基于时频域特征的场景音频研究
2018-06-13王旭东
张 勇, 张 溯, 王旭东, 路 阳, 王 臣
(1. 东北石油大学 a. 电子科学学院; b. 黑龙江省网络化与智能控制重点实验室, 黑龙江 大庆 163318;2. 大庆油田有限责任公司第一采油厂 仪表安装维修大队, 黑龙江 大庆 163453;3. 黑龙江八一农垦大学 电气与信息学院, 黑龙江 大庆 163319)
0 引 言
随着计算机科学与人工智能的飞速发展, 人们对声音的研究变得越来越深入, 同时将语音作为信号的一种, 进行数字化处理, 逐步发展出庞大的学科体系[1]。经过多年的探索, 对语音的研究已经无法满足人类社会的需求, 人们的目光开始转向了非语音的环境声音, 并从中可获取大量有价值的信息。对其所处场景的研究可以帮助人们从海量的数据中抽取有用的信息, 并应用于现代农业、 地质勘探、 军事科研等领域[2], 具有十分重要的意义。
当前对场景音频的分析可以从时域、 频域两方面入手。在时域分析方面, 无论待分析的场景音频是数字量还是模拟量, 以时间为自变量的时域信号都是其原有的表达形式。时域分析的波形简洁易懂, 但含有的有效信息较少, 常选取的特征有过零率、 短时能量和自相关函数等。而频域分析则包含了更多的感知性能和声学特征, 对外界环境变化的抗干扰能力和适应性更强, 其中使用最广泛的声学特征是梅尔频率倒谱系数(MFCC: Mel Frequency Cepstrum Coefficient)[3]。它结合了人耳的听觉特征和语音产生原理, 与频率呈非线性对应关系, 对结构性突出的音频(比如语音)有着出色的刻画能力。但是场景音频一般时长较长, 频率变化比语音音频剧烈得多, 在非平稳态噪声条件下, 性能会急剧下降, 影响声学特征的提取[4]。如果使用短时特征, 就不能完整的刻画出场景音频的声学特征; 如果使用长时统计值, 会造成特征的局部结构性信息的丢失[5]。时域信号和频域信号都是一维信号, 如果将这两者联合, 将时间和频率同时作为自变量, 而将对应的能量值当作因变量, 这既可反映音频信号的长时特征, 也能反映其局部特性, 使场景音频的时频域特征得到完整的保留。
笔者通过对场景音频的时频域特征进行提取, 得到待分析信号的语谱图, 对于其中涉及到的重要参数进行调整, 使其中的声学特征得到完整保留, 使语谱图的表现效果达到最佳状态, 进而可应用于场景音频的分类处理及模式识别等研究方向[6]。
1 语谱图
语谱图是一种可视化语言, 能描述声音时间-频率-频谱能量密度的变化, 被广泛应用于音频识别及去噪领域[7,8]。语谱图的显示简洁明了, 灰度语谱图上会用深浅不同的黑灰色条纹呈现出有规律的形状, 即声纹, 它反映音频信号的变化规律。语谱图的横坐标为时间, 纵坐标为频率, 而对应点的颜色深浅则表示在该时间、 频率上频谱能量的大小[9]。
1.1 语谱图的产生原理
绘制语谱图的核心思想是假设音频信号在一定时间内是稳定的, 对音频信号进行分段, 将每段音频当做平稳时间信号处理。关键算法为短时傅立叶变换(STFT: Short Time Fourier Transform)和离散傅里叶变换(DFT: Discrete Fourier Transformation)。STFT又叫窗式傅里叶变换, 它将非平稳过程看成是一系列短时平稳信号的叠加, 短时性可通过在时间上加窗实现。快速傅里叶变换为离散傅里叶变换的一种快速高效的算法, 因此一般在实际操作时, 使用快速傅里叶变换。
假设离散时域信号为x(n),n=0,1,…,N-1, 其中n为时域采样点序号,N是信号长度。然后对信号进行分帧处理, 则x(n)表示为xq(m),q=0,1,…,Q-1, 其中q是帧序号,m是帧同步的时间序号,Q为帧长(一帧内的采样点数)。信号x(n)的STFT为
(1)
其中w(q)为窗序列[10], 则信号x(n)的离散时间傅里叶变换(DTFT: Discrete Time Fourier Transform)为
(2)
DTF由DTFT采样得到, 采用DFT, 则x(n)的短时幅度谱估计为
(3)
假设信号x(n)的傅里叶变换为X(w), 则x(n)的自相关函数的傅里叶变换可以表示为X(q)与共轭变换conj(X(q))的乘积[11]。则时间m处的频谱能量密度函数P(q,k)可表示为
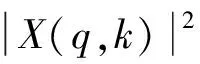
(4)
频谱能量密度函数P(q,k)的分贝(dB)表示为
P(q,k)(dB)=10Log10(P(q,k))
(5)
其中以q为横坐标,k为纵坐标, 以P(q,k)(dB)为表示对应点上的灰度值, 所得的二维图像就是时间信号x(n)的语谱图。
1.2 窗函数
加窗是对音频进行语谱图提取过程中的重要步骤。当使用软件对音频信号进行分析和处理时, 不可能使用无限长的音频信号, 而是要截取部分有效的片段进行操作。因此, 需从待分析音频中截取一个片段, 对该片段进行周期延拓处理, 从而得到虚拟的无限长的音频信号, 就可以对该信号进行分析和处理。无限长的音频信号被截断以后, 其频谱会发畸变, 从而造成频谱能量泄露。为减少频谱能量泄漏, 可采用不同的截取函数对信号进行截断[12], 截断函数称为窗函数, 简称为窗。
不同的窗函数对信号频谱的影响不同, 控制频谱能量泄漏的能力不同, 频率识别精度和幅值识别精度也不同。对于场景音频, 一般其频谱表现都十分复杂, 包含多个频率分量, 周期性较差, 随机性较强, 因此在窗函数的选择方面, 需遵循主瓣宽度窄, 旁瓣衰减速度快的原则[13]。在这种情况下, 汉宁窗(Hanning)和海明窗(Hamming)都是不错的选择。
汉宁窗又被称为升余弦窗[14], 可将其看为3个矩形时间窗的频谱和, 它可使旁瓣互相抵消, 衰减速度较快, 可消除干扰和能量泄漏。其表达式为
(6)
其中whn(n,τ)表示窗函数,n=1,2,3,…,Nwin,n为窗函数采样点序号,τ表示窗的中间位置,Nwin为窗长。汉宁窗输出的波形图如图1所示。
海明窗也是余弦窗的一种, 又被称为改进的升余弦窗, 汉宁窗和海明窗都是升余弦窗, 只是加权系数不同, 海明窗的加权系数能使旁瓣达到更小。其表达式为
(7)
其中whm(n,τ)表示窗函数,n=1,2,3,…,Nwin,n为窗函数采样点序号,τ表示窗的中间位置,Nwin为窗长。海明窗输出的波形图如图2所示。
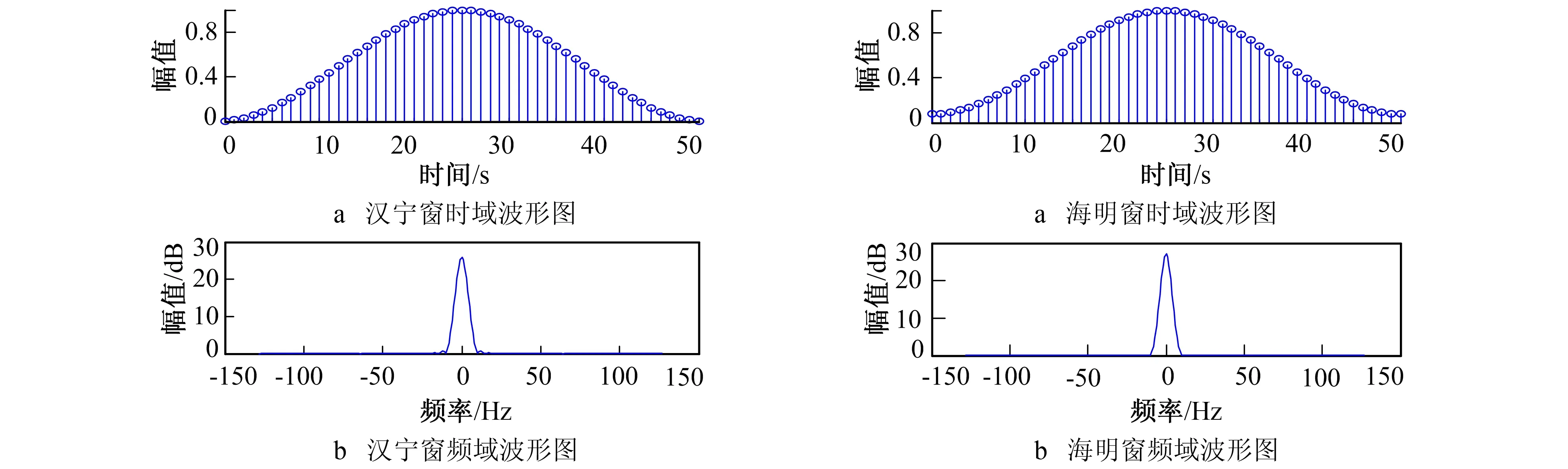
图1 汉宁窗波形图 图2 海明窗波形图 Fig.1 The waveform of hanning window Fig.2 The waveform of hamming window
1.3 语谱图的提取流程
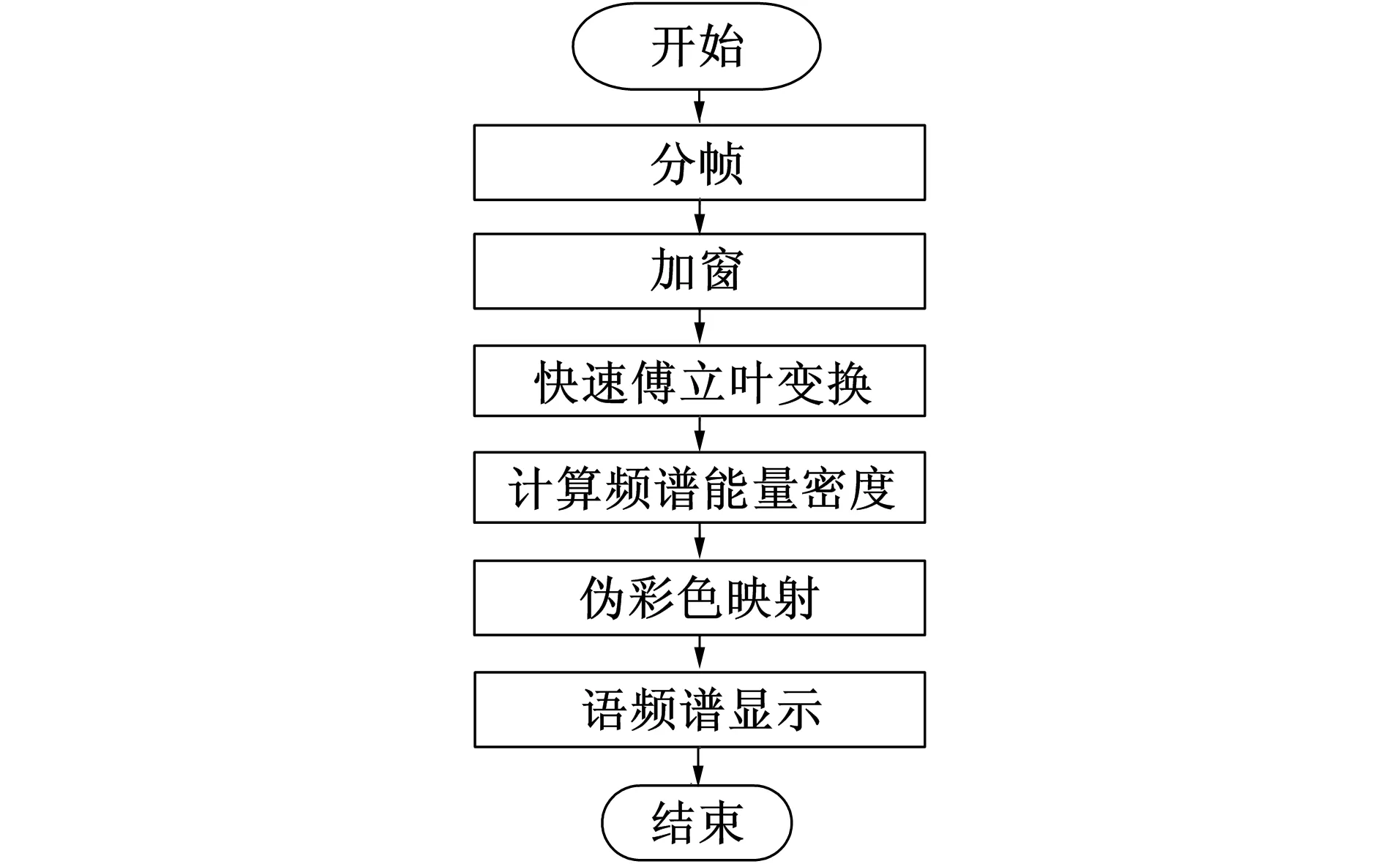
图3 语谱图提取流程图Fig.3 The flow chart of the extraction of spectrogram
语谱图提取流程如图3所示。该过程的具体算法及操作步骤:
1) 在Matlab中, 使用wavread函数读取待分析场景音频, 并将音频数据赋值给Sg, 将采样率赋值给Fs;
2) 设置窗长Nwin和帧移Nshift, 根据窗长及信号长度确定分帧数n, 考虑到后续步骤中FFT的使用,Nwin最好设置为2的幂次[15], 若128/256/512/1 024, 本实验中选取1 024, 取得了较好效果, 帧移的选择影响时域分辨率和计算量[16], 则帧移Nshift可设置为窗长的二分之一;
3) 生成一个空矩阵A, 矩阵大小为n(1/2Nwin+1);
4) 对音频信号Sg进行分帧处理, 假设Si为第i帧信号的数据;
5) 对Si进行加窗处理, 窗函数的选择参考前文1.2;
6) 对加窗后的数据进行快速傅里叶变换, 即FFT, 变换后的数据用Zi表示;
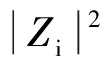
8) 将第i帧的频谱能量密度Pi数据赋值给矩阵A的第i列;
9) 滑动窗向右移动Nshift个采样点, 获得第i+1帧个音频信号数据Si+1, 重复步骤4)~8), 直到处理完所有分帧数据;
10) 将矩阵A映射为灰度图, 得到原始音频信号的语谱图。
2 场景音频语谱图的显示与分析
对本实验所需的场景音频数据, 可通过两种方式获取: 1) 使用麦克风及声卡自行收集; 2) 从网络上的开源数据库中获取所需音频数据。本次实验的场景音频通过网络数据库下载获得, 共11个场景, 具体场景如图4所示。

图4 收集到的11种场景音频Fig.4 The collected 11 scene audio
获得场景音频后, 通过Adobe Audition软件对音频进行剪辑, 音频长度均不超过30 s, 单声道, 采样率为44 100 Hz。
在对场景音频提取语谱图的过程中, 由于设置的窗长不同, 可将语谱图分为宽带语谱图和窄带语谱图两种。宽带语谱图的窗长较短, 时间分辨率好, 频率分辨率低, 不能反映出声音的纹理特性。窄带语谱图的窗长较长, 频率分辨率好, 但时间分辨率不理想。图5~图10分别给出篮球场、 海滩和高速公路3个场景的音频宽带语谱图和窄带语谱图。
由图5~图10可见, 每个对应点的值表示对应时间和频率上的频谱能量密度, 实际效果为频谱能量密度越大的点, 颜色越深。可以看出, 场景音频语谱图包含着丰富的纹理信息, 其中有与频率轴平行的竖直条纹, 由若干点组成的有规律的散沙状图案, 以及一些单独的没有特定规则的条纹。这些条纹及形状可以将其理解为场景音频中的声学事件在语谱图上的具体表现。
根据对图5、 图7和图9的观察可见, 宽带语谱图虽然时间方面的分辨率较强, 但无法将声学事件完整提取, 很难在语谱图上直观表现出场景音频的声学特性。而图6、 图8和图10等窄带语谱图则将场景音频中的声学事件完整的提取出来, 表达了声学事件具有的重复性、 连贯性以及趋势等。图6中的有规律的竖条纹为篮球拍击地面的声音, 若干个这样的声学事件组成了一个完整的篮球场场景音频。图8海滩场景语谱图则很好的将连贯的海浪声和比海浪声音略高频的海鸥叫声这两个声学事件完整提取。图10高速公路场景语谱图则完整的反映了高速路上车辆轰鸣声由远及近的声学事件。
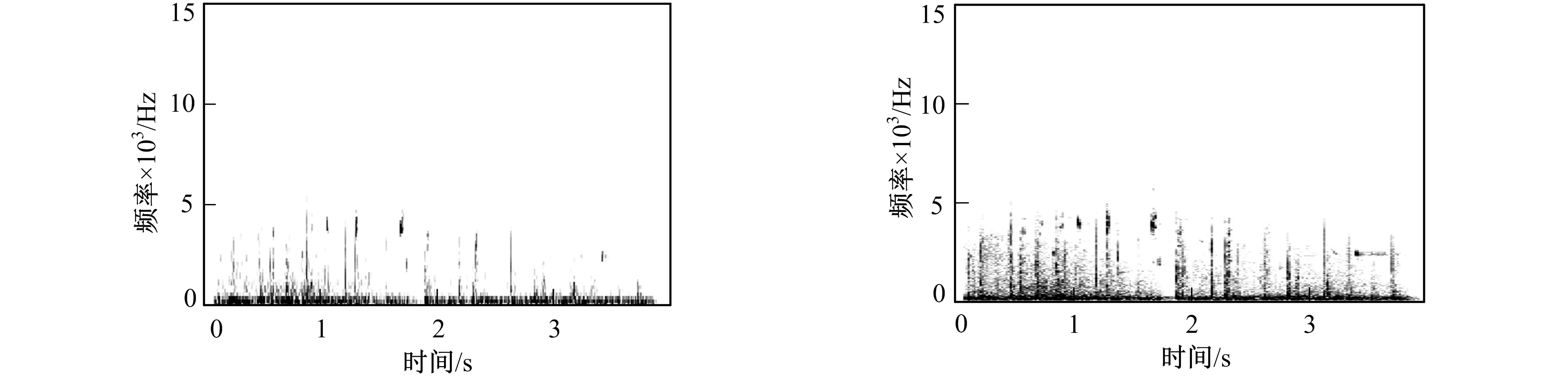
图5 篮球场场景音频宽带语谱图显示 图6 篮球场场景音频窄带语谱图显示 Fig.5 The basketball court scene audio wideband spectrogram display Fig.6 The basketball court scene audio narrowband spectrogram display

图7 海滩场景音频宽带语谱图显示 图8 海滩场景音频窄带语谱图显示 Fig.7 The beach scene audio wideband spectrogram display Fig.8 The beach scene audio narrowband spectrogram display
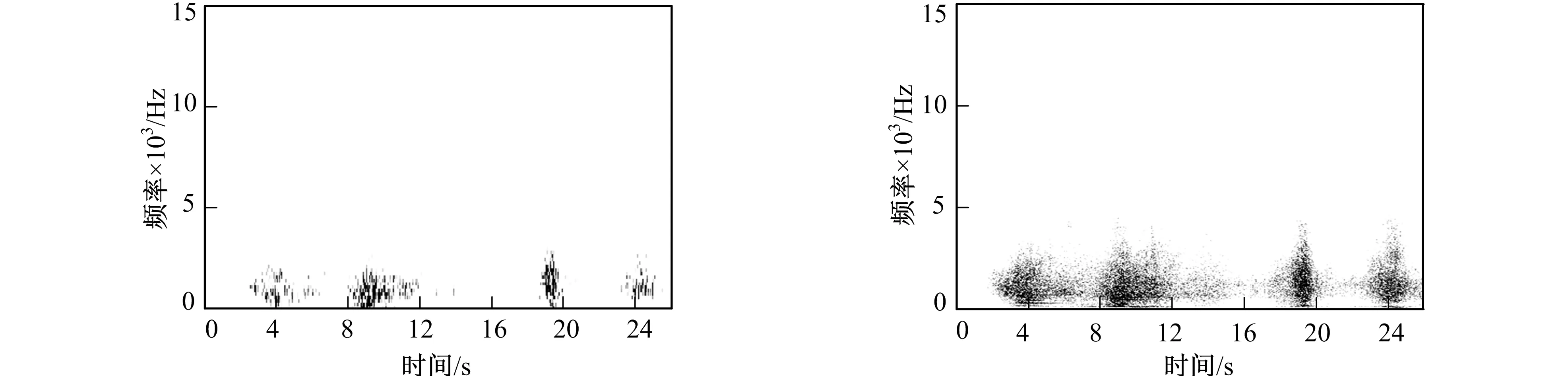
图9 高速公路场景音频宽带语谱图显示 图10 高速公路场景音频窄带语谱图显示 Fig.9 The highway scene audio wideband spectrogram display Fig.10 The highway scene audio narrowband spectrogram display
3 结 语
当前用于场景类音频的声学分析方式均存在不足, 使用时频域特征分析更加适合场景音频, 语谱图分析能够反映待分析信号的时频域特征。笔者提出了一种使用语谱图对场景音频进行分析的方法, 阐述了语谱图的产生机制以及提取语谱图的基本流程, 并给出具体算法。对操作过程中窗函数的选择、 提取过程中的注意事项进行了简要分析, 并给出参考性意见。最后对不同场景的音频进行语谱图提取, 分别得到其宽带语谱图及窄带语谱图, 并分析了窗长对于音频场景语谱图提取效果的影响, 得出了对于场景音频分析, 更适合使用窄带语谱图的结论。笔者的研究内容有助于完整提取待分析信号的声学特征, 加深对于场景音频分析和处理的研究, 可应用于场景音频的识别和分类, 具有一定的科学意义和参考价值。
参考文献:
[1]陈莹, 钟菲, 郭树旭, 等. 基于块对角结构的语音信号盲压缩重构 [J]. 吉林大学学报: 信息科学版, 2016, 34(4): 491-495.
CHEN Ying, ZHONG Fei, GUO Shuxu, et al. Blind Compressed Sensing Reconstruction of Speech Signal Based on Block Diagonal Structure [J]. Journal of Jilin University: Information Science Edition, 2016, 34(4): 491-495.
[2]王霏, 何东超, 李月. 陆地地震勘探环境噪声的混沌性建模研究 [J]. 吉林大学学报: 信息科学版, 2016, 34(3): 320-326.
WANG Fei, HE Dongchao, LI Yue. Modeling Study of Chaotic Ambient Noise in Land Seismic Exploration [J]. Journal of Jilin University: Information Science Edition, 2016, 34(3): 320-326.
[3]李姗, 徐珑婷. 基于语谱图提取瓶颈特征的情感识别算法研究 [J]. 计算机技术与发展, 2017, 27(5): 82-86.
LI Shan, XU Longting. Research on Emotion Recognition Algorithm Based on Spectrogram Feature Extraction of Bottleneck Feature [J]. Computer Technology and Development, 2017, 27(5): 82-86.
[4]尚永强, 殷未来, 姜双双, 等. 基于相位调制特征的语音活动检测 [J]. 吉林大学学报: 信息科学版, 2016, 34(1): 29-33.
SHANG Yongqiang, YIN Weilai, JIANG Shuangshuang, et al. Voice Activity Detection Based on Phase Modulation Feature [J]. Journal of Jilin University: Information Science Edition, 2016, 34(1): 29-33.
[5]王乃峰. 基于深层神经网络的音频特征提取及场景识别研究 [D]. 哈尔滨: 哈尔滨工业大学计算机科学与技术学院, 2015.
WANG Naifeng. Research on Audio Feature Extraction and Context Recognition Based on Deep Neural Networks [D]. Harbin: School of Computer Science and Technology, Harbin Institute of Technology, 2015.
[6]PEERAPOL KHUNARSAL, CHIDCHANOK LURSINSAP, THANAPANT RAICHAROEN. Very Short Time Environmental Sound Classification Based on Spectrogram Pattern Matching [J]. Information Sciences, 2013, 243: 57-74.
[7]蒋锦刚, 邵小云, 万海波, 等. 基于语谱图特征信息分割提取的声景观中鸟类生物多样性分析 [J]. 生态学报, 2016, 36(23): 7713-7723.
JIANG Jingang, SHAO Xiaoyun, WAN Haibo, et al. Bird diversity Research Using Audio Record Files and the Spectrogram Segmentation Method [J]. Acta Ecologica Sinica, 2016, 36(23): 7713-7723.
[8]郑党, 鲍鸿, 张晶. 基于小波语谱图分析的语音去噪技术 [J]. 计算机工程与应用, 2016, 52(4): 94-98.
ZHENG Dang, BAO Hong, ZHANG Jing. Speech De-Noising Technology Based on Wavelet-Speech Spectrogram [J]. Computer Engineering and Applications, 2016, 52(4): 94-98.
[9]THOMAS A LAMPERT, SIMON E M O’KEEFE. A Survey of Spectrogram Track Detection Algorithms [J]. Applied Acoustics, 2010, 71(2): 87-100.
[10]LI Jiarui, HONG Ying. Wheeze Detecting Method Based on Spectrogram Entropy Analysis [J]. Chinses Journal of Acoustics, 2016, 35(4): 508-515.
[11]李富强, 万红, 黄俊杰. 基于MATLAB的语谱图显示与分析 [J]. 微计算机信息, 2005, 21(20): 172-174.
LI Fuqiang, WAN Hong, HUANG Junjie. The Display and Analysis of Sonogram Based on MATLAB [J]. Microcomputer Information, 2005, 21(20): 172-174.
[12]崔璨, 袁英才. 窗函数在信号处理中的应用 [J]. 北京印刷学院学报, 2014, 22(4): 71-77.
CUI Can, YUAN Yingcai. Application of Window Function in Signal Processing [J]. Journal of Beijing Institute of Graphic Communication, 2014, 22(4): 71-77.
[13]毛青春, 徐分亮. 窗函数及其应用 [J]. 中国水运, 2007, 7(2): 230-232.
MAO Qingchun, XU Fenliang. The Window’s Function and it’s Application [J]. China Water Transport, 2007, 7(2): 230-232.
[14]王爱娟, 邢艳秋, 邱赛, 等. 基于窗函数的林区ICESat-GLAS波形数据消噪研究 [J]. 西北林学院学报, 2016, 31(1): 214-220.
WANG Aijuan, XING Yanqiu, QIU Sai, et al. Denoising of Forest ICESat-GLAS Waveform Data Based on Window Function [J]. Journal of Northwest Forestry University, 2016, 31(1): 214-220.
[15]杨春风. 基于语谱图的音频数字水印算法 [D]. 兰州: 西北师范大学数学与统计学院, 2009.
YANG Chunfeng. Audio Digital Watermarking Algorithm Based on Spectrogram [D]. Lanzhou: College of Mathematics and Statistics, Northwest Normal University, 2009.
[16]肖纯智, 孙大飞, 高勇. 一种基于语谱图分析的语音增强算法 [J]. 电声技术, 2012, 36(9): 44-48.
XIAO Chunzhi, SUN Dafei, GAO Yong. A Speech Enhancement Algorithm Based on Speech Spectrogram [J]. Audio Engineering, 2012, 36(9): 44-48.
