一种基于类别先验信息的问题检索语言模型
2014-02-28吉宗诚
吉宗诚,王 斌
(1.中国科学院 计算技术研究所,北京 100190;2. 中国科学院大学,北京 100049)
1 介绍
近年来,社区问答系统(例如,Yahoo! Answers*http://answers.yahoo.com/,百度知道*http://zhidao.baidu.com/等等)逐渐成为一种非常流行而实用的互联网应用。人们不但可以通过社区问答系统进行提问以满足自己的信息需求,而且还可以回答其他用户提问的问题来分享自己的知识。随着社区问答系统的发展,在互联网上已经积累了大量的问题答案对。为了能够重用这些非常宝贵的历史问题答案对资源,设计出一个非常有效的问题检索模型至关重要。问题检索即给定一个查询问题,系统能够从问题答案库中检索出与查询问题非常相似的问题答案对并返回给用户。
作为传统信息检索的一个特殊应用,相似问题检索与传统信息检索的一个不同之处在于社区问答系统中的历史问题是按照人工设定好的层次类别体系进行组织的。即,社区问答系统中的每个问题都有一个对应的类别标签。在同一个类别或者同一个子类别中的问题往往都属于同一类话题。因此,可以利用这里的类别信息来增强相似问题检索。
在之前的相关研究中,已经有一些工作[1-4]开始尝试在已有的检索模型中引入问题的类别信息。实验结果表明合理的引入问题的类别信息可以非常有效地提升相似问题检索的性能。特别地,Cao等人在文献[2]中,在语言模型建模的框架下提出了一种二级平滑的方法来引入问题的类别信息以提高相似问题检索的性能,并且取得了不错的实验结果。然而,该方法是使用一种启发式的方法将类别信息相关的模型与已有的检索模型在模型间(externally)进行一种在词项层次上(at the word level)的简单的线性插值。
语言模型建模的方法因其在信息检索中具有非常不错的检索性能,已经成为一个非常具有吸引力的研究方向。因此,在本文中我们将尝试将类别信息融入到一元语言模型的建模过程中。我们的基本出发点是这样的: 同一个词项w在不同的类别中应该具有不同的词项权重。即,一个历史问题Q中的一个词项w在其所属的类别Cat(Q)中应该与该词项在其他类别Cat′(Q)中具有不同的词项权重。例如,词项“China”在类别“Travel.AsiaPacific.China”中比在类别“Travel.AsiaPacific.Korea”中出现得比较频繁,因此将会具有更高的词项权重。这里,我们将词项在不同类别中具有不同的词项权重以Dirichlet超参的形式来对一元语言模型中的词项参数进行加权。因此,我们将得到一种将类别信息相关的模型融入到一元语言模型建模过程中的方法,我们称之为在模型内(internally)进行一种在词项层次上(at the word level)的融入方式。这种在词项层次上的融入方式是具有数学推导依据的。另外,我们在来源于Yahoo! Answers的大量真实数据集上做了实验比较和分析,实验结果表明我们提出的方法比之前在模型外进行简单的线性插值的方法具有非常显著的性能提升。
本文的组织如下: 第2节介绍相似问题检索的相关工作;第3节详细描述本文提出的融入问题类别信息的方法以及理论分析;第4节介绍实验内容与结果讨论;最后第5节进行总结并提出一些未来工作。
2 相关工作
近年来,社区问答系统中的相似问题检索已经被研究人员进行了广泛的研究。之前的许多工作主要集中在使用基于翻译的方法[5-8]、基于潜性话题模型的方法[1,9]以及基于句法树匹配的方法[10]来缓解查询问题和历史问题之间的词汇鸿沟问题。此外,Ming等人在文献[4]中提出了一种利用类别信息的词项赋权的方法来提高在某一特定类别中的问题检索性能。Cao等人在文献[2-3]中分别提出了不同的策略使用问题的类别信息来提高相似问题检索的性能。Cai等人在文献[1]中学习潜性话题模型时,也融入了问题的类别信息以进一步提高相似问题检索的性能。
由于本文的主要工作是研究一种新的使用类别信息的方法来提高相似问题检索的性能。特别地,我们是在一元语言模型建模的框架下融入问题的类别信息。因此,我们将详细介绍在文献[2]中所提出的在一元语言模型框架下的二级平滑的方法: 首先计算出类别的语言模型,并使用背景语言模型进行平滑;接着计算问题的语言模型,并使用平滑后的类别语言模型进行平滑。给定一个查询问题q和一个历史问题Q(其叶子类别为Cat(Q)),使用二级平滑的方法的排序函数如式(1)所示。
其中,λ和β是两个平滑参数。如果令β=1,排序函数将退化为没有使用类别信息而仅使用Jelinek-Mercer(JM)平滑[11]的一元语言模型。Pml(w|Q)、Pml(w|Cat(Q))、Pml(w|Coll)分别为词项w在历史问题Q、叶子类别Cat(Q)以及整个问题集合Coll中的最大似然估计。
从公式(1)中我们可以看出,该方法是将平滑后的类别语言模型与原始历史问题的语言模型在模型间进行一种在词项层次上的简单的线性插值。然而,在本文的工作中,我们将提出一种新的将类别信息融入到一元语言模型建模过程中的方法,该方法可以看作是在模型内进行一种在词项层次上的融入方式。
3 本文的方法
在这一节里,我们将首先简单回顾一下一元语言模型建模的方法,紧接着将详细介绍我们提出的方法,最后我们还将给出本文方法优于二级平滑方法的理论分析。
3.1 一元语言模型
一元语言模型在之前的相似问题检索的研究中[3, 5, 7]已经被广泛的采用。该模型的基本想法是这样的: 首先为每一个历史问题估计一个语言模型,然后根据所估计的语言模型来分别计算查询似然以对历史问题进行排序。
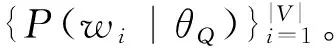
其中,c(w,q)为词项w在查询问题q中的词频。
为了避免零概率估计问题,人们通常将所估计的语言模型与背景语言模型使用一些不同的策略来对参数估计进行平滑[11]。
3.2 基于类别先验信息的语言模型
接下来,我们将详细介绍将类别信息融入到一元语言模型建模过程中的方法。
我们的基本出发点是这样的: 同一个词项w在不同的类别中应该具有不同的词项权重。即,一个历史问题Q中的一个词项w在其所属的类别Cat(Q)中应该与该词项在其他类别Cat′(Q)中具有不同的词项权重。例如,词项“virus”在类别“Computers &Internet.Security”中比在类别“Computers &Internet.Software”中出现得比较频繁,因此将会具有更高的词项权重,我们将这种与类别相关的词项权重看作是词项的先验知识。特别地,在本文中我们将词项w在类别Cat(Q)上的语言模型P(w|θCat(Q))作为词项w在该类别上的权重。我们将寻找一个能够更好地刻画词项在不同类别中具有不同权重的方法留作未来工作。
通过使用经验贝叶斯分析,我们可以使用词项参数分布的先验分布来表达对词项的先验知识,而词项参数分布的共轭分布通常被用来表示这种先验分布。多项式分布的共轭分布是Dirichlet分布。于是,我们将向θQ引入超参为u=(u1,u2,…,u|V|)的Dirichlet先验分布,如式(14)所示。
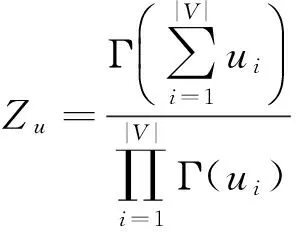
引入Dirichlet分布后,θQ的后验分布为式(5)。
有了上述θQ的后验分布后,词项参数的估计可表示为式(6)。
3.3 参数平滑
同样,为了避免零概率估计问题,我们将进一步使用背景语言模型P(w|Coll)来对上述模型进行平滑。特别地,我们将使用基于整个历史问题集的Dirichlet先验(μP(w1|Coll),μP(w2|Coll),…,μP(w|V||Coll)来进行平滑。于是,我们得到如下平滑后的基于类别先验信息的语言模型的参数估计:
需要特别注意的是,从公式(7)中我们可以看出,平滑后的基于类别先验信息的语言模型的词频可以看成分别由文档层次的词频c(wi,Q)、类别层次的伪词频λCatP(wi|θCat(Q))以及文档集层次的伪词频μP(wi|Coll)组成。如果令λCat=0,公式(7)所示的排序函数将会忽略问题的类别信息,从而退化为使用Dirichlet平滑的一元语言模型[11]。
最后,在查询似然语言模型的框架下,使用平滑后的基于类别先验信息的语言模型的排序函数如式(8)所示。
3.4 理论分析
接下来,我们将通过理论分析来探讨本文所提的方法要优于文献[2]中提出的二级平滑方法的原因。对式(1)、(7)进行变形,分别得到式(9)、(10):
从式(9)、(10)中可以看出,本文提出的平滑后的基于类别先验信息的模型在公式形式上类似于式(9)中的二级平滑的方法,其中:
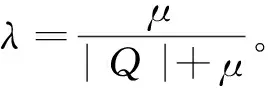
2) 若β≠1,λCat≠0,公式(10)中与类别相关的词项权重信息(类别语言模型)以及背景语言模型的系数均随着问题长度|Q|的变化而进行动态的调整,而在公式(9)中所对应的系数对每个问题都是固定的。因此,本文所提方法在理论上是要优于二级平滑方法的。在实验中我们也将看到本文方法的检索性能要优于文献[2]中提出的二级平滑方法。
4 实验与讨论
4.1 实验配置
4.1.1 基准方法
为了评估基于类别先验信息的语言模型的检索性能,我们使用以下三类基准方法:
1) LM: 未考虑类别信息的一元语言模型。在实验中,我们将分别给出使用JM平滑和Dirichlet平滑的实验结果,分别记为LMJM和LMDir。
2) LM@OptC: 该方法仅在查询问题在Yahoo! Answers中由用户指定类别中使用一元语言模型进行检索,其中我们只使用JM平滑方法来平滑这里的一元语言模型。
3) LM@LS: 在文献[2]中提出的二级平滑的方法。
4.1.2 数据集
我们采用在之前使用类别信息来增强相似问题检索的先驱工作[2-3]中所公开的采集于真实社区问答系统Yahoo! Answers的数据集*http://homepages.inf.ed.ac.uk/gcong/qa/。该数据集包含252个查询问题、1 373个作为查询的标准答案的相关历史问题。在实验中,我们采用以下过程来对所有的问题进行预处理: 所有问题均小写化,使用常用的418个停用词表来去除所有的停用词。经过预处理后,我们得到最终的含有3 111 219个问题的历史问题库,该问题库包含26个一级类别,1 262个叶子类别。每个问题属于唯一一个叶子类别。
4.1.3 评价指标
我们采用以下两个常用的评价指标来评估所有方法的检索性能: Mean Average Precision (MAP)、Precision@10 (P@10)。系统返回的相关问题越靠前,MAP分值越高; 而P@10则反映了系统返回的前10个候选问题中相关的问题个数所占的比例。另外,我们还使用pairedt-test (P<0.05)来做统计显著性检验。
4.2 参数设置
在实验中,需要设置许多参数。同文献[2],将公式(1)中的β设为1、λ设为0.2,从而得到LMJM;将公式(1)中的β设为0.2、λ设为0.2,从而得到LM@LS。
在LMDir中,我们将公式(7)中的λCat设为0,然后分别使用1,2,3,…,20,30,40,50来调节Dirichlet平滑的参数μ。如图1所示,当μ>5时,MAP值相对比较高且稳定;当3≤μ≤11时,P@10值相对比较高,而当μ>11时,P@10值便快速下降。因此,最好的参数μ的取值在5~11之间,这里的结论与传统的在TREC数据集上的Dirichlet参数的设置[11](在500~2 500之间)大不相同。其主要原因可能是因为在问题检索中历史问题都非常短,而传统检索任务中所使用的TREC数据并不是这样的。特别地,接下来我们将参数μ固定设为10。
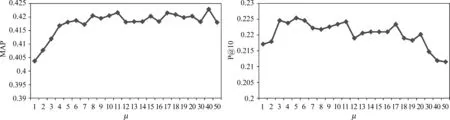
图1 问题检索中使用Dirichlet平滑的一元语言模型对参数μ的敏感性分析
在基于类别先验信息的语言模型中,参数λCat为最重要的参数。该参数控制着类别信息所带来的先验知识所占的比重。在实验中,我们使用1,2,3,…,20来调节参数λCat。图2展示了基于类别先验信息的语言模型对参数λCat的敏感性分析。可以看出,当7≤λCat≤15时,MAP的取值比较高;而当2≤λCat≤8时,P@10的取值比较高,当λCat>8时,P@10的取值逐渐下降。因此,在接下来的模型比较中,我们取λCat=7作为最好的模型参数。
4.3 结果比较
表1为使用不同的检索方法进行相似问题检索的性能比较结果。可以得出以下结论:
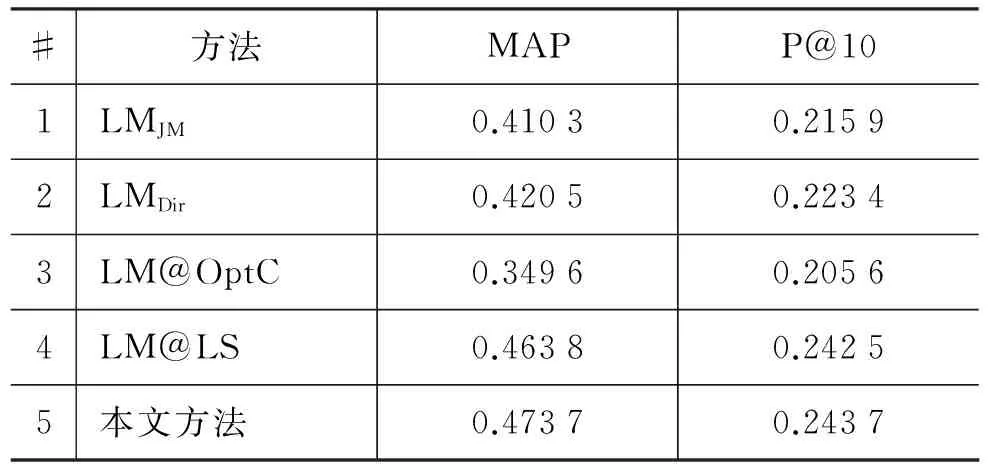
表1 不同问题检索方法的结果比较

图2 基于类别先验信息的语言模型对参数λCat的敏感性分析
1) 在我们的实验配置中,使用Dirichlet平滑的一元语言模型比使用JM平滑的一元语言模型具有非常显著的提高(第1行vs. 第2行)。
2) 仅在查询问题所属类别中使用一元语言模型进行检索的结果并不比没有考虑类别信息的一元语言模型的结果好(第3行 vs. 第1,2行)。这一结果与之前的工作[2-3]所报告的结果一致。其主要原因是因为一些相关问题并不仅仅存在于查询问题所属类别中,往往还会存在于一些其他的类别中。
3) 当使用文献[2]中所提出的二级平滑方法时,实验结果可以非常显著地提升问题检索的性能(第4行 vs. 第1,2行)。该结果也同样与之前的工作[2-3]所报告的结果一致。
4) 当使用本文所提出的方法时,实验结果在MAP和P@10上均比二级平滑方法的结果具有进一步的提升,并且具有统计显著性的提高。
5 总结
在本文中,我们提出了一种新的基于问题类别先验信息的语言模型来提高社区问答中相似问题检索的性能。该方法具有严格的数学推导依据。在来源于Yahoo! Answers的真实的大量数据集上做了实验比较和分析,实验结果表明我们提出的方法比之前在模型外进行简单的线性插值的方法具有非常显著的性能提升。在未来的工作中,我们将寻找一个能够更好地刻画词项在不同类别中具有不同权重的方法;另外,我们还将尝试将问题的答案信息融入到本文所提的检索框架中,以进一步提升相似问题检索的性能。
[1] Li Cai, Guangyou Zhou, Kang Liu, et al. Learning the latent topics for question retrieval in community qa[C]//Proceedings of the IJCNLP, Chiang Mai, Thailand: Asian Federation of Natural Language Processing, 2011: 273-281.
[2] Xin Cao, Gao Cong, Bin Cui, et al. The use of categorization information in language models for question retrieval [C]//Proceedings of the CIKM, Hong Kong, China: ACM, 2009: 265-274.
[3] Xin Cao, Gao Cong, Bin Cui, et al. A generalized framework of exploring category information for question retrieval in community question answer archives [C]//Proceedings of the WWW, Raleigh, North Carolina, USA: ACM, 2010: 201-210.
[4] Zhao-Yan Ming, Tat-Seng Chua, Gao Cong. Exploring domain-specific term weight in archived question search[C]//Proceedings of the CIKM, Toronto, ON, Canada: ACM, 2010: 1605-1608.
[5] Jiwoon Jeon, W Bruce Croft, Joon Ho Lee. Finding similar questions in large question and answer archives[C]//Proceedings of the CIKM, Bremen, Germany: ACM, 2005: 84-90.
[6] Jung-Tae Lee, Sang-Bum Kim, Young-In Song,et al. Bridging lexical gaps between queries and questions on large online q&a collections with compact translation models[C]//Proceedings of the EMNLP, Honolulu, Hawaii: Association for Computational Linguistics, 2008: 410-418.
[7] Xiaobing Xue, Jiwoon Jeon, W Bruce Croft. Retrieval models for question and answer archives[C]//Proceedings of the SIGIR, Singapore, Singapore: ACM, 2008: 475-482.
[8] Guangyou Zhou, Li Cai, Jun Zhao, et al. Phrase-based translation model for question retrieval in community question answer archives[C]//Proceedings of the ACL-HLT, Portland, Oregon, USA: Association for Computational Linguistics, 2011: 653-662.
[9] Zongcheng Ji, Fei Xu, Bin Wang, et al. Question-answer topic model for question retrieval in community question answering[C]//Proceedings of the CIKM, Maui, Hawaii, USA: ACM, 2012: 2471-2474.
[10] Kai Wang, Zhaoyan Ming, and Tat-Seng Chua. A syntactic tree matching approach to finding similar questions in community-based qa services[C]//Proceedings of the SIGIR, Boston, MA, USA: ACM, 2009: 187-194.
[11] Chengxiang Zhai and John Lafferty. A study of smoothing methods for language models applied to ad hoc information retrieval[C]//Proceedings of the SIGIR, New Orleans, Louisiana, United States: ACM, 2001: 334-342.
[12] John Lafferty and Chengxiang Zhai. Document language models, query models, and risk minimization for information retrieval[C]//Proceedings of the SIGIR, New Orleans, Louisiana, United States: ACM, 2001: 111-119.
