自适应抗噪的清/浊/静音判决算法
2015-06-01李荣芸赵晓群徐静云同济大学电子与信息工程学院上海201804
李荣芸,赵晓群,徐静云(同济大学电子与信息工程学院,上海201804)
自适应抗噪的清/浊/静音判决算法
李荣芸,赵晓群∗,徐静云
(同济大学电子与信息工程学院,上海201804)
摘 要:清/浊/静音判决(UVS)是语音压缩、合成以及识别中的一个重要参数。为了解决传统判决方法训练过程复杂,导致语音编码效率低的问题,给出一种无训练过程的判决方法。提取基于循环平均幅度差的特征参量,利用判决参数间的相关性,自适应调整阈值,实现清/浊/静音判决。该判决方法具有很好的抗噪声干扰能力,有效提高判决的准确率。测试结果表明:该算法简化了清/浊/静音判决的计算量,清音误判率降低了10%,浊音误判率保持在4%以内;将该算法应用于低速率语音编码方案MELP(mixed excitation linear prediction)0.6 kbps的清浊音判决中,解码后的合成语音质量优于原始MELP编码方案,PESQ分数提高0.3,具有较好的可懂度和自然度。
关键词:模式识别;清/浊/静音判决;自适应阈值;低信噪比;低速率语音编码
0 引言
近20年,一直没有间断对于清/浊/静音判决(UVS)进行研究。从语音中区分出静音的分类方法称为端点检测(EPD),语言识别、语音文档检索和语音数据挖掘[1⁃4]都应用到这一技术。端点检测后,语音划分为静音段和有声段两部分,将有声段根据其周期性的差异细分为清音和浊音,即清浊音判决或元音起始点检测(VOP),这一思想广泛应用于语音编码、说话人识别和情感识别[5⁃7]等领域。
由于语音背景环境较为复杂,目前的UVS算法,采用多层网路反馈[8]来解决噪声的干扰,复杂算法的计算导致无法满足实时或低延时语音信息传输,或是采用大量语料训练[9]的方法来模拟噪声环境,但是相对于实际噪声环境,训练使用的噪声库是有限的,无法完全涵盖所有实际环境,使得码书的适应范围有限,仅在特定环境下有较优性能。端点检测方法主要误差来自于噪声[10],为了减少噪声的影响,文献[11]使用单频率滤波器(SFF),获得在每个频率上的幅度谱包络,利用提取的频谱信息,以其方差特性来区分语音和环境噪声,有效避免通过训练语料得出语音或噪声的特征值的过程,但是提取频谱信息依赖于高分辨率的时域和频域信号,低信噪比的环境下,判决受到影响。
清浊音判决有待改进的地方是在清浊音过渡帧上,即清音过渡到浊音或浊音过渡到清音,这些帧的时域信号不具有明显的周期特性,准确设定清音和浊音的界限存在难度。针对这一问题,文献[12⁃14]提出通过提取频域和时域的多维特征值进行训练,加强清音与浊音的区分度,这种方法在语音信号的能量幅度平稳的情况下具有较好的判决准确率,但是对于声音强度较弱的字或者词的判决中,这些浊音被误判为静音或是清音,导致发送端丢弃语音周期信息,接收端呈现类噪声特性,语音的可懂度大幅下降。
本文给出新的UVS判决方法能够很好地解决这3方面的问题。仅提取单帧的有效信息,作为判决的依据,降低了复杂计算带来的时延。利用循环平均幅度差函数[15⁃16](CAMDF)的抗噪声干扰性质及帧间信息的相关性,在噪声环境下,改善了UVS判决的准确率。本文采用自适应阈值[17]的判决方法,根据前一帧的先验判决结果,动态调整阈值门限的幅度,保证声音强度较弱的字或词被正确判决。同时,严格限定阈值幅度的调整范围,避免阈值上限调整过低,导致清音误判为浊音,甚至静音误判为浊音,更要避免阈值下限调整过高,导致浊音或清音误判为静音,造成语音信息丢失。
1 清/浊/静音检测原理
1.1CAMDF函数的定义

CAMDF采用类似于循环卷积的方法,对离散化语音采样序列s(n)进行处理,帧长为N,其定义为其中,sw(n)=s(n)w(n),短时信号常见处理加窗函数,本文取w(n)=0.54-0.46cos(2πn/N),mod(n+k,N)表示进行模为N的求模、取余运算。
1.2CAMDF函数的计算量和准确度
CAMDF是在AMDF基础上的改进方法,与其他AMDF修正算法相比,具有更低的计算复杂度。可变长AMDF[18](LVAMDF)所需的帧长数据随着时延增加而成倍递增,增加窗长AMDF[19](EAMDF)通过前后帧的数据平滑下降趋势,需要用到3帧数据获得函数值。而每一帧的CAMDF只需对一帧时域信号数据进行运算,降低了计算量。CAMDF函数有关于k=N/2对称特性,在式(1)的基础上进一步降低计算量,重新定义为
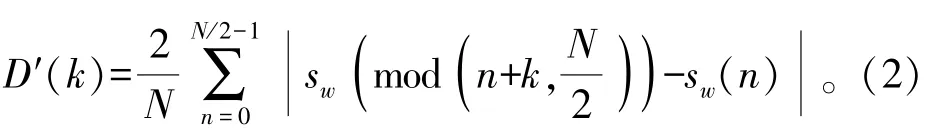
AMDF存在幅值随着时延增加而严重衰减的问题,LVAMDF函数的后半部分值的周期性偏差较大,EAMDF函数的前半部分数值的周期性略有偏差,不能完整体现语音帧特性。而CAMDF具有清晰的峰值、谷值以及周期性。图1为AMDF改进函数曲线的比较图,CAMDF不仅消除了下降趋势,并且保留了浊音的有效信息。

图1 通过CAMDF以及其他改进AMDF函数提炼的一帧特性比较图Fig.1 Comparison of one frame character via CAMDF and other improved AMDF algorithms
1.3CAMDF函数的噪声鲁棒性
考虑到军事和日常通讯环境的噪声类型和信噪比范围,对语音信号加入不同信噪比条件下的噪声模拟实际环境下的语音,噪声选取标准噪声库noiseX⁃92中的各类噪声。信噪比0 dB、5 dB和10 dB的加噪语音的D′(k)函数波形与纯净语音的函数波形均值线和周期性一致。
信噪比为-5 dB的加噪语音的D′(k)函数波形与纯净语音的函数波形周期性基本一致,部分噪声环境下D′(k)的各峰值和谷值与纯净语音略有差异,图2为某语音浊音帧在SNR=-5 dB各类噪声的D′(k)曲线,由于工厂噪声为平稳噪声,滤除噪声过程降低了部分时域信号峰值,D′(k)曲线波动幅度比纯净语音小,但对应曲线的均值线与纯净语音仍保持一致。在SNR为-5 dB情况下,D′(k)曲线受到飞机噪声较大干扰,如图3,曲线随着滞后时间累积,呈现上升趋势。机舱内的通信一般保持在10 dB以上,-5 dB的下限情况不常见,在0 dB信噪比下,飞机噪声的D′(k)曲线不存在上升趋势问题,能满足实际需求。
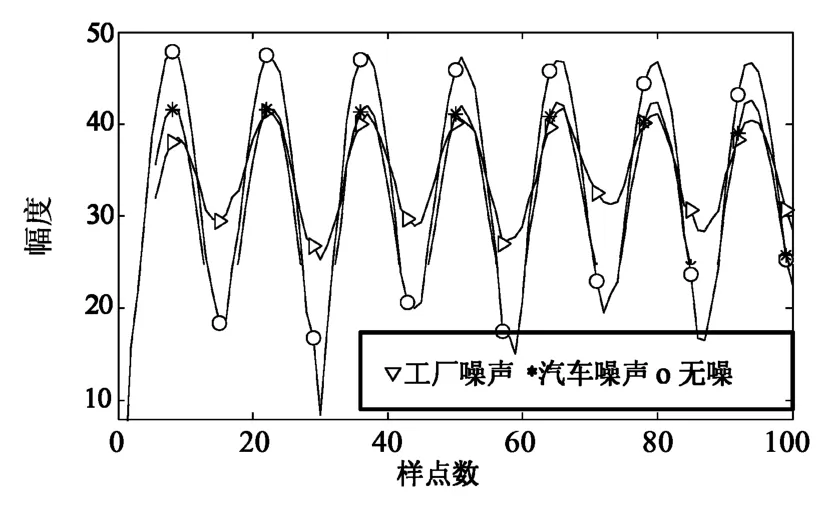
图2 不同噪声环境下的D′(k)曲线比较图(SNR=-5 dB)Fig.2 Comparison of D′(k)in term of noisy type(SNR=-5 dB)

图3 不同信噪比下的D′(k)曲线比较图Fig.3 Comparison of D′(k)in term of SNR level
录制多段实际噪声,进行大量实验验证,表明CAMDF函数对于除飞机噪声的其他噪声环境在-5 dB的极限情况下有较好的抗干扰能力。
1.4CAMDF的清/浊/静音特性
D′(k)围绕均值线水平波动,并且对于清音帧、浊音和静音有明显的差异区分。对于静音帧,D′(k)呈现出波动小、幅值低的特点;清音则函数值波动剧烈,函数值的动态范围较小;浊音帧函数值动态范围较大,峰值点分布分散,呈现明显的周期性。
对于不同讲话者,D′(k)具有相同的特性,图4~5分别代表男声和女声对应清音、浊音、静音帧的D′(k)曲线特性。图4清浊音过渡帧的幅值介于浊音帧2和清音帧之间,基本上不具有周期性,判决算法中,需要根据前后帧的语音特征进行平滑处理。
由于女声的基音频率比男声高,浊音帧的D′(k)曲线完整保留了多个周期的波形,如图5浊音帧1和浊音帧2曲线,浊音帧的幅度均值线变化不大。而图4浊音帧1和浊音帧2曲线,男声D′(k)曲线幅度均值线相差一半,针对浮动范围大的问题,判决中所设置门限,需要采用自适应调整的方法。

图4 不同帧类型下的D′(k)曲线比较图(男声)Fig.4 Comparison of D′(k)in term of frame type(male speaker)

图5 不同帧类型下的D′(k)曲线比较图(女声)Fig.5 Comparison of D′(k)in term of frame type(female speaker)
1.5采用CAMDF的判决算法
根据上述CAMDF特性,第i帧CAMDF均值MD(i)是一个可以区分清浊静音的有效参数,跨过均值线的次数PD(i)作为另一个评判参数。MD(i)和PD(i)定义为

设前NIS帧为语音前导无话段,4个阈值门限T1、T2、T3、T4的初始值定义为


本文以录制的语音短语为例,时域波形如图6(a),清浊静音判决步骤如下:
1)计算CAMDF的幅度和过均值概率对于降噪语音计算评判参数MD(i)和PD(i),如图6(b)和图6(c)所示,并归一化平滑处理。
2)采用自适应多门限判决法采用多门限判决方法,门限和清/浊/静音判决有以下关系:
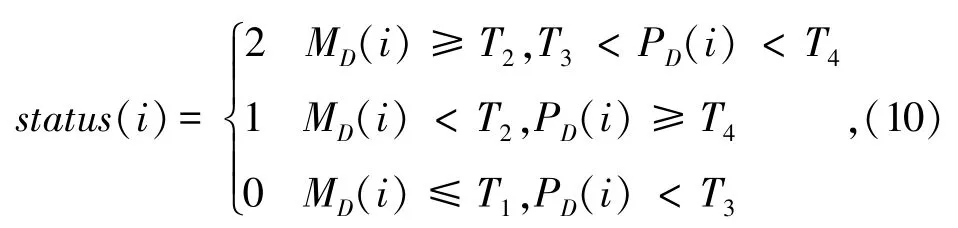
status(i)=2表示为浊音帧,status(i)=1表示为清音,status(i)=0则是静音帧。
3)根据初始阈值判决出多帧清音帧,对应PD(i)值反馈调整T4,统计初始几帧浊音帧反馈的MD(i)值,作为调整T2阈值的参考。在后续帧的判决中,T2和T4的调整过程类似,由于同一个说话人的语音语调不会突变,阈值调整幅度限定在[-0.05,0.05]之间。
4)特殊帧的平滑处理。尾音虽然幅度值逐渐变小,但具有周期性,进行特殊处理,判决为浊音;喘息声具有一定的能量,由于持续时间较短,平滑为静音;连读现象的语音,在字与字过渡帧处,判决为清音。如图6(d)所示。
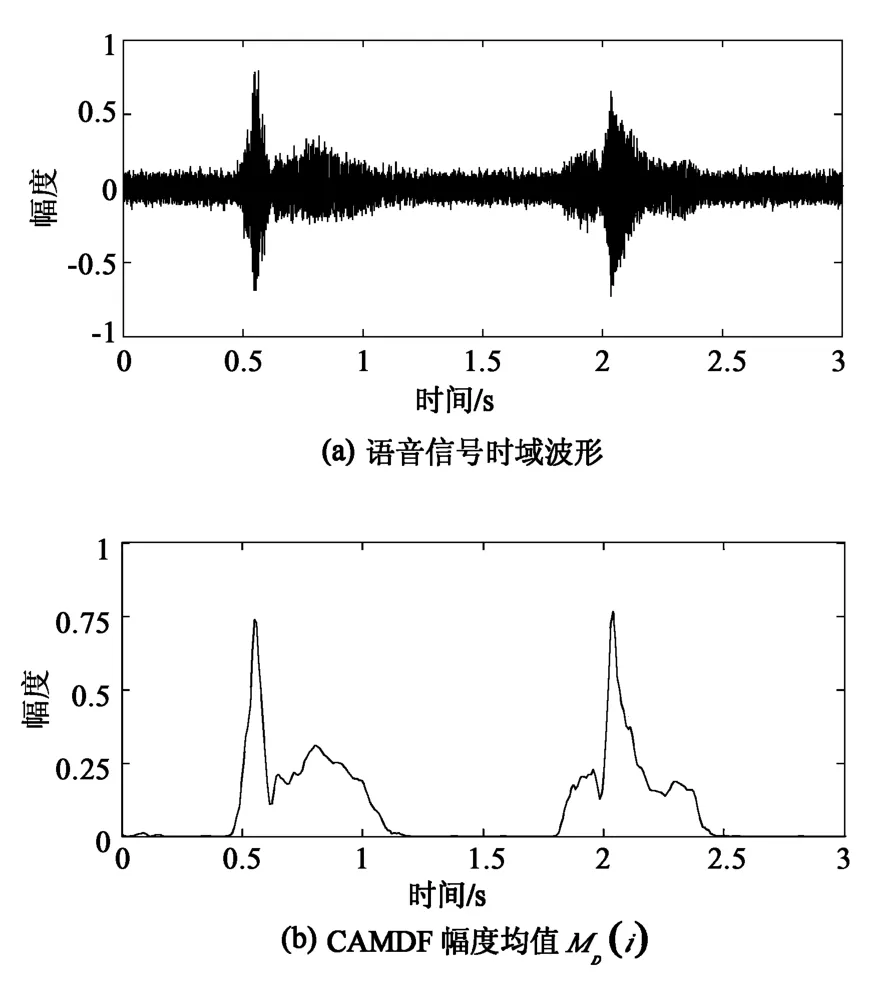

图6 清/浊/静音判决过程Fig.6 UVS detection process
2 实验验证
2.1判决准确度测试
本文进行了大量的准确度测试实验,使用Keele基音检测库中的10段语音,分别是男声5段,女声5段,实验数据的采样率为22.05 kHz,采取帧长为512个样点,帧移为200个样点。以Keele基音检测库中的清浊音标注作为判决标准,对比本文方法的判决结果,将出错帧数在总帧数占的比例作为误判率的衡量标准。
由于浊音误判为静音或清音会导致语音周期信息丢失,极大程度影响语音的自然度,而清音或静音误判为浊音,额外的无效周期信息降低了语音信息的传输速率,因此,准确度主要从这3个指标进行测试。
实验结果如表1所示,浊音误判为静音为3.2%,浊音误判为清音为0.8%,清音/静音误判率为15.3%,比Bayes(清音误判率62.2%)以及Fisher算法(清音误判率26.0%)准确度高,有较好的端点检测性能。
2.2抗噪声干扰测试
在噪声环境下,很有可能将浊音误判为清音或是静音,本文的判决算法具有抗噪声干扰性能,能在低信噪比的情况下,保证这类判决的准确性。如表2所示,以Keele数据库中的女声3语音为例,总帧数为3 050帧,加入noiseX⁃92中的工厂噪声以及高斯白噪声。低信噪比的语音浊音误判率控制在10%之内,高信噪比(SNR>5 dB)的情况下浊音误判率低于4%。
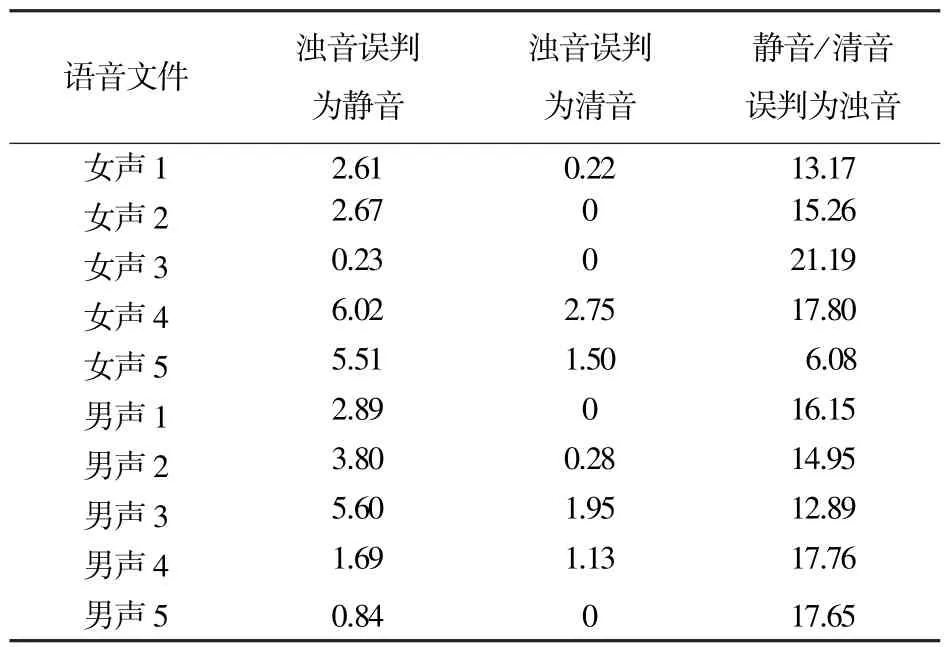
表1 UVS的误判率Tab.1 Error detection rate of UVS %

表2 不同信噪比下的误判率Tab.2 Error detection rate of UVS at different SNR level%
2.3应用测试
MELP[20]编码方案中,使用第一子带的声强结合残差信号峰值作为判决参数,以固定门限判决出来,与Keele语音库10段语音进行对比,平均浊音误判率为17.42%,清音误判率为14.13%,以女声2语音为例,如图7,随着信噪比的增加,MELP子带判决方法的浊音误判率急剧上升,本文的判决方法能有效控制在较低误码率区间内。
浊音误判为清音直接导致基音周期检测时出现倍频或半频现象,对于信噪比低于-5 dB,解码后的合成语音质量下降。针对这一问题,将本文的判决方法应用于该编码方案中,合成语音的PESQ[21]值如表3所示,应用本文判决方法有效提高了信噪比为-5 dB的合成语音质量,尤其对于女声语音的优化效果更为明显。

图7 子带与CAMDF判决浊音误判率比较图Fig.7 UVS error detection rate of sub⁃band detection and CAMDF detection

表3 不同信噪比下合成语音的PESQ值Tab.3 Speech PESQ value at different SNR level
3 结束语
本文从理论和实验两方面,证明了新的判决方法能有效区分清音帧、浊音帧和静音帧。该方法的浊音误判率远低于MELP编码方案中的子带判决,将该方法应用于低速率语音编码方案中,有效提高了合成语音的PESQ得分。
本文清/浊/静音判决的最大优势是根据前导无声段作为初始参数,利用判决参量的相互关系,采用自适应阈值的方法,避免了阈值训练过程,降低计算量。此外,该判决方法对于信噪比高于-5 dB的高斯白噪声和信噪比高于0 dB的工厂噪声,浊音误判率控制在4%以内,对于其他噪声也有抗干扰能力。该判决方法限于有前导无话段的语音,对于初始帧为清音或者浊音帧的语音效果有待研究。
参考文献
[1]HUANG CHIEN⁃LIN MATSUDA S HORI C.Feature normalization using MVAW processing for spoken language recognition C //2013 Asia⁃Pacific Signal and Information Processing Association Annual Summit and Conference Kaohsiung Taiwan 2013 1⁃4.
[2]WU BING⁃FEI WANG KUN⁃CHING.Robust endpoint detection algo⁃rithm based on the adaptive band⁃partitioning spectral entropy in ad⁃verse environments J .IEEE Transactions on Speech and Audio Pro⁃cessing 2005 13 5 762⁃775.
[3]Wu Gin⁃Der Huang Pang⁃Hsuan.A vectorization⁃optimization⁃method⁃based type⁃2 fuzzy neural network for noisy data classification J .IEEE Transactions on Fuzzy Systems 2013 21 1 1⁃15.
[4]CHOMORLIG ZHANG ZE.Research on endpoint detection for mongolian speech based on support vector machine C //2011 Interna⁃tional Conference on Intelligence Science and Information Engineering Wuhan China 2011 290⁃294.
[5]VUPPALA A K YADAV J CHAKRABARTI S et al.Vowel onset point detection for low bit rate coded speech J .IEEE/ACM Transactions on Audio Speech and Language Processing.2012 20 6 1894⁃1903.
[6]MING J HAZEN T J GLASS J R et al.Robust speaker recognition in noisy conditions J .IEEE/ACM Transactions on Audio Speech and Language Processing 2007 15 5 1711⁃1723.
[7]LASKOWSKI K.Contrasting emotion⁃bearing laughter types in multipar⁃ticipant vocal activity detection for meetings C //IEEE International Conference on Acoustics Speech and Signal Processing Taipei Taiwan 2009 4765⁃4768.
[8]SHAO C BOUCHARD M.Efficient classification of noisy speech using neural networks C //Seventh International Symposiun on Signal Pro⁃cessing and Its Applications 2003 357⁃360.
[9]XU HAITIAN DALSGAARD P TAN ZHENG⁃HUA et al.Noise condi⁃tion⁃dependent training based on noise classification and SNR estimation J .IEEE/ACM Transactions on Audio Speech and Language Processing 2007 15 8 2431⁃2443.
[10]BERITELLI F CASALE S SERRANO S.Adaptive V/UV speech de⁃tection based on acoustic noise estimation and classification J .Elec⁃tronics Letters 2007 43 4 249⁃251.
[11]Aneeja G Yegnanarayana B.Single frequency filtering approach for discriminating speech and nonspeech J .IEEE/ACM Transactions on Audio Speech and Language Processing 2015 23 4 705⁃717.
[12]WANG YUXUAN HAN KUN WANG DELIANG.Exploring monaural features for claasification⁃based speech segregation J .IEEE/ACM Transactions on Audio Speech and Language Processing 2013 21 2 270⁃279.
[13]LOBO A P LOIZOU P C.Voiced/unvoiced speech discrimination in noise using Gabor atomic decomposition C //2003 IEEE International Conference on Acoustics Speech and Signal Processing Hong Kong 2003 1 820⁃823.
[14]Dhananjaya N Yegnanarayana B.Voiced/nonvoiced detection based on robustness of voiced epochs J .IEEE Signal Processing Letters 2010 17 3 273⁃276.
[15]张文耀 许刚.循环AMDF及其语音基音周期估计算法 J .电子学报 2003 31 6 886⁃890.
[16]马莎莎 戴曙光 穆平安.基于短时能量的循环AMDF基音检测算法 J .计算机仿真 2014 31 7 278⁃282.
[17]LI YANGXIONG JIN HAI LI WEI et al.Fast speaker clustering using distance of feature matrix mean and adaptive convergence threshold J .Signal processing IET 2014 8 8 844⁃851.
[18]张康杰 赵欢.基于LV⁃AMDF的自适应基音检测算法 J .计算机应用 2007 27 7 1674⁃1676 1679.
[19]Ghulam Muhammad.Noise robust pitch detection based on extended AMDF C //Proceedings of IEEE ISSPIT Sarajevo 2008 133⁃138.
[20]Gao Di Zhao Xiaoqun.A 600bps MELP⁃based speech quantization scheme for underwater acoustic channels C //2013 Fifth International Conference on Computational and Information Sciences ICCIS Shiyan Hubei China 2013 1983⁃1986.
[21]Rix A W Beerends J G Hollier M P et al.Perceptual evaluation of speech quality PESQ ⁃a new method for speech quality assessment of telephone networks and codecs C //IEEE International Conference on Acoustics Speech and Signal Processing Salt Lake City UT 2001 2 749⁃752.
Adaptive anti⁃noise unvoiced/voiced/silence detection algorithm
LI Rong⁃yun ZHAO Xiao⁃qun XU Jing⁃yun
School of Electronics and Information Engineering Tongji University Shanghai 201804 China
AbstractThe Unvoiced/Voiced/Silence detection UVS provides a preliminary acoustic segment which is a key parameter in speech compression synthesis and recognition.The complication of traditional UVS methodsƷ training procedure causes low efficiency of speech vocoder.To solve this problem a UVS detection without training proceeding is proposed in this paper.After new characteristic parameters of unvoiced and voiced signal are extracted adaptable threshold is proposed based on the correlation of those parameters.With its perfect an⁃ti⁃noise ability the correct rate of this detection improves sharply.The simulation result shows that this algorithm not only simplifies the unvoiced/voiced/silence detection but also efficiently decreases 10%of unvoiced and maintains lower than 4%of voiced discrimination error.The improved 0.6 kbps MELP vocoder applying this detection algorithm gets a 0.3 higher PESQ score and better synthetic speech performance compared with original vocoder which produces good natural and intelligible speech.
Key wordspattern recognition unvoiced/voiced/silence detection adaptive threshold low SNR low bit⁃rate speech coding
作者简介:李荣芸(1990⁃),女,上海人,硕士研究生,主要研究方向为甚低速率语音编码、语音合成、语音增强等;∗通信作者:赵晓群(1962⁃),男,黑龙江依安人,博士,教授,博士生导师,主要研究方向为数字语音预处理、语音编码、语音增强、语音识别等,Email:zhao_xiaoqun@tongji.edu.cn。
基金项目:国家自然科学基金资助项目(61271248)
收稿日期:2015⁃01⁃24
文章编号:1007⁃791X(2015)02⁃0133⁃06
DOI:10.3969/j.issn.1007⁃791X.2015.02.006
文献标识码:A
中图分类号:TN912
