噪声数据下基于模型权重与随机子空间的集成学习
2015-01-16林培榕林耀进
林培榕, 林耀进
(闽南师范大学 计算机学院,福建 漳州 363000)
噪声数据下基于模型权重与随机子空间的集成学习
林培榕, 林耀进
(闽南师范大学 计算机学院,福建 漳州 363000)
针对训练集中类标号存在噪声的情况,提高分类模型的稳定性和分类精度是分类建模的目标。文章通过随机化邻域属性约简,生成多个邻域可分子空间,从而形成不同的基分类模型;通过基分类模型的预测结果及一致性原则学习基分类模型权重,降低了噪声对基分类模型权重学习的影响;最后利用模型权重融合基分类模型的分类结果获得测试样本的类别,并通过仿真实验验证该方法的有效性。
噪声数据;集成学习;邻域粗糙集;随机约简;模型权重
0 引 言
噪声数据对数据分析和知识发现有着明显的负向影响,许多学者在噪声数据上深入地研究各种挖掘方法[1-4]。噪声数据的挖掘方法主要分为带噪声的挖掘和去除噪声后再挖掘2种。带噪声的挖掘主要是指直接在噪声数据上构建更加鲁棒的挖掘方法。例如,文献[1]将噪声分为属性噪声和类噪声2种,对噪声在机器学习中的影响进行了系统的评价,同时研究了属性噪声与类噪声之间的关系、噪声在不同属性中的影响及相应的解决方案;文献[5]针对动态分类集成选择介绍了一类GMDH的数据处理方法,并在保证子分类器的精度和多样性基础上介绍了集成学习中分类器的动态选择策略;文献[6]在对样本分配一个类标号隶属度概率向量的基础上,在训练分类模型时将样本所属类标号的置信度作为权重以降低噪声的影响。去除噪声再挖掘方法主要是利用K近邻、ROC曲线等方法对噪声进行去除后再利用传统方法进行挖掘[4,7]。
集成学习在对测试样本进行分类时,通过把若干个单分类器集成起来,对多个分类器的分类结果进行某种组合来决定最终的分类,以取得比单个分类器更好的性能[8]。在集成学习中,子分类器的差异性[9]及分类器的权重学习[10]是影响集成学习效果的关键。文献[11]为了提高分类器的差异性和精度,提出了一种基于成对差异性度量的选择性集成方法;文献[12]采用特征选择方法得到一个有效的特征序列,进而将特征序列划分为几个区段并依据在各区段的采样比例进行随机采样,以此来改进子分类器性能和子分类器的多样性;文献[13]通过邻域粗糙集生成多个特征子空间,在不同空间中学习分类器,取得了良好的效果;文献[14]根据多分类器行为信息,产生待测样本局部分类精度的有效判定区域,提出适用于集成学习方法的权重自适应调整多分类器集成算法;文献[15]提出了一种线性加权投票的集成学习方法。
由于训练集中类标号存在噪声会对传统分类模型的学习能力有着巨大的干扰,而集成学习有着强大的泛化能力及稳定性,因此本文提出了一种基于随机子空间与模型权重的集成学习方法。首先在保证核属性基础上,通过随机化邻域约简,得到一组分类性能较强的邻域可分子空间,在每个子空间学习一个分类模型,由此得到一系列的子分类模型。其中,子分类模型的权重依赖于模型预测结果的一致程度,避免了训练集存在噪声对子分类模型权重学习产生的误差。实验结果表明,本文提出的方法分类性能优于或相当于其他相关的分类模型。
1 邻域粗糙集
粗糙集理论自1982年由Pawlak教授提出以来,得到了广泛的研究和发展。针对数值型与名义型并存的数据,文献[16]构建了基于邻域粒化的粗糙集模型。
给定决策表〈U,A,D〉,U={x1,x2,…,xM}为由样本构成的非空有限集,A={a1,a2,…,aN}为描述样本的属性集合,D为分类属性。
定义1 对于xi∈U,定义xi的邻域为δ(xi)={xj|xj∈U,Δ(xi,xj)≤δ},其中δ≥0,Δ为距离函数。
定义2 给定〈U,A,D〉,如果A生成一组论域上的邻域关系,则称〈U,A,D〉为邻域决策系统。

2 随机子空间与模型权重的集成学习
2.1 邻域随机子空间
在邻域粗糙集的前向贪心属性约简算法中,根据属性重要度的大小依次获得最重要的属性,直到增加任何属性,区分能力都不再增长,于是生成一个嵌套的特征子集序列:B1⊂B2⊂…⊂Bk。由于每次都是选择区分能力最大的特征,因此只能得到1个约简。给定一个决策表〈U,A,D〉,一般存在多个可以保持原始数据近似能力的属性子集。例如,文献[17]放宽贪心算法每一个都选最佳属性的要求,而采用随机区分能力最大的前F个特征的一个作为选中属性,然后通过多次运行算法得到多个具有区分能力的属性子集;文献[18]提出WADF方法来求得多个约简,通过随机删除非核属性中的一个属性,在删除后的属性子集上寻找新的约简,即可得到多个属性约简。
由于删除核属性会降低系统的逼近能力,而约简中的非核属性的区分能力可以由其他若干个属性来替代,因此本文融合文献[17-18]的优点,首先求得核属性,再随机选择核属性外重要度排前F个的任一属性,然后在所有剩余属性中进行属性约简,最后通过重复上面步骤得到多个具有区分能力的属性子集。此算法依据是在保证核属性不丢失的情况下,每个决策信息系统一般都存在多个保持原始数据近似能力的属性子集,不同的约简构成的特征空间蕴含的信息不同,具有相互补充的作用。另外,通过构建多属性约简的集成学习可提高系统泛化能力。
算法1 保持核属性下随机化属性约简算法。
输入:决策表〈U,A,D〉,参数δ、随机数F。
2.加强建设项目环境规划和环境影响评价,落实开发建设项目的管理工作,落实污染物排放总量控制工作,实施环境统计,各种污染因子的调查工作,从源头管理杜绝新的污染源的产生。
输出:约简red。
(1)计算核属性Core:Core→red。
(2)当ai∈A-red,计算属性ai的重要度Sig(ai,B,D)。
(3)选择属性ak,ak为属性集{A-red}中属性重要度前F中随机一个。
(4)若Sig(ak,B,D)>0,则red∪ak→red,回到步骤(2);否则,返回约简red。
算法1中约简本质上是一组保持原始数据近似刻画能力的特征子集。
2.2 模型权重
通过邻域粗糙集的随机化属性约简算法得到一组属性子空间集合后,在属性子空间集合{AR1,AR2,…,ARn}上分别构建基分类模型{C1,C2,…,Cn}。假设存在测试样本x,如果一个基分类模型对x类标号的预测比大多数基分类模型更加一致,说明该基分类模型对x类标号的预测将更加准确,也具有更大的权重,将其称为一致性原则。该原则充分体现了众数投票准则,即大多数相同的投票结果为最终结果。
通过分类模型之间的一致性来近似刻画分类模型的权重,可得:
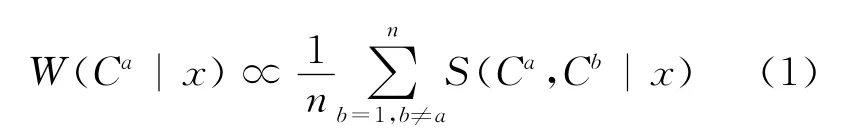
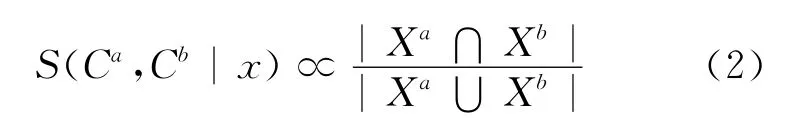
由于存在对测试样本类标号的正确预测只集中于少数几个分类模型的情况,所以S(Ca,Cb|x)反映的是Ca与Cb2个模型之间的局部一致性,并不能保证所有模型的全局一致性。因此,需增加一个平滑项使W(Ca|x)近似满足全局一致性,即

(3)式由模型一致项和平滑项组成,模型一致项反映了模型之间一致性程度,而平滑项反映对模型的无偏使用。其中,(3)式满足约束条件
2.3 集成学习模型
给定一个决策表〈U,A,D〉,条件属性集为{a1,a2,…,aN},利用2.1中的随机化属性约简算法得到一组属性子空间集合{AR1,AR2,…,ARn},通过在属性子空间集合{AR1,AR2,…,ARn}上分别构建多个子分类模型{C1,C2,…,Cn}。利用2.2中根据子分类模型与其他子分类模型的输出结果的一致程度高低原则得到每个子分类模型的权重,以加权投票的方式对测试样本的输出结果进行融合,得到测试样本的最终类标号。
3 实 验
为了验证本文方法的有效性,从UCI数据库中下载了4个数据集,分别为wdbc、heart、hepatitis及ICU,数据的描述信息见表1所列。

表1 数据集描述
对于集成学习方法,选择Cart和LSVM作为基分类模型。算法1中的邻域大小直接影响特征子空间的生成,本文中邻域设置为0.1,随机数设为100。另外,产生噪声的方法通过随机打乱样本的序号后,取前p%(p=10,20,30)个样本进行改变类标号。最后,采用十折交叉验证法进行验证。测试样本的类标号存在10%、20%和30%噪声比率的情况下4个数据集在不同分类方法下的分类精度见表2~表4所列。其中,分类方法Cart、LSVM、众数投票法及本文方法分别代表传统的Cart分类模型、LSVM分类模型、采用众数投票法的算法1及本文所提出的方法。
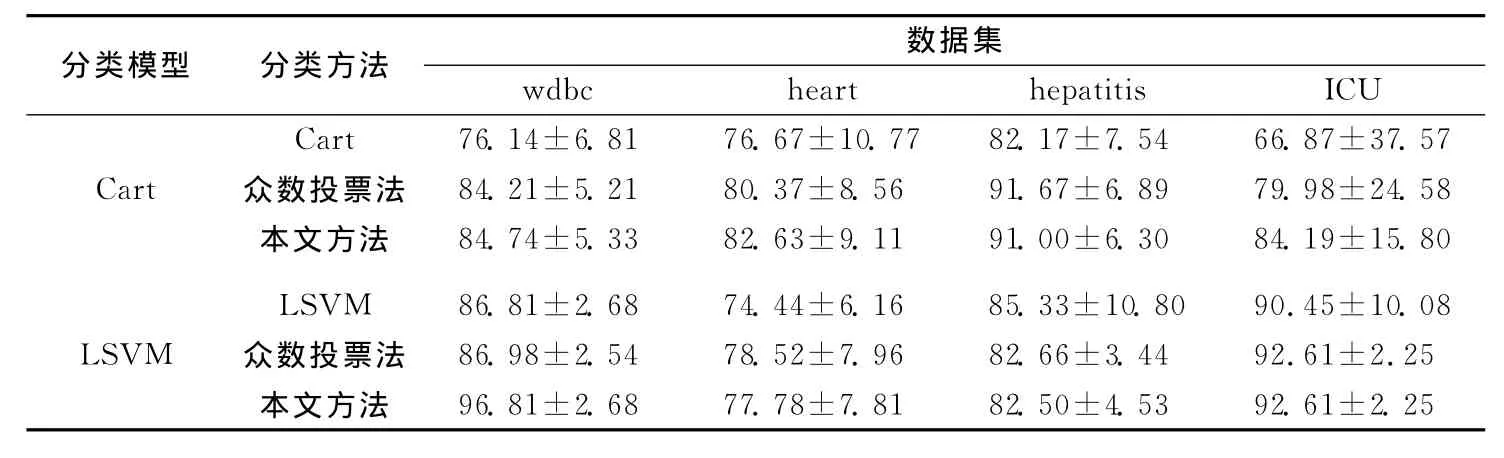
表2 噪声率10%下分类精度的比较

表3 噪声率20%下分类精度的比较

表4 噪声率30%下分类精度的比较
由表2~表4可以看出,针对类标号存在噪声的数据集,集成学习方法比传统的分类方法具有更强的泛化能力,而本文中考虑了模型权重的集成方法在大部分的实验上比传统的众数投票集成学习具有更强的分类性能。
4个数据集在2个基分类器上的分类精度随着噪声比率变化的情况如图1所示。从图1可以看出,随着噪声比率的增大,分类精度基本呈现降低趋势,与实际情况相符。相比于传统分类模型及众数投票法,本文方法的分类精度降低趋势比较缓慢,说明本文方法受噪声影响较低,具有较高的稳定性;对于ICU数据集,本文方法与众数投票法的分类精度基本没有下降,分析可知ICU是一个不平衡数据集,其1类、2类及3类的样本数比例为37∶1∶1,而噪声的生成方法很大程度上改变了数据的分布,影响了分类精度的变化。


图1 4种分类方法在不同噪声比率下的分类精度对比
在不同的噪声比率下,本文方法的分类精度比众数投票法及传统的Cart、Lsvm分类方法都高。
4 结束语
针对类标号存在噪声的情况,本文提出了一种基于随机子空间和模型权重的分类集成方法。该算法在不删除核属性下随机选择一组具有较高分类能力的特征子集,以此来提高子分类模型的性能且增强子分类模型的多样性;然后利用基分类模型预测结果的一致程度来学习不同分类模型的权重;最后通过加权融合集成学习获得对象的类别。实验结果表明,本文算法优于传统单个分类器的分类性能,且在多数情况下优于经典的众数投票集成方法。
[1]Zhu X Q,Wu X D.Class noise vs.attribute noise:a quantitative study[J].Artificial Intelligence Review,2004,22(3):177-210.
[2]Wu X D,Zhu X Q.Mining with noise knowledge:error-aware data mining[J].IEEE Transactions on Systems,Man and Cybernetics,Part A,2008,38(4):917-932.
[3]Zhu B,He C Z,Liatsis P.A robust missing value imputation method for noisy data[J].Applied Intelligence,2012,36(1):61-74.
[4]石鑫鑫,胡学钢,林耀进.融合互近邻和可信度的K-近邻分类算法[J].合肥工业大学学报:自然科学版,2014,37(9):1055-1058.
[5]Xiao J,He C Z,Jiang X Y,et al.A dynamic classifier ensemble selection approach for noise data[J].Information Sciences,2010,180(18):3402-3421.
[6]Rebbapragada U,Brodley C E.Class noise mitigation through instance weighting[C]//Machine Learning:ECML,2007:708-715.
[7]Catal C,Alan O,Balkan K.Class noise detection based on software metrics and ROC curves[J].Information Sciences,2011,181(21):4867-4877.
[8]Kittler J,Hatef M,Duin R P W,et al.On combining classifiers[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,1998,20(3):226-239.
[9]Zhou Z H,Yu Y.Ensembling local learners through multimodal perturbation[J].IEEE Transactions on Systems,Man and Cybernetics,Part B,2005,35(4):725-735.
[10]Kuncheva L I,Rodriguez J J.A weighted voting framework for classifiers ensembles[J].Knowledge and Information Systems,2014,38(2):259-275.
[11]杨长胜,陶 亮,曹振田,等.基于成对差异性度量的选择性集成方法[J].模式识别与人工智能,2010,23(4):565-570.
[12]杨 明,王 飞.一种基于局部随机子空间的分类集成算法[J].模式识别与人工智能,2012,25(4):595-603.
[13]Hu Q H,Yu D R,Xie Z X,et al.EROS:ensemble rough subspaces[J].Pattern Recognition,2007,40 (12):3728-3739.
[14]方 敏.集成学习的多分类器动态融合方法研究[J].系统工程与电子技术,2006,28(11):1759-1761,1769.
[15]Fumera G,Roli F.A theoretical and experimental analysis of linear combiners for multiple classifier systems [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2005,27(6):942-956.
[16]Hu Q H,Yu D R,Xie Z X.Neighborhood classifiers[J].Expert Systems with Applications,2008,34 (2):866-876.
[17]朱鹏飞,胡清华,于达仁.基于随机化属性选择和邻域覆盖约简的集成学习[J].电子学报,2012,40(2):273-278.
[18]Wu Q X,Bell D,McGinnity M.Multiknowledge for decision making[J].Knowledge and Information Systems,2005,7(2):246-266.
Ensemble learning based on model weight and random subspace in noise data
LIN Pei-rong, LIN Yao-jin
(School of Computer Science and Engineering,Minnan Normal University,Zhangzhou 363000,China)
In view of the class label noise in training dataset,the objective of classification modeling is to improve the stability and classification accuracy of classification model.In this paper,a set of neighborhood separable subspaces is generated based on randomized neighborhood attribute reduction,in which a set of base classification models is obtained.The weight of base classification model is studied by the prediction of base classification model and consensus principle,which decreases the impact of noise data on the weight study of base classification model.Finally,the classification result is gotten by combing the classification decision of different base classification models using model weight,and the experimental results show the validity of the method.
noise data;ensemble learning;neighborhood rough set;randomized reduction;model weight
TP181
A
1003-5060(2015)02-0186-06
10.3969/j.issn.1003-5060.2015.02.010
2013-10-25;
2014-10-08
国家自然科学基金资助项目(61303131;61379021);福建省自然科学基金资助项目(2013J01028)和漳州市科技计划资助项目(ZZ2013J04)
林培榕(1966-),男,福建平和人,闽南师范大学教授,硕士生导师.
(责任编辑 胡亚敏)
