不均衡数据混合取样分类算法
2015-06-01杜红乐商洛学院数学与计算机应用学院陕西商洛726000
杜红乐,张 燕(商洛学院数学与计算机应用学院,陕西商洛726000)
不均衡数据混合取样分类算法
杜红乐∗,张 燕
(商洛学院数学与计算机应用学院,陕西商洛726000)
摘 要:针对不均衡数据分类决策面偏移导致少数类识别率较低的问题,提出一种混合取样算法。首先计算类样本数的比值K;然后分别在多数类和少数类中随机选取一个样本,计算该样本的K-1近邻,以K个样本的中心作为新样本;再对剩余的样本重复上面操作,直到所有样本都被处理;最后所得新样本与原少数类样本共同构成新的训练集。该算法在改变样本密度的同时保持了原样本的空间分布,实验结果表明该算法能够提高SVM在不均衡数据下的分类性能,尤其是少数类的分类性能。
关键词:支持向量机;过取样;不均衡数据集;欠取样;K近邻
0 引言
支持向量机(Support Vector Machine,SVM)是在统计学习理论基础上发展起来的一种新的机器学习方法,它基于结构风险最小化原则,在解决小样本、非线性及高维模式识别问题中表现出许多特有的优势。近年来,SVM是机器学习领域的一个研究热点,在许多领域都取得广泛的应用。
传统SVM在均衡训练样本下有较好的分类性能,然而研究表明,在样本数量不均衡的情况下SVM对少类样本分类准确率远低于对多类样本的分类准确率,因为传统SVM算法偏向于多数类,即对多数类样本的过于拟合,而对少数类样本则是欠学习,因而导致对少数类样本的分类错误率较高。但实际应用中对少数类样本的分类性能要求比对多类样本的分类性能高的多,例如入侵检测中入侵行为样本较难收集,是少数样本,把一个入侵行为错分为正常行为要比把一个正常行为错分为入侵行为造成的危害大的多。因此为提高对不平衡数据的分类能力,研究者们提出了很多相应的解决方法,这些方法可以分为两类:数据层面的方法和算法层面的方法。数据层面的方法主要是通过一定策略删除多数类的样本或者增加少数类的样本使数据集均衡化,进而提高分类器在不均衡数据集下的分类性能,常采用的方法有过采样[1⁃4]、欠采样[5⁃9]和混合取样[10⁃12]。算法层面的方法主要有单类学习、代价敏感学习、核方法、集成方法如boosting等。
文献[4⁃9]都采用聚类算法对数据集进行相应处理,文献[5]利用K⁃Means算法对多数类样本进行聚类并提取类中心,得到与少数类样本数量相当的样本重构新的训练集,为了避免少数类样本过少导致最终训练样本过度稀疏,对少数类样本采用SMOTE算法进行过取样;文献[6]为提高泛化能力,聚类在核空间中进行,并利用AdaBoost集成手段对该欠取样算法进行集成;文献[7]引入“聚类一致性系数”找出处于少数类边界区域和处于多数类中心区域的样本,然后用SMOTE对少数类样本进行过取样,用改进的随机欠取样对多数类样本进行处理;文献[8]利用谱聚类的优点对多数类样本在核空间中进行谱聚类,然后依据聚类大小和聚类与少数样本间的距离选择有代表性的信息点。以上方法要么用聚类方法,要么经过聚类再进一步进行欠取样和过取样,但导致分类超平面偏移主要原因是两类中样本密度差异,数据集的均衡化处理实际就是在多数类和少数类样本空间中密度分布的均衡化,而影响分类超平面走势的是样本空间分布,而聚类算法在改变样本密度同时会改变样本的空间分布。
基于以上分析,结合聚类算法和K近邻算法,本文给出一种基于核空间的K近邻变形算法,并将其应用于不均衡数据分类中,该算法首先计算多数类样本数与少数类样本数的比值K;然后对多数类随机选取一个样本p并计算其K-1个近邻样本,用K个样本的中心取代上面K个样本;重复以上过程直到所有样本都被处理;对于少数类样本用K个近邻的中心加入原少数类样本中,最终重构新的数据训练集。该算法不仅保持样本在原样本的空间分布,而且对不均衡数据进行均衡化处理,仿真实验表明该方法较好地避免了不均衡数据集导致分类决策面偏移的问题,提高了分类器的分类准确率,特别是对少数类样本的分类准确率。
1 支持向量机
1.1SVM算法
训练SVM的过程实质就是求解最优分类超平面问题,即要保证正确分类的最小错误率,又要保证最大化分类间隔。给定一个样本集T={(x1,y1),(x2,y2),…,(xl,yl)},xi∈Rn,yi∈{1,-1}。SVM的主要目的是构造一个分类超平面以分割两类不同的样本,使得分类间隔最大,同时错误率最小,通过求解下面二次优化问题,得到决策函数。


通过引入Lagrange算子可以得到问题(1)的对偶问题:其中,K(xi,xj)为核函数,K(xi,xj)=〈ϕ(xi),ϕ(xj)〉,是采用非线性映射φ:Rn|→F将训练样本从输入空间映射到某一特征空间,在该特征空间中样本是线性可分的。最后可以得到决策函数为

由决策函数可以看出,影响支持向量机最终分类性能的是支持向量,即ai≠0的样本,如图1所示,而那些远离分类超平面的样本对分类结果影响较小可以忽略。

图1 样本比例100∶100分类超平面Fig.1 Classification decision surface of proportion of the sample 100∶100
1.2不均衡数据对SVM的影响
不均衡数据(Imbalanced Data,ID)指的是同一数据集中某些类的样本数量比其他类的样本数量多的多,其中样本数量多的类称为多数类,样本数量少的类称为少数类。通常如果目标类在数据集中所占比例非常小(通常远低于10%)就称为稀有类。所谓不均衡分类问题指的是对这些不平衡数据进行分类时,传统的分类方法倾向于对多数类有较高的识别率,对少数类的识别率却很低的问题。
为观察不均衡数据对分类决策面的影响,随机产生两类均匀分布的样本,第一类样本为U([0,1]×[0,1]),第二类样本为U([0,1]×[1,2]),第一类样本数为200,第二类样本数为20,经支持向量机训练最终的分类决策面如图2所示,其中0号线为分类超平面。
由图1和图2可以看出数据不均衡的情况下,分类超平面向少数类样本侧移动,如图2中,分类超平面向少数类方向偏移,导致对多数类的过学习。这是因为支持向量机在训练的时候认为两类样本错分造成的损失相同,即采用了相同的惩罚因子。支持向量机为了使分类间隔尽可能的大,同时保证分类错误率尽可能的小,因此分类超平面会向少数类样本方向偏移,最终导致对少数类样本分类错误率较高。针对此,文献[13]提出了对两个类采用不同的惩罚因子,为体现对少数类的重视,对少数类采用较大的惩罚因子,而对多数类采用较小的惩罚因子,一方面对于不同的训练数据惩罚因子确定困难,另一方面,数据不均衡问题根本原因在于样本密度不均衡性,在图2中表现为多数类和少数类在两个区域中的样本密度不同,因此提高少数类样本的分类准确率从样本的均衡化入手,使得分类超平面不会向少数类方向偏移。图3为图2中数据把原来边界样本删除,但分类边界样本密度不改变情况下的分类超平面示意图。由此可以看到,若只改变样本数量而不改变样本密度,则不会改变分类超平面的位置,因此重取样需要保持样本原有的分布同时改变样本密度。

图2 样本比例200∶20时的分类超平面Fig.2 Classification decision surface of proportion of the sample 200∶20
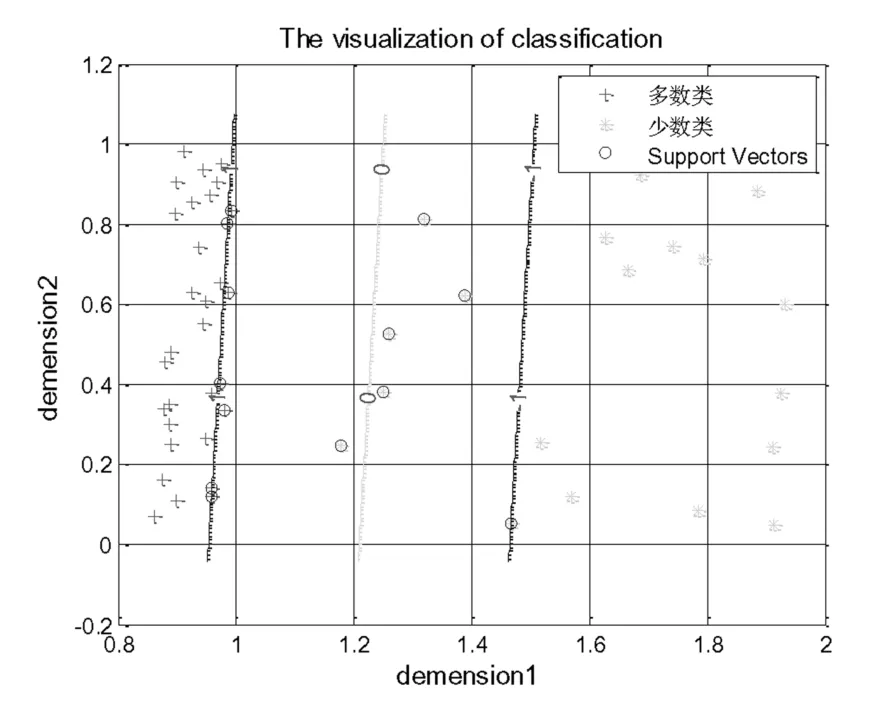
图3 样本密度不改变的分类超平面Fig.3 Classification decision surface of invariant density of the sample
2 重取样算法
本算法首先依据多数类样本和少数类样本数量比值确定K值,然后对多数类随机取一个样本p 的K-1个近邻,然后利用这K个样本的平均值取代该样本,然后计算样本p最远的样本的K-1个近邻,重复以上过程构造新的平衡数据集,该方法可以保持样本原来的密度分布,同时可以对不均衡训练数据进行均衡化,避免直接使用不均衡数据集导致对多数类过拟合现象。
算法1 欠取样算法

算法2 过取样算法

算法1得到的数据集CB和算法2得到的数据集CS合并得到新的训练集。算法1和算法2都是利用K近邻进行数据处理,具体处理过程如下:
1)计算样本之间的距离矩阵

2)任意选择一行,记录该行中最小的K个值对应的列号,然后计算对应编号的数据的平均值;
3)删除上面列号对应的行和列,若行数小于K,则计算剩余编号对应的数据的平均值;否则重复执行(2)。
计算距离采用特征空间中的距离,本文中核函数选择RBF进行空间转换。算法1和算法2都能够更准确的保持数据集原来的样本分布,对于少数类样本能够较充分的包含该类样本信息时可以只选择算法1对多数类样本进行欠取样,对于多数类样本如果已经不能再精简的情况下可以只选择算法2对少数类样本进行过取样,在大多数情况下结合使用算法1和算法2。
3 实验及数据分析
为验证本文算法的有效性,该节用人工数据集和UCI数据集对本文算法进行验证。实验设计思路如下:首先选择二维人工不均衡数据,可以看到分类超平面的偏移情况,并与聚类方法和不使用降维处理的SVM算法进行对比,来验证本文算法的性能;然后用不均衡的UCI数据集进行相同的验证;最后对分类器训练的时间复杂度进行分析,并比较在UCI数据集上的训练时间进行比较,对比分类时间及总体分类性能上的效果。
本文中所做实验是在Matlab 7.11.0环境下,结合台湾林智仁老师的LIBSVM[14],CPU为Intel Core i7 2.3GHz,8G内存,操作系统为Win7的PC机上完成。
3.1性能评价
对于均衡数据的分类方法中,常用分类精度作为评价指标,该评价指标基于错分代价相同,因此这个评价指标用在不均衡数据集则不合理,学者[15]给出了针对不均衡数据的评价指标,TP为正类样本被分为正类的数量,FP为正类样本被分为负类的数量,FN为负类样本被分为正类的样本数量,TN为负类样本被分为负类的数量。假设正类为多数类,则由此得少数类正确分类率为

多数类样本正确率为
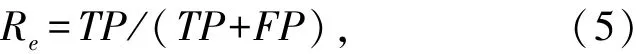
少数类查准率为

Pr=TN/(FP+TN),(6)则Fv和Gm定义如下:其中,λ为Pr与Re的相对重要性。Fv综合考虑少数类样本的准确率和查准率,因此能够更准确的反映对少数类样本的分类性能;而Gm综合考虑多数类和少数类样本的分类准确率,因此能够衡量分类器的整体分类性能。本文实验中使用这两个评价指标,且取λ=1。
3.2人工数据集
3.2.1线性可分数据
为简化过程本文实验数据采用人工生成方式,为观察不均衡数据对分类决策面的影响,随机产生两类均匀分布的不均衡样本,第一类样本为U([0,1]×[0,1]),第二类样本为U([0,1]×[1,2]),第一类样本数为200,第二类样本数为20。测试集同样采用均衡分布的人工数据第一类样本为U([0,1]×[0,1]),第二类样本为U([0,1]×[1,2]),两类样本各100个样本。
由于上面数据集是随机生成的,具有一定的偶然性,因此实验给出5次测试结果及平均值。表1给出了5次随机数据的实验结果,其中核函数采用径向基核函数。
从表1中可以看到,本文算法的Fv和Gm3次结果比聚类算法结果要好,有一次同聚类算法的结果相同,有一次比聚类算法的结果稍差,但是所有都比直接采用SVM算法要好,从5次的平均值可以看到该算法略优于聚类算法,明显优于直接采用SVM算法。图4和图5是图2中不均衡数据集经聚类算法和本文算法进行相应处理后,用SVM进行训练得到的分类超平面图,可以看到分类超平面明显向多数类倾斜,倾斜程度可以通过K值进行控制。从图中可以看到本文算法较好的保持了原样本的空间分布,因此该算法比聚类算法和直接用SVM算法实验效果好。

表1 实验结果对比(一)Tab.1 Comparison of experimental results(1)

图4 聚类算法的分类超平面Fig.4 Classification figure of clustering algorithm

图5 本文算法的分类超平面Fig.5 Classification figure of the proposed algorithm
3.2.2线性不可分数据集
其中,第一类样本的半径是均匀分布ρ∈[0,5],第二类样本的半径是均匀分布ρ∈[5,10],第一类样本数为200个,第二类样本数为20,作为训练样本;测试样本集数量为200,两类各100个样本。这里选择径向基核函数K(x,y)=exp(-g‖x-y‖2)。与3.2.1节相同,实验同样给出5次测试结果及平均值,表2给出了5次随机数据的实验结果,其中核函数仍然采用径向基核函数。从表2中可以看到,5次实验结果中本文算法都优于聚类算法和直接SVM算法,尤其是在第4次中,本文算法的Fv和Gm都达到到100%。对比表1和表2,表2中本文算法和聚类算法的性能指标要优于表1,原因在于该数据集的样本空间要比表1中对应样本空间要大,因此样本分布在边界附近的概率就小,因此各项指标优于表1。
3.3UCI数据集
本实验数据集采选取Contraceptive Method Choice(Cmc)、Haberman′s survival、Ionosphere、Letter Recognition和Pima Indians Diabetes5组UCI数据,这5组实验数据属性都为实数,并且类样本间有不同程度的不均衡性,本实验中多数类样本为正类,少数类样本为负类。由表3可以看出,多数类和少数类各组数据中属性、样本数量等特点。数据集Cmc和letter是多类数据集,该实验把其转换为2类数据,数据集Cmc把B类作为少数类,其它R和L类作为多数类,数据集letter把A类作为少数类,其它B⁃Z类作为多数类。
表4给出了在数据集Cmc、Haberman′ssurvival、Ionosphere、Letter Recognition和Pima上的实验结果,本文算法在数据集pima和Ionosphere上实验效果比聚类算法差,而在其余数据集上算法优于聚类算法,原因在于本文算法若K=1则相当于数据集未被改变,不均衡问题仍然存在;若K=2相当于把多数类样本减少一半,结果是原来的多数类变为少数类,原来的少数类变为多数类,构成新的不均衡数据。而对于比值较大的Cmc、Haberman′s survival和Letter Recognition数据集有较好的实验效果。

表2 实验结果对比(二)Tab.2 Comparison of experimental results(2)

表3 实验数据集Tab.3 Experimental datasets

表4 实验结果对比(三)Tab.4 Comparison of experimental results(3)
3.4K值对算法的影响
本文算法计算K近邻,实际用的是距离自身K-1个最近样本,因此如果K=1,就相当于没有对样本进行处理,样本数量不变,分布不变;若K值过大就是整个多数类样本变为一个样本,因此K值决定样本的缩减规模和增加规模。为了更直观的看到K值的影响,该节选用3.2.1节中的数据集,不同K值对应的结果如表5所示。由表5可以看出,随着K值的增加,分类性能越来越好,尤其是对少数类,但是当K值为30、50、100的时候分类性能再次下降,原因在于K值过大导致出现新的不均衡。

表5 K值的影响Tab.5 Effect of K values
4 结束语
针对实际应用中训练样本不均衡的问题,主要表现为密度分布不均衡,结合聚类算法本文提出基于K近邻算法的欠取样SVM分类算法。该方法用K近邻算法对多数类进行欠取样和对少数类样本过取样,然后得到新的训练集并最终得到分类超平面。该方法进行重取样后能够保持原样本的密度分布,并且达到样本的均衡化处理,最后用人工数据集和UCI数据集进行验证该方法的有效性。通过与聚类算法及直接用SVM算法进行比较,结果表明在不同的数据集及不同的不均衡化程度下,本文方法有较好的实验效果。然而所有实验均在2类分类上进行,如何实现在多类不均衡数据集下实现数据集的均衡化将是下一阶段的主要工作。
参考文献
[1]李雄飞 李军 董元方 等.一种新的不平衡数据学习算法PCBoost J .计算机学报 2012 35 2 202⁃209.
[2]曾志强 吴群 廖备水.一种基于核SMOTE的非平衡数据集分类方法 J .电子学报 2009 37 11 2489⁃2495.
[3]CHEN B MA L HU J.An improved multi⁃label classification method based on SVM with delicate decision boundary J .Interna⁃ tional Journal of Innovative Computing Information and Control 2010 6 4 1605⁃1614.
[4]楼晓俊 孙雨轩 刘海涛.聚类边界过采样不平衡数据分类方法J .浙江大学学报 工学版 2013 47 6 944⁃950.
[5]林舒杨 李翠华 江弋 等.不平衡数据的降维采样方法研究 J .计算机研究与发展 2011 48 S 47⁃53.
[6]陶新民 郝思媛 张冬雪.核聚类集成失衡数据SVM算法 J .哈尔滨工程大学学报 2013 34 3 381⁃388.
[7]陈思 郭躬德 陈黎飞.基于聚类融合的不平衡数据分类方法J .模式识别与人工智能 2010 23 6 772⁃780.
[8]陶新民 张冬梅 郝思媛 等.基于谱聚类欠取样的不均衡数据SVM算法 J .控制与决策 2012 27 12 1761⁃1768 1775.
[9]杨智明 彭宇 彭喜元.基于支持向量机的不平衡数据集分类方法研究 J .仪器仪表学报 2009 30 5 1094⁃1099.
[10]陶新民 童智靖 刘玉.基于ODR和BSMOTE结合的不均衡数据SVM分类算法 J .控制与决策 2011 26 10 1535⁃1541.
[11]曹鹏 李博 栗伟 等.基于概率分布估计的混合采样算法 J .控制与决策 2014 29 5 815⁃820.
[12]夏战国 夏士雄 蔡世玉 等.类不均衡的半监督高斯过程分类算法 J .通信学报 2013 34 5 42⁃51.
[13]蔡艳艳 宋晓东.针对非平衡数据分类的新型模糊SVM模型J .西安电子科技大学学报 自然科学版 2015 42 5 140⁃145.
[14]CHANG C C LIN C J.LIBSVM a library for support vector ma⁃chines EB/OL .http //www.csie.ntu.edu.tw/~cjlin/libsvm
[15]SU C T CHEN L S.Knowledge acquisition through information granulation for imbalanced data J .Expert Systems with Applica⁃tions 2006 31 3 531⁃541.
A classification algorithm based on mixed sampling for imbalanced dataset
DU Hong⁃le,ZHANG Yan
(School of Mathematics and Computer Application,Shangluo University,Shangluo,Shaanxi 726000,China)
Abstract:In order to solve the problem of the lower accuracy of minority class caused by classification hyper plane shifting,a mixed sampling algorithm for imbalanced data classification is proposed.First,the ratio of the numbers of majority class and minority class,K is calculated.Then,a sample is chosen randomly from majority class and minority class,and K-1 nearest neighbors of the sample are calculated,the center of above K samples is taken as a new sample.Above processing is repeated until all samples are processed.The new generated samples and original minority class are put together as a new training dataset.At the same time,the sample den⁃sity is changed and the sample distribution in the feature space is kept.Experiment results show this proposed algorithm can improve the classification performance of SVM for imbalanced dataset,especially for the minority class.
Key words:support vector machine;over⁃sampling;imbalanced dataset;under⁃sampling;K⁃nearest neighbor
作者简介:∗杜红乐(1979⁃),男,河南洛阳人,硕士,讲师,主要研究方向为机器学习、数据挖掘,Email:dhl5597@126.com。
基金项目:陕西省自然科学基金资助项目(2014JM2⁃6122);陕西省教育厅科技计划资助项目(12JK0748);商洛学院科学与技术研究项目(13sky024)
收稿日期:2014⁃12⁃22
文章编号:1007⁃791X(2015)02⁃0158⁃07
DOI:10.3969/j.issn.1007⁃791X.2015.02.010
文献标识码:A
中图分类号:TP301.6
