基于带汇点流形的面向属性抽取式观点摘要
2014-02-28徐学可谭松波程学旗
徐学可,谭松波,刘 悦,程学旗
(1. 中国科学院 计算技术研究所,北京 100190;2. 中国科学院大学,北京 100190)
引言
观点摘要技术帮助人们快速、高效地把握海量顾客点评中的主要观点信息。传统的观点摘要技术往往从点评数据中抽取扁平式的观点句子列表作为摘要[1],来传达点评中的重要观点信息。然而,顾客通常针对评论实体的特定属性(aspect)(例如,餐馆的环境、服务等)发表观点;同时,不同的用户也关注不同的属性。因此,观点摘要技术应该深入到属性层次。本文中,我们研究面向属性的抽取式观点摘要,该任务针对特定属性,从给定实体的点评集中抽取少量观点句子,用以传达点评中顾客对该属性的主要观点信息。相对于传统的摘要形式,该任务可以按照实体的属性信息把摘要组织成结构化形式,从而方便用户定位感兴趣属性的观点信息,同时帮助用户更深刻、全面地了解实体。
总体而言,目前大部分方法[2-4]主要考虑句子本身的局部性信息,例如,是否包含属性相关观点及观点的强度等,来孤立地选择句子作为摘要,没有充分考虑到点评集中候选句子间观点相似性的全局性信息、摘要结果中句子间的观点差异性要求。同时,观点的识别也往往基于一个通用观点词典。针对现有方法不足,我们提出1)利用属性相关观点词知识来抽取满足富含信息(informativeness)要求的摘要,也就是说摘要不能仅仅给出好或坏等泛泛观点,而是要给出好或坏的具体体现等更具体有意义的信息,而属性相关观点词相对通用观点词来说通常能对相应属性提供更有意义的描绘[5];2)利用点评集中候选句子间观点相似性关系的全局性信息来抽取重要的观点(重要性, salience),也就是说所抽取的句子能一定程度上能传达点评中很多其他句子中的相关观点信息;3)同时考虑摘要结果中句子间的差异性要求来消除摘要中的冗余观点,抽取多样性的观点(多样性, diversity),从而尽可能多的覆盖点评中的重要观点信息,最大化满足潜在用户的多样性的信息需求。为此我们提出了基于带汇点的流形排序[6]的一体化的摘要抽取模型,在一体化的流形排序过程中同时考虑这三方面要求,来抽取高质量的观点摘要。
本文的主要贡献在于:
1. 针对面向属性抽取式观点摘要,提出富含信息、重要性及多样性三方面质量要求;
2. 提出了基于带汇点流形排序的一体化摘要抽取模型,在一体化的流形排序过程中同时考虑这三方面要求,来抽取高质量的观点摘要。
1 相关工作
面向属性抽取式观点摘要系统通常包含两个部分: 属性抽取及面向属性观点摘要抽取。
对于属性抽取,部分工作从点评中抽取显式的评价对象作为属性。这些评价对象包括产品的部件(component)或者特性(attribute)等[3]。近年来,统计话题模型如PLSA、LDA 及其各种变种在属性抽取中得到广泛应用。在这些工作中[4, 7],属性被视为隐含的话题,或者词空间上的概率分布,所抽取的每个属性具有完备一致的语义表示,体现了语义相关的一系列评价对象信息。
对于摘要抽取,目前大部分研究往往仅根据句子是否包含属性相关观点及观点的强度[2-4]来进行挑选。例如,Hu等人[2]从包含属性信息的句子中抽取形容词作为观点词,以此识别属性相关观点句子作为摘要。Ling等人[4]按句子语言模型与预先学习的属性模型的负Kullback-Leibler(KL)距离将句子归类到不同属性,然后对各个属性挑选相似度分值靠前的句子作为摘要。此外,Blair-Goldensohn 等人[3]迭代地选择满足给定情感极性要求的具有最大极性可信度的属性相关句子作为摘要,其中每个迭代步使用一个标记来控制当前挑选句子需满足的情感极性要求,以此控制最终摘要的褒贬分布大体与点评中实际分布相符。从某种程度讲,该方法考虑摘要结果中观点的差异性,但这种差异性仅仅体现在情感极性,因而不能充分保证观点的多样性。
2 方法框架
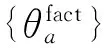
第二个阶段是在线摘要抽取阶段,给定实体的点评集(如一家候选餐馆)及属性a(如餐馆的环境),我们利用带汇点的流形排序过程来抽取少量句子作为摘要。具体过程如下:
针对属性a,我们构造全局流形结构,也就是带权网络,其中节点包括句子及一个代表属性及属性相关观点词知识的源节点。句子跟源节点间边的权重体现句子是否包含属性相关的明确有意义的观点,而句子间边的权重体现了句子是否针对该属性传达相似的观点。
接下来是迭代地选择句子作为摘要,直到达到给定的摘要长度限制。在每个迭代步,我们利用流形结构上的流形排序过程来挑选一个句子作为摘要,并把该句子调为汇点。
3 属性观点联合模型
3.1 模型描绘
传统LDA模型[8]所抽取话题往往不能对应于属性[7]。我们观察到,一个分句(clause)往往只涉及一个属性。因此为了让抽取的话题对应于属性,我们可以利用分句层次的词共现信息。然而,直接在分句集合上进行挖掘,往往受到分句数据稀疏性影响。为此,我们构建虚拟文档,给定一个词,将出现该词的所有分句连接得到的大文档,称为该词对应的虚拟文档(Virtual Document)。我们的模型应用到虚拟文档集上而不是分句集或点评文档集上。这样,我们就可以克服分句的数据稀疏性问题同时充分利用分句层次词共现信息,来更好抽取属性。给定特定领域顾客点评集,其中点评中每个分句视为一个词序列。假设我们有D个虚拟文档,每个虚拟文档视为相应分句的词序列连接构成的一个大词序列,而每个词是一个词典中的一个项目,这里词典中包含V个词,分别记为w=1,...,V。虚拟文档vd中的第n个词wv d,n与两个变量关联:zv d,n跟ζv d,n。其中,zv d,n表示属性;ζv d,n为主客观标签(subjectivity label),表示该词是传达情感(褒或贬)的观点词(ζv d,n=opn)还是不传达情感的客观词(ζv d,n=fact)。根据JAO模型,虚拟文档集的产生过程如下:
1. 对于每个属性 z:
(a) 对主客观标签opn 跟fact, 分别从参数为β的Dirichlet分布中选择一个词分布Φz,fact~Dir(β);Φz,opn~Dir(β).
2. 对每个虚拟文档vd:
(a) 从参数为α的Dirichlet分布选择一个属性分布θw d~Dir(α)
(b) 对vd中的每个词wv d,n:
(i) 按属性分布θv d采样一个属性zv d,n~θv d
(ii) 按主客观标签分布νv d,n选择一个主客观标签ζv d,n~vv d,n
(1) 如果ζd,s,n=opn, 按词分布产生Φzv d,n,opn产生wv d,n:wv d,n~Φzv d,n,opn
(2) 否则,按词分布Φzv d,n,fact产生wv d,n:wv d,n~Φzv d,n,fact
3.2 如何区分观点词跟客观词
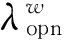
这样,主客观标签ζv d,n的赋值很大程度上由wv d,n是否出现在观点词典中决定。
3.3 模型参数估计
我们采用collapsed Gibbs sampling[9]方法来对所有zv d,n及ζv d,n变量的赋值进行后验估计。根据collapsed Gibbs sampling,变量赋值按一个给定所有其他变量赋值及观察数据下的条件概率分布依序选择产生。这里,zv d,n和ζv d,n的赋值根据以下条件概率分布联合选择产生:
其中w是虚拟文档集的总词序列;T是事先指定的属性个数;z及ζ分别是这个词序列(除了vd中第n个词外)上词的属性及主客观标签赋值序列;是vd中词的个数是vd中词被赋值为属性t的次数是w上任何词(或者词w)赋值为属性t及主客观标签l的次数。以上所有次数统计都排除vd的第n个词。
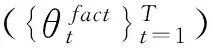
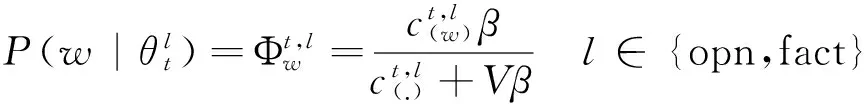
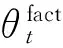
4 摘要抽取
我们利用带汇点的流形排序过程从点评集中抽取少量句子作为摘要,用来传达顾客对于该属性的主要观点信息。作为一种半监督的排序方法,流形排序[10]基于全体对象内在的全局流形结构(带权网络)以及一个输入查询(对应带权网络中的源节点),利用各个节点在带权网络上的排序分值迭代传播直至达到平衡的流形排序过程来寻找查询相关并且重要的对象。 Cheng等人[6]在流形结构中引入汇点对应已经挑选的节点,并在流形排序中对与汇点相近的节点进行惩罚,从而能进一步寻找多样性的节点。
4.1 基本概念
给定一个实体的点评集及属性a,我们有一组数据点χ={x0,x1,...,xn},x0为源节点代表客观属性及属性相关观点词知识,其他节点代表点评集中的各个句子。我们定义f=[f0,f1,…,fn]T为排序分值向量,其中fm为数据点xm的排序分值,作为挑选句子的依据,此外,y=[y0,y1,…,yn]T定义为先验向量,其中ym为数据点xm的先验分值。我们设置源节点x0的先验值为1,而句子节点的先验值为0。通过这样我们引入了客观属性词及属性相关观点词知识作为排序过程中的先验监督。
4.2 构造流形结构
针对属性a,我们构造全局流形结构,也就是数据χ上的带权网络,该流形结构同时捕获评论语料中句子间观点相似性关系的全局性信息和来自客观属性模型及属性观点模型的先验监督。在该带权网络中,句子间边的权重体现了句子是否针对该属性传达相似的观点(尤其是有意义的观点),而不是泛泛的内容相似。同时,我们认为一个完整的观点大致上由观点对象(由客观属性词反映)跟描绘该观点对象的观点词构成。综上,我们在计算权重时应该突出客观属性词跟属性观点词,具体定义如式(4)所示。
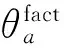
而句子跟源节点间边的权重体现句子是否包含属性相关的有意义的观点。具体定义如式(5)所示。
4.3 摘要抽取
基于上节所构造的流形结构,我们采用迭代选句子的方式来生成摘要,每个迭代步利用带汇点的流形排序过程(也就是排序分值迭代传播的过程)来挑选一个句子进入摘要,并把该句子调为汇点。这个摘要过程如下:
1 初始,所有数据点都设置为自由点。
2 构建流形上的数据点的关系矩阵(affinity matrix)W,其中Wi,j是数据点xi与xj间边的权重。这里,Wi,i设为0,以避免排序分值的自我传播。
3 对称地归一化W如下:S=D-1/2WD-1/2,这里D为对角矩阵,其中Dii等于W行i的所有元素之和。
4 重复如下的步骤,每步挑选一个句子进入摘要。直到摘要达到指定的长度限制(通常为100词)。
4.1 迭代计算f(t+1)=αSIff(t)+(1-α)y直到收敛,其中0≤α≤1控制句子相互关系信息跟先验知识二者的相对重要性(我们参考PageRank算法,设置α为0.85)。而If是个对角指示矩阵,当数据点xi为汇点时,其(i-i)元素为0 时指示,否则为1。
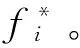
4.3 选择分值最大的自由句子(假设为xm)进入摘要,同时将xm调为汇点也就是说设置If的(m-m)元素为0。
步骤4.1 是核心步骤,数据点的排序分值在先验知识的监督下沿着带权网络迭代传播直到收敛。在这个过程中源节点起着先验基督的作用,使得与源节点接近的句子得到更多的排序分值,从而帮助抽取包含富含信息的属性相关观点的句子。同时,充分利用全局性的句子间关系信息,使得与很多其他句子接近的句子能得到更多的排序分值,由于句子间边关系权重反映二者是否针对该属性传达相似的观点(其中强调属性相关观点词),而不是泛泛的内容相似,因此所抽取的句子能同时传达很多其他句子中的属性相关观点信息(尤其是富含信息的有意义观点)。此外,所有在之前步骤步中已经挑选为摘要的句子都调为汇点,并停止向周围数据点传播分值。这样与这些句子接近的句子,也就是针对该属性有相似观点的句子,在分值传播过程中很自然地受到惩罚。这样我们避免挑选与已有摘要观点冗余的句子,从而保证摘要中观点的差异性。
带汇点的流形排序具有很好的收敛性质和完备的优化框架解释[6]。基于该排序过程,我们以一种有充足理论基础的方式,同时捕获富含信息、重要性及多样性这三方面要求,从而达到这三方面性能的平衡和最终摘要质量的优化,避免了启发式方法带来的随机性和性能不平衡。
5 实验结果及分析
5.1 实验设置
5.1.1 点评数据
我们的实验评估利用公开的餐馆点评集[11]及我们从汽车点评网站www.edmunds.com采集的汽车点评集。餐馆点评集包含从CitySearch旅游网站采集的涉及5 531个纽约餐馆的52 264篇顾客点评。餐馆点评集已经做了包括句子分割、词性标注等预处理。平均每篇点评包含大约5.28个句子。汽车点评集的数据预处理与餐馆点评集类似,包括断句、词性标注、否定词处理及停用词去除等。汽车点评集包含329 个车型(car model,例如,“ford focus 2008”)的共14 718 篇点评719 329 个句子。
5.1.2 JAO学习相关
为了进行JAO的学习,我们需要构造虚拟文档。为此,我们首先根据冒号跟逗号对每个句子进一步分割,得到分句,然后基于一个停用词表*http://ir.dcs.gla.ac.uk/resources/linguistic_utils/stop_words/进一步去除停用词。最终每个分句都转化为带词性标注的词序列。例如, “the quality is good” 变换为 “quality_noun good_adj”。我们仅仅选择点评集中出现次数不少于20次的形容词、名词、动词及副词来构造虚拟文档。出现次数过少的词对应的虚拟文档往往没有充分的共现信息;而其他词性的词往往是一些不具备实义的没有属性区分能力的功能词。对于每个选择的词,我们把出现该词的所有分句的词序列连接,构成相应的虚拟文档的词序列。
我们执行100轮Gibbs sampling迭代。根据文献[12],属性个数T设置为14;按照现有研究的惯例[9]设置α=50/T及βw=0.1,没有针对我们的数据进行专门调试。实验中采用的观点词典基于两个公开的知识库构建: MPQA Subjectivity Lexicon*http://www.cs.pitt.edu/mpqa/与SentiWordNet*http://sentiwordnet.isti.cnr.it/。
5.1.3 摘要质量评估设置
对于餐馆点评集合,我们选择了点评数量最多的10个餐馆;同时参照文献[5],选择 “Food”、“Staff”及“Ambiance”三个主要的属性用以评估。对于汽车点评集,我们选择点评数量靠前的10 款车型,其中为了保证车型多样性,对每个汽车制造商我们仅仅选择一款车型。我们选择网站www.edmunds.com 定义的5 个主要属性用以评估: “Body Styles”、“Powertrains & Performance”、“Safety”、“Interior Design &Features”及 “Driving Impressions”。
我们首先使用ROUGE自动文摘评价工具(ROUGEeval-1.5.5版*http://haydn.isi.edu/ROUGE/)进行定量的摘要质量评估。ROUGE通过计数自动摘要跟人工生成的参考摘要间共同的词序列或N元词串来定量评估自动摘要的质量。为了进行ROUGE定量评估,对于餐馆的每个属性,我们分别构造参考摘要。具体地,我们浏览该餐馆点评文本,发现该属性的主要观点信息(观点对象及观点词搭配,例如,“bland cupcake”)。我们挑选体现这些观点的少量句子(总共大概100词),其中排除仅仅包含泛泛而谈观点的句子,同时消除参考摘要中没有提供新观点信息的冗余观点句子。表1给出了一个参考摘要实例。对于汽车点评集,由于www.edmunds.com网站对各型汽车的主要属性分别提供了编辑点评,我们用编辑点评作为摘要质量定量评估的参考摘要。
ROUGE 指标主要度量摘要的整体质量,为了进一步针对富含信息、重要性、多样性等具体要求进行评估,我们额外设计了如下指标。
平均观点覆盖度: 主要衡量所抽取摘要是否传达点评集中的重要的富含信息的相关观点。具体地,平均观点覆盖度是各个摘要句子的观点覆盖度的平均,而摘要句子的观点覆盖度度量了该句子是否覆盖了点评集中的很多句子的属性相关观点(尤其是富含信息的观点)。该度量主要反映了摘要是否满足重要性要求。
平均观点相似度: 度量了摘要句子间的平均观点相似度。该度量反映了摘要结果的观点差异性要求,分值越低表明差异性越大,也越好。该度量主要反映了摘要是否满足多样性的要求。
5.1.4 摘要抽取基准方法

MR: 这个方法与MRSP的区别是没有引入汇点机制,根据经典流形排序对句子排序,然后依序选择句子。这个方法仅仅考虑重要性及富含信息要求,没有考虑多样性要求。
Prior: 这个方法依据公式5计算的流形结构中句子跟源节点的权重值来选择句子,没有经过流形排序过程。这个方法仅仅考虑富含信息要求没有考虑重要性跟多样性要求。
Prior.Gen: 该方法类似Prior, 区别在于公式5中使用通用观点模型代替属性观点模型。该方法没有考虑所提出的三方面要求,可以看作仅仅考虑观点属性相关性的传统方法的代表。
5.2 实验结果
表1 给出了某餐馆在“Food”属性上的自动摘要结果实例。从中我们可以看出,所抽取的摘要传达了针对该属性的非常有意义并且多样化的观点信息,例如,“the icing is sweet, smooth and buttery”, “the frosting is smooth and creamy”等。此外,抽取的摘要跟参考摘要相比非常相似:它们都关注共同的“food”属性相关的观点对象,例如,“icing”, “frosting” 及 “cupcakes”等对该餐馆的顾客主要点评的食品(而不是“chicken”等其他食品),同时相应的观点也非常相近,例如,“cake dry”,“frosting a bit/overly sweet”等,甚至参考摘要中的个别句子被自动方法直接抽取。
表2 给出了不同方法的在餐馆点评集上的定量性能比较(其中参数λ设置为0.5),我们采用了ROUGE-1 Average-F、ROUGE-2 Average-F及ROUGE-L Average-F三个具体指标。方括号给出了这些指标分数的95%置信区间。从表中可以看出,我们的方法在各个指标上均显著优于所有基准方法。这表明了我们方法的有效性。同时,该表也表明,所提出的三个要求对于抽取高质量摘要都必不可少。我们观察到Prior及MRSP分别显著优于Prior.Gen 及 MRSP.Gen。这表明,利用属性相关观点词相对于通用观点词能抽取更有意义的高质量观点摘要。我们也观察到MR方法显著优于Prior。这表明,考虑句子间观点相似性关系的全局性信息以抽取重要观点能帮助提高摘要质量。最后,我们观察到MRSP性能优于MR。这表明,通过引入汇点机制来惩罚冗余观点句子,提高摘要的多样性,进而提高摘要的质量。
从表3的结果(其中参数λ设置为0.15)中,我们可以观察到表2类似的结论。主要区别是: 属性相关观点词对性能提升相对不明显,具体体现在: 1) Prior及MRSP性能对Prior.Gen及MRSP.Gen的性能提升相对在餐馆点评集并不明显;2)λ最优值为较小的0.15,也就是属性相关观点词知识的相对重要性较低。由于作为参考文摘的编辑点评主要以提供专业的相对客观的介绍为主(在这一点,编辑点评似乎并不完全适合作为参考摘要,因此该结果的参考意义不如餐馆点评上的结果), 因此利用属性相关观点词来抽取富含信息观点在指标上获益不大。但是,依然可以看到我们的摘要模型可以抽取出跟编辑点评更加拟合的观点信息。

表1 针对某餐馆的“Food”属性的摘要实例
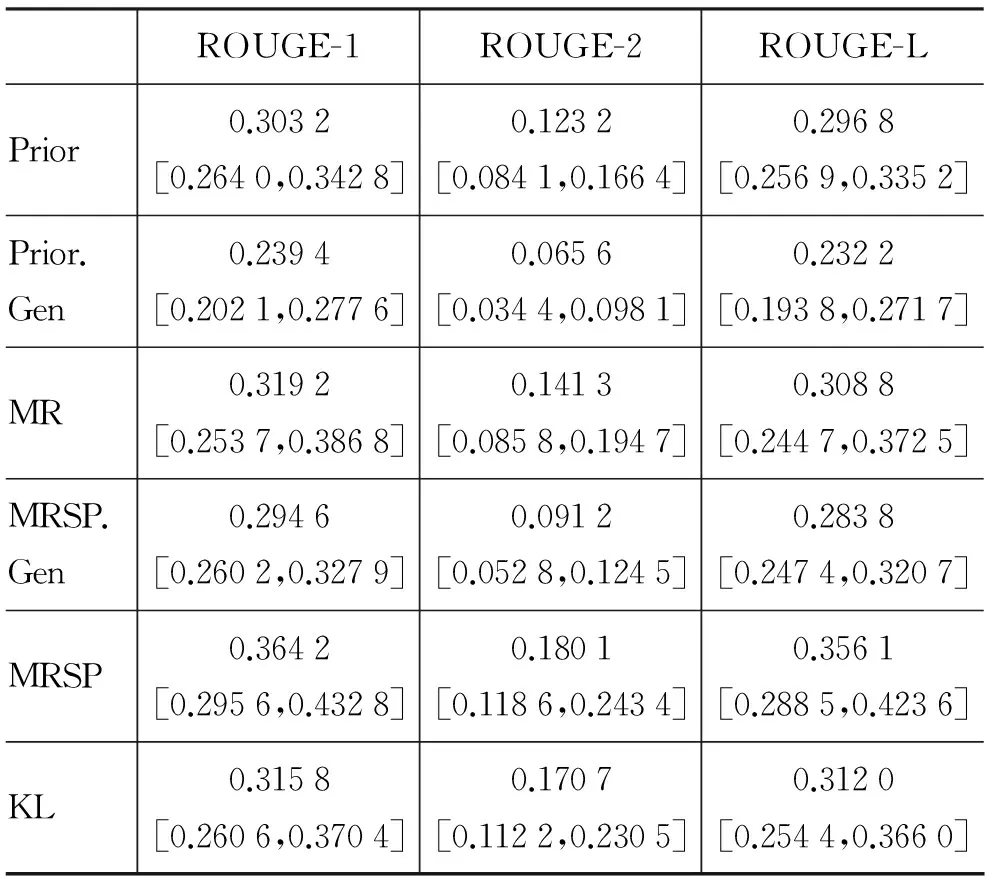
表2 不同摘要抽取方法在餐馆点评集上的定量性能比较
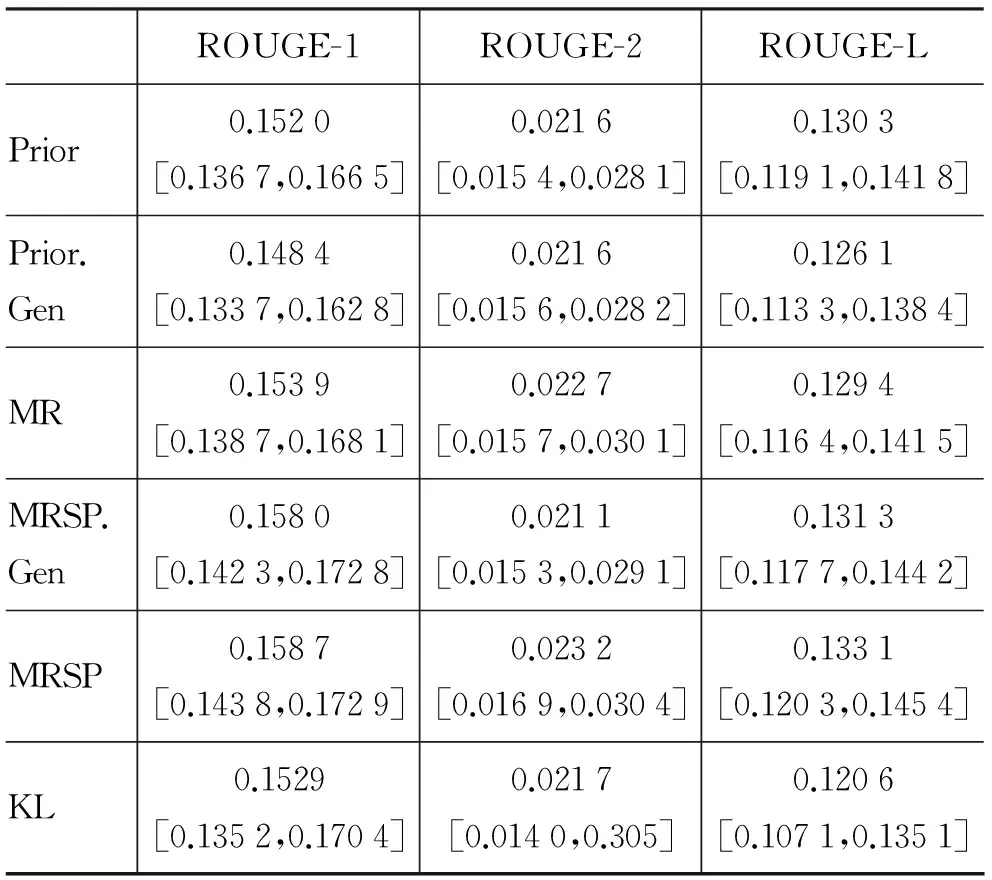
表3 不同摘要抽取方法在汽车点评集合上的定量性能比较
图1给出了餐馆点评上MRSP方法的随λ值变化的ROUGE-1 Average-F分值曲线。这里参数λ(见公式4、5)决定了属性相关观点词在摘要过程中的相对重要性。我们可以看到,ROUGE-1 Average-F分值随着λ值增加而增加,直到0.5。 这表明属性相关观点词能够帮助提高摘要质量;但λ值接近1时,分值曲线程下降趋势,这是由于过度强调观点词可能导致观点的相关性下降,毕竟客观属性词相对来说更能保证句子的属性相关性;当λ=1时,依然有可观的性能,超过单纯利用客观属性模型的方法(即λ=0)。这表明属性相关观点词信息本身就能抽取高质量的属性相关观点。
表4和表5分别给出餐馆和汽车点评上不同方法的平均观点覆盖度及平均观点相似度的结果。值得注意的是这两个指标没有利用人工参考摘要,因而更加客观。从表中可以看出: MRSP相对MR及Prior在平均观点相似度度(越低越好)上性能有显著的提升,同时在平均观点覆盖度上性能与MR相当。表明通过引入汇点, 能帮助抽取多样性的观点(Diversity),并且保证观点的重要性(Salience)不下降。同时,MR及MRSP相对Prior在平均观点覆盖上有显著的提升,表明利用流形排序过程能有效利用候选句子间相互关系,帮助抽取重要的观点(Salience)。
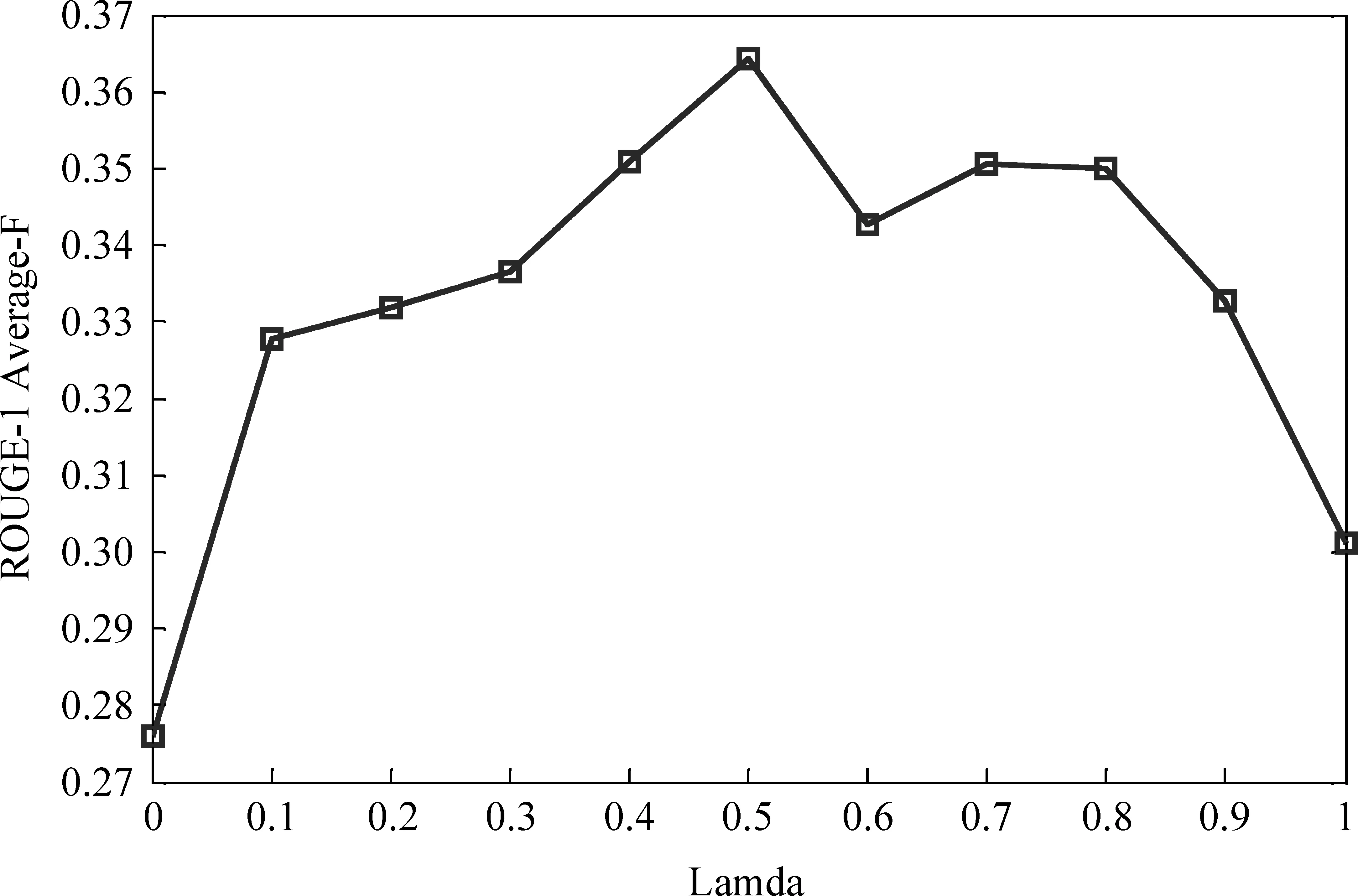
图1 餐馆点评上MRSP方法摘要性能(ROUGE1 Average-F)随λ变化曲线
表4餐馆点评上不同方法的平均观点覆盖度及平均观点相似度比较

平均观点覆盖度平均观点相似度度MRSP0.06155.2058E-4Prior0.04627.1470E-4MR0.06249.2979E-4
表5汽车点评上不同方法的平均观点覆盖度及平均观点相似度比较
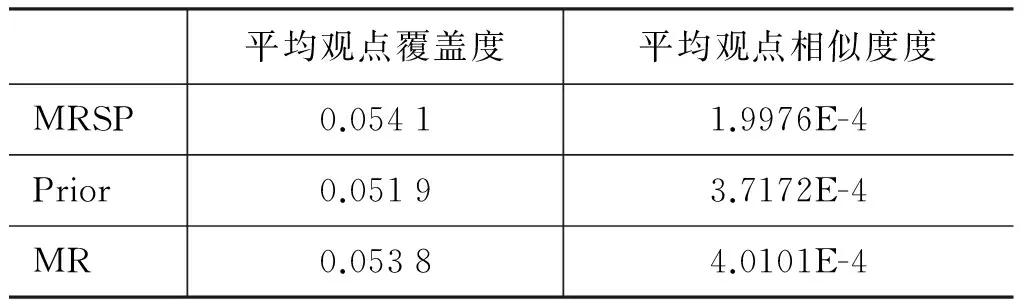
平均观点覆盖度平均观点相似度度MRSP0.05411.9976E-4Prior0.05193.7172E-4MR0.05384.0101E-4
6 小结与展望
本文研究面向属性抽取式观点摘要。目前大部分方法主要考虑句子本身的局部性信息,来孤立地选择句子作为摘要,没有很好考虑摘要质量问题。在本章,我们提出了基于带汇点的流形排序框架的一体化摘要抽取模型,以客观属性词及属性相关观点词知识作为先验监督,融合句子流形结构,同时考虑摘要结果句子的差异性要求来抽取满足富含信息、 重要性及多样性等的高质量摘要。实验验证了模型能抽取高质量的观点摘要,同时验证了所提出三个要求的合理性和必要性。
[1] K Lerman, S Blair-Goldensohn, R McDonald. Sentiment summarization: evaluating and learning user preferences[C]//Proceedings of the EACL ’09, 2009:514-522.
[2] M Hu, B Liu. Mining and summarizing customer reviews[C]//Proceedings of the SIGKDD, 2004:168-177.
[3] S Blair-Goldensohn, K Hannan, R McDonald, et al. Building a sentiment summarizer for local service reviews[C]//Proceeding of the WWW Workshop on NLP in the Information Explosion Era, 2008.
[4] X Ling, Q Mei, C Zhai, et al. Mining multi-faceted overviews of arbitrary topics in a text collection[C]//Proceeding of the 14th ACM SIGKDD, 2008: 497-505.
[5] X Zhao, J Jiang, H Yan, et al. Jointly modeling aspects and opinions with a MaxEnt-LDA hybrid[C]//Proceeding of the EMNLP 2010, 2010: 56-65.
[6] X Cheng, P Du, J Guo, et al. Ranking on data manifold with sink points [J]. IEEE Transactions on Knowledge and Data Engineering, 2013,25(1): 177-191.
[7] I Titov, R McDonald. A joint model of text and aspect ratings for sentiment summarization[C]//Proceedings of the ACL-08:HLT,2008.
[8] D Blei, A Ng, M Jordan. Latent Dirichlet allocation[J]. Journal of Machine Learning Research, 2003, 3(3): 993-1022.
[9] T Griffiths, M Steyvers. Finding scientific topics[C]//Proceedings of the National Academy of Sciences, 101(Suppl 1), 2004: 5228-5535.
[10] D Zhou, J Weston, A Gretton, et al. Ranking on data manifolds[C]//Proceedings of Advances in Neural Information Processing System 16, 2004.
[11] G Ganu, N Elhadad, A Marian. Beyond the stars: improving rating predictions using review text content[C]//Proceedings of International Workshop on the Web and Databases, 2009.
[12] S Brody, N Elhadad. An unsupervised aspect-sentiment model for online reviews[C]//Proceedings of Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics (HLT ’10), 2010.
