片上网络路由器及互连低成本测试方法
2013-11-23向东
向 东
(清华大学软件学院 北京 100084)
1 引 言
片上网络是目前的热点研究专题。以片上网络和3D 封装的 IC 技术合成的三维片上网络实现了更延迟、更低的能量消耗和更高的网络宽带。为了片上网络测试提出了充足的针对可测试性技术(Testability Techniques)的设计。文献[1]以一种 BIST 设计为基础为转换器和链接测试提出了一种简单的测试方案。[1]的方法利用数据传送机制的内在相似性来减少相互连接测试的测试成本和用一个额外转换器(Extra Swith)来支持多播。该方法可有效地降低互连测试时间。文献[2]提出了一个针对片上网络内核测试的新测试压缩方案,可有效降低测试传输时间。
片上网络测试包括路由器、内核和互连测试。文献[3]提出了一个 DET 方案同时向所有相同路由器传送数据。但对于大规模的片上网络,路径和连线开销(Connection Overhead)可能是个问题。Cota 等[4]提出了一个新的基于 BIST 的方案来测试路由器和相互连接,根据该方案每个路由器都必须插入一个测试码生成器(Test Generator)和 MISR。文献[1]提出了一个通过对相同路由器增加一个转换器来支持多播操作的方法来传递测试包的多播方案。
本文接下来第二节介绍对路由器传送测试数据的新的基于单播的多播方案。第三节介绍对相互连接测试的新的测试应用程序方案。第四节介绍详细的实验细节。第五节为经验结果。第六节为本文结论。
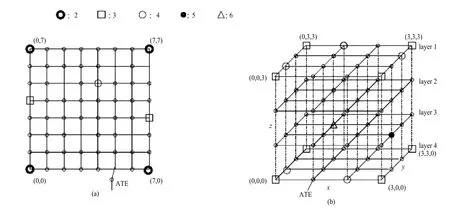
图1 NOC 里路由器的分类:(a)二维封装的 8×8NoCS,(b)三维封装的 4×4×4 片上网络
2 片上网络路由器测试
在三维封装的片上网络里,路由器根据结点度数分为四类。如图 2 所示,对于相同类的路由器,我们采用基于单播的多播方案来传送测试包。一个基于单播的多播方案提供了一个基于软件的多播,因而一个单播路由器上不需要硬件修改来支持多播。像在[5]一样多播源(ATE)仅在第一步单播步骤参与测试传送进程。同一类路由器测试一次性传完。单播采用文献[6,7]里的自适应路由方案。
不像文献[5],路由器测试和测试包传送不可能同时进行。我们的方法是将测试数据包传送到目的结点接收缓冲器里。测试数据包传输一直到接收缓冲器(Consumption Buffer)存满为止,此时保存在接收缓冲器里的测试置入到路由器中。测试包又传送到路由器接收缓冲器中,重复上述处理直到该类路由器的测试传输完毕。
四度边界路由器测试数据包传送所需的三步单播步骤如图 3 所示。在第一步单播步骤时,测试数据包被传送到第四层里最右边列里的所有边界路由器和路由器 A。通过第二步单播步骤,所有在第四、E 和F 层的边界路由器接收测试包。在第四层的所有边界路由器中,除了与 ATE 相连的外,其余的都将测试包传送到第三步单播步骤里第一层的所有边界路由器。在第三步单播步骤里,路由器 A 传送测试包到路由器 B 和 C。
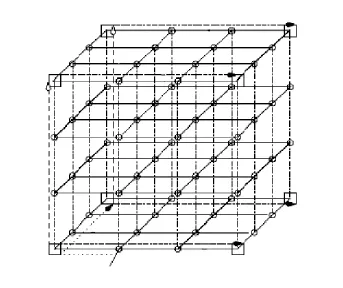
图2 三度路由器测试图
图2 显示的是在三维封装的片上网络三度路由器测试方案。测试数据包从与 ATE 相连的路由器传送到第一步单播步骤里第四层最右边列的角落路由器里。测试包垂直地传送到剩下的如图 2 所示的最左边的 YZ 平面里第二步单播步骤角落路由器。然后被传送到最右边 YZ 平面里第三步单播步骤里的其他四个路由器。
如图 4 所示,我们的方法以四步单播步骤将一个测试包传送到所有五度的路由器里。测试包从 ATE传送到第一单播步骤中第四层里最左边列里五度路由器。在第一步单播步骤中,接收测试包的路由器将测试包传送至第二步单播步骤中第四层所有其他五度路由器。在第四层最左边列五度路由器传送测试包到第三步单播步骤里最左边列 YZ 平面度数为五的所有路由器。同时,在第四层最左边列里五度路由器传送数据到第三步单播步骤里最右边 YZ 平面里所有的五度路由器。
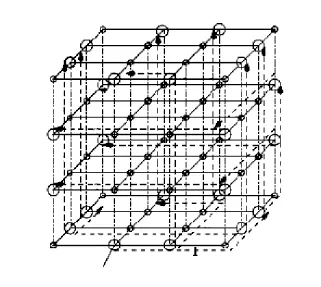
图3 四度路由器测试图
在第四步单播步骤里,最左边 YZ 平面的路由器发送接收到的测试包至前 XY 平面和后 XY 平面度数为五的路由器。如图 4 所示,在第四层里五度路由器传送数据测试包到单播步骤 4 中第一层里所有度数为五的路由器。
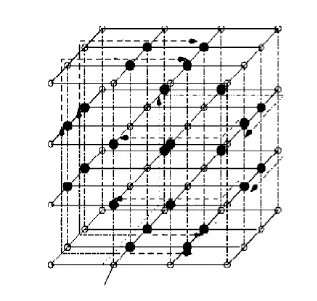
图4 五度路由器测试图
我们的方法以三步单播步骤传送测试包到所有阶次为六的路由器,如图 5 所示。在第一步单播步骤里,一个从 ATE 处的测试包被传送到第三层里最左边列里内部的路由器。在第二步单播步骤里,接收到的测试包被传送到所有其他同层的内部路由器。在第三步单播步骤里,第三层所有内部路由器沿维 Z 传送数据包到同列的所有其他内部路由器。以上表明提出的测试交付程序是可扩展的。也就是说,测试成本可以类似于片上网络的任何规模。实验结果亦符合这条。
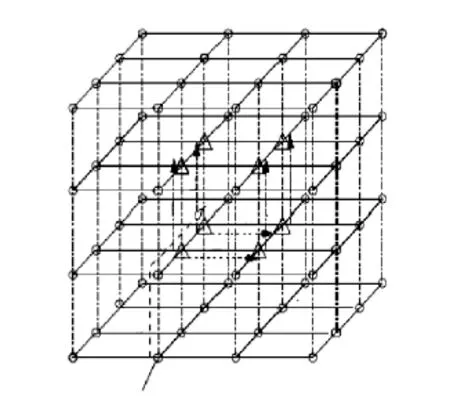
图5 六度路由器测试图
在我们的方法中,每个路由器插入一个为所有测试包压缩和获取测试回应的 MISR。运用与基于单播的多播方案的相反操作,相同分类的内核测试回应传送回 ATE 就像[5]提出的一样。
3 相互连接测试方案
与[4,8]中 BIST 方案不同的是,确定性测试数据包传送内核与响应保存在内核的 MISR。我们考虑到供给相同路由器之间的链接的桥接故障(Bridging Fault)。其他任何的物理链路(Physical Link)间的桥接故障也包括在内。
在我们的方法中,首先把测试数据从 ATE 传送到所有内核,每个内核接收到两个测试数据包:一个是如图 6 所示,同样大小的另一个测试数据包含了所有的零。如图 7 所示,用三步单播步骤就可以播送一个测试包到所有内核。传播方案与通道交叠的路由策略一致,也可采用可以被其他任何路由策略。

图6 32 位互连测试的测试包
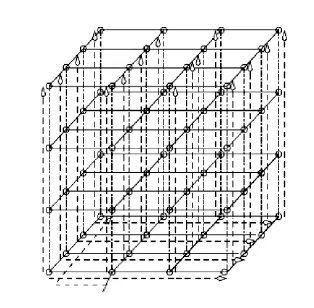
图7 互连测试中播送的数据图
如图 8 所呈现的测试传送方案,每个节点(Node)沿 X+方向传送测试包 P1到相邻路由器。含有所有 0 的测试包 P2沿着 Y+和 Z+方向传送。测试包 P2也从最右边的 Y-Z 平面、最后的 X-Y 平面和上面的 X-Y 层里的路由器沿 X-,Y-和 Z-方向传送到最末端。如图 10(a)所示,测试包经注入通道引入到网络。然后测试包通过与相邻路由器联系的物理链路传送,最终通过接受通道被相邻路由器接收。在图 10 中只有三个链路出现。在三个测试数据微片(Flit)传送后,a 与任何其他在路由器 R1里注入通道的链接之间、b 与任何其他沿 X+方向路由器 R1和 R2之间的物理通道、c 与在路由器 R2中的接收通道里的所有其他链接的桥接故障均可检测到。B 和所有从 R1沿维 Y 和 Z 的物理链接之间的桥接故障也覆盖在其中。路由器 R2、R3和 R4的情况一样。
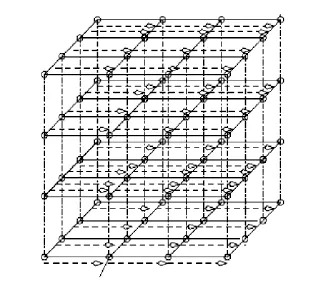
图8 沿 X 面的测试应用图
当测试包 P2如上述同样的方式传送时,测试包P1如图 9 所示从最左边的路由器沿 X+方向传送到最右边的路由器。测试包 P1首先经过如图 9 所示路由器 R1的注入通道被插入到网络。之后,测试包被传送过 R1和 R2、R2和 R3、R3和 R4之间的物理链路。最后测试包经由在 R4的接收通道被接收。完成测试置入后,任何一对物理链路之间的桥接故障都会被检测到。类似地,测试包沿 X-方向以两种不同的方式传递。测试包沿维 Y 和 Z 以两种方式传送如同沿维 X 的方式一样。
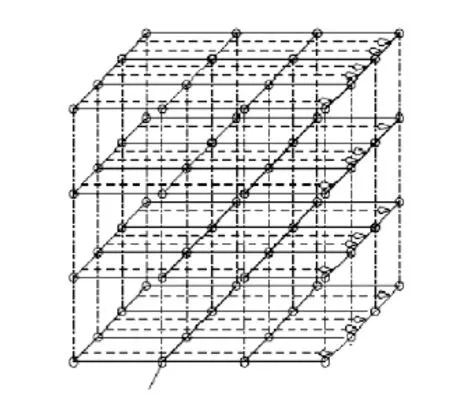
图9 相邻物理链路桥接故障测试图
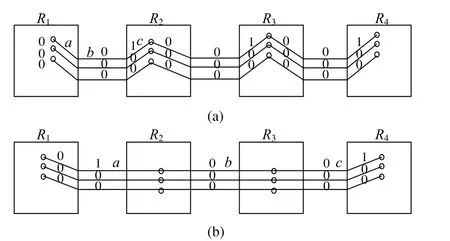
图10 互连测试应用:(a)为基于图 8 方案;(b)为基于图 9 方案
4 实现细节
就像所有其他的基于单播的多播操作一样,ATE仅仅只参与第一步单播步骤。而完全不同于[5]所述,总的测试时间包括传送测试包的时间和对应所有测试的时间。不像对内核的测试,传送单个测试包所需要的单播步骤数对总的测试时间有很大的影响。当网络在传送数据时,对路由器的测试应用程序就不能完成。
消耗缓冲器的深度对测试时间有很大的影响。假设消耗缓冲器的大小为 K。我们的方法在第一个测试包已经从 ATE 处传送后传送第二个测试包。也就是说,第二个测试包在第一个测试包播送后仅用一个单播步骤播送。这就使测试交付程序形成了一条管线。这个程序持续到 K 测试包传送完。K 测试向量(Test Vector)应用于路由器的同时,测试回应被压缩成MISR。而测试交付程序在 K 测试向量被应用完之后继续运行。程序持续运行直到所有测试全部应用于路由器。所有用来传送的时间远没有超过传送一个测试包的时间,因为 ATE 只在第一步单播步骤里参与传送一个测试包。消耗缓冲器的深度对测试时间影响的实验结果将在实验结果部分阐述。
当将测试包保存在一个内核的接收缓冲器里时,可以存储测试包的数量取决于接收缓冲器的深度。当接收缓冲满了时,保存在里面的测试就会置入到路由器。我们的方法在测试置入后,重新开始测试传送。这个处理一直持续到所有测试包传送到目的地,且测试已经应用到路由器。
在一个三维封装的片上网络里,路由器分为四种类型。在三维封装的片上网络里,也分为 4 个类别。其中,两个额外位用来表示在测试包的类别,其他的两位额外位用于表示单播步骤数。因为所有的测试包可以以最多四步单独的单播步骤传送进所有的路由器,所以在 ATE 里保存相同分类的所有路由器的寻址是没必要的。在测试数据包大头文件保存所有在第一步单播步骤里接收测试包的目的地就足够了。所有在第一步单播步骤里接收测试包的路由器创建新的头文件包含了成功单播步骤目的地。我们的方法转向对下个路由器分类测试传输直到所有测试包传送到路由器的当前分类。
收集测试响应的技术与[5]十分地不同,但也十分地简单。我们的方法是插入一个对所有测试包可以接收和获取测试回应的 MISR 到每个路由器中。如图11 所示,一个路由器的测试响应以一种新的方式在MISR 压缩。所有测试向量的测试回应被压缩成单个的向量保存在 MISR 中。相同分类的内核测试响应与在[5]提出的方案一样传送回 ATE,但采用与基于单播的多播方案的反向操作。在多播树里,传送测试包的一个节点的后继就成为响应数据包的前驱。在多播树里,为测试回应压缩每个节点唯一的前驱成为它单一的后继。
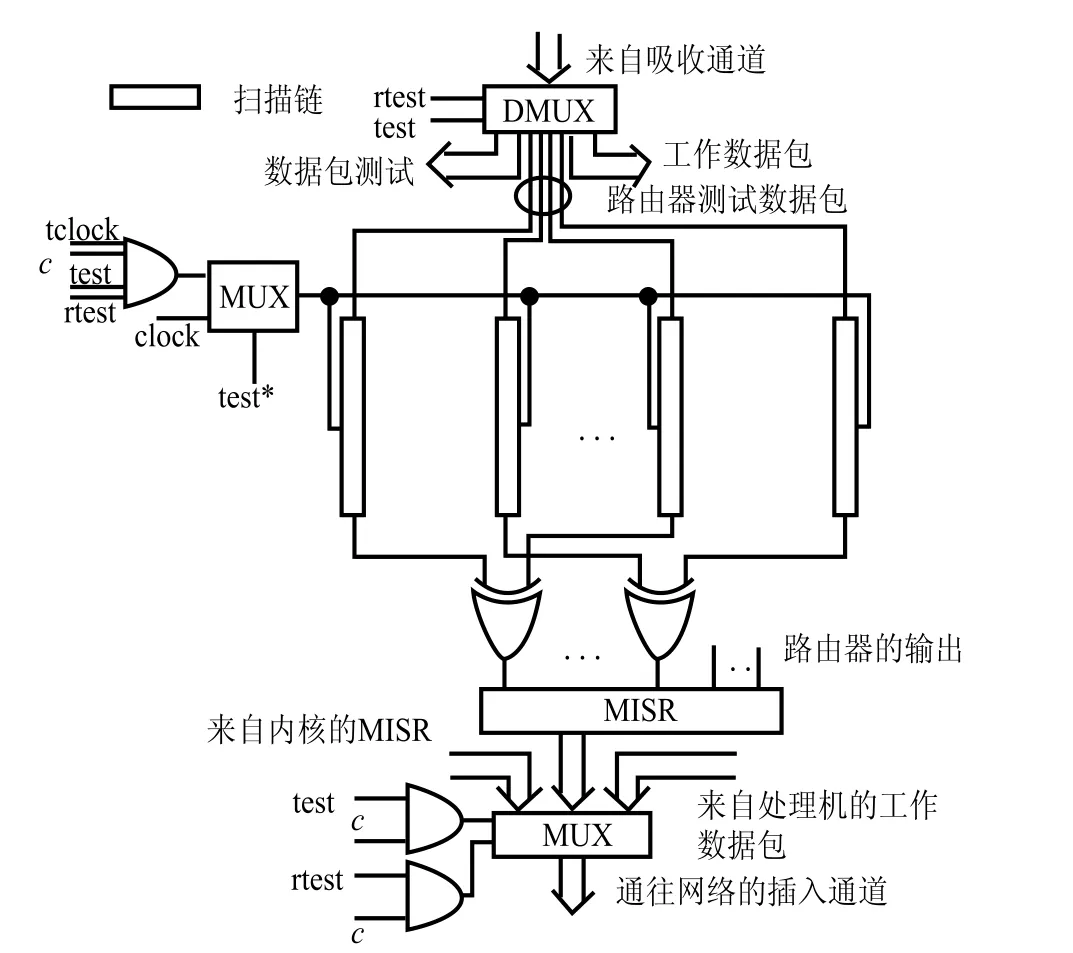
图11 含有一个基于 MISR 的测试回应紧密器的 DET 构架图
测试响应包不会和含有测试包的片上网络源发生冲突。这是因为测试响应是在所有测试包传送到所有内核且应用于路由器后才收集的。对于相同分类的路由器测试包,作为单一的响应包传送回 ATE。而所有从相同分类的路由器得到的测试响应包则沿着测试包传输设计的基于单播的多播方案相反路线传送。
额外的管脚(Extra Pin)数必须很好地控制。每个路由器都需要一些扫描输入和扫描输出管脚,当在片上网络中内核的数量足够大时,额外管脚数量也可以达到非常地大。如果每个内核用一个单独的测试选择管脚,那么对于所有的路由器来说,扫描触发器的测试选择管脚的数量也会非常地大。只有相同分类的路由器才可以同时被测试,因此片上网络的测试效率不是很高。
如先前所述,测试响应采用 MISR 为基础的响应压缩器压缩,如果需要它可以容忍未知响应信号。驱动触发器 MUX 的额外管脚 rtest 可以被所有的路由器共享,因而必须另外一个额外的管脚。当 rtest=0 和 test=1 时,为内核测试;当 rtest=1,test=1 和 test’=1 时,为路由器测试状态;当rtest=0,test=0 和 test’=0 时,为片上网络工作模式。
一个额外的管脚 c 与所有的 AND 入口相连驱动扫描链。路由器的每个分类都需要一个单独的额外插针 c。可以采用一个全局额外寄存器,在那里每个全局额外扫描链的扫描触发器与附加管脚相连。因此,控制路由器四个不同分类的额外管脚的数量仅仅只有一个。对每个测试数据包载入控制向量是没必要的。对于相同分类的路由器的所有测试包可以在传送针对另一分类的路由器的测试包之前传送。
如果额外管脚 c 的值为 0,那么对其他分类的路由器的扫面链会被工作时钟(Operational Clock)clock 控制。如果 test’=1 和 c=1,那么所有扫描链被测试时钟 tclock 控制。也就是说,仅仅一个全局扫描输入管脚和一个扫描输出管脚就够了。无论如何,仅仅只有一个额外寄存器的一位字节设为 1,所有其他字节设为 0。
一个路由器的所有扫描输入插针连接到 DMUX的输出,它的输入连接到接收缓冲器。这个接收通道就是从网络到一个内部内核的一个接口。如图 11 所示,扫描链的扫描输入管脚从信号分离器(Demultiplexer)的输出驱动。信号分离器输出的其中一个就是扫描输入管脚,其他的就是连接到处理器来传送工作数据包的通道。扫描输入管脚并没有在片上网络的输入采用任何额外管脚。
MISR 与 MUX 相连,它的输出从路由器处与注入缓冲器相连。而保存在 MISR 的最终数据传回到ATE。因此,所有的路由器共享相同的额外管脚 e。注入缓冲就是为每个从内核到网络的节点接口。保存在 MISR 的最终测试回应从内核经过注入缓冲注入到片上网络,在基于单播的多播方案里,它被消耗在它的前导处。在相同内核处消耗的测试响应包被压缩成单个测试回应包,再次注入到片上网络,然后当传送测试包时,传送到它特定的前导。这种技术与[5]中响应压缩方案类似。
5 实验结果
我们已经实现了本文提出的方法和文献[1]中的方法。通过运用 TSMC65 纳米单元库及斯坦福大学的系统来综合基于通道交叠的自适应路由器[6]。不同数量输入、输入端口的路由器划分为不同的类型。其他的路由器方法,如维序路由(Dimension Order Routing)或转弯模型(Turn Model)都可以通过TSMC65 纳米单元库(Cell Library)及斯坦福大学的系统来综合。
综合出来的路由器如表 1 所示。原始输入、输出和面积如表 1 所示。我们采用十个扫描链来实现路由器测试。路由器测试考虑单固定型故障(Stuck-at Fault)。对于路由器测试考虑转换故障(Transition Fault)测试也一样。我们采用商用ATPG 工具 TetraMax of SYNOPSYS 来产生测试码。表 1 还给出了故障覆盖率 FC,测试向量数及路由器面积。我们假设测试在测试包被每个内核接收后立刻开始执行。在从每个内核到片上网络的注入通道及接收通道能够存放三个测试或测试响应包。
测试包首先被传递到与 ATE 相连的内核。该数据包被传输到与该多播通讯相关联的内核。3D 封装的片上网络里每个物理通道都有两个虚拟的通道。当注入缓冲器提供足够的缓冲器来保存三个包时,每个内核的接收缓冲器可以保存多个测试包。相邻两个路由器为每个时钟周期传递一个测试数据微片,一个测试数据微片包含 32 位数据。
表2 为当接收缓冲器存储量变化时, 4×4×4片上网络上采用该方法的实验结果。如表 3 所示,对于 6×6×6 网格测试时间有少量增加。表明本文方法的可扩展性很好。表 4 为本文方法在测试时间和测试数据容量上与文献[1]方法的比较。当网络的大小增加时,文献[1]提出方法的时间也大大增加。值得注意的是,文献[1]的测试数据容量包含了测试响应。在被MISR 压缩后,本文方法的测试数据响应量就不重要了。
文献[1]中的方法仍然传送测试响应数据到内核,因而可以从插入响应压缩器到内核来判断一个路由器是否有故障。本文方法考虑到当测试数据通过一个故障的路由器和连接传送时,测试数据有可能被改变,这可以在响应数据里体现。

表1 在 3D 封装路由器的参数统计

表4 与文献 [1]比较
6 结 论
本文提出新的三维封装片上网络路由器测试方法。依据路由器分类,相同类型的路由器可共享相同的测试数据。提出了一种新的基于单播的多播技术来传输路由器测试数据。相同路由器的测试可以采用一种基于单播的多播方案来完成。通过采用 MISR 来压缩测试响应可大幅降低测试响应数据量,因而可有效地降低测试时间。与[1]中的片上网络测试技术相比,我们的方法不需要修改路由器的硬件来支持多播。本文还提出一种简单的基于单播的多播方案来测试网络互连,它不需要修改单播路由器。实验结果表明,本文方法只需要很小的面积开销,测试时间明显低于以往的方法。
[1]Grecu C, Ivanov A, Saleh R, et al. Testing network-on-chip communication fabrics [J]. IEEE Transactions on Computer-Aided Design of Intergrated Circuits and Systems, 2007, 26(12):2201-2214.
[2]Froese V, Ibers R, Hellebrand S. Reusing NoC-infrastructure for test data compression [C]// Proceedings of the 28th VLSI Test Symposium, 2010: 227-231.
[3]Amory AM, Briao E, Cota E, et al. A scalable test strategy for network-on-chip routers [C]// Proceedings of IEEE International Test Conference, 2005: 590-599.
[4]Cota E, Kastensmidt FL, Cassel M, et al. A high-faultcoverage approach for the test of data, control and handshake interconnects in mesh networks-on-chip [J]. IEEE Transactions on Computers, 2008, 57(9): 1202-1215.
[5]Xiang D, Zhang Y. Cost-effective power-aware core testing in NoCs based on a new unicast-based multicast scheme [J]. IEEE Transactions on Computer-Aided Design of Intergrated Circuits and Systems, 2011, 30(1): 135-147.
[6]Xiang D. Deadlock-free adaptive routing in meshes with faulttolerance ability based on channel overlap-ping [J]. IEEE Transactions on Dependable and Secure Computing, 2011, 8(1):74-88.
[7]Luo W, Xiang D. An efficient adaptive deadlock-free routing algorithm for torus networks [J]. IEEE Transactions on Parallel and Distributed Systems, 2012, 23(5): 800-808.
[8]Hervé MB, Moraes M, Almeidal P, et al. Functional test of mesh-based NoCs with deterministic routing: integrating the test of interconnects and routers [J]. Journal of Electronic Testing,2011, 27(5): 635-646.
