位置服务中的查询隐私度量框架研究
2014-01-17张学军桂小林冯志超田丰余思赵建强
张学军,桂小林,冯志超,田丰,余思,赵建强
(1.西安交通大学电子与信息工程学院,710049,西安;2.兰州交通大学电子与信息工程学院,730070,兰州)
智能移动设备(例如智能手机、PDA等)的广泛使用促进了位置服务(location-based service,LBS)的快速发展。据美国ABI Research最新预测,LBS全球总收入将由2009年的26亿美元上升到2014年的140多亿美元[1]。虽然LBS为用户提供了极大的方便,但也造成了严重的隐私关注。恶意攻击者可以将包含位置信息的LBS查询与用户关联起来,推断出其生活习惯、兴趣爱好、健康状况等个人敏感信息。研究者就如何允许用户在享受LBS的同时限制其隐私泄露提出了许多查询隐私保护机制[1-5],但是,对这些保护机制的评价通常忽略了攻击者可能具有的背景知识和推理能力,而这些背景知识和推理能力可以帮助攻击者减少其对用户真实位置的不确定性[4]。因此,已有的查询隐私度量方法过高地评价了给定保护系统提供的隐私保护水平。而且,目前的LBS隐私保护研究主要集中在保护技术研发上,对隐私保护系统可信性及隐私保护机制有效性的评估还不够成熟和完善,明显缺乏一个形式化的框架来说明和度量各种查询隐私保护机制。
本文针对上述问题,设计了一个融合攻击者背景知识和推理能力的形式化查询隐私度量框架。该框架综合考虑LBS系统中影响用户查询隐私的各种因素,能正确度量各种查询隐私保护机制的有效性。
1 相关工作
在查询隐私中,位置k匿名[5]是最常使用的度量指标,k是匿名集的大小,k越大,查询的隐私性越高。林欣等指出,当匿名集中各个用户发送查询的概率不相等时,匿名集的大小就不能反映每个用户的真正匿名性[6]。Shokri等分析了位置k匿名在攻击者具有用户实时位置信息、统计信息和无信息时保护隐私的有效性,得出k匿名对查询隐私有效,对位置隐私无效,并指出攻击者可以利用k匿名的缺陷推断出用户的当前位置[7]。为此,他们提出了一种基于扭曲的隐私度量指标,通过比较攻击者跟踪用户获得的轨迹和用户真实轨迹之间的差异来反映用户的隐私保护水平[8]。最近,Shokri等设计了一个位置隐私量化工具,假定攻击者可以利用从用户轨迹采样中抽取的用户移动模型、LBS访问模式等推断其截获的轨迹的真正制造者,并使用攻击者的期望估计误差作为隐私度量指标[9],它在思想上和我们的工作很接近。通过对以上工作的研究发现:①已有的查询隐私度量方法大都忽略了攻击者的背景知识和推理能力,而这些信息和隐私度量密切相关。②已有的查询隐私度量方法大都针对某个特定的隐私保护技术,缺乏一个泛化的度量框架来量化各种隐私保护机制,因此建立融合攻击者背景知识和推理能力的查询隐私框架就显得非常必要。
2 查询隐私度量框架
为了正确度量各种查询隐私保护机制在不同攻击模型下的有效性,需要综合考虑LBS系统中影响用户查询隐私的各种因素和它们之间的关系,例如用户的时空状态和需求、攻击者的背景知识和推理能力、隐私保护机制实现算法、隐私指标等。本文将这些高度相关的因素放在一起,针对匿名和泛隐私保护机制,设计了一个形式化查询隐私度量框架,如图1所示。
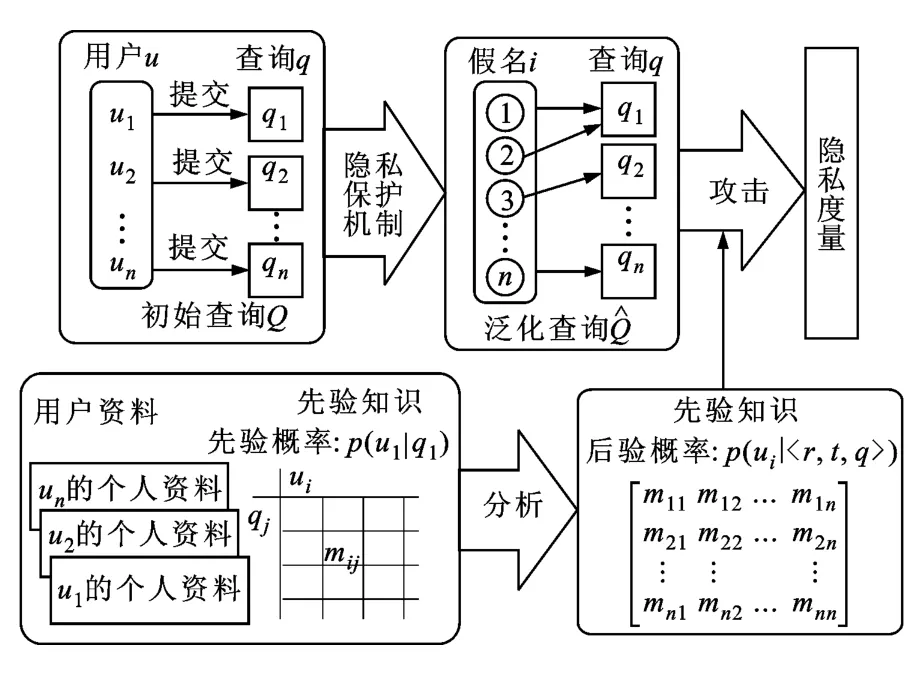
图1 查询隐私度量框架
定义该框架为六元组<U,Q,PPM,,Aattacker,Mmetric>,其中U是用户u的集合。Q为用户u在t时刻l位置上发出的LBS查询集合。PPM是隐私保护机制,它对查询q(q∈Q)进行扭曲处理并产生泛化查询是攻击者可以观察的泛化查询的集合。Aattacker是攻击者,指能够通过LBS访问用户位置和查询的任何实体。Aattacker能够利用他对PPM、用户资料的背景知识和,通过执行推理攻击推断出q的真正请求者。Mmetric是查询隐私度量指标,用于度量攻击者的攻击性能。攻击者的推理是统计意义上的,他利用获得的用户资料抽取每个用户发送q的先验概率,形成概率矩阵M=(mij),进而利用M尝试重构泛化区域内每个用户发送的后验概率。
2.1 移动用户
在移动无线网络环境中,用户是在一定的时空状态下执行LBS查询,时空特性不仅包含它的实际状态,也包含来自观察者角度的状态。
记U={u1,u2,…,uN}为在区域L 内移动的N个用户的集合,L={l1,l2,…,lM}为 M 个不同位置的集合,时间T={1,2,3,…,T}是离散的,为可记录时间实例的集合。由于用户是移动的,其位置随时间发生变化,所以记函数whereis:U×T→L为用户在任意时刻的真实位置。用户u在时刻t的位置分布定义为集合S(t)={(u,whereis(u,t))|u∈U}。
定义1(初始查询Q) 设Qu为LBS支持的所有查询qu的集合,则定义用户u的初始查询q为一个四元组<u,t,whereis(u,t),qu>,其中u∈U 为用户标识,t∈T 为查询q发生的时间戳,whereis(u,t)∈L是用户u在t时刻与查询q相关联的位置,qu∈Qu是查询体。用户U在时刻T所有可能的初始查询的集合为Q⊆U×T×L×Qu。初始查询Q代表了用户在真实环境中的实际状态。
2.2 隐私保护机制
LBS系统中,攻击者能够利用其可用的背景知识从初始查询Q中推理出用户的隐私信息或定位其位置。为了防止这种威胁,需要在LBS服务器得到用户查询之前,对其进行扭曲处理产生泛化查询。隐私保护机制就是实现这种扭曲处理的。
定义3(隐私保护机制PPM) 设Q是初始查询,泛化查询,则定义隐私保护机制为映射函数f:Q→。例如,有f(q)=。转换函数f实现初始查询到泛化查询的映射,攻击者的目标就是通过观察到的泛化查询的子集,尽力重构出查询Q。
2.3 攻击者
为了正确评估隐私保护机制的有效性,必须对攻击模型进行建模。攻击模型可通过攻击者的背景知识和推理能力来刻画。对每种隐私保护机制,攻击者所拥有的背景知识和推理能力直接影响攻击这种保护技术的难易程度。攻击者得到的有用背景知识越多,推理能力越强,就越有可能推断出用户的隐私。所以,只有将攻击者的背景知识和推理能力融入到隐私度量中,才能正确度量用户的隐私保护水平。
2.3.1 攻击者背景知识和推理能力假设 在隐私度量中融入攻击者的背景知识,就需要知道攻击者可能拥有多少或哪些背景知识,这在实际中是不可行的。因此,一般会对攻击者所拥有的背景知识和推理能力做出各种假设。本文做如下假设[10]:①攻击者具有用户实时位置分布的全局知识;②攻击者可获取匿名服务器转发给LBS服务器的任何泛化查询,匿名服务器可信且用户和匿名服务器之间的通信是安全的;③匿名服务器使用的隐私保护方法是公开的,即对匿名集中的每个用户,攻击者通过隐私保护方法得到的匿名区域和其他人进行计算得到的匿名区域一样;④攻击者可利用获得的用户资料得到关于用户的先验知识;⑤攻击者不具备用户隐私需求的决策过程,但在获得匿名服务器转发的泛化查询后,可以了解用户的隐私需求;⑥攻击者不能关联同一用户的任意两个查询。
2.3.2 攻击者背景知识的表达与量化 在查询隐私中,攻击者的目标是通过观察到的的子集,利用相关的背景知识尽可能正确地重新识别出q的真正发送者u。攻击者观察到泛化查询子集的范围取决于它的能力。对全局攻击者,它观察到泛化查询的子集等于。攻击者识别出的真正发送者越正确,用户隐私泄露的可能性就越大。因此,可以将u和初始查询q以及u和泛化查询之间的关联描述为条件概率p(u|q)和p(u|)。将所有p(u|q)和p(u|)都看作变量,而将背景知识表达为这些变量的约束。
本文中,假定攻击者具有用户资料的背景知识。用户资料可描述为与用户相关的一组属性的集合,分为描述信息(例如国家、种族等)、联系信息(例如姓名,地址等)和偏好信息(例如移动模型等)[11]。攻击者还可以通过对用户的观察截取到一些服务请求的背景知识,例如用户的假名、查询内容、位置等。攻击者将具有的背景知识和观察到的信息进行关联攻击,得到p(u|q)和p(u|),这就将背景知识表达成了变量p(u|q)和p(u|)的约束。
2.3.3 先验知识的获取 用户资料的每个属性都有一定的取值范围,其取值可离散化为明确的形式。例如,性别的取值可表示为“男”、“女”等。这样,每个属性的取值都是有限的。设A={a1,a2,…,an}是要考虑的n个属性,则每个用户的资料可表示为Φu={a1:v1,a2:v2,…,an:vn},其中vi是用户u 的属性ai的取值,ai的取值可以为空。
给定一个属性ai,先将其值离散化。如果是数字型,则把连续数据空间划分为不相交且互斥的间隔区域,离散后的每个属性用二进制串表示。于是用户的资料可以用一个向量Pu=<l1,l2,…,ln>表示,其中li是一个二进制数字序列,该序列的长度等于ai的所有可能离散值的个数。如果vi满足相应离散值,则相应二进制位取为1,否则为0。如性别所有可能的值是“男”和“女”,可用两位二进制表示:“男”对应的位取1,为“10”,“女”对应的位取1,为“01”;
对每个查询q,都有一个相关属性的子集用于推理该查询的真正请求者。由于用户资料中的每个属性对攻击者识别查询q的重要性不同,所以相关属性的每个值都应有一个权重以确定该属性值识别查询q的重要程度。例如奢侈品的查询,相关的属性应包括工作、月薪和年龄。在这3个属性中,月薪比年龄重要,而且月薪超过10 000元比月薪低于1 000元对该查询更重要。因此,引入相关向量W(q)=<w1,w2,…,wn>表示属性值和查询q之间的关系,其中n为属性的个数。对于任意用户u∈U 和表示用户u的资料和查询q的相关程度。于是,用户u发送查询q的概率为

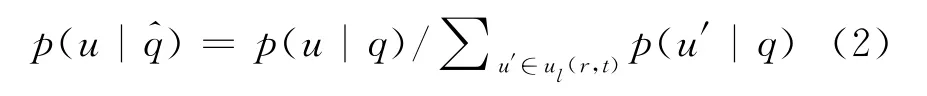
2.4 隐私度量
为了客观评价查询隐私保护机制的实际效果,需要建立一些评价指标来度量用户的查询隐私。
2.4.1 位置k匿名
定义4(位置k匿名) 设q=<u,t,whereis(u,t),qu>∈Q是一个初始查询=<i,r,t,qu>∈是其对应的泛化查询。如果匿名集中的所有用户u满足则称用户u是位置k匿名。
2.4.2 β熵匿名 在查询隐私保护中,如果用户和查询关联的不确定性越大,攻击者越难推断出查询的真正发送者,因此可以借鉴信息论中的熵理论,用攻击者识别泛化查询的不确定性来度量用户的查询隐私。
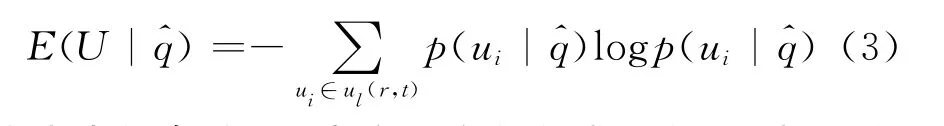
从攻击者的角度看,当它没有任何背景知识时,匿名区域内每个用户发送查询的可能性相同,匿名区域的熵最大,用户的查询隐私保护水平最高。
定义5(β熵匿名) 设β>0,q=<u,t,whereis(u,t),qu>∈Q 是初始查询=<i,r,t,qu>∈是其对应的泛化查询,如果对于所有的用户u∈ul(r,t),满足则称用户u是β熵匿名。
2.4.3 δ互信息匿名 互信息可用于度量两个随机变量之间的相关性。在查询隐私中,可以用互信息度量泛化查询被攻击者截取后查询不确定性的减少程度。攻击者在截取到泛化查询之前,仅知道q是由用户U以概率p(U|q)发送,其不确定性可描述为E(U|q)。攻击者截取到泛化查询后,其不确定性可以表示为E(U|)。于是,攻击者截取到泛化查询前后不确定性的增益为
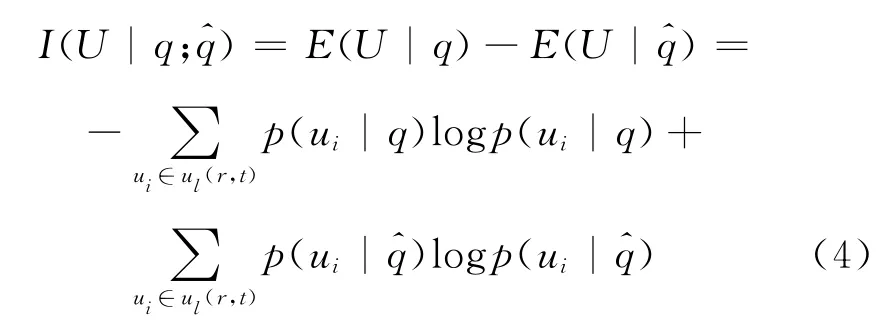
定义6(δ互信息匿名) 设δ>0,q=<u,t,whereis(u,t),qu>∈Q是初始查询=<i,r,t,qu>∈是其对应的泛化查询,如果对所有用户u∈ul(r,t),满足I(U|q;)≤δ∧f(q)=,则称查询发送者u是δ互信息匿名。
3 实验分析
利用框架对dichotomicPoints[10]隐私保护算法的有效性进行度量。实验在产生用户位置坐标和LBS请求时,采用业界认可的Thomas Brinkhoff路网数据生成器[12]模拟生成用户在Oldenburg市区(面积为23.57km×26.92km)交通路网内的运动轨迹,随机产生10 000个用户,用户的移动速度采用默认设置。攻击者关于用户资料的背景知识可用UCI机器学习中的Adult数据集,利用2.3节的方法求出。因为本文主要关注框架对隐私保护机制有效性的度量,所以在实验中采用随机产生用户先验知识的方法。模拟算法在Windows7平台下使用Java实现,测试机器的基本参数为3.51GHz Intel Core(TM)i5处理器、4GB内存。实验结果取算法执行100次仿真的平均值。
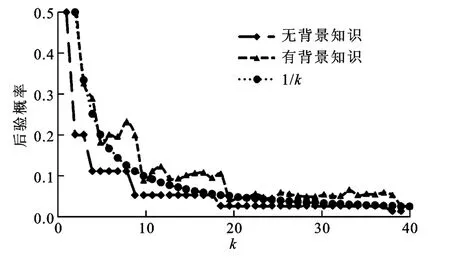
图2 位置k匿名度量
3.1 位置k匿名度量
图2给出了攻击者有、无背景知识时,利用位置k匿名度量查询隐私保护机制的情况。无背景知识时,在攻击者看来,由dichotomicPoints算法产生的匿名区域内每个用户发送查询的可能性相同。当观察到泛化查询时,攻击者只能推断出匿名区域内用户发送的概率为该匿名区域内用户数目的倒数,即图中“无背景知识”对应的曲线。有背景知识时,从攻击者的角度看,匿名区域内每个用户发送查询的概率不再相等,攻击者使用攻击算法找出最有可能发送查询的用户,即图中“有背景知识”对应的曲线。首先用户的后验概率随着k值的增加而减小,这是因为k越大,隐私保护机制产生匿名区域的用户数就越多。其次,给定一个k值,攻击者没有背景知识时,发送用户的后验概率均小于1/k,即攻击者不能以大于1/k的概率识别出查询发送者,k的大小能反映用户的隐私水平;攻击者有背景知识时,发送用户的后验概率大于1/k,即攻击者能以大于1/k的概率识别出查询发送者,用户的隐私有可能暴露,匿名集的大小已不能正确反映用户的隐私水平。因此,在查询隐私度量中考虑攻击者背景知识是必不可少的,同时也表明查询隐私的度量结果应该包括用户查询隐私水平值和攻击者背景知识的假设,这可帮助用户理解他们隐私受保护的程度以及攻击者背景知识对用户隐私保护的重要性。
3.2 β熵匿名和δ互信息匿名度量
β熵匿名和δ互信息匿名指标用于度量攻击者对查询的不确定性,反映了用户的查询隐私水平。
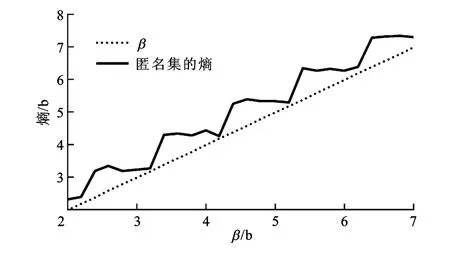
图3 β熵匿名度量

图4 β熵匿名区域面积
一个满足β熵匿名的匿名区域可以确保该匿名区域的熵值大于β,而满足δ互信息匿名的匿名区域可确保攻击者对查询不确定性的减少小于δ。图3和图5描述了不同β和δ对应的熵和互信息,可以看出,由dichotomicPoints算法产生匿名区域的所有用户都满足β熵匿名和δ互信息匿名的定义,且当β和δ分别接近整数时,熵值和互信息值的变化比较急速,这是由熵的本质所确定的。图4和图6给出了匿名区域平均面积占数据空间的比率随β和δ分别变化的情况,图4中匿名区域的面积随β增大而增大,这是因为β越大,匿名区域的熵越大,匿名区域内包含的用户越多,匿名区域的面积就越大,用户的隐私保护水平也越高,但服务质量越低。如图6所示,匿名区域的面积随着δ的增大而减小,因为δ越大,攻击者的不确性越小,匿名区域内包含的用户数越少,满足隐私需求的匿名区域就越小,用户的隐私保护水平也越低,但服务质量越高。因此,β熵匿名和δ互信息匿名指标能够正确反映攻击者具有背景知识时,查询隐私保护机制提供的用户隐私保护水平,可以帮助用户确定隐私需求和服务质量之间的平衡。
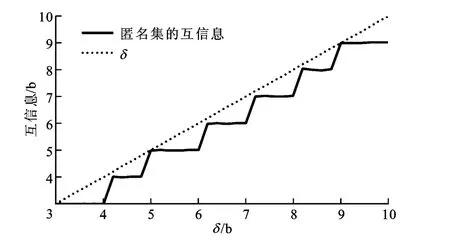
图5 δ互信息匿名度量
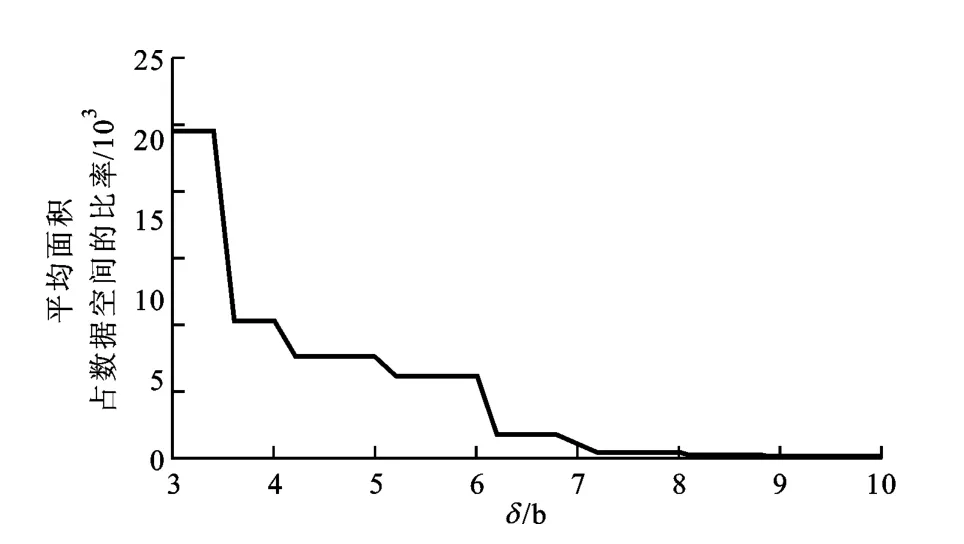
图6 δ互信息匿名区域面积
4 结 论
本文提出了一个形式化的查询隐私度量框架。该框架综合考虑了LBS系统中影响用户查询隐私的各种因素,定义了攻击者可用背景知识和推理能力的假设及隐私度量指标。实验结果验证了该框架的有效性。同时,对实验结果的分析表明,考虑攻击者的背景知识和推理能力对LBS查询隐私保护的度量是必不可少的,在设计隐私保护机制时需要对攻击者的知识和其目标的一致性进行建模,才能设计出更适合实际的查询隐私保护机制。后续工作中,将考虑把位置服务应用集成到框架中,分析隐私保护机制对于这些应用的有效性。另外,对攻击者具有用户移动模型和查询历史等背景知识进行合理的建模也是将要进行的重点工作之一。
[1] PAN Xiao,XU Jianliang,MENG Xiaofeng.Protection location privacy against location-dependent attacks in mobile services[J].IEEE Transactions on Knowledge and Data Engineering,2012,24(8):1506-1519.
[2] XU T,CAI Ying.Exploring historical location data for anonymity preservation in location-based services[C]∥Proceedings of the 27th IEEE International Conference on Computer Communications.Piscataway,NJ,USA:IEEE,2008:1220-1228.
[3] PING A,ZHANG Nan,FU Xinwen,et al.Protection of query privacy for continuous location based services[C]∥Proceedings of the 30th IEEE International Conference on Computer Communications.Piscataway,NJ,USA:IEEE,2011:1710-1718.
[4] SHOKRI R,THEODORAKOPOULOS G, TRONCOSO C,et al.Protecting location privacy:optimal strategy against localization attacks[C]∥Proceedings of the 19th ACM Conference on Computer and Communication Security.New York,USA:ACM,2012:617-626.
[5] GRUTESER M,GRUNWALD D.Anonymous usage of location-based services through spatial and temporal cloaking[C]∥Proceedings of the First International Conference on Mobile Systems, Application,and Services.New York,USA:ACM,2003:31-42.
[6] 林欣,李善平,杨朝会.LBS中连续查询攻击算法及匿名性度量 [J].软件学报,2009,20(4):1058-1068.LIN Xin,LI Shanping,YANG Zhaohui.Attacking algorithms against continuous queries in LBS and anonymity measurement[J].Journal of Software,2009,20(4):1058-1068.
[7] SHOKRI R,TRONCOSO C,DIAZ C.Unraveling an old cloak:k-anonymity for location privacy[C]∥Proceedings of the 2010ACM Workshop on Privacy in the Electronic Society.New York,USA:ACM,2012:115-118.
[8] SHOKRI R,FREUDIGER J,JADLIWALA M,et al.A distortion-based metric for location privacy [C]∥Proceedings of the 8th ACM Workshop on Privacy in the Electronic Society.New York,USA:ACM,2009:21-30.
[9] SHOKRI R,THEODORAKOPOUS G,BOUDEC J-Y L,et al.Quantifying location privacy [C]∥Proceedings of the 32nd IEEE Symposium on Security and Privacy.Piscataway,NJ,USA:IEEE,2011:247-262.
[10]CHEN Xihui,PANG Jun.Measuring query privacy in location-based services[C]∥Proceedings of the Second ACM Conference on Data and Application Security and Privacy.New York,USA:ACM,2012:49-60.
[11]SHIN H,ATLURI V,VAIDYA J.A profile anonymization model for privacy in a personalized location base service environment[C]∥Proceedings of the 9th International Conference on Mobile Data Management.Piscataway,NJ,USA:IEEE,2008:73-80.
[12]BRINKHOFF T.A framework for generating networkbased moving objects [J].GeoInformatica,2002,6(2):153-180.
