基于特征子集的推荐系统托攻击无监督检测
2014-08-05曾学文邓浩江
彭 飞,曾学文,邓浩江,刘 磊
(1. 中国科学院大学,北京 100 190;2. 中国科学院声学研究所国家网络新媒体工程技术研究中心,北京 10019 0)
基于特征子集的推荐系统托攻击无监督检测
彭 飞1,2,曾学文2,邓浩江2,刘 磊2
(1. 中国科学院大学,北京 100 190;2. 中国科学院声学研究所国家网络新媒体工程技术研究中心,北京 10019 0)
针对现有基于协同过滤的推荐系统易受托攻击影响的问题,提出一种基于特征子集的推荐系统托攻击无监督检测算法。利用现有攻击模型在项目选择上的随机性,给出一种描述用户兴趣集中程度的特征属性:兴趣峰度系数。将该系数与已有的推荐系统用户特征属性结合作为备选特征集,采用无监督特征选择方法为不同类型托攻击选取相应的检测特征子集。根据选择出的特征子集计算每个用户的离群度,以此进行排序并确定攻击目标,在已排序的用户序列上设置滑动窗口,通过计算窗口内攻击目标的平均评分偏移值对攻击用户进行过滤。实验结果证明,兴趣峰度系数的信息增益高于已有的特征属性,基于特征子集的无监督检测算法相比于现有的无监督检测方法具有更高的稳定性和精准度。
推荐系统;托攻击;无监督检测;特征子集;峰度系数;滑动窗口
1 概述
随着互联网和信息技术的发展,人们逐步进入信息过载的时代。如何从海量数据中提取出用户感兴趣的内容、克服信息不对称是目前亟需解决的问题。推荐系统一方面帮助普通用户发现感兴趣的内容,另一方面帮助内容提供者将信息推送到对它感兴趣的用户面前,从而实现信息生产者和消费者的双赢。然而,目前主流的基于协同过滤的推荐方式极易受到托攻击[1]的影响。通过伪造用户概貌模型,托攻击者可以增加或减少目标对象的推荐频率。例如,在电子商务推荐系统中,某些生产商或店主通过向系统注入虚假用户评价,增加自己商品的推荐频度,减少竞争对手商品被推荐的可能性,从而提升自己的收益。如何防范和检测托攻击、提升推荐系统的健壮性和稳定性成为近年来推荐系统领域的一个研究热点[2]。
为解决基于协同过滤的推荐系统易受托攻击影响的问题,本文一方面利用现有攻击模型在项目选择上的随机性,提出一种描述用户兴趣集中程度的特征属性:兴趣峰度系数(Kurtosis Coefficient of Interest, KCI);另一方面,利用无监督特征选择方法,为不同攻击模型选取针对性的检测指标,并基于选择出的指标,设计一种基于特征子集的无监督检测算法,针对不同的攻击策略选择相应的特征子集,以此对攻击用户进行过滤。
2 研究背景
协同过滤推荐的准确性有赖于大量用户的参与,因而推荐系统无法过度限制用户的操作。攻击者能以极低的代价向系统中恶意注入虚假概貌,这些概貌的构建方式可使系统中大量用户的兴趣与攻击者相近,少量的攻击概貌就能有效操纵推荐结果[2]。托攻击有2个目的:提高目标项的评价,称为推攻击;降低目标项的评价,称为核攻击[3]。下文首先对推荐系统托攻击中的相关定义[4]进行解释,然后对国内外研究现状进行介绍。
2.1 相关定义
定义1(攻击概貌) 假定集合I包含系统中所有的项目,集合U包含所有的用户。一个攻击概貌[2]由目标项目it∈I、选择项目集合IS⊂I、填充项目集合IF⊂I和未评分的项目集合Iφ4个部分组成。根据不同的攻击模型,函数δ,σ和γ分别设定IS,IF及it的评分值。图1给出了一个攻击概貌的一般形式。
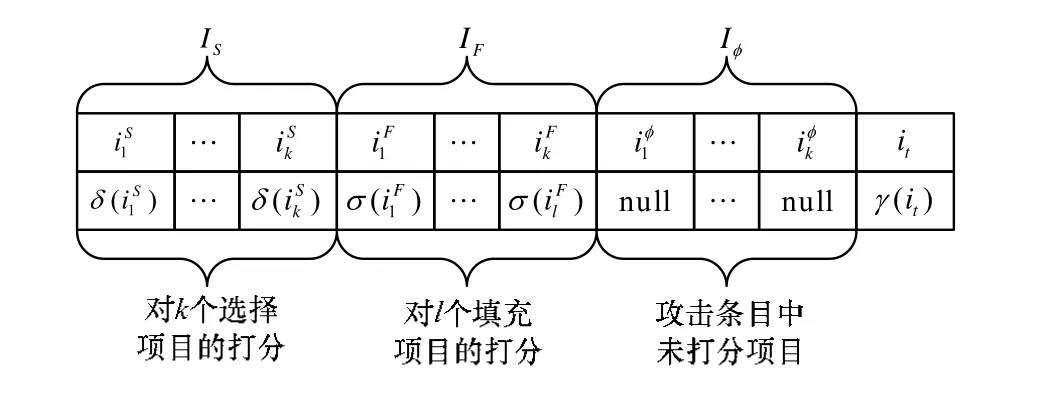
图1 攻击概貌的一般形式
定义2(攻击规模) 攻击规模是指向系统中注入的攻击概貌的数目与系统中用户概貌总数的比值。
定义3(填充规模) 填充规模是指在一个攻击概貌中,被评分的项目数目与系统中项目总数的比值。
定义4(攻击模型) 攻击模型是一个四元组:

(1)随机攻击:该方法对目标项目评最高分,对填充项目按与系统平均分、方差相等的高斯分布随机评分;
(2)平均攻击:该方法对目标项目评最高分,对填充项目取其系统平均分;
(3)流行攻击:该方法对目标项目评最高分,对选择出的流行项目取其系统平均分,对填充项目按与系统平均分、方差相等的高斯分布随机评分。
通常使用攻击规模和填充规模来确定攻击的强度,不同攻击规模、填充规模、攻击模型对系统会产生不同的影响[5]。
2.2 国内外研究现状
针对推荐系统托攻击的研究主要包括攻击检测以及鲁棒性推荐算法两方面,本文主要对托攻击的检测算法进行分析,托攻击的检测算法主要有基于监督学习和基于无监督学习2种思路。
早期的工作大都集中于有监督检测算法。文献[6]提出了基于用户概貌统计特征的方法,通过提取正常用户概貌与攻击概貌的特征属性,利用特征值之间的差异检测攻击概貌。文献[7]对攻击概貌的统计特征进行分析,设计了更多更有效的特征属性提取方法。文献[8]则提出了基于特征选择的检测方法,进一步提高了有监督检测算法的精准度。
鉴于有监督检测算法固有的局限性,目前的研究更多集中于无监督检测算法。文献[9]利用奈曼-皮尔逊准则来检测托攻击,并分别提出监督学习算法和无监督学习算法。文献[10]提出了PLSA(Probabilistic Latent Semantic Analysis)检测算法与PCA VarSelect(Variable-selection using Principal Component Analysis)检测算法[11]。PLSA算法利用攻击用户间极端相似的特点对其进行聚类识别。PCA VarSelect算法对评分矩阵做主成分分析,并以每个用户对应的前1至3个主成分系数的大小作为攻击检测的指标。文献[12]通过计算Hv-score值来寻找攻击概貌,并以此设计了UnRAP(Unsupervised Retrival of Attack Profiles)算法。
此外,文献[13]提出了基于信任的不实评价过滤方法,利用用户的声誉以及用户间的信任程度来减轻攻击用户对系统的影响。文献[14]在特征选择的基础上,对朴素贝叶斯分类器进行扩展,设计了能够应对混合攻击的半监督检测方法。
通过对上述研究分析可以发现,现有的无监督算法都只依赖于某一固定特征,并以此作为攻击概貌检测的指标,这种单一的检测标准在面对不同攻击场景时,很难保证精准度,并且随着新的攻击策略的出现,现有的无监督检测方法也都难以进行调整和应对。为此,下文将提出兴趣峰度系数(KCI)和基于特征子集的无监督检测方法。
3 兴趣峰度系数
现有的托攻击检测特征属性都是用于衡量攻击用户评分的异常程度,而本文提出的KCI还可以对攻击用户在项目选择上的异常信息进行提取。系统中每个项目都具有一些主题关键词来标识该项目的特征,用户对项目的选择在一定程度上反映了自己的兴趣取向。以MovieLens数据集(http://grouplens.com)为例,每个电影都包含几个反映电影类型的关键词,如cartoon、music、comedy、action等,用户对电影的选择反映了用户对相应电影类型的偏好,例如,儿童会更多地选择cartoon类型的电影,而年轻人则更可能选择action类型的电影。因此,一个正常的用户在选择电影时会体现出自身对某些特定类型电影的喜好。然而,在现有攻击策略下,一个托攻击用户在选取填充项目时,是随机选择的,没有考虑到用户对某些电影类型的关注。
为此,本文提出一种描述用户兴趣集中程度的特征属性:兴趣峰度系数(KCI)。下文以MovieLens数据集为例,描述该属性的计算方法。
矩阵A表示用户的观影记录,是一个m× n大小的矩阵(m表示用户数,n表示电影数),矩阵各项的取值定义如式(1)所示,其中,Rui表示用户u对电影i的评分,下同。
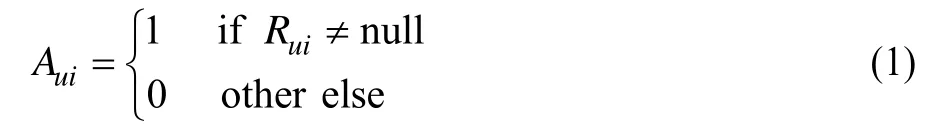
矩阵M表示电影的类型信息,是一个n× l大小的矩阵(l表示电影类型的数目),矩阵各项的取值定义如式(2)所示。
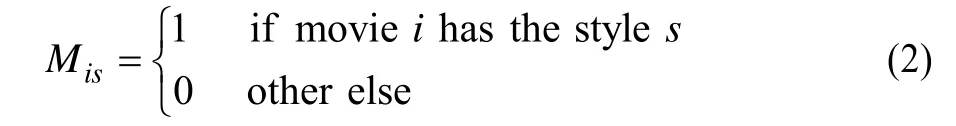
利用上述2个矩阵可以得到用户对各种电影类型的偏好矩阵T,T的计算方法如式(3)所示,T中的矩阵元素Tus表示了用户u观看类型s的电影次数。

进一步地,采用数理统计中的峰度系数来评估用户对各类电影兴趣分布的集中程度。公式如下:
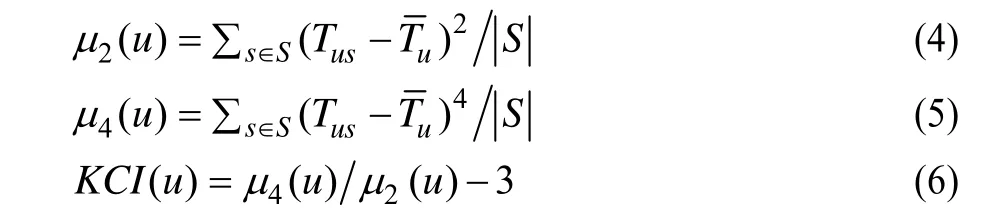
对MovieLens 100K数据集进行攻击规模为5%、填充规模为10%的随机攻击时,攻击用户与真实用户概貌的KCI分布如图2所示,KCI值已经过归一化处理。图中横轴0表示真实用户,1表示攻击用户。
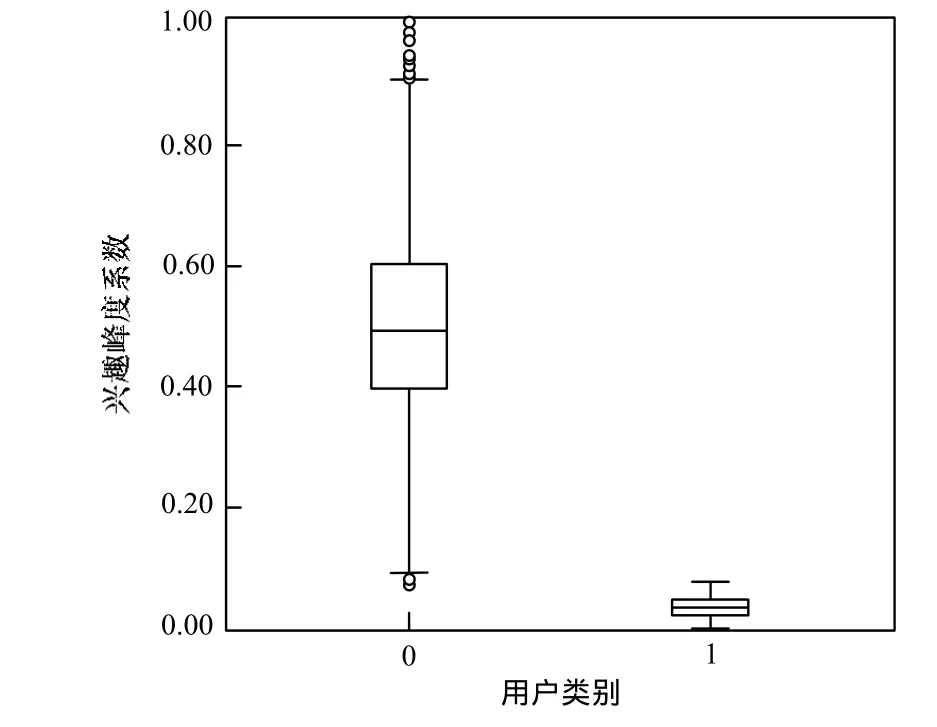
图2 兴趣峰度系数分布对比
可以看出,真实用户的KCI取值集中于0.4~0.6之间,而攻击用户KCI取值趋近于0,以此作为分类属性,对攻击用户具有较好的辨识度。
4 基于特征子集的无监督检测算法
在上节介绍的兴趣峰度系数基础上,本文引用文献[7]中定义的10个指标,包括RDMA、WDMA、WDA、Degsim、LengthVar、FMV、FMD、PV、FMTD、TMF以及文献[12]提出的Hv-score。
本文2.1节介绍了一些主流的攻击手段,随着推荐系统的日益成熟,新的攻击手段也将逐渐涌现。直接利用上述所有的特征属性进行托攻击检测会有如下问题:有些特征是冗余的甚至是不相关的,冗余特征的存在会降低学习算法的效率,而不相关特征(噪音特征)的存在会有损学习算法的性能。因此,在进行无监督检测之前,有必要对数据进行预处理以去除冗余特征和噪音,即进行无监督特征选择。特征选择的目标可认为是从原始特征子集中选取包含全部或绝大部分信息的特征子集。由于被丢弃的特征几乎是无信息量的,因此学习算法的性能将会很少降低,甚至由于去掉带有干扰信息的特征而导致算法性能提高。
为此,本文利用无监督特征选择方法,针对不同攻击策略,筛选出对于当前场景下最有效的特征子集,选择方法遵循“最小冗余-最大相关”标准[15],无监督特征选择方法本身不是本文讨论的重点,在文献[16]中有详细描述。
在无监督特征选择的基础上,本文提出一种基于特征子集的推荐系统托攻击无监督检测算法UnDSA-FS,具体步骤如下:
步骤1为每个用户计算特征子集中各特征值
针对不同的攻击策略选择不同的特征子集,利用上述无监督特征子集选择方法,本文确定3种主流的攻击策略下,特征子集选择结果如表1所示。

表1 特征子集选择结果
计算每个用户对应特征子集中的各特征值,除了本文提出的兴趣峰度系数外,其他特征属性的计算方法可参考文献[7-12]。
步骤2计算每个用户在特征子集上的离群度
根据攻击用户与真实用户特征属性分布的特点,本文采用基于距离和离群点的检测方法。离群度计算方法如式(7)所示,其中,d( u)表示用户u的特征子集与其他用户的距离和;fu和fv表示用户u和用户v对于特征f的特征值,Fsub即步骤1中选择出来的特征子集。
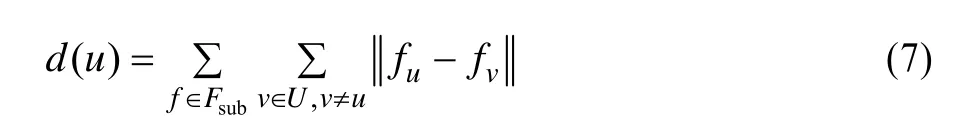
步骤3确定攻击目标项
在步骤2计算出各用户距离和的基础上,按降序排列生成用户排序列表。取前10的用户,并计算各个项目在前10个用户中的平均评分偏移。具有最大评分偏移绝对值的项目被视为攻击目标it。平均评分偏移计算方法如式(8)所示,其中,b( i)表示项目i的平均评分偏移;Ri表示项目i的平均分;U为用户集合;LN(U)表示用户排序列表的前N个用户。同时,根据目标项的评分偏移b( i)判断攻击目的:如果b( i)为正,则为推攻击;为负值,则为核攻击。
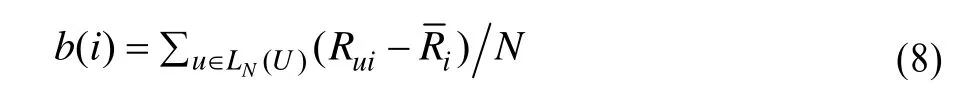
步骤4确定攻击用户
在确定目标项目之后,通过一个滑动窗口(大小设为10)滑过步骤3所得的用户排序列表,每次滑过一个用户,计算当前窗口中目标项目的平均评分偏移,当窗口由攻击用户富集的部分滑动到正常用户的范围时,目标项目的平均评分偏移值就会发生跳变,返回当前窗口起始位置作为停止点。
然后对停止点之前的排序列表进行分析检索攻击用户,如果没有对目标项目评分或者对其评分跟攻击的目的是相反的,则认为是正常用户,否则视为攻击用户。
5 实验与结果分析
在Movielens 100 K数据集上对本文提出的兴趣峰度系数以及基于特征子集的无监督检测算法进行实验分析。该数据集包含943个用户对1 682部电影的100 000个评分记录。
5.1 信息增益对比
信息增益是用来度量特征属性对训练样例区分能力的指标,即系统在有无该属性时熵的差值。文献[7]对通用的托攻击检测特征属性的信息增益进行了实验评估,并发现RDMA、WDMA、WDA以及LengthVar是最具有辨识度的通用特征属性。本文将KCI与这些特征进行对比,测试并分析各特征属性在数据集上的信息增益情况。
计算出数据集中所有的用户概貌的各特征值。然后,针对攻击用户和真实用户计算信息增益。图3~图5所示结果是100次随机选取攻击目标攻击条件下的各特征属性的信息增益平均值。图中展示了随机攻击、平均攻击和流行攻击在攻击规模为3%条件下,不同填充规模下的信息增益对比。可以看出,KCI在大多数填充规模下的信息增益都优于RDMA、WDMA、WDA和LengthVar属性。只有在填充规模为1%时,KCI的信息增益不理想,这是由于过少的填充项目无法体现出用户兴趣的分布。上述测试结果充分说明了用户兴趣峰度系数的作用。

图3 随机推攻击检测的信息增益对比
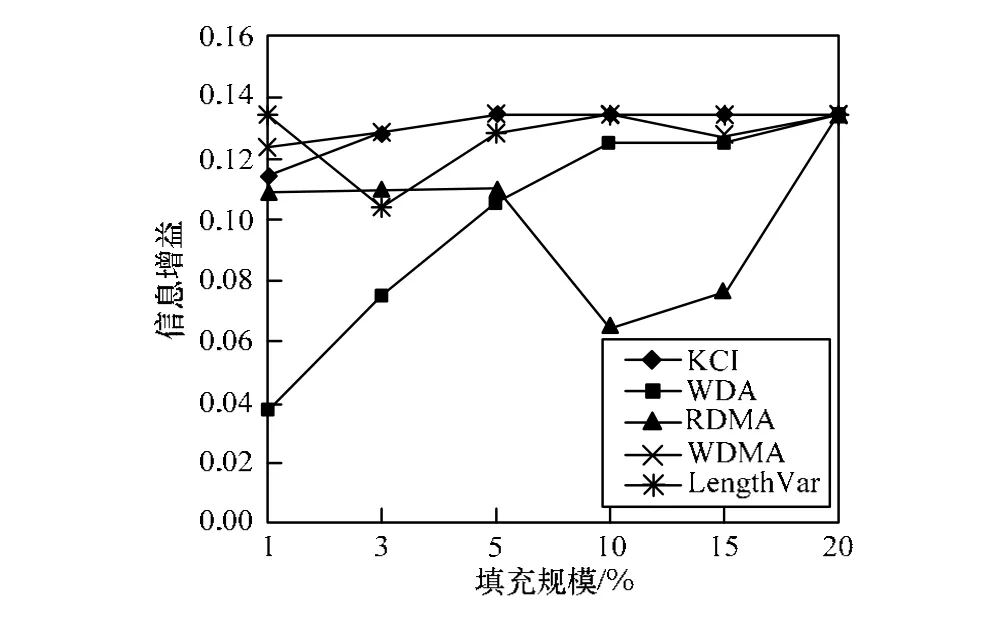
图4 平均推攻击检测的信息增益对比
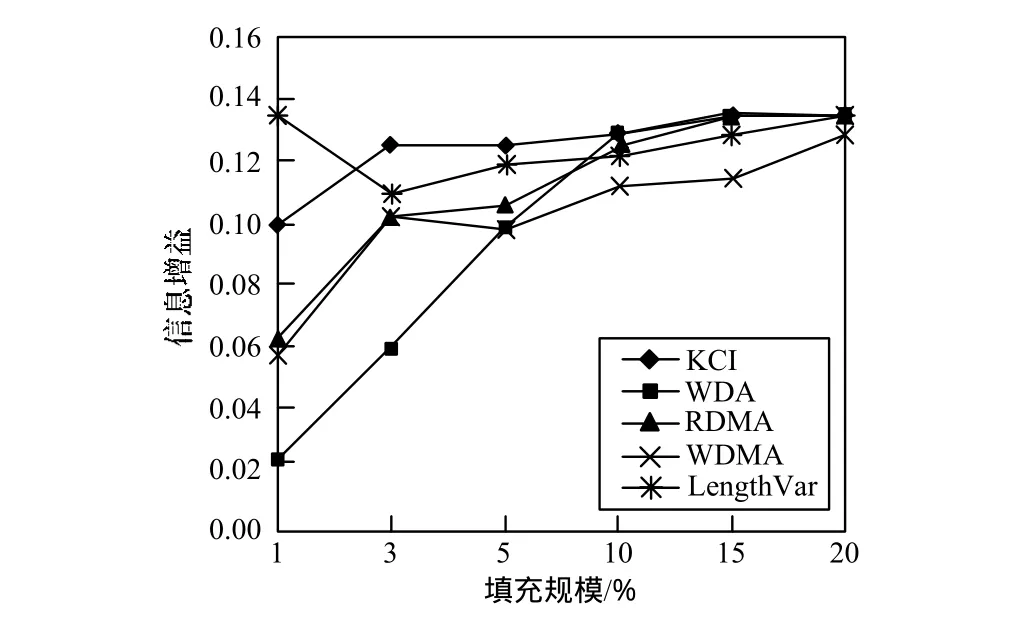
图5 流行推攻击检测的信息增益对比
5.2 Un DSA-FS算法检测效果对比
托攻击检测算法效果的评价采用准确率p、召回率r或两者的综合指标F值[17]。计算方法如下:

本文2.2节介绍了目前已有的一些无监督检测算法,包括PCA VarSelect和UnRAP等。图6~图8展示了3种攻击模型在攻击规模为3%时,随着填充规模的变化,PCA VarSelect、UnRAP以及UnDSA-FS算法的F值。从中可以看出,在不同填充规模下,UnRAP算法的稳定性和精准度都较差,PCA VarSelect精准度一般,而本文基于特征子集的检测方法稳定性和精准度都较好。

图6 随机推攻击检测的精准度对比

图7 平均推攻击检测的精准度对比
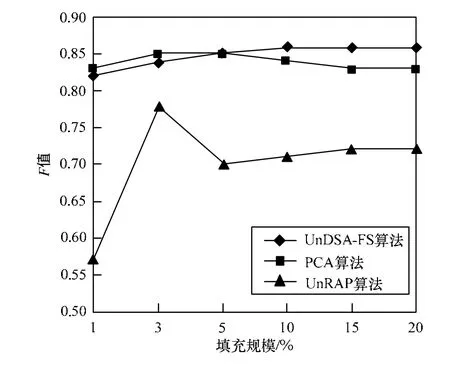
图8 流行推攻击检测的精准度对比
5.3 Un DSA-FS在不同攻击场景下的测试
为对UnDSA-FS算法进行全面的评估,本文采取3× 4× 6的设计模式[3],攻击模型(随机攻击,均值攻击,流行攻击),攻击规模(3%, 5%, 10%, 15%)和填充规模(1%, 3%, 5%, 10%, 15%, 20%)的不同组合对应一组实验配置。每组实验配置下,独立地向数据集注入10次推攻击,最终实验数据是这10次攻击检测的均值。
表2~表4展示了UnDSA-FS算法的检测效果。从中可以看出,本文算法取得了较好的检测性能,大部分召回率都在90%以上。随着攻击规模和填充率的增大,攻击概貌的异常程度愈加显著,可见,本文算法的检测效果有增强的趋势。

表2 随机推攻击检测的准确率和召回率

表3 平均推攻击检测的准确率和召回率

表4 流行推攻击检测的准确率和召回率
6 结束语
本文一方面利用现有攻击模型在项目选择上的随机性,提出一种描述用户兴趣集中程度的特征属性——兴趣峰度系数。另一方面,利用无监督特征选择方法,为不同类型托攻击选取有效的检测指标,并基于选择出的指标,设计一种基于特征子集的无监督检测算法。该算法在不同攻击规模、攻击模型、填充规模下都能较好地对攻击概貌进行检测。本文提出的是一种对于各种类型推荐系统都适用的通用方法,下一步的工作重点是研究在服务推荐、电子商务等特定领域中托攻击者的异常特征,进一步提升检测效果。
[1] Burke R, O’Mahony M P, Hurley N J. Rob ust Collaborative Recommendation[M]. New York, USA: Springer, 2011.
[2] Seminario C E, W ilson D C. Robustness and Accuracy Tradeoffs for Recommender Systems Under Attack[C]//Proc. of the 25th International Florida A rtificial Intelligence Research So ciety Conference. Mar co Island, US A: AAAI Press, 2012: 86-91.
[3] 李 聪, 骆志刚, 石金龙. 一种探测推荐系统托攻击的无监督算法[J]. 自动化学报, 2011, 37(2): 160-167.
[4] 魏 莎. 协同过滤推荐系统中攻击概貌检测算法研究[D].秦皇岛: 燕山大学, 2012.
[5] Lee J S, Zhu Dan. Shilling Attack Detection——A N ew Approach for a Trustworthy Recommender System[J]. INFORMS Journal on Computing, 2012, 24(1): 117-131.
[6] Chirita P A, Nejdl W, Zamfir C. Preventing Shilling Attacks in Online Recomm ender Systems[C]//Proc. of ACM International Workshop on Web Information and Data Management. New York, USA: ACM Press, 2005: 67-74.
[7] Burke R, Mobasher B, Williams C, et al. Classification Features for A ttack Detection in Co llaborative Reco mmendation Systems[C]//Proc. of the 12th ACM SI GKDD In ternational Conference on Knowledge Discovery and Data Mining. Philadelphia, USA: ACM Press, 2006: 542-547.
[8] 伍之昂, 庄 毅, 王有权, 等. 基于特征选择的推荐系统托攻击检测算法[J]. 电子学报, 2012, 40(8): 1687-1693.
[9] Hurley N, Cheng Z, Zhang M. Statistical Attack Detection[C]// Proc. of ACM Conferenc e o n Recommen der Systems. New York, USA: ACM Press, 2009: 149-156.
[10] Mehta B, Nejdl W. Unsupervised S trategies for Shilling
Detection and Robust Collaborative Filterin g[J]. User
Modeling and User-adapted Interaction, 2009, 19(1/2): 65-97. [11] Mehta B, Hofmann T, F ankauser P. Lies a nd Propaga nda: Detection Spam Users in Collaborative Filtering[C]//Proc. of the 12th International C onference on Intelligent User Interfaces. New York, USA: ACM Press, 2007: 14-21.
[12] Bryan K, O’Mahony M P, Cun ningham P. Uns upervised Retrieval of A ttack Profiles in C ollaborative R ecommender Systems[C]//Proc. of 2008 ACM Conference on Recommender Systems. New York, USA: ACM Press, 2008: 155-162.
[13] 单明辉, 贡佳炜, 牛尔力, 等. R ulerRep: 一种基于偏离度的过滤不实评价新方法[J]. 计算机学报, 2010, 33(7): 1226-1235.
[14] W u Zhiang, W u Junjie, Cao Jie, et al. HySAD: A Semisupervised H ybrid Shilling A ttack D etector for Trustworthy Product Re commendation[C]//Proc. of the 18th ACM SIGKDD International C onference on Knowledge Discovery and Data Mining. [S. l.]: ACM Press, 2012: 985-993.
[15] Peng Hanchuan, Long Fuhui, Ding C. Feature Selection Based on Mutual Infor mation: Criteria of Max-depend ency, Maxrelevance, and Min-redundancy[J]. IEEE T ransactions on Pattern Analysis and Machine Intelligence, 2005, 27(8): 1226-1238.
[16] 徐峻岭, 周毓明, 陈 林, 等. 基于互信息的无监督特征选择[J]. 计算机研究与发展, 2012, 49(2): 372-382.
[17] Lewis D D. A Sequential Algorithm for Training Text Classifiers[C]//Proc. of the 17th Annual International ACM SIGI R Conference on Research a nd Development in I nformation Retrieval. New York, USA: ACM Press, 1994: 3-12.
编辑 金胡考
Unsupervised Detection of Shilling Attack for Recommender System Based on Feature Subset
PENG Fei1,2, ZENG Xue-wen2, DENG Hao-jiang2, LIU Lei2
(1. University of Chinese Academy of Sciences, Beijing 100190, China; 2. National Network New Media Engineering Research Center, Institute of Acoustics, Chinese Academy of Sciences, Beijing 100190, China)
To solve the problem that existing recommender systems based on collaborative filtering are vulnerable to the shilling attac k, this paper proposes an Unsupervised Detection Algorithm of Shilling Attack B ased on Feature Subset(U nDSA-FS). A feature named Kurtosis Coefficient of Interest(KCI) is proposed to describe the intensity degree of user’s interest. Taking the KCI and other existed features as candi date feature set, this algorithm uses unsuperv ised feature selection method to ch oose proper feature su bset for different attack strategies. It computes the distan ce sum of each user, sorts t he users by the distance sum and identifies the atta ck target. It sets a sliding window on the sorted us er sequence, and filters the at tack users by calcu lating the mean rating deviation of attack target. Experimental result verifies that the info rmation gain of KCI is higher than existing features’, and the proposed UnDSA-FS has a better performance in stability and precision compared with existing unsupervised detection methods.
recommender system; shilling attack; unsupervised detection; feature subset; kurtosis coefficient; sliding window
10.3969/j.issn.1000-3428.2014.05.023
国家“863”计划基金资助项目“融合网络业务体系开发”(2011AA01A102);国家科技支撑计划基金资助项目“ACR创新应用示范”(2011BAH19B04);中国科学院重点部署基金资助项目“NGB有线无线融合开放业务平台关键技术研究与验证”(KGZDEW-103-2)。
彭 飞(1988-),男,博士研究生,主研方向:网络安全,个性化服务推荐;曾学文、邓浩江,研究员、博士、博士生导师;刘 磊,副研究员、博士。
2013-03-25
2013-05-27E-mail:pengf@dsp.ac.cn
1000-3428(2014)05-0109-06
A
TP309
