基于云模型构造BPA的瓦斯监测证据合成算法
2014-03-22黄丹丹
陈 强,李 彬,卢 愿,黄丹丹
(江西理工大学电气工程与自动化学院,江西赣州341000)
基于云模型构造BPA的瓦斯监测证据合成算法
陈 强,李 彬,卢 愿,黄丹丹
(江西理工大学电气工程与自动化学院,江西赣州341000)
煤矿瓦斯监测中,利用D-S证据合成方法实现多传感器信息融合可以提高系统整体决策和预警能力.根据煤矿安全规范设定区域危险等级,使用云模型建立危险等级属性隶属度曲线簇,输入传感器检测量提取各属性隶属度作为D-S融合的基本概率赋值.为了实现高度冲突证据合成,提出D-S与加权平均法混合的分步证据合成算法.仿真结果表明文中提出的算法合成高度冲突证据时,具有令人满意的收敛效果.
瓦斯监测;信息融合;云模型;D-S证据合成
0 引言
瓦斯监测是煤矿安全监测最重要的方面之一.煤矿瓦斯局部区域用于瓦斯监测的主要有CH4、温度、风速/负压、CO等传感器.国内现行瓦斯监测监控系统大多只能在监测参数出现超限之后才作出被动的应急反应,缺乏危险到来前的预判和预警功能.对各种瓦斯监测传感器信息进行智能化融合,充分利用多传感器信息的互补性可以提高系统所提取信息的有效性和可靠性,提升系统整体决策和预警能力.中国是瓦斯灾害频发国家,对这方面的需求显得更为迫切.煤矿安全监测和预测中需要解决的关键问题之一是井下(区域)安全状态评判问题.山东科技大学曹庆桂等[1]人通过建立煤矿风险预警指标体系,提出了一个基于BP神经网络和D-S证据理论的煤矿风险预警方案;使用BP神经网络输出结果构造证据理论的基本概率赋值
(BPA),获得了较为令人满意的评价效果.但是,BP神经网络需要预先获得一定数量的训练样本对其进行学习训练才具有实用价值.而煤矿安全监测中要获取大量由实际监测数据与安全状态一一对应的训练样本常常是极为困难的,使这一方法的应用范围受到限制.中国神华万利煤炭分公司王占勇和中国矿业大学马震等[2]人使用灰色关联分析法,通过将多个传感器的实测数据与矿井安全等级参考向量进行关联度计算,将所得的关联度大小排序,选择一个关联度最大的向量对应的安全等级作为评判值.这一方法有一定效果,但当被测量对应的参考向量数值分布区域处于无上限或无下限区域时,这一方法并不适用.因此这一方法同样存在严重的局限性.研究中尝试使用云模型构造证据理论的基本概率赋值(Basic Probability Assignment,BPA).
1 基于云模型的BPA构造方法
1.1 云模型和隶属云
云模型是中国学者李德毅[3]针对模糊集合论中的隶属函数提出的.“隶属云”概念为解决模糊与精确相结合的问题开辟了一条新的途径.如今云模型已被广泛应用于数据挖掘与知识发现、系统评测、决策支持、智能控制、网络安全等领域.李德毅将模糊学中的隶属度概念加以发展得到形象化的隶属云概念;通过隶属云的定义,将模糊性问题的亦此亦彼性和隶属度的随机性进行了统一的刻划;在精确定量值与不确定定性描述之间架起了一座有效的桥梁,因而具有广泛的应用价值.
隶属云定义如下:设X是一个普通集合,X={x}称为论域.关于X论域中的模糊集合A,是指对于任意元素x都存在一个有稳定倾向的随机数μA(x),叫做x对A的隶属度,如果论域中的元素是简单有序的,则X可以看作是基础变量,隶属度在X上的分布叫做隶属云.如果论域中的元素X不是简单有序的,而根据某个法则,可将X映射到另一个有序的论域X′上,X′中的一个且只有一个x′和x对应,则X′是基础变量,隶属度在X′上的分布叫做隶属云.隶属云就象一朵远看有形,近看无形的云彩,其期望曲线近似服从正态分布或半正态分布.而论域上某一点的隶属度分布符合统计意义上的正态分布规律.如图1为隶属云及其数字特征.隶属云隐含了三次正态分布规律,记作:N3(x0, b2,σ2max),其中x0,b,σmax分别称为隶属云的期望值、带宽和方差,它们被用来表征隶属云的三个数字特征.
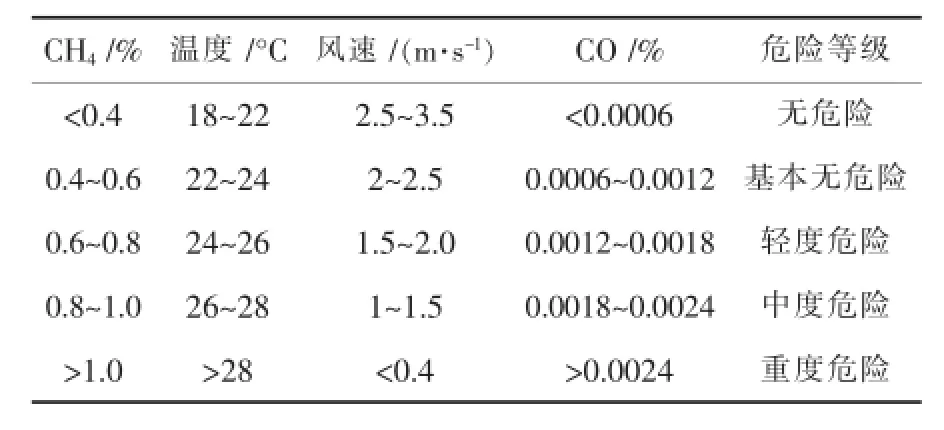
表1 危险等级对应的检测量分布

图1 隶属云及其数字特征
1)隶属云的期望值x0.隶属云期望曲线符合正态分布规律,图1中的A点即为期望正态分布的顶点,在此处x=x0,μ(x)=1;
2)隶属云的带宽b.带宽b刻划隶属云中模糊概念的裕度,在隶属云期望曲线B点处有x=x0+ 3b,μ=0.0111;


1.2 瓦斯监测检测值与危险等级评价值的转换
现将煤矿安全状态参照国家煤矿安全规范划分为无危险、基本无危险、轻度危险、中度危险和重度危险5个等级(如表1).每一个危险等级都有其对应的大致分布区域.例如:CH4轻度危险对应的体积分数是在0.5%~0.9%的区域,其中间值为0.7%.因此可用一正态分布曲线来描述在这一区域体积分数值对“轻度危险”的隶属程度,这一曲线即是云模型中的平均隶属度曲线.同样的道理,对于全部的检测量及各危险等级,均可用相同的方法来描述实际检测值与危险等级之间的隶属程度关系,将这些曲线叠加起来就得到图2所示的平均隶
属度分布曲线簇.通过这些曲线簇即可将定量的检测参数转换为相应的危险程度等级.图2中的(a)、(b)、(c)、(d)分别为CH4、温度、风速和CO传感器检测量对应各危险等级的平均隶属度分布曲线簇.图中基本无危险、轻度危险和中度危险的平均隶属度分布均为正态分布曲线,无危险和重度危险对应的均为半边正态分布曲线.图2中各正态分布曲线的x0值通过表1中的参数分布范围得到.对应不同检测量的带宽互不相同.设CH4、温度、风速和CO四种平均隶属度分布曲线带宽分别为b1、b2、b3、b4.根据文献[3]分别可计算出:b1=0.0667,b2= 0.667,b3=0.1667,b4=0.0002.
现有江西某煤矿采煤工作面监测点日常某一时点监测数据如下:CH40.73%、温度23.5°C、风速1.9 m/s、CO 0.00175%,使用式(1),代入各相应的期望值x0和计算出的各带宽值,计算得各检测量对应的各危险等级的隶属度如表2.当隶属度小于0.001时被近似为0.由于对应任一检测量的各危险等级隶属度之和小于1,只要将1与各危险等级隶属度总和之差值分配给不确定区间,即可满足D-S融合的归一化条件.因此可将这些隶属度视作对各属性值的基本概率赋值(BPA).这样就可对各种传感器检测结果使用D-S证据理论进行融合.
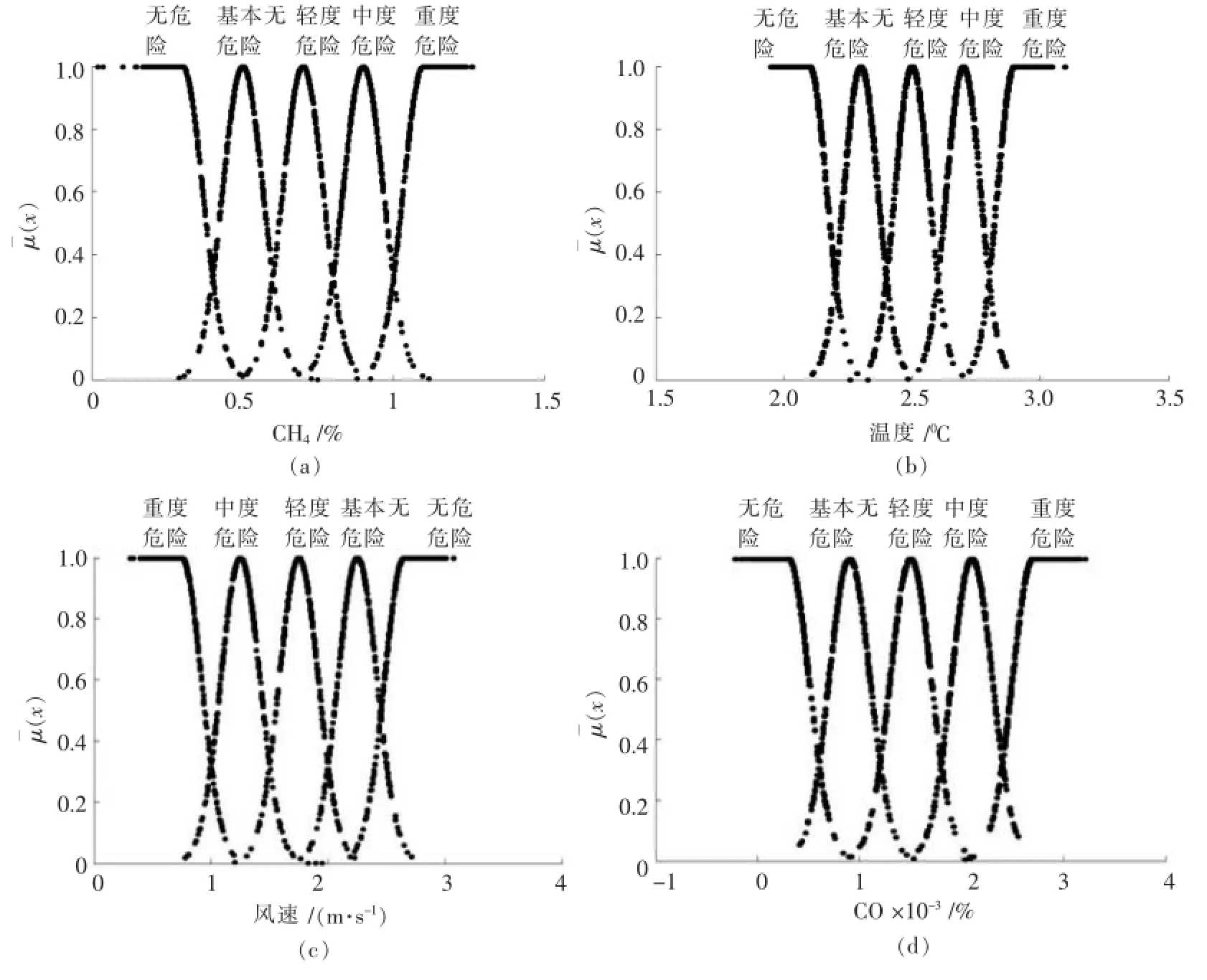
图2 CH4、温度、风速和CO传感器检测量对应各危险等级的平均隶属度分布曲线簇

表2 检测量对应的各危险等级隶属度BPA
2 D-S证据理论和D-S证据合成公式
D-S证据理论是20世纪70年代由Dempster[4]提出,后由Shafer[5]加以补充发展后形成的一种信息融合方法.设空间Θ={x1,x2,…,xn}由一些互斥且穷举的元素组成,称为辨识框架.Θ的幂集2Θ形成一个命题集合,定义函数m:2Θ→[0,1],如果集合中的任一命题A(Aє2Θ)满足:

则称m为A的基本概率赋值(BPA,亦称基本信任分配).如果m(A)>0,则称A为焦元.对于相互独立的2个证据源m1(*),m2(*),Dempster[4]提供了如下经典合成公式:

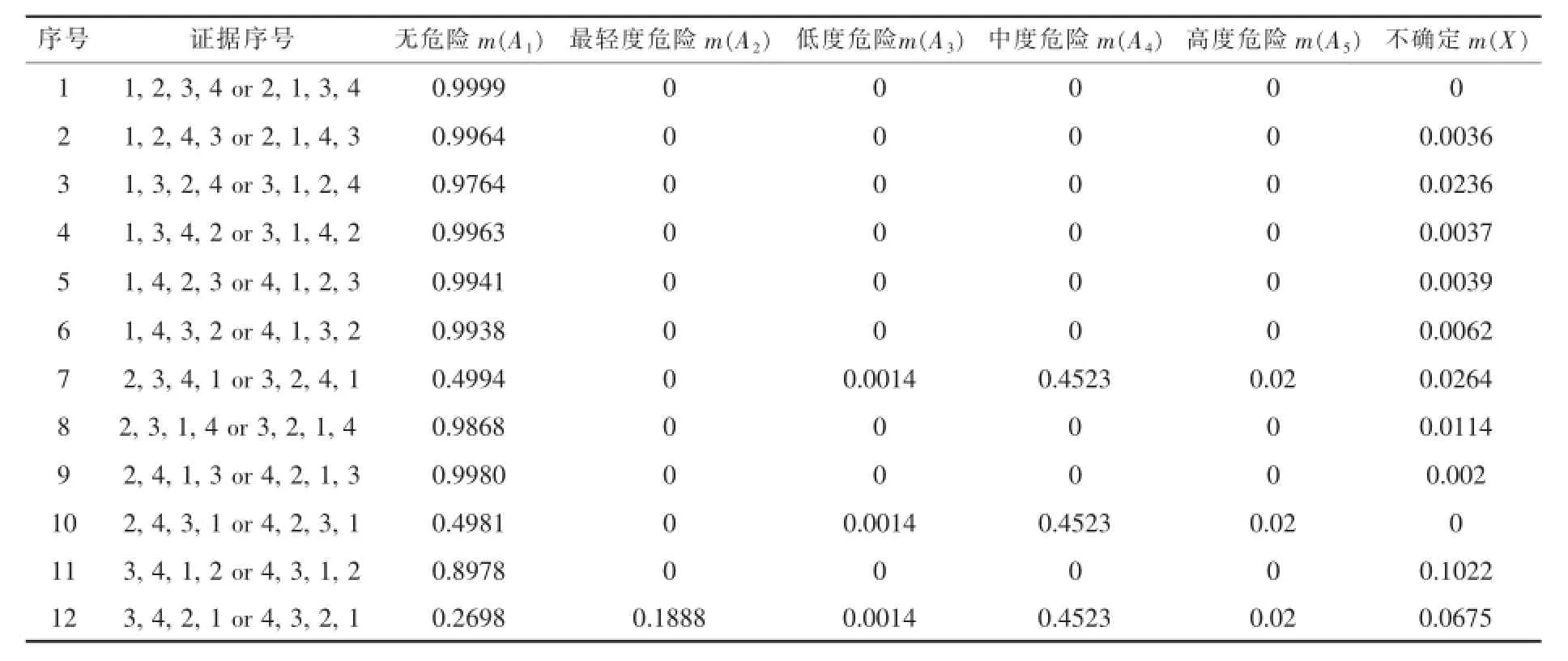
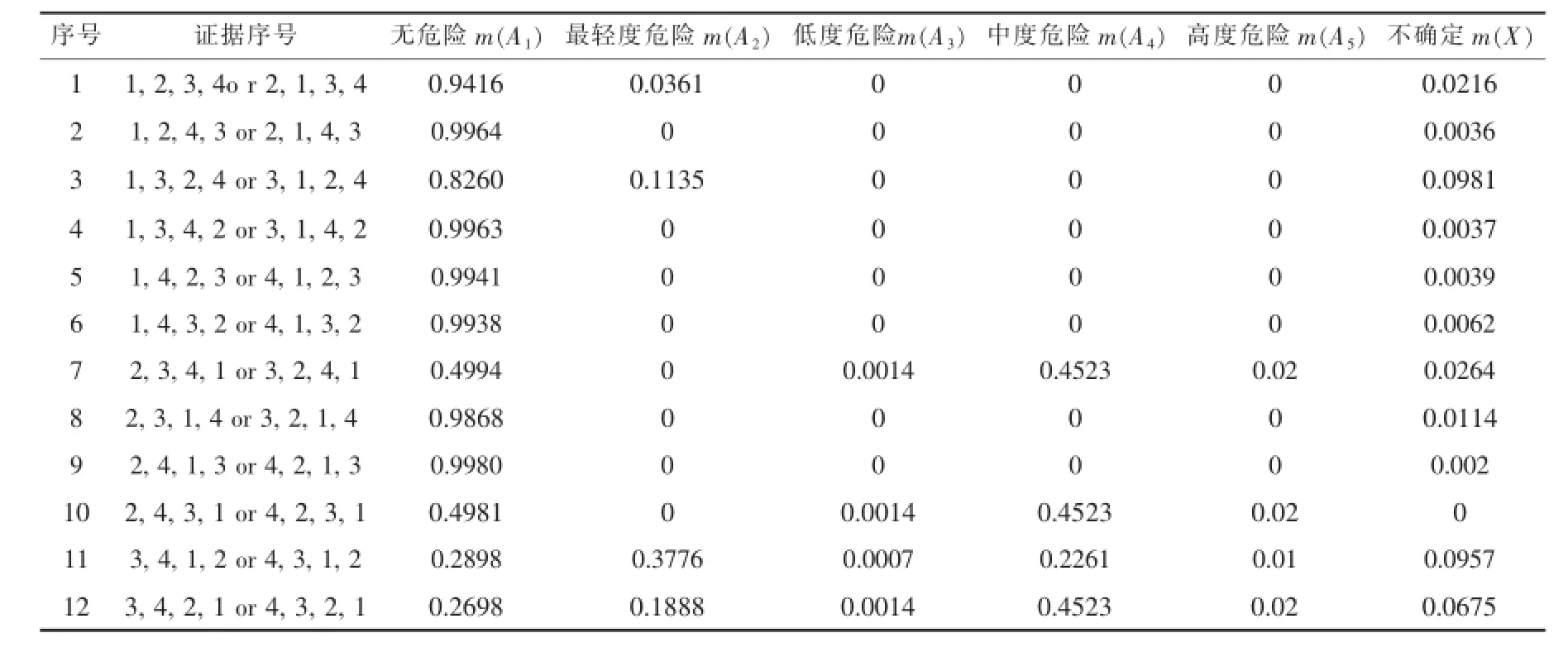
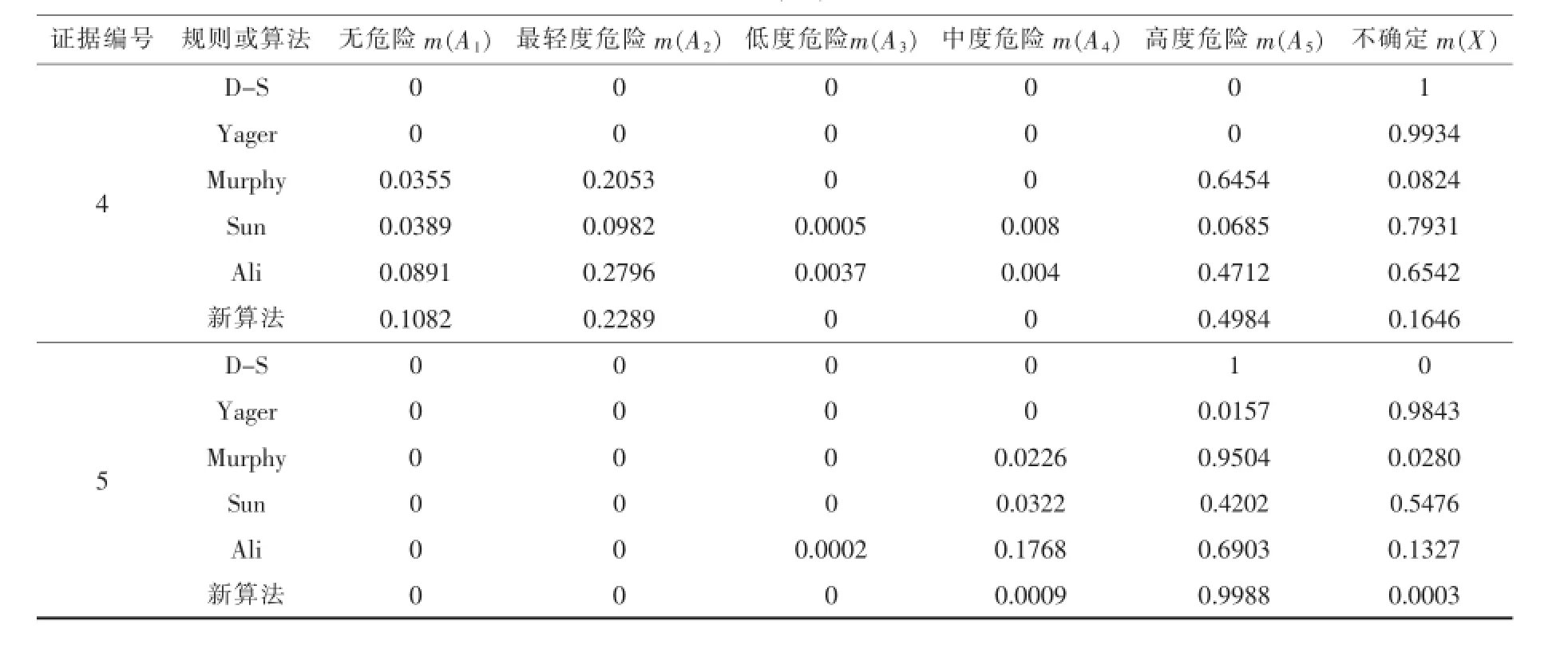
式(3)和(4)中的K值表示各项证据的相互冲突程度.当K=1时表示各方面证据极度冲突,无法进行证据合成.事实上,如果,将使合成后的m(A)<0,同样无意义,因此,多个证据相互合成的先决条件是0 3.1 国内外学者提出的改进措施 使用Dempster的经典D-S证据合成公式合成两个高度冲突证据时,常常得到有违常理的结果[6].针对这一问题,国内外学者已经提出了很多改进规则或算法.改进方案大体可分为两类:一类属于规则修改方法;另一类是证据修改方法.Yager[7]提出了一种改进方法,取消了D-S证据合成中的归一化因子,并将冲突信息全部赋予不确定项.虽然该方法可以避免极端的合成结果,但由于大多数信任分配给不确定项,在处理许多实际问题时,仍无法带来满意效果.其合成公式如下: 这里,权重由证据的可靠性或重要性决定.该方法可以较好地解决高度冲突证据合成问题,但其合成结果的收敛效果差一些.至于如何确定权重是一个需要进一步研究的问题.因此,作者认为这种方法不太适合单独使用,但可以与其他方法结合使用.Murphy[8]提出的改进方法是:首先,求取各证据的平均可信分配,然后使用经典合成规则,反复使用先平均,后合成的方法,对证据进行K-1次合成. Murphy方法的计算过程较为繁复,合成结果的收敛性也需进一步改善.Lefevre[9]提出的改进方案是根据现实情况重新分配冲突的那部份信任分配.阿里[10]提出一种证据修改规则,借鉴两个事件的联合概率实现证据信任分配的修改.在文献[11-19]中,国内学者们也分别提出了多种不同改进方法.合成结果得到不同程度的改善.他们的方法大体都是结合经典的D-S方法和平均法.高度冲突证据合成时,更新BPA的主要部分来自BPA的平均值乘以一定的加权系数.加权系数则是通过计算证据之间的相互支持程度或证据距离确定的.这些方法可以避免传统D-S方法的一票否决现象或出现不合常理的结果.但现有大部份改进规则的计算过程都比较复杂.作者认为,如果加权平均方法只提供证据合成的中间结果,且最后合成结果能令人满意,则加权平均法可视作一种简单而有效的缓解冲突方法.因此,提出一种将经典D-S方法与加权平均法混合交替使用的新型合成算法. 3.2Dempster合成公式与加权平均法混合的分步合成算法 新合成算法如下: 1)根据设置的可信分配值上限(0.9999)预处理所有的证据数据和,设置加权平均法的加权系数和冲突阈值Kmax; 2)计算待合成的两个证据的冲突程度K; 3)如果K 4)如果所有证据合成完毕,则保存最后结果并退出.否则,设置当前合成结果为第一个证据,提取下一个证据作为第二个证据等待合成,回到2). 关于冲突阈值如何确定的问题.在实际情况下,高度冲突证据与非高度冲突证据之间较难作出明确的区别.使用新算法合成时,如果非高度冲突情况被视为高度冲突,可能降低合成结果的准确性.如果情况相反,将高度冲突视作非高度冲突,则可能无法得到融合结果.因此,作者宁愿非高度冲突情况被视为高度冲突,而不是相反.作者选取了煤矿瓦斯监测中具有典型意义的多组数据样本进行阈值Kmax的合理取值范围,以及证据使用顺序对最终合成结果的仿真研究(详情参见4.1).研究结果表明:当Kmax≥0.98时,有时会得到不合常理的合成结果;当Kmax≤0.96时,合成结果的收敛程度有时会下降;当0.96≤Kmax≤0.98时,既可获得较好的收敛效果,又不会出现不合常理的合成结果.因此作者建议:Kmax=0.96~0.98.这一阈值对于决定是否适用Dempster合成公式进行证据合成具有普遍的参考意义.此外,作者进行的多个仿真实例表明,使用新算法合成时,证据使用的先后顺序有时会对最终合成结果的收敛程度产生影响.其原因是由于证据顺序的不合理,导致最后一步合成中,因冲 突程度超过阈值,被迫选用平均法进行合成,使最终合成结果收敛程度不够令人满意.此时,如果按照尽可能避免在最后一步合成中选用平均法的原则,试探性地改变证据顺序,往往能获得收敛程度明显好得多的合成结果(详情参见4.1). 表3 5个证据样本与危险等级对应的BPA值 表4 证据2中证据顺序对新算法合成结果的影响之一(Kmax=0.95) 收集了5组从某煤矿瓦斯监测系统提取的冲突样本数据(如表3).这些样本代表5种经常出现在煤矿井下的不同情况(1个正常样本和4个异常样本). 4.1 证据顺序和阈值Kmax对合成结果的影响 为了研究证据顺序和阈值Kmax对最终合成结果的影响,作者选取表3中的证据2,在选取Kmax=0.95和Kmax=0.97两种不同情况下,分别对证据2中4组证据的全部24种可能的证据顺序情况进行了新算法合成仿真研究,仿真结果如表4所示.仿真结果表明. 1)在大多数证据顺序情况下(66.7%),新算法最终可以获得高度收敛的合成结果;少数证据顺序情况下(33.3%),最终合成结果的收敛程度不够令 人满意.出现这种情况的原因是最后合成步骤使用了平均法; 2)实际合成中,有时可以通过改变证据顺序避免令人不满意的合成结果; 表5 证据2中证据顺序对新算法合成结果的影响之二(Kmax=0.97) 表6 新算法(Kmax=0.97)与国内外一些代表性改进规则对5种不同冲突程度证据合成结果的对比 3)当Kmax=0.95时(见表4),有8种证据顺序情况合成结果的收敛程度不够令人满意;而当Kmax= 0.97时(见表5),只有6种证据顺序情况合成结果的收敛程度不够令人满意.这表明合理地增大Kmax可改进某些合成结果的收敛程度. 4.2 新算法与国内外一些代表性改进规则合成结果对比 作者分别使用经典的D-S证据合成方法、几种国内外代表性改进方法和作者提出的算法进.行合成有效性对比测试.测试结果如表6所示.测试结果表明: 1)多数情况下,新算法的最终合成结果比表列的代表性改进规则具有更好的收敛效果和较小的不确定性. 2)在证据6的合成中,出现了不够收敛的合成结果.出现此结果的原因是,在最后一步合成中,加权平均法被选用.可见,使用本文算法时,应尽量避免在最后一步使用加权平均法.如果将证据 行2和4互换,最后合成结果将是A1=0,A2=0,A3=0, A4=0,A5=0.9923,X=0.0073.这使合成结果的收敛效果得到了明显改善.因此,可通过适当调整证据顺序改善合成结果的收敛性.此外,作者认为可以合理地调整加权平均法的加权系数来改善合成效果,并使合成结果更符合工程实际.具体实施方案是本课题有待进一步深入研究的问题. 表6 (续) 理论研究和仿真结果表明:作者提出的将井下区域危险程度等级作为证据焦元,使用云模型构造D-S证据合成的BPA是一种可行且有效的方法.与国内外一些代表性改进规则相比较,作者提出的算法合成计算过程相对较为简捷;合成高度冲突证据时,多数情况下其合成结果的收敛效果较为令人满意.使用新算法合成高度冲突证据时,如果最后一步选用平均法,可能会使合成结果的收敛性变差.但如果适当调整证据顺序,可明显改善合成结果的收敛性. [1]曹庆贵,张广宇,张建.基于神经网络和证据理论的煤矿风险预警模型[J].矿业安全和环保,2011,38(1):587-590. [2]王占勇,马震,王青青.煤矿瓦斯监测多传感器信息融合方法研究[J].煤炭科技,2010,2(2):1-3. [3]李德毅,孟海军,史雪梅.隶属云和隶属云发生器[J].计算机研究与发展,1995,32(6):15-20. [4]DempsteA.Upperandlowerprobabilitiesinducedbya multivaluedmapping[J].AnnalsofMathematicalStatisti,1967,38:325-339. [5]Shafer G.A mathematical theory of evidence[M].Princeton:Princeton University Press,1976. [6]Zadeh L.A simple view of the Dempster-shafer theory of evidence and its implication for the rule of combination[J].AI Magazine 1986,7(2):85-90. [7]Yager R R.On the Dempste–shafer framework and new combination rules[J].Information Sciences,1987,41(2):93-137. [8]Murphy C K.Combining belief functions when evidence conflicts[J]. Decision Support Systems.2000,29(1):1-9. [9]LefevreE,ColotO,VannoorenbergheP.Belieffunction combination and the conflict management[J].Information Fusion, 2002,3(2):149-162. [10]Tazid Ali,Palash Dutta,Hrishikesh Boruah.A new combination rule for conflict problem of dempster-shafer evidence theory[J]. International Journal of Energy,Information and Communications, 2012,3(1):35-40. [11]孙全,叶秀清,顾伟康.一种新的基于证据理论的合成公式[J].电子学报,2000,28(8):117-119. [12]李弼程,王波,魏俊,等.一种有效的证据理论合成公式[J].数据采集与处理,2002,17(1):33-36. [13]邓勇,施文康.一种改进的证据推理组合规则[J].上海交通大学学报,2003,37(8):1275-1278. [14]肖明珠,陈光禹.一种改进的证据合成公式[J].数据采集与处理, 2004,19(4):467-469. [15]潘恺,李辉,邢钢.基于置信距离的冲突证据合成方法[J].计算机工程,2013,39(1):290-293. [16]权文,王晓丹,王坚,等.一种基于局部冲突分配的DST组合规则[J].电子学报,2012,40(9):1880-1884. [17]董增寿,邓丽君,曾建潮.一种新的基于证据权重的D-S改进算法[J].计算机技术与发展,2013,23(5):58-62. [18]刘希亮,陈桂明,李方溪,等.采用聚类分析的冲突证据判定及合成方法[J].红外与激光工程,2013,42(10):2853-2857. [19]蒲书缙,汪志强,甘建超.冲突证据合成规则及其合理性的研究[J].电子信息对抗技术,2010,24(1):25-30. Evidence combination algorithm based on BPA generated by cloud model for gas monitoring CHEN Qiang,LI Bin,LU Yuan,HUANG Dandan D-S evidence combination can improve overall decision and early warning capability in coal mine gas monitoring system.In this study,the danger levels of local region in coal mine are defined according to coal mine safety specification.Cloud model is used for generating the curve clusters of the membership degrees corresponding to the danger levels.The membership degrees extracted from the curve clusters are regarded as basic probability assignment for D-S evidence combination.The study puts forward a step-by-step combination algorithm mixing D-S method and the weighted average method for severe conflicting evidence combination. The simulation results show that the proposed algorithm has satisfactory convergence effect on severe conflicting evidence combination. gas monitoring;information fusion;cloud model;D-S evidence combination TP79;TD82 A 2014-05-10 江西省教育厅科技资助研究项目(GJJ13398);江西省研究生创新专项资金资助项目(YC2013-S195) 陈强(1964-),男,教授,主要从事矿井、矿山安全监测、人工免疫理论及应用等方面的研究,E-mail:ls6400@126.com. 2095-3046(2014)05-0062-07 10.13265/j.cnki.jxlgdxxb.2014.05.0123 对D-S证据合成方法的改进
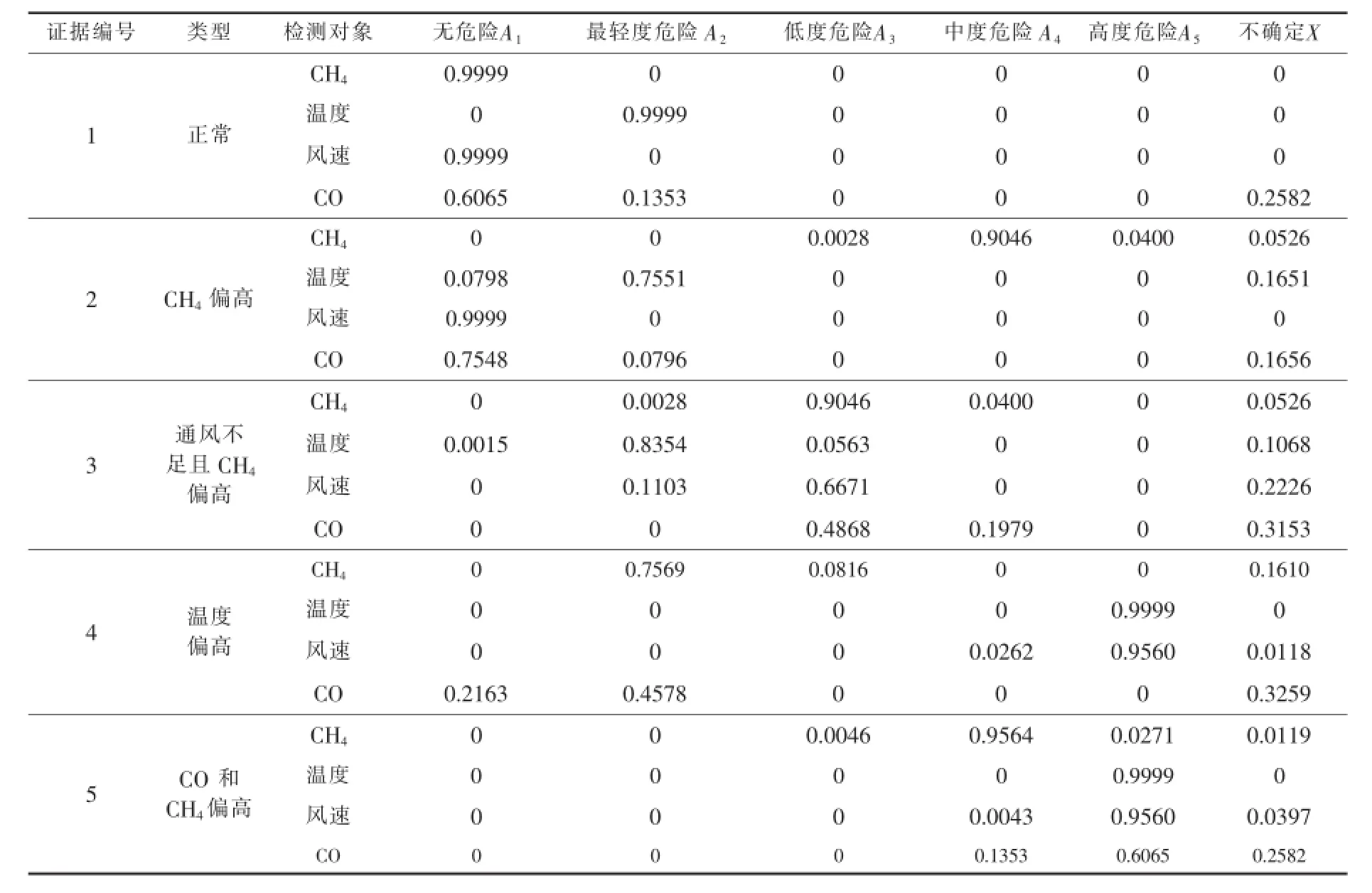
4 仿真结果和分析

5 结论
(School of Electrical Engineering and Automation,Jiangxi University of Science and Technology,Ganzhou 341000,China)
