基于语料库的译者风格分析——以《格列佛游记》两译本为例
2014-07-26司斯
司 斯
(曲阜师范大学 翻译学院,山东 日照 276826)
长期以来,翻译活动一直被认为是一种模仿性的活动,而非创造性的活动,译者也被称作戴着手镣和脚镣的舞者。因此,翻译一直被放在隐性的位置,正如刘宓庆所言“原语风格意义的所在,以及在对原语的风格意义进行分析的基础上获得译文风格对原语风格的‘适应性’”[1](1990:1)。因此传统的翻译风格研究,大多是规定性的研究,运用翻译理论,如奈达的功能对等理论,严复的“信、达、雅”等来看译文是如何最大限度地再现原文、体现原文的风格的。20世纪90年代,语料库语言学蓬勃发展,与此同时描写性译学也逐渐兴起,在这种背景下语料库翻译研究也开始迅速发展。“它借助现代计算机技术,不仅从语言学和比较语言学的角度,而且从政治、意识形态、经济、文化等宏观的角度去研究翻译现象,揭示翻译中存在的概然性法则,系统地总结出翻译文本和翻译过程中的‘翻译总特征’,从而对翻译得到了广角的全面认识”[2](陈伟,72)。因此基于语料库的研究,可以避免译者风格研究中掺杂过多的个人情感因素,研究主观性过强等缺点,发挥其建立在大量数据分析的基础上研究更加客观科学的优势。本文将利用语料库的分析方法,通过分析《格列佛游记》两中译本的词汇特征来探讨译者风格,以期剔除传统研究中的主观因素,使本文研究更加的客观。
一、语料库与译者风格
根据Baker的观点,译者风格指“留在文本中的一系列语言和非语言的个性特征”[3](2000:245)。Baker是把语料库研究应用于译者风格研究的第一人,在她之前几乎很少有人注意到译者的翻译风格特征。她还指出“译者的翻译风格具体表现在文本类型和翻译策略的选择以及译者所运用的前言、后语、脚注、文内解释,以及译者个人偏爱的表达形式和重复出现的语言行为方式。”[3](2000:246)。自此以后,国内外的学者们开始利用语料库对翻译风格进行研究,其中不乏有英国伦敦大学人文科学系博士生自建的关于塞万提斯的《堂吉·柯德》的西班牙语—汉语平行语料库,国内胡开宝教授指导创建的莎士比亚戏剧语料库,燕山大学的红楼梦语料库,以及基于这些语料库做的一些研究。张美芳曾指出“利用语料库进行研究,对一些难以捉摸的不引人注目的语言习惯进行描述、分析、比较和阐释,能比较令人信服地说明译者的烙印确实存在”。[4](2002:57)
二、语料库与检索方案
(一)语料库的创建
本文选取的原创文本是英国十八世纪前期著名的讽刺家和政论家江奈生·斯威夫特的《格列佛游记》的前两卷,共50750字。因为《格列佛游记》曾被许多译者翻译过,而且因为小说中的许多人物特点颇具儿童文学的特色甚至还被翻译成儿童文本,深受儿童的喜爱。因此在选取译本的时候,遵循了以下几个原则:第一,因为其被看作儿童文本,所以在翻译的时候有些译本采取的是编译的翻译策略,导致文本不全,不能准确地反映译者的风格。因此,在选取文本时,首先选取的是对全文的译本。第二,既然要分析译者风格,我们必须要保证译文的质量,必须保证是著名出版社的译本,使研究具有价值可言。第三,为了研究的需要,选取了具有一定时间跨度的译本,相信在不同历史时期译者会有不同的风格。基于以上三点,本文选取的两部汉译文本分别是:1962年人民文学出版社出版的张建译本的前两卷,共80172字,2006年上海译文出版社出版的孙予译本的前两卷,共87808字。以此建立双语平行语料库,并运用此语料库进行译者风格分析。
(二)数据检索和分析
本文通过自行建立的小型语料库,通过AntConc软件检索了高频词、类符/形符比平均句长等,以定量研究为主、定性研究为辅的方法来分析了张译本和孙译本。并且,我们通过这些数据客观直接地分析张译本、孙译本和原文的相符程度,两位译者翻译手法和翻译风格的不同。
1.高频词检索和分析
高频词检索是AntConc最基本的功能,检索的是词汇出现的频率,在这里对出现频率较高的前十位词进行检索和整理。通过表1,可以看出原文中前五位的词中有第一人称代词“I”,后十位词中还含有第一人称的形容词性物主代词“my”,由此可以看出原文多用第一人称来叙述。因此,在译文处理时可以看出张译本和孙译本前十位的高频词中都有第一人称“我”,且都在前五位出现。因为原文小说是一部游记,是主人翁在两个国家(即人们所熟知的小人国和大人国)的游历。所以两位译者在翻译时都注意到这点,把游历者第一人称的身份表现出来了,可以说达到了严复所说的“信”。因为原文中用的形容词性物主代词“my”和所有格“of”较多,因此在翻译时就会产生很多的“的”字,表示的是一种所属或修饰。原文中冠词“a”,使用的频率也较高,张译本和孙译本也都注意到了这点,所以汉语的数量词“一”也都用的很多。纵观张译本和孙译本前十位的高频词,可以发现前五位的高频词几乎是一样的,唯有后五位有些许的不同,比如张译本中用了“把”字而孙译本中却没有用到,到底是哪个译本用词更加准确呢?这可以从文中例子看出。
(1)The Emperor lays on a table,three fine silken threads if six inches long.
张译本:皇帝把三根六英寸长的精美丝线放在桌上。
孙译本:国王在一张平台上放三根精致的绸带,每根绸带有6英寸长。
例一中,张译本翻译时用了“把”字句,孙译本在翻译时直接就是直译下来的。从原文的句子中可以看出“three fine silken threads”虽然放在了后面,可是作的却是句子的宾语。一般来说英语句子SVO这一结构中都会嵌入状语、定语或补语结构等,而且英语习惯将字数多、结构较为复杂的重要信息放到句子的后面,而汉语却习惯将此类词放到前面,因此,出于这一目的需借助“把”字句。据我们所知“把”字句是一种主动句型,其语用功能主要是为了陈述客观事实,发出指令和表达主观情绪等[5](胡显耀、曾佳,2011:70)。而宾语后的句子成分均用于说明受主语发出动作的影响,宾语所指事物的位置、性质或状态的变化[6](胡开宝,2009:113)。因此,我们可以看出张译本使用“把”字句来翻译更符合汉语的表达习惯且能表现出宾语受主语“the emperor”的影响。
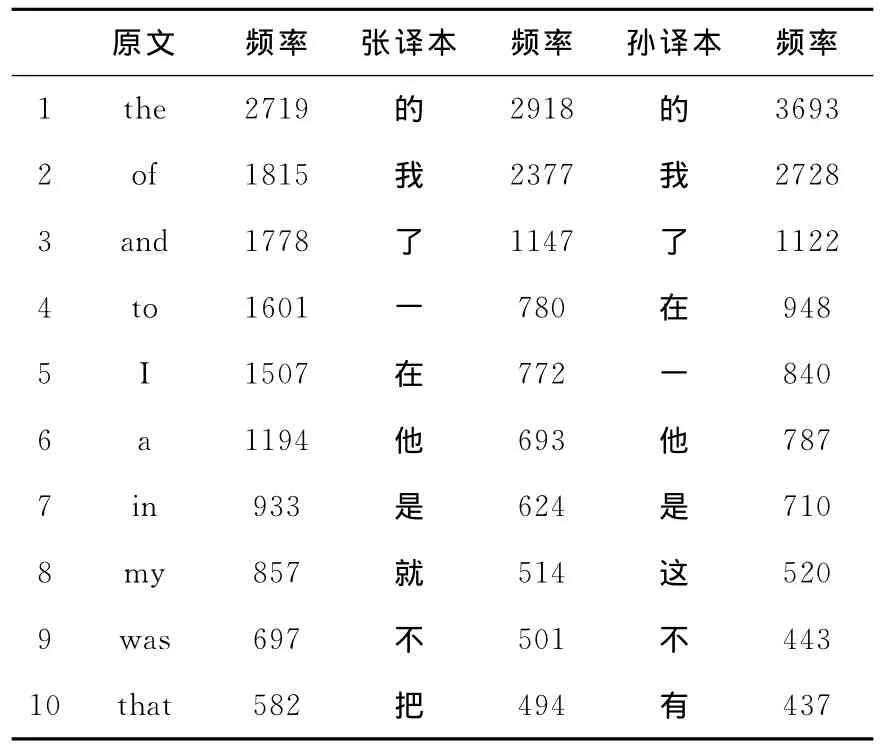
表1 各语料库词表前10位词
2.类符/形符比
类符(type)指文中不同的词,排除重复并忽略大小写,形符(token)指文中所有出现的词[7](Baker,1995)。Baker指出,类符/形符比值(TTR)的高低与写作者词汇使用的丰富程度和多样性成正比。而当所比较的文本长度不同时,类符、形符比值可因类符聚集的均匀程度不同而受到影响,所以使用标准化的类符/形符比值则更为可靠[3](2000:25)。据我们所知,TTR 的值越大,说明此译本用词量大,用词也丰富;反之则说明词汇量小,词汇变化度低,用词丰富度不够。表2是我们用AntConc软件检索出的两个译本的类符/形符比,张译本为7.4%,孙译本为7.6%。由此我们可以看出,孙译本的类符/形符比较大,张译本则较小,但是两者并未相差很大,因此说明孙译本比张译本用词量稍大且词汇丰富。
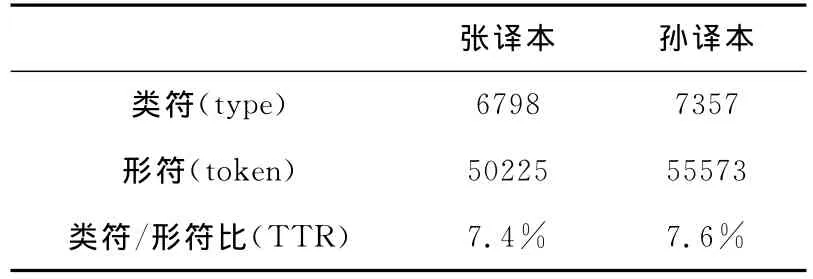
表2 类符/形符比
3.个性词的使用
Baker认为如同手拿一个物体一定会留下手印,译者完成翻译活动时,也一定会留下个人的“痕迹”[3](2000:241-266)。这与翻译家的语言使用习惯、特定历史时期的语言规范有一定的关系。如表3,我们可以清晰地看出,这两个译本中个性词有一定的差异,孙译本中的个性词较之张译本更多。从词性分布来看,形容词、名词、副词和量词分布趋势相似,其中均以个性动词较多,孙译本比张译本多出1147个词,这符合汉语动词活跃的特点。
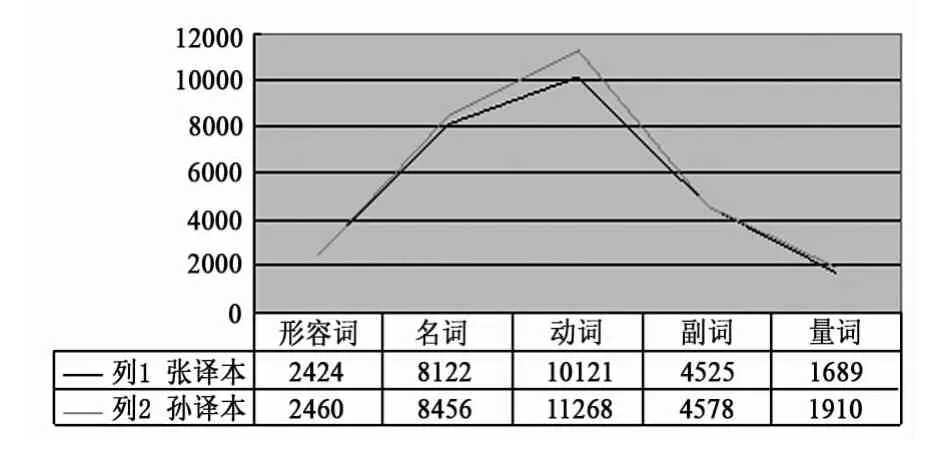
表3 个性词
三、结语
本文基于语料库的方法,利用检索软件,检索出高频词、类符/形符比、个性词等相关的数据,并以此数据来分析两个译本。通过以上分析,我们发现张译本和孙译本在翻译时都遵循了“信”的原则,把原文本都准确地翻译成了中文,并且注意了人称、代词等的变化。其中,张译本更加的严谨,使用词语时更合乎汉语的表达习惯,但是孙译本词汇使用丰富,变化度大,个性词的使用也更丰富。虽然利用语料库的方法进行定量分析,可以避免主观性和随意性,但是本文仍有不足。未来的研究还可以从多个层面、多个角度来分析这两个中文译本,以加深对译者风格的探究。
[1]刘宓庆.翻译风格论[J].外国语,1990,(1).
[2]陈伟.翻译英语语料库与基于翻译英语语料库的描述性翻译研究[J].外国语,2007,(1).
[3]Baker,M.Towards a Methodology for Investigating the Style of a Literary Translator[J].Target,2000,(2).
[4]张美方.利用语料库调查译者的文体——贝克研究新法评介[J].解放军外国语学院学报,2002,(3).
[5]胡显耀,曾佳.从“把”字句看翻译汉语的杂糅特征[J].外语研究,2011,(6).
[6]胡开宝.基于语料库的莎剧《哈姆雷特》汉译文本中“把”字句应用及其动因研究[J].外语学刊,2009,(1).
[7]Baker.M.Corpus in Translation Studies:An Overview and some Suggestions for Future Research[J].Target,1995,(2).
