开放式信息抽取研究进展
2014-02-28蔡东风
杨 博,蔡东风,杨 华
(1. 沈阳航空航天大学 知识工程研究中心,辽宁 沈阳 110136;2. 沈阳航空航天大学 计算机学院,辽宁 沈阳 110136)
1 引言
从自由文本中抽取有用的结构化信息在当前大数据时代已获得广泛关注,这种浅层语义表示是文本蕴含、知识库构建、问答等复杂语义任务的重要基础。但传统的有监督方法并不能胜任海量信息抽取,主要是受限于训练数据。近年来有两种无监督的文本理解方法关注于浅层语义,即机器阅读[1]和阅读式学习[2]。两者的差异在于:首先是对文本的表示方式不同,机器阅读需表示成固定的实体—关系三元组结构(Arg1, Rel, Arg2),而阅读式学习需根据依存句法树表示成更为灵活的关系—实体结构,可以抽取多于两个实体的关系对,而且关系并不限于动词短语,而是基于依存的关系对(中心词、关系、修饰词);其次是文本领域的不同,机器阅读不限制主题与领域,而阅读式学习仅关注限定领域的文本以构建特定主题的语义模型。
虽然有时仅仅通过基于动词的实体关系不能完整地表达语义信息,但机器阅读的主要贡献是对抽取模式的发展,即能适应大规模文本的开放式信息抽取(Open Information Extraction, OIE)[3]。与机器阅读互补的是,以依存分析为基础的阅读式学习含有丰富的句法特征,这样可以保证信息量及准确性,但其代价就是抽取效率的下降。因此,既要适应从海量文本中高效地抽取浅层语义信息,也要尽量抽取细微的完整信息,以利于后续深层语义任务的进行,是本文主要探讨的内容。
开放式信息抽取按关系参数复杂程度可分为二元、多元等类别,本文第二部分将按此路线对典型的OIE系统予以阐述;鉴于目前主流的OIE系统尚无法实现隐含关系抽取,本文第三部分将介绍采用Markov逻辑、本体推理等联合推理方式进行深层隐含信息抽取的新方法;第四部分进行总结与展望。
2 开放式实体关系抽取
传统的信息抽取是在限定文本领域、限定语义单元类型的条件下进行的,这显然不适用于无法预先定义实体-关系类型的大规模文本。尤其是随着互联网的飞速发展,如何从海量的非结构化Web文本中快速、自动、准确地抽取有用信息就显得尤为重要。华盛顿大学在开放式信息抽取领域积累了许多颇具代表性的成果,以下按时间顺序对OIE的几个具有里程碑意义的系统予以介绍与分析。
2.1 二元开放式实体关系抽取
2.1.1 KnowItAll和TextRunner
KnowItAll[4]是由传统信息抽取向开放式信息抽取过度的一个有益尝试: 为解决语料非均匀性问题,KnowItAll采用词性标记而不是句法分析,也无需命名实体识别,由识别向抽取转变;在自动抽取方面,采用领域独立的抽取模板来标注小规模训练语料并使用bootstrapping扩展到未知的大规模语料,能从大量网页中抽取多种实体关系。尽管 KnowItAll的训练过程为自监督,但抽取并不完全是自动的,即需要用户在每次抽取信息之前指出一个感兴趣的关系,当语料规模庞大、内容复杂时,预定义所有感兴趣的关系也确实是个问题,效率并不理想。
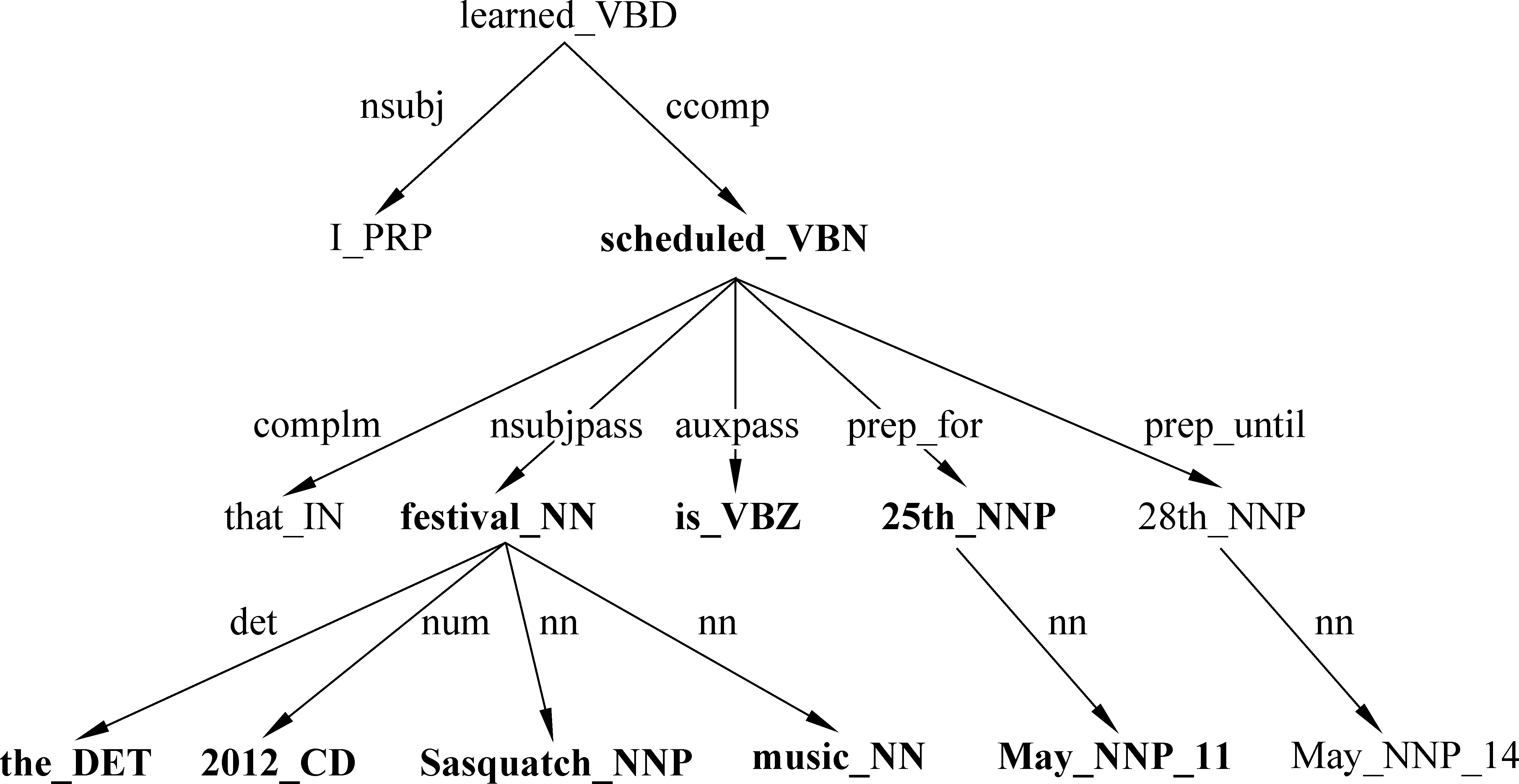
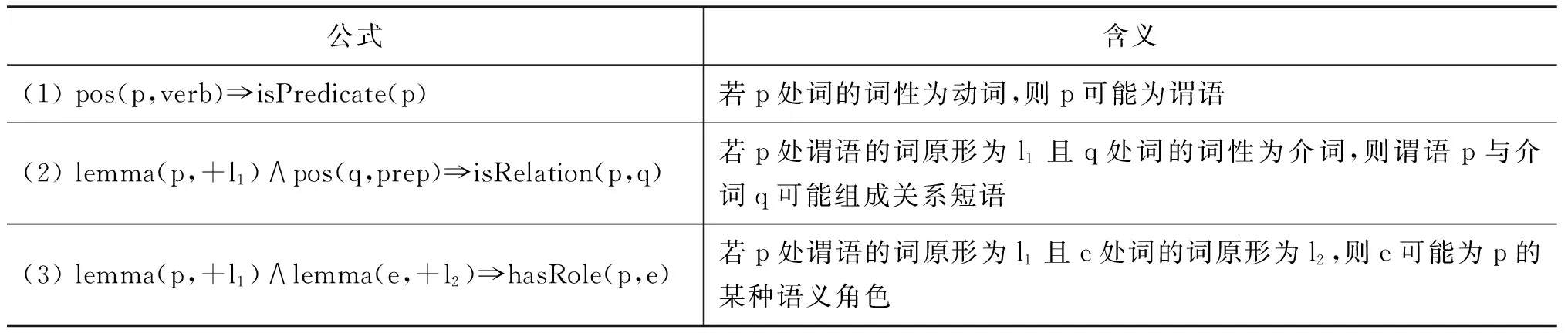
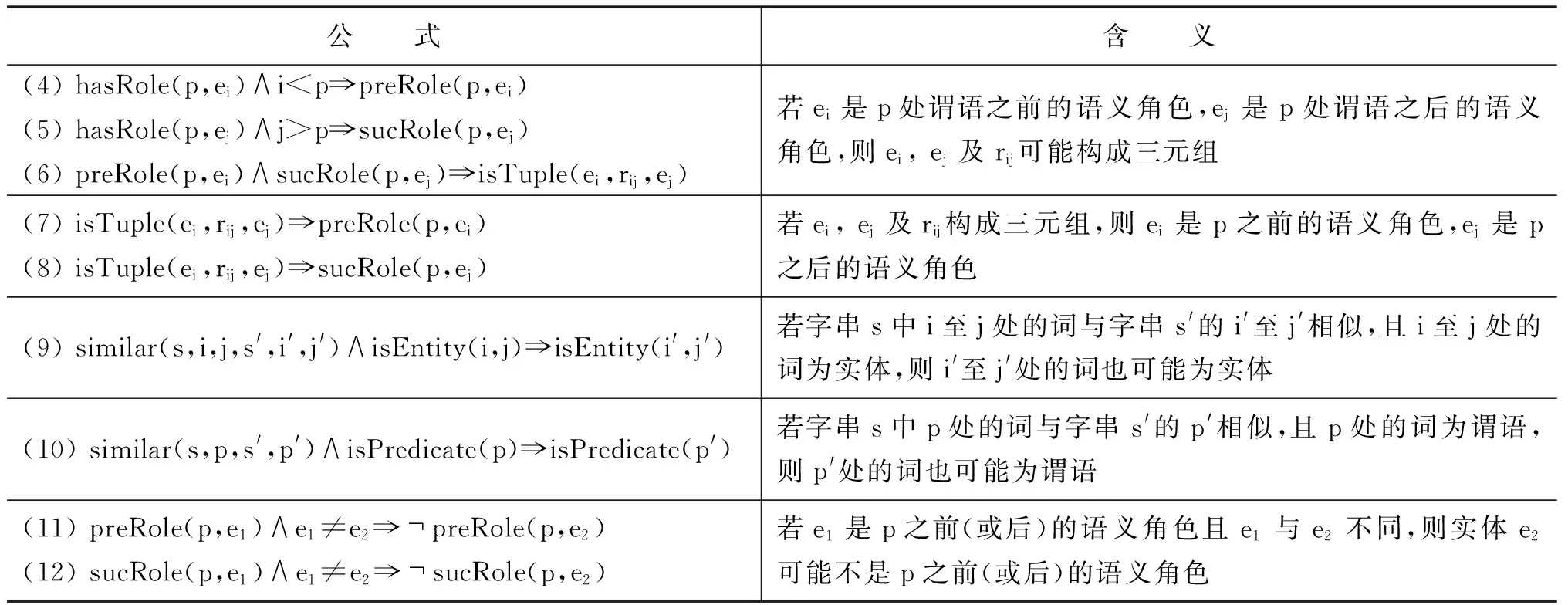
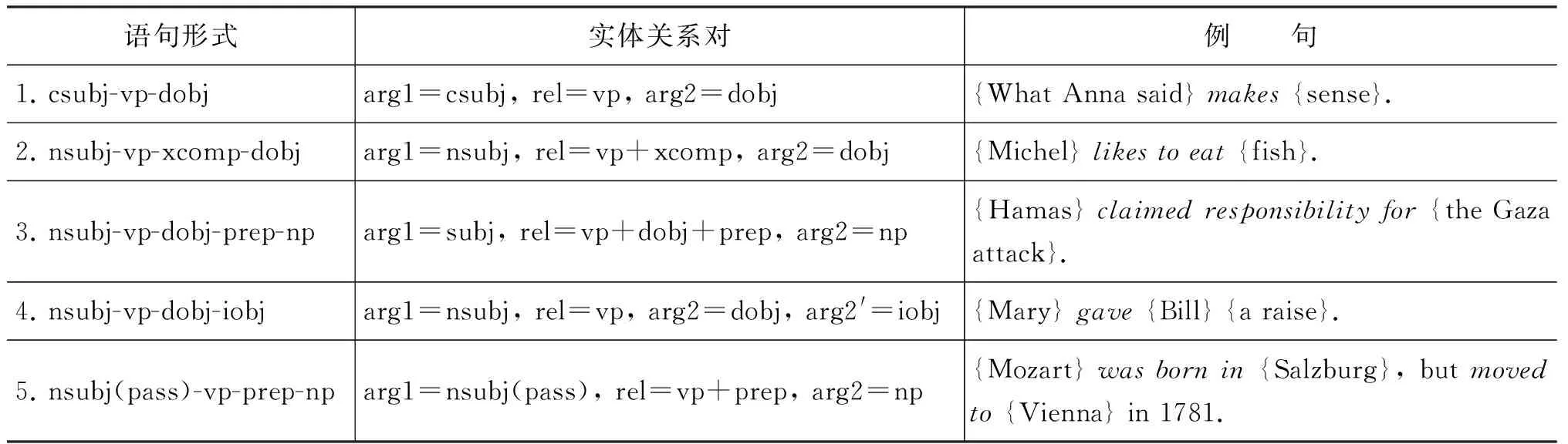
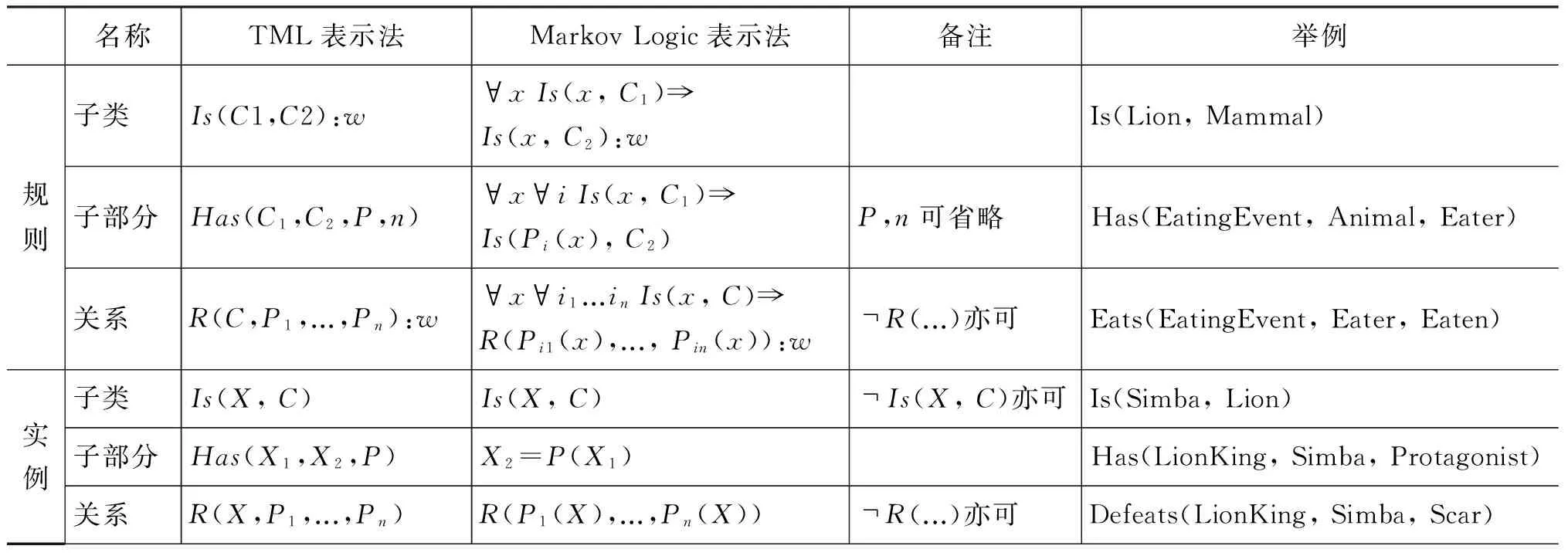
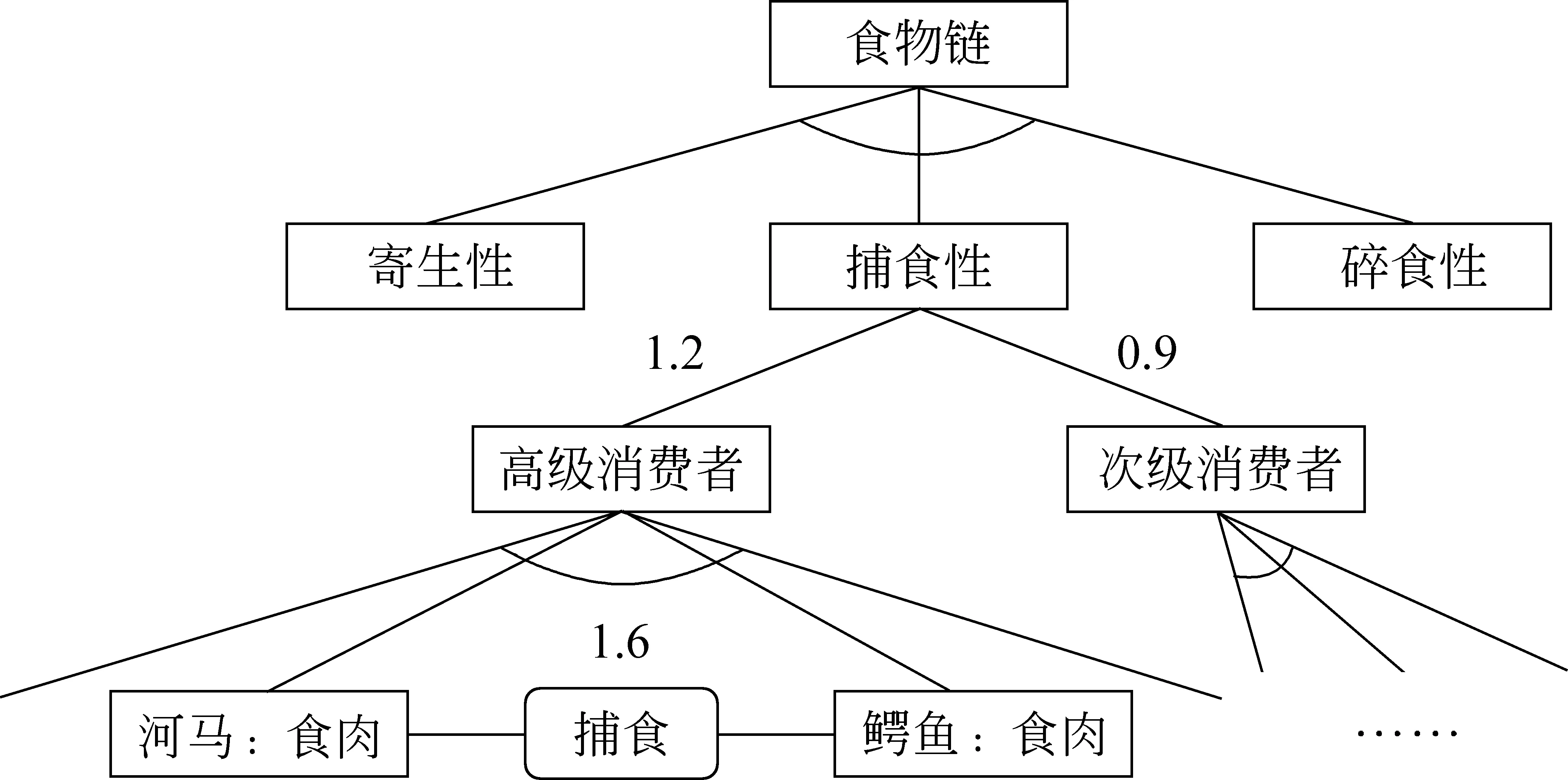
OIE的目标是从非限定领域的文本中自动发现所有可能的关系。随着第一个OIE系统——TextRunner[5-6]的问世,真正意义上的大规模、领域独立、高效的目标得以实现。TextRunner(O-CRF)利用启发式规则从宾州树库训练样本,采用二阶线性链CRF抽取器从开放式文本中自动抽取关系三元组,其输入是含词性标记和NP语块分析的语句(由OpenNLP工具实现),输出格式是(ei,rij,ej)(i 2.1.2 WOE TextRunner能自动抽取Web文本中大量的实体关系,但在准确率和召回率方面还不够理想。2010年,Wu Fei提出一种源于Wikipedia的OIE方法——WOE[7],通过将Infobox的属性值与相应语句匹配生成特定关系训练样本,与Kylin[8]相同,再从这些样本中抽象出关系独立(开放)的训练数据经自监督学习得到抽取器。WOE的抽取器有两个:WOEpos和WOEparse。WOEpos仅包含词性、NP语块、大写、标点等浅层特征,学习算法与TextRunner相同,通过训练Mallet机器学习软件包中的二阶CRF模型输出两名词短语间确定的关系词,与TextRunner相比效率相仿,准确率和召回率略有提升;而WOEparse包含依存分析等深层句法特征,学习通过识别两名词短语间的最短依存路径进行,并采用通用句法模板判断该最短依存路径是否表示两名词短语间的某种语义关系,但最短路径并不能完全确定语义关系,比如“Anna was not born in UK”按最短依存路径的抽取结果为(Anna, BornIn, UK),这显然违背了原句语义,所以还需附加修饰语和“auxpass”、“neg”等依存标记,形成扩展路径。通过对Wikipedia语料的训练可知,出现频率较高的5个句法模板是:N-nsubj→V←prep-N、N-nsubjpass→V←prep-N、N-nsubj→V←dobj-N、N-nsubjpass→V←agent-N 、N-nsubj→V←dobj-N←prep-N。从[7]中的实验结果可知,采用句法特征的WOEparse能明显改善实体关系抽取效果,但代价就是抽取速度的下降,要比TextRunner慢30倍。 2.1.3 ReVerb和R2A2 针对TextRunner抽取出的无信息量和错误信息以及WOE中句法特征对抽取速度影响的不足,第2代OIE——ReVerb[9]对此予以改进,其抽取器是逻辑回归分类器,由浅层句法特征(词性、NP语块)训练得到。ReVerb的特色之处是应用浅层句法约束来消除错误信息并减少无信息量的信息抽取,该句法约束针对关系短语,关系短语的构成有3种情况:①一个简单的动词短语;②动词短语与紧随其后的介词或虚词(如born in);③动词短语与其后的简单名词短语并且以介词或虚词结尾(如has great admiration for)。经300句测试语料发现,有85%的二元动词关系短语满足该约束,不满足约束的情况有:8%为非连续短语结构(如X turned Y off);4%为关系短语不在实体之间(如…the Y that X discovered);3%为词性不匹配(如X to attack Y)。但仅通过句法约束抽取出的关系短语不一定有价值(可能包含很多实体),还需进行词性约束。ReVerb以动词关系抽取为主,得到满足约束的关系后再依据邻近原则确定左右实体,其问题也主要在于此,即关系短语能准确得到,但实体词经常出错,比如“Women in China can have the status either equal to men or respected by the society”的抽取结果为(China, can have, the status),但事实上Arg1应为women,Arg2也因被截断而出错。其他的常见错误是将大于二元的关系误认为二元关系,如“He lent me a book”的抽取结果为(He, lent, me)。 实体结构按出现频率可分为简单名词短语(如Calciumpreventsosteoporosis)、附加介词(如Lake Michigan is one ofthefiveGreatLakesofNorthAmerica)、并列结构(如GoogleandAppleare headquartered in Silicon Valley)、独立从句(如Scientists estimatethat80%ofoilremainsathreat)、关系从句(如Russia,whichmarcheswithChina, has the largest territory in the world)等情况,其中简单名词短语最为普遍,这也是ReVerb之前的OIE系统成功的原因。但对于其他情况,ReVerb常见的实体错误就不可避免了,为此R2A2[10]融入了实体学习组件ArgLearner以更好地判别实体的边界。ArgLearner首先确定Arg1、Arg2,再进一步识别两者的左右边界,其中Arg1的右边界利用Weka机器学习软件包中的REPTree决策树学习器识别,Arg1的左边界和Arg2的右边界利用Mallet机器学习软件包中的CRF分类器识别,鉴于Arg2通常在关系短语之后,所以无需独立确定其左边界。通过实验发现,R2A2对Arg1的改善较明显,适用于简单名词短语、附加介词、并列结构等情况,对Arg2的改善略逊于Arg1,且R2A2的准确率与召回率明显高于ReVerb。 2.1.4 OLLIE 以上提及的OIE系统已经可以有效地进行大规模网络信息抽取,但仍然有两个主要缺陷: 一是仅抽取以动词为核心的关系,这样会遗漏以其他句法实体(如名词、形容词等)为核心的重要信息;二是忽略上下文全局信息,仅对语句的局部进行分析,使得部分抽取结果并非事实。为此,文献[11]提出新一代OIE系统——开放式语言学习信息抽取(Open Language Learning for Information Extraction, OLLIE),弥补了以往OIE的不足。如表1所示,用ReVerb、 WOE对前3句进行抽取是没有任何结果的,但采用OLLIE可得到扩展后的准确结果;用ReVerb、WOE对后两句抽取的结果并不完整,采用OLLIE可抽取出融入了上下文的完整信息。 表1 OLLIE信息抽取实例 为抽取扩展的以动词、名词、形容词等为核心的关系,OLLIE的关系抽取分3个步骤进行。第一步是构建bootstrapping集,将由ReVerb抽取的高置信度的三元组作为初始集合,再采用bootstrapping方法自动构建较大规模的训练集,为确保信息与初始种子一致,可将依存路径长度作为约束以保留主干成分。这种将训练数据推广到未知关系的方式普遍适用于OIE,若关系词与种子匹配,便可学习到开放模板以应用于其他关系抽取。 第二步是学习开放模板,开放模板是从依存路径到开放式抽取的一种映射,表2列出了OLLIE频率较高的模板。其中,模板5的slot指依存路径中不在种子关系对中出现的空位节点,需在词性和词法上限制,若其不与关系对成反义则可跳过,如“Federer hired Annacone as a coach”的种子关系对为(Annacone; is the coach of; Federer),hired即为空位词。对候选模板要进行以下4项检查: ①依存路径没有空位节点;②关系节点在Arg1与Arg2中间;③若模板中有介词,需与关系中的介词匹配;④路径中没有nn或amod边。其中依存分析使用高效的Malt分析器,以适应大规模信息抽取。若满足条件,可作为无词法约束的句法模板(表2的1~3模板);若不满足条件,对候选模板的关系和空位词还需在词法和语义上约束,如表2的4~5模板,采用相似词汇列表等方式,可借助WordNet等实现。 第三步是用开放模板从未知语句抽取二元关系。先将开放模板与语句的依存分析结果匹配以识别实体与关系的基节点,再扩展为与之前抽取相关的全部信息。如图1所示是对语句“I learned that the 2012 Sasquatch music festival is scheduled for May 25th until May 28th”的依存分析结果。将表2中抽取模式1与该句匹配,可知arg1对应“festival”,rel对应“scheduled”,arg2对应“25th”及介词“for”,但抽取(festival, be scheduled for, 25th)的意义不大,于是进行扩展。将边为amod(形容词), nn(名词组合), det(冠词), neg(否定词), prep_of(介词of), num(数字),quantmod(数量短语)的词组成名词短语,当核心名词不恰当时,还需扩展标记为rcmod(关系从句), infmod(动词不定式), partmod(分词),ref(指代词), prepc_of的边, 因为这些是表达重要信息的关系从句。对于关系短语,需扩展标记为advmod(副词), mod(修饰词),aux(助动词),auxpass(被动词),cop(系动词),prt(动词短语)的边,当dobj(直接宾语), iobj(间接宾语)不在实体中出现时也要在此步扩展。在识别这些词后,需按原句次序排列,如图1的抽取结果为(the Sasquatch music festival, be scheduled for, May 25th)。 图1 依存分析树实例 此外,OLLIE还融入上下文分析的功能以解决部分抽取结果并非事实的不足,即为关系对扩展一个额外的域。如表1的第4句增加了表示归因的AttributedTo域,第5句增加了表示条件为真的ClausalModifier域以使结果准确有效。附加域通过依存分析实现: 如归因结构在依存分析中标记为ccomp,但不是所有的ccomp边都为归因结构,还要借助VerbNet进行匹配;又如状语从句在依存分析中标记为advcl,筛选后再将从句的首个词与训练集(如if, when, although, because等)匹配,若符合便增加ClausalModifier域。 OLLIE与以往的OIE相比有两个重大突破: 一是扩展了关系抽取范围,可以识别以名词、形容词等成分为核心的关系;二是融入上下文信息,使结果更具事实性。OLLIE美中不足的是: 易受依存分析错误的影响,开放模板不能保证适应所有情况,二元实体关系会忽略一些重要信息等。从文献[11]中的实验结果可知,OLLIE与Reverb等相比已经表现出无可争议的优越性,对OIE的深入发展具有重要意义。 现有的OIE方法多数关注二元实体的抽取,文献[12]中基于语义角色标注的OIE分析显示,在考察的英文语句中有40%的实体关系为n元的。不恰当地处理n元实体关系会导致抽取结果不完整、无信息量甚至错误。如对于语句“The first commercial airline flight was from St. Petersburg to Tampa in 1914”,至少可以抽取出3个关系对:(the first commercial airline flight, was from, St. Petersburg),(the first commercial airline flight, was to, Tampa),(the first commercial airline flight, was in, 1914)。但采用ReVerb等OIE系统是无法得到这些关系的。尽管ReVerb可以识别各句中的若干从句,但仅能抽取各从句中的一组关系对。浅层句法信息虽然提高了OIE的效率,却无法抽取高阶n元事件。目前对Wikipedia进行高阶事件抽取已有一些研究,但需要限制实体类型,如文献[13]从Infobox中抽取时间、地点、类别信息等,文献[14-15]可从英文语句抽取n元事件,但至少要包含一个时间信息。 文献[16]在Wanderlust[17]的基础上,提出一种可对任意实体类型进行n元信息抽取的方法——KRAKEN。KRAKEN将Stanford依存分析结果作为输入,按以下3个步骤进行: (1) 检测事件短语:KRAKEN将事件短语视为一系列动词、修饰语和介词,如has been known、deserves to own等,通过aux, cop, xcomp, acomp, prt, auxpass等依存标记连接。检测到的事件短语可包含一个动词,也可包含不与上述依存标记连接的词。 (2) 检测实体主导词:对事件短语的每个词,依据依存路径查找实体主导词,如依存路径nsubj-↓表示一个向下的类型为nsubj的连接,该连接所指向的即为实体主导词。如图2所示,一个事件短语是was coined,根据依存路径rcmod-↑-appos-↑可找到主语Doublethink。 (3) 检测全部实体:从实体主导词递归地寻找向下的连接可得到全部实体。经过以上3步可形成事件,若事件短语至少含有一个实体,则将其抽取为事件。如图2中,由依存路径prep-↓-pobj-↓可找到2个实体(Orwell和the novel 1984);从该句可抽取出2个n元事件,即WasCoined(Doublethink,(by) Orwell,(in) the novel 1984)和Describes(Doublethink, fictional concept)。 图2 n元OIE实例 文献[16]将KRAKEN与ReVerb进行比较,结果表明KRAKEN可较为准确地抽取完整的n元事件,弥补了ReVerb的不足。但KRAKEN在检测错误依存分析时采用了启发式信息,使得实验的500句有155句跳过,而且深层句法特征使得效率下降,不能胜任大规模Web文本的情况。未来的一个发展方向是对事件短语及实体的规范化,如文献[18-19]中的无监督聚类方法可促进相似事件短语或实体的聚类,文献[20]中的远距离监督方法将事件整合到现有的知识库中,以此提高召回率和实用性,也可利用文献[21]中的由依存关系获取子句集合,并依据子句类型灵活组合的方法抽取更为多样的n元关系。将二元实体关系抽取扩展为语义丰富的n元关系是必然趋势,也是一个前沿方向。 信息抽取是自然语言处理的一个重要分支,也是知识发现的前提,一个主要难点在于并非所有的实体关系都可以明显地直接抽取,隐含关系也是普遍存在的,如“牛奶含有钙”也可说成“钙可从牛奶中提取”或“喝牛奶可预防骨质疏松”等。之前的很多方法都不涉及隐含关系抽取,如自动内容抽取会议ACE2007的语料库虽同时标注了明显和隐含关系,但评测时通常忽略后者,目前主流的OIE系统也无法实现。若对抽取出的信息不加以规范和归纳,是无法发掘文本中隐含的深层语义关系的,此时引入联合推理,可以极大地改善此局面,能自动推理得到更为丰富的信息,促进对文本的理解。文献[22]就极力推崇采用联合推理的方法处理自然语言的问题。目前概率联合推理主要包括Markov逻辑和由粗略至精细(coarse-to-fine)的本体推理两种,以下分别予以阐述。 Markov逻辑网(Markov Logic Networks, MLN)[23]是一种将Markov网络与一阶逻辑相结合的统计关系学习框架,为大规模Markov网提供了一种简练的逻辑语言,为一阶逻辑增加了不确定性处理能力,在语义角色标注[24]、共指消解[25]、文本蕴含[26]、实体链接消歧[27]等研究中得到很好的应用。 MLN可看作一种用一阶逻辑公式来实例化Markov网络的模板语言,是公式Fj及其相应权重wj的集合,其基本推理任务是MAP(Maximum a Posteriori)推理,即寻找一个值使得可满足的子句的权值之和最大。MLN能够在对象实体和关系不断变化中自动调整其网络结构和参数,不仅避免了隐马尔科夫模型的独立性假设,而且与线性链结构的条件随机场相比可扩展成任意的网络结构,更为通用。 之前利用MLN处理信息抽取问题,需要限定类别和领域[28],既然开放式信息抽取是今后的发展趋势,那么在OIE中融入联合推理,使两者相得益彰,是很好的研究方法。 3.1.1 StatSnowball和EntSum 文献[29]提出一种无监督自学习的知识挖掘模型——统计滚雪球(StatSnowball),即对初始种子进行bootstrapping循环迭代,直到不再生成新的可信模板或知识为止,MLN是其底层引擎(由alchemy工具包实现)。MLN的一个主要任务是定义能反映普遍规律的一阶逻辑模板公式,在序列标记任务中可定义句子级别的公式以模拟线性链CRF,即InField(ti, REL-S)∧Verb(ti+1)⟹InField(ti+1, REL-C),含义为若前一个词是关系词的开始(REL-S)且当前词为动词则当前词很可能是关系词的延续(REL-C),结果表明MLN要好于CRF。文献[29]中也将StatSnowball用于二元OIE任务,模板分别利用经验和l1范式选取(即MLN中的结构学习),因为使用MLN作为底层统计模型,故可以实现各种级别的联合抽取(如在网页级别还可定义公式:SimilarToken(t1,t2)∧F1(t1)∧F2(t2)∧InField(t1,+f)⟹InField(t2,+f),含义为对于同类关系,相似的词应有相似的标记,其中+号表明该公式对于不同的实例需要分别实例化并赋予不同权重),故能融合跨关系的知识以提高抽取效率。 StatSnowball与OIE的不同之处是:OIE需人工选择特征经自学习得到抽取器,而StatSnowball是自动产生和选择模板以形成抽取器。与传统Snowball[30]方法相比,Snowball使用严格的关键字匹配模板,只能抽取少量的固定种类的关系,而且手工设计的模板可移植性差,而StatSnowball不存在这类问题。 在StatSnowball 的基础上,文献[31]提出一种实体识别和关系抽取的联合模型——EntSum。以往的信息抽取通常将实体与关系的识别分开进行,鉴于两者紧密相关,将实体—关系抽取联合处理,会改善抽取效果。EntSum模型由基于扩展CRF的命名实体识别模块和基于StatSnowball的bootstrapping关系抽取模块组成,两模块用迭代方法结合起来,使得关系抽取的模板语法特征和知识语义特征能被实体识别利用,可在保证准确率的同时提高召回率,两项任务均得到更好的效果。 3.1.2 基于thebeast引擎的OIE 文献[32]使用MLN另一个常用引擎thebeast实现了二元OIE,其主要思想类似于语义角色标注,即关系短语rij可作为谓语,而实体是谓语的某种语义角色,所以可先抽取谓语,而且将实体—关系抽取联合进行。在thebeast工具包中,公式分局部与全局两种,可涉及任意个可观察基原子(由已知信息可获得的证据谓词)但只包含一个隐基原子(需经过推理判别其真值的查询谓词)的公式为局部公式。为实现OIE,可定义如表3所示的3个局部公式。 表3 局部公式 与局部公式不同,全局公式可包含多个隐基原子,用来处理涉及多个实体—关系时的约束关系,以保持一致性。为实现OIE,可定义如表4所示的9个全局公式。 表4 全局公式 如对于语句“With the rapid rise of mechanization in the late 19th and 20th centuries, farming tasks could be done with a speed and on a scale previously impossible.”由公式⑴可推断“be done”为谓语,由公式(2)可推断“be done with”为关系短语,由公式⑶可推断“farming tasks”、“a speed”可作为谓语的某种语义角色,由公式(4)~(6)可推断“farming tasks”、“a speed”分别在“be done with”之前和之后,且可构成三元组(farming tasks, be done with, a speed),由公式(7)~(8)也可由三元组反过来验证实体与关系短语的确切的前后位置(双向联合推理),由公式(9)~(10),若已知该句的实体及关系,且该句与其它句相似,则可推断其它句的实体及关系,公式(11)~(12)在结构上进行约束,即谓语的每个语义角色仅有一个,可避免冗余。 Thebeast中的MAP推理采用以整数线性规划(Integer Linear Programming, ILP)[33]为基本求解器(base solver)的割平面推理(Cutting Plane Inference, CPI)算法[34],权重学习采用在线最大边际(Online Max-Margin)算法[35]进行。从文献[32]中的实验结果可知,采用基于MLN的联合推理方法进行开放式信息抽取,对实体、关系抽取的准确率、召回率、F值等主要评价指标均优于TextRunner,从而说明联合推理的方法要好于独立抽取的效果。 但上述方法同样存在无信息量的问题,从WOE及OLLIE的经验可知,采用句法特征可增加信息量,于是可引入可观察谓词dep(h,m,d),表示h处有指向m处的依存弧d。本文定义了如表5所示的部分模板,很容易将其转化为Markov逻辑公式。 表5 基于句法特征的部分抽取规则 将深层句法特征融入联合推理中,可得到更为丰富的信息抽取结果,如从“The professor of UCLA, Judea Pearl, won the A.M. Turing Award of the year”中不仅可得到(Judea Pearl, won, the A.M. Turing Award),还可抽取出(Judea Pearl, is, a professor of UCLA)、(A.M. Turing, is, an award)等基本信息,这是仅仅通过动词所不能表达的。同时,为减轻深层句法特征对抽取效率的影响,可采用Malt、DepPattern等高效的句法分析器。此外,开放式信息抽取不应局限于二元实体,可设计能从语句中抽取多元实体关系的模板,比如“{The peasant}nsubjcarries{the rabbit}dobj, {holding}xcompit by its ears”、“Benoit talked to Michel in order tosecure{the account}dobj”等句式。应用联合推理进行n元完整信息抽取将是未来的发展趋势。 信息抽取不应局限于从非结构化文本中高效并准确地挖掘信息,而应为更高层次的应用(如决策、问答等)起到辅助的作用;抽取结果构成的知识库也不应成为静态的存储信息的容器,而应成为能从文本的隐含事实中推断新信息的知识挖掘模型。多数现有的信息抽取系统仅仅抽取文本中叙述的事实,并非真正意义上的知识库,如OLLIE能从Web文本中抽取大量实体关系,但并未对其有效组织。有些系统融入了规则学习,如NELL(the Never-Ending Language Learner)[36]采用半监督的bootstrapping方法,给定初始本体类别和种子(如personHasCitizenship: 与众不同的是,KOG[39]应用MLN联合推理方法将Wikipedia的Infobox与WordNet相结合自动构建出丰富的本体结构,既避免了Wikipedia的异构、冗余、不规范的缺陷,也弥补了WordNet缺乏属性结构的不足,形成实体—属性—值的机器可读的结构,为Wikipedia进行包含SQL查询、专题浏览等功能的深层问答应用做了铺垫;VELVET[40]仅需输入种子本体,利用联合推理在背景知识库与目标关系间自动建立最佳本体映射,通过远距离监督为目标关系启发式地生成训练样本,并采用本体平滑方法学习关系抽取器,能在最弱监督下抽取关系,也为结构化知识库的构建奠定了基础。文献[41]利用句法和语义特征将OIE与关系聚类、消歧等技术整合,自动构建出基于Wikipedia的较为完备的语义网络,也为大规模语义信息的本体化提供一种思路。 Markov逻辑作为目前较为理想的一阶逻辑概率模型,既能使一阶谓词逻辑、产生式规则焕发生机,又能充分利用概率方法处理不确定性问题,使两者优势互补,但其应用很大程度上受限于推理效率,其表达能力仍为命题逻辑的层次。文献[42]指出,图模型中的近似推理仍为NP难问题,即便是非常受限的命题语言也不易于处理。但近期提升概率推理(Lifted Probabilistic Inference)[43]使得推理的简化成为可能,OLPI[44]就通过coarse-to-fine的本体结构提高了推理和学习效率。文献[45]将其与Markov逻辑整合,提出了简易Markov逻辑(Tractable Markov Logic, TML),并证明是目前最为丰富和高效的逻辑语言之一。在TML中,领域知识分解为若干部分,各部分取自事物类的层次化结构,依据此结构,各部分进一步分解为子部分,以此类推。 TML知识库是规则的集合,有3种形式,如表6所示(x、X分别表示变量和常量)。 表6 TML的语言形式 子类规则表示C1是C2的子类,而且相同类的子类是独立的。子部分规则含意为C1类的对象包含C2类的n个子部分P,默认为n=1。子部分规则为不带权重的严格公式,因为局部分解的不确定性可通过子类规则表达。而且严格公式之间不存在矛盾,因为有矛盾的知识库的分配函数为零。关系规则表示类C对象的子部分P1,P2…之间存在关系R,R为不存在这样的关系。关系规则的参数采用权重而不是概率,使得TML知识库更为简洁,因为权重仅需表示从父类到子类的对数概率的变化,这样就可以省略无变化的关系。 TML的层次化类图中的节点表示类(非叶节点)或实例(叶节点),若满足Is(B,A)则有从A到B的边,且图中必须有既不是任何类的子类也不是其子部分的顶层类,顶层类中仅有一个对象。如图3所示,是描述食物链的简略TML知识库,其含义为顶层对象食物链包含捕食性、寄生性、碎食性3个子部分,捕食性食物链又可细分为高级消费者(通常为肉食性动物)、次级消费者(通常为植食性动物)、生产者(通常为植物)等子类,在高级消费者这一子类中,河马、鳄鱼这两个子部分的关系为捕食。 图3 TML知识库举例 TML的表示能力很强,允许概率继承层次化结构和高树宽的关系模型,如规模为n的非递归概率上下文无关文法可用TML知识库在多项式计算复杂度内表示,证明详见文献[45]。 作为一种逻辑语言,TML与描述逻辑很相似,但减少了很多限制,如允许在某子类的子部分之间存在任意参数的关系。TML易于处理是因为层次化类结构与局部分解的嵌套组合降低了MLN分配函数的复杂度,即每步仅处理一个子集,能进行高效的大规模一阶逻辑推理,适用于语义Web等很多领域。 自然语言中的许多表述在句法和语义上可分解为层次化的类/局部结构,文本通常包含对象间存在的各种关系。自然语言中的概念和关系包含的丰富的本体结构通过TML能简洁地表示事件与关系的语义信息,从而可将从非结构化文本抽取到的信息组织成TML知识库。文献[46]就提出了一种利用TML将语句分析、事件抽取、知识库归纳联合处理的设想。利用TML进行信息抽取及知识库构建是一个很有前景的领域,虽然TML的理论刚提出不久,应用案例尚未成熟,但可以预见TML在本体知识推理中将扮演重要角色。 开放式信息抽取能在无人工标注的非限定领域的海量文本中自动抽取非限定语义单元类型的实体关系对,是从非结构化文本中挖掘知识的主要途径,对深入理解文本起到关键作用。本文按时间顺序,对KnowItAll、TextRunner、WOE、ReVerb、R2A2等典型二元OIE系统进行总结与分析,其主要局限是仅抽取以动词为核心的关系,而且未兼顾上下文全局信息,这样会使信息量及置信度不足。新一代OLLIE系统针对这两点进行了深度改进,使二元实体关系抽取提升到较高水平。但实际的实体关系并非仅此而已,高阶n元实体关系占有较大比例。KRAKEN系统巧妙地引入句法特征,通过依存路径可较为准确地检测到n元实体关系,为OIE的发展又开创了先河。 但上述开放式实体关系抽取方法无法深入字里行间以达到推断文本深层含义的目的。为实现机器阅读的深入理解文本的宏伟目标,采用联合推理的方法可有效推断出文本传达出的更为丰富的信息。本文将概率联合推理分为Markov逻辑和coarse-to-fine本体推理两类,并分析了StatSnowball、EntSum、thebeast等采用Markov逻辑进行开放式信息抽取的方法。基于Markov逻辑的OIE在某种程度上可提升性能,但限于推理效率的瓶颈,与实现高效的大规模网络信息抽取仍有一定距离,而且固定格式的平面结构关系对也不利于知识库构建、决策、问答等深层语义任务的进行。在提升概率推理的基础上,以TML为代表的本体推理的提出突破了Markov逻辑的困境,可以清晰地构建出层次化的本体知识库,有效地表示复杂的知识体系,以支持推理及自动知识发现。 信息抽取是进行决策、问答等深层语义任务的主要渠道,然而目前大多数方法是将各阶段目标分解为独立的子任务再集成,这样做的弊端是: ①前一阶段无法识别的在后续阶段不再出现,而后续阶段要依赖之前的结果进行,信息因此而不完整;②前一阶段识别错误的对后续阶段又是误导,而此时后续阶段又无法通过其它信息纠正错误,错误率因此而累积;③后续阶段任务会为之前的任务提供很多有用的特征,而如果顺序式处理各阶段任务将屏蔽此辅助与优化的功能。之所以采用联合推理进行信息抽取,一方面可以推断表面文字所不能显示的深层隐含信息,另一方面就是综合各阶段子任务,相互融合、相互补充、相互促进,像杠杆一样在各方面之间寻求平衡,以趋向整体上的理想效果。如果说开放式信息抽取是机器阅读的强有力的采集工具,Markov逻辑又为其锦上添花的话,那么基于本体结构的联合推理方法将是在自动深入理解文本的征程上迈出的深远的一步。 [1] Oren Etzioni, Michele Banko, Michael J. Cafarella. Machine reading[C]//Proceedings of AAAI Conference on Artificial Intelligence, 2006. [2] K Barker, B Agashe, S Chaw, et al. Learning by reading: A prototype system, performance baseline and lessons learned[C]//Proceedings of 22nd National Conference of Artificial Intelligence, 2007. [3] 赵军,刘康,周光有,蔡黎.开放式文本信息抽取[J].中文信息学报,2011,25(6):98-110. [4] O Etzioni, M Cafarella, D Downey, et al. Unsupervised named-entity extraction from the web: An experimental study[J]. Artificial Intelligence, 2005, 165(1):91-134. [5] Michele Banko, Michael J Cafarella, Stephen Soderland, et al. Open information extraction from the web[C]//Proceedings of IJCAI, 2007. [6] Michele Banko, Oren Etzioni. The tradeoffs between open and traditional relation extraction[C]//Proceedings of Annual Meeting of the Association for Computational Linguistics, 2008. [7] F Wu, D S Weld. Open information extraction using Wikipedia[C]//Proceedings of Annual Meeting of the Association for Computational Linguistics, 2010: 118-127. [8] Fei Wu, Daniel S Weld. Automatically semantifying Wikipedia[C]//Proceedings of the 16th Conference on Information and Knowledge Management, 2007. [9] Anthony Fader, Stephen Soderland, Oren Etzioni. Identifying relations for open information extraction[C]//Proceedings of Conference on Empirical Methods in Natural Language Processing, 2011. [10] Oren Etzioni, Anthony Fader, Janara Christensen, et al. Open information extraction: the second generation[C]//Proceedings of International Joint Conference on Artificial Intelligence, 2011. [11] Mausam, Michael Schmitz, Robert Bart, Stephen Soderland, Oren Etzioni. Open Language Learning for Information Extraction[C]//Proceedings of Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CONLL), 2012. [12] Janara Christensen, Mausam, Stephen Soderland, Oren Etzioni. An analysis of open information extraction based on semantic role labeling[C]//Proceedings of K-CAP, 2011: 113-120. [13] Johannes Hoffart, Fabian M. Suchanek, Klaus Berberich, et al. YAGO2: A Spatrally and Iemporally Enhanced Knowledge Base Powwikipedia[J].Artificial Intelligence, 2013,194:28-16. [14] Xiao Ling, Daniel S.Weld. Temporal information extraction[C]//Proceedings of the 24th AAAI Conference on Artificial Intelligence, 2010. [15] Gerhard Weikum, Nikos Ntarmos, Marc Spaniol, et al. Longitudinal analytics on web archive data: It’s about time![C]//Proceedings of CIDR, 2011: 199-202. [16] Alan Akbik, Alexander Loser. KRAKEN: N-ary Facts in Open Information Extraction[C]//Proceedings of AKBC-WEKEX at NAACL, 2012: 52-56. [17] Alan Akbik, Jurgen Bross. Wanderlust: Extracting semantic relations from natural language text using dependency grammar patterns[C]//Proceedings of the 1st Workshop on Semantic Search at 18th WWWW Conference, 2009. [18] D T Bollegala, Y Matsuo, M Ishizuka. Relational duality: Unsupervised extraction of semantic relations between entities on the web[C]//Proceedings of the 19th international conference on world wide web, 2010: 151-160. [19] Bonan Min, Shuming Shi, Ralph Grishman, Chin-Yew Lin. Ensemble Semantics for Large-scale Unsupervised Relation Extraction[C]//Proceedings of Empirical Methods in Natural Language Processing and Computational Natural Language Learning, 2012: 1027-1037. [20] M Mintz, S Bills, R Snow, D Jurafsky. Distant supervision for relation extraction without labeled data[C]//Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP, 2009: 1003-1011. [21] Del Corro L, Gemulla R. ClansIE: Clanse-based Open Information Extraction[C]//Proceedings of the 22nd International conference on world wide web, 2013: 355-366. [22] Andrew McCallum. Joint Inference for Natural Language Processing[C]//Proceedings of the 13th Conference on Computational Natural Language Learning, 2009. [23] P Domingos, D Lowd. Markov Logic: An Interface Layer for Artificial Intelligence[M]. Morgan & Claypool, San Rafael, CA, 2009. [24] Wanxiang Che, Ting Liu. Jointly Modeling WSD and SRL with Markov Logic[C]//Proceedings of the 23rd International Conference on Computational Linguistics, 2010: 161-169. [25] Yang Song, Jing Jiang, Wayne Xin Zhao, et al. Joint Learning for Coreference Resolution with Markov Logic[C]//Proceedings of Conference on Empirical Methods in Natural Language Processing, 2012. [26] Xipeng Qiu, Ling Cao, Zhao Liu, Xuan jing Huang. Recongnizing Inference in Iexts with Markov Logic Networks[J]. ACM Language Information Processing, 2012, 11(4), Article 15. [27] Hongjie Dai, Richard Tzong-Han Tsai, Wen-Lian Hsu. Entity Disambiguation Using a Markov Logic Network[C]//Proceedings of the 5th International Joint Conference on Natural Language Processing, 2011: 846-855. [28] Hoifung Poon, Pedro Domingos. Joint Inference in Information Extraction[C]//Proceedings of the 22nd National Conference on Artificial Intelligence, 2007: 913-918. [29] Jun Zhu, Zaiqing Nie, Xiaojiang Liu, Bo Zhang, Jirong Wen. StatSnowball: a statistical approach to extracting entity relationships[C]//Proceedings of the 18th international conference on World Wide Web, 2009: 101-110. [30] E Agichtein, L Gravano. Snowball: Extracting relations from large plain-text collections[C]//Proceedings of the 5th ACM International Conference on Di-gital Libraries, 2000. [31] Xiaojiang Liu, Nenghai Yu. People Summarization by Combining Named Entity Recognition and Relation Extraction[J]. Journal of Convergence Information Technology, 2010, 5(10): 233-241. [32] Yongbin Liu, Bingru Yang. Joint Inference: a Statistical Approach for Open Information Extraction[J]. Appl. Math. Inf. 2012, 6(2): 627-633. [33] James Clarke. Global Inference for Sentence Compression: An Integer Linear Programming Approach[D]. PHD thesis, University of Edinburgh, 2008. [34] Sebastian Riedel. Efficient Prediction of Relational Structure and its Application to Natural Language Processing[D]. PHD thesis, University of Edinburgh, 2009. [35] Tuyen N. Huynh, Raymond J. Mooney. Online Max-Margin Weight Learning for Markov Logic Networks [C]//Proceedings of the 11th SIAM International Conference on Data Mining, 2011: 642-651. [36] A Carlson, J. Betteridge, B. Kisiel, et al. Toward an architecture for never-ending language learning[C]//Proceedings of the 24th National Conference on Artificial Intelligence, 2010: 1306-1313. [37] Thahir Mohamed, Estevam R. Hruschka Jr., Tom M.Mitchell. Discovering Relations between Noun Categories[C]//Proceedings of EMNLP, 2011. [38] S Schoenmackers. Inference over the web[D]. PHD thesis, University of Washington, 2011. [39] Fei Wu, Daniel S. Weld. Automatically refining the wikipedia infobox ontology[C]//Proceedings of the 17th International Conference on World Wide Web, 2008. [40] Congle Zhang, Raphael Hoffmann, Daniel S. Weld. Ontological Smoothing for Relation Extraction with Minimal Supervision[C]//Proceedings of AAAI, 2012. [41] A Moro, R Navigli. Integrating Syntactic and Semantic Analysis into the Open Information Extraution Paradigm[C]//Proceedings of IJCAI, 2013. [42] D Roth. On the hardness of approximate reasoning[J]. Artificial Intelligence, 1996, 82:273-302. [43] V Gogate, P Domingos. Probabilistic theorem proving[C]//Proceedings of the 27th Conference on Uncertainty in Artificial Intelligence, 2011:256-265. [44] C Kiddon, P Domingos. Coarse-to-fine inference and learning for first-order probabilistic models[C]//Proceedings of the 25th AAAI Conference on Artificial Intelligence, 2011:1049-1056. [45] P Domingos, Austin Webb. A Tractable First-Order Probabilistic Logic[C]//Proceedings of the 26th AAAI Conference on Artificial Intelligence, 2012. [46] Chloe Kiddon, Pedro Domingos. Knowledge Extraction and Joint Inference Using Tractable Markov Logic [C]//Proceedings of AKBC-WEKEX at NAACL, 2012: 79-83.
2.2 n元开放式实体关系抽取

3 基于联合推理的开放式信息抽取
3.1 基于Markov逻辑网的OIE
3.2 基于本体推理的信息抽取
4 总结与展望
