基于可信度模型的重复主数据检测算法
2014-08-05王继奎李少波
王继奎,李少波
(1. 中国科学院成都计算机应用研究所,成都 6 10041;2. 贵州大学省部共建现代制造技术教育部重点实验室,贵阳 5 50003;3. 兰州商学院信息工程学院,兰州 730 020)
基于可信度模型的重复主数据检测算法
王继奎1,2,3,李少波1,2
(1. 中国科学院成都计算机应用研究所,成都 6 10041;2. 贵州大学省部共建现代制造技术教育部重点实验室,贵阳 5 50003;3. 兰州商学院信息工程学院,兰州 730 020)
针对来源于多个业务系统的重复主数据影响主数据质量、主数据同步及主数据挖掘等问题,提出重复主数据检测算法fastCdrDetection。从数据可信度的角度出发,在考虑数据源可信度、数据最后更新时间及数据长度的基础上,建立主数据可信度模型,并实现可信记录生成算法。设计非递归的字符串相似度计算算法FiledMatch,解决了由中文简写、缩写、错误拼写造成的主数据重复问题,采用sourceKeys算法对来源于同一业务系统、具有同样业务主键的重复记录进行预处理,从而提高重复主数据检测效率。通过对某电网基建物资63万余条供应商存量数据及23万余条模拟数据进行实验,结果表明,与PQS算法相比,fastCdrDetection算法的召回率由74%提高到88%,准确率由61%提高到95%,证明了算法的有效性。
多数据源;重复主数据;可信度模型;检测算法;数据可信度
1 概述
重复主数据会对主数据质量、主数据同步及主数据挖掘等操作产生不良影响[1],如何检测重复主数据是十分重要的研究课题。文献[2]对重复记录进行了定义,文献[3]提出识别相似重复记录的5个基本步骤:数据预处理,缩小搜索空间,相似重复记录识别,相似重复记录清除和验证。文献[4]提出由召回率与准确率2个标准度量重复记录识别的有效性。在字段识别方面,文献[5]提出著名的S-W递归算法,文献[6]对S-W算法进行了改进,加入了扩大的递归变量,提高了运行效率。文献[7]提出非递归算法以及PCM算法。在实际应用中,发现主数据重复主要由中文简写、缩写、错误拼写造成,针对这3种情况,提出一种非递归的字符串相似度计算算法FieldMatch。目前的重复记录检测算法主要基于排序-比较-合并的思路,常用的算法有近邻排序法SNM[8]、多趟近邻排序法MPN[9]、优先队列算法PQS[10]。文献[11]设计的Max-merge算法兼顾了闭包算法[12]相似的传递性与独立性,对XML对象识别有较高的准确率与召回率。本文从数据可信度的角度出发,建立主数据可信度模型,基于主数据可信度模型改进了PQS算法,对每一个聚类采用可信记录作为代表记录参与相似度计算,以提高检测算法的召回率与准确率,并采用某电网公司的供应商主数据存量数据进行实验。
2 主数据重复记录检测模型
2.1 符号、缩写及其含义
符号、缩写及其含义如表1所示。

表1 符号、缩写及其含义
2.2 术语定义
定义1属性相似度:sim(ri.attrk, rj.attrk)表示记录ri与rj的k属性相似度;其计算方法是若2个属性ri.attrk,rj.attrk是相似的,当且仅当2个字段的sim(ri.attrk, rj.attrk)>t。ri.attrk.el代表i的k属性的字符,score(ri.attrk, rj.attrk)表示记录i的属性k的字符与记录j的属性k的字符匹配值,score (ri.attrk, rj.attrk)∈[0,1]、|ri.attrk|<|rj.attrk|。将ri.attrk,rj.attrk转化为字符串,逐一扫描2个字符串数组,若字符相等,则score值为1,否则向后扫描rj.attrk;若ri.attrk扫描结束,则算法结束。

由于ri、rj具有相同的关系模式,因此|ri|=|rj|=n,相似度计算公式转变为:

其中,RD代表识别出的重复记录的集合;RO代表实际重复记录的集合。
定义4准确率:

2.3 识别主数据重复记录的规则
2.3.1 sourceKeys计算规则的记录
规则1记录i的sourceKeys由记录的业务主键与记录来源系统决定。
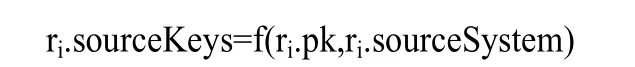
2.3.2 重复规则的记录
关系R为重复关系,R’为不重复关系。
规则2若记录的sourceKeys相同,则记录为重复记录。

规则3若2条记录相似度大于阈值,则2条记录重复。

2.4 多数据源可信度定义
定义5数据源可信度ri.sTScore。目前为简便计算,ri.sTScore由系统赋初始值,ri.sTScore∈(0,1)。
定义6字段可信度ri.attrk.tScore。由字段的数据源、记录的最后更新时间、字段长度共同决定。其依据为:
(1)从主数据系统的建设实践中总结出长的字段更可信,主要是因为重复主数据很多是缩写、简写造成的;
(2)在长度相同的基础上,来源系统可信度大的数据更可信;
(3)字段长度与来源系统的可信度均相等,从实践上发现这样的重复主数据大多是来源于同一业务系统,这种情况下记录的最后更新时间可以作为数据可信的依据,因为最后更新的数据应该是现实世界的真值,也更可信。

2.5 重复主数据检测
重复主数据检测模型如图1所示。
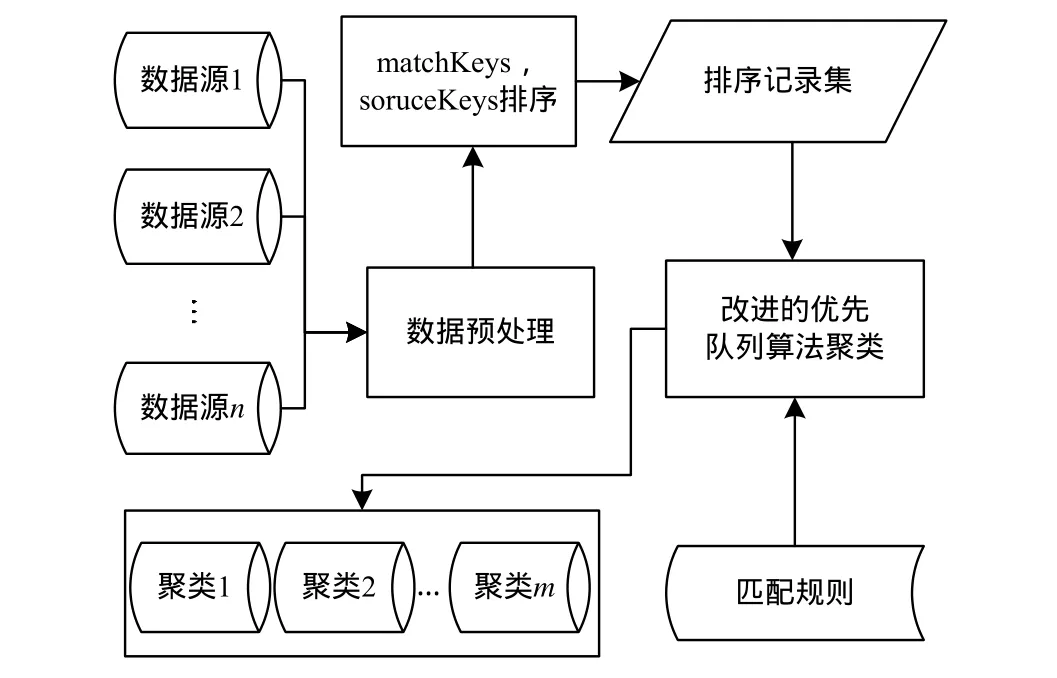
图1 重复主数据检测模型
重复主数据检测算法步骤具体如下:
(1)从各业务系统中抽取进入主数据系统的存量数据。
(2)根据主数据的数据格式要求对存量数据进行预处理,计算sourceKeys与matchKeys,并从源数据库日志中获取数据的lsDate,填充到待检测数据集中。
(3)以matchkeys为第一排序关键字,sourceKeys为第二关键字升序排序。
(4)采用fastCdrDetection(Fast Cluster Duplicate Records Detection)算法进行聚类,队列每个节点的代表记录为本聚类的可信记录。
(5)输出聚类记录数大于1的聚类记录。
3 fastCdrDetection检测算法
算法1属性相似度sim(ri.attrk, rj.attrk)算法
思路:属性值数字型或boolean,完全相等,相似度为1,否则为0;其他类型统一处理成字符串。
属性相似度计算是计算记录相似度的基础,目前主要有基本的字段匹配算法与递归的字段匹配算法2种,主要针对英文字符串的相似度研究。通过分析主数据管理系统中,常出现的不一致表现主要为缩写、简写与错写,采用FieldMatch字符串比较算法。
输入带比较的2个记录的属性值ri.attrk,rj.attrk
输出相似度比较结果
f1Array,f2Array为ri.attrk,rj.attrk的字符串数组;k与m为指向f1Array,f2Array的指针,初始值为0;count统计字符相同的结果,初始值位0。


算法分析:将ri.attrk转化为字符数组,每个字符即ri.attrk的原子串,将rj.attrk转化为字符数组,扫描一遍2个数组,统计相同字符的个数。设ri.attrk对应的数组长度为m,rj.attrk对应的数组长度为n,最好情况需要比较min(m,n),最坏情况需要比较max(m,n)。
算法2记录相似度similarity(ri, rj)算法
思路:ri.soruceKey=rj.soruceKey表示ri,rj是来源于同一业务系统的同一实体,similarity(ri, rj)值为1;否则根据式(3)计算相似度。

算法3可信记录生成算法getTrustedRecord
输入待检测记录ri,聚类m的可信记录trustedRecord(m)
输出聚类m的可信记录
参数:change: boolean,初始值位false。
思路:计算待检测记录ri与聚类m的可信记录trusted-Record(m)的相似度;若相似度大于阈值,同一字段值不同,则选取可信度更高的字段值作为可信记录的字段值,生成可信记录。

算法分析:在计算聚类的代表记录(可信记录)时,需要根据可信度模型计算字段的可信度进而生成可信记录,与PQS算法相比会产生额外开销。从实验结果可看出,处理10 146条供应商数据fastCdrDetection算法耗时14 660 ms,而PQS算法耗时14 430 ms,平均每条数据fastCdrDetection算法多耗时0.022 7 ms。
算法4matchKeys生成算法
思路:根据主数据管理业务需要,选取特定字段或者字段集作为matchKeys生成字段,将各生成字段的转换为字符串,然后连接起来作为matchKeys。

算法5 fastCdrDetection算法
思路:fastCdrDetection算法基于排序-检测-合并思路。首先利用matchKeys作为第一排序关键字,sourceKeys作为第二排序关键字对记录进行排序。顺序扫描记录集,比较当前记录ri与优先队列包含的可信记录,若在优先队列中有重复记录,则将这条记录合并入匹配记录所在的聚类中,包含这个记录的聚类进入优先队列并有最高的优先级;若扫描整个优先队列后发现ri不属于任何一个聚类,则生成新的聚类加入优先队列,并使其具有最高优先级。将ri加入该聚类中,成为该聚类的可信记录。最后输出所有聚类记录数大于1的聚类记录,即为重复记录。
采用优先队列策略识别重复记录的精度很大程度上依赖于排序所选择的关键字,第一关键字的选择要结合业务应用场景,为了快速检测来源于同一系统、具有同一业务主键的重复记录,采用sourceKeys作为第二排序关键字。优先队列算法选择进入聚类的第一条记录作为代表记录,而fastCdrDetection算法采用可信记录作为代表记录,采用动态的、不断变好的可信记录替换进入聚类的第一条记录作为聚类的代表记录,提高了检测结果的准确率与召回率。
输入排序后的记录集recordSet
输出重复记录检测结果
参数:PQ表示优先队列,maxPriority表示当前最高优先级。

算法分析:
由于采用了对来源于同一业务系统、具有同样业务主键的重复记录进行了预先处理,在比较相似度时先比较记录的sourceSystem,因此在实际应用中fastCdrDetection算法具有更高的效率,来源于同一业务系统、具有同一业务主键的重复记录越多,则算法效率越高;在记录相似度计算时,采用本文聚类的可信记录代替进入聚类的第一条记录,相似度计算结果也具有更高的准确性。
4 实验与结果分析
由于优先队列算法项的代表记录采用的是聚类的第一条记录,导致记录相似度比较的结果失真,算法的准确率与召回率降低;fastCdrDetection检测算法采用可信记录代替作为聚类的代表记录,并在检测过程中首先检测来源于同一数据源的数据的sourceKeys,能较快的检测出来源于同一数据源的重复记录。
实验验证程序采用Java语言编写,在Win7 64位操作系统、Jre1.6环境下运行。实验采用的数据为来源于物资基建系统供应商主数据63万余条及模拟噪声数据23万余条。主要对比PQS算法与fastCdrDetection算法的运行时间、召回率、准确率。
4.1 相似度算法对比
fastCdrDetection算法使用的字符串相似度算法是非递归的基于位置编码的匹配算法,属性相似度算法对比实验以PCM算法为对比对象。取某电网公司前1 000条供应商名称作为测试数据进行测试。
(1)算法准确率
实验表明,PCM由于采取了罚分的手段,针对中文识别,识别准确率不稳定;FieldMatch算法是基于统计的方法,顺次扫描2个字符串,指针一直向后扫描不回归,如果存在不一致的字符,则匹配结束。针对主数据管理系统常出现的中文缩写、简写等情况,FieldMatch相似度比较的准确度更高。实验结果表明,FieldMatch针对主数据中文识别准确率随着阈值的提高而逐渐稳步提高。图2中字段相似度阈值t∈(0,1],算法准确率P∈(0,1]。

图2 算法准确率对比
(2)算法召回率
对比实验表明,FieldMatch一直比PCM算法召回率高。通过分析真实数据发现,由于PCM算法采取了罚分的思路,导致一些表示同一供应商实体的数据没有被识别出来,而FieldMatch则能较好地识别。图3中字段相似度阈值t∈(0,1],算法召回率R∈(0,1]。

图3 算法召回率对比
(3)算法识别出的重复聚类数对比
实验结果表明,PCM算法识别出的聚类数始终比FieldMatch算法少,随着阈值的增加2种算法识别出的重复聚类数不断减少。通过分析发现随着阈值的增加属性相似的要求变得越来越高,导致重复的聚类数不断减少。由于PCM是基于位置的罚分算法,使得计算所得的相似度低于FieldMatchs算法,因此实验结果表明,FieldMatch算法在相同阈值设置的情况下发现的重复聚类数比PCM算法多。图4中字段相似度阈值t∈(0,1],聚类个数n是一个整数。
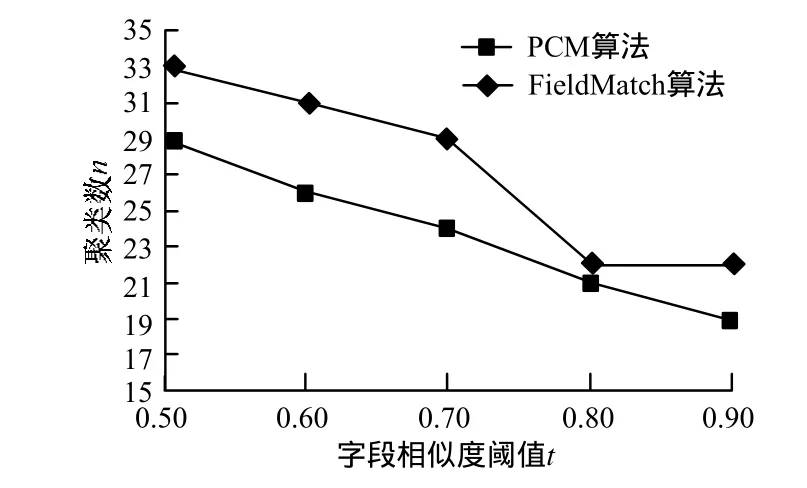
图4 算法识别出的聚类数对比
4.2 P QS算法与fastCdrDetection算法对比
实验采用数据为供应商数据,总计10 146条,记录相似度阈值为0.9,属性相似度阈值为0.8,通过人工识别重复记录数位42条,PQS算法与fastCdrDetection算法性能对比如表2所示。

表2 算法性能对比
可以看出,在同样运行参数的情况下,fastCdrDetection算法比PQS算法的召回率与准确率高。通过分析实验数据发现,由于fastCdrDetection算法采用基于可信度计算,利用更好的记录代替PQS算法第一条记录(或者是最后一条)参与相似度计算,相似度计算的结果更接近实际结果,因此算法的召回率与准确率较高。然而,fastCdrDetection采用更好的记录替代PQS的代表记录,因此运算时间比PQS算法略长。但由于采用sourceKeys快速计算记录的相似度,随着来源于同一源系统的重复记录的增加,会缩短fastCdr-Detection的运算时间。
4.3 运行参数对算法的影响
采用某电网公司基建物资联系人表中的前6 0 00条数据进行测试,数据规模对算法性能的影响如表3所示。

表3 数据规模对算法性能的影响
由表3可以看出,随着规模的增加,每条记录的处理时间也在不断增加,聚类数也在增加,这说明对海量数据必须进行分组处理,并合理控制优先队列的长度。
5 结束语
重复主数据检测是主数据集成的热门研究课题,从数据可信度的角度出发,在考虑了数据源可信度、数据最后更新时间及数据长度的基础上建立了主数据可信度模型,并实现可信记录生成算法。本文提出一种非递归的字符串相似度计算FieldMatch算法,较好地解决了由中文简写、缩写、错误拼写造成的主数据重复问题。针对来源于同一数据源的重复主数据,设计sourceKeys进行预处理,提高算法效率,并提出fastCdrDetection主数据重复记录检测算法,对每一个聚类采用可信记录作为代表记录参与相似度计算,从而提高检测算法的召回率与准确率。采用某电网公司的供应商主数据存量数据进行实验,实验结果表明,与PQS相比,fastCdrDetection算法的召回率由74%提高到88%,准确率由61%提高到95%,证明了fastCdrDetection聚类算法有较高的召回率及准确率。目前可信度模型仅考虑了主数据字段的长度、来源系统的可信度及记录最后更新时间因素,今后将对数据源的可信度生成算法进行研究。
[1] Hernandez M A, Stolfo S J. Real-world D ata is D irty: Data Cleansing and th e Merge/Purge Problem[J]. Data Ming and Knowledge Discovery, 1998, 2(1): 9-37.
[2] 韩京宇, 徐立臻, 董逸生. 数据质量研究综述[J]. 计算机科学, 2008, 35(2): 1-5.
[3] Batin C, Scannapieca M. Data Quality: Concepts, Methodologies and Techniques[M]. New York, USA: Springer-Verlag, 2006.
[4] 陈 伟, 丁秋林. 可扩展数据清理平台的研究[J]. 电子科技大学学报, 2006, 35(1): 100-103.
[5] Smith T F, Waterman M S. Identification of C ommon Molecular Subseque nces[J]. Journal of Molecular Biology, 198 1, 147(1): 195-197.
[6] Nawaz Z, Bertelsk A. Acceleration of Simth-Waterman Using Recursive V ariable Expansion[C]//Proceedings o f the 1 1th EUROMICRO Conference on Digital System Design Architectures, Methods and Tools. Parma, Italy: IEEE Press, 2008: 915-922.
[7] 张 永, 迟忠先, 闫德勤. 数据仓库ETL中相似重复记录的检测方法及应用[J]. 计算机应用, 2006, 26(4): 880-882.
[8] Hernandez M, Stolfo S. The Merge/Purge Problem for Large Databases[C]//Proceedings of ACM SIGMOD International Conference on Management of Data. San Jose, USA: [s. n.], 1995: 127-138.
[9] 李 坚, 郑 宁. 对基于MPN数据清洗算法的改进[J].计算机应用与软件, 2008, 25(2): 245-247.
[10] Monge A, Elkan C. An Efficient Domain Independent Algorithm for Detecting A pproximately D uplicate Database Records[C]//Proceedings of SI GMOD Workshop on Data Mining and Knowledge Discovery. Tucson, USA: [s. n.], 1997: 23-29.
[11] 李亚坤, 王宏志. 基于实体描述属性技术的XML重复对象检测方法[J]. 计算机学报, 2011, 34(11): 2132- 2141.
[12] Whang S E, Menestrina D, Georgiaet K. Entity Resolution with Iterative Blocking[C]//Proceedings of the 35th SI GMOD International Conference on Management of Data. New York, USA: ACM Press, 2009: 219-231.
编辑 陆燕菲
Duplicate Master Data Detection Algorithm Based on Credibility Model
WANG Ji-kui1,2,3, LI Shao-bo1,2
(1. Chengdu Institute of Computer Applications, Chinese Academy of Sciences, Chengdu 610041, China; 2. Key Laboratory of Advanced Manufacturing Technology, Ministry of Education, Guizhou University, Guiyang 550003, China; 3. College of Information Engineering, Lanzhou University of Finance and Economics, Lanzhou 730020, China)
To avoid the effect of duplicate master data from multiple business systems on the quality, synchronization of the master data as well as master data mining, this paper propose a fastCdrDetec tion(Fast Cluster Duplicate Record s Detection) algo rithm, in wh ich a duplicate master data detection model and a credible record ge nerating algorithm are included, c onsidering data source reliabil ity, data refresh time and data length. A non-recursive algorithm FiledMatch is established for character string similar ity calculation. Aiming at the eliminating problems caused by abbreviations and wrong spellings in Chinese input, a sourceKeys algorithm is constructed for pretreatment of duplicate records arising from a same business system and sharing same business keys to achieve high efficiency in duplicate master data detection. Experiments are carried on a power grid with 630 thousand records of raw material and 230 thousand simulated data records. Result shows that the recall rate of the fastCdrDetection algorithm is 88%, while the PQS algorithm is 74%, and the accuracy is 95% to 61%. The effectiveness of the algorithm is verified.
multiple data source; duplicate master data; credibility model; detection algorithm; data credibility
10.3969/j.issn.1000-3428.2014.05.007
国家科技支撑计划基金资助项目(2012BAF12B14)。
王继奎(1978-),男,副教授、博士研究生,主研方向:数据管理,软件过程技术,智能计算;李少波,教授、博士生导师。
2013-04-02
2013-05-27E-mail:wjkweb@163.com
1000-3428(2014)05-0031-05
A
TP311
