基于标签混合语义空间的音乐推荐方法研究
2014-02-28刘文飞林鸿飞
闫 俊,刘文飞,林鸿飞
(大连理工大学 信息检索研究室,辽宁 大连 116024)
1 引言
近几年,社交网络越来越受到人们的青睐,而交流和维护朋友间的关系是人们使用此类社交网络的主要原因[1]。有研究表明,在Facebook中,用户会分享相当大一部分关于他们自己日常生活的内容[2]。音乐,作为很多社交网络中人们分享的资源之一,受到了很多网站的重视,其中首推专门进行音乐分享的社交网站,例如,last.fm,豆瓣音乐等。
在音乐网站中,音乐资源的海量增长使用户对音乐的选择显得尤其困难。针对上述问题,网站中出现了“推荐”板块,即根据用户在网站中的听歌信息预测用户的潜在兴趣歌曲,从而为用户进行推荐。
针对推荐,基于文本的推荐方法是目前的主要研究方向。歌曲描述文件的表示方法可以基于其文本相关信息,如元数据、歌词、标签或从博客中挖掘出的综述文字等[3]。在前面所提到的文本信息中,标签由于涵盖了包括流派、风格、情感、用户想法或者乐器等多层面的信息[4],所以成为了很多研究者用于音乐推荐的资源。
关于基于标签的音乐推荐,文献[5]中提出了一种使用HOSVD(Higher Order Singular Value Decomposition)方法进行分解降维从而对用户进行推荐的方法。文献[4]在文献[5]的方法基础上,结合音频信息对推荐算法进行了改进。作为对比,文献[6]中提出了一种比传统基于歌曲或基于用户的协同过滤更好的方法;该方法中,用户的标签、曲目以及标签—项目关系都会影响社区网络的生成,除了用户相似度,歌曲相似度的计算同时融入了公共标签、公共用户以及公共标签—歌曲关系的影响。此外,文献[7]中将标签进行了聚类,这些聚类一定程度上提高了音乐推荐的效果。在音乐文本信息中,音乐流派可以被证明是帮助用户选择喜欢歌曲的有用信息[8]。鉴于上述成果,文献[9]中提出了一种基于音乐流派和用户社区相似度的混合推荐方法,该方法通过显式地将标签映射到流派空间,同时加入社区网络用户相似度,从而为用户进行歌曲推荐,取得了比LSA方法更好的效果。上述方法有的使用空间矩阵方法,有的加入了协同关系信息,没有充分挖掘标签文本信息的潜在语义空间。标签作为一种文本信息,其潜在语义空间对歌曲推荐起着关键作用。
针对上述问题,本文将社会化标签作为音乐推荐主要依据的同时,深入挖掘了其潜在语义空间对音乐推荐的作用,从而进行音乐推荐模型的建立。本文首先将标签映射到流派、情感以及上下文信息三个空间,然后在三个空间分别计算用户和歌曲的相似度,最后将三个空间的相似度按照不同方式融合,从而形成推荐模型。实验结果表明,融合不同空间相似度的推荐方法得到了很好的效果。
文章的组织结构如下:第2节对研究方法中的相关工作进行说明,第3节详细介绍本文的主要研究方法,第4节是实验结果及分析,第5节进行总结。
2 相关工作
2.1 音乐流派本体
本文使用的音乐流派相关外部资源是文献[9]中提出的音乐流派本体库,该本体库包括22个流派,分别为:acoustic, ambient, blues, classical, country, electronic, emo, folk, hardcore, hip-hop, indie, jazz, Latin, metal, pop, pop-punk, punk, reggae, r&b, rock, soul, world。
音乐流派词汇本体可用一个二元组进行表示:
GenreItem = (B, G)
其中B代表词或词组;G则代表流派,范围即是上述22个流派。
2.2 情感词汇本体
本文使用的情感相关外部资源是文献[10]中提供的情感词库,该情感词库将情感词分为了6类情感,分别是:anger, disgust, fear, joy, sadness, surprise。
该情感词汇本体也可用一个二元组进行表示:
EmotionItem = (W, E)
其中W代表一个词;而E代表情感类别。
2.3 上下文信息
本文中标签除可以映射到流派空间和情感空间之外,还可以从某些潜在意义上反映人们对音乐的喜爱。本文通过对这些标签进行分析,发现这些标签的范围极其广泛,包括地理、国家、生理、环境等方面。由于属于这些方面的标签数量较少,同时没有具体的方法将这些标签具体分类,本文将这些标签集合起来,形成了本文的第三个空间—上下文信息空间。
2.4 逻辑回归
本小节中,将重点介绍本文中用到的两种逻辑回归模型。
(1) 支持向量机
支持向量机(Support Vector Machine),简称SVM,是一种监督式学习方法,广泛应用于统计分类以及回归分析中。
在分类中,支持向量机的主要目标是找到一个超平面,使实例正确分布在该超平面的两侧,并且使超平面到它两侧最近实例的距离最远,这个超平面被称作最大间隔超平面[11]。
1995年, Corinna Cortes与Vapnik提出了一种改进的最大间隔区方法[12],这种方法可以处理标记错误的样本,用于回归分析中。
(2) 逻辑斯蒂判别式
逻辑斯蒂判别式主要用于分类,而本文中重点运用了该方法的二值分类回归模型[11]。在该模型中,有如下假设,如式(1)所示。
其中P(x|Ci)表示类条件密度。在式(1)中,假设类条件密度的对数似然比是线性的,经过推导和整理,可以得到实例属于某一类的概率估计如式(2)所示。
于是通过一定的学习方法学习得到参数w和w0,从而就可以根据概率估计式(2)预测给定实例的分类信息了。
3 基于标签混合语义空间的音乐推荐
本文将在这一部分详细介绍三个空间中用户与歌曲的相似度计算方法,并将融合方法进行详尽的介绍。
3.1 歌曲和用户的文件表示
(1) 歌曲文件表示
本文中,歌曲i用一个文件tracki进行表示,tracki中包含歌曲i中含有的所有标签labelk,i以及labelk,i在i中相对于最常用标签的整数型比例perk,i(从0到100),为了不丢弃0数值的影响,本文将perk,i加1进行平滑。
(2) 用户文件表示
本文中,用户文件userj的表示方法类似于歌词文件,它所含有的标签及比例用其听过的歌含有的标签集合来表示。
3.2 流派相似度计算
3.2.1 标签到流派的映射
如2.1节中所讲,本文依赖于音乐流派本体库将标签映射到流派上。映射方法参考的是文献[9]提出的方法,并定义如下公式。
3.2.2 流派空间向量表示方法及相似度计算
首先,以歌曲为例介绍歌曲的流派空间向量表示方法,具体方法如下:
(1) 歌曲的流派向量出现频率计算如式(4)所示。
其中,Ni,g表示流派g在歌曲i中出现频率,k表示歌曲i文件中的标签个数,l代表标签。
(2) 歌曲的流派向量权重计算:
本文采用TF*IDF方法来计算歌曲文件在流派各个维度上的权重,具体公式如式(5)所示。
其中,wi,g表示歌曲文件i在流派g维上的权重,Ni表示歌曲i中出现在所有流派频率的总和,|T|表示歌曲的总数目,|Tg|表示出现过流派g的歌曲总数目。
本文用类似的方法对用户流派向量权重进行计算。其中,TF单独针对用户文件计算,而IDF使用上述歌曲流派的IDF值。
为了和文献[9]中的方法进行对比,本文中同样使用cosine方法计算用户和歌曲间的流派相似度,见式(6)。
其中,wuser,g和wtrack,g分别代表用户和歌曲流派向量的各维权重。
3.3 情感相似度计算
3.3.1 标签到情感的映射
本文依赖于2.1节中提到的情感本体库进行音乐情感映射。映射方法如下:
将情感本体库中的单词作为查询关键字在数据库中查询含有该单词的标签内容,从而将标签映射到该词汇对应的情感中。
3.3.2 情感空间向量表示方法及相似度计算
类似于3.2节中流派向量的表示方法,可得到情感向量的各维权重wi,e以及用户与歌曲的情感相似度EmoSim(user,track)。
3.4 上下文信息相似度计算
3.4.1 用户和歌曲的上下文信息空间表示
本文采用“词袋”对用户和歌曲的上下文信息空间进行表示,此处的“词袋”表示的是单词集合文件。以歌曲为例,上下文信息空间表示具体步骤如下:
(1) 对每一首歌曲建立一个词袋文件。
(2) 对于歌曲文件tracki中的第k个标签labelk,i,如果被映射到了流派或者情感空间,则丢弃;否则,将该标签写入该歌曲对应的词袋文件中。
(3) 由于上下文标签的稀疏性,本文采用WordNet对词袋文件内容进行了同义词扩展,形成了更加丰富的词袋文件。
至此,歌曲文件的上下文信息空间表示完成,而用户则参照歌曲文件的表示方法。
3.4.2 用户和歌曲上下文信息空间相似度计算
本文采用jaccard系数计算用户和歌曲的上下文信息相似度。计算公式如式(7)所示。
其中,user和track分别表示用户和歌曲的上下文信息空间词袋文件。|user∩track|表示用户词袋与歌曲词袋相同词的个数,|user∪track|表示用户词袋与歌曲词袋词的并集的个数。
本文使用如下方法对上下文信息空间相似度进行归一化:
其中,minSim表示上下文空间相似度计算出的最小值,maxSim表示其最大值。
3.5 将三个空间相似度进行融合
3.5.1 线性融合
本文中主要采用线性融合方法对三个空间的相似度进行融合。如式(9)所示。
其中,Sim(user,track)表示用户与歌曲的总相似度,λ1、λ2、λ3分别代表流派、情感、上下文空间相似度的相关性系数,且λ1+λ2+λ3=1。
3.5.2 逻辑回归融合
本文除了主要使用上述的线性融合方法以外,同时使用了支持向量机和逻辑斯蒂判别式两种逻辑回归方法将本文三个空间的相似度进行了融合。具体融合原理方法已在2.4节中进行了相关介绍。
用户—歌曲对的三个空间的相似度可以形成一个三维向量simVec(GenreSim,EmoSim,ContSim),把该三维向量作为输入实例,可以得到逻辑回归的结果,结果越高,用户—歌曲对的相似度越大。
4 实验结果与分析
4.1 语料来源及实验流程
本文的语料使用的是文献[9]中的语料。在这个语料中,每首歌曲的标签信息不仅包含标签内容,还包括标签在歌曲中相对于最常用标签的整数比例(1到101),而在实验过程中本文也用到了该数据信息。
为了和文献[9]的方法进行对比,本文同样采用了四倍交叉验证方法来进行实验。本文将75%的歌曲信息作为训练集,另外25%的歌曲信息作为测试集。用户文件使用训练集的数据进行文件表示,实验目标是正确地为用户推荐测试集中的歌曲。
4.2 评价方法
本文中采用最常用的P@N方法来评价推荐的准确率,该方法指的是前N个推荐结果中的相关歌曲占的比率。
4.3 实验结果及分析
本文首先在流派、情感和上下文信息三个空间分别进行相似度计算从而为用户进行歌曲推荐,和文献[9]中的方法进行对比试验,得到的结果如表1所示。
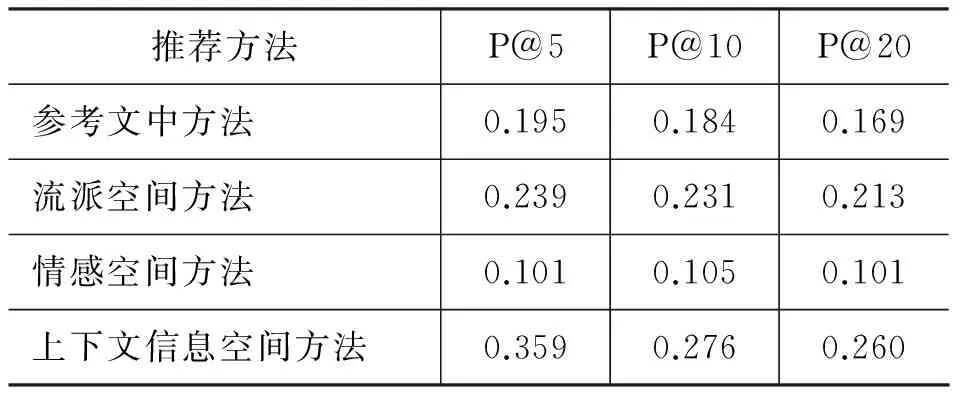
表1 单独空间推荐实验结果
由表1结果可看出,本文中单独使用流派空间和上下文信息空间的推荐效果已经好于文献[9]中的最高结果,其中上下文信息空间推荐效果最好,而情感空间的推荐效果最差。这说明,在用户对歌曲标注的标签中,除流派和情感信息以外,潜在的影响因素仍然具有相当大的作用,而由于歌曲的情感相对单一,用户对音乐的情感要求比较丰富,所以推荐效果较差。
在单独空间实验基础上,本文针对其中一个测试集进行了不同的相关融合方法测试,融合方法实验结果如表2所示。
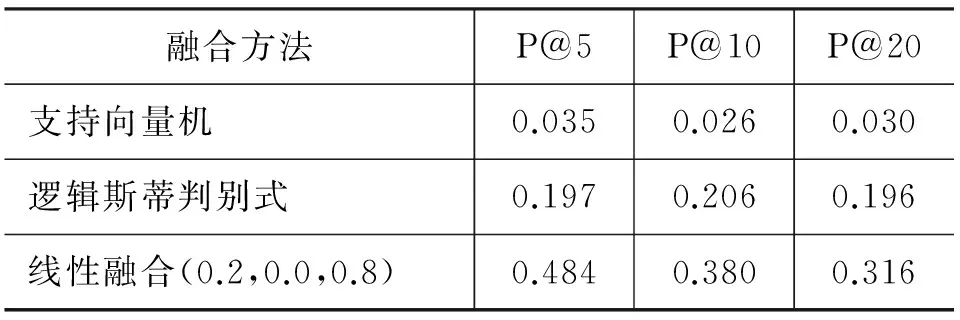
表2 融合推荐实验结果
由表2实验结果可看出,线性融合的方法远远高于两种逻辑回归方法。经过分析,主要的原因在于训练集信息不平衡。使用逻辑回归方法进行训练时,训练集中仅提供1(用户听过歌曲)和0(用户未听过歌曲)两种输出,而由于用户听过的歌曲数量有限,输出为1的样本很少;同时,在输出为0的实例中,我们并不能确认用户不喜欢该歌曲。逻辑回归方法是一种相对复杂的机器学习方法,本文将用户和歌曲对的三个相似度分数作为输入向量、1和0作为输出进行实例训练,提供的信息不够全面,所以逻辑回归的效果并不如简单的线性融合方法好。
在上述实验中可以看出,线性融合的方法最好。于是,本文在所有实验数据上进行线性融合方法。为了统计最佳结果,本文将三个系数分别赋值0到1(依次加0.1),做了66组系数实验对比,最后统计出了三个空间两两融合以及三个一起融合最佳结果的系数(公式(9)所示),交叉验证结果如表3所示。
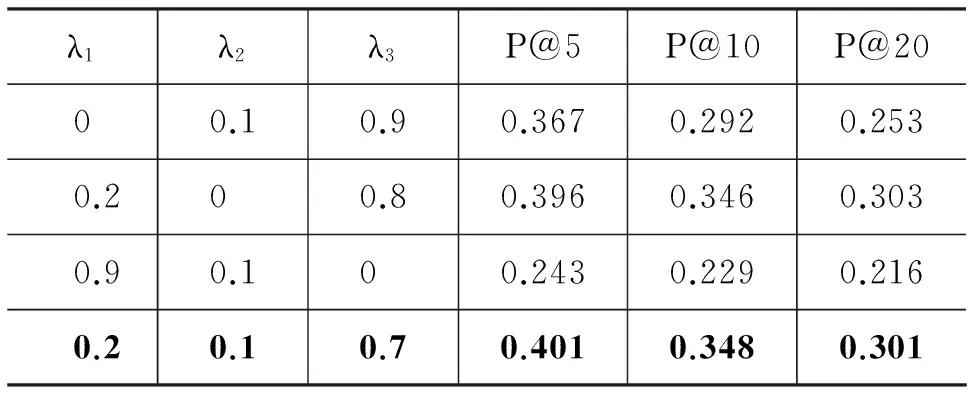
表3 线性融合四倍交叉验证结果
由表3的结果可以看出,融合三个空间的相似度具有最好的结果,且最佳结果都好于单独使用一个空间(表1)。通过分析结果,本文得出结论,在本文的三个语义空间中,决定用户是否喜欢一首歌的最重要因素来自于上下文信息空间,流派次之,最后是情感。这个现象说明,人们喜欢音乐的因素有很多,并不能简单的使用单一的语义空间来对用户的兴趣进行推测,而应该融合更多的语义空间对用户推荐合适的歌曲。
5 总结
在音乐资源(歌词,乐谱等)中,标签有效地反映了用户对音乐的个性化认知。因此,本文将社会化标签作为主要音乐推荐依据,创新性的将标签同时映射到了流派、情感和上下文信息三个空间中,深入挖掘了这三个空间对用户喜欢歌曲的影响力大小,并在各单独空间基础上进行相关性融合研究,从而有效的为用户推荐了其需要的歌曲。
[1] Dwyer C, Hiltz S R, Passerini K. Trust and Privacy Concern Within Social Networking Sites: A Comparison of Facebook and MySpace[C]//Proceedings of the 13th Americas Conference on Information Systems(AMCIS 2007). Keystone, Colorado, 2007.
[2] Acquisti A and Gross R. Imagined Communities: Awareness Information Sharing and Privacy on the Facebook[C]//Proceedings of the 6th Workshop on Privacy Enhancing Technologies. Cambridge, UK. 2006: 36-58.
[3] Celma O and Lamere P. Music Recommendation Tutorial[C]//Proceedings of the 16th ACM International Conference on Multimedia. New York, NY, USA. 2008: 1157-1158.
[4] Nanopoulos A, Rafailidis D and Symeonidis P et al. MusicBox: Personalized Music Recommendation Based on Cubic Analysis of Social Tags[J]. Audio, Speech, and Language Processing, IEEE Transactions. 2010. 18(2): 407-412.
[5] Symeonidis P, Ruxanda M and Nanopoulos A et al. Ternary semantic analysis of social tags for personalized music recommendation[C]//Proceedings of the ISMIR. Philadelphia, USA. 2008: 219-224.
[6] Liang H, Xu Y and Li Y et al. Collaborative Filtering Recommender Systems Using Tag Information[C]//Proceedings of the Web Intelligence and Intelligent Agent Technology. Sydney, Australia. 2008: 59-62.
[7] Shepitsen A, Gemmell J, and Mobasher B et al. Personalized recommendation in social tagging systems using hierarchical clustering[C]//Proceedings of the 2008 ACM Conference on Recommender Systems(RecSys ’08). New York, NY, USA. 2008: 259-266.
[8] Cai R, Zhang C and Wang C et al. MusicSense: contextual music recommendation using emotional[C]//Proceedings of the 15th International Conference on Multimedia Allocation Modeling. New York, NY, USA. 2007: 553-556.
[9] Tatli I, Birturk A. A Tag-Based Hybrid Music Recommendation System Using Semantic Relations and Multi-domain Information[C]//Proceedings of the Data Mining Workshops (ICDMW), 2011 IEEE 11th International Conference. Angeles, CA, USA. 2011: 548-554.
[10] Strapparava C, Mihalcea R. Learning to identify emotions in text[C]//Proceedings of the 2008 ACM Symposium on Applied Computing. New York, USA. 2008: 1556-1560.
[11] 阿培丁. 机器学习导论[M]. 机械工程出版社, 2009: 135-141.
[12] Cortes C, Vapnik V. Support-Vector Networks[J]. Machine Learning. 1995. 20(3): 273-297.
