社会媒体短文本内容的语义概念关联和扩展
2014-02-28肖永磊刘盛华程学旗赵文静王宇平
肖永磊,刘盛华,刘 悦,程学旗,赵文静,任 彦,王宇平
(1. 中国科学院 计算技术研究所,北京 100190;2. 中国科学院大学,北京 100190;3. 西安电子科技大学计算机学院,陕西 西安 710126;4. 国家计算机网络应急技术处理协调中心,北京 100029)
1 引言
随着Web2.0的发展,微博、论坛、照片分享网站Flicker等社会化媒体已深入人们的日常生活,其中衍生出来的标签推荐、新闻推荐、问答、评论等应用产生了大量的网络短文本。社会化媒体上的短文本按其时间属性组织形成的消息流,包含着网民们的许多思想观念与倾向,对其进行深入的挖掘有重大的应用价值和学术意义。然而,文本消息的不完整性、海量性和动态性导致文本消息流的话题发现、倾向性分析和热点信息挖掘等数据挖掘任务变得十分困难。本文提出了一种新的短文本语义概念扩展方法,可以去除短文本的噪声和增加短文本的内容特征,可以作为其他数据挖掘方法的补充。由于社会化媒体短文本的多样性,本文选择了应用较多的微博作为实验数据来源,来说明论文提出的方法。
微博作为新的信息交流平台,得到快速的发展,并逐渐成为用户群最庞大、最活跃的网络媒体之一。Twitter最近几年用户数量突飞猛进,已经成为最大的在线微博平台,拥有超过6 500万的用户,每天超过2亿条的微博。据报告[1]显示,2011年在中国已经有14%的互联网用户开始使用微博,并呈逐年上升的趋势。微博传播迅速,极大地方便了人们交流,同时也带来信息过载问题。由于人们时间和能力有限,往往不能及时有效地获取自己感兴趣的信息。微博产生的海量信息已经成为多种应用的重要信息源,比如新闻话题发现和追踪[2],广告投放,个性化内容推荐等。Takeshi[3]等首先利用用户tweets的关键词信息,tweets长度,上下文等特征构建一个分类器,将Twitter用户看成一个传感器,采用了卡曼滤波算法和粒子滤波算法预测地震事件发生的地点。
不同于传统的长文本,以微博为代表的社会媒体短文本具有以下特征:
1) 用语大多随意,具有不规范性[4];
2) 长度有限,使其具有天然的极稀疏性,很难提取出有效的内容特征[5]。
以上特征对微博信息的挖掘带来了很大的挑战。针对微博内容的极稀疏性,将其链接到其他的知识库来扩展内容特征的研究,最近受到了越来越多的关注。Abel[6]等利用新闻信息来增加tweets的上下文,然后利用这些上下文信息来定义用户的属性。另外将Wikipedia作为辅助知识库也成为一个主要的研究方向。Wikipedia作为一个互联网开放式的在线百科全书,具有较广的覆盖面和较高的准确度。由于其包含大量的语料,具有内容组织结构化,不需要人工搭建等特点,比较适用于网络数据挖掘,可以用于自然语言处理中词义消歧、文本分类和索引、构建和维护语义资源等领域。目前基于Wikipedia的研究工作包含了关键词语义扩展[5],命名实体识别,词义消歧[7]等方面。研究工作[5,8-9]通过利用Wikipedia的结构化信息来扩展微博或者短文本的内容,并结合机器学习的方法训练模型,取得了比较好的效果。文献[8]设计了一种在线的可以将短文本链接到语义相关的Wikipedia页面的系统,它采用了一种快速、有效的基于上下文的投票机制来进行语义消歧,在短文本和长文本上都获得了比较高的准确率,但是文献[8]不能获得语义相近的更多概念集合,因为它的链接过程是基于字符匹配的,不能找到那些不匹配但语义相近的概念。文献[9]用图模型描述了Wikipedia中的概念之间关系,采用了随机游走算法来找到语义相关的概念集合,虽然可以找到那些没有共现的语义相似度很高的概念,但图节点数量巨大,计算效率成为一个瓶颈。与文献[8-9]相比,本文提出的方法不仅可以找出语义相关的概念,而且计算效率也得到比较大的提升。与文献[10]中基于目录信息和文献[11]中基于概念共现的方法来计算概念之间的相似度相比,本文提出的语义概念扩展方法在性能和准确率上都有较大的提升。
Wikipedia包含了大量的概念并以概念为标题的网络文章,它的文章正文所包含的相关概念也以锚文本的方式显式给出,本文中提到的概念和锚文本含有相同的意义。本文提出了一种新的方法利用Wikipedia作为辅助知识库为微博做语义概念扩展,从而达到扩展社会媒体短文本的内容语义特征的效果。本文选择了有代表性的社会媒体——微博来描述提出的语义概念扩展方法。首先,生成微博所有可能的n-gram,提取n-gram的可链接性、词频、逆文档频率等特征,利用LR(logistic regression)进行剪枝,去掉不需要增加概念语义的n-gram。其次,采用了基于上下文相关的互信息方法将n-gram与Wikipedia中的概念对应起来。最后,利用Wikipedia的概念与文档之间的结构化信息,构建了基于概念—文档矩阵的非负矩阵分解(NMF)模型,有效获取概念之间的语义相似度关系,为已关联的概念增加更多语义相似的概念。论文的结构如下,第2节为相关工作,第3节是介绍了微博语义概念扩展的详细方法,第4节为实验和分析,最后第5节对本文工作做了总结和展望。
2 相关工作
相关工作主要分为针对Twitter内容的研究和基于NMF的文本建模的研究。
2.1 基于Twitter的研究
许多针对微博的应用主要是找到用户感兴趣的话题,例如,电影、产品、人物等,并基于这些信息进行话题追踪、市场营销、个性化推荐等,工作[5,8,12-13]针对不同应用采用有监督或者无监督的机器学习方法对大量微博进行数据挖掘。Liu[10]等集中在tweet中的命名实体识别领域,他们采用了一种基于KNN的监督学习的框架来鉴别4种不同的实体类型。Abel[6]等先对tweet增加上下文信息,然后利用增加的上下文信息为用户定义属性,首先利用新闻内容为tweet增加语义信息,其次利用增加的语义信息来对用户属性建模。Mendes[14]等利用微博中的链接数据来对tweet进行标注,他们直接利用tweet里面的hashtag标签或者在DBpedia中利用字符串匹配查找在tweet中出现的实体。Edgar[15]等提出了一种自动将tweet与Wikipedia中文章对应起来的方法。他们首先提出了一种基于召回率的方法获取与微博相关的概念集合,然后使用了多种方法对概念进行重新排序,并使用机器学习的方法来提升结果。虽然Edgar的方法能达到较高的正确率和召回率,但是计算效率不高,并且得到的概念是基于共现的,并不能获取潜在语义空间上相似的概念集合。为了获得潜在语义空间上相似的概念集合,本文提出基于NMF的方法用于计算Wikipedia中概念之间的语义相关性。
2.2 基于NMF的研究
NMF(非负矩阵分解)[16-17]提出了一种新的矩阵描述的方法,对非负矩阵X,寻找一个逼近的分解X≈WH,其中W和H都是非负矩阵,非负性约束使得矩阵的表述与其它线性描述方法如ICA[18]相比更具直观性,更符合常理。Shahmaz[19]等提出了一种基于NMF的方法,可以自动识别非结构化文档的语义特征并进行聚类和话题发现,与传统的潜在语义发现方法相比,取得了比较好的效果。Ankan[20]等提出了一种动态的NMF方法,通过比较分解得到的矩阵的变化能快速地识别新出现的话题,并能跟踪到话题随着时间的变化情况。Patrik[21]等提出了基于稀疏性约束的NMF分解方法,通过对迭代产生的矩阵加以稀疏性约束来提升矩阵分解的效果,实验表明,该方法具有比较快的收敛性和比较高的准确率。本次实验主要是采用NMF计算Wikipedia中概念的语义相似性,类似普通的词—文档矩阵分解可以得到词—词的语义相似度矩阵,通过对Wikipedia中概念—文档矩阵分解可以得到概念—概念的语义相似度矩阵,这是本文与其它链接到Wikipedia的研究工作中最主要的不同。
3 微博语义概念扩展
本文将Wikipedia作为知识库,为微博信息扩展相关的语义概念。语义概念的扩展主要分为以下阶段。首先,提取出微博信息的所有n-gram,并对微博的n-gram进行可链接性剪枝。在剪枝阶段,提取所有n-gram的可链接性、词频、逆文档频率等特征,并利用LR(logistic regression)模型进行剪枝,去掉不需要关联语义概念的n-gram。其次,在n-gram和Wikipedia概念关联和消歧阶段,采用了基于上下文相关的互信息方法将剪枝后的n-gram与Wikipedia中的概念对应起来。最后,在语义概念扩展阶段,利用Wikipedia的概念与文档之间的结构化信息,构建了基于概念—文档矩阵的非负矩阵分解模型,有效获取概念之间的语义相似度,为已关联的概念增加更多语义相似的概念。本文用到的符号在表1中给出了具体含义的描述。
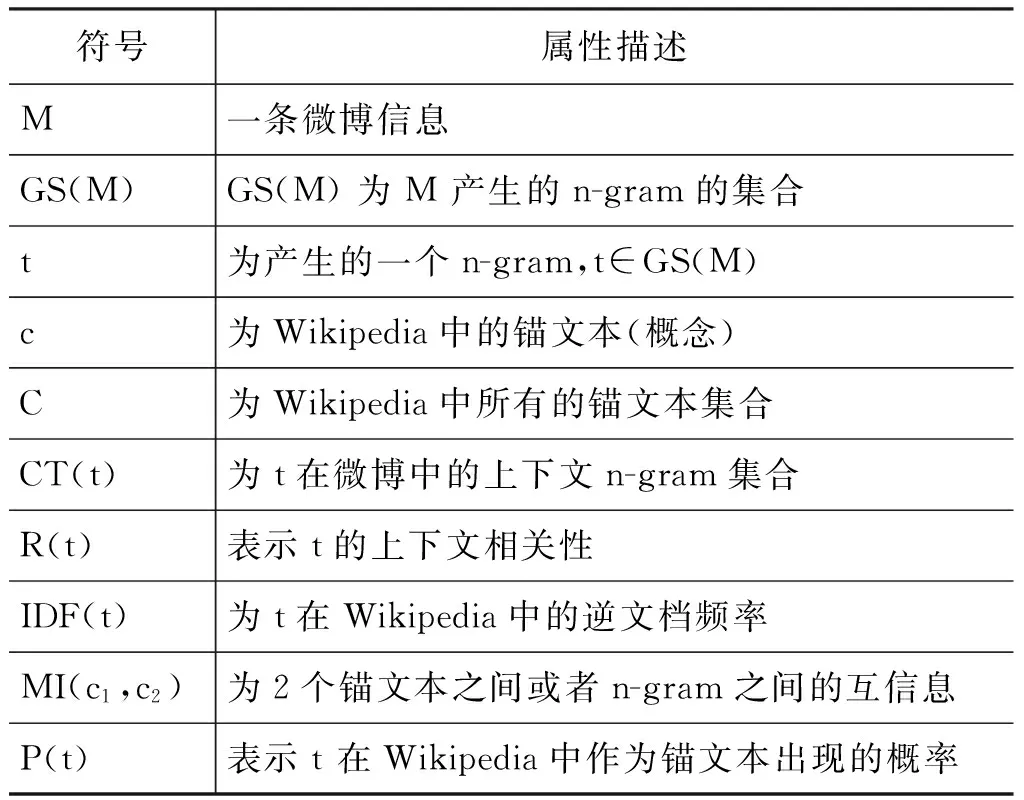
表1 本文用到的符号描述
续表

符号属性描述LINK(t)表示t在Wikipedia中的锚文本中出现的次数OCR(t)表示t在Wikipedia中总的出现次数LOC(t)与t相匹配的Wikipedia中锚文本集合SEM(c)与c语义相关的所有锚文本集合H(x)为x的在Wikipedia的边际熵,x为任意的n-gram或者锚文本H(x,y)为x,y的联合熵
3.1 可链接性剪枝
对于微博信息M,为了找出其中可以进行语义概念扩展的n-gram,首先提取出微博所有的n-gram集合(1≤n≤|M|)。根据文献[9]的研究表明,当n取4时,精度不会明显下降并且计算效率也能提升很多,因此本文的n取的最大值是4。对于微博M,设M产生的所有可能的n-gram组成集合GS(M) ,我们首先进行剪枝处理,因为并不是所有的n-gram都需要增加语义,对这些n-gram增加语义不仅不能帮助我们理解微博语义,反而可能会增加歧义。例如,
ObamaandKoehlerwillvisitchinatomorrow!
其中,Obama是美国总统,Koehler是德国总统,它们可以链接到Wikipedia进行语义概念扩展,and在Wikipedia中可以作为加法器出现,如果也链接到Wikipedia就增加了歧义,所以要进行n-gram的剪枝。与文献[8]中工作不同的是我们将剪枝过程提前,这样可以减少链接的n-gram数目,提高语义概念扩展阶段的计算效率。在这里我们提出了一种基于LR的机器学习方法来判断这些n-gram的可链接性,并找出比较重要的特征。
首先对于每一个n-gram,我们通过以下方式计算它在Wikipedia中出现在锚文本中的概率,如式(1)所示。
其中当t含有多个词时,对任意的ti∈t,OCR(t) = ∑OCR(ti-LINK(t)。
其次,对于每一个n-gram,计算它在Wikipedia中的逆文档频率IDF(t),如式(2)所示。
(2)
最后结合LR方法,确定了预测函数(3),其中OCR(t)与|C|的比值表示t出现的概率,如式(3)所示。
(3)
即对于给定的t,函数F(t) >ρ的时候我们就认为t可以进行链接处理,反之就对t进行剪枝,ρ为指定的阈值。
3.2 概念关联和消歧
对于经过剪枝后需要进行语义概念扩展的t,需要将t链接到Wikipedia中对应的锚文本,这时候会产生很多带有歧义的锚文本。因为对于给定的t,可能在不同的上下文中存在不同的锚文本与之对应。比如Michal Jordan 可以与Wikipedia中超过20种锚文本相对应。如何从这些锚文本集合中选出与t最相关的锚文本即为语义消歧过程。这里我们采用了一种简单有效的基于上下文互信息的方法来决定t来链接到哪个锚文本。利用式(4)计算t和锚文本c之间的互信息MI(t,c)。
MI(t,c=H(t+H(c-H(t,c
(4)
对任意的ci∈LOC(t,选出与t上下文CT(t)相关性最大的锚文本ci满足式(5):
(5)
3.3 语义概念扩展
语义概念的扩展主要是为了增加更多语义相关的概念集合,主要涉及概念之间的语义相似度计算和语义概念扩展。当获得了每一个t在Wikipedia中对应的锚文本c之后,很多的研究工作[7-8]把该锚文本的链接或者页面内容作为扩展的概念语义或者背景知识,这些方法通常是基于字符匹配或者共现的,不能找到与锚文本语义相关的更多锚文本信息,从而扩展的语义概念就很有限,为了扩展更多的语义相关的概念,需要采取一种有效的方法来找到与c语义相近的更多概念。比如Barack Obama,与其语义相近的锚文本有President of the United States 和U.S.Senator 等。Wikipedia中的页面包含很多个锚文本,目前专门针对锚文本进行语义挖掘的研究并不多,文献[9]采取了一种基于图模型的随机游走算法来查找语义相关的锚文本,但由于节点数据巨大计算效率比较低。我们提出了利用NMF的方法来计算锚文本之间的语义相似度的方法,在此基础上为锚文本增加更多的语义信息。
3.3.1 语义概念相似度
如何计算概念之间的语义相似度,已经成为采用Wikipedia进行数据挖掘工作中比较重要的一部分,不同于文献[7,11]的计算方法和文献[9]中的基于图的随机游走算法,我们采用NMF方法来计算概念之间的语义相关性。本文将文献[7,11]中实现的方法作为基准与我们提出的方法进行对比。
基于NMF的语义概念建模。假设初始待分解矩阵X为m×n的概念—文档矩阵,m为概念集合的数目,n为文档集合的数目,则可以利用NMF算法分解得到两个非负矩阵W和H,其中W是m×r的概念—主题矩阵,H是r×n的主题—文档矩阵,这里r为分解矩阵W的列数和H的行数,表示文档集合中主题的数目。由相关工作中的研究可以知道,矩阵分解的方法不同,适用的领域也不同。本文实现的NMF方法是文献[21]提出的基于L1,L2稀疏性约束的NMF方法,该方法实验证明了对分解过程中矩阵W和H的稀疏性进行显示的L1,L2约束可以加快收敛速度,提高算法的效率和结果的准确度。在矩阵分解的迭代过程中,寻找非负的矩阵W和H,使得以下目标函数最小,如式(6)所示。
E(W,H=||X-WH||2
(6)
矩阵分解主要分为两个阶段。一是投影过程,即对分解迭代过程中产生的矩阵加以稀疏性约束,在L1约束和L2约束不变的条件下,找到矩阵每一行或者每一列的最优投影向量;二是分解过程,在每次迭代过程中,按照非负约束和稀疏性约束,利用第一阶段得到的最优解进行分解迭代直到满足停止条件。算法描述如下。
投影部分算法
说明:对任意的向量x,在给定的L1约束和L2约束下寻找离x最近(欧氏距离)的非负向量s,对每一个元素分别计算,直到所有元素都非负则停止。m和s都是与x维度相同的向量
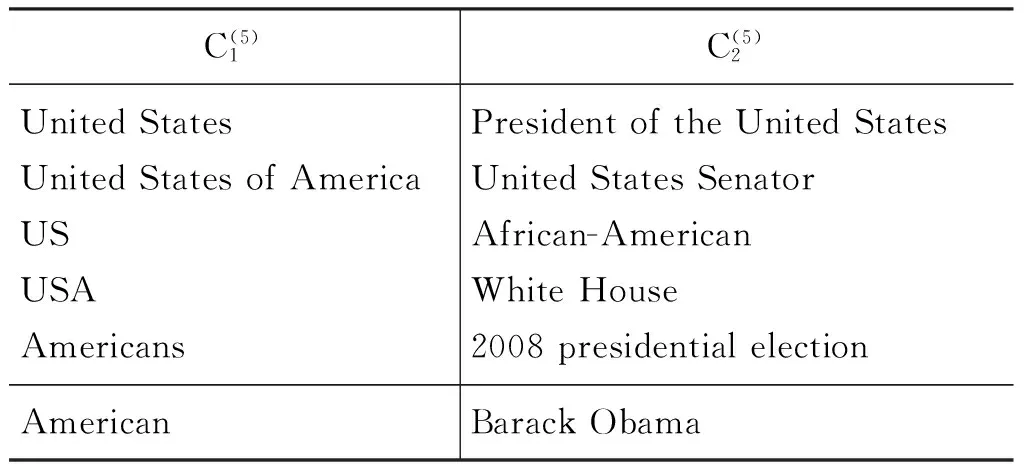
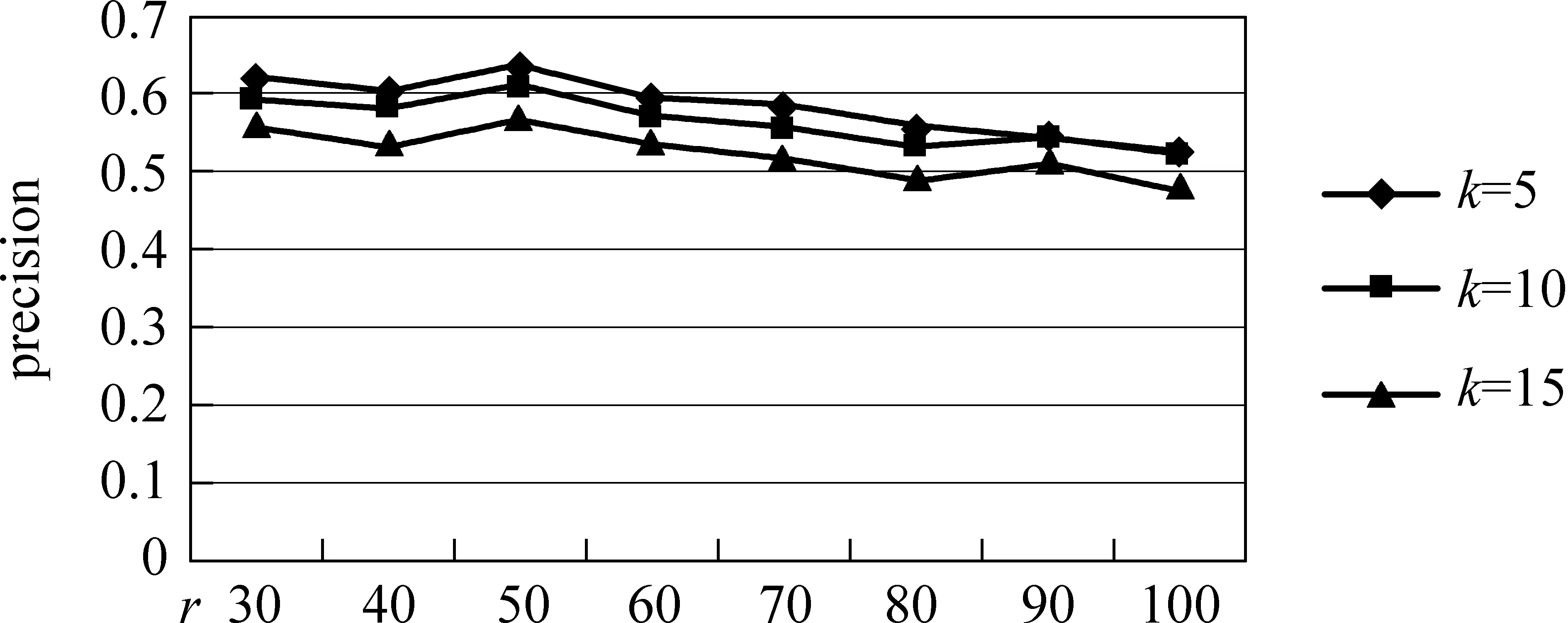
For (i=0;i 1. si:=xi+(L1-∑xi)/dim(x 2. Z:={} //Z为向量s中元素为负值的下标集合 3. while true: else mi= 0 (b) s:=m+α(s-m) //α为设定的正值 (c) if all of s are non-negative, return s //如果s的元素都为正,则返回s (d) Z:=Z∪{i;si<0} //如果si为负,则将下标i添加到集合Z (e) si=0,∀i∈Z //将s中所有为负数的值设为0 (f) c:=(∑si-L1)/(dim(x)-size(Z)) (g) si:=si-c,∀i∉Z (h) go (a) 矩阵分解的算法 说明:基于L1和L2稀疏性约束的NMF分解 1. init W and H to random positive matrics //将W和H初始化为非负的随机矩阵 2. If sparseness constraints on W apply, then project each column of W to be non-negative, have unchanged L2 norm, but L1 norm set to achieve desired sparseness //如果对W加稀疏性约束,将W的每一列在L1,L2约束下进行非负的投影 3. If sparseness constraints on H apply, then project each row of H to be non-negative, have unitL2 norm, andL1 norm set to achieve desired sparseness //如果对H加稀疏性约束,将H的每一行在L1,L2约束下进行非负的投影 4. while(tot (a) If sparseness constraints onW apply : //如果W加了约束 (1) set W:=W-μW(WH-X)HT (2) Project each column of W to be non-negative, have unchanged L2 norm, but L1 norm set to achieve desired sparseness //计算W的投影 Else W:=W⊗(XHT)(WHHT) //如果W没有加约束 (b) If sparseness constraints on H apply: //如果H加了约束 (1) set H:=H-μH(WH-X)WT (2) Project each column of H to be non-negative, have unchanged L2 norm, but L1 norm set to achieve desired sparseness //计算H的投影 Else H:=H⊗(WTX)(WHWT) //如果H没有加约束 (c) it++; tot = ||X-WH||2 3.3.2 基于语义相似度的概念扩展 在求得锚文本跟锚文本之间的相似度之后,并不能简单的基于语义相似度选取最大的K个,因为没有考虑上下文信息,即使有些相似度很高的锚文本也不能用来增加语义,否则只会对微博的理解产生更多的歧义。作为比较,在实验过程中我们分别实现了基于上下文和不基于上下文的语义概念扩展方法。在基于上下文的方法中,我们提出了一种结合逆文档频率和互信息的方法来计算锚文本跟上下文的语义相关性。假设t对应的锚文本为m,对任意的mi∈SEM(m,上下文语义一致性SM(mi,t) 通过式(7)计算。 对于给定的K值,使得以下目标函数最大即为跟上下文最相关的K个锚文本集合。 本次试验采用的1 000条tweet数据是基于TREC 2011数据集,从其中选取了300条tweet,对其产生的2 691个n-gram进行了人工标注,用来训练和测试可链接剪枝中的LR模型,其余的700条用来做语义扩展。Wikipedia采用的是2011年的数据集,大概有1 200万的网页,380万锚文本数据,为了验证本文提出方法的有效性,我们在对Wikipedia语料构建索引之后,按照与American和Obama相关的话题选择了其中的2 078篇页面作为此次实验的语料,共含有117 227个锚文本。 在过滤掉语料中的非锚文本词之后,初始化得到概念—文档矩阵X,经过NMF矩阵分解后得到的矩阵W为概念—主题矩阵,H为文档—主题矩阵,得到的概念—概念相似度矩阵为W×WT,然后基于这个相似度矩阵进行上下文无关和上下文相关的语义概念扩展。作为比较,实验实现了文献[7,11]的计算概念之间相关度的方法。 (1) Silvim[7]的基于目录信息的计算方法 c为Wikipedia中的锚文本,g(c)是Wikipedia中这个锚文本所属于的目录集合的向量表示。作者采用了以式(9)来计算锚文本之间的相似度。 (9) (2) Milne和Witten[11]的基于共现信息的计算方法 c为Wikipedia中的锚文本,g(c)为包含c的Wikipedia的页面集合,A为所有的Wikipedia页面集合。 (10) 剪枝阶段利用LR模型的实验的结果如表2所示。 表2 LR的结果 假设tp表示模型将样本中标注为1的预测为1;fp表示将-1预测成1;fn表示将-1预测成0;tn表示将1预测成0,基于测试集合得到的结果数据计算方式如下。 最终发现在所有训练集合中,可以进行链接的t总数为872个,平均每一条微博有2.91个n-gram可以进行链接。在选择进行预测的三个特征中,比较重要的特征是n-gram的P(t)和IDF(t)。 利用NMF方法得到的初步结果如表3所示,例子中给出了2个概念的语义相关度最大的前5个概念。 表3 NMF分解得到的前5个最相关的概念向量 本次实验中设置文档主题数r = 50,迭代停止误差为tot=0.000 001,迭代次数为8 000,针对不同计算方法得到的结果集合上,作为比较我们选取了不同的结果集合范围。不基于上下文的语义概念扩展方法与其它两种方法得到的准确率如图1所示。 图1 给定主题数r在不同范围k的结果正确率(不基于上下文) 从图上看出在不同的范围K基于NMF的方法在准确率上均比其他两种方法有比较大的提升,从曲线的趋势可以看出,基于NMF的方法梯度下降较慢,具有比较好的扩展性。Silvim的方法由于直接采用了概念的目录信息,而Wikipedia的目录信息噪声大,很多目录的区分度较低,使结果的准确度较低。Milne 和Witten的基于共现的方法在候选集合比较小的时候,准确率较高,但是当集合范围逐渐扩大,引入了更多语义不相关的概念使准确率下降很快。由于选择的语料只是Wikipedia的一个子集,在以后的工作中可以选择更全面的语料来更深入的评价基于NMF的相似度计算方法。 在不基于上下文的基础上,增加了利用上下文信息扩展语义概念的结果如图2所示。 图2 给定主题数r在不同 k的正确率(基于上下文) 可以看出在原有方法基础上再结合上下文语义,三种方法的实验结果都获得了比较大的提升,证明了基于上下文语义概念扩展方法的有效性。 图2和图3的实验中文档集合主题数目r是相同的,本次实验中也探讨了不同的主题数目r对结果正确率的影响。 图3 不同的主题数目r的正确率 从实验的效果看,结果的正确率跟初始设置的文档集合主题数目r的设定有比较大的关系。由于r通常是由人为设定,跟人的经验相关,造成的误差会比较大。因此,我们下一步的改进方向是针对文本的特点,自动选择一个较优的主题数目r,从而能提高实验效率和准确率。 本文提出了一种基于NMF的方法来计算Wikipedia中概念语义相似度,并在此基础上为社会媒体短文本扩展语义概念,扩展它们的内容特征。基于部分微博语料的实验表明该方法可以实现较好的性能。接下来我们将从以下三个方面进行改进。首先是增大Wikipedia的实验数据集合,对该方法在大数据集合上的性能进行深入的探讨。由于实验的条件所限,本次试验只选择了部分Wikipedia语料,扩大语料规模,验证该方法在大规模数据集合的性能在拥有海量数据的今天具有很强的现实意义和应用价值;其次,通过一种自动化寻找最优的主题数目的方法来对NMF进行改进,减少人工设定和调试参数的工作量,提高程序的运行效率和精度。最后,社会媒体短文本有多种类型,本次实验虽然选用的是微博数据,但可以扩展到其他短文本领域如评论分析、标签推荐等,除此之外,该方法不仅可以寻找出短文本中有意义的概念实体,而且可以进行语义概念扩展,方便在扩展的语义特征空间上进行深入的数据挖掘处理。 [1] 中国互联网络信息中心. 第28次中国互联网络发展状况统计报告[R]. 2011. [2] A Sitaram, A Huberman. Predicting the Future With Social Media[C]//Proceedings of the ACM, 2010. [3] S Takeshi, O Makoto, M Yutaka. Earthquake Shakes Twitter Users:Real-time Event Detection by Social Sensors[C]//Proceedings of the WWW, 2010. [4] A Mathes. Folksonomies-cooperative classification and communication through shared metadata[J]. Computer Mediated Communication, 2004, 47(10): 1-13. [5] S Banerjee, K Ramanathan, A Gupta. Clustering Short Texts using Wikipedia[C]//Proceedings of the SIGIR,ACM, 2007: 787-788. [6] A Fabian, G Qi, H Geert-Jan, et al. Semantic Enrichment of Twitter Posts for User Profile Construction on the Social Web[C]//Proceedings of the ESWC, 2011. [7] C Silvim. Large-scale named entity disambiguation based on Wikipedia data[C]//Proceedings of the EMNLP, 2006. [8] F Paolo, S Ugo.TAGME:On-the-fly Annotation of Short Text Fragments(by Wikipedia Entities)[C]//Proceedings of the CIKM,2010. [9] H Xianpei,S Le, Z Jun. Collective Entity Linking in Web Text:A Graph-Based Method[C]//Proceedings of the SIGIR, 2011. [10] L Xiaohua, Z Shaodian,W Furu,et al. Recognizing Named Entities in Tweets[C]//Proceedings of the ACL, 2011. [11] D Milne, I H Witten. Learning to link with Wikipedia[C]//Proceedings of the CIKM, 2008. [12] P Cao,S Liu, J Gao,et al. Finding Topic-related Tweets Using Conversational Thread[C]//Proceedings of the IFIP 7th International Conference on Intelligent Information Processing, 2012. [13] 莫溢,刘盛华,刘悦,程学旗. 一种相关话题微博信息的筛选规则学习算法[J]. 中文信息学报,2012,26(5):1-7. [14] P N Mendes, P Alexandre,K Pavan, et al. Linked open social signals[C]//Proceedings of the WI-IAT, 2010. [15] M Edgar,W Wouter, R Maarten. Adding Semantics to Microblog Posts[C]//Proceedings of the WSDM, 2012. [16] D D Lee, H S Seung. Learning the parts of objects by non-negative matrix factorization Nature,1999, 401(6755):788-791. [17] D D Lee, H S Seung. Algorithms for non-negative matrix factorization[C]//Proceedings of Neural Information Processing Systems, 2001. [18] A Hyvarinen,J Karhunen, E Oja. Independent Component Analysis[C]//Proceedings of the Wiley Interscience, 2001. [19] S Farial,W Berry Michael, V Paul. Document clustering using nonnegative martix factorization[J].Information Processing and Management, 2006,42(2):373-386. [20] A Saha, S Vikas. Learning Evolving and Emerging Topics in Social Media:A Dynamic NMF approach with Temporal Regularization[C]//Proceedings of the WSDM, 2012. [21] Patrik O.Hoyer.Non-negative Matrix Factorization with Sparseness Constraints[J]. Journal of Machine Learning Research, 2004,5:1457-1469.
4 实验和评价
4.1 实验数据
4.2 候选语义概念扩展比较算法
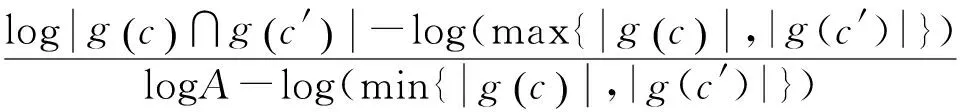
4.3 实验结果和评价



5 总结及展望
