利用实例的异构网络服务模式匹配方法
2015-03-22王新云郭艺歌
何 杰, 王新云, 郭艺歌
(1.宁夏大学 资源环境学院, 银川 750021; 2.宁夏大学 西北土地退化与生态恢复教育部重点实验室, 银川 750021)
何 杰1*, 王新云2, 郭艺歌2
(1.宁夏大学 资源环境学院, 银川 750021; 2.宁夏大学 西北土地退化与生态恢复教育部重点实验室, 银川 750021)
提出了一种利用实例的模式匹配方法,在对网络服务模式元素标签及模式结构匹配基础上,通过对网络服务实例数据的精确匹配来确定模式元素间对应关系,解决了多版本异构网络服务模式间由于结构和语义差异造成的映射丢失问题.最后,以Geoserver不同版本网络要素服务(WFS)和网络覆盖服务(WCS)匹配试验验证了方法的有效性.
模式匹配; 实例; 多版本; 网络要素服务; 网络覆盖服务
模式匹配[1-5]是异构的网络服务集成的一个关键步骤.当前,不管是语法模式匹配方法还是语义(本体)匹配方法,大致可以分为基于元数据、基于实例及基于元数据和实例混合的形式.基于元数据的模式匹配算法[2-4,6-7]通常从概念名称、概念的描述或定义及结构上作匹配,但多版本异构的网络服务模式,如多版本网络要素服务(WFS)[8]、网络覆盖服务(WCS)[9]、传感器观测服务(SOS)[10]模式等,由于基于的信息模型的差异造成了模式结构和元素语义上的差异,同时由于不同领域的概念定义和组织不同,往往很难确定来自不同领域不同描述的概念间关系,如,SOS中的ObservationOfferings与WFS中的FeatureMembers间的语义关系就很难确定.基于实例的模式匹配方法主要通过元素的实例值间的匹配来确定元素间关联关系,如Wang Jiying等[11]人提出的基于实例的模式匹配方法来解决网络数据库站点内及站点间的数据模式匹配问题,且利用交叉验证技术来提高匹配精度,该方法不足之处在于样本实例的选择对匹配性能影响大.为了确定主、客GIS数据库中的共同体,王育红、陈军提出了一种改进的基于实例的层次式模式匹配方法[5]来实现实体对应关系的自动建立和要素类相似值计算.但文献[5]针对的是GIS数据库实例,其结构和组织与本文的网络服务实例不同.在AnHai Doan等[12]提出的一种基于机器学习的本体匹配方法应用分类的实例来计算概念的联合概率分布,再通过相似函数把概率分布转化为概念相似值.该方法要求实例在语法上相同,否则匹配质量差,此外,如果缺少实例则很难确定概念间的映射关系.A.Bilke等[13]设计了一种高效的基于实例的模式匹配方法,该方法的突出特点是不依赖于任何模式的属性名字,能识别出语义上不同语法上相似的属性,但该方法匹配结果依赖实例数据中的副本数,如果没有副本则算法无法工作.
为了克服异构网络服务模式结构和元素语义差异造成的映射丢失问题,本文提出一种以元数据匹配器为主导,以实例匹配器为辅助的模式匹配方法.首先通过对异构网络服务模式利用元数据匹配器生成初步匹配结果,然后,在初次匹配结果基础上应用实例匹配器计算出元素间的实例相似值来精炼初次匹配结果,从而最大限度发现映射,改善匹配精度.
1 系统体系结构
异质的网络服务模式,如,WFS、WCS、SOS,基于的信息模型不同,模式无论从结构和内容比较都有很大差异,这些差异主要表现在如下几个方面:①结构差异.包括类级别差异和属性级别差异.类级别差异表现为模式新增某类或删除某类,或者类本身的命名发生了变化、类的属性变化、类的继承变化等.属性级差异主要表现为命名变化、修改、引用变化、约束条件发生改变等.②内容差异.结构上的差异带来了内容上的巨大变化,如类或属性的增、删、改带来的相应实例值的变化.③实例值差异.主要表现在:i)空间实例数据的时间差异,如WCS服务实例中,同空间范围不同时段的地物覆盖可能不同;ii)空间实例数据的属性差异,如相同几何形状的空间实例可能由于属性差异表达的是不同地物类;iii)空间参考差异.数据值相等的空间属性值,由于其采用的参考系不同导致实例值不同.
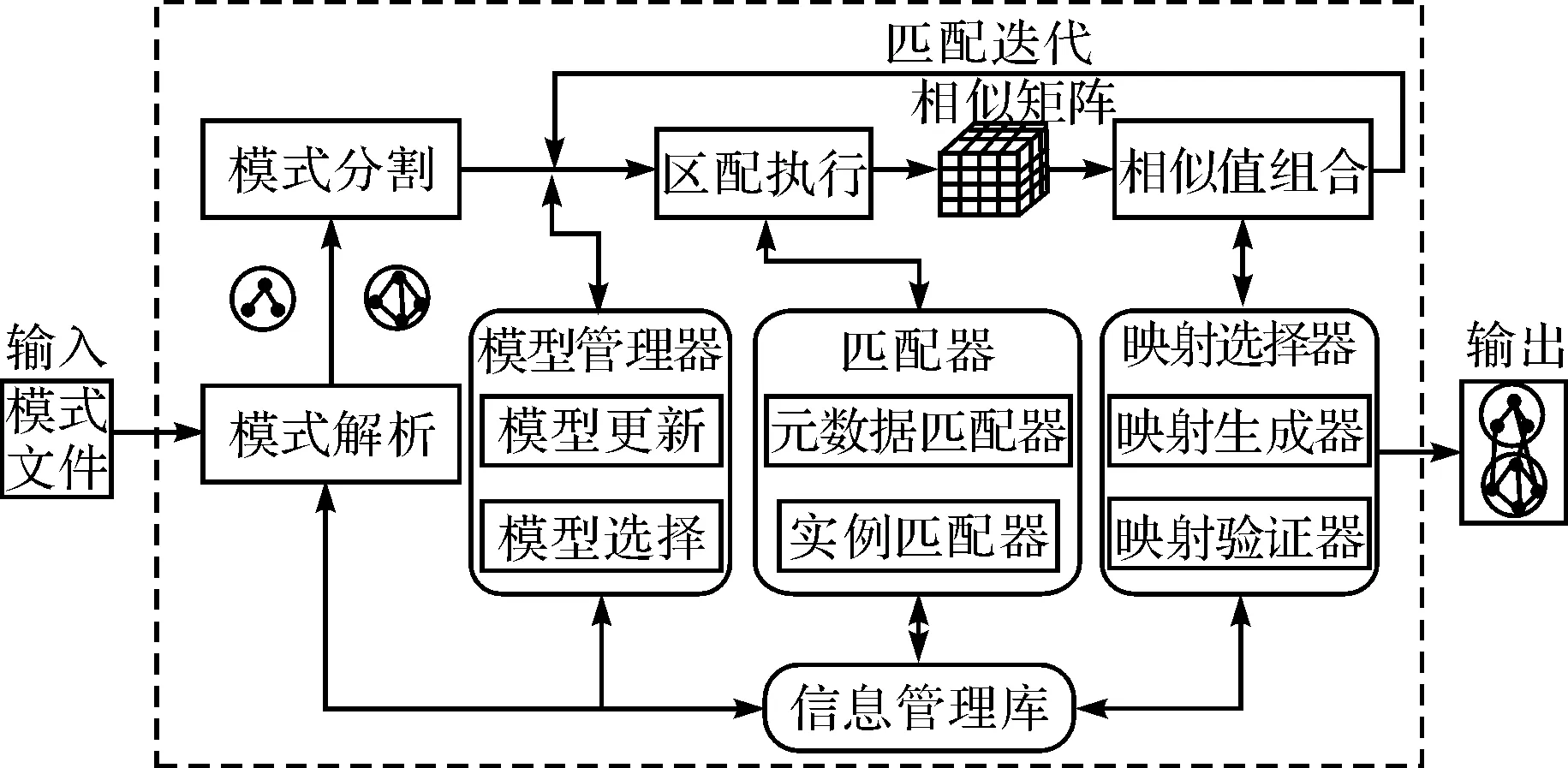
图1 系统体系结构Fig.1 Architecture of the schema matching system
针对异构网络服务模式这些差异,设计的模式匹配算法既要能解决结构与内容差异引起的映射丢失,同时能顾及实例值本身差异,为此,设计了一种的元数据与实例组合的模式匹配方法,系统充分利用现有的元数据匹配器-COMA[14]的匹配能力,同时设计适合空间领域特征的实例匹配器来辅助提高匹配质量.图1是系统总体结构图.系统包括4个核心的部件,即模式解析、模式分割、匹配执行及相似值组合部件.模式解析部件主要实现对输入的网络服务模式进行解析,并表示成匹配要求的模式树结构形式,同时提取模式树中对应元素的实例值.模式分割部件则为了提高模式匹配性能及减少误匹配率,把匹配的模式树进行合理分割,并找出其中候选相似子树.匹配执行部件则根据从匹配器库中选择的匹配器执行匹配工作,生成对应的相似值矩阵.相似值组合部件对相似矩阵中的相似值按照一种组合方法形成对应元素的组合相似值,最后映射选择器根据设定的相似值阈值或者根据信息管理库中的参考映射生成候选映射,候选映射经过验证器验证后输出最终匹配结果.相似值组合的结果如果不能满足用户要求则继续返回到匹配执行阶段执行新的匹配迭代过程,同时在匹配执行时灵活选择不同匹配器组合,并把最优匹配组合保存到信息管理库中.模型管理器主要管理不同输入格式(XML,XSD,OWL等)的网络服务模式在匹配系统中的表示方式(树/图),实现对模型的更新和选择功能.信息管理库是系统不可缺少的辅助部件,主要用来保存匹配系统各阶段的中间结果,同时为匹配各阶段提供有用的参考信息,如以前的匹配结果,参考相似片段,参考映射信息,不同匹配器组合信息等.
2 系统实现
2.1 模式解析

图2 WCS部分XML实例在系统内部统一表示Fig.2 The internal schema representation of WCS XML instance
模式解析主要目的是用一种内部模式表示方法对输入的模式文件进行表示.对每个读取的实例数据,用一个五元组表示,即Element=(ID,Name,Type,Instance,Patterns),ID表示元素在模式树中的位置,用3位数字表示,第1位数字表示节点的父亲节点在树中层数,根节点的父亲节点层数为0;第2位表示元素父亲节点在该层的编号,对于根节点,其值为0;第3位数字表示元素在子树中的编号,根节点为1,如ID=”114”,表示是第1层第1个节点的第4个子节点.Name为实例数据对应的属性元素的标签.Type表示实例数据类型.Instance为属性元素对应的实例数据值.Patterns为实例值的规则表达式.为了实例值识别比较方便,为不同实例值设计不同规则表达式,如字符串实例中的邮箱规则表达式用*@*.*,网址用http://*.*,日期值表示为[d-]{4}-[d-]{2}-[d-]{2},时间表示为 [d-]{2}[d-]{2}:[d-]{2}.对于一般的数字值,用[d-]{n}.[d-]{m}表示,即由n个整数数字及小数点后的m个数字组成.对于一般字符串,表达式A.*表示字符A开头的任意字符或数字,A[w-]{n}表示A开头的n个字符或数字,其中,”*”、w表示任意字符或数字,”d”表示任何数字.图2显示的是WCS模式实例部分片段实例元素表示图.
2.2 模式分割
模式分割基于模式表示图(模式树)进行,分割步骤包括:模式树分割和相似子树识别.
2.2.1模式树分割 根据树节点的度的大小来对树进行分割,分割步骤为:首先按照广度优先方法对树进行遍历,并计算每个节点的出度和入度,入度为0节点为根节点,出度为0节点为叶子节点,出入度都为0节点为孤节点;然后对树进行分割,即从根节点开始,把根节点出度置0,根节点所有直接子节点的入度减1;最后确定分割后子树,即统计所有入度为0节点,每个入度为0节点及其子节点组成一棵新的子树.图3显示的是图2模式树一次分割后结果.图中每个节点用其ID号表示,节点旁标注的是节点度的大小,左边表示入度值,右边为出度值.
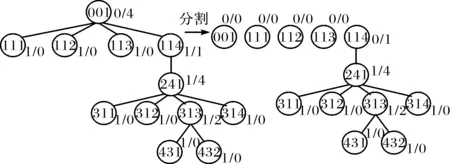
图3 图2模式树一次分割结果Fig.3 Results of the first partition on schema tree in Fig.2
2.2.2相似子树识别 只有相似子树中的对应元素将可能是匹配的候选映射,所以匹配执行前,先识别所有相似子树,再对这些子树进行匹配.当前子树识别方法大多都是根据子树节点命名和结构的综合相似值来判断[15],由于在文献[15]中的名称相似值算法使用的是基于编辑距离的语法方法,考虑到命名的语义异质性,如同名异义,对这些具有相同名称不同意义的标签,如果使用语法方法将会得到错误的匹配结果,所以,名称相似值采用利用语义的匹配方法[16].子树相似值计算公式定义如下:
sim(s,t)=α×simnss(s,t)+ (1-α)×simst(s,t),
其中,sim(s,t)为源子树s和目的子树t的组合相似值.simnss(s,t)为两个子树的根节点语义相似值,simst(s,t)为两个子树的结构相似值,α为权重,0<α<1,同时α值大小可根据实际匹配任务进行调节.通常名称相似值权重比结构相似值权重高,本文中,α取值0.6.
2.3 匹配执行
模式匹配的执行基于所有相似子树对.对于所有的相似子树,们运用两种匹配系统进行组合匹配,即首先应用元数据匹配方法来计算模式树节点间的节点语义相似值,接着应用本文设计的实例匹配器来计算节点间的实例数据相似值,最后对两种相似值取平均值作为节点间的最终组合相似值,而对于没有实例值的节点,其实例相似值为0,所以节点语义相似值即为其组合相似值.下面将详细介绍实例匹配器实现.
2.3.1 实例相似值定义 空间信息网络服务实例数据分为3种类型:字符型,数值型及混合型.字符型实例值可分为单字串符和多字串符,单字符串值如元素名称(Name=”groveMontain”)值,标识(ID=”001”)值等,多字符串值如元素属性描述(description=”NOAA15AdvancedMicrowaveSoundingUnit-AFootprintData”)值等.字符型实例相似值计算定义如下.
定义1(字符实例相似值)设有源字符串Α=(α1,α2,α3,…,αn),目的字符串B=(β1,β2,β3,…,βm),其中α1,α2,α3,…,αn,β1,β2,β3,…,βm为字符串Α、B的原子字符串(原字符串根据其中的停止词,如空格、分号等分成的子字符串,同时去掉其中冠词、介词等),则字符串Α、B的内积为:
(1)
其中,simedit(αi,βj)表示任意两个单字符串根据编辑距离计算的相似值.有了内积,们就能导出字符串的范数和原始字符串相似值定义.
定义2(字符串范数和相似值)设有字符串Α,其范数定义如下:
(2)
则两个原始字符串Α、B间的相似值定义如下:
(3)
数值型实例也分为单数值和多数值型.单数值型就一个实例数值,如观测数据分辨率值(Resolution=”0.0001”),多数值型如观测数据的范围值(lowerCorner=”-90.0-180.0”).对于单数值实例相似值们直接用一个数值比较函数计算,如公式(4)所示.当两个数值相等时相似值为1,其它情况为0.
(4)
空间信息领域数值型比较必须是同属性数据,且具有相同的坐标参考、相同尺度及单位相同.所以对数值型数据比较前先判断数据是否满足上述条件,否则要进行相应转换,如坐标系统转换等,对于属性不同数据则不能用上述公式计算.对于多值型实例比较时,首先确定每个单值代表的属性及其在数值集中位置,然后确定其要比较的目的数值,为了计算方便,同时保证目的数值在数值集中位置与源单值相同,具体计算定义如下.
(5)
最终相似值取所有单值相似值和的平均值.
混合型实例中则既有字符又有数值,如天气观测数据中的观测值中既有时间字符值又包含有温度、压力、风速及风向等数值,如图4所示.此时,在计算实例相似值时,则首先根据实例元素的文本块(TextBlock)模式来确定每个子实例,根据元素类型字段确定每个子实例结构组成.从图4中文本块模式知道每个子实例数据都是由空格分割,从DataRecord的字段值知道每个实例值都是由时间(time)、温度(temperature)、压强(pressure)、风速(windSpeed)及风向(windDirection)组成.接着根据分割符(tokenSeparator=”,”)可以取得每个子实例对应的属性字段值,即组成天气观测的5个值.知道这些实例值及类型后,就可以用公式(3)、(5)对不同类型实例相似值进行计算,然后把这些子实例值的平均值作为混合型实例值的最终相似值,公式定义如下.
定义4(混合型实例相似值)设有混合型实例值H=(Hstr,Hdig),F=(Fstr,Fdig),其中,Hstr,Fstr,Hdig,Fdig分别为混合实例值的字符值部分及数字值部分,则实例H、F的相似值为:
sim(Hdig,Fdig)).
(6)

图4 部分实例片段Fig.4 Parts of instance fragment
2.3.2 实例匹配 实例匹配前先对实例进行预匹配.预匹配主要是计算两个候选实例对相似值,即两个元素标签的语义相似值与实例正则表达式相似值的组合值,当组合值大于设计的门限值(本文设定为0.6)即认为两个元素实例相似.计算公式定义如下.
定义5(候选实例相似值)设有源实例元素Es=(id1,label1,ss1,exp1,flag1),目的实例元素Et=(id2,label2,ss2,exp2,flag2),其候选实例相似值定义为:
sim(Es,Et)=α×sim(label1,label2)+ (1-α)×sim(exp1,exp2),
(7)
其中,sim(label1,label2)表示两个实例元素节点语义相似值.sim(exp1,exp2)表示的是实例正则表达式相似值.在计算正则表达式值时,先判断元素的实例类型是否相同,即判断Flag值是否相同,如不同,则表达式相似值为0,否则根据公式计算表达式相似值.由于表示不同语义的标签,实例值可能相同,所以在选择候选实例相似对时,把两个元素标签在语义上的相似性作为关键因素,所以公式(7)中的α取值为0.7.如,WFS两种版本服务实例元素Es=(“104”,FeatureCollection.featureMember.states.fid”,”states.3”,”s[w-]{8}”,1),Et=(“204”,” FeatureCollection.featureMembers.states.id”,”states.3”,”s[w-]{8}”,1),节点的语义相似值为0.67,通过编辑距离计算得到正则表达式相似值为1.0,所以根据公式(7)得到候选实例相似值sim(Es,Et)=0.7*0.67+1.0*0.3=0.79.超过门限值0.6,所以Es,Et为候选实例对.
确定候选实例对,就可以对实例对进行实例匹配了.图5是候选实例对匹配流程,匹配器输入的候选实例对,输出的是候选实例对的相似值.对每个输出实例相似值,用一个三元组表示,即Mapping=(id1,id2,siminstance),其中id1,id2为对应实例的标签ID号,siminstance则是两个实例间相似值(大小在0到1之间).具体算法描述如下.
560 Comparison of efficacy and safety between wearing orthokeratology contact lens and frame glasses in control of child myopia
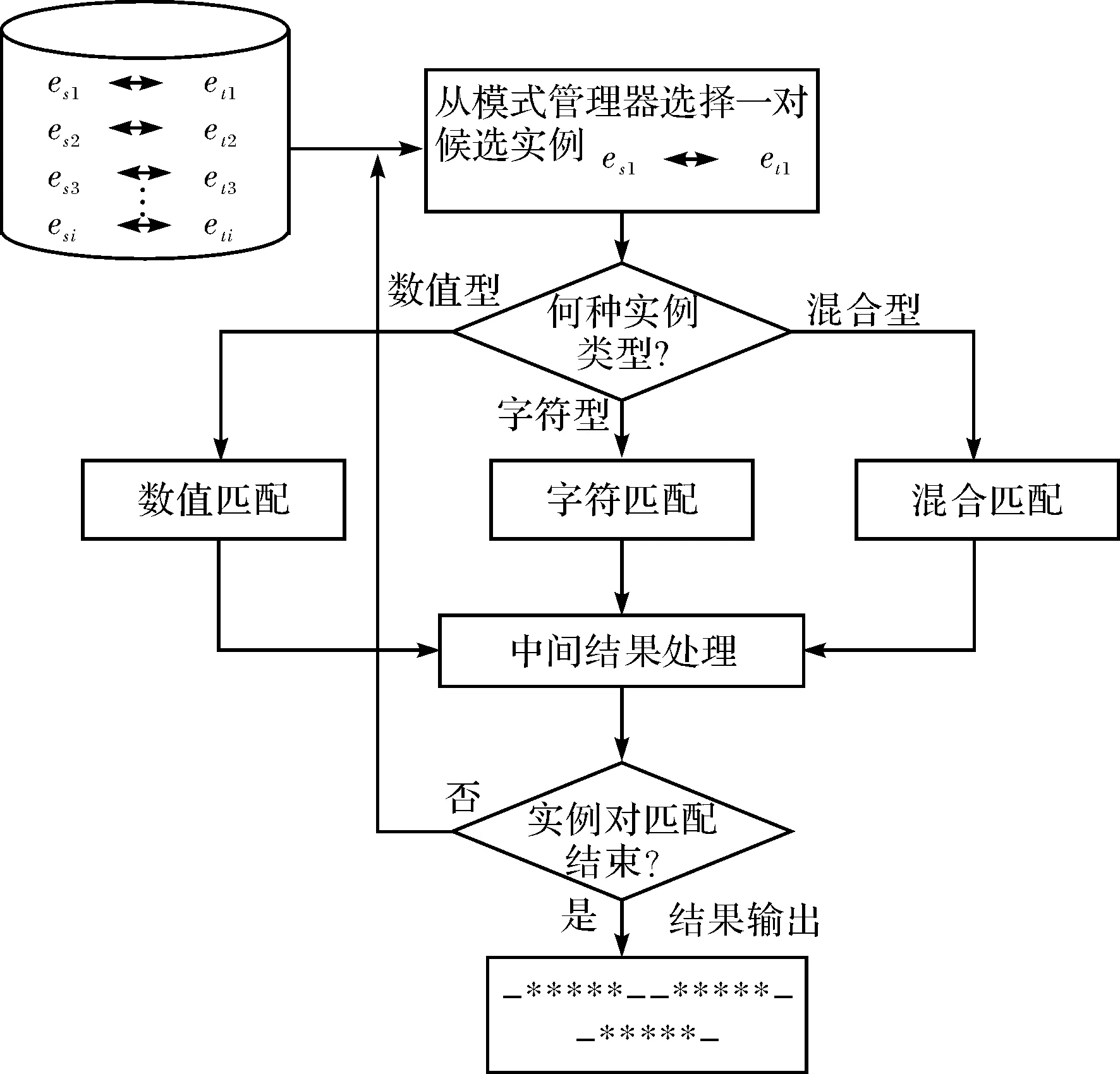
图5 候选实例对匹配流程图Fig.5 Process of the candidate instance pairs matching
算法:实例匹配算法.
输入:相似候选实例对(Es,Et).
输出:实例间映射Mappings.
instanceMatching(Es,Et).
Step 1: 从模式管理器中选择未匹配实例对(esi,etj);
Step2: 判断实例类型,如果是字符类型,使用公式(3)计算实例间的字符相似值;如果是数值型,则使用公式(5)计算实例间的数值相似值;如果是混合类型,则首先根据实例元素的文本块(TextBlock)模式及模式的字段类型来确定实例数据集中每个实例值的结构组成,然后分离出其中的字符实例及数值实例,再利用公式(6)计算混合型实例相似值;
Step3: 匹配中间结果处理.即把匹配的中间结果保存到信息管理库,同时对库中以前的中间匹配结果进行更新,如使用平均值或最大值法对多个不同相似值的相同实例对进行合并;
Step4: 如果实例对匹配完,转步骤Step5,否则返回到步骤Step1,重新执行上述步骤;
Step5: 输出实例匹配结果,算法结束.
3 实验及讨论
本文试验使用的计算机配置为:MicrosoftwindowsXPProfessional操作系统, 2.5GHzIntelCore2Quad处理器,2.0GBRAM,且机器上安装的SunJava1.6.0库.实验数据以开源的WebGIS实现—Geoserver(http://geoserver.org/display/GEOS/Welcome)提供的两种不同版本的WFS、WCS网络服务实例为例,分别选择了wfsGetCapabilities、describeFeatureType、getFeature,wcsGetCapabilities,describeCoverage、getCoverage1.0.0与1.1.1两种版本的XML模式文件进行匹配.在模式实例的文件解析时,同时对模式实例的元素及其实例类型进行了自动化统计,统计结果如表1、表2所示.
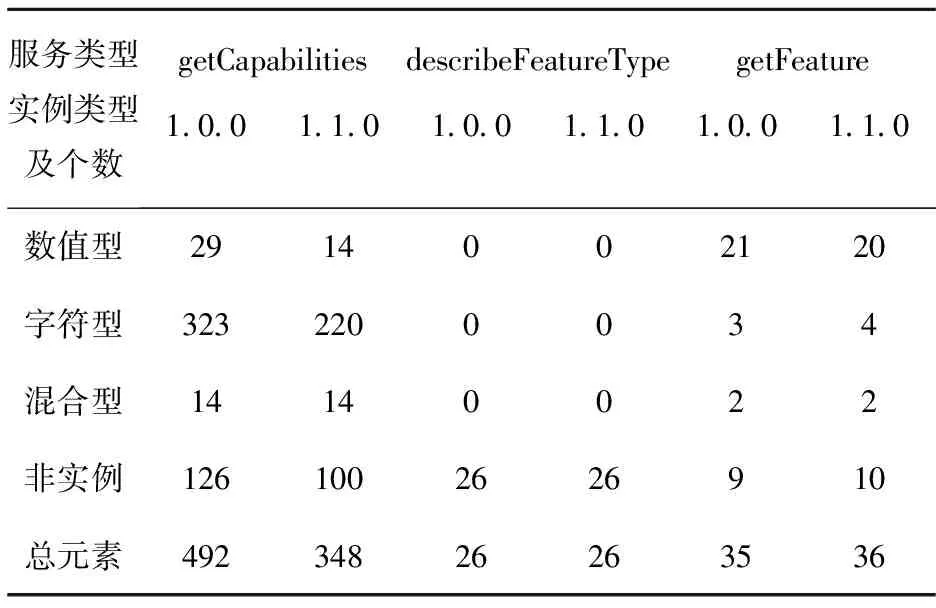
表1 WFS服务实例元素统计

表2 WCS服务实例元素统计
应用①iMatch;②COMA;③iMatch+COMA分别进行匹配试验,其中iMatch使用的是本文设计的几种实例匹配算法;COMA则使用其自带上下文匹配器,匹配器相似值聚合方法使用的是平均值法,匹配结果使用双向定向法,相似值组合方法取平均值法,候选者选择方法取最大值法.同时,用传统的查全率(Recall),精度(Precision)来评估匹配结果,试验结果如图6、图7所示.从图6、图7看出,对于getCapabilities操作的两种不同版本响应文件,实例元素较多,通过自动预处理和人为确认,两个版本所有元素间,有319对候选元素,其中候选实例元素有248对,实例匹配发现,所有248对实例元素间相似值都为1,同时,应用COMA进行元素标签和结构匹配,确定了305对映射关系,由于有100多元素没有实例,导致实例匹配不起作用,以致实例匹配查全率和精度都低于COMA,只有80%左右.同样,对于getFeature操作的两种响应文件,有31对候选元素,其中实例元素有25对,实例匹配确定了全部25对实例映射,COMA匹配发现了31对候选映射中的29对,由于实例的不完全,在查全率和精度上还是COMA领先.对于describeFeatureType操作的响应文件,由于没有实例元素,所以iMatch匹配的查全率和精度均为0,而26对非实例元素对使用COMA匹配时,查全率和精度都达到理想的100%.对于WCS的wcsGetCapabilities两种不同版本响应文件,由于近一半元素没有实例数据,导致了iMatch查全率只有60%左右;对于describ-eCoverage,非实例元素相对较少,对于34个实例元素,iMatch发现了其中25对,查全率近75%,而由于describeCoverage元素语义差异性,导致COMA匹配查全率不高,大约65%;对于getCoverage,XML实例文件元素很少(10个左右),11个实例数据,iMatch发现了其中7个映射,查全率67%,不同版本getCoverage结构与元素语义差异大,所以仅仅通过COMA匹配,查全率和精度都较低,查全率只有56%,精度也只有60%左右.可见,COMA对于非实例元素匹配效果好,而iMatch对于实例元素匹配又非常理想,例如getFeature实例模式中元素对posList↔coordinates, 利用COMA不能确定它们间映射关系,但通过实例匹配却完全可以,所以基于实例和基于元数据匹配器组合匹配能达到理想效果,如图6、图7中,iMatch+COMA匹配器组合,对于所有模式及实例,匹配查全率和精度都是最好的,部分匹配查全率达到100%,精度高达98%.
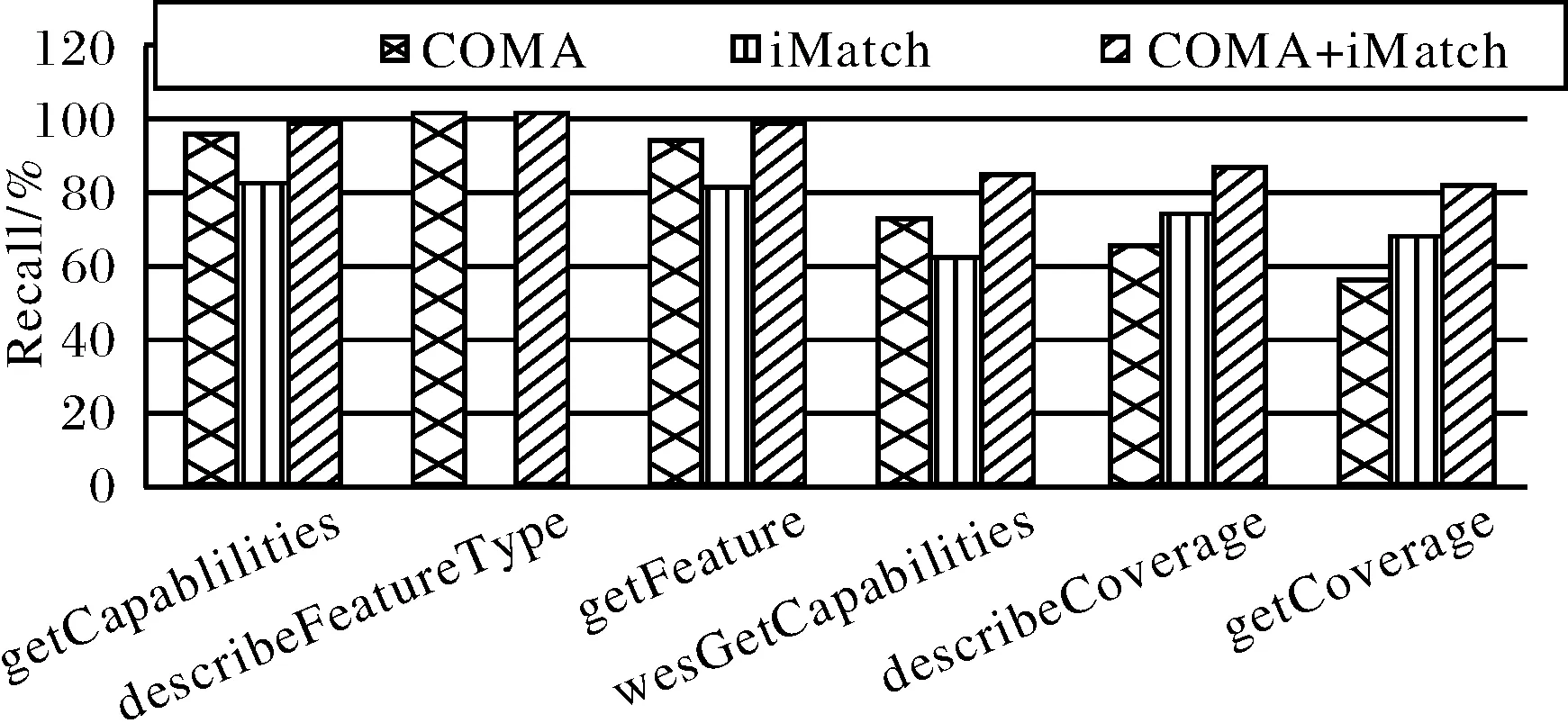
图6 匹配查全率比较Fig.6 The recall of 3 match methods

图7 匹配精度比较Fig.7 The precision of 3 match methods
基于实例匹配方法中字符型和混合型实例都描述了某种属性和特征,相同实例一般都描述的是类似元素特征,但对于数值型实例则不同,由于仅仅只是代表数字多少,且在一个模式实例中同数值的实例可能很多,匹配时如果没有元素标签语义辅助很容易造成错误映射产生.为了测试系统对于数值型实例匹配的健壮性,以getCapabilities操作的响应文件为例,手工增加了30对错误候选映射元素,其中15对为数值型映射,匹配器选择iMatch+COMA,实验结果如图8所示.从图8可以看出,随着错误候选映射的增加,特别是数值型候选实例的增加,匹配查全率和精度也随着快速降低.当错误候选映射从8增加到28时,精度从98%下降到65左右,所以对数值型实例匹配时,一定要在匹配预处理时确定好可能的正确映射,否则容易影响匹配质量.
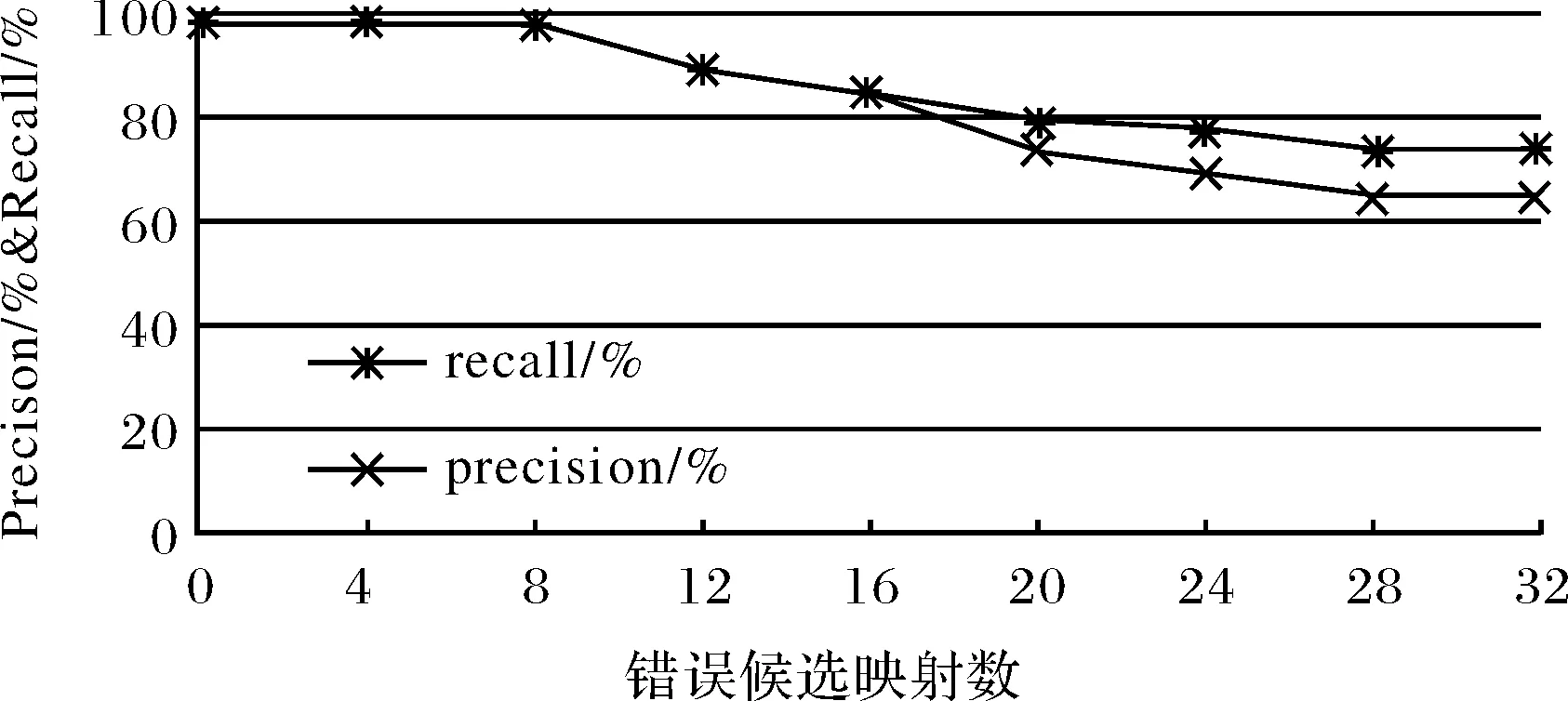
图8 加入30个错误映射后的匹配健壮性Fig.8 Robustness of schema match with 30 false candidate mappings
4 结论与展望
针对当前空间信息网络服务模式匹配中存在的由于语义异质性问题导致的映射丢失问题,本文在综合分析现有元数据和实例匹配器基础上提出了以元数据匹配器为基础,实例匹配器为辅助的组合模式匹配方法,并重点阐述了实例数据提取及匹配算法.WFS、WCS服务实例匹配验证结果表明,文中提出的方法有效提高了匹配的查全率和精度.异质的空间信息网络服务,特别是异质的传感器观测服务(SOS)匹配问题将是下一步研究重点.由于不同的观测服务实例数据格式、表示和语义差异巨大,因此,未来,我们将利用大量SOS服务实例来试验本文提出的方法,同时针对匹配中遇到复杂实例,如结构复杂、大数据匹配问题,设计更优的算法来提高匹配质量.
[1]SHVAIKOP,EUZENATJ.Asurveyofschema-basedmatchingapproaches[J].JournalonDataSemanticsIV, 2005, 4:146-171.
[2]GIUNCHIGLIAF,SHVAIKOP.Semanticmatching[J].KERJournal, 2003, 18(3):265-280.
[3]GIUNCHIGLIAF,SHVAIKOP,YATSKEVICHM.S-Match:AnalgorithmandanimplementationofSemanticMatching[C]//In:ProceedingsoftheEuropeanSemanticWebSymposium(ESWS),Springer,Heidelberg, 2004:61-75.
[4]GIUNCHIGLIAF,YATSKEVICHM,GIUNCHIGLIAE.Efficientsemanticmatching[C]//InProceedingsofESWC,Heraklion,Greece, 2005:272-289.
[5] 王育红, 陈 军. 基于实例的GIS数据库模式匹配方法[J]. 武汉大学学报(信息科学版), 2008, 33(1):46-50.
[6]AUMÜLLERD,DOH,MAβMANNS,etal.SchemaandontologymatchingwithCOMA++[C]//Procofthe2005ACMSIGMODInt.ConferenceonManagementofData.ACMPress,NewYork,NY,USA, 2005:906-908.
[7]NOYN,MUSENM.ThePROMPTsuite:interactivetoolsforontologymergingandmapping[J].InternationalJournalofHuman-ComputerStudies, 2003, 59(6):983-1024.
[8]VRETANOSPA.OGCTMWebFeatureserviceimplementationspecification[S]In:OpenGeospatialConsortium(OGC),DocumentNumber:02-058,Wayland,MA,USA, 2002:105.
[9]WHITESIDEA,EVANSJD.OGCTMWebCoverageserviceimplementationspecification[S].In:OpenGeospatialConsortium(OGC),DocumentNumber:07-067,Wayland,MA,USA, 2007:133.
[10]NAA,PRIESTM.OGCTMSensorObservationserviceimplementationspecification[S].In:OpenGeospatialConsortium(OGC),DocumentNumber:06-009,Wayland,MA,USA, 2006:187.
[11]WANGJ,WENJ,LOCHOVSKYFH,etalInstance-basedschemamatchingforwebdatabasesbydomain-specificqueryprobing[C]//Proceedingsof30thIntlConferenceonVeryLargeDatabases,Toronto,Canada, 2004:408-419.
[12]DOANA,MADHAVANJ,DOMINGOSP,etal.Ontologymatching:Amachinelearningapproach[C]//StaabS,StuderR(eds).HandbookonontologiesininformationSystems.Springer,BerlinHeidelbergNewYork, 2004:397-416.
[13]BILKEA,NAUMBNNF.Schemamatchingusingduplicates[C]//Procofthe21stIntlConferenceonDataEngineering(ICDE),Tokyo,Japan, 2005:69-80.
[14]DOHH,RAHME.COMA-Asystemforflexiblecombinationofmatchalgorithms[C]//Proceedingsofthe28thInternationalConferenceonVeryLargeDataBases,HongKong,China, 2002.
[15]CHENN,HEJ,WANGW,etal.ExtendedFRAG-BASEschemamatchingformulti-versionopenGISservicesretrieval[J].InternationalJournalofGeographicalInformationScience, 2011, 25(7):1045-1068.
[16] 何 杰, 陈能成, 郑 重, 等. 利用语义的多版本网络覆盖服务模式匹配方法[J].武汉大学学报(信息科学版), 2012, 37(2):210-214.
An instance-based web services schema matching method
HE Jie1, WANG Xinyun2, GUO Yige2
(1.School of Resource and Environment, Ningxia University, Yinchuan 750021;2.Ministry of Education Key Laboratory for Restoration and Reconstruction of Degraded Ecosystem in Northwest China, Ningxia University, Yinchuan 750021)
To solve the problems of mapping lost on schema matching among heterogeneous web service schemas caused by difference in structure and semantics, this paper presents a schema matching method with instance applied. Firstly, a metadata matcher is used to do matching on element tags and schema structure. Then, an instance matching algorithm is designed for exact matching on element instance data to determine the correspondence between schema elements. Finally, schema matching tests are carried on different versions of the Web Feature Service (WFS) and Web Coverage Service (WCS), demonstrating that the method is feasible.
schema matching; instance; multi-version; web feature service; web coverage service
2015-04-12.
国家自然科学基金项目(41201393);宁夏自然科学基金项目(NZ12110);武汉大学测绘遥感信息工程国家重点实验室开放基金项目(14I03).
1000-1190(2015)06-0843-08
TP393;P208
A
*E-mail: whujiejie@163.com.
