基于并行粒子群优化算法的蛋白质二级结构预测
2014-03-19周文刚毋红军
周文刚,毋红军,孙 挺
(1.周口师范学院 计算机科学与技术学院,河南 周口466001;2.华北水利水电大学 数学与信息科学学院,河南 郑州450011)
目前,业界出现了许多通过计算智能方法预测蛋白质结构的算法,各有所长,亦各有局限.基于知识的算法中,比较典型的有:王栋等[1]实现了基于并行多类支持向量机的蛋白质结构预测,通过加权一对多的多类分类方法,能获得明确的结构类判别结果,但是对二元分类的错误非常敏感;张斌等[2]基于RBF神经网络并结合主成分分析,提高了预测精度和速度,但不同的阅读窗口存在不同的最优扩展函数,普适性不强.在基于分子动力学的算法中,比较典型的有:栾忠兰等[3]基于Backrub模型,实现了并行扰动蛋白质骨架和侧链的运动模型,能快速准确捕捉蛋白质天然构象的波动,提高了对点突变侧链的预测精度,但其是在OpenMP的锁机制下实现对构象骨架和侧链的同时扰动,并行粒度需要进一步细化;陈沙沙等[4]提出基于折叠模式的蛋白质三维结构片段库构建方法,使用骨架预测并行蚁群算法生成候选三维结构集,对于低同源目标可以得到更接近天然的三维结构,但对于一些特殊蛋白质不能正确预测.
充分考虑到蛋白质结构复杂、立体化的特点,综合现有文献的研究结果,对于全新的或者低同源的蛋白质二级结构预测来说,从头预测法有着算法简单、容易并行化的特点.本文基于分子动力学理论,以Toy模型的蛋白质结构为研究对象,介绍一种基于混沌扰动的、具有完全学习策略的量子行为粒子群算法,并基于CUDA,使用该算法实现了对蛋白质二级结构的并行预测.
1 蛋白质结构预测
Stillinger提出的Toy模型是结构比较简单、能量容易计算,又比较准确接近真实结构的模型.它将氨基酸根据疏水性(A)和亲水性(B)分为两类,在二维平面上用单位长度的键把氨基酸按顺序依次相连并折叠成一个线性链.设残基序列记为ξ1,ξ2,…,ξn,其相邻残基间的二面角角度值序列记为θ1,θ2,…,θn-1,其中,ξ1,ξ2间的连接是整条残基旋转的基准,因此θ1≡0,θi是以ξi-1ξi间的连线为基准,ξiξi+1间旋转的角度,值为负时表示逆时针旋转.
Toy模型不考虑分子间的相互作用,把蛋白质序列的能量简化为分子内部的主链弯曲势能V1和非绑定残基相互作用能量V2两部分,V1只和弯曲角度有关,V2与任意两个不相邻残基的极性和距离相关.一个由n个残基组成的蛋白质序列的能量函数记为
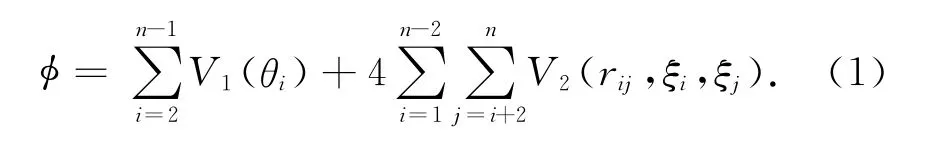
其中
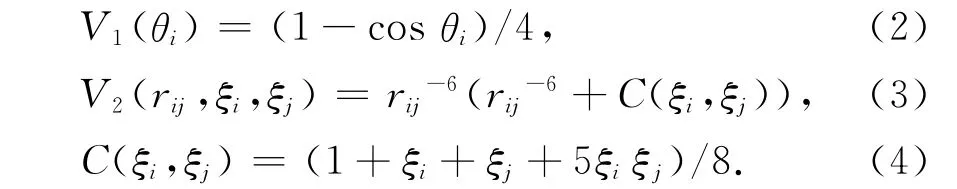
对式(4),将残基用ξ1,ξ2,…,ξn表示,当残基i为疏水性时ξi=1,否则ξi=-1.
这样,蛋白质二级结构预测就简化为寻找一组能使式(1)表征的能量值最小的相邻残基间二面角序列的问题.
2 融合混沌优化与完全学习策略的量子行为粒子群(C-CLQ-PSO)并行算法
2.1 具有完全学习策略的量子行为粒子群算法
粒子群优化(PSO)算法的基本思想来源于社会认知理论,其进化公式除包含粒子前一时刻的信息之外,还加权融合了进化过程中的粒子自身经验信息和群体共享信息,具有易实现、不受解空间限制性假设的约束等优点.但实践表明,PSO算法在求解复杂多峰问题时易早熟,因此,在求解不同的最优化问题时,要根据问题的数据特点改进粒子进化公式.
有不少文献致力于改善粒子群算法易早熟、精度低的缺点.申元霞等[5]提出了相关性粒子群优化模型,建立了粒子对自身经验信息和群体共享信息认知的内在联系.陈伟等[6]提出了具有完全学习策略的量子行为粒子群(CLQPSO)算法,在迭代更新时能充分利用种群中所有粒子当前最佳位置所提供的社会信息,并且通过粒子间的社会合作行为来提高种群多样性,可在更广泛的潜在区域中搜索优化问题的最优解,改善了算法在求解多峰优化问题时的全局收敛性能.张少辉等[7]在惯性权重非线性递减策略的基础上,引入小阻尼振荡函数,对粒子优化过程进行非线性递减随机扰动,加快了收敛速度,在一定程度上避免了早熟.
笔者针对陈伟提出的CLQPSO算法,对收缩扩张因子等参数的取值进行改进,提高了算法的收敛速度和精度.改进后的算法描述如下:对最优化问题P,在解空间范围内,初始化m个随机的可行解,每个可行解视为一个粒子.假设粒子在量子空间中运行并具有量子行为.做以下假定:
记粒子i在搜索空间中的某时刻t的位置为:Xi(t)=(xi1(t),xi2(t),…,xiD(t)),D为可行解的维数.根据问题性质,确定一个评价粒子X接近最优解程度的适应度函数f(X).
记搜索过程中粒子i当前最靠近问题P全局最优解的最佳值为Pi=(pi1,pi2,…,piD).
记粒子i的局部吸引子qi=(qi1,qi2,…,qiD),则具有完全学习策略的量子行为粒子群聚类算法的粒子进化公式为

其中α为控制粒子收敛速度的收缩扩张因子,u为(0,1)范围内均匀分布的随机数.u>0.5时,α前的符号取+,否则取-.实验表明,当α<1.782,可保证算法收敛[6].对于远离全局最优解的粒子,α的取值应该小一些,反之应该增大α值.通过自适应机制对α的取值进行变化可以让QPSO具有较好的收敛性能,式(6)是一个决定α值的自适应经验公式.

其中,z=lg(ΔF),

误差ΔF表示粒子Xi与全局最优位置g的接近程度.对于一个确定的粒子来说,误差ΔF越小就表示该粒子离全局最优值越接近,此时粒子的搜索范围也应随之缩小.
式(5)中,qij(t)=pfi(j)j(t)表示:t时刻粒子i的局部吸引子qi第j维qij(t)的值,随机取自粒子群中各粒子在t时刻最佳位置的对应维(即列坐标要一致)的值.pfi(j)j(t)中用来确定粒子编号的函数fi(j)的取值按如下规则确定:
对粒子i,引入参数学习概率[6]

pci值的大小决定了粒子i的全局勘探和局部开发能力.对粒子i的每一维,如第j维,产生一个随机数,若该数大于pci,则fi(j)=i,即qij(t)=pij(t),表示取当前粒子i的t时刻最佳值的第j维的值;否则,就需要向其他粒子学习,即在粒子群中随机取除粒子i之外的其他粒子的t时刻最佳值的第j维的值.若qij(t)的所有维决策变量均取自粒子i的t时刻最佳值的第j维的值,则需要在qij(t)随机选择某一维决策变量向其他粒子的t时刻最佳值的第j维进行学习,以提高粒子的全局勘探能力.
式(7)可以使各粒子的pci值按非线性规律从0.05增加到0.5,使种群粒子的全局勘探能力和局部开发能力达到一个理想的平衡状态,从而使算法能适应不同类型目标函数的最优化问题.
上述改进后具有完全学习策略的量子行为粒子群(MCLQPSO)算法的流程如下:
①指定粒子群粒子个数M,随机产生各粒子的当前值,并把此当前值作为该粒子的当前最佳值.
②根据粒子群中各粒子的当前最佳值,找出全体粒子的当前最佳值g.
③对每个粒子,采用完全学习策略(即式(1))更新其局部吸引子,并计算每个粒子的新值,记为Xi(t+1).
④对每个粒子,若f(Xi(t+1))优于f(Pi),则置Pi=Xi(t+1).
⑤重复步骤②~④,直到满足停止准则或达到预设的最大迭代次数为止.
2.2 粒子进化过程中的混沌优化
混沌是一种具有随机性、遍历性特点的非线性现象,能在一定范围内,从给定的初始条件出发,由确定性方程得到具有随机性的运动状态.实验表明,在粒子群算法的进化过程中引入混沌,有利于提高收敛速度和增强全局搜索能力[8,9].
对粒子群算法进行混沌优化可以包括粒子群的混沌初始化、粒子个体的混沌扰动、迭代公式中参数的混沌优化,如匡芳君等[8]在每一次迭代时,都先对惯性因子、学习因子等参数进行混沌化处理,高鹰等[9]以当前搜索到的全局最优解为初始值迭代产生一个混沌序列,把该混沌序列中的最优解随机替代当前粒子群中的某个粒子,然后继续迭代.实验表明,这两种方法都可以有效地避免粒子过早停滞于局部最优解.笔者融合这两种方法对CLQPSO算法进行改进,分别对收缩扩张因子α和每轮迭代得到的全局最优值进行混沌优化处理,以有效避免粒子早熟.

Logistic方程(式(8))是一个典型的混沌系统迭代公式:使用式(8)对值X∈(Xmax,Xmin)产生混沌变化的步骤如下:
①将X通过方程(9)映射到方程定义域[0,1],记为

②将y1作为初值代入式(8)迭代k次,得到混沌序列(y1,y2,…,yk).
③分别将混沌序列的每个值代入式(10),逆映射到原定义域,作为混沌变化之后的值序列,记为(X1,X2,…,Xk).

④按照某种评价指标从(X1,X2,…,Xk)选择一个值Xi作为X混沌之后的值,在不存在有意义的评价指标时,也可以随机选择一个Xi作为X混沌之后的值.
按式(6)产生收缩扩张因子α之后,可以按上述算法进行混沌变化,并从混沌变化之后的值序列中随机选择一个作为新的α,从而实现对进化过程的扰动.
对式(5)中的粒子i的局部吸引子qi混沌优化,是将qi的各元qij分别作为X,按上述算法进行混沌优化,得到一个q1i=(q1i1,q1i2,…,q1in),混沌变化m次,产生m个值组成的混沌序列(q1i,q2i,…,qmi),将序列中每个值逆映射回原解空间,得到一个局部吸引子的混沌优化序列,从中找到适应度最优的作为新的局部吸引子替换qi,然后再进行下一轮的粒子群进化.实验表明,经过上述混沌优化,可以使每一代群体的适应度更优,有助于改变进化后期敛速慢、精度差的缺点[6].
2.3 基于统一计算设备架构(CUDA)的并行化
为保证全局收敛效果,粒子群算法通常需要构造多个群,每个群包含若干个粒子,各个群按互不相同的、随机生成的初始粒子独立进化并收敛到各自的最优解.实现过程中,每个群的初始粒子生成、群中各粒子的进化及混沌优化都具有细粒度并行的特征.不少文献研究粒子群算法的并行化,概括起来主要有采用MPI并行计算环境的机群模式、基于OpenMP共享存储的多线程并行、基于FPGA的并行三种形式.但对于一些复杂问题,需要构造的粒子群的群数和群中粒子数都比较多,使用上述方法会因为大量进程间的通信、内存读写等问题造成性能的降低,而依靠FPGA等专用设备实现的并行所需的硬件成本过高,限制了其在普通微机上的推广应用[10].
CUDA是由NVIDIA公司推出的一种基于GPU的并行计算架构,可以实现基于SIMD的细粒度并行.蔡勇等[10]实现了基于CUDA的粒子群并行化,通过在GPU中建立与粒子数相同的线程数,并为个体粒子开辟独立的计算空间,每个线程执行一个粒子的寻优计算,利用GPU的并行性,将多个粒子寻优时间缩短成与一个粒子计算的时间相似,加速比达到90.
GPU以线程、线程块(Block)、块网格(Grid)三个不同的层次来组织线程,每个Grid中包含若干个Block,每个Block包含高达1536个线程.CUDA利用三个向量实现对这三个层次运行单元的调用.GPU采用多层次的存储器结构,每个线程都有一个容量较小但速度快的私有寄存器,Block拥有一个对块内的所有线程均可见的共享存储器,Grid内的所有线程都可读写一块相同的全局存储器和一个只供读取的常数存储器.这种结构可以实现同一Grid内Block间存在不需通信的粗粒度并行,也可以实现同一Block内线程之间需要通信的细粒度并行,便于粒子群并行化.
CUDA采用CPU与GPU协同工作的编程模型,CPU负责无法分解的串行操作和控制逻辑性强的处理,GPU执行并行操作.GPU上运行的程序由多个内核函数Kernel组成,每个Kernel由一个Grid来处理.将没有数据依赖关系的多个并行任务分别用Kernel表示,借以实现粗粒度并行.CUDA的计算流程通常是CPU传数据到GPU、执行Kernel、GPU传数据到CPU.
笔者基于CUDA,对上文介绍的C-CLQPSO算法,采取一个Block对应一个粒子群、一个线程对应一个粒子、粒子群数据存储在Block内共享存储器的方案,在初始化粒子群、粒子进化、粒子当前最优值及粒子群全局最优值混沌优化等环节进行并行化.
3 用于蛋白质二级结构从头预测的CCLS-PSO并行算法
3.1 粒子结构及存储
对由n个残基ξ1,ξ2,…,ξn组成的蛋白质,用残基间n-1个二面角的角度值(θ1,θ2,…,θn-1)作为一个粒子的各元,其中θi∈(-π,π),把ξ1,ξ2间的角度视为旋转基准,因此θ1≡0,参与运算不影响能量值,也无须存储.
根据粒子的进化需要,每个粒子要存储的数据包括:当前粒子各元素值、当前最优值、具有当前最优值时的粒子各元素值、当前进化代数,每个粒子群还要存储当前全局最优值.考虑到线程私有寄存器不足以存储整个粒子的各元素值,因此将上述数据以矩阵的形式存储到Block内存储器中.
3.2 算法流程
根据所使用显卡的存储能力和计算资源确定合适的粒子群数与群中粒子数,原则是一个Block块负责一个粒子群,一个线程负责一个粒子.当粒子数超过线程数时,CUDA会自动调配线程间的计算任务,但粒子数的设定要不超过线程数且应为16的倍数,这样可以充分发挥并行能力.
3.2.1 粒子群的初始化
设定粒子群数及各粒子群中的粒子个数,以及粒子的元素个数,调用Kernel函数,将生成粒子的任务分配给各线程,并行初始化粒子群.对于粒子各元素的初值,使用能在GPU上生成各种类型随机数的CURAND函数库中的函数生成.一个粒子群生成的各粒子按3.1所述的方案存储到负责处理该粒子群的Block块的内存中.
3.2.2 粒子群的并行优化过程
调用Kernel函数,把下面对一个粒子的优化过程分配给各线程,实现粒子群的并行优化:
①在指定的定义域内,随机生成式(5)中的α,μ,按式(5)完成第一轮优化,得到新的局部吸引子qi.
②对qi按2.2所介绍的方法进行混沌变异,得到混沌序列(q1i,q2i,…,qki),按式(1)计算序列中各个qji的能量值,找出最小能量值对应的序列作为新的局部吸引子.
③按式(6)计算α,并对之进行混沌扰动,取扰动之后的α和新随机生成的μ,按式(5)完成新一轮优化,得到新的局部吸引子qi,累加优化代数.
④重复②~③,直至搜出全局最优解或者达到预设的优化代数.
4 实验结果分析
实验使用的计算机CPU为I5-2500K,内存4G,Windows7-64位操作系统,显卡为具有48个执行单元的GEFORCE GTX650,编程工具为VS2008+CUDA toolkit2.3.
实验的目的是比较串行的C-CLS-PSO算法和笔者介绍的并行C-CLS-PSO算法在对蛋白质残基序列进行二级结构从头预测时的性能区别.根据式(1),搜索蛋白质能量最小值所耗时主要取决于残基序列的长度,笔者采用Fibonacci序列随机生成了10个长度依次为21~30的残基序列,设定最大优化代数为10000,粒子群数24个,每个粒子群有256个粒子.表1列出了C-CLS-PSO算法串行、并行时的效率.

表1 不同序列长度时C-CLS-PSO算法串行与并行的比较
实验结果表明,对于蛋白质二级结构的从头预测,并行的C-CLS-PSO算法比串行的C-CLSPSO算法提高40余倍的性能.
5 结论
本文针对蛋白质二级结构预测问题,实现了一种融合混沌进化、完全学习策略、基于CUDA并行的粒子群算法.实验结果表明,基于C-CLS-PSO算法能实现对蛋白质二级结构的并行预测,通过CUDA提供的函数,能充分利用GPU的并行计算能力,降低了传统将串行算法并行化的难度,也降低了并行运行所需的硬件门槛.
目前,限于GPU的存储和计算能力,还不能对较长的蛋白质序列进行二级结构并行预测.下一步要研究如果突破这些限制,实现对具有较长长度的残基序列进行并行预测,以使该算法更有实际应用意义.
[1]王栋,孙济洲,李福超,等.基于并行多类支持向量机的蛋白质结构预测[J].计算机应用研究,2011,28(2):465-468.
[2]张斌,尹京苑,薛丹.基于RBF神经网络的蛋白质二级结构预测[J].生物信息学,2011,9(3):224-228.
[3]栗忠兰,吕强,杨凌云,等.一种蛋白质点突变计算机预测的并行模型[J].小型微型计算机系统,2012,33(5):963-966.
[4]陈沙沙,吴宏杰,吕强.一种基于折叠模式识别的蛋白质结构片段库构建方法[J].小型微型计算机系统,2013,34(2):356-359.
[5]申元霞,王国胤,曾传华.相关性粒子群优化模型[J].软件学报,2011,22(4):695-708.
[6]陈伟,周頔,孙俊,等.一种采用完全学习策略的量子行为粒子群优化算法[J].控制与决策,2012,27(5):719-730.
[7]张少辉,吴文欢,韩秋英.非线性随机扰动的粒子群优化算法[J].周口师范学院学报,2012,29(5):98-100.
[8]匡芳君,徐蔚鸿,张思扬.基于改进混沌粒子群的混合核SVM参数优化及应用[J].计算机应用研究,2014,31(3):671-674.
[9]高鹰,谢胜利.混沌粒子群优化算法[J].计算机科学,2004,31(8):13-15.
[10]蔡勇,李光耀,王琥.基于CUDA架构的并行粒子群优化算法的设计与实现[J].计算机应用研究,2013,30(8):2415-2418.
