一种基于分布式rough本体的语义相似度计算方法
2014-05-26常宝娴陈玮玮李素娟
常宝娴,陈玮玮,李素娟
(南京工业大学理学院,南京 211816)
一种基于分布式rough本体的语义相似度计算方法
常宝娴,陈玮玮,李素娟*
(南京工业大学理学院,南京 211816)
针对传统的语义相似度计算方法缺少相应领域本体和精确知识支撑等缺陷,提出一种基于分布式rough本体的语义相似度计算方法.通过半自动构建领域本体保证语义相似度计算的准确度,采用rough的上下近似提高语义相似度计算的精确性,并通过实例验证了该算法的有效性.结果表明:该文方法不仅可减弱对领域专家的依赖,而且还能大幅提高语义相似度计算的查全率和准确率.
rough本体;语义相似度;分布式;远程教育
互联网作为人们获取信息的重要渠道,其规模在不断扩大,如何提高信息的准确度成为目前研究的热点之一.针对现有的网络信息难以运用计算机进行处理的现状,Bemers-Lee[1-2]提出了语义网的概念.而作为语义网基础的本体则采用了规范化语言对概念和关系进行形式化说明,使得计算机理解及互操作成为可能[3-4].与基于语法的信息检索不同,本体在信息检索中的应用能够显著提高检索的精确率和返回率[5].本体信息检索领域中概念的语义相似度计算起着重要的作用.语义相似度的计算通过对本体要素的语义距离或者贴近度的度量,能综合评价本体的复用及重用的可能性,也可作为本体融合与集成等任务的前期评估[6].近年来,国内外出现的语义相似度计算的相关研究成果大多根据某种分类体系来计算,或利用大规模的语料库进行统计,如李鹏等[7]提出基于语义词典的树状层次结构中的路径长度计算语义相似度;夏天[8]提出基于词语空间向量模型统计并计算特征词向量间的相似度.然而,由于分类体系受主观因素影响较大,难以反映客观性能,语料库统计法则因依赖于语料库的优劣而存在数据稀疏的问题,并伴有噪声干扰;因此,Slowinski[9],Ishizu[10]等提出利用rough集扩展本体,以rough关系作为概念的上下近似,从原始语义和数据层面规避了主观性和稀疏性等问题.本文应用rough本体改善基于经典本体的信息检索方法,探讨了rough本体的构建、计算、匹配等关键技术,采用分布式计算方法从现有网页页面提取并构建rough领域本体,建立rough本体语义相似度计算模型,设计相关语义相似度计算算法,并通过远程教育领域语义相似度的计算验证该方法的可行性和有效性.
1 基于分布式rough本体的语义相似度计算
基本步骤:首先根据基于主题相似度判定的垂直搜索引擎框架Nutch算法从初始地址集合中搜集出与研究主题相关的网页集合,然后采用自然语言处理(natural language processing,NLP)处理网页内容,得出资源描述框架(resource description framework,RDF)数据并存入已设计的分布式非关系数据库HBASE(Hadoop database),最后通过本文语义相似度计算算法计算概念间的语义相似度.
1.1 Nutch垂直搜索
采用Nutch搜索引擎框架,有针对性地建立初始网页地址集,利用Nutch垂直搜索算法对网页进行抓取,创建动态判定矩阵

进行主题相关性识别,其中wURL(u)为页面u对应的地址的权值,wCLK(u)为页面u的点击次数对应的权值.wURL(u)=w(u)[δ+(1-δ)S(T,Q)],w(u)为页面的PageRank值,S(T,Q)为所得链接文本T和主题词集Q的相似度,δ为调整参数,一般取0.4~0.8.
1.2 NLP 文本处理
资源描述框架可通过断言三元组表示为

下文简称SPO.断言的主语必须通过通用资源标识符 (uniform resource identifier,URI)识别.谓语必须在词汇表中定义,以便与词汇表的名称空间URI关联.宾语可以通过URI或文本识别,如果该宾语是另一个断言的主语,则其必须通过URI识别.谓语的主要作用是定义主语和宾语之间的关系.通过NLP文本处理工具处理大量文本数据得到相应的断言三元组.
1.3 HBASE存储
根据断言三元组设计成不同的HBASE表结构:SPO(主谓宾)、POS(谓宾主)与OSP(宾主谓).3张表的表定义相同,每张表只包含一个簇列(分布式数据库的访问控制单元),每行数据均存储在一个簇列中.区别在于所存放的数据不同,SPO表的分布式数据库的主键是(主语,谓语),簇列中存放宾语值;POS表的分布式数据库的主键是(谓语,宾语),簇列中存放主语值;OSP表的分布式数据库的主键是(宾语,主语),簇列中存放谓语值.将NLP文本处理得到的断言三元组,根据其位置关系及内容存储至对应的SPO、POS或OSP表中.
1.4 基于rough本体的分布式语义相似度计算算法
将处理得到的SPO近似空间的整个个体全集U划分成等价类集合,即以属性集Q作为等价关系构造近似空间所得到的结果.
定义1 对于概念A,其等价概念集R(A)为所有(S,P,O)三元组中P(O,S)=A的概念的集合,即

定义2 概念A的上近似概念集

定义3 概念A的下近似概念集

定义4 概念A与概念B的粗糙相似度S(A,B)为概念A、B的上近似概念集的交集与概念A、B下近似概念集的交集之和,即
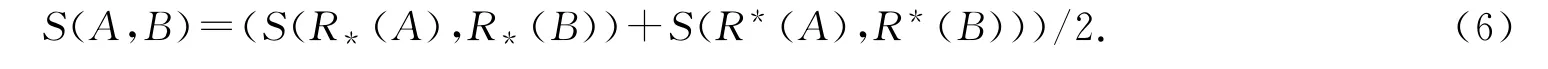
通过上下近似关系可进一步得到
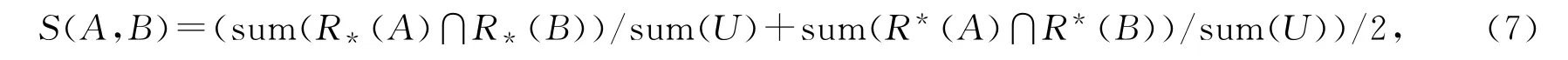
其中sum(·)表示概念出现的次数.
本文算法具体步骤如下:
步骤1 通过HBASE簇分割数据至HBASE每个子域.
步骤2 映射.
1)通过各个子域U i计算概念A,B的等价概念子集R i(A),Ri(B);
2)参考定义2,3计算概念A,B在每个子域里的上下近似概念集R*i(A),(A),R*i(B),(B);
3)计算在每个子域里概念A,B的相似度

步骤3 约简.统计所有子域的相似度,加权求和得到概念A,B的相似度
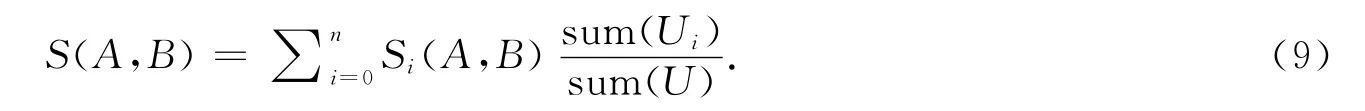
2 实验结果与分析
通过远程教育领域的相关数据测试本文算法,初始网页地址集合选取了教育领域内比较著名的几个网站,如中国现代远程与继续教育网、中国远程教育网、21互联远程教育网、中国农村远程教育网等,将其网址作为Nutch搜索的输入.抓取网站中涉及远程教育资源的页面,参考几个主要网站中重要词汇表选取远程教育资源的重要概念,如课件、试题、教案、素材、问题、答疑、名师、测评、名师课堂、教学视频、试听课程、论文、备课笔记、听课笔记、教育礼仪、教学媒体、学习难点、相似课程、随堂问题、课堂反馈、辅导、信誉评价、学员动态、学生作品、教育评估、模拟考试、技能培训等.根据Nutch垂直搜索算法,筛选出有效页面1 235个,然后对这些页面采用SPO三元组参考重要概念进行数据提取,得到37 542个三元组存入HBASE,依据公式(8)分为10个子域循环计算每两个重要概念间的相似度,最后对每个子域的计算值进行加权求和得到每两个概念的相似度,并与基于Word Net语义相似度[11]的计算结果进行比较,部分结果如表1所示.
由表1可见,本文算法相比简单的关键词匹配算法相似度较高,且在进行大量数据处理时效率较高.
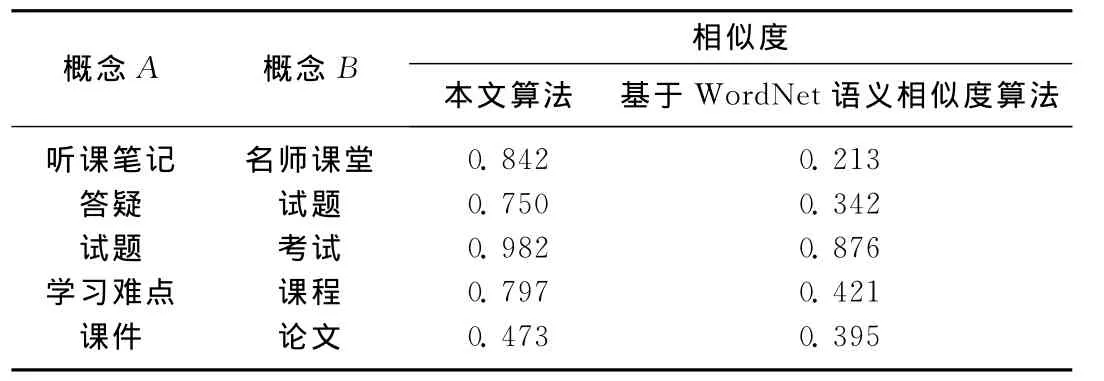
表1 语义相似度计算结果Tab.1 Result of computation
3 结语
本文提出了一种基于分布式rough本体的语义相似度计算方法,其相似度计算准确率较一般语义相似度计算方法高,且处理效率高,为大量数据的查询处理提供了新的方法,对于构建领域本体具备较强的借鉴意义.然而,本文在进行SPO三元组数据提取时,未考虑谓语词汇对概念的影响,一定程度上影响了概念间相似度的准确值,今后将在谓语词汇对语义相似度的影响及领域本体的自动化构建方面作进一步的研究.
[1]BERNERS-LEE T.Long live the web:a call for continued open standards and neutrality[J].Sci Am,2010,303(6):80-85.
[2]BERNERS-LEE T,HENDLER J,LASSILA O.The semantic web:a new form of Web content that is meaningful to computers will unleash a revolution of new possibilities[J].Sci Am,2001,284(5):34-43.
[3]HITZLER P,HARMELEN F V.A reasonable semantic web[J].Semant Web,2010,1(1):39-44.
[4]孙茂圣,朱俊武,李斌.一个基于agent组织的web服务集成框架 [J].扬州大学学报:自然科学版,2009,12(4):60-65.
[5]TAGARELLI A,GULLO F.Evaluating PageRank methods for structural sense ranking in labeled tree data[C]//Proceedings of the 2nd International Conference on Web Intelligence,Mining and Semantics.New York,USA:ACM,2012:129-174.
[6]徐健,方安,洪娜.一种基于词语相似度计算的本体映射方法 [J].现代图书情报技术,2013,29(2):36-42.
[7]李鹏,陶兰,王弼佐.一种改进的本体语义相似度计算及其应用 [J].计算机工程与设计,2007,28(1):227-229.
[8]夏天.汉语词语语义相似度计算研究 [J].计算机工程,2007,33(6):191-194.
[9]SLOWINSKI R,GRECO S,MATARAZZO B.Rough sets in decision making[M]//MEYERS R A.Encyclopedia of complexity and systems science.New York:Springer,2009:7753-7787.
[10]ISHIZU S,GEHRMANN A,NAGAI Y,et al.Rough ontology:Extension of ontologies by rough sets[M]//HUTCHISON D,KANADE T,KITTLER J,et al.Lecture notes in computer science.Berlin:Springer-Verlag,2007,4557:456-462.
[11]ZHAO Lihua,ICHISE R.Aggregation of similarity measures in ontology matching[C]//The 5th International Workshop on Ontology Matching.Shanghai:[s.n.],2010:423-441.
A distributed computing method of semantic similarity based on rough ontology
CHANG Baoxian,CHEN Weiwei,LI Sujuan*
(Coll of Sci,Nanjing Univ of Technol,Nanjing 211816,China)
This paper presents a distributed computing method of semantic similarity based on rough ontology and improves the precision according to ontology,the completeness according to the upper approximation and low approximation of rough theory.It also improves the independence according to distributed data processing.An experiment of gathering web pages automatically of remote education is used to construct domain rough ontology and compute the semantic similarity.The experiment shows that the algorithm not only reduces the dependence of domain experts,but also greatly enhances the rates of completeness and precision.
rough ontology;semantic similarity;distributed;remote education
TP 311.51
A
1007-824X(2014)01-0060-03
2013-09-05.* 联系人,E-mail:lisujuan1978@126.com.
江苏省高校自然科学基金资助项目(11KJB520006).
常宝娴,陈玮玮,李素娟.一种基于分布式rough本体的语义相似度计算方法 [J].扬州大学学报:自然科学版,2014,17(1):60-62,66.
(责任编辑 林 子)
