基于科研在线文档库平台的标签推荐系统
2014-08-05蔡芳,沈一,南凯
蔡 芳,沈 一,南 凯
(1. 中国科学院计算机网络信息中心,北京100190;2. 中国科学院大学,北京 100049)
基于科研在线文档库平台的标签推荐系统
蔡 芳1,2,沈 一1,2,南 凯1
(1. 中国科学院计算机网络信息中心,北京100190;2. 中国科学院大学,北京 100049)
科研在线文档库是一个面向团队的文档协同与管理工具,为虚拟团队提供合作平台。它采用标签系统的方式组织其中的所有文档。在文档库的使用过程中,出现了无标签文档数量的累积以及用户为文档添加的标签质量偏低问题,影响文档的分类和共享。针对该问题,采用适用于科研在线文档库平台的标签推荐方法,包括协同过滤以及关键词抽取2个部分,促使用户为文档添加合格的标签,提高文档系统的使用效率。协同过滤推荐部分的实验采用准确率和召回率衡量标准,关键词抽取部分采用用户调查的实验方式,实验证明为每个文档提供3个候选标签能够得到理想效果。在实际使用环境中,该系统具有较高的精确度和可靠性,简单易于实现。
标签推荐;标签系统;协同过滤;关键词抽取;冷启动;文档协同
1 概述
Web2.0下,用户行为由Web1.0中获取信息转变为以交互为主的方式,信息发布的来源转向Web用户。相对于传统的基于网站预先设定的分类体系的信息分类方法,标签系统的开放性、简单性、标签由资源共享者提供等特点[1],使得它成为Web2.0网站的重要信息分类和索引方式。用户生成内容(User Generated Content, UG C)标签系统,通过让用户对信息打标签,将具有相同标签的信息进行分类归纳整理,形成以标签为中心的信息分类系统[2]。2004年,标签系统领域的信息架构专家,提出分众分类法的概念,指群众自发性定义的平面非等级标签分类,用于信息的分类和共享。目前比较流行的UGC标签系统有书签类站点Delicious、论文书签网站CiteULike、相片分享网站Flickr等。
科研在线文档库(Duckling D ocument L ibrary, DDL)是一个面向虚拟组织的协作式、文档共享和管理工具[3]。系统利用用户添加的标签对团队中所有的文档进行分类。其中未打标签的文档被放置于无标签文档类。一方面,随着团队成员和文档数量的增加,无标签文档的数量开始累积,这些文档处于一种平行无清晰组织结构的状态,当用户需要在其中寻找某一特定类别的信息时,比较耗时,这种情况不利于DDL文档的高效利用和管理,所以为无标签文档推荐标签成为一种需求。另一方面,由于用户可以任意地为文档添加标签,而用户自身对信息和词汇的理解存在不准确性,使系统中的标签存在一定程度的冗余性、不一致性和不完备性[4]。这些问题都会影响到标签系统在进行文档组织、分类时的性能,所以提升标签的质量成为标签系统中核心的问题。当用户想为文档添加标签时,为用户提供高质量的标签备选,可以有效地缓解上述问题。
本文基于协同推荐的方式,为无标签页面提供高质量候选标签。如传统的协同推荐一样,对于一个新的团队文档集合,存在数据稀疏的冷启动问题。针对这种现象,系统采用关键词抽取的方式,利用文档自身的内容信息提取候选标签集合。当系统中的标签积累到一定质量和数量之后,再采取协同过滤的方式进行标签推荐。
本文利用文档内容信息和文档与标签之间的关系进行标签的推荐,而传统的标签推荐系统,基本都是基于用户、标签、资源3个对象之间的关系[5-6],较少考虑资源自身的内容特征。当用户在DDL中对某一文档进行添加标签的操作时,系统会提供相关的推荐标签集合,此时,用户可以直接选择相关的标签进行添加,也可以在候选标签的提示下,添加自己的语义层面标签,这样可以有效地提升用户打标签的质量,降低打标签的难度。
2 标签推荐系统相关工作
标签推荐可以有效地提高系统标签质量,减少用户打标签的难度,近年来成为学术界和工业界关注研究的重点。在传统的标签推荐系统中,比较简单的标签推荐方法包括4种(统称为基于最流行的推荐法):为用户推荐整个系统最热门的标签,为用户推荐他自己经常使用的标签,为用户推荐资源上最热门的标签。通过系数将前面2种方式的推荐结果进行线性加权的简单混合推荐[2]。
这4种方式不用进行复杂的模型训练和计算,实现成本低,在商业系统中较常使用。例如豆瓣,用户可以为一本书或者是一部电影添加标签,此时,标签系统会为用户提供2类标签,一类是用户自己的标签,另一类是此书籍或者电影上经常被标记的标签。对于商业产品,此类方法效果较好而且实现简单快速。但是这些算法对于新用户或者是不太热门的物品,存在冷启动问题,很难有较理想的推荐效果。
图模型也可以用于标签推荐系统。先根据用户对资源打标签这种行为,生成用户-资源-标签无向图。基于此图的相关算法有FolkRank算法[7],此算法认为一个标签如果标记重要资源,而且是重要的用户进行的标注,那么这个标签就更重要。经过迭代计算,得到标签的得分排名,然后为资源提供topN标签推荐。另外一类是采用基于随机游走的PersonalRank算法[8],此算法基本思路是:从用户U对应的节点VU出发进行随机游走,游走到任何一个节点时,按照概率选择继续游走或者是返回节点VU开始重新游走,经过迭代计算,使各个节点被访问的概率收敛到一个值,该概率就是推荐列表中标签的权重。这些算法都存在要进行模型训练、计算复杂、时间复杂度高等问题,在实际系统中应用起来还有很多实际的困难需要解决。
本文提出了一种综合协同过滤推荐以及关键词抽取的标签推荐方式。在DDL平台上,由于文档上被标记的标签都是共享的,即只存在文档、标签二维空间,而不是图模型中的三维空间,这样前文所说的一些推荐方式并不适合DDL实际环境,在此情况下本文提出一种不考虑用户的协同推荐方式,简单高效,易于实现。现在主流的标签推荐研究都是在Delicious、Bibsonomy等公开的数据之上进行的[9],标签数据量有一定的基础,不用考虑冷启动的问题。在DDL中,若成立一个新的科研团队,其中基本没有标签,此时,采用第2种推荐方法:基于内容的关键词抽取标签推荐方法。
3 综合协同过滤和关键词抽取的标签推荐系统
Delicious、豆瓣等系统中,用户和资源之间是多对多的关系,用户U1和U2都可以对资源I添加标签,并且他们添加的标签集合S1、S2是独立的。而在DDL中,由于DDL的宗旨是团队协作和共享,团队成员之间的关系是十分亲密的,因此所有用户对于一个文档添加的标签都属于一个集合S。由于不存在完整的用户-资源-标签三维空间,本文第2节中提到的主流标签推荐方式并不适合DDL,从可用性、实用性、易于实现等方面考虑,提出一种综合协同过滤和关键词抽取的标签推荐方法。
当团队中已打标签的文档数目占所有文档的比例超过一个阈值时,采用协同过滤标签推荐方式,当小于这个阈值时,采用关键词抽取方式。
3.1 基于内容的协同过滤标签推荐
传统的协同过滤中,通过用户对资源的评分矩阵计算资源相似度或者是用户相似度。例如电子商务网站中当2个物品被同一个用户喜欢,那么它们的相似度加一。在DDL中,文档的协作分享面向科研团队,在一个团队中,用户和文档之间关系的黏度是比较强的,即一个用户访问某2个页面的可能性很大,并不能代表这2个页面的相似度关系,因此,使用传统的相似度判断方法并不适合DDL。基于此,本文采用基于内容判断文档相似度的方法。
3.1.1 文档特征向量
对于DDL团队中的文档,在对其文档内容分词之后,利用TF-IDF模型计算文档中每个关键词的权重,然后构建文档特征向量:
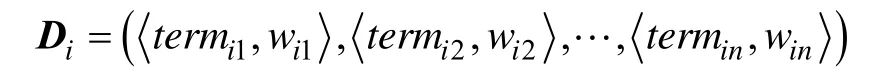
其中,Di表示文档i的特征向量;termij(j=1,2,…,n)表示将文档i的特征词按照权重由大到小排序之后的第j个特征词;wij是其对应的tf-idf权重。
3.1.2 相似文档集合
目标是计算目标文档的相似文档集合。在构建了团队文档向量空间模型之后,利用余弦定理计算2个文档特征向量之间的距离:

其中,分子代表特征向量Di和Dj中相同的特征词对应的权重乘积求和。
在DDL团队中,对于目标页面d,计算它与团队中其他文档的相似度,选取前30个页面形成d的相似页面集合Nd:
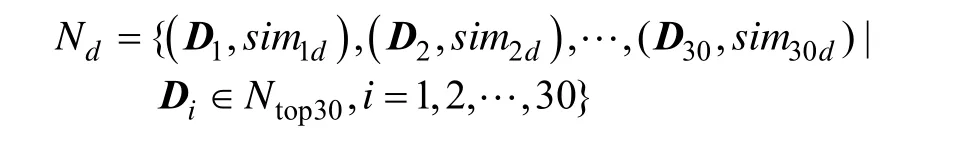
其中,Ntop30表示与目标文档d相似度最大的前30个文档集合;Di表示第i个文档向量;simid表示文档i与目标文档d的相似度权重。
3.1.3 推荐标签集合
在DDL中,对于目标文档d,其相似文档集合为Nd,对于其中的每个文档i,其上有一些已经被标记上的标签t,将对应于i的已有标签集合记为Ti。对页面d的推荐标签集合如下:Trec- d={(td1,wtd1),(td2,wtd2),…,(tdk,wtdk)}。其中,tdi∈T1∪T2∪…∪T30(i=1,2,…,k)是为目标文档d推荐的第i个标签;wtdi是标签tdi对应的排名权重,由如下公式计算:
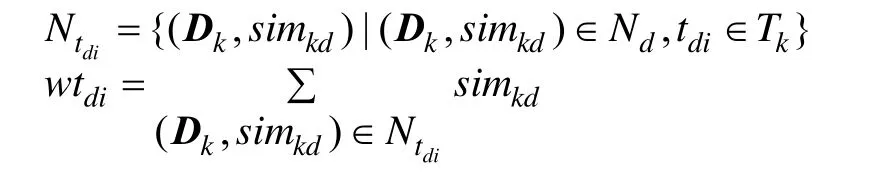
其中,Tk代表文档k上已有的标签集合;Ntdi代表在目标文档d的相似文档集合Nd中包含标签tdi的所有文档的集合;Trec-d按照标签权重wtdi进行排序。
3.2 关键词抽取
用TF-IDF度量关键词的权重。采用公式tf-idft, d= tft, d×idft,tft,d表示词项频率,idft表示逆文档频率。在词袋模型[10]的文档视图下,TF-IDF模型能够表示文档中词项的区分度和重要度[11]。TF-IDF被公认为信息检索中最重要的发明,常用于搜索引擎排名中确定网页和查询的相关性、自底向上文档分类等问题中[12]。
对于一个全新的团队,系统中基本没有标签,在协同过滤方式中会出现冷启动的问题,本文采用关键词抽取的方式来解决。具体做法如下:采用IKAnalyzer中文分词器的智能切分方式对文档分词,将DDL中已经存在的标签作为自定义的扩展词典,过滤单个汉字词项和数字,然后统计文档中词项的TF-IDF值,选取topK作为推荐集合:
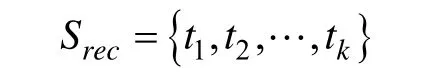
其中,关键词按照权重由大到小排名,推荐文档的前K个最大TF-IDF权重的关键词集合。
4 实验及结果分析
4.1 基于内容的协同过滤标签推荐
4.1.1 实验数据及度量方法
为验证算法的性能,本系统采用DDL中某一团队的部分数据集合。这个数据集合包含3 000个页面。随机选取所有页面的20%作为测试集合,即训练集合页面数目为600。
由于系统属于TopN推荐,即为用户提供一个推荐列表。TopN推荐的预测精度一般通过准确率和召回率来度量。这里,采用这2种传统的度量方式:
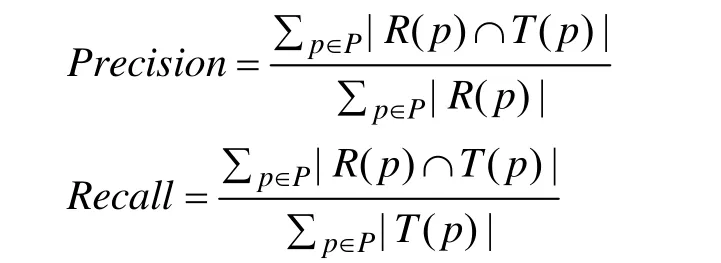
其中,p表示测试页面集合;R(p)表示给页面推荐的标签集合;T(p)表示测试集中的页面实际被标记上的标签。
通过选取不同的列表长度N,计算出一组准确率和召回率,以此判断最佳的推荐长度。为了保证测试实验的准确性,重复实验5次,每次用于测试的600个页面都是随机选择的不同页面。
4.1.2 结果分析
选取N={3,4,5,6}进行实验,每次进行5次重复实验。图1代表取不同的N值时的准确率,图2是对应的召回率。
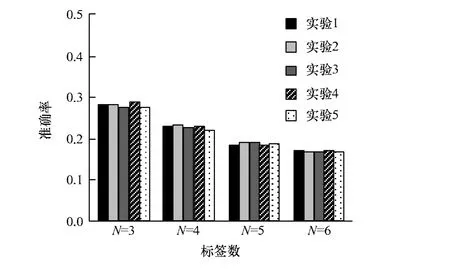
图1 N取不同值时的准确率
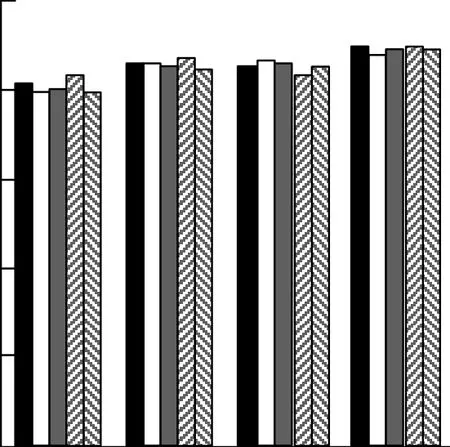
图2 N取不同值时的召回率
从图1中可以看出,准确率相对于召回率处于一个较小的取值空间,因为准确率代表的是页面推荐集合和原有标签集合的交集C与推荐标签集合的总数目R的比例。当N变大时,R增长较快,例如N为3时,推荐总数为3×600= 1 800,N为4时推荐总数为4×600=2 400,而选用的团队页面集合基本上每个页面的标签数目在1个~2个之间,而集合C受到原有标签集合的数目限制,C与R的数量差距较大,这也就解释了精确率都在较小数据区间内的现象。
而准确率随着N的增长呈现下降的趋势,主要是由于N的增长导致R显著增大,但是对于C的提升没有很明显的效果,出于实际DDL中页面的标签基本上是在3个以内,此处认为选择N为3时,比较理想。
召回率代表了集合C与页面原有标签集合T的比例。对于随机选择的600个测试页面集合,T的数量基本稳定,但是当增大推荐数目N时,如同在分析精确度时所描述的,N对于推荐效果的提升虽然没有很显著的影响,但是当推荐的候选集合增大,交集C还是会有小幅度的增加,因此,也就表现为召回率的小幅度增大变化,但是这个增长幅度太小,故认为N为3时的召回率已经是比较理想了。
综合上述原因,采用推荐标签集合长度N为3较理想。
4.2 关键词抽取推荐
本文是基于TF-IDF进行关键词提取,所得到的关键词推荐集合是基于分词结果。例如页面“试用期/实习期管理”,得到的推荐集合是{实习期,试用期,转正};页面“考勤公示说明”,推荐集合{缺勤,考勤,公示};页面“2010级硕士生开题答辩”,推荐集合{开题,硕士生,2010级}。可以看出,内容抽取的方式能够得到一些比较好的代表文档内容的关键词,这样能够方便用户对文档添加标签。内容抽取方式得到的是词粒度的标签。而当DDL团队被使用一段时间之后,部分页面会被添加上一些语义层面的标签,例如“科研与教育”、“全室共享”,这样在基于内容的协同推荐方式下,就会为页面提供一些语义层面的标签推荐,例如上面提到的页面“2010级硕士生开题答辩”,得到推荐集合{科研与教育,分享与研究,默认集合 }。
对于该推荐方式采用用户调查的方式进行实验。由于对于已有标签的页面,其上的标签可能会影响用户对推荐结果的主观判断。因此,随机选择团队中个300个未打标签页面,选择5个用户参加调查,评价分为3个等级。重复实验5次结果如表1所示。其中数据分别代表300个页面中用户满意、感觉一般和不满意页面的数目所占的比例。
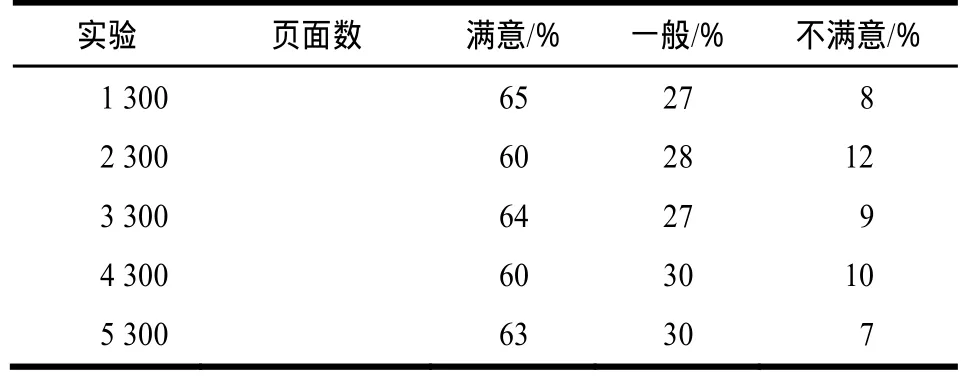
表1 用户调查满意度
随着使用时间的增长,标签数量和质量会逐步的积累和改善,从而标签推荐系统的效果也会稳步上升。
5 结束语
本文综合协同过滤方法和关键词抽取方法对DDL团队文档推荐标签。在解决标签推荐冷启动问题的同时能够为用户提供高质量的候选标签集合,方便用户对页面添加具有代表性的标签。提升了DDL的标签系统,使得文档的组织、管理和分享更加高效有序。实验结果证明,该系统能够为文档提供较高精度的标签推荐,有利于DDL标签系统的有效构建和发展。下一步工作着重于提高标签推荐的精度,同时在关键词抽取方面,利用主题模型进行实验,和TF-IDF方法进行对比。
[1] Golder S A, Huberman B A. The Structure of Collaborative Tagging System[J]. Journal of Information Science, 2006, 32(2): 198-208.
[2] 项 亮. 推荐系统实践[M]. 北京: 人民邮电出版社, 2012.
[3] 南 凯, 董科军, 谢建军, 等. 面向云服务的科研协同平台研究[J]. 华中科技大学学报: 自然科学版, 2010, 38(1): 14-19.
[4] Guy M, Tonkin E. Folksonomies: Tidying up Tags?[J]. D-Lib Magazine, 2006, 12(1): 1-15.
[5] 许棣华, 王志坚, 林巧民, 等. 一种基于偏好的个性化标签推荐系统[J]. 计算机应用研究, 2011, 28(7): 2573-2575.
[6] G emmell J, Schimoler T, Mobasher B, et al. Hybrid Tag Recommendation for Social A nnotation Systems[C]//Proc. of the 19th ACM International Conf erence on Information and Knowledge Management. New York, USA: ACM Press, 2010: 829-838.
[7] Hotho A, Jäschke R, Schmitz C, et al. Information Retrieval in Folksonomies: Search and Ranking[C]//Proc. of the 3rd European Sema ntic W eb Conference. Berlin, Germany: Springer-Verlag, 2006: 411-426.
[8] Haveliwala T H. T opic-sensitive PageRa nk[C]//Proc. of the 11th International Conference on World Wide Web. New York, USA: ACM Press, 2002: 517-526.
[9] 勒延安, 李玉华, 刘行军. 不同粒度标签推荐算法的比较研究[J]. 计算机应用研究, 2012, 19(2): 504-509.
[10] Lewis D D. Naive(Bayes) at Forty: The Independenc e Assumption in Information Retrieval[C]//Proc. of the 10th European Confer ence o n Mac hine Le arning. Lo ndon, UK: Springer-Verlag, 1998: 4-15.
[11] Manning C D, Rag havan P, Schütze H. 信息检索导论[M]. 王 斌, 译. 北京: 人民邮电出版社, 2010.
[12] 吴 军. 数学之美[M]. 北京: 人民邮电出版社, 2012.
编辑 顾逸斐
Tag Recommendation System Based on Duckling Document Library Platform
CAI Fang1,2, SHEN Yi1,2, NAN Kai1
(1. Computer Network Information Center, Chinese Academy of Sciences, Beijing 100190, China; 2. University of Chinese Academy of Sciences, Beijing 100049, China)
Duckling Document Library(DDL) is a tool for document collaboration and management among research teams. It provides a cooperation platform for virtual teams. T ag system is used to manage all the documents on it. During the use of the lib rary, the number of documents without any tags is gradually accumulating and the quality of tags labeled by users to some documents is not so good. All these troubles impede the effective control of the documents. In order to solve these problems, this paper proposes a tag recommendation method suitable for the document library of research onl ine platform, which includes collaboration filterin g recommendation and keywor ds extraction recommendation, in this way users are prompted to ad d qualified tags and improve the efficiency of the document libr ary. Precision and recall rate metrics are used in the collaboration filtering recommendation and user survey in the keyw ords extraction recommendation. Experimental results show that a recommended list of three tags can get desired effect. In production environment, this tag recommendation system has qualified accuracy, reliability and is easy to be implemented.
tag recommendation; tag system; collaborative filtering; keywords extraction; cold-start; document collaboration
10.3969/j.issn.1000-3428.2014.05.061
中国科学院十二五信息化基金资助项目“科研信息化应用推进工程(XXH12503)。
蔡 芳(1990-),女,硕士研究生,主研方向:网络协同,推荐系统;沈 一,博士研究生;南 凯,研究员。
2013-03-05
2013-05-03E-mail:caifangzky@sina.cn
1000-3428(2014)05-0295-04
A
TP39
