基于融合特征的微博主客观分类方法
2014-02-28张晓梅高俊杰
张晓梅,李 茹,2,王 斌,吴 迪,高俊杰
(1.山西大学 计算机与信息技术学院,山西 太原 030006;2.山西大学 计算智能与中文信息处理教育部重点实验室,山西 太原 030006)
1 引言
微博作为一种新型的社交媒体平台,为用户提供了更加迅速、便捷的网络社交服务,尤其是面对一些突发事件时,微博起着至关重要的作用。例如,雅安地震中,以新浪微博为代表的社交媒体凸显了强大的平台影响力和号召力,极大地提升了灾难救助的效率。地震发生后,救援人员、网友、公众人士、媒体等均第一时间在微博上发出相关的震灾信息。然而,微博的海量信息中还包含有大量话题不相关亦或客观描述等其他无用信息,这就为政府部门等从微博中快速查找有用信息带来了巨大困难。因此,如何从微博中自动获取话题相关的有价值信息成为一个亟待解决的问题。
微博中与影视、期刊、产品、新政策等话题密切相关的主观性文本,不仅有助于影视公司进行作品销量分析,而且有利于产品公司进行质量提高,同时,对于政府部门进行舆情监督等工作也有重要价值。因此,本文将微博中话题相关的主观性文本称为有用信息,其他话题不相关或者话题相关但属于客观描述的文本称为无用信息。本文面向微博的主客观分类研究旨在将微博中有用信息与无用信息进行区分,即针对限定话题下的相关微博文本进行分类研究,进而从微博中提取有用信息。此外,微博的主客观分类研究在自然语言处理领域中也具有重要意义,它不仅是情感分析[1-2]和观点摘要[3]等研究领域的基础,也是观点检索系统[4]等研究的重要内容。
近年来,面向微博的主客观分类研究引起了众多研究者的关注。其中,使用机器学习方法解决这一问题是当前主流[5-7],这种方法在性能上比基于规则的方法有明显优势[8]。然而,在机器学习方法中,特征的选择对分类的准确性起着至关重要的作用,因此,为了提高分类性能,需要选取有效的特征选择方法。文献[9]通过计算特征项n-gram在不同情感类中出现的概率熵来进行特征选择,文献[10]则通过对三种特征选择方法(信息增益、卡方统计和文档频率)的性能进行比较,选择效果最好的作为最终特征选择方法。然而,衡量某个特征项的重要程度需要从类别关联度和类别区分度两方面来判断,上述文献均采用单一方法进行特征选择,仅从某方面衡量特征的重要程度,同时,这些分类方法均未考虑特征之间的冗余性以及特征选择方法之间的互补性。
因此,为了克服现有分类方法的缺点,综合不同特征选择方法的优势,进一步提高微博主客观分类的准确性,本文提出了一种基于融合特征的微博主客观分类方法,该方法研究了不同特征选择方法对微博主客观分类的影响,并利用特征融合算法将两类特征选择方法进行有效组合,考察组合后得到的融合特征能否获得比最好特征选择方法所得特征更好的分类效果。
本文的组织结构如下: 第2节给出主客观分类方法;第3节是实验结果和分析;最后一节是本文的结论和将来的一些工作。
2 主客观分类
2.1 问题描述
面向传统文本的主客观分类问题一般不考虑话题相关性,而实际应用中话题相关的主观性文本倍受关注且更具有潜在商业价值,因此,本文针对限定话题下的相关微博进行了主客观分类研究。用一个三元组(ti,W,C)表示微博数据,其中,ti表示微博中某个热门话题,W表示该话题下的微博文本集合,C表示微博文本类别集合。因此,本文面向微博的主客观分类问题可以形式化为: 给定微博热门话题t1,t2,…,tn,以及相关微博文本集Wti,目标是从Wti中将隶属于类别Cj的微博文本识别出来。
本文同时考虑了微博的话题相关性和主客观性两个层面的特征,并将该问题看成一个二分类问题,即针对限定话题以及相关微博文本集,将话题相关的主观性微博即有用信息的类别标记为“1”,话题无关或话题相关但属于客观描述等无用信息的类别标记为“0”,进而通过机器学习方法构建微博主客观分类模型来解决此二分类问题。
2.2 分类模型
最大熵(Maxent,简称ME)相对其他机器学习方法,其最大特点是不需要满足特征与特征之间的条件独立。因此,该方法适合融合各种不一样的特征,而无需考虑它们之间的影响,故本文首选最大熵分类器作为微博主客观分类工具。同时,支撑向量机(Support Vector Machine,简称SVM)也是当前较为流行的一种机器学习方法,而且在情感分类任务中取得了不错的效果[10-11],因此,本文也使用SVM分类器对微博主客观分类进行了对比研究。
机器学习方法的学习效果很大程度上依赖于特征的选择,但在进行特征选择前,需要先确定基本特征。本文根据微博语言特点以及对传统文本的研究经验,提出了更加全面的基本特征,并在此基础上,对两类不同特征选择方法进行组合,有效地选择出相对最好特征选择方法更优的融合特征,进而结合该融合特征,利用机器学习方法对已标注微博进行建模,从而对未标注微博进行类别预测。
2.3 基本特征
虽然中文微博限制用户输入的文本不超过140个中文字符,但与英文微博相比,中文微博包含了更丰富的语义信息,所以,对于中文微博的主客观分类研究更为复杂。此外,微博文本也区别于普通文本,微博文本有其专属的特征,因此,本文通过总结相关研究工作[11-12],并结合微博自身特点,提取了4大类共22个特征,如表1所示。
虽然所有的基本特征都可以作为分类器的输入,但不相关或者冗余的特征可能会造成负面影响从而降低分类器的识别性能,因此,在分类前进行特征选择是必要的。本文目的就是从基本特征中选择出包含丰富语义信息且能够较好地对微博进行形式化描述的特征子集。本文利用表1中所述基本特征,通过对不同特征选择方法的特点进行分析,提出一种特征融合算法对两类特征选择方法进行组合来获取微博主客观分类的融合特征。
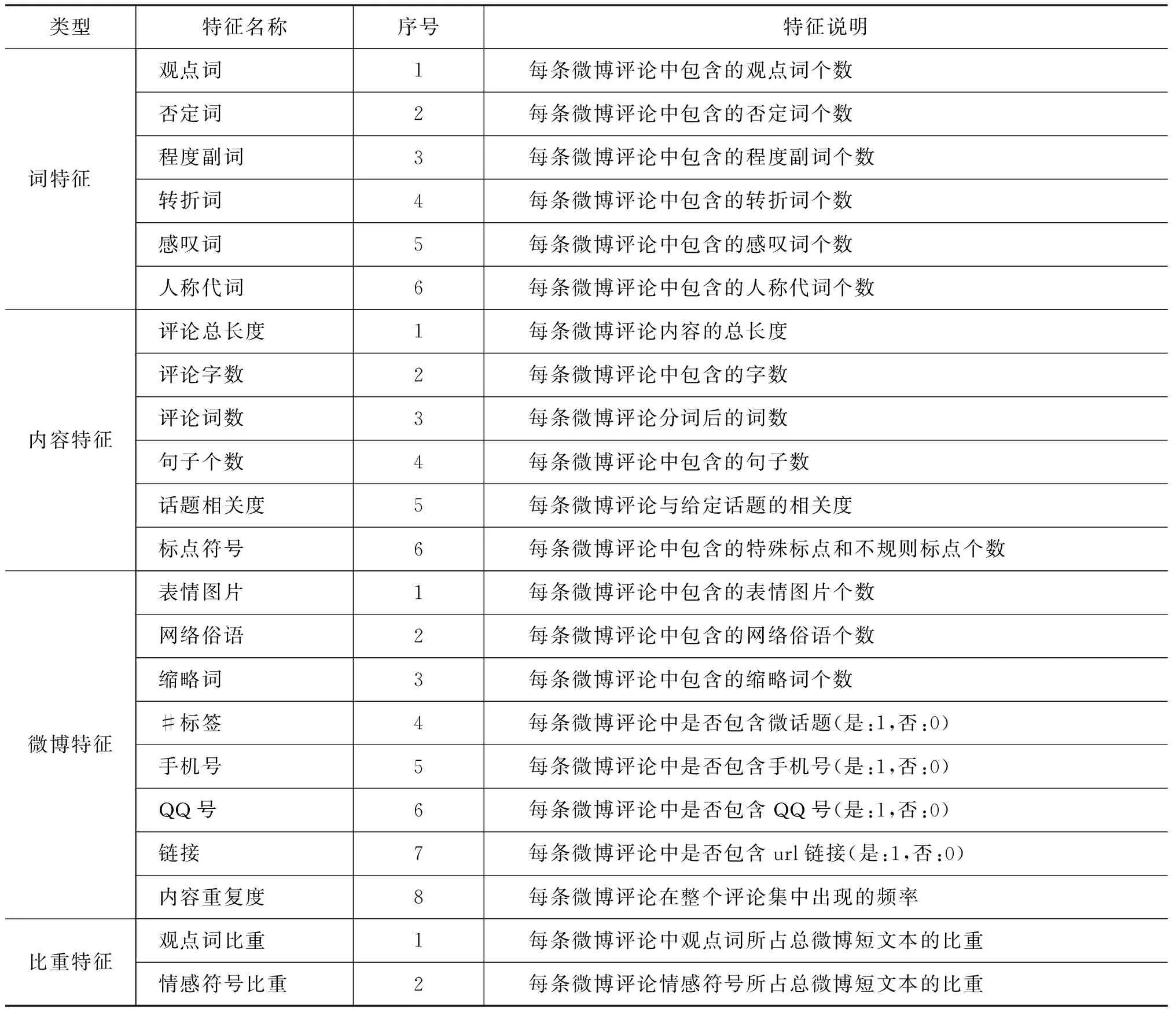
表1 基本特征
注: 情感符号是标点符号和表情图片的统称;表情图片中不包含表情符号(如: O(∩_∩)O)。
2.4 融合特征
每个特征都不同程度的反映了所研究问题的部分信息,但特征太多会增加计算量和增加研究问题的复杂性,因此,希望通过定量分析,用较少的特征子集表达较多的信息量,特征选择方法正是基于这样的目的而提出的。本文为了充分利用各特征选择方法的优势,提出了一种特征融合算法,通过对两类特征选择方法(详细内容如2.4.1所述)进行组合来获取有效融合特征。
2.4.1 特征选择方法
特征选择方法可以分为两类: 有监督的特征选择方法和无监督的特征选择方法。常用有监督特征选择方法包括: 文档频率(Document Frequency,DF)、信息增益(Information Gain,IG)、平方统计(Chi-Square Statistic, CHI)和互信息(Mutual Information,MI)等方法[13]。其中,IG、CHI和MI是以关联度来衡量特征项的重要程度,但IG是针对类别整体来考虑某特征项的重要性。而DF方法则通过阈值来选取具有代表性和类区分能力强的特征,即以类别区分度来衡量特征的重要性。这4种方法都可以从不同层面来获取对分类有重要影响的特征,但其缺点是度量值的计算均与语料库类别标注相关。
无监督的特征选择方法主要是指主成分分析法(Principal Components Analysis,PCA),该方法已广泛应用于所有科学领域的数据集上[14],其基本思想是: 设法将原来多个具有一定相关性的特征集,重新组合成一组新的互相无关的综合特征子集来代替原来的特征集。它是考察多个特征间相关性一种多元统计方法,研究如何通过少数几个主成分来揭示多个特征间的内部结构,即从原始特征中导出少数几个主成分,使它们尽可能多地保留原始特征的信息,且彼此间互不相关。该方法的优点是所得特征子集可以有效降低特征之间的冗余度,但该方法也有不足,其容易忽略那些不相关的但类别区分度较高的特征。同时,该方法进行特征选择时不考虑语料库类别标注情况,所以,它受语料库中类别标注的主观因素影响较小,但其无法衡量特征与类别的关联程度。
因此,为了充分利用不同类型特征选择方法的优势,本文在上述两类特征选择方法的基础上,提出了一种基于融合特征的微博主客观分类方法。该方法主要是利用一种特征融合算法来获取融合特征,其核心思想是: 利用上述两类特征选择方法,在降低原基本特征冗余度的同时考虑特征的类别关联度和类别区分能力,即将这两类特征选择方法进行互补和组合,从而获取最佳融合特征。这样不仅可以降低原基本特征的维数和冗余度,而且保留了重要的基本特征,同时,相对平衡了语料库标注稳定性对特征选择的影响。
从理论上讲,如果把一条微博文本看作一个实体,则其可由多个属性来描述,每个属性又可以具化到多个实例(即特征项),文中有监督的特征选择方法仅是对基本特征项的单纯组合,即在特征层面对微博文本进行描述,而无监督的特征选择方法PCA则可以看作对特征项进行了加权组合,即在属性层面来描述微博文本,本文通过对这两种不同类型的特征选择方法进行组合,从而可以融合不同层面的信息来对微博文本进行形式化描述,进而获取更佳分类效果。
2.4.2 特征融合算法
本文特征融合算法的基本思路: 利用无监督特征选择方法即PCA对原基本特征进行特征选择,获取冗余度低且互不相关的综合性特征子集;将有监督特征选择方法中的四种方法分别对原基本特征进行特征选择,并利用Feature Bagging算法(简称FB)对四种特征选择方法进行有效组合,即将其选择的特征子集进行融合,从而从原基本特征集中选择出类别关联度高且类别区分度高的特征子集;将前面两种特征子集进行融合从而得到最佳融合特征。本文将该特征融合算法称为PFB融合算法,其具体内容如图1所示。

Input:特征选择方法集合methodSet={firstMethodSet,secondMethodSet},基本特征集合featureSetOutput:融合特征集合subFSetInit:subFSet←⌀;Step1:用methodSet集合中secondMethodSet集合的无监督特征选择方法PCA对featureSet中的基本特征进行选择,获取第一类加权综合性特征子集subFSet1;Step2:用methodSet集合中firstMethodSet集合的的四种有监督的特征选择方法分别对featureSet中的特征进行选择,并利用FB算法将各特征选择结果进行融合,从而获取第二类最佳特征子集subFSet2;Step3:将Step1和Step2中的两类型子集进行合并,获取融合特征子集,即:subFSet2subFSet1∪subFSet2。图1 PFB算法总体流程
其中,FB算法是用来处理多特征选择方法组合问题,其基本思想是: 选择R个特征选择方法Mi(i=1,2,...,R)分别对N个基本特征Fj(j=1,2,...,N)进行特征选择,其中,Mi属于第一类有监督的特征选择方法,Fj是根据语料库中的数据预定义的基本特征。对于基本特征集合中的每个特征Fj,用这R个特征选择方法分别对其进行打分,最终,将得分最高的特征作为最终特征子集,其具体内容如图2所示。

Input:firstMethodSet,featureSet,thresholdKOutput:subFSet2Init:subFSet2←⌀,特征得分featureScore[featureSetSize]←{0};Step1:Forallmi∈firstMethodSet 特征统计值featureStatisticValue[featureSetSize]←{0}; Forallfj∈featureSet featureStatisticValuej←getStatisticValue(mi,fj); EndFor featureLocNumdescSort(featureStatisticValue,featureSet); Forallfj∈featureSet 特征位置编号fLocj←getNum(featLocNum,fj); IffLocj<=thresholdK featureScorej←featureScorej+1; Else featureScorej←featureScorej+0; EndForEndForStep2:featureScore←descSort(featureScore);Step3:subFSet2←getHighestScoreFeatureSet(featureScore,featureSet)。图2 FB算法过程
3 实验
3.1 实验语料
本文针对新浪微博热门话题应用,对某热门话题的相关微博文本进行主客观分类研究。为了实验方便,本文所用数据集来自于数据堂(http://www.datatang.com/),人工从中筛选了10个话题以及相关的9 268条微博评论。为了减少语料粗糙对微博主客观分类准确率的影响,本文对语料进行了预处理,包括: 去掉转发等不规则符号以及重复内容、剔除并存储微话题和链接、剔除表情符号等工作,最终保留了5 618条微博,详细内容如表2所示。
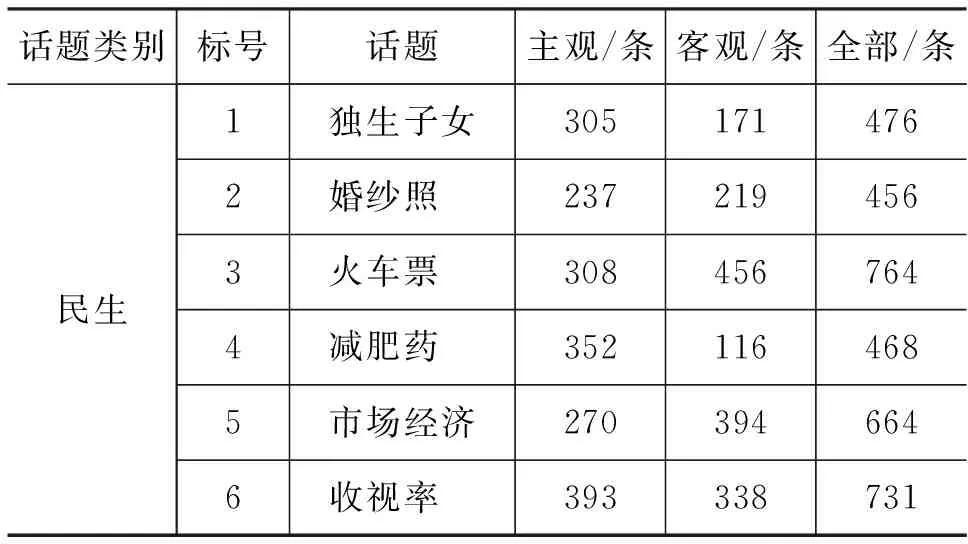
表2 数据集的统计信息
续表
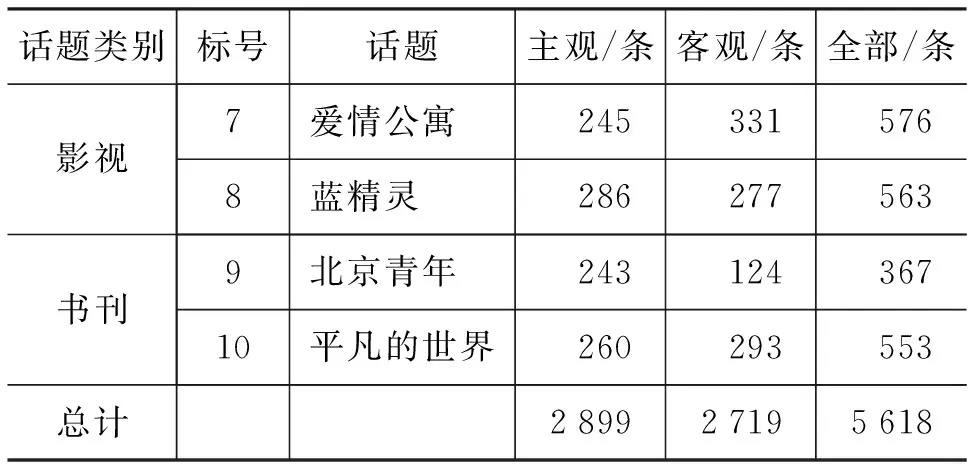
话题类别标号话题主观/条客观/条全部/条影视7爱情公寓 2453315768蓝精灵 286277563书刊9北京青年 24312436710平凡的世界260293553总计289927195618
经统计,语料库中主观性微博所占全部微博的51.6%,即语料库中主观性微博和客观微博数量相对均衡。另外,词库的构建也是微博主客观分类至关重要的内容[15],本文构建了7个词库,包括: 观点词库、否定词库、程度副词库、转折词库、感叹词库、网络俗语词库以及缩略词库。其中,观点词库整合了常用的两大知识库,即由董振东等人提出建立的HowNet知识系统[16]和由大连理工大学建立的情感词汇本体[17],并综合了由山西大学建立的汉语框架网(Chinese FrameNet,CFN)的词元库[18];网络俗语词库和缩略词库主要参照大连理工大学的情感词汇本体,否定词库等其他词库均利用网络资源总结所得。词库规模以及样例如表3所示。
3.2 评价标准
本实验通过计算正确率(A)指标来评测微博主客观自动分类的效果,具体定义如下:
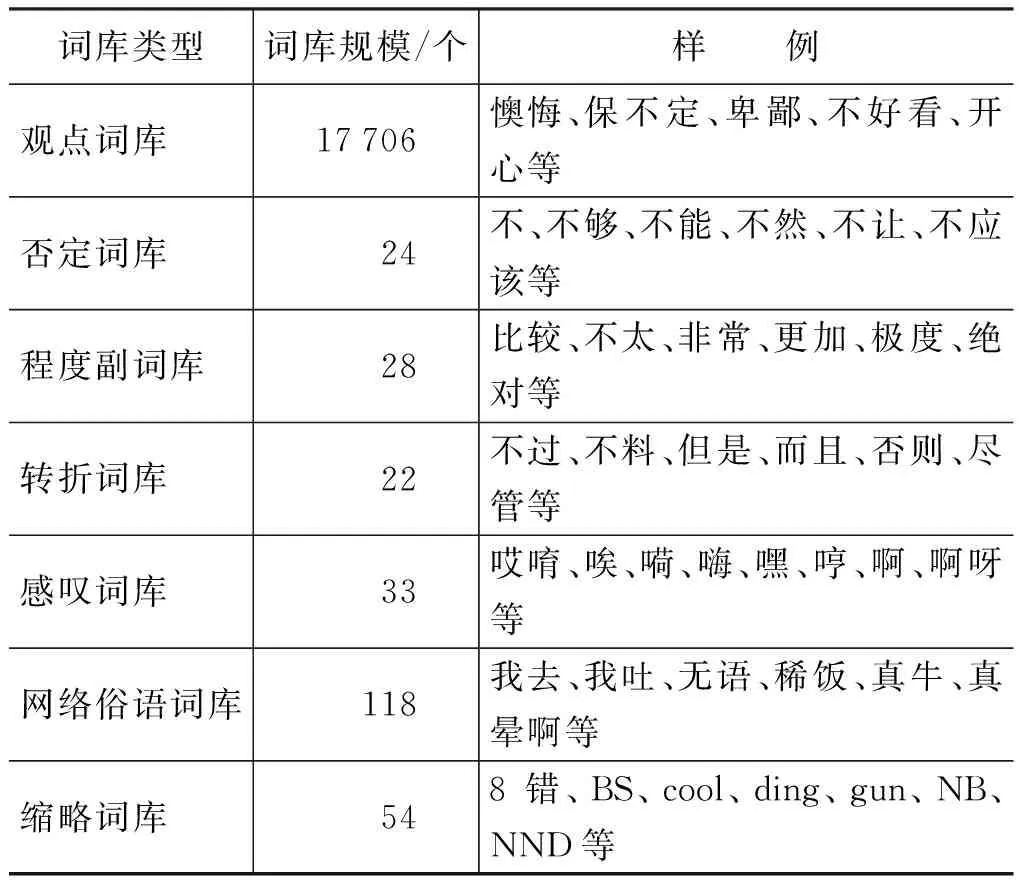
表3 词库的统计信息

此外,本文还通过计算准确率(P)、召回率(R)、F-测试值(F1)三个指标对主观性微博的识别效果进行了评测,具体定义如下:



3.3 实验结果及分析
在实现基于融合特征的微博主客观分类时,本文选用五折交叉验证(five-fold cross-validation)作为评测方法,并分别使用材智仁设计的SVM和张乐博士编写的ME分类器对微博进行主客观分类。
3.3.1 不同特征选择方法的主客观分类结果对比
本文先对所有基本特征直接进行分类,并在此基础上,分别采用7种不同特征选择方法(其中包括两种特征融合算法)进行特征选择而后结合不同分类器进行主客观分类。不同特征选择方法的分类结果如表4所示(均使用正确率A来评价)。
从表4可以发现, 本文提出的PFB融合算法在不同分类器中均获得了最佳分类结果,但结合ME分类器的结果相对较好。同时,PFB融合算法比单独的PCA和FB算法的结果均有很大提高。此外,本文也得出了与文献[10]一致的结果,即就单一特征选择方法而言,使用IG进行特征选择的分类结果最好。
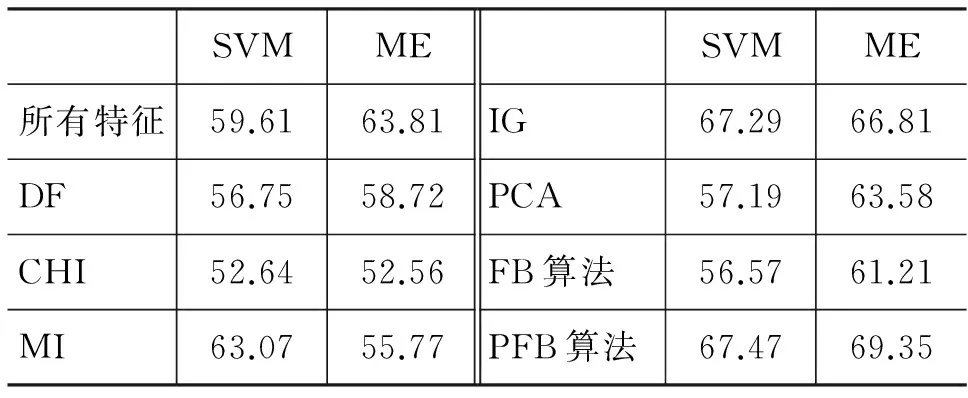
表4 不同特征选择方法的分类结果
3.3.2 主观性微博的识别结果对比
实际应用中主观性微博的价值更大,因此,本文通过使用F1值来进一步衡量不同特征选择方法结合不同分类器对主观性微博的识别效果,如图3所示。
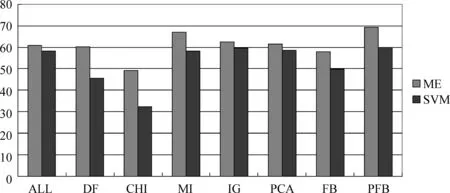
图3 主观性微博的识别结果
图3表示分别使用SVM和ME分类器时,不同特征选择方法对主观性微博的识别结果。通过对图3中两种不同分类器的识别结果进行对比,可以发现本文数据以及方法结合张乐博士编写的ME分类器的主观性微博识别结果相对较好。同时,从图3中可以看出,相比其他特征选择方法,PFB特征融合算法结合两种不同分类器的主观性微博识别结果均是最好的。因此,本文提出的PFB融合算法在主观性微博识别方面依然可以取得最佳效果。
3.3.3 不同类型话题的实验结果对比
为了观察不同类型微博语料对于本方法的影响,本实验采用实验3.3.2中效果最好的PFB融合算法,并结合ME分类器对语料库中不同类型话题下的主观性微博进行识别。如图4所示(均以F1值为评价标准),从图中结果可以发现本文特征结合PFB融合算法对这三类不同类型语料的主观性微博识别性能波动较小,初步说明本文方法较为稳定,但“民生”话题的主观性微博识别结果相对较低。通过分析,话题相关性特征对主观性微博的识别结果具有重要影响,文中“民生”话题的相关微博文本中所包含话题较为灵活,因此,本文实验对微博的话题相关性判断还有待进一步提高。
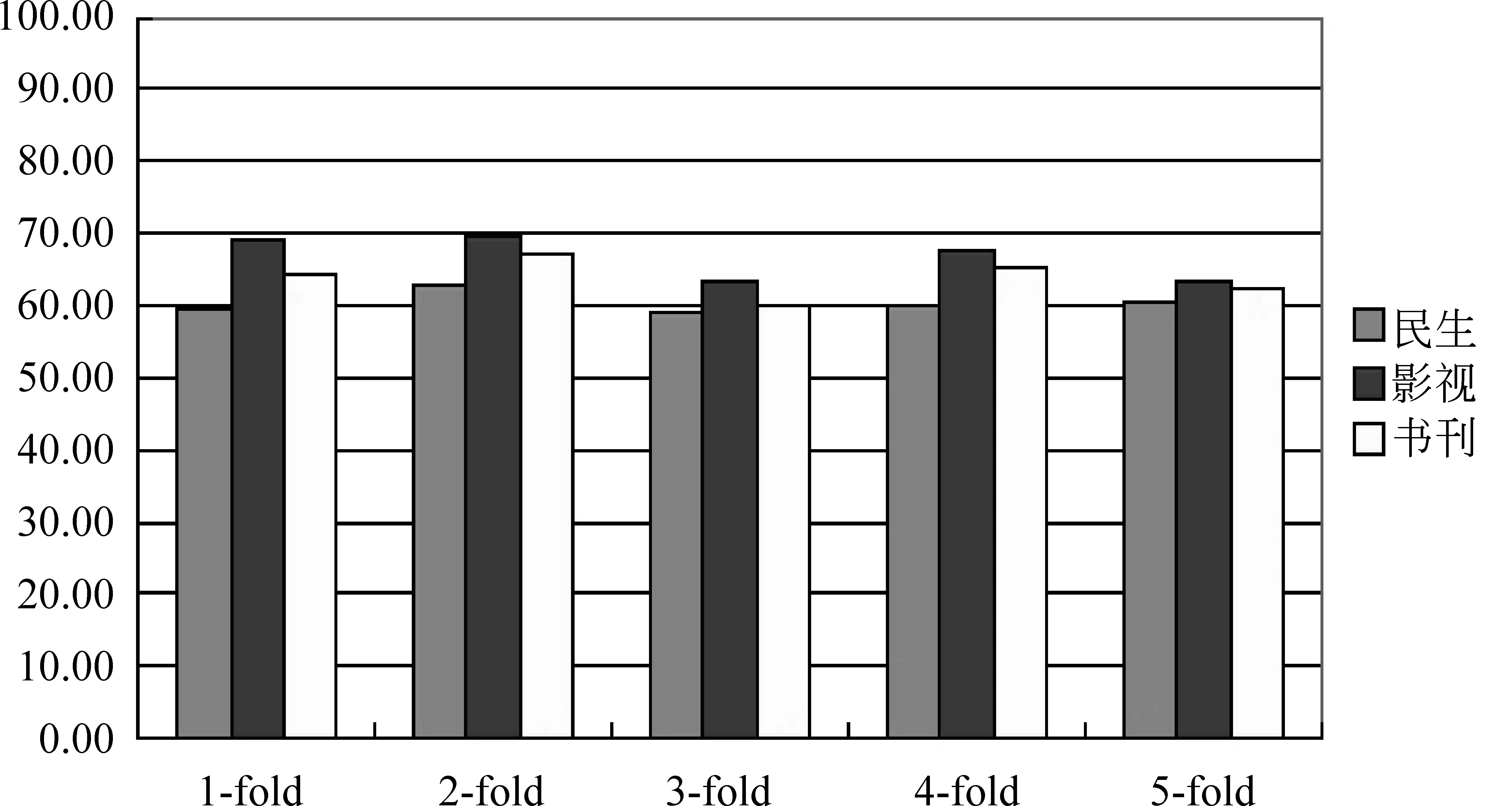
图4 不同类型话题的识别结果
3.3.4 单特征的IG值对比
信息增益可以根据某个特征项为整个类别提供的信息量多少来对特征性的重要程度进行判定,它能够考察特征对整个系统的贡献,IG值越大,说明该特征越重要。本文通过计算每个特征项的IG值来比较各特征项的重要性,结果如图5所示。(通过观察语料,发现在本实验中不适合使用句子个数、内容重复度和链接特征,故实验前已将其剔除。图5横坐标中编号F1~F19分别与表1中其余19个特征按顺序一一对应)通过比较,可以发现每个特征对微博主客观分类均有效果,但个别特征未被充分利用,例如,观点词特征F1,根据经验,F1是非常重要的特征,但在本实验中效果较差,因此,观点词特征有待进一步研究。
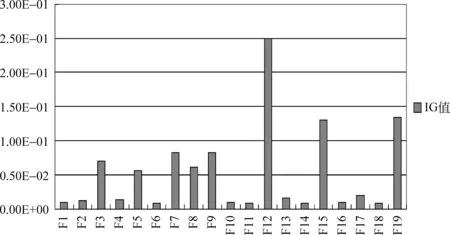
图5 不同特征的信息增益值
最后,本文对微博主客观分类研究进行了错误分析,发现实验对两种类型的微博不能准确识别。
① 隐性话题相关的主观性微博。例如,“我也要!(话题“婚纱照”)”。该微博并没有显性包含话题词,也没有Hashtags,本文实验对这种隐性话题相关的微博不能准确识别。
② 包含新型网络词汇的主观性微博。例如,“《爱情公寓2》重口味宣传片。太重了。太重了。(话题“爱情公寓”)”。由于网络俗语更新速度快以及本文对网络术语收集较少,对该类型微博也不能准确识别。
4 结论
本文提出了一种面向微博主客观分类的PFB特征融合算法,该算法综合了不同特征选择方法的优势,并通过对不同特征选择方法进行有效组合来获取融合特征。本文利用该算法,同时结合机器学习方法对新浪微博热门话题中的微博数据进行了主客观分类研究。实验结果表明该融合算法能够获得比最好基特征选择方法更佳的分类效果。在下一步的研究工作中,将考虑加入更多微博特征,例如,用户名、转发和回复等,并进一步对隐性话题相关的主观性微博进行研究。
[1] Jiang L,Yu M,Zhou M,et al. Target-dependent Twitter Sentiment Classification[C]//Proceedings of the AMACL,2011:151-160.
[2] Barbosa L,Feng J L. Robust Sentiment Detection on Twitter from Biased and Noisy[C]//Proceedings of the COLING,2010: 36-44.
[3] Hu M Q, Liu B. Opinion Extraction and Summarization on the Web[C]//Proceedings of the AAAI,2006:1621-1624.
[4] Yu H, Hatzivassiloglou V. Towards Answering Opinion Question:Separating Facts from Opinions and Identifying the Polarity of Opinion Sentences[C]//Proceedings of the EMNLP, 2003: 129-136.
[5] Go A,Bhayani R, Huang L. Twitter Sentiment Classification Using Distant Supervision[R]. Technical report, Stanford Digital Library Technologies Project, 2009.
[6] Pak A,Paroubek P. Twitter as a Corpus for Sentiment Analysis and Opinion Mining[C]//Proceedings of LREC,2010: 1320-1326.
[7] Davidov D,Tsur O,Rappoport A. Enhanced Sentiment Learning Using Twitter Hashtags and Smileys[C]//Proceedings of the COLING,2010:241-249.
[8] 李寿山,黄居仁. 基于Stacking组合分类方法的中文情感分类研究[J].中文信息学报,2010,24(5):56-61.
[9] 张珊,于留宝,胡长军. 基于表情图片与情感词的中文微博情感分析[J].计算机科学,2012,39(z3): 146-148,176.
[10] 刘志明,刘鲁. 基于机器学习的中文微博情感分类实证研究[J].计算机工程与应用,2012,48(1):1-4.
[11] 谢丽星,周明,孙茂松. 基于层次结构的多策略中文微博情感分析和特征抽取[J].中文信息学报,2012,26(1):73-83.
[12] 姚天防,彭思崴. 汉语主客观文本分类方法的研究[C]//第三届全国信息检索与内容安全学术会议论文集,2007:117-123.
[13] Yang Y M,Pedersen J O. A Comparative Study on Feature Selection in Text Categorization[C]//Proceedings of the ICML,1997: 412-420.
[14] Boutsidis C, Mahoney M W,Drineas P. Unsupervised Feature Selection for Principal Components Analysis[C]//Proceedings of the KDD,2008:61-69.
[15] Shen Y,Li S C,Zheng L,et al. Emotion Mining Research on Micro-blog[C]//Proceedings of the SWS,2009: 71-75.
[16] Dong Z D, Dong Q. HowNet. http://www.keenage.com/, 2005.
[17] 徐琳宏,林鸿飞,潘宇,等.情感词汇本体的构造[J].情报学报, 2008, 27(2): 180-185.
[18] You L P, Liu K Y. Building Chinese FrameNet Database[C]//Proceedings of the IEEE NLP-KE,2005:301-306.
