基于NLB检索系统词语搭配统计值的日语近义词词典编纂构想
2015-09-11刘艳伟刘玉琴
刘艳伟 刘玉琴
(大连理工大学 软件学院,辽宁 大连 116624)
基于NLB检索系统词语搭配统计值的日语近义词词典编纂构想
刘艳伟 刘玉琴1
(大连理工大学 软件学院,辽宁 大连 116624)
日语近义词词典作为日语学习者重要的参考工具书,若不能提供丰富、详尽、科学的近义词辨析信息,很可能导致误用,阻碍学习。语料库提供大量的真实语料,基于语料库的词语搭配,对近义词进行辨析,使近义词研究更具科学性和有效性。NLB检索系统是日本国立国语研究所和Lago语言研究所共同开发的日语在线检索系统,检索数据源于「現代日本語書き言葉均衡コーパス」语料库。NLB自动呈现节点词与搭配词的共现频数、MI值和LD值。本文基于NLB检索系统,以近义词「文句」和「苦情」为例,从词配角度区分二者的异同,探讨日语近义词词典编纂的新方法。
NLB检索系统;词语搭配;共现频数;MI值;LD值
一、引言
近义词(synonym),在很多研究中也被译为“同义词”。Lyons(1981:50)定义并确立了同义词的分类标准,同时也指出了近义词的概念:意义上相近但不相同的词。本文中的近义词将沿用Lyons的概念。
日语近义词的大量存在使近义词辨析成为日语学习中不容忽视的领域。任培红(2008:57)指出:“传统的近义词辨析方法,是在教学中给出定义和描述,辅之以少量例句。教师和学习者往往依赖词典,或通过内省和凭经验进行定性分析,以比较近义词之间的差异。”日语近义词词典作为日语学习者重要的参考工具书,应该提供丰富详尽的近义词辨析信息。笔者选取一组常用的近义词「文句」和「苦情」,考察了近义词词典对其用法的解释,发现结果并不尽如人意。
语料库问世前的研究,缺乏足够的自然数据,缺乏科学性和有效性。语料库提供大量的真实语料,国内外学者运用语料库的方法对近义词进行了研究,具有代表性的欧美学者有Biber等(2000)、Kennedy(1998)、Thomas & Short(2001);日本学者有田野村忠温(1994)、大曾美惠子(2002)、野田春美(2004)、杉本武(2009);国内运用语料库方法从事英语近义词研究的有张继东、刘萍(2005)、任培红(2008)、王春艳(2009)、陆军(2010)等,从事日语近义词研究的有毛文伟(2002)、王华伟、曹亚辉(2012)等。其中,有些研究并没有科学的统计方法,缺乏科学理论依据。有的研究虽然采用了科学的统计方法,但由于统计过程完全靠人工进行,需要语言学者必须掌握统计学知识,也会耗费大量的精力。
张继东、刘萍(2005)提出了基于语料库进行同义词辨析的三种方法,即同义词在不同语域中词频分布差异;搭配词的计算与同义词的辨析;语义韵、类联结与同义词的辨析。其中搭配词的计算与同义词的辨析方法就是以节点词的跨距为参照,统计同义词的显著搭配词,并计算同义词与其搭配词相互信息值(MI值)以及Z值(或T值)。
朱文慧、马立东(2010)将基于语料库的近义词辨析的方法归为四种:近义词的词汇搭配,近义词的语义韵,近义词的类连接以及近义词的语域分布的异同。尝试将语料库中检索到的近义词的搭配词及语义韵特点等信息整合到英汉学习型词典的近义词辨析栏中,从而实现英汉学习型词典中近义词辨析栏的优化设置。这开辟了基于语料库编纂近义词词典的科学新理念。但只是宏观提出了划分方法,关于词配研究的相关统计值、统计方法和显著搭配的例句等都没有涉及。
本文借鉴以上张继东、刘萍(2005)、朱文慧、马立东(2010)提出的通过词语搭配进行同义词辨析的方法,以近义词「文句」和「苦情」为例,在综合现有日语近义词词典的基础上,结合NLB检索系统提供的词语搭配值(MI值和LD值),来区分日语近义词异同,提出基于NLB检索系统词语搭配统计值,编纂日语近义词词典的新方法。
二、NLB检索系统及其提供的词语搭配统计值
NLB为NINJAL-LWP for BCCWJ的简称。日本国立国语研究所构建的「現代日本語書き言葉均衡コーパス」已经广为中国日语研究者所知。正是为了方便「現代日本語書き言葉均衡コーパス」的检索,日本国立国语研究所和Lago语言研究所共同开发了在线检索系统NLB。该系统于2013年6月25日公开,容量共计约1.05亿词。NLB最大的特征是能系统地展示各词汇与节点词之间的共起关系。网址为:http:// nlb.ninjal.ac.jp/。所使用的解析器和词典为:形态素解析器 MeCab0.99+IPA,词典2.7.0,系受关系解析器CaboCha0.64。
词语搭配指词与词的结伴,是一种高度因循性的词语组合,是词语间的典型共现行为(邓耀臣,2003)。在外语学习中,掌握和使用典型的词语搭配是学习本族语者的无标记语言的重要内容之一(邓耀臣,2003)。语料库证据表明,每一个词项都有其独特的搭配行为,同义词也不例外,它们一般只在概念意义上相同或接近,但在搭配词选择上并不能随意替换(陆军,2010)。国内关于词语搭配中共现词显著性的测量方法通常使用MI值和T值两种。这两种方法都是通过比较共现词的观察频数(observed frequency)和期望频数(expected frequency)的差异来确定搭配序列在语料库中出现概率的显著程度(邓耀臣,2003)。
(一)MI值的统计测量
MI值(Mutual Information Score 互信息值)表示的是互相共现的两个词中,一个词对另一个词的影响程度,或者说一个词在语料库中出现的频数所能提供的关于另一个词出现的概率信息。MI值越大,说明节点词对其词汇环境影响越大,对其共现词吸引力越强。因此,MI值表示的是词语间的搭配强度。
MI=log2(共现的实际频数×语料库总词数/节点词频数×搭配词频数)(王华伟 曹亚辉,2012)
基于语料库的词语搭配研究中通常把MI值≥3的词作为显著搭配词(Church等,1991)。
(二)T值的统计测量
T值表示的是节点词与搭配词相互预见或相互吸引的程度。T值达到一定程度,搭配词即可被视为显著搭配词,它与节点词组成的序列则是显著搭配。卫乃兴(2002:107)指出:“研究者一般将T值≥2的认定为显著值,因为用该值基本上可将偶然搭配词过滤掉,获得全部有意义的搭配。”

(三)LD值的统计测量
NLB检索系统采用的是MI值和LD值的统计测量。中条、内山(2004)对9种统计值准确度比较后得知,D值是有用度和准确度都很高的指标。D值常用来统计处理词语搭配,它的计算不需要语料库的总词量,只通过节点词频数和共起词频数二者的关系来计算词语搭配的强度。
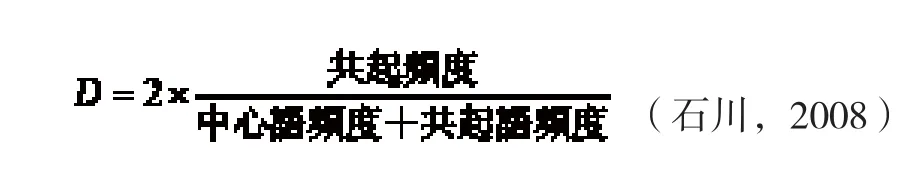
但是因为D值很小,常常是0.0xx,所以Rychlý(2008)提出用LD值代替D值。LD即LogDice,是将D值对数化的结果。

LD的最大值是14,通常情况下小于10。LD值越大,搭配强度越大。本文将LD值≥3的搭配视为显著搭配。
三、日语词典中对「文句」和「苦情」的释义
「文句」和「苦情」都有“牢骚、抱怨、不满”之意,在表示该意义时为近义词。本文将二者进行比较,目的在于说明NLB检索系统提供的MI值和LD值在区分日语近义词时起到的重要作用,提出基于NLB检索系统编纂日语近义词词典的新方法。「文句」和「苦情」是两个常用的名词,在句中可以充当主语或宾语成分。词典中对二者表示“牢骚、抱怨、不满”之意时的解释为:
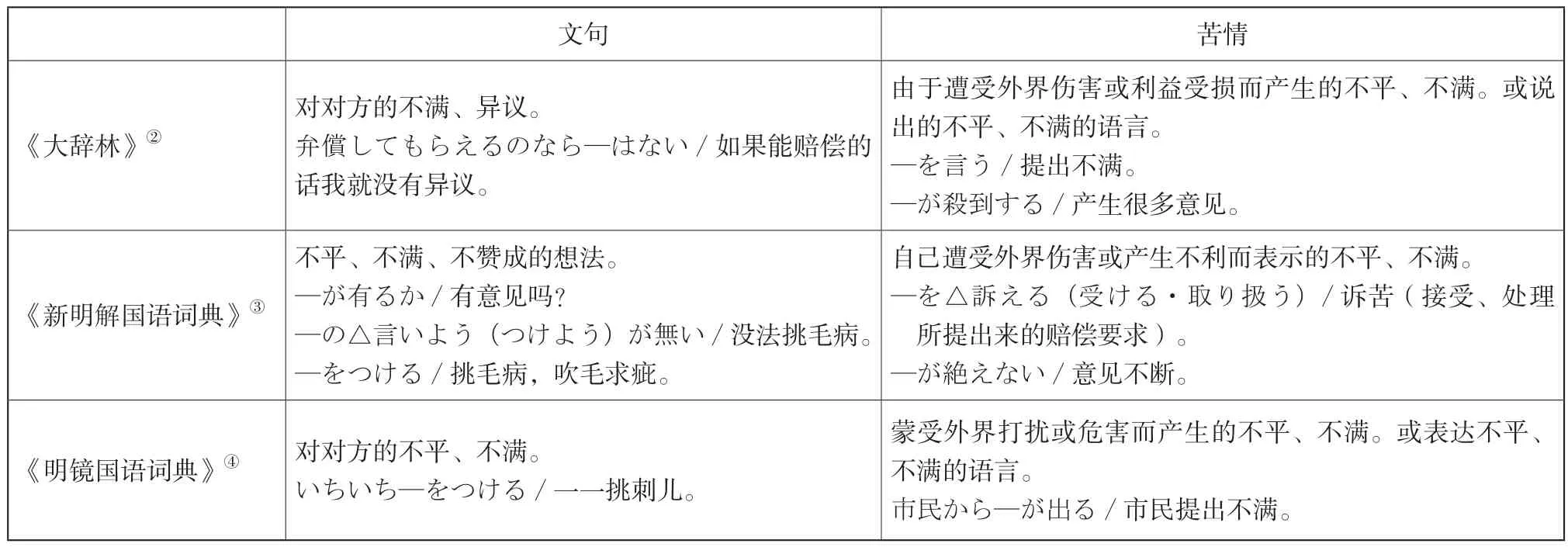
表1 词典中对「文句」和「苦情」的释义①
词典虽然列举了一些搭配和例句, 但单凭这些脱离上下文和真实语境的例子很难使学习者真正掌握二者微妙的差异和恰当的用法。根据以上解释,日语学习者很容易做出如此判断:「文句」是单纯地向对方表示不满,而「苦情」则是因为自己的利益受到了损害而不满。由于例句过短、过少,使学习者无法更多地把握该词的使用语境,很有可能造成误用。再有, 例句中出现的搭配词语是否为显著搭配不得而知。《新明解国语词典》中给出的「苦情を取り扱う」,这种搭配本身虽然没有问题,但它的显著程度还需要科学的验证。
『使い方の分かる類語例解辞典』⑤(以下简称为《类语辞典》)把「文句」和「苦情」作为一对近义词进行了辨析:
相同意义:对蒙受的伤害、妨碍等表示的不满、不平或愤怒。
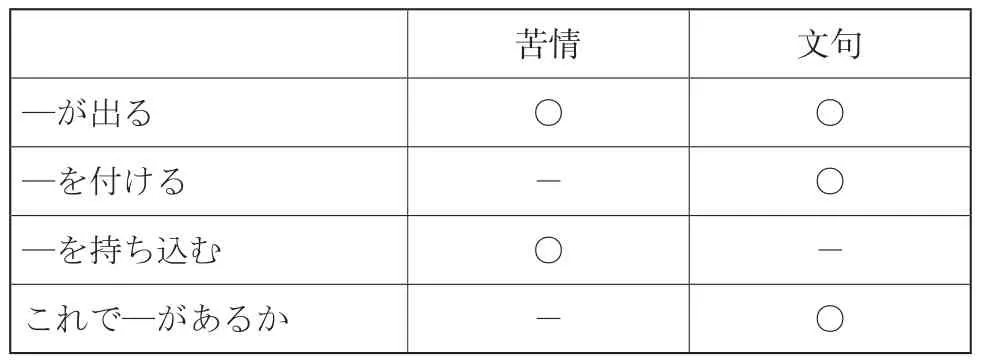
区别:(一)「苦情」是因为外界给自己带来了妨碍、困扰或因购买的商品存在问题而提出的不满,是比较正式的表达方式。(二)「文句」可用于挑刺儿、找茬儿等没有正当理由的不满。
《类语辞典》同样存在以上三部词典的问题:例句过短过少;搭配词语是否为显著搭配有待验证。除此之外,《大》、《新》、《明》三部词典将“蒙受外界的损害”只作为「苦情」的前提,关于「文句」的释义中是没有这个前提的,因此日语学习者很有可能将这一前提作为「文句」和「苦情」的区别。而《类语辞典》却将这一前提作为二者的共同之处,词典之间的矛盾使日语学习者感到迷茫,手足无措。
四、基于NLB检索系统的考察
在NLB检索系统中输入节点词「文句」和「苦情」,系统显示出「現代日本語書き言葉均衡コーパス」中所包含的节点词「文句」的频数为2,490,节点词「苦情」的频数为2,376,不符合义项要求的部分将在考察时排除。NLB检索系统将节点词的所有用法都进行了归类,如「节点词+助詞+動詞」「動詞+节点词」「节点词+助詞+形容詞」「节点词+助詞」等。本文基于NLB检索系统提供的频数、MI值和LD值,以近义词「文句」和「苦情」为例,从词配角度区分二者的异同,探讨编纂日语近义词词典的新方法。
首先将节点词「文句」和「苦情」后续「を+動詞」用法中共现频数最多的前10个搭配词及其MI值和LD值进行汇总,形成表2。
点击语料库中的共现词,可以查看语料库中包含该共现词的例句。笔者经过逐一检验之后,排除以下类型检索结果。
(1)「文句を唱える」类型。这里的「文句」应该是“词句、话语”之意,不符合义项要求。
(2)后续动词为非实意动词的类型,(表2中标记*之处)例如:
★文句を~~いる
◆お父さんは黙っている。お母さんはどんどん続けてお父さんに文句を言っている。でも、お父さんの声は聞えない。/父亲沉默不语。妈妈一个劲儿地发着牢骚。可是,却听不到父亲的声音。
★文句を~~くる
◆どうにか家までたどり着いたと思ったら、今度は料金に文句をつけてきた。/想着这下可算到家了,可是又对费用问题挑起刺儿来。
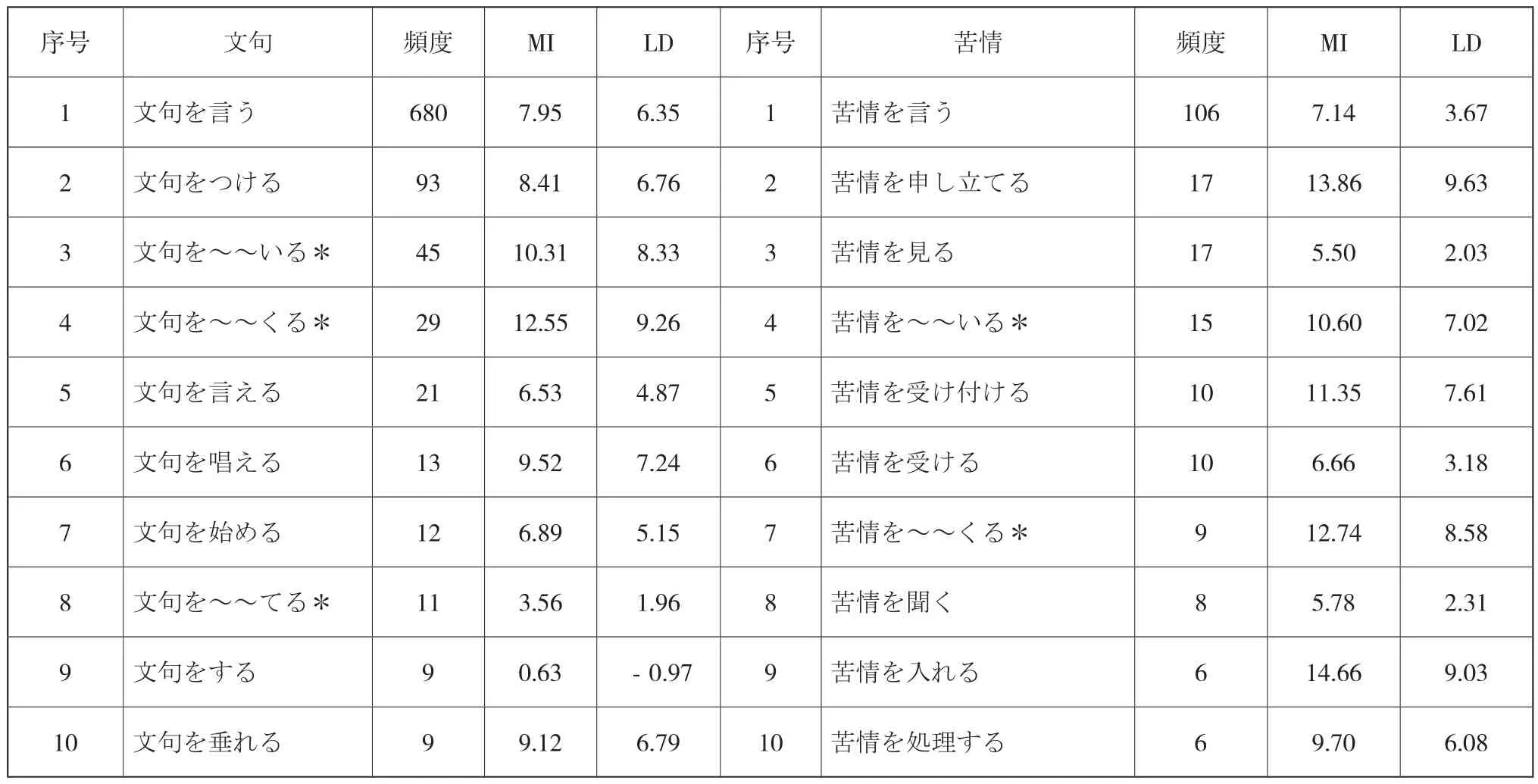
表2 节点词「文句」和「苦情」后续「を+動詞」时共现频数最多的前10个搭配词⑥
★文句を~~てる
◆新婚旅行のお土産を配った同僚に「これっくらいの土産じゃね…」と面と向かって文句を言ってた。/一个同事刚分完自己新婚旅行的礼物,就有人当面牢骚道:“就这种礼物啊……”。
「苦情を~~いる」和「苦情を~~くる」属于同一类型,在此省略例句,这类用法也不属于本文考察范围,筛选时将其排除。
从表2的搭配情况来看,「文句」和「苦情」后面存在相同的共现动词「言う」。动词「つける」「言える」「始める」等只与「文句」共现,而「申し立てる」「見る」「受け付ける」等只与「苦情」共现。从共现频数来看,与两词共现频数最高的都是「言う」,分别为680次和106次,前者约等于后者的6倍,可见「文句を言う」比「苦情を言う」的使用频率高。
然而,搭配词共现频数高并不意味着是显著搭配,还需要分析MI值和LD值的情况。MI值≥3,LD值≥3的词即可视为显著搭配词。MI值和LD值越大,说明节点词对其词汇环境影响越大,对其共现词吸引力越强。
表2中节点词「文句」后续「を言う」频数为680,排在第一位,MI值为7.95,LD值为6.35,远大于3,所以,「を言う」为「文句」的显著搭配。而节点词「苦情」后续「を見る」的频数为17,虽然排在第3位,但由于其MI值为5.50,LD值为2.03,LD值小于3,所以不视为显著搭配。
五、基于词语搭配统计值的近义词词典编纂思路
使用以上方法,分别汇总「文句」和「苦情」所有用法中的显著搭配,再将其分条对照地编入词典,并筛选出语料库中有代表性的句子作为例句。拟编写近义词词典样例,参见表3。篇幅原因,表3中只列出「文句」和「苦情」后续「を+動詞」的用法。词典采取左右对照的形式,相同用法在同一行左右对照出现,使两词区别一目了然。
从表3的样例可以清楚的比较两个近义词的区别。第一,在后续「を+動詞」的用法中,与「文句」显著搭配的动词只有「言う」和「つける」两个,而与「苦情」显著搭配的动词有「言う」「申し立てる」「受け付ける」和「受ける」。第二,「言う」与两个词都是显著搭配,表达的意义却不同。通过词典样例可知,「文句」是一方带有情绪地埋怨另一方,而「苦情」是对自己蒙受的损失、不利或遭到的不愉快提出申诉,多用于公众发出的不满或个人对公家的不满,而亲人、朋友之间的不满则用「文句」。
六、结语
NLB检索系统自动呈现频数、MI值和LD值,省去了日语研究者自己统计的过程,弥补了研究者统计学知识的匮乏,打破了语言学与统计学之间的界限。根据频数、MI值和LD值,能够科学准确地判断词语搭配强度等相关信息,掌握节点词的常用用法,便于区分近义词的异同。
另外,NLB检索系统中的语料为广大日语学者非常熟悉的「現代日本語書き言葉均衡コーパス」语料库语料,它呈现的是原汁原味的真实语料,把这些日常生活中经常用到的日语经过筛选之后编入词典,会帮助日语学习者在不同语境中了解近义词的各自用法,方便对近义词做出辨析,有助于区分近义词,避免误用,加快正确掌握目的语的进程。
注释:
① 本文日文例句部分为笔者译。
② 参见:松村明.2006.大辞林 第二版[Z].東京:三省堂.
③ 参见:金田一京助.1999.新明解国語辞典 第五版[Z].東京:三省堂.
④ 参见:北原保雄.2002.明鏡国語辞典 第一版[Z].東京:大修館書店.
⑤ 参见:遠藤織枝等.2003.使い方の分かる類語例解辞典 新装版[Z].東京:小学館.
⑥ 「文句」节点词频数:1,070,搭配动词数量:88;「苦情」节点词频数:292,搭配动词数量:70。
[1] Biber, D., S. Conrad & R. Reppen. 2000.Corpus Linguistics Foreign Language[M]. Cambridge: Cambridge University Press.
[2] Church, K. et al. 1991. Using statistics in lexical analysis[A]. In U. Zernik (ed.), Lexical Acquisition:Exploring On-line Resources to Build a Lexicon[C]. Hillsdale, NJ:Lawrence Erlbaum Associates.
[3] Kennedy, G. 1998.An Introduction to Corpus Linguistics[M]. London: Addison Wesley Longman.
[4] Lyons, J. 1981. Language and L inguistics[M].Cambridge: Cambridge University Press.
[5] Rychlý, P. 2008. A lexicographer-friendly association score[J]. Proceedings of Recent Advances in Slavonic Natural Language Processing, (4):6-9.
[6] Thomas, J & M. Short. 2001.用语料库研究语言[M].北京:外语教学与研究出版社.
[7] 石川慎一郎.2008.コロケーションの強度をどう測るか——ダイス係数、tスコア,相互情報量を中心として[A].徳永健伸.自然言語処理[C].京都:中西印刷.
[8] 大曽美惠子.2002.コーパスから得られるコロケーション情報―『影響、刺激、感動』を中心に― [A].名古屋大学言語文化部・国際言語文化研究科.言語文化論集[C].名古屋:名古屋大学.
[9] 杉本武.2009.コーパスからみた類義語動詞:「ねじる」と「ひねる」[J].文芸言語研究言語篇,(55):109-122.
[10] 田野村忠温.1994.丁寧体の述語否定形の選択に関する計量の調査——「~ません」と「~ないです」[A].古谷大輔.大阪外国語大学論集[C].大阪:一心社.
[11] 中條清美 内山将夫.2004.統計的指標を利用した特徴語抽出に関する研究[A].斉田智里.関東甲信越英語教育学会紀要[C].横浜:関東甲信越英語教育学会.
[12] 野田春美.2004.否定ていねい形「ません」と「ないです」の使用に関わる要因―用例調査と若年層アンケート調査に基づいてー[J].計量国語学,(5):228-244.
[13] 邓耀臣.2003.词语搭配研究中的统计方法[J].大连海事大学学报(社会科学版),(4):74-77.
[14] 陆军.2010.基于语料库的学习者英语近义词搭配行为与语义韵研究[J].现代外语,(3):276-286+329-330.
[15] 毛文伟.2002.试析复合辞“~テナラナイ”“~テショウガナイ”“~テタマラナイ”的异同──语料库统计法在语法研究中的应用一例[J].解放军外国语学院学报,(3):62-66.
[16] 任培红.2008.近义词的教与学:以Common和Ordinary为例[J].解放军外国语学院学报,(4):57-60.
[17] 王春艳.2009.基于语料库的中国学习者英语近义词区分探讨[J].外语与外语教学,(6):27-31.
[18] 王华伟 曹亚辉.2012.日语教学中基于语料库的词语搭配研究——以一组动词近义词为例[J].解放军外国语学院学报,(2):71-75+91.
[19] 卫乃兴.2002.基于语料库和语料库驱动的词语搭配研究[J].当代语言学,(2):101-114.
[20] 张继东 刘萍.2005.基于语料库近义词辨析的一般方法[J].解放军外国语学院学报,(6):49-52.
[21] 朱文慧 马立东.2010.英汉学习型词典中近义词辨析栏的优化设置──基于语料库的近义词辨析及其应用[J].辞书研究,(6):78-87.
Conceptions of Japanese Synonym Lexicography Based on the Statistics of Word Collocation in NLB Retrieval System
As an important reference book for Japanese learners, Japanese synonym dictionary will impede students’ Japanese learning and lead them to misuse some words if it cannot provide rich, detailed and scientific synonym discrimination information. Since a corpus provides a large quantity of authentic language materials, synonym discrimination based on a corpus can make the research into synonyms more scientific and effective. As an online Japanese retrieval system jointly developed by National Institute for Japanese Language and Linguistics and Lago Language Research Institute, NLB gets its data from the Balanced Corpus of Contemporary Written Japanese and it can automatically reflect the co-occurrence frequency, MI value and LD value of node words and their collocates. Based on the collocation information found in NLB, this paper analyzes the similarities and differences between “文句” and “苦情”, and thus explores the new methods of Japanese synonym lexicography.
NLB retrieval system; collocation; co-occurrence frequency; MI score; LD score
G42
A
2095-4948(2015)02-0070-06
本文为教育部人文社会科学研究规划基金项目“基于视频语料库的日语拒绝行为的研究”(13YJA740039)、辽宁省教育科学“十二五”规划项目“基于视频语料库的日语授受表达习得平台的建设”(JG14DB090)的阶段性成果。
刘艳伟,女,大连理工大学软件学院讲师,研究方向为应用语言学;刘玉琴,女,大连理工大学软件学院副教授,博士,研究方向为教育工学、应用言语学、语料库语言学。
