER C.The discernibility matrices and functions in information systems[M].Dordrecht:Kluwer Academic Publishers,1992:331-362.
[3]胡峰,王国胤.属性序下的快速约简算法[J].计算机学报,2007,30(8):1429-1435.
HU Feng,WANG Guoyin.Quick Reduction Algorithm Based on Attribute Order[J].Chinese Journal of Computers,2007,30(8):1429-1435.
[4]肖大伟,王国胤,胡峰.一种基于粗糙集理论的快速并行属性约简算法[J].计算机科学,2009,36(3):208-211.
XIAO Dawei,WANG Guoyin,HU Feng.Fast Parallel Attribute Reduction Algorithm Based on Rough Set Theory[J].Computer Science,2009,36(3):208-211.
[5]陈峥嵘.基于MapReduce和Rough集理论的海量数据属性约简方法研究[D].重庆:重庆邮电大学,2012.
CHEN Zhengrong.Research on Methods of Attribute Reduction for Massive Data Based on MapReduce and Rough Set Theory[D].Chongqing:Chongqing University of Posts and Telecommunications,2012.
[6]杨明,杨萍.差别矩阵浓缩及其属性约简求解方法[J].计算机科学,2006,33(9):181-183.
YANG Ming,YANG Ping.Discernibility Matrix Enriching and Computation for Attribute Reduction[J].Computer Science,2006,33(9):181-183.
[7]殷志伟,张健沛.基于浓缩布尔矩阵的属性约简算法[J].哈尔滨工程大学学报,2009,30(3):307-311.
YIN Zhiwei,ZHANG Jianpei.An Attribute Reduction Algorithm Based on a Concentration Boolean Matrix[J].Journal of Harbin Engineering University,2009,30(3):307-311.
[8]王国胤.Rough集理论与知识获取[M].西安:西安交通大学出版社,2001:30-62.
WANG Guoyin.Rough Set Theory and Knowledge Acquisition[M].Xi’an:Xi’an Jiaotong University Press,2001:30-62.
[9]DEAN J,GHEMMAWAT S.MapReduce:Simplified data processing on large clusters[C]//ACM.Proceedings of the 6th USENIX Symposium on Operating Systems Design and Implementation.New York:Press,2004:137-150.
[10]DEAN J,GHEMAWAT S.MapReduce:A flexible data processing tool[J].Communications of the ACM,2010,53(1):72-77.
[11]李丹.基于粗糙集的数据挖掘属性约简算法的研究[D].哈尔滨:哈尔滨工程大学,2008.
LI Dan.Research on Attribute Reduction Algorithms for Data Mining Based on Rough Set[D].Harbin:Harbin Engineering University,2008.
[12]苗夺谦,胡桂荣.知识约简的一种启发式算法[J].计算机研究与发展,1999,36(6):681-684.
MIAO Duoqian,HU Guirong.A Heuristic Algorithm for Reduction of Knowledge[J].Journal of Computer Researching and Development,1999,36(6):681-684.
[13]叶东毅,陈昭炯.一个新的差别矩阵及其求核方法[J].电子学报,2002,30(7):1086-1088.
YE Dongyi,CHEN Zhaojiong.A New Discernibility Matrix and the Computation of a Core[J].Acta Electronica Sinica,2002,30(7):1086-1088.
[14]ANONYMITY.KDDCUP99[EB/OL].(2007-06-26)[2013-01-19].http://kdd.ics.uci.edu/databases/kddcup99/.
[15]赵容泳,张浩,李翠玲,等.粗糙集理论中分辨函数的析取范式生成算法[J].计算机工程,2006,32(2):183-185.
ZHAO Rongyong,ZHANG Hao,LI Cuiling,et al.Disjunctive Normal Form Generation Algorithm for Discernibility Function in Rough Set Theory[J].Computer Engineering,2006,32(2):183-185.
