自然场景下基于部分模型的车体检测
2015-05-04牛常勇
陈 帅,张 勇,牛常勇
(郑州大学 信息工程学院,河南 郑州450004)
0 引 言
目前比较常用的车体检测方法主要分为两类:第一类是基于机器学习特征提取,如神经网络、Adaboost等;第二类是基于人工设计特征提取,如颜色特征、对称性、边缘特征[1]等。人工设计特征方法实现比较简单而且易于理解,但是传统的人工设计特征方法的在复杂的自然场景下容易受到背景噪声的干扰。针对于这个问题,使用基于部分模型的检测方法,用检测部分特征代替检测整体特征,而常用的基于部分模型的检测方法,由于没有合理划分部分模型,导致漏检率和错误率较高。本文提出了一种部分模型划分算法,合理划分部分模型,克服了在复杂自然场景下误检率和漏检率高的问题,相比于比较成熟的PBT方法[2],召回率也有较明显的提高。
1 表示法
1.1 图像的特征表示
特征表示分为两个部分,分别为像素级的特征表示和特征聚合。
1.1.1 像素级特征表示
定义Φ(x,y)和 Ω(x,y)分别为在在图像 (x,y)点梯度的方向和大小。对于彩色图像,Φ和Ω是每个像素在红、绿、蓝3个色彩通道中,最大梯度的方向和大小。
每个像素的梯度投影到p个方向上,在 (x,y)点的p维的特征向量

1.1.2 特征聚合
假设F是一张w×h图片的像素级特征图。如果直接用F计算,需要计算w×h个元素,需要花费大量的时间。而特征聚合就是为了解决这个问题,设k是一个正整数,将k×k个像素的值通过求和 (或平均值)的方法聚合成一个点 (也成为C的一个单元),得到一个新的特征图C,C的长和宽分别为w/k和h/k,用C计算时,其计算量缩小了k2倍,在本文中取k=8。
1.2 可重构的部分模型
使用的模型是由一个表示整体的低分辨率模板和多个较小的高分辨率模板组成的可重构模型[3-8]。这些模板都是 HoG (histogram of gradients)[9]直方图表示的。我们使用的模型有点类似PBT模型,但是与PBT模型使用固定数量、固定大小的正方形的部分模板不同,本文模型中的部分模板的大小和数量都不是固定,而且形状也不是单一正方形。这种改进使正特征的聚合度大大增加,同时也减小了负特征的干扰。除此之外,针对车体检测的场景,检测算法和PBT模型算法也有很大不同,在检测算法中加入了目标融合算法,避免了同一目标被多次检测出的情况。
我们使用的模型T可以表示成一个root-level模板F0和n个part-level模板Tj的组合,即

式中:F0——root层模板,也是root层滤波器;Tj表示第j个part-level模板,Tj=(Fj,Pj),其中Pj=(xj,yj)表示第j个part-level模板在root-level模板中的位置,Fj是一个3维向量,表示第j个滤波器

(1)dj= (dxj,dx2j,dyj,dy2j)表示第j个滤波器的位移的大小和方向;
(2)ωj是第j层滤波器的参数向量,它包括HoG直方图的权重,偏移量的大小和位移dj的负权重;
(3)Sj表示第j层滤波器的位置和大小,在本文中,Sj是一个长方形,它的边长最小可以取3个HoG单元 (即24像素),最大的可以取滤波器F0长宽和的1/4。这就导致Sj有很多种不同取值,如何确定Sj的大小,将在文章的下一个章节中介绍。
2 主要算法
2.1 支持向量机
D= {(xi,yi),…,(xn,yn)}表示训练数据集,其中xi代表第i张图片的特征图,yi∈ {-1,1},yi=-1表示第i张图片是负样本,而yi=1表示第i张图片是正样本。学习算法的目标是等到一个线性的分类器可以分类正样本和负样本。
分类器可以表示为

对于式 (1)不确定的是参数向量ωi和隐藏值zi,所以不能直接计算出ωi,在本文中,我们使用Latent-SVM算法[10-13]计算参数向量 ωi的最优解。
根据SVM算法,问题 (1)可以转化为
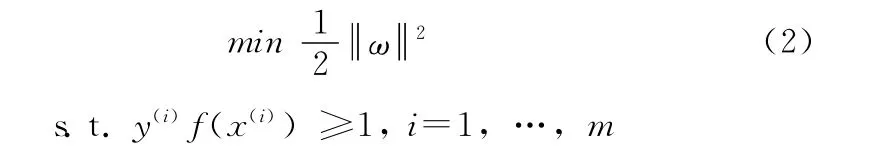
使上式取得最小值的ω就是ω的最优解。
构造拉格拉日算子来解决问题 (2)得到下式
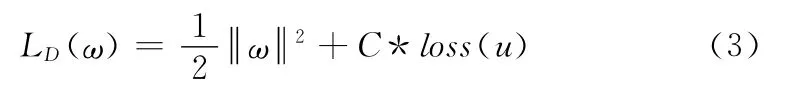
常数C 表示f(x(i))之间的相关性,u=∑y(i)f(x(i)),loss(u)是衰减函数,在传统的SVM算法中,使用的衰减函数loss(u)=max(0,1-y(i)f(x(i))),但是因为这个衰减函数有求最大值的操作,所以它不是一个连续可导的函数如图1所示,在本文中使用neg-sigmoid函数来代替原有的衰减函数,其中

图1 衰减函数
使用neg-sigmoid函数作为衰减函数有两个好处:
(1)如图1所示,当u接近0时neg-Sigmoid函数可以近似为线性函数,即
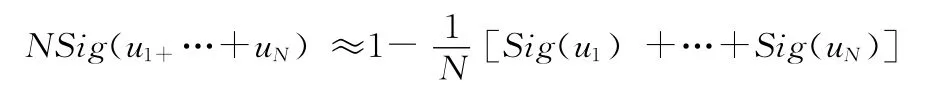
在本文中,u的取值在 [0,1]内且比较接近0,可以认为绝大部分u符合上式,此时衰减函数为线性函数 (其中
(2)如图1所示,NSig(neg-Sigmoid)始终在0-1衰减即 (max(0,1-y(i)f(x(i))))的上方,所以对最小化 LD没有影响。
因此式 (3)可以写为
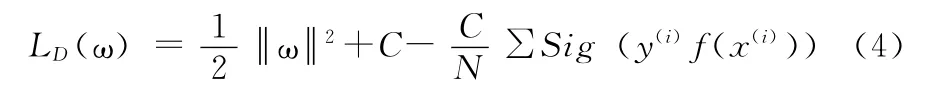
设Zp是zi的取值范围且Z(xi)= {zi},Zp∈D,定义LD(ω,Zp)=LD(Zp)(ω),其中D(Zp)∈D,结合式 (4)可以得到
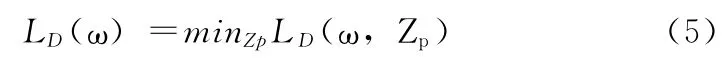
由此可见,LD(ω,Zp)是LD(ω)的上界,所以求LD(ω)的最小值可以转化成最小化LD(ω,Zp)。
求LD(ω,Zp)的最小值得方法如下:
(1)在zi∈Zp的条件下求使得f(x)取最大值的zi,即

此时LD(Zp)(ω)是只与ω有关的凸函数。
(2)令▽LD=0,可以得到
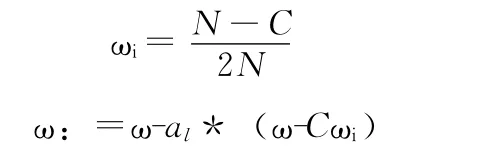
al是第l次迭代的学习率系数 (在线性SVM算法中,学习率al=1/l[14]),将算出的ω带入LD中。
重复步骤 (1),(2)直到ω收敛,此时得到的ω就是最优的参数向量。
2.2 部分模型的划分和目标融合
2.2.1 部分模型的划分算法
我们通过部分模型划分算法得到一个最优的部分模型结构。该算法有两个步骤:
(1)对于不同阈值,得到不同的部分模型。设thresh是root层模型的阈值,thresh的取值范围为 [min(F0),max(F0)]。
具体算法如下:
1)将F0中大于thresh的元素置1,小于thresh的元素置0;
2)设F=F0,找到一个尽可能大的矩形S1,在F中,S1∈ [3*3,sizeof(F)/2]且S1内部的元素都不为0,记录S1位置和大小,并将F内S1位置的元素置0,重复此步骤,直到F中没有满足要求的S1;
3)设F=F0,找到一个尽可能大的矩形S2,在F中,S2内部的元素都不为1且S2∈ [3*3,sizeof(F)/2],记录S2的位置和大小,并将F内S2位置的元素置1,重复此步骤,知道F中没有满足要求的S2;
4)输出S=S1∪S2。
(2)Sj表示第j个阈值对应的部分模型结构,设Ej=∑ F0(si)2,si∈Sj是第j个阈值对用的部分模型结构中的一个part模板。最优模板问题可以等价成Ej最大化的问题,当Ej是所有E中的最大值是,Sj就是最优的部分模型结构。
2.2.2 目标融合算法
在PBT模型算法中,由于在检测目标是会对输入图像进行多次的缩放,会导致同一个目标在不同缩放层级同时被检测出来的现象。针对于车体检测的特点,即两辆车不可能重叠。本文提出了一种目标融合算法:处理有重叠的检测结果,根据重叠部分的响应值重新检测,将多余的结果过滤掉,只保留最优的结果。避免了同一辆车被检测到多次所导造成的误检。
3 实验结果
本实验选用的数据集训练数据集和测试数据集,其中测试数据集由15000张分辨率为1616×1232的照片组成。均来自于郑州某路口的监控。数据集包含有8000张白天的照片数据和7000张夜晚照片。其中包括了各种车型 (包括轿车,面包车,越野车,公交车,卡车等)。训练数据集包括正样本和负样本两种,其中正样本为400张分辨率为1616×1232的照片组成,包含200张白天照片和200张夜晚照片,负样本是从VOCdevkit数据集中选取的一部分图片数据。
分别用PBT的方法和本文的方法在训练数据集上训练,得到的模型如图2所示。
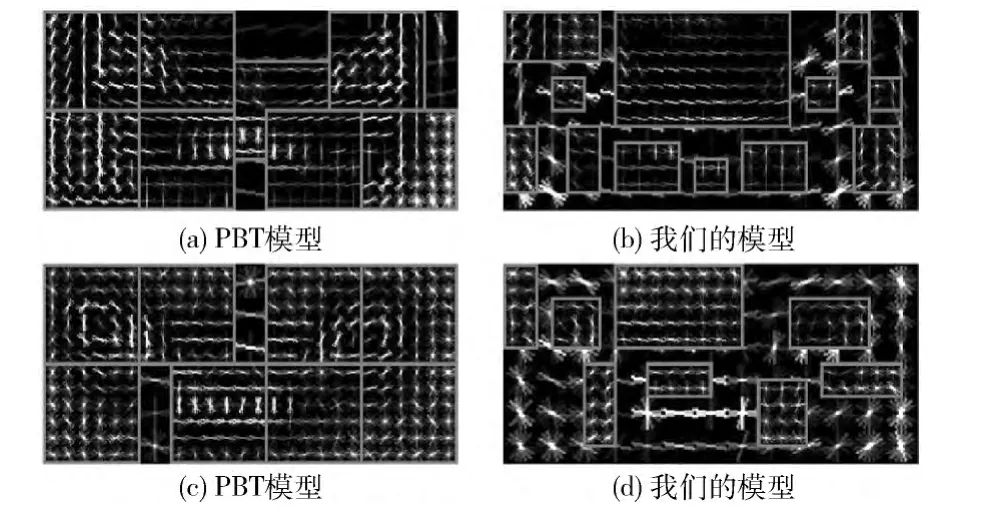
图2 模型((a)和(b)是白天数据训练得到的模型,(c)和(d)是夜晚数据训练得到的模型)
在测试数据集中分别用PBT方法的模型和本文方法的模型检测和分类,检测的召回率见表1,分类的正确率见表2。
检测结果和分类的结果如图3,图4所示。我们的方法无论是在检测还是分类上都优于PBT的方法,是因为在我们提出的部分模型划分算法是按照目标特征的分布来划分部分模型的,把属于同一特征的部分尽可能的划分在同一个部分模型中,同时也将不属于该部分的特征可以更好的把目标的特征提取出来。

表1 检测的正确率

表2 分类的正确率

图3 车体检测结果 (白色框为夜晚目标,黑色框为白天目标)

图4 分类的结果 (其中白色框体表示结果是卡车和公交车,黑色框体表示结果是轿车)
4 结束语
提出了的一种自然场景下基于部分模型的车体检测方法。实验分别在白天和夜晚两个数据集中比较该方法和PBT的方法,实验结果表明本文提出的方法在车体检测上有很高的准确率,表明了本文的方法更适合用于车体检测中。此外本文中使用的方法不仅能应用于车体检测中,还可以应用到人体检测、移动物体检测中去。计划引入车牌检测和识别,用并行计算的方法实现算法,以达到实时检测的目标。
[1]Leibe B,Leonardis A,Schiele B.Robust object detection with interleaved categorization and segmentation [J].International Journal of Computer Vision,2008,7 (1):259-289.
[2]Felzenszwalb P,Girshick R,McAllester D,et al.Object detection with discriminatively trained part based models [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2010,32 (9):1627-1645.
[3]Amit Y,Trouve A.POP:Patchwork of parts models for object recognition [J].International Journal of Computer Vision,2007,75 (2):267-282.
[4]Felzenszwalb P,McAllester D,Ramanan D.A discriminatively trained,multiscale,deformable part model [C]//IEEE Conference on Computer Vision and Pattern Recognition,2008:1-8.
[5]Lv Yang,Yao Benjamin,Wang Yongtian,et al.Reconfigurable templates for robust vehicle detection and classification [C]//Workshop on Application of Computer Vision,2012:321-328.
[6]Wu Yingnian,Si Zhangzhang,Gong Haifeng,et al.Learning active basis model for object detection and recognition [J].International Journal of Computer Vision,2010,90 (2):198-235.
[7]McIntosh C,Hamarneh G.Medial-based deformable models in nonconvex shape-spaces for medical image segmentation [J].IEEE Trans on Medical Imaging,2012,31 (1):33-50.
[8]Zhu S,Mumford D.A stochastic grammar of images [J].Foundations and Trends in Computer Graphics and Vision,2007,2 (4):259-362.
[9]Chan Yiming,Fu Lichen,Hsiao Pei-Yung,et al.Pedestrian detection using histograms of Oriented Gradients of granule feature[C]//Intelligent Vehicles Symposium,2013:1410-1415.
[10]John Yu Chun-Nam,Thorsten Joachims.Learning structural SVMs with latent variables [C]//International Conference on Machine Learning,2009:1169-1176.
[11]Sun Chao,Zhang Tianzhu,Bao Bing-Kun,et al.Latent support vector machine for sign language recognition with Kinect [C]//20th IEEE International Conference on Image Processing,2013:4190-4194.
[12]Lo Sio-Long,Tsoi Ah-Chung.Human action recognition:A dense trajectory and similarity constrained latent support vector machine approach [C]//2nd IAPR Asian Conference on Pattern Recognition,2013:230-235.
[13]Vahdat A,Cannons K,Mori G,et al.Compositional models for video event detection:A multiple kernel learning latent variable approach [C]//IEEE International Conference on Computer Vision,2013:1185-1192.
[14]Shalev-Shwartz S,Singer Y,Srebro N.Pegasos:Primal estimated sub-gradient solver for SVM [J].Mathematical Programming,2011,127 (1):3-30.
