面向语音情感识别的语谱图特征提取算法
2015-03-15陶华伟梁瑞宇张昕然王青云
陶华伟 査 诚 梁瑞宇,2 张昕然 赵 力 王青云,2
(1东南大学水声信号处理教育部重点实验室,南京210096)
(2南京工程学院通信工程学院,南京211167)
语音作为最主要的交流手段之一,在新型的人机交互领域中备受关注.为了使人机交互系统和机器人的对话系统更加智能和完善,语音的情感分析变得越来越重要[1-2].此外,在一些长时间的、单调的、高强度的任务(如航天、航海等)中,相关人员常会产生某些负面情绪[3],有效地识别这些负面情绪,有助于提高个体认知和工作效率,防患于未然.面对犯罪调查、智能协助等问题[4],语音情感识别也能够起到重要作用.因此,语音情感识别算法研究具有重要的实用意义.
针对语音情感识别问题,学者们从不同角度进行了研究,取得了许多有价值的成果[5-8].考虑到特征构造及特征选择对识别性能影响较大[9-10],学者们对情感特征进行了细致的分析和研究,并提出了多种语音情感特征构造方式.当前语音情感特征主要包括韵律特征、频域特征、音质特征[11-12].语音信号频域和时域中信号间的相关性在语音情感识别中起到了重要作用[13].但针对语音信号间相关性的研究,往往仅集中在频域或时域中,将语音信号时频两域的相关性相结合的文献则较少.语谱图是一种语音能量时频分布的可视化表达方式,其横轴代表时间,纵轴代表频率,连通了时频两域,将语谱图的频率点建模为图像的像素点,便可利用图像特征探讨相邻频点间的联系,为研究时频两域相关性提供了一种新的思路.
基于此,本文提出了一种面向语音情感识别的语谱图特征提取算法.首先,提取情感语音的语谱图;然后,将提取到的语谱图进行归一化处理,得到语谱图灰度图像;再次,利用Gabor小波计算不同方向、不同尺度语谱图的Gabor图谱,并利用局部二值模式抽取语谱图Gabor图谱的纹理信息;最后,将不同尺度、不同方向Gabor图谱抽取到的LBP特征级联,组成一种新的语音情感特征.在柏林库(EMODB)和FAU AiBo库上的实验结果表明,基于本文提出的特征能够较好地识别不同种类情感,此外,与现有声学特征融合后还可有效地提升识别率.
1 语谱图图像特征提取算法
特征提取算法的具体步骤如下:① 对语音进行加窗分帧,提取语音的语谱图;②计算语谱图线性或对数归一化幅度值,将语谱图量化为0~255的灰度图;③采用不同尺度、不同方向的Gabor小波计算语谱图的Gabor图谱;④ 计算不同尺度、不同方向Gabor图谱的局部二值模式;⑤ 将不同尺度、不同方向下求得的局部二值模式特征级联,构成一种新的语音情感特征.算法流程如图1所示.
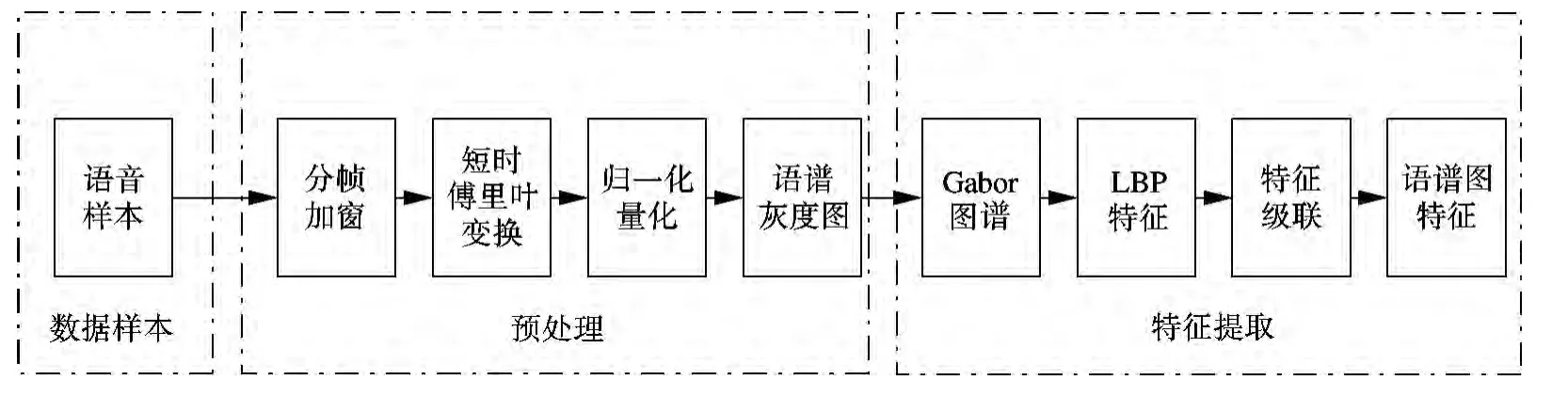
图1 特征提取算法流程图
1.1 语谱图灰度图像表示
语谱图的静音段包含大量的非零数值,直接计算语谱图的LBP特征会引入误差.因此,需要对语谱图进行预处理,得到归一化的语谱图灰度图像.首先,对语音进行分帧、加窗及离散傅里叶变换处理,即

式中,s(n)为语音信号;X为s(n)的傅里叶系数;N为窗长;ω(n)为汉明窗函数.由此可得到s(n)的语谱图
其次,采用线性和对数能量2种不同的方法生成语谱图 LLinear(a,b)和 LLog(a,b),即
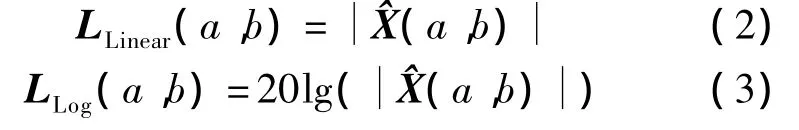
式中,a∈{1,2,…,A},b∈{1,2,…,B}为语谱图像素的坐标,其中A,B分别为语谱图横、纵坐标的最大值.
然后,采用最大最小归一化方法对语谱图进行归一化,得到归一化语音图谱,即

式中,L(a,b)为语谱图;Lmax(a,b),Lmin(a,b)分别为语谱图灰度级中的最大值和最小值.
1.2 语谱图的Gabor图谱
Gabor小波可以凸显相邻灰度级间的变化.本文采用Gabor小波对语谱图灰度图进行处理.Gabor小波的核函数定义如下:
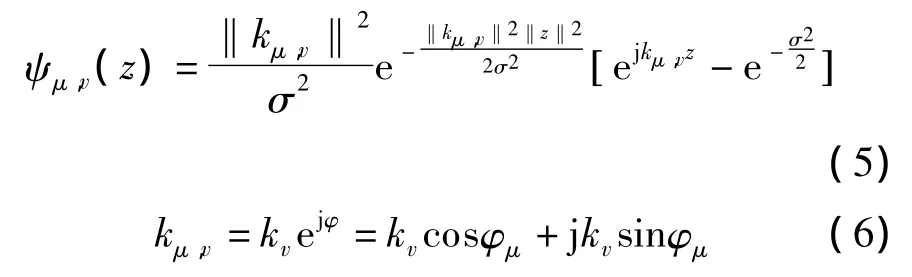
式中,μ表示Gabor的核方向;v表示核尺度;z表示像素点的空间坐标;σ表示高斯函数的半径;kv
本文采用五尺度八方向的Gabor小波,其参数设置为:v∈{0,1,2,3,4},μ∈{0,1,2,3,4,5,6,7},σ=2π.通过将生成的Gabor小波与语谱图灰度图像进行卷积运算,可得到40张Gabor图谱.
1.3 局部纹理特征

式中,gc为中心像素点的灰度值;gp为周边邻域像素点的值;P为选取周边邻域点的总个数;R为邻域半径.假设gc点的坐标为(0,0),则gp的坐标为(Rcos(2πp/P),Rsin(2πp/P)).
对图像上所有像素点进行LBP编码,便可得到LBP编码图谱.LBP编码图谱直方图的计算公式为
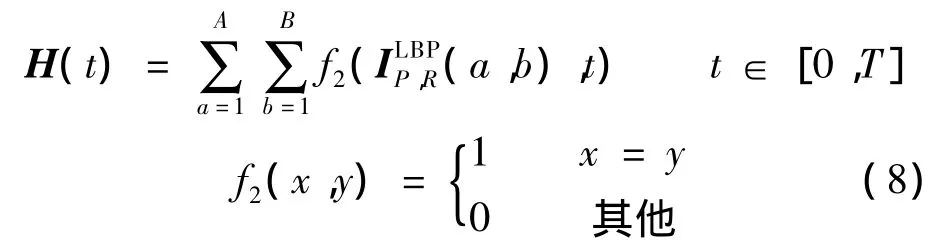
式中,T为LBP编码后的最大灰度值.
研究发现,LBP图谱中只有少部分的灰度级占主要作用,因此定义了如下的一致模式:
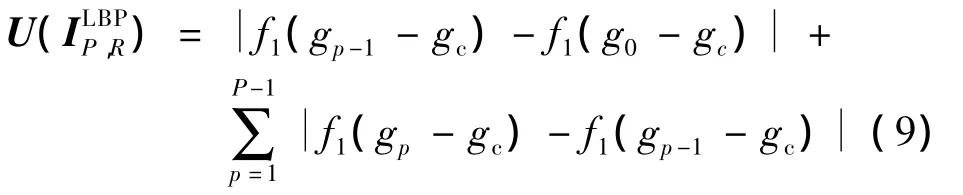
式中,U表示数值0/1变换次数.该一致模式可将循环二值次数限制为U≤2.经过一致模式处理后,一致模式LBP中包含P(P-1)+3个不同值.
本文中,采用一致模式LBP计算Gabor图谱的纹理特征,基于第l个Gabor图谱求得的LBP直方图为 ql(l=1,2,…,40).将不同尺度、不同方向Gabor图谱下的LBP直方图级联,便可得到特征Q={q1,q2,…,q40}.
2 分类识别
识别系统框图如图2所示.首先,将训练样本库中的语音进行预处理和特征提取,得到训练样本特征矩阵Htrain;其次,利用训练样本对矩阵Htrain进行训练,得到最优分类器参数;然后,将测试样本进行预处理和特征提取,得到测试样本矩阵Htest;最后,将测试样本矩阵输入分类器中,输出识别结果.
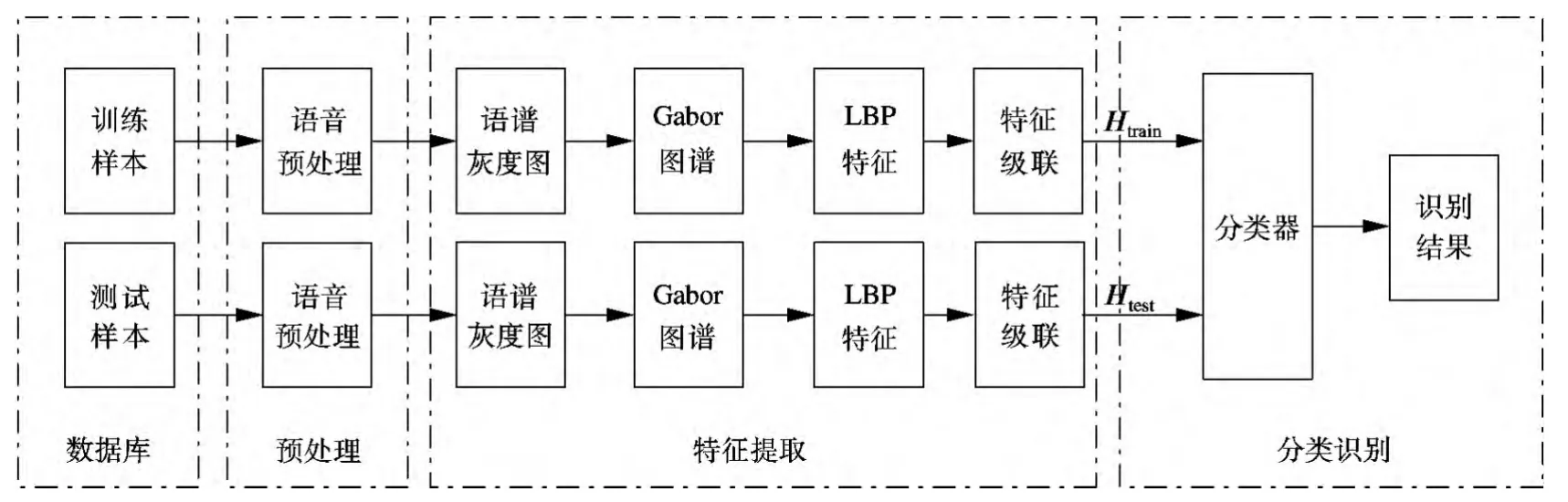
图2 语音情感识别系统
本文采用K近邻算法、支持向量机(SVM)和Softmax分类器进行语音情感识别.K近邻算法中取K=1,距离公式采用χ2统计距离公式,即

式中,cm,dm为特征中的元素;C,D为语音的情感特征,且其维数为M.SVM采用LIBSVM工具箱,核函数采用径向基核.Softmax分类器中权重衰减项设为10-4,迭代次数设为200.
3 仿真实验
3.1 实验数据库及实验设计
为验证算法的有效性,本文分别在柏林库(EMO-DB)和FAU AiBo库上进行仿真.
柏林库由10个不同的人(5男5女)录制而成,包含7种不同的情感,分别为平静、害怕、厌恶、喜悦、讨厌、悲伤、愤怒.算法选取其中494条语句构成数据库进行实验.
FAU AiBo库由2所学校51个年龄在10~13岁的儿童录制而成,按照2009年情感挑战赛标准将其分为5种不同情感,分别为A(angry,touchy,reprimanding),E(emphatic),N(neutral),P(motherese,joyful),R(rest).数据库包含2 部分,其中ohm库包含9 959条语句,mont包含8 257条语句.
所选用的实验方案包含如下3种:
1)采用Leave one speaker out(LOSO)方案,即选取柏林库中的9个人作为训练集,剩余的作为测试集;10个人轮流作测试集,将10次识别结果求平均,作为最终识别结果.
2)将柏林库中编号为“03”,“08”,“09”,“10”,“11”的5个人的220条语音作为测试集,其余5人语音作为训练集.
3)FAU AiBo库采用ohm库作为训练集,mont作为测试集.
3.2 不同频谱图像比较实验
下面基于3种实验方案来验证对数图谱和线性图谱对所提特征提取算法的影响.
表1为实验方案1和方案3下所提的特征提取算法的识别结果.由表可知,在2个不同的数据库上,线性图谱的识别率略高于对数图谱.对比3种不同的分类器,在柏林库中,Softmax分类器可以取得最好的识别效果,识别率达到76.62%;在FAU AiBo库上SVM分类器可以取得最好的识别效果,识别率达到65.04%.
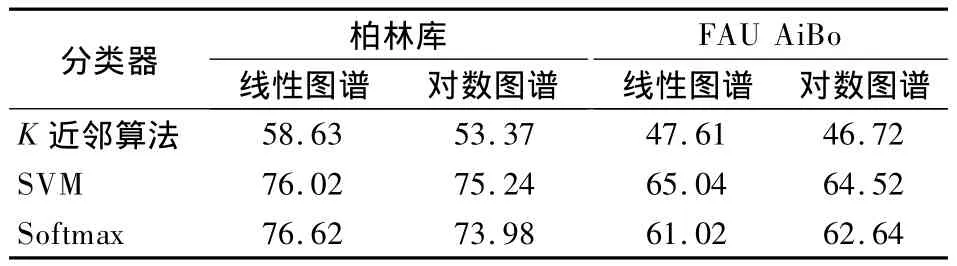
表1 方案1和方案3下所提算法的特征识别率 %
为进一步验证线性和对数2种图谱特征提取算法的识别性能,依照实验方案2,采用Softmax分类器进行识别,计算2种图谱的分类混淆矩阵.图3给出了2种图谱的混淆矩阵.可以看出,2种图谱对喜悦、愤怒情感的识别率较低,对厌恶、讨厌、平静、悲伤识别性能较好.线性、对数图谱对7种情感识别率的平均值分别为78.00%和76.43%.
3种实验方案结果表明,就本文算法而言,线性图谱的识别性能略优于对数图谱.原因在于,语谱图采用线性运算处理后,最大最小值幅值差距比对数语谱图小;当进行最大最小归一化运算时,线性语谱图量化间距比对数语谱图小,在量化时能够保留较多的细节信息.
3.3 不同特征比较实验
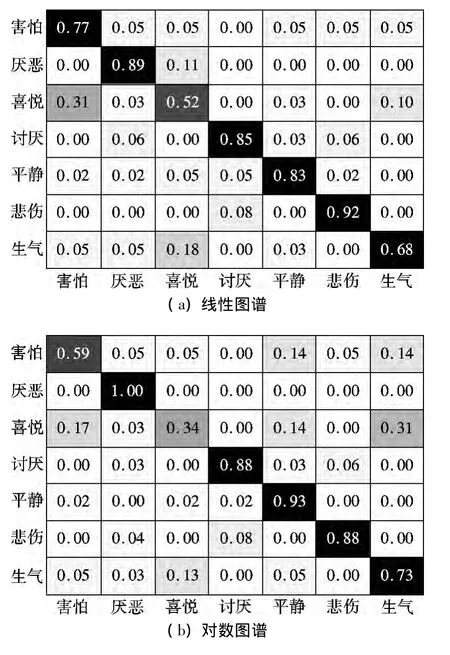
图3 混淆矩阵
文献[14]提取了语音的基频、过零率、能量、共振峰、持续时间、Mel频率倒谱系数特征等408维特征,基本包含了现有情感识别常见的语音特征.表2为按照本文算法提取到的特征与文献[14]特征的对比结果.由表可知,所提特征的识别率明显优于文献[14]特征.在柏林库上,所提特征的识别率较文献[14]特征高出5%以上;在FAU AiBo库,所提特征的识别率较文献[14]特征最少提升3%.产生上述结果的原因在于:时长的变化是语音情感的一个重要特征,该特征在频谱上表现为语音段和静音段比例的变化;在归一化语谱图灰度图像中,静音段的灰度级基本相同,LBP编码值为0,而非静音段的灰度值差异较大,LBP编码值发生了变化,故LBP算法可以表征静音段和有声段比例的变化;不同情感语音频谱分布产生了较大变化,而LBP描述子通过计算中心频点与周边邻域的关系,有效地表征了这一特征.因此,所提算法取得了更好的识别效果.
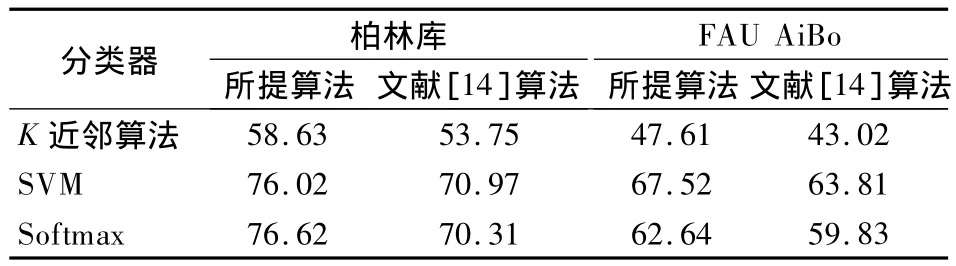
表2 方案1和方案2下不同算法的特征识别率 %
3.4 特征融合实验
为进一步验证所提算法的有效性,基于实验方案2,将所提特征与文献[14]的特征融合,进行语音情感识别,识别结果见图4.由图可知,在3种不同的分类器下,将所提特征与文献[14]的特征进行融合后,可以有效地提高识别率,识别率至少比文献[14]的特征提升了5%以上.特别地,在Softmax分类器下,融合特征识别率为80.46%.而采用文献[14]的特征进行识别,识别率仅为68.64%.究其原因在于,所提算法与现有的声学特征具有较好的融合性,有效地提升了系统识别性能.
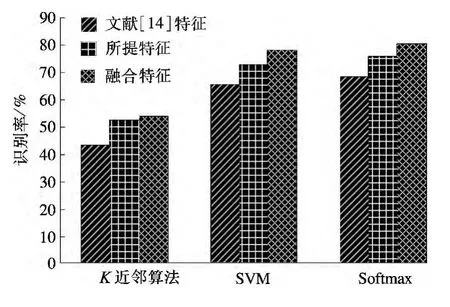
图4 不同特征识别率
4 结语
本文提出了一种面向语音情感识别的语谱图特征提取算法.首先,对图像进行处理,得到语谱图灰度图像;然后,采用Gabor小波提取语谱图灰度图像的Gabor图谱,并采用LBP算法提取Gabor图谱的纹理图像信息;最后,将不同尺度、不同方向Gabor图谱提取到的LBP特征进行级联,作为一种新的语音情感特征进行情感识别.柏林库和FAU AiBo库上的实验结果验证了本文算法的有效性.
本文将语谱图建模为灰度图像,并利用LBP特征研究不同频点间相关性对情感识别的影响,为研究情感识别提供一个新的思路.此外,当前语音情感识别主流趋势是采用多种不同特征融合进行情感识别,语谱图图像特征可以作为一类新的特征进一步增强情感语音识别系统的性能.
References)
[1] Attabi Y,Dumouchel P.Anchor models for emotion recognition from speech[J].IEEE Transactions on Affective Computing,2013,4(3):280-290.
[2] Ramakrishnan S,El Emary I M M.Speech emotion recognition approaches in human computer interaction[J].Telecommunication Systems,2013,52(3):1467-1478.
[3] Lee A K C,Larson E,Maddox R K,et al.Using neuroimaging to understand the cortical mechanisms of auditory selective attention[J].Hearing Research,2014,307:111-120.
[4] Minker W,Pittermann J,Pittermann A,et al.Challenges in speech-based human-computer interfaces[J].International Journal of Speech Technology,2007,10(2/3):109-119.
[5] Zhao X M,Zhang S Q,Lei B C.Robust emotion recognition in noisy speech via sparse representation[J].Neural Computing and Applications,2014,24(7/8):1539-1553.
[6] Huang C W,Chen G M,Yu H,et al.Speech emotion recognition under white noise[J].Archives of Acoustics,2013,38(4):457-463.
[7] Yan J J,Wang X L,Gu W Y,et al.Speech emotion recognition based on sparse representation[J].Archives of Acoustics,2013,38(4):465-470.
[8] Wu C H,Liang W B.Emotion recognition of affective speech based on multiple classifiers using acoustic-prosodic information and semantic labels[J].IEEE Transactions on Affective Computing,2011,2(1):10-21.
[9] Bozkurt E,Erzin E,Erdem C E,et al.Formant position based weighted spectral features for emotion recognition[J].Speech Communication,2011,53(9):1186-1197.
[10] Altun H,Polat G.Boosting selection of speech related features to improve performance of multi-class SVMs in emotion detection[J].Expert Systems with Applications,2009,36(4):8197-8203.
[11] Mencattini A,Martinelli E,Costantini G,et al.Speech emotion recognition using amplitude modulation parameters and a combined feature selection procedure[J].Knowledge-Based Systems,2014,63:68-81.
[12] El Ayadi M,Kamel M S,Karray F.Survey on speech emotion recognition:features,classification schemes,and databases[J].Pattern Recognition,2011,44(3):572-587.
[13] 韩文静,李海峰,阮华斌,等.语音情感识别研究进展综述[J].软件学报,2014,25(1):37-50.Han Wenjing,Li Haifeng,Ruan Huabin,et al.Review on speech emotion recognition[J].Journal of Software,2014,25(1):37-50.(in Chinese)
[14] Xu X Z,Huang C W,Wu C,et al.Graph learning based speaker independent speech emotion recognition[J].Advanced in Electrical and Computer Engineering,2014,14(2):17-22.
