一种基于类别分布的增量特征选择算法
2014-08-16孙慧慧
石 莉,李 敏,孙慧慧
淮北师范大学计算机科学与技术学院,安徽淮北,235000
一种基于类别分布的增量特征选择算法
石 莉,李 敏,孙慧慧
淮北师范大学计算机科学与技术学院,安徽淮北,235000
样本数量分布不平衡时,特征的分布同样会不平衡。大类别中经常出现的特征,在小类别中很少出现或者根本不出现,使得分类器被大类别所淹没,小类别的识别率很低。为此,根据数据的类别分布提出一种基于差异系数的增量特征选择算法CVIFS(Coefficient Variance-based Incremental Feature Selection),选取最具有区分能力的特征,提高小类别的识别率,使用区间估计检测概念漂移。经实验验证,该算法处理偏斜数据流时优于信息增益,具有较低的均衡误差率(Balanced Error Rate BER)。
概念漂移;偏斜分布;差异系数;信息增益
数据流中的概念漂移以及偏斜分布,使其样本无法准确反映整个空间的数据分布,分类器容易被大类别淹没而忽略小类。针对偏斜分布,目前主要采取抽样、单类别学习和特征选择的方法来处理[1]。数据的高维性会使偏斜分布问题更为严重,因此特征选择相对分类算法更重要[2]。
根据不平衡分类问题的特点,选择对小类别有较好指示作用的特征是提高小类别分类性能的关键,所以选择有丰富类别信息的特征是解决非均衡问题的一条有效的途径。本文提出一种不依赖于其他方法的特征选择方法,称为基于差异系数的增量特征选择算法(CVIFS)。该方法根据特征的类别分布,选择在类间分布差异较大的特征,并结合增量学习来处理概念漂移问题。
移动超平面数据上的实验表明,处理偏斜数据流时优于信息增益,CVIFS具有较低的均衡误差率(Balanced Error Rate BER)。
1 相关工作
传统的特征选择方法在均衡数据上效果很好,但在非均衡数据上效果并不理想[3-4]。因为这些方法一般倾向于高频词,导致非平衡问题中的小类别被大类别所淹没。信息增益(IG)和卡方统计量(CHI)是传统的特征选择算法中效果最好的度量指标[5]。近年来,很多学者对不均衡问题的特征选择进行了深入研究。Zheng等人提出显式的近似最优组合正特征(指示文档属于某类别的特征)和负特征(指示文档不属于某类别的特征)[6-7]能够提高特征选择在非平衡数据上的效果,但是这种框架依赖于其他方法,只有当所依据的方法能够很好地选择正负特征时,此方法才是有效的。Chen首次提出基于ROC曲线的FAST(Feature Selection Assessment by Sliding Thresholds)特征选择方法[8],采用滑动阈值机制进行特征选择,在偏斜小样本数据集上能够取得较好的效果;但样本较大时,阈值设置会遇到麻烦,不适用于数据流上的特征选择。靖红芳等人依据特征在类间的分布特点,提出了基于类别分布的特征选择框架[9],采用类间方差区分属性;然而,不同特征间的水平差异较大,需要区别对待,类间方差不能兼顾这一点。Wang等人采用一个探索评价函数选择一定数量的特征[10],选择那些特征与目标类之间的相关性高而特征相互之间的关联性低的特征;然而,他们同样没有注意到不同特征间的水平差异。刘智等人依据特征的重要程度,提出基于W分布和D分布的动态特征选择方法[11],然而计算开销过大。
2 信息增益(IG)
信息增益是按照能“最佳分类”的特征A进行划分,该特征使得完成元组分类所需的平均信息量最小。信息增益作为特征选择的度量,选择信息增益值最大的那些特征。对于数据集D,特征A的信息增益定义如下:
Gain(A)=Info(D)-InfoA(D)
(1)
(2)
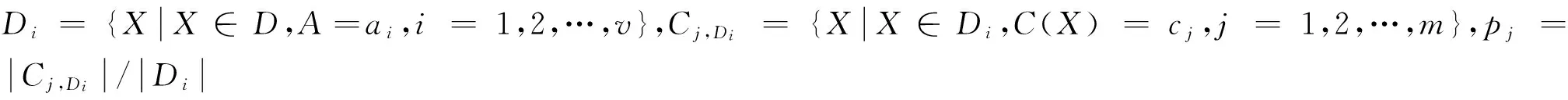
从信息增益的定义及描述可以看出,信息增益没有重视小类别的重要性,因此不适合作为偏斜分布的数据流分类中的特征选择度量。
3 基于差异系数的增量特征选择算法(CVIFS)
当数据流逐步流入时,到来的数据被分成数据段S1,S2,…,Sn,…,对于每个数据段Sk,仅有少量的正实例,绝大部分为负实例。其中,Sn是最近时间步到来的数据段。数据段Sn中的每个实例X={A1,A2,…,An;C},其中Ai为X的特征,假设其值为el,l=1,2,…,v, 类变量C=+1或-1。
θP={X∈Sn,C(X)=+1};
θN={X∈Sn,C(X)=-1};
Sn1={X∈Sn,Ai=ei};
θP1={X∈Sn1,C(X)=+1};
θN1={X∈Snl,C(X)=-1}。
3.1 差异系数
差异系数CV常用于同一总体中的不同样本的离散程度的比较。对于水平相差较大,则是对同一种测量的不同样本,进行观测值离散程度的比较。差异系数大时,表明分散程度大,反之,分散程度小。在没有概念漂移的情况下,对数据块Sn中实例的差异系数为:
(3)
其中,SAi、MAi分别为关于特征Ai的标准差和平均值。

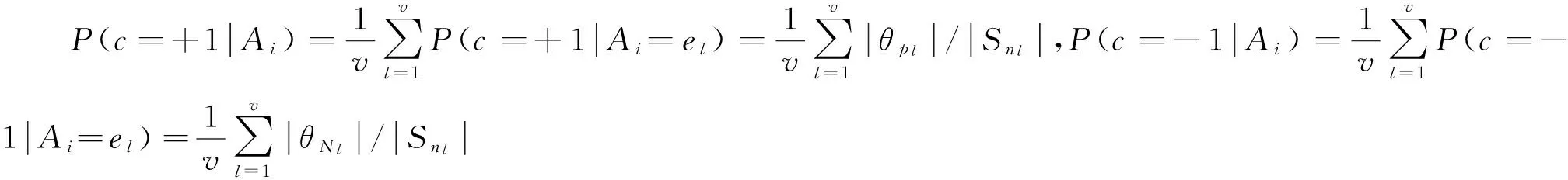
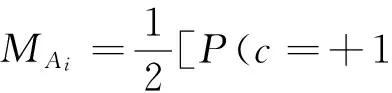
(4)
(5)
(6)
利用差异系数公式计算出每个特征的CV(Ai,C)之后,选择值最高的z个特征。
3.2 概念漂移发现
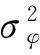
(7)
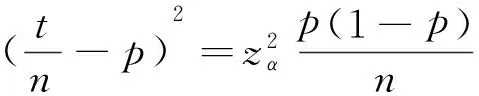
(8)
(9)
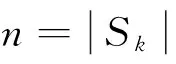
增量特征选择算法具体描述如下:
输入:偏斜数据流S1,S2,…,Sk,…;特征个数z;
输出:特征子集Fs;
1.Fs←∅;t=0
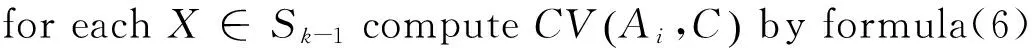
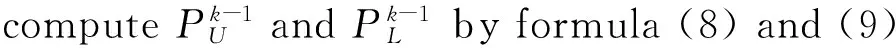
3.Fs←Ranker(CV(Ai,C),z)
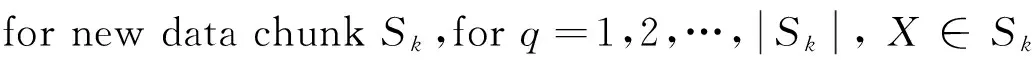
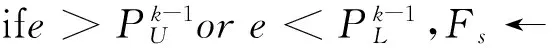
6.returnFs
算法1:基于差异系数的增量特征选择算法(CVIFS)
4 实验及实验结果
为了验证CVIFS对概念漂移的适应性及其在不同偏斜率情况下的分类效果,在移动超平面数据集上与基于信息增益进行了比较。实验所采用的分类器为NaiveBayes(NB),评价函数为均衡误差率(BER)。
4.1 移动超平面数据集
4.2 评价函数
在一般情况下,研究者采用全体实例的分类精度来评价分类器的分类性能。由于偏斜数据的分布特点,精度不能很好地反映分类器的分类情况。理想的分类算法不仅能在小类别上取得好的结果,而且在大类别上也能取得好的结果。这就需要一个能够兼顾二者的评价指标。均衡误差率(Balanced Error Rate BER)常用来衡量不均衡数据的分类[8]。均衡误差率是两个类的错误率的平均值,由下式给出:
(10)
其中FP(true positives)指分类器正确标记的正实例,FN(true negatives)是分类器正确标记的负实例。FP(false positives)是错误标记的负实例,FN(false negatives)是错误标记的正实例。
4.3 实验结果
下面给出当数据流中数据段的大小为1 600,特征个数为50,偏斜率r=1%,5%,10%,15%时的实验结果,偏斜率即为正实例所占的比例。当数据流中的数据段为2 000,3 000,4 000时得到了相似的结果。
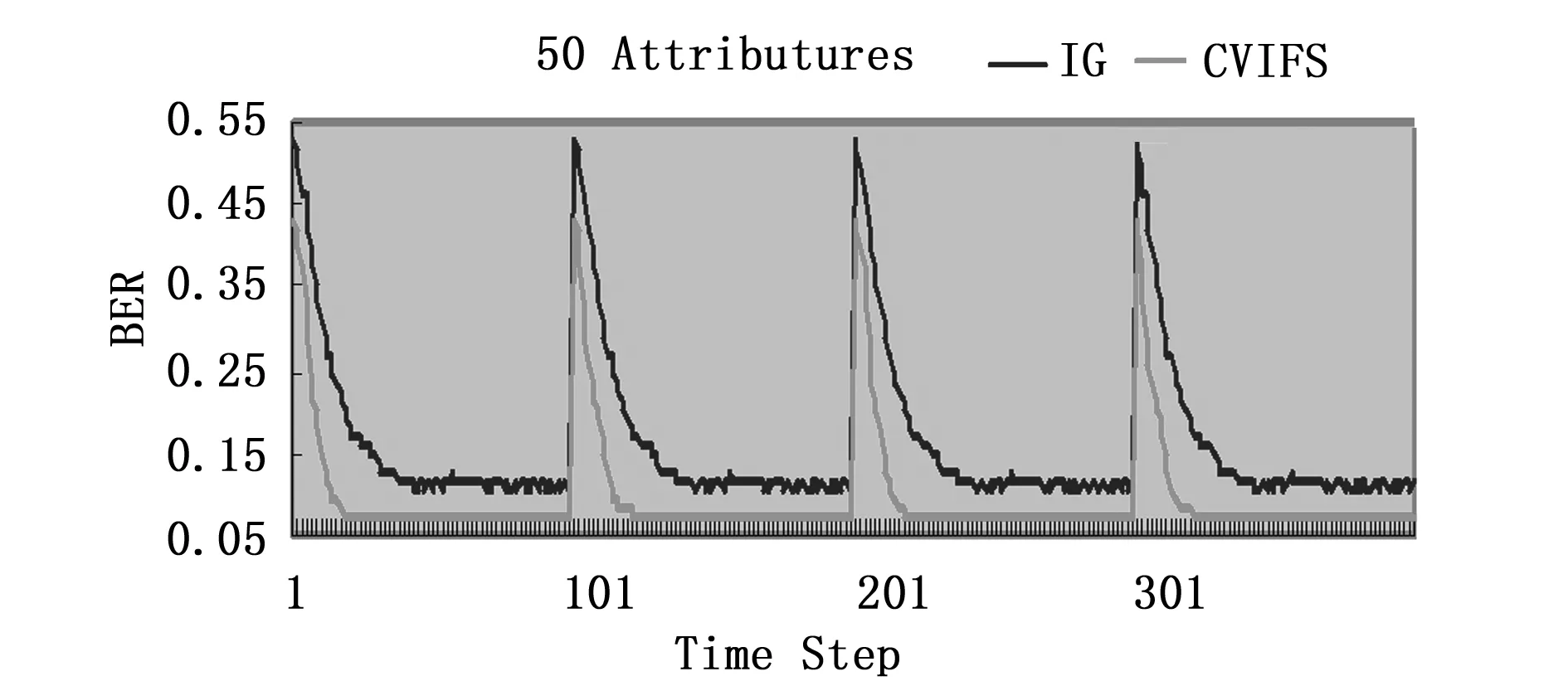
图1 r=1%时两种算法在超平面数据集上的比较
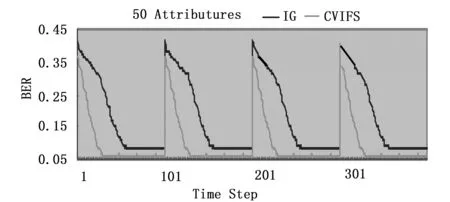
图2 r=5%时两种算法在超平面数据集上的比较
图1是在超平面数据集上,将基于CV的增量特征选择算法与基于IG的增量特征选择算法所预测的均衡误差率的比较。其中,横坐标是时间步,纵坐标是在检测集合上的均衡误差率。实验中,偏斜率r=1%,从图1中可以看出,基于CV的特征选择算法的均衡误差率明显低于基于IG的特征选择算法。遇到概念漂移时,基于CV的增量特征选择算法也能很快地收敛到目标概念。
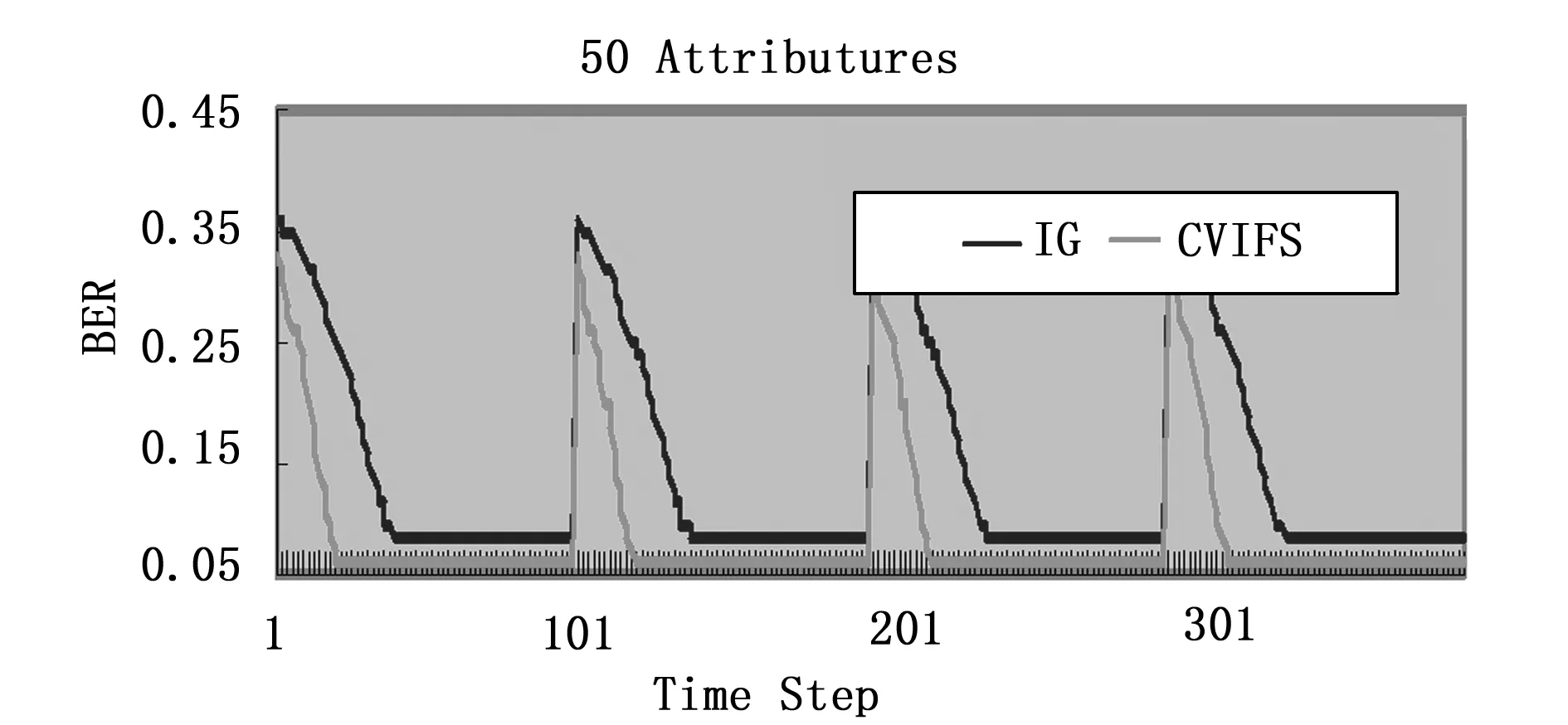
图3 r=10%时两种算法在超平面数据集上的比较
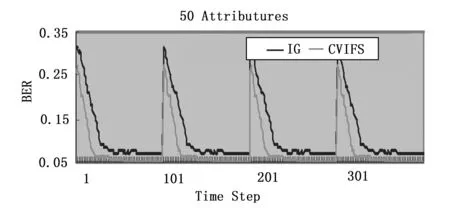
图4 r=15%时两种算法在超平面数据集上的比较
图2、图3、图4分别是在偏斜率r为5%,10%,15%时的两种算法在超平面数据集上的比较。从图中可以看出,随着偏斜率的升高,基于信息增益的增量特征选择算法的均衡误差率有一定的下降,但遇到概念漂移时还是不能很快地适应概念漂移。基于差异系数的增量特征选择算法不但能够保持较低的均衡误差率,而且能够很快地适应概念漂移。在移动超平面数据集上的实验表明,当偏斜率下降时,基于信息增益的增量特征选择算法的误差率很高,且不能很好地处理概念漂移。这与信息增益选择的属性是平均信息量高有关。基于类别分布的差异系数增量特征选择不但能够保持较低的均衡误差率,而且能够很快地适应概念漂移。这是因为差异系数选择的是类间分布差异较大的特征,也就是类别指示性强的那些特征。
5 结束语
本文给出的基于类别分布的差异系数增量特征选择算法,并用区间估计检测概念漂移。移动超平面数据集上的实验结果表明,在处理偏斜数据流时,优于信息增益。但是,目前的特征选择函数性能的评估均是通过试验验证的方法,即完全基于经验的方法。因此进一步的理论分析非常重要。而且,目前讨论的是二类偏斜数据流问题,多分类的偏斜数据流特征选择问题也有待进一步研究。
[1]NiteshV.Chawla,NathalieJapkowicz,AleksanderKolcz.Editorial:SpecialIssueonLearningfromImbalancedDataSets[J].ACMSIGKDDExplorationnewsletter,2004,6(1):1-6
[2]FormanG.Anextensiveempiricalstudyoffeatureselectionmetricsfortestclassification[J].JournalofMachineLearningResearch,2003(3):1289-1305
[3]MladenicD,GrobelnikM.FeatureselectionforunbalancedclassdistributionandNoveBayes[C]//ProceedingsofsixteenthInternationalConferenceonMachineLearning(ICML1999).BledSlovenia,1999:258-267
[5]YangY,PedersenJO.AComparativeStudyonFeatureSelectioninTextCategorization[C]//ProceedingsofthefourteenthInternationalConferenceonMachineLearning(ICML1997).MashvilleTennesseeUSA,1997:412-420
[6]ZhengZ,WuX,SrihariR.FeatureSelectionforTextCategorizationonImbalancedData[J].ACMSIGKDDExplorationsnewsletter,2004(1):80-89
[7]ZhengZ,SrihariR.OptimallyCombiningPositiveandNegativeFeaturesforTextCategorization[C]//ProceedingsoftheICML’03WorkshoponLearningfromImbalancedDataSets.WashingtonDCUSA,2003:1-8
[8]ChenX,MichaelWasikowski.FAST:AROC-basedFeatureSelectionMetricforSmallSamplesandImbalancedDataClassificationProblems[C]//KDD’08.NevadaUSA,2008:124-132
[9]靖红芳,王斌,杨雅辉.基于类别分布的特征选择框架[J].计算机研究与发展,2009(9):1586-1593
[10]WangK,BunjiraMakond,WangK.AnImprovedSurvivabilityPrognosisofBreastCancerbyUsingSamplingandFeatureSelectionTechniquetoSolveImbalancedPatientClassificationData[J].BMCMedicalInformaticsandDecisionMaking,2013:1-14
[11]刘智,杨宗凯.采用动态特征选择的中文情感识别研究[J].小型微型计算机系统,2014,35(2):358-364
[12]王勇.WEB数据挖掘研究[D].西安:西北工业大学研究生院,2006:42-43
[13]YueX,MoH,ChiZ.Immune-inspiredincrementalfeatureselectiontechnologytodatastreams[J].AppliedsoftComputing.2008,8(2):1041-1049
(责任编辑:汪材印)
An Algorithm of Incremental Feature Selection Based on Category Distribution
SHI LI,LI Ming,SUN Hui-hui
School of Computer Science and Tecknnology,Huaibei Normal University,Huaibei Anhui,235000,China
The distribution of sample size is very uneven, and the feature distribution of sample will be uneven too. Classifier is submerged by the majority classes easily and the minority classes are hardly distinguished, because the features which often appear in the majority classes hardly appear in the minority classes or even do not occur. In this paper, the method for discovering concept drifting on imbalanced data streams and CVIFS(Coefficient Variance-based Incremental Feature Selection) algorithm are proposed according to the characteristics of imbalanced classification problems. The interval estimation is used to detect concept drifting. Experimental study on Moving Hyperplane dataset shows that the proposed algorithm has lower BER(Balanced Error Rate)than Information Gain on imbalanced data streams with concept drifting.
concept drifting;imbalanced distribution;coefficient variance;information gain
10.3969/j.issn.1673-2006.2014.11.022
2014-07-28
安徽省高校自然科学研究项目“云计算环境下信息服务交互信任管理的关键问题研究”(KJ2013Z281);淮北师范大学青年科研项目“基于类别分布的增量特征选择算法研究”(2014xq012);淮北师范大学青年自然科学研究项目“面向云服务的交互信任模型构建与信任实体评价研究”(700693)。
石莉(1978-),女,安徽淮北人,博士,讲师,主要研究方向:评价方法与应用,算法理论。
TP181
A
1673-2006(2014)11-0075-04
