InfiniBand中面向有限多播表条目数的多播路由算法
2022-04-06陈淑平何王全漆锋滨
陈淑平 何王全 李 祎 漆锋滨
(国家并行计算机工程技术研究中心 北京 100190)
(chenshuping_hit@163.com)
多播是一种重要的集合操作,对高性能应用的性能具有重要的影响.它可以通过点对点消息实现,也可以通过专用的硬件实现.相比用点对点消息实现的多播,硬件支持的多播操作具有性能高、CPU占用率低等优点,正受到越来越多的关注.InfiniBand等高速互连网络中,硬件支持的多播操作通过构建多播树实现,树的高度、路由的负载均衡程度等对多播消息的性能具有至关重要的影响.过去的研究中,主要关注于降低树高、提升路由负载均衡程度.
随着超级计算机系统规模的不断扩大,多播组的个数急剧增加,可能会超过硬件支持的多播表(multicast forwarding table, MFT)条目数,而现有的多播路由算法没有给出相应的解决方案.为此,本文提出一种面向有限多播表条目数的多播路由算法,在硬件仅支持很小的多播表时,能够支持创建数千甚至数万个多播组.本文主要贡献有2个方面:
1) 提出了面向有限多播表条目数的多播路由算法MR4LMS(multicast routing for limited MFT size),仅需较小的多播表就可支持数千甚至数万个多播组,并尽量降低多播树高度及链路EFI(edge forwarding index).
2) 在多种典型拓扑结构及典型通信模式下对MR4LMS的链路EFI、运行时间等进行了测试,获得了令人满意的性能开销,表明MR4LMS可用于大规模互连网络系统.
1 背景及相关工作
目前,超级计算机系统的规模越来越大,拥有的处理器数及核心数越来越多.例如2020年6月全球Top500排名第一的Fugaku系统[1-2]拥有7 299 072个核心.与之相应,高性能计算应用的性能越来越依赖于互连网络系统的性能,尤其是集合通信的性能[3-4].集合通信包括广播、同步、规约、scatter、gather等类型及其变体,可实现多个进程间的同步、数据分发与收集等功能,对高性能计算应用的性能至关重要.最新研究表明,集合通信在消息通信中所占的比例越来越大.Chunduri等人[5]对IBM BG/Q Mira中MPI调用次数及时间开销进行了研究,发现集合通信时间开销约占消息通信总时间开销的2/3.因此,如何优化集合操作的性能成为高性能互连网络研究的一个热点.
集合通信可以通过点对点消息实现,也可以通过专用的硬件集合操作实现.很长一段时间以来,无论是在广域网还是在数据中心网络中,硬件支持的集合操作由于其复杂度、可扩展性、容错等方面的原因,并未得到广泛应用.例如,MPICH,MVAPICH, OpenMPI等[6-9]虽然也针对不同互连网络提供了硬件版本的集合操作,但大部分用户仍然选择使用点到点版本的集合通信.
但是,基于点到点消息实现的集合操作,其性能与硬件支持的集合操作相比存在不小差距.一是同一数据包在很多链路上会传输多次,造成资源浪费.二是由于缺乏获取底层网络拓扑信息的能力,集合操作的逻辑结构不能适配底层网络的物理结构,导致其无法充分利用底层网络的传输能力.随着系统规模的不断扩大,以软件方式实现的集合操作面临越来越严重的性能问题;而硬件支持的集合操作具有性能高、CPU占用率低等优点,正受到越来越多的关注.近几年出现了很多硬件集合通信技术,如Mellanox的SHARP技术[10].

Fig. 1 Illustration for multicast tree图1 多播树示意图
硬件支持的集合操作中,多播技术是重要的支撑.集合通信中的广播、同步、全局规约、AllGather等操作需要将相同的数据分发给参与集合通信的不同进程,它们均可通过硬件支持的多播进行加速.多播消息性能对这些集合操作的性能具有重要影响.
InfiniBand网络中,OpenSM负责生成多播路由,基本原理是构建1棵多播树覆盖参与多播操作的所有节点.用户根据需要创建很多个多播组,OpenSM为每个多播组构建1棵多播树,并占用多播路由表的1个条目号.多播组的1个成员向其他成员进行多播操作时,数据包沿着多播树进行传输.例如,在图1所示的多播组中,阴影所示节点发送多播包时,每到达1个交换机,就查询该多播组对应的多播表条目,以决定将数据包从哪些端口分发出去.
OpenSM目前支持MINIHOP,UP/DN,DN/UP,FTREE,LASH[11-12],DOR,TORUS-2QoS,NUE[13],DFSSSP[14-15]这9种路由引擎.它们使用的多播路由算法概括起来分为2类,分别是MINIHOP-MC及SSSP-MC.两者都是从树根开始自上而下构建多播树,区别在于MINIHOP-MC是基于最小跳表(minihop table)构建多播树,而SSSP-MC是基于单源最短路径(single source shortest path)构建多播树.两者各有优缺点:MINIHOP-MC运行速度快,但路由均衡性较差;SSSP-MC具有良好的路由均衡性,但运行时间长.
InfiniBand规范[16]规定每个子网最多支持16 384个多播表条目.由此带来的问题是:随着系统规模的不断扩大,系统中多播组的个数也急剧增加,可能会超过硬件支持的多播表条目数.很多情况下,多播表条目数不能满足应用程序的需要,原因包括:
1) 不同厂商的交换机支持的多播表条目数是不同的,有些厂商仅支持少量的多播条目数,以降低硬件成本及功耗.
2) 随着系统规模的不断扩大,应用程序需要创建的多播组个数急剧增加,可能会超过16 384.例如,当应用程序规模达到262 144个进程时,若将这些进程组织成256×32×32的3维网格结构,为每个维度中每行都创建1个多播组,则共需17 408个多播组,已经超过了InfiniBand支持的最大多播组个数.
OpenSM中现有的多播路由算法均默认多播表条目数是够用的,因此没有给出当多播表条目数不足时构建多播表的方案.本文提出一种面向有限多播表条目数的多播路由算法,在硬件仅支持很小的多播表时,能够支持创建数千甚至数万个多播组.
2 定义及假设
2.1 基本概念
定义1.互连网络.互连网络是1个有向图I=G(N,C),其中N为网络节点集合,C为通信链路集合.网络节点又分为终端及交换机.终端一般是网卡设备,用于收发数据;而交换机用于转发数据.
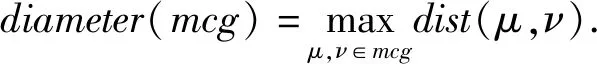
定义3.多播树.多播树(multicast tree, MCT)是互连网络有向图的连通子图,对应互连网络中的1棵树.该树内的1个节点发送数据时,会复制到该树内的所有节点中.为了实现多播功能,多播组必须映射到1棵多播树中.1个多播组对应1棵多播树,但1棵多播树可供多个多播组使用.
定义4.多播表条目号.InfiniBand进行路由时利用LID(local identification)进行寻址.LID是16 b长度的标识符,其构成的地址空间中,前49 152个用于单播路由,每个对应子网中的1个节点,例如交换机、网卡等;后16 384个用于多播路由,称为MLID(multicast identification),每个对应多播表中的1个条目.每个多播表条目都是1个位图,每位对应1个交换机端口.
用户在发送多播消息时,需同时指定目的MGID及目的MLID.多播数据包中包含MGID及MLID字段.当多播数据包在网络中传输时,交换机以MLID为索引查找对应的多播表条目,并将多播包复制到不同端口;而终端在收到多播包后,由于记录了每个MGID包含哪些QP (queue pair)等信息,可以根据MGID将多播数据包放入不同的QP.InfiniBand协议规定:必须为每个多播组指定1个MLID,但多个多播组可共用同一个MLID.
不同厂商支持的多播路由表条目数不同,例如Mellanox每个交换机中的多播表条目数为16 384,而有些厂商采用精简InfiniBand协议,仅支持少量的多播条目数.在本文中,多播表条目号与MLID含义相同,后文将交替使用这2个术语.
需要指出的是,InfiniBand规范及现有文献中,每个MLID仅能被1棵多播树使用.而本文提出的多播路由算法中,只要不经过相同的交换机,多棵多播树就可以共用同一个MLID,即占用同一个多播表条目号.
定义5.多播树的染色.需要为每棵多播树都分配1个多播表条目号.在不考虑多播表大小的情况下,可以为每棵多播树分配1个全局唯一的多播表条目号.而在考虑到多播表有大小限制时,需要重用多播表条目号.为多播树分配多播表条目号时,必须遵循2个原则:1)同一棵多播树在其使用的所有交换机内使用相同的多播表条目号;2)若2棵多播树经过同一个交换机,则这2棵多播树不能使用相同的多播表条目号.可以用术语“染色”来描述多播表条目号分配问题.构建1个图,将每棵多播树作为图的顶点;只要2棵多播树经过同一交换机,则称这2棵多播树“相邻”,对应的2个顶点间添加1条边.我们将多播表条目号用颜色表示,颜色的数量等于交换机内的多播表条目数.为“相邻”的多播树指定不同的多播表条目号,也即用不同的颜色染色.后文将用术语“染色”表示为多播树分配多播表条目号.
定义6.EFI(edge forwarding index).文献[17-18]定义了单播路由中的EFI指数.我们对此进行扩展,将链路的EFI定义为经过该链路的多播组个数.所有链路的最大EFI值一定程度上反映了路由均衡程度,值越大表示拥塞程度越高.最大EFI由拓扑结构、路由算法、通信模式等决定,对多播操作性能具有重要影响,因此需要尽量降低最大EFI.
定义7.TFI(tree forwarding index).每棵多播树的TFI定义为使用该多播树的多播组个数.该指标反映了多播树中多播数据包的冗余程度.多个多播组共用1棵多播树时,1个多播组发送的多播数据包会复制到其他多播组内(但不会被QP接收),造成资源浪费.
定义8.最小跳表.每个交换机都有1张最小跳表,逻辑上组织成2维表格形式,行号为i、列号为j的单元记录了从该交换机的端口j出发到LID为i的目标节点的最短路径长度.最小跳表是由OpenSM在拓扑探查阶段构建的.
为阐述定义1~8,以图2为例进行说明.

Fig. 2 Illustration for multicast groups图2 多播组示意图
1) 终端A,B组成1个多播组,MGID为ff00∷0001,其多播树包含A,B,sw1及它们之间的链路,使用0号多播表条目;
2) 终端C,D组成另一个多播组,MGID为ff00∷0002,其多播树包含C,D,sw2及它们之间的链路,由于该多播树与1)中多播树没有共同的交换机,因此也使用0号多播表条目;
3) 终端E,G组成又一个多播组,MGID为ff00∷0003,其多播树包含E,F,G,H,sw0,sw3,sw4及它们之间的链路,多播条目号仍为0;
4) 终端F,H组成另外一个多播组,MGID为ff00∷0004;它与MGID为ff00∷0003的多播组共用同一棵多播树.当ff00∷0003多播组内的成员发送数据时, ff00∷0004多播组内的网卡也会收到数据,但由于MGID不同,最终会删掉这些数据包.
2.2 影响多播性能的因素
多播操作的性能受多播树高度及链路EFI等的影响.仅考虑1个多播组时,多播树高度对集合操作性能至关重要.当网络中有多个多播组同时收发消息时,链路EFI对集合操作的性能也有重要影响.
2.2.1 多播树高度
多播树高度会影响多播消息的延迟.我们构建了如图3所示的实验环境,并进行了2组测试,每组测试均使用4个进程构成的多播组进行多播操作,但2组测试中的进程距离不同.第1组测试中,4个进程位于拓扑结构中临近的终端上,使用的多播树高度为1.第2组测试中,4个进程分散在拓扑结构中的不同位置,多播树高度为2.每组测试中各种消息长度均进行5 000次测试,分别计算平均延迟及99%消息尾延迟.其中99%消息尾延迟的计算方法为:对这5 000个消息的延迟进行排序,取末尾第4 950(5 000×99%)个消息的延迟.
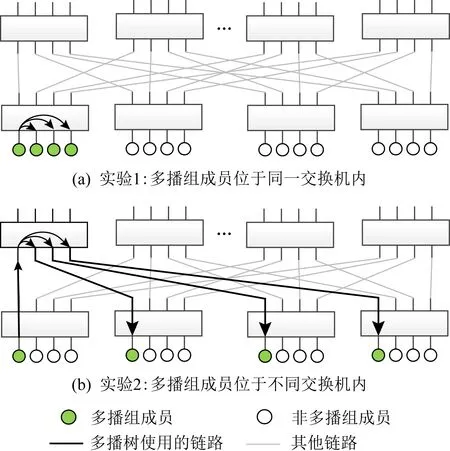
Fig. 3 Experimental environment for testing the effect of multicast tree height on multicast performance图3 用于测试多播树高度对多播性能影响的实验环境
测试结果如表1所示.对小消息来说,无论是平均值还是99%尾延迟都增长了约20%;对2 KB消息来说,增长幅度在15%左右.这是因为对长消息来说,增加的跳步数导致的时间开销相比数据拷贝的时间开销较小.可以预见,随着广播树高度的增大,延迟增加会更加明显.

Table1 Multicast Message Latency for Different Tree Height
2.2.2 链路EFI
如果有大量多播组经过同一条链路,则会对集合操作的性能造成影响.如图4所示,每4个相邻的终端节点组成1个多播组,但所有多播组都使用粗线所示的同一棵多播树,因此链路EFI等于创建的多播组的个数.例如,EFI=1,表示仅使用4个终端节点,创建1个多播组;EFI=128,表示使用512个终端节点,创建128个多播组.在这种情况下,1个多播组发送的数据会复制到使用同一多播树的其他多播组内.下面的实验分别测试了不同EFI下多播操作的延迟.每种EFI下均进行5 000次测试,分别计算平均延迟及99%消息尾延迟.
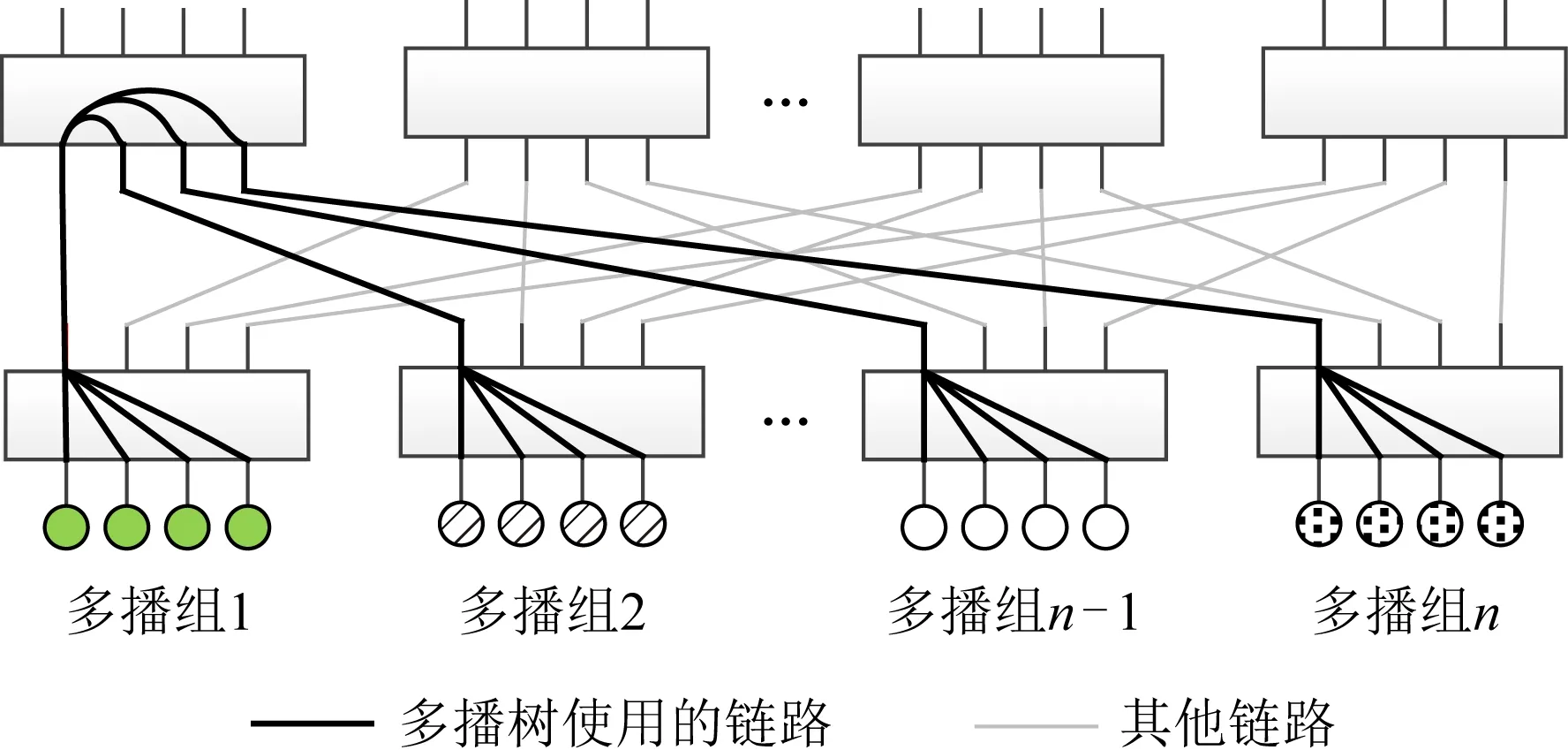
Fig. 4 Experimental environment for testing the effect of EFI on multicast performance图4 用于测试EFI对多播操作性能影响的实验环境
结果如表2所示.对8B长度的小消息来说,随着EFI的增加,延迟会略有增加,但是由于数据长度非常小,即使有多个广播组经过同一条链路,也不会对延迟造成很大影响.而对2 KB消息来说,由于数据较大,EFI增大带来的影响会比较明显.例如EFI=16时,平均延迟会增大约38%;EFI=128时,平均延迟会增大约1066%.这对大量使用广播操作的应用程序来说会带来不可忽视的性能影响.需要指出的是,在实际运行的课题中,共用同一条链路的多播组可能不会同时发送数据,此时EFI对多播消息性能的影响没有实验所示的这么明显.
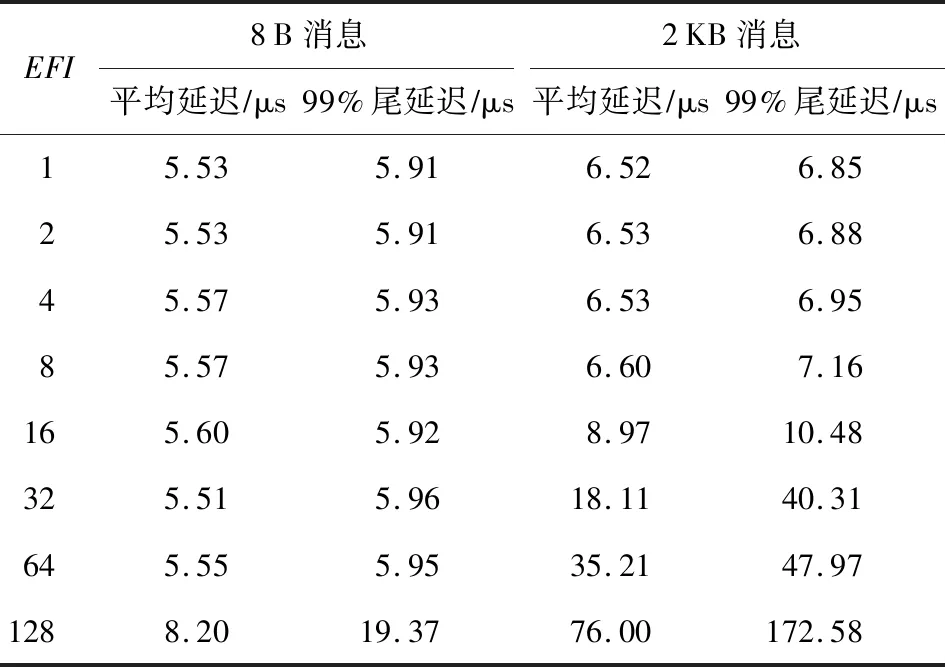
Table2 Multicast Message Latency for Different EFI
2.3 多播路由算法的设计目标
结合上面实验,我们列出多播路由算法的设计目标:1)满足硬件多播表条目数的限制;2)最小化多播树的高度,以降低多播消息延迟;3)最小化链路EFI,使不同多播组尽量分布到不同链路上,降低不同多播组间的相互干扰.给定一系列多播组,找出同时满足上述3个目标的多播路由是非常困难的,有时候这3个目标甚至是相互矛盾的.在实际的使用场景中,新创建1个多播组后,没有必要对已经存在的多播组重新计算路由,原因包括:1)重算路由的时间开销很大;2)如果重算路由,则可能导致新计算的路由跟原来的路由不一致,从而引起多播路由的暂时失效,进而引起丢包等问题.
考虑到多播组的实际使用场景,我们对上述目标进行排序:首先必须满足多播表条目数的限制,然后尽量降低多播树高度及EFI指数.以此为目标,我们提出了面向有限多播表条目数的多播路由算法MR4LMS.
3 面向有限多播表条目数的多播路由
当多播表条目数少于多播组个数时,我们有2种策略:1)构建合适的多播树,使它们使用不同的交换机,从而可以共用同一种颜色;2)使多个多播组共用1棵多播树,从而减少多播树数量.
我们提出了2种算法来构造多播树,并设计了开销模型从这2种算法中选择一种使用.我们还提出了多播组合并算法,在颜色数不足时将多个多播组合并成1个虚拟多播组.下面具体介绍这些算法.表3列出了MR4LMS使用的符号.

Table3 Symbols Used in MR4LMS
3.1 先构造后染色算法
先构造后染色算法(first build then color, FBTC)的基本原理是先构造1棵高度最低、所经过链路负载较轻的多播树,然后尝试用不同的颜色为其染色.如果染色不成功,则尝试用其他的交换机作为根构造1棵新的多播树.如果所有备选交换机都尝试了一遍仍不成功,则需要将该多播组合并到1个已存在的多播树中.详细过程见算法1.
算法1.FBTC算法.
输入:互连网络I=G(N,C)、多播组mcg;
输出:多播树mct.
① 遍历所有交换机,找出到mcg各成员最大跳步数最小的交换机作为备选树根,并按负载情况进行排序,存入rootList;
② for eachrootinrootList
③mct←build_mct_from_down_to_up(I,
root,mcg);
④color←color_mcast_tree(mct);
⑤ ifcolor是无效值 then
⑥ continue;
⑦ end if
⑧mcg.mct←mct;
⑨ 更新mct每条链路的权重;
⑩ 更新mct中每个交换机的多播路由表;
3.1.1 选择树根
算法1中行①代码用于找出所有可能的树根.树根的位置决定了多播树的高度,应该选择到多播组内各成员最大跳步数最小的交换机作为树根,以降低多播操作的延迟.根据各交换机的最小跳表,可以很容易地计算出每个交换机到多播组内各成员的最少跳步数,并找出其中的最大值,从而找到所有的备选树根.如果某个备选树根的多播组条目号已用完,则需要忽略该树根.当有多个备选树根时,可根据备选树根的负载情况进行排序,优先使用负载低的树根.在最坏情况下,其运行时间上限为O(|N|2).在超大规模互连网络中,可以利用多线程同时计算多个交换机的最大跳步数.
3.1.2 自底向上构建多播树
算法1中行③代码用于构建多播树.此时需要考虑负载均衡问题,也就是尽量使用负载低的链路.有2种方法可用于构建负载均衡的多播树.
1) 采用SSSP-MC使用的方法,以经过各链路的多播组个数作为权重,利用Dijkstra算法计算树根到所有节点的单源最短路径,从而构造出1棵树.其时间复杂度为Θ(|E|+|N|log|N|).该方法的缺点是不管多播组中有多少个成员,都需要遍历整个拓扑结构以构建1棵包括所有节点的生成树,因此其运行时间较长.
2) 基于最小跳表自底向上构建.选择树根后,每次从多播组的1个成员出发向树根前进.每次经过1个交换机选择下一跳时,都查询该交换机的最小跳表,选出到树根跳步最少的端口.如果有多个端口满足条件,则根据负载情况从中选择一条负载最轻的.该方法构建的多播树一定是路径最短的.其运行时间由多播组中成员数决定,在最坏情况下,运行时间上限为O(|E|+|N|).当多播组成员很少时,该方法比基于Dijkstra的方法快得多.
我们选择基于最小跳表的自底向上构建方法,过程如算法2所示.
算法2.build_mct_from_down_to_up.
输入:互连网络I=G(N,C)、多播组mcg、树根root;
输出:多播树mct.
① 对N中每个节点ω做初始化,ω.visited←
false,ω.parent←∅;
② for eachμ∈mcg.membersdo
③curr←μ;
④ whilecurr≠root且curr.visited≠true
do
⑤curr.visited←true,Q←∅;
⑥least_hop←curr.hops[root][0];
⑦ 依次检查curr的每个端口p,若curr.hops[root][p]==least_hop,则将该端口连接的远端节点ν加入队列Q;
⑧ 从Q中找出具有最小权重的节点ν*;
⑨curr.parent←ν*;
⑩curr←ν*;
/*开始构建多播树*/
3.1.3 为多播树染色
算法1中行④代码尝试为构建的多播树染色.依次尝试每种颜色,检查多播树中各交换机是否已经使用了该颜色.若是,则不能使用该颜色进行染色,需尝试下一种颜色.如果尝试了所有颜色仍不成功,则尝试其他交换机作为根.在最坏情况下,为1棵多播树染色,其运行时间上限为O(Ncolor×(|E|+|N|)),其中Ncolor为颜色数.FBTC算法在最坏情况下的运行时间上限为O(Ncolor×|N|×(|E|+|N|)+|N|2).
当为多播树找到一种可用的颜色后,算法1行⑨⑩用于更新各交换机的权重及多播表.如果尝试了所有的树根仍不能染色成功,则需要进行合并操作(见3.3节).
3.2 先染色后构造算法
FBTC算法在构造多播树时没有考虑目前的颜色使用情况.当可用的多播表条目很多时,可以快速构建出多播树;但当可用的多播表条目数较少时,构造出的多播树很可能染色失败,此时就需要尝试使用其他的树根.而在大规模互连网络中,能够作为备选树根的交换机有成千上万台,将所有交换机尝试一遍是非常费时的.尤其是当系统中已经存在大量多播组时,很可能尝试了所有树根仍不能染色成功,最终只能将该多播组合并到已有的多播组中,那么前面的所有尝试都是徒劳的.
如果在建立多播树的过程中,能够考虑到目前的颜色使用情况,则会提高染色成功的概率,避免盲目的尝试.先染色后构造算法(first color then build, FCTB)根据每种颜色的使用情况,先确定一种颜色,然后在该颜色下构建多播树.
首先引入Gcolor子图.每个交换机需要记录各颜色的使用情况,其中colorBusy[color]表示对应颜色是否已被使用,mcts[color]记录了使用该颜色的多播树.
对每种颜色color,我们都可以构造1个子图Gcolor,构造方法如下.以网络拓扑图G为基础,检查每条链路(μ,ν),如果符合下列条件之一,则将该链路从图中删除:
1)μ是交换机,ν是终端,μ.colorBusy[color]=1;
2)μ和ν均是交换机,μ.colorBusy[color]≠ν.colorBusy[color];
3)μ和ν均是交换机,μ.colorBusy[color]及ν.colorBusy[color]都是1,但μ.mcts[color]≠ν.mcts[color].
实际上Gcolor由2部分组成:1)使用该颜色的所有多播树包含的节点及链路;2)G中去掉使用该颜色的所有多播树包含的节点及其所有链路后剩余的部分.在具体实现中,可以不用单独存储每个Gcolor,后面描述的所有对Gcolor的操作,均可通过G及colorBusy位图实现.
先染色后构造算法具体过程见算法3.
算法3.FCTB算法.
输入:互连网络I=G(N,C)、多播组mcg;
输出:多播树mct.
① 利用算法1所述方法找出所有的备选树根;
② for 0到Ncolor-1范围内的每种color, do
③ 任选mcg的1个成员作为出发点,以广度优先搜索(breadth first search, BFS)在图Gcolor中进行遍历;
④ 若mcg某个成员在Gcolor中不可达,则尝试下一种颜色;
⑤ 对每个可达的树根root,以它为出发点在Gcolor中进行广度优先遍历,计算root到mcg各成员的跳步数,若在Gcolor中的最大跳步数大于在G中的最大跳步数,则尝试下一个树根;
⑥ 若找到了可用的颜色color及树根root,则跳到步骤⑨;
⑦ end for/*未找到可用的树根及颜色,需要与其他多播组合并*/
⑧ return NULL;
⑨mct←build_mct_by_dijkstra(I,mcg,
root,color);
⑩ 更新mct每条链路的权重;
3.2.1 选择颜色
算法3中行①找出所有可能的树根,方法与算法1行①完全一样.行②~⑦依次检查每种颜色下能否构建出高度最低的多播树.行③④首先利用广度优先搜索在Gcolor中进行遍历,检查多播组内各成员是否是连通的.如果不连通,则在该颜色下不可能构造出多播树,从而可以忽略该颜色;如果连通,则需要找到可用的树根.行⑤检查备选树根是否满足下列条件:1)该树根在Gcolor中是可达的,否则以它为根不能构造多播树;2)该树根在Gcolor中到多播组内各成员的最大距离不大于在G中到多播组内各成员的最大距离,否则构建出的多播树不是高度最优的.计算树根在Gcolor中到多播组各成员的最大距离时,只能使用广度优先搜索进行遍历,而不能直接使用最小跳表.若找不到合适的颜色及树根,则需要将该多播组跟其他多播组进行合并.需要指出的是,找出的连通子图,有可能是某棵已经创建好的多播树,此时新创建的多播组是该多播树的1个子集,可以直接使用该多播树.
FCTB需要执行多次广度优先遍历,时间开销较大.与FBTC一样,FCTB最坏情况下运行时间上限为O(Ncolor×|N|×(|E|+|N|)).但随着Gcolor中链路数逐渐减少,进行广度优先遍历的时间会大大减少.尤其是当系统中存在大量多播组时,对很多颜色来说,多播组成员在Gcolor中已不是连通的,从而可以节省后续检查时间,直接尝试其他颜色.
3.2.2 在Gcolor中构造多播树
当选择好颜色及树根后,我们必定可以在Gcolor中构造出1棵高度最低的多播树.此时只能使用Dijkstra算法(算法3行⑨),而不能使用3.1.2节提到的自底向上构建方法.原因是自底向上构建方法需要利用最小跳表,但最小跳表是基于图G构造的,不能用于Gcolor中构造多播树.另外,为Gcolor构造新的最小跳表时间开销很大,得不偿失.具体算法见3.3.2节算法5.
3.3 多播组合并算法
当多播组个数太多而无法成功染色时,需要合并1个或多个已经存在的多播组,形成1个大的虚拟多播组.
3.3.1 选择被合并的多播组
首先要确定需合并哪些多播组才能使新创建的多播组染色成功.被合并的多播组要尽量少,以降低链路EFI.分2个步骤确定被合并的多播组.
1) 从已存在的多播组中选出与新创建的多播组最相似者,并将两者合并.由于已存在的多播组已经染色,合并后的多播组只能使用被选中多播组的颜色,即color.在Gcolor中检查合并后的多播组是否是连通的,若是连通的,则无需再合并其他的多播组.
2) 若合并后的多播组是非连通的,则基于最小跳表为合并后的多播组自底向上构建1棵临时的多播树.然后在Gcolor中检查该临时多播树的每个交换机,若该颜色对应的多播表条目已被使用,则将使用该条目的所有多播组也合并到虚拟多播组中,从而保证虚拟多播组在Gcolor中是连通的.
步骤1中,如何选择最“相似”的多播组,对后续染色及多播性能具有重要影响.直观上看,2个节点距离越近越“相似”.受此启发,我们定义了多播组与多播树间的距离:
(1)
2个组(多播组或多播树)的距离定义为每个组中各成员到对方组中成员最短距离的均值.2个多播组的距离越近,则这2个多播组共用同一个交换机的可能性越高,两者合并后用同一种颜色染色成功的概率也越大.
上述过程实际上采用了2种策略选择被合并的多播组:首先使用乐观策略,选择1个最相似的多播组进行合并;如果合并后仍不能染色成功,则使用悲观策略,将所需的多个多播组同时合并到一起.实际上,我们也可以全部采用乐观策略:当第1次合并后仍不能染色成功时,则可以再选择1个与合并后多播组最相似的多播组继续合并,该过程一直重复,直到合并成功或将所有多播组合并到一起.我们未采用该方法的原因是:当系统中存在大量多播组时,可用的颜色数严重不足,可能需要进行多次合并才能染色成功,而每次合并都需利用式(1)计算“相似度”,时间开销很大.
经过上述2个步骤,我们获得1个包含多个多播组的虚拟多播组,称为vMcg(virtual MCG).伪代码描述的合并算法见算法4.
算法4.合并算法.
输入:互连网络I=G(N,C)、多播组mcg;
输出:多播树mct.
① 对I.existingMctList中的每棵多播树,都利用式(1)计算它与mcg的距离,找出具有最小距离的那棵多播树,记为mct1;
② 将mcg的成员与mct1合并,创建1个虚拟多播组vMcg;
③color←mct1.color;
④ 若vMcg的所有成员在Gcolor中是连通的,则跳到步骤;
/*需要合并其他多播组*/
⑤ 为vMcg选择1个树根roottmp;
⑥mct2←build_mct_from_down_to_up(I,
roottmp,vMcg);
⑦ for each switchswinmct2do
⑧ ifsw.colorBusy[color]==true
⑨ 将sw.mcts[color]与vMcg合并;
⑩ end if
/*在Gcolor中为vMcg构建多播树*/
root,color);
算法4行①计算所有多播树与新创建的多播组间的距离,最坏情况下耗时O(|N|3).为加快计算速度,可以用多线程同时计算.另外,当多播树个数很多时,根据式(1)计算距离的时间开销很大.此时可以采用另一种更简单高效的方式,即不再选择最“相似”的多播树进行合并,而是选择多播组数最少的那个Gcolor,然后直接从行⑤代码开始在Gcolor中合并所需的多播组.也就是不再尝试乐观策略,而是直接使用悲观策略选择所需合并的多播组.
3.3.2 利用Dijkstra构建多播树
合并后vMcg的成员在Gcolor中是连通的,为vMcg构建多播树的过程类似于FCTB算法.首先通过广度优先遍历计算各个交换机到vMcg各成员的最大距离,据此选择1个作为树根,然后利用Dijkstra算法在Gcolor中构造1棵树.为vMcg构建多播树时,需要考虑是否保留原有的多播树.我们有2种策略.
1) 销毁旧的多播树,为vMcg重新创建1棵多播树.由于需要为原有的多播组重新计算并更新路由,该方法可能会导致短暂的路由一致性问题,即在更新路由的过程中出现丢包等现象.此时需要由上层应用采用其他手段保证可靠传输.
2) 不销毁旧的多播树,而是在原多播树上通过添加枝叶形成1棵新的、更大的多播树,从而保证原来那些多播组不受影响.缺点是构建的多播树可能不是最优的.
我们同时支持这2种策略,用户可以通过环境变量选择一种.下面介绍第2种方法,伪代码见算法5.行②~④是标准的Dijkstra算法.行⑤~用于将旧的多播树链入新多播树.每处理完1个节点,就检查该节点是否在原多播树中.如果是,则从该节点出发,用广度优先遍历将原多播树中的所有节点及链路加入新产生的多播树中.
算法5.build_mct_by_dijkstra.
输入:互连网络I=G(N,C)、多播组mcg、树根root、颜色color、旧的多播树对应的图I′=G(N′,C′);
输出:多播树mct.
① 对N中每个节点ω做初始化,设置ω.parent←∅,ω.distance←∞,并设置root.dist←0,Q←N;
② whileQ≠∅ do
③ 在Q中找到具有最小dist的节点μ,并从Q中删除节点μ;
④ 在图Gcolor中检查μ的每条链路(μ,υ),若υ仍在Q中,且μ.dist+weight(e)<υ.dist,则设置υ.dist←μ.dist+weight(e),υ.parent←e;/*处理旧的多播树中的节点*/
⑤ ifμ∈N′
⑥QBFS←{μ};
⑦ whileQBFS≠∅ do
⑧ 取QBFS的首元素μ′,检查μ′的每条链路e=(μ′,υ′),若υ′不在Q中,则继续检查下一条链路;
⑨ 若e是旧的多播树中的链路,则设置υ′.dist←μ′.dist+weight(e),υ′.parent←e,并将υ′加到QBFS的队尾;
⑩ 若υ′不是旧多播树中的节点,且μ′.dist+weight(e)<υ′.dist,则设置υ′.dist←μ′.dist+weight(e),υ′.parent←e;
/*开始构建多播树*/
3.3.3 删除多播组
被删除的多播组可能跟其他多播组共用同一棵多播树,因此删除该多播组不能影响其他多播组的正常使用.首先将待删除多播组中的成员从多播树中删掉,然后递归检查多播树中剩余交换机.若该交换机仅有1个上行端口连接到多播树的上一层,而所有下行端口都是空的,则从多播树中删除该交换机.伪代码见算法6.
算法6.从多播树中删除1个多播组.
输入:多播树mct、多播组mcg.
① 初始化1个空队列Q;
② 将mcg的每个成员从mct中删掉;
③ 检查mct中的每个交换机,若它的下行链路均不在mct中,则将该交换机加入Q;
④ whileQ≠∅ do
⑤ 取Q的首元素sw,并将sw从mct中删除;
⑥ 依次检查sw上行端口连接的交换机υ,若υ在mct中,且下行链路均不在mct中,则将该交换机加入Q;
⑦ end while
3.4 时间开销模型及算法选择

由于不能精确测量各部分开销,上述开销模型仅能用于定性分析.直观上看,我们采用2种启发式:
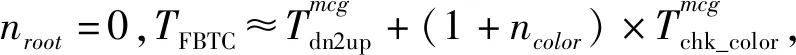
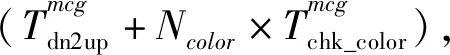

Fig. 5 Algorithm selection policy图5 算法选择策略
我们采用如图5所示的策略在FBTC和FCTB中进行选择:初始化时使用FBTC算法;一旦FBTC染色失败,则下一次构建多播表时切换为FCTB算法;在使用FCTB算法时,不需要合并而能够连续成功的次数超过某预设阈值(例如20次),则切换回FBTC算法.伪代码描述的算法见算法7.
算法7.MR4LMS算法.
输入:互连网络I=G(N,C)、多播组mcg、当前路由算法current_alg;
输出:多播树mct.
① ifcurrent_alg为FBTC then
②mct←FBTC(I,mcg);
③ 若失败,则设置current_alg为FCTB;
④ else
⑤mct←FCTB(I,mcg);
⑥ 若成功,且连续成功的次数达到20,则设置current_alg为FBTC;
⑦ end if
⑧ 若mct创建失败,则利用算法4创建mct;
⑨ returnmct.
4 实现及实验评估
4.1 实 现
我们在OpenSM 3.3.22中实现了MR4LMS,共有约5 000行代码.为了支持多棵多播树共用1个多播表条目号,我们对OpenSM源码进行了修改,包括为每棵多播树(OpenSM中称为mbox)添加color字段,用户在发送多播消息时指定的不再是MLID,而是该color值.
另外,我们还对加入、离开多播组的机制进行了简单的修改,以解决频繁重算路由的问题.加入多播组时,不是每收到1个加入多播组的请求就重算路由,而是等收齐同一个多播组的所有请求之后再计算路由.1个成员离开多播组后,也不重算路由;仅当所有成员均离开后,再删掉该多播组.
为了提升运行速度,我们在很多地方使用了多线程进行加速,包括:1)利用式(1)计算2个多播组间的距离时;2)计算各交换机到多播组内各成员最大距离时;3)在Gcolor内进行广度优先搜索时.
4.2 实验环境
我们使用ibsim-0.7[19]模拟各种网络拓扑;使用测试程序模拟发起加入或离开多播组的请求.OpenSM运行在1台48核Intel Xeon E5-2680 v3服务器上,频率为2.50 GHz.需要指出的是,在ibsim下的测试结果跟在真实网络环境下的测试结果是一样的,因为后面测试的EFI及运行时间等性能数据跟是否使用ibsim模拟拓扑结构无关.
4.2.1 拓扑结构
我们将在不同拓扑结构下对MR4LMS的性能进行测试,包括2个超算中心使用的拓扑,以及几种典型的人造拓扑结构(包括标准胖树[20-21]、3D环网、蜻蜓网络[22]等).
1) 超算中心的拓扑结构
我们利用ibnetdiscover获得了2个超算中心的网络拓扑结构,包括“神威蓝光”计算机及“神威太湖之光”计算机.“神威蓝光”计算机[23]安装于济南超算中心,包含8 704个运算处理器,采用裁剪胖树结构[24],每个叶子交换机与最顶层交换机间都有8条路径.“神威太湖之光”计算机[25-26]安装于无锡超算中心,包含40 960个运算处理器,是目前世界上规模最大的InfiniBand网络,其结构与“神威蓝光”类似,但规模更大,每个叶子交换机与最顶层交换机间都有2条路径.
2) 典型的人造拓扑结构
包括4种拓扑:
① 3层胖树.采用40端口交换机构建标准3层胖树结构,终端个数N=16 000.
② 3D -Torus.构造了30×20×20的3D -Torus网络,每个交换机连接2个终端,终端个数为N=24 000.
③ 蜻蜓网络.配置参数为a=18,p=h=9,终端个数N=26 406.
④ 随机网络.共2 048台40口交换机,每台交换机20个端口连接网卡,另外20个端口随机连接到其他交换机端口,终端个数为N=40 960.
4.2.2 通信模式
MPI集合通信中,主要有2种通信域划分方法[27-28]:1)划分成2维或3维网格,其每个维度中每行或每列都是1个通信域,对应1个多播组.2)划分成层次结构,例如树型结构,每层分成很多组,每个组构成1个通信域;每个组再选出1个leader,形成更高层次的组.划分成网格时,通信域内的成员数较少,但通信域的个数很多,对多播表条目数的需求量更大.后面实验中,我们采用2维及3维网格划分进程,以测试存在大量多播组时多播路由算法的性能.对每种拓扑结构,我们都测试了多种典型的通信模式,包括2维及3维网格模式,以及随机加入多播组的模式.
在多核及众核编程模型中,每个处理器上可运行多个进程.一般采用混合编程模型,如MPI+OpenMP等.位于同一处理器上的进程可以建立1个独立的通信域.每个处理器中选出1个leader用于在处理器间进行通信.我们的实验中,既测试了每个终端运行1个进程的情况,也测试了每个终端运行多个进程的情况.
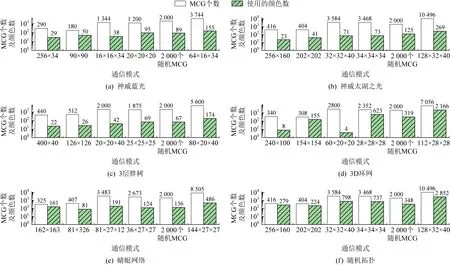
Fig. 6 Counts of MCGs and colors for different topologies and communication patters图6 不同拓扑和通信模式下的多播组个数及所需颜色数
需要指出的是,FBTC及FCTB算法在选择树根时,仅考虑了那些到多播组内各成员最大距离最小的交换机作为备选树根,因此构造出的多播树高度是最低的;而合并算法也优先考虑到多播组内各成员最大距离小的交换机作为树根.因此,影响多播性能的2个因素中,我们仅测试最大链路EFI,而不再关注多播树高度.
4.3 无合并时所需的颜色数
MR4LMS中,只要2棵多播树不使用同一个交换机,它们就可以共用同一个多播表条目号,从而使所需的多播表条目数少于多播组个数.对每种拓扑结构,我们都通过实验测试MR4LMS算法在典型通信模式下所需的多播表条目数,并据此为每种拓扑结构选择1个合理的Ncolor值.我们测试了6种典型的通信模式,包括2种2维网格结构,该模式下每个终端运行1个进程;2种3维网格结构,每个终端运行1个进程; 1种随机多播组模式,每个终端运行1个进程;1种3维网格结构,每个终端运行4个进程.
测试最后2种通信模式的目的是观察MR4LMS在创建大量多播组时的性能;实际应用课题一般不采用这2种通信模式.前面4种2维或3维网格模式中,有些是按拓扑结构进行划分,模拟拓扑感知的通信模式[27-28];有些划分成正方形或立方体形状,模拟拓扑无感的通信模式.以神威蓝光为例,256×34通信模式下,第1维有34个多播组,每个组都位于同一个运算中板内,因此通信模式与拓扑结构匹配.而90×90通信模式下,存在很多跨运算中板的多播组,因此通信模式与拓扑结构不匹配.
测试结果如图6所示,图6(a)~(c)分别是神威蓝光、神威太湖之光以及3层标准胖树结构下的测试结果.存在下列现象:
1) 使用的颜色数远低于多播组的个数.例如,神威太湖之光中,128×32×40通信模式下,创建了10 496个多播组,仅使用了269种颜色.这是因为胖树及裁剪胖树中有大量冗余路径,多播组可以分布到不同的冗余路径上,从而可以尽量使用相同的颜色.
2) 大部分通信模式下,所需的颜色数少于128.因此,在这3种拓扑结构中,Ncolor=128对大部分多播通信模式来说是够用的.
3) 通信模式是否与底层拓扑结构匹配,对所需的颜色数影响不大.例如,图6(a)中256×34模式需要29种颜色,而90×90需要50种颜色,没有剧烈增加.
图6(d)显示了3D环网下的测试结果.3D环网中虽然也有很多冗余路径,但这些冗余路径有共用的交换机,因此很多MCG需要经过相同的链路,导致所需的颜色数较大.当通信模式与拓扑结构匹配时(例如240×100,60×20×20),所需颜色数很少.当通信模式与拓扑结构不匹配时,所需颜色数较大,最大达到了2166.图6(e)(f)分别显示了蜻蜓网络和随机网络下的测试结果.与3D环网一样,由于互不干扰的冗余路径较少,这2种拓扑结构下所需的颜色数也较大,最大分别为486,2852.
4.4 无合并时的最大EFI
本节将测试无合并时MR4LMS算法的最大EFI,与MINIHOP-MC及SSSP-MC多播路由算法进行比较,结果如图7所示.可以发现,大部分情况下MR4LMS算法的EFI明显低于MINIHOP-MC算法,而与SSSP-MC算法基本相当.MINIHOP-MC的EFI较大的原因是,它没有考虑多个多播组间的负载均衡问题,因此多个多播组可能共用同一条链路.该测试结果表明,MR4LMS产生的多播表,其性能高于MINIHOP-MC,而与SSSP-MC基本相当.
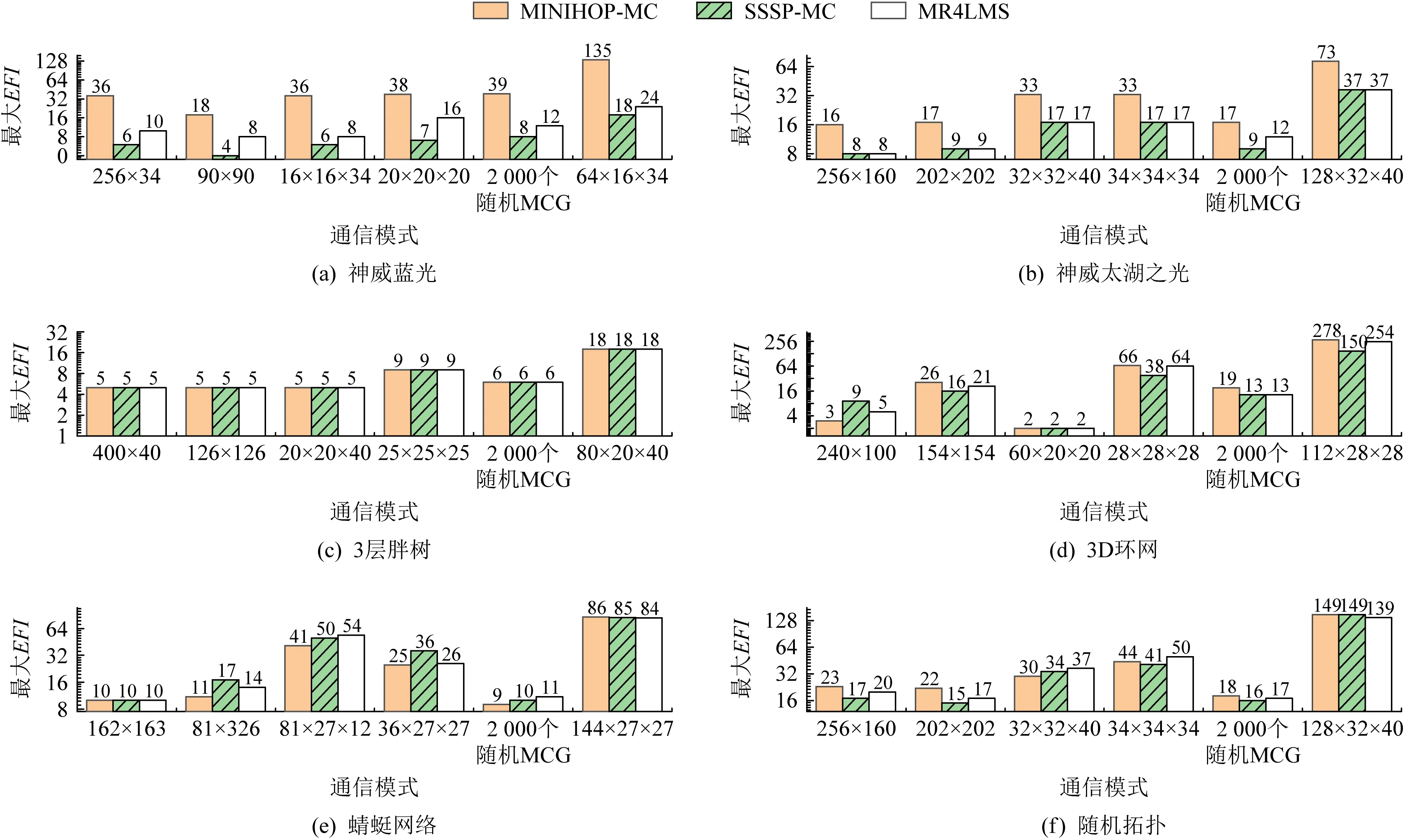
Fig. 7 Maximum EFI for different algorithms图7 不同算法的最大EFI
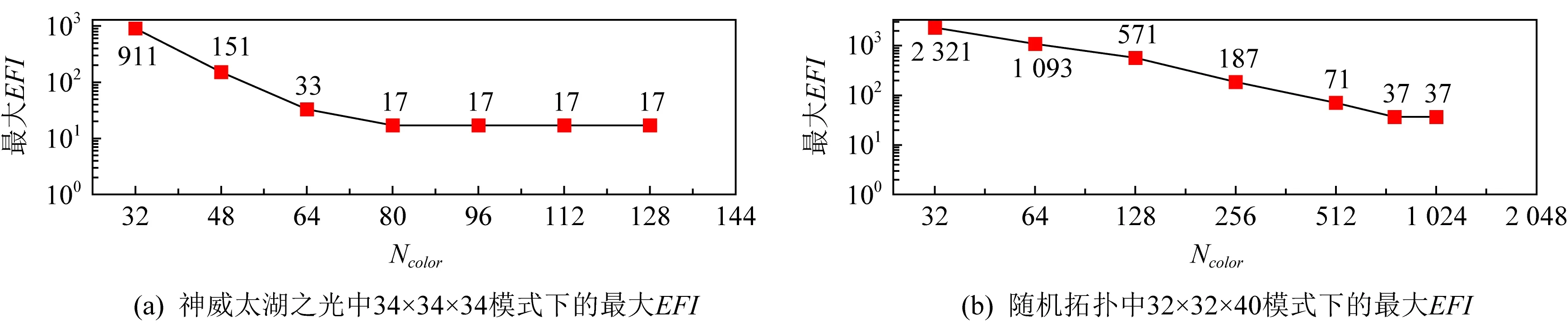
Fig. 8 Maximum EFI for different Ncolor图8 不同Ncolor下的最大EFI
4.5 合并算法有效性测试
合并多播组会导致链路EFI升高,影响多播消息性能.图8显示了2种通信模式下不同Ncolor的最大EFI变化情况:1)神威太湖之光下的34×34×34通信模式;2)随机网络下的32×32×40通信模式.可以发现,如果将Ncolor设成较小的值,会导致最大EFI变的很大,对多播消息性能造成影响.
我们为上述6种拓扑结构采用如表4所示的Ncolor配置,并测试各种通信模式下的最大EFI及TFI,以检验这些Ncolor是否合理.对其他拓扑结构及网络规模,也可以采用类似方法:先确定其典型的通信模式,并通过实验确定1个合适的Ncolor,使得大部分通信模式下Ncolor是够用的,或合并后EFI没有显著增加,从而在多播表大小与多播消息性能间进行适当的平衡.

Table4 Ncolor Used in MR4LMS
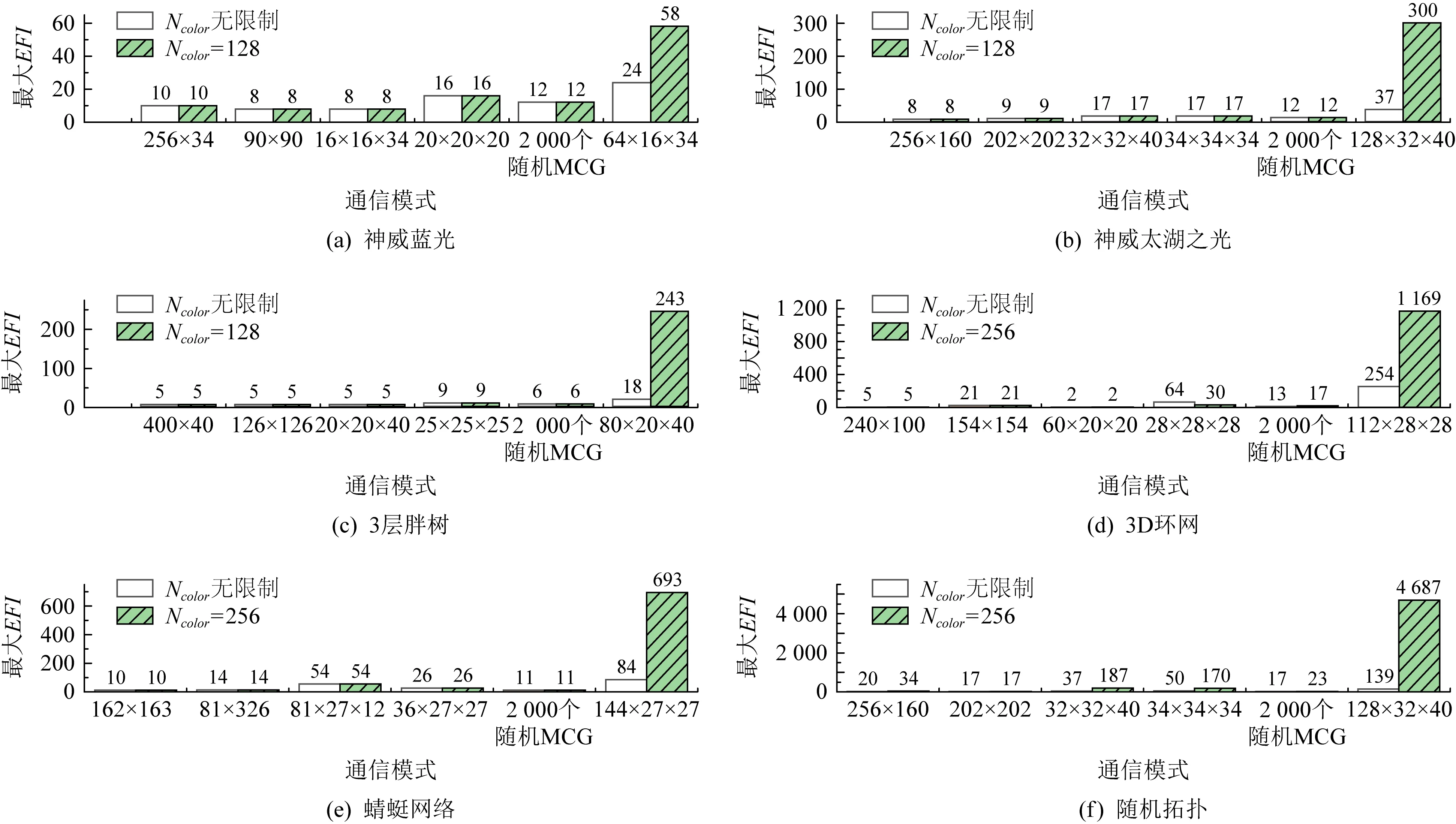
Fig. 9 Maximum EFI for the recommended Ncolor图9 推荐Ncolor下的最大EFI
4.5.1 推荐Ncolor下的EFI
本节将测试推荐Ncolor下的最大EFI.对每种拓扑结构,我们都进行2组对比实验:1)将Ncolor设为无穷大,从而保证不会发生合并;2)测试推荐的Ncolor.每组测试都分别记录各通信模式下的最大EFI,结果如图9所示.存在下列现象:
1) 大部分通信模式下,由于颜色数够用,不需要合并多播组,最大EFI也较小,一般低于50,这表明2种构造多播树的方法具有良好的负载均衡性,能够将多播组分布到不同链路上.
2) 少量通信模式下,由于颜色数不够用,需要合并多播组,其中一部分通信模式合并后EFI与无合并时相比并无显著增加.例如,在神威蓝光下,Ncolor=128时仅64×16×34模式下需要合并多播组,最大EFI由无合并时的24增加到58;随机网络拓扑中,Ncolor=256时256×160模式下需要合并多播组,最大EFI由无合并时的20增加到34.
3) 还有一部分通信模式,合并后EFI显著增大.例如,在神威太湖之光中,128×32×40模式下最大EFI由无合并时的37增加到300;在随机拓扑中,128×32×40模式下最大EFI由无合并时的139增加到4 687.最大EFI剧烈增加的情况基本都出现在每个处理器运行4个进程的通信模式下.这是因为每个处理器上有4个进程时,每个交换机上多播组的个数显著增加.例如在胖树结构中,原来每个处理器上仅有1个进程时,每个叶子交换机上仅有20个进程,在3维网格通信模式下,最多需要60个多播组(实际上不需要这么多多播组,因为有些进程可能位于同一个多播组内).而当每个处理器上有4个进程时,每个叶子交换机上有80个进程,在3维网格通信模式下,最多需要240个多播组,导致多播组的个数超过交换机支持的多播表条目数,因此需要进行很多多播组合并操作.
在实际应用场景中,很少会遇到这样的通信模式,因为当1个处理器上运行多个进程时,用户一般会为它们建立1个单独的通信域用于处理器内的集合通信,并从中选择一个作为leader用于处理器间的集合通信.
4) 3D环网中,28×28×28通信模式下,Ncolor=256时的最大EFI反而低于Ncolor无限制时.这是因为在颜色数足够时,FBTC算法在尝试第1个树根时总会成功,而它采用贪心策略根据局部信息进行负载均衡,有可能产生非最优的解,也即产生最大EFI非最小的多播树.
综上所述,我们选择的Ncolor对大部分通信模式来说,不需要合并多播组;部分通信模式需要合并多播组,但合并后EFI没有显著增加,因此不会对多播消息性能带来严重影响;极少数需要创建超过1万个多播组的情况,合并后EFI可能会显著增加,但用户使用该类通信模式的情况较少.
4.5.2 推荐Ncolor下的TFI
最大TFI反映了有多少个多播组共用1棵多播树.TFI越小越好;当没有合并发生时,TFI=1.本节将测试推荐Ncolor下的最大TFI,以进一步观察多播组的合并情况,检查是否存在大量多播组合并到同一棵多播树的情况.我们统计了每种通信模式下的最大TFI,测试结果如图10所示.可以发现,每个处理器上运行1个进程的通信模式中,TFI最大为10,表明最多有10个多播组共用1棵多播树.而在每个处理器上运行4个进程的通信模式中,TFI最大为66.
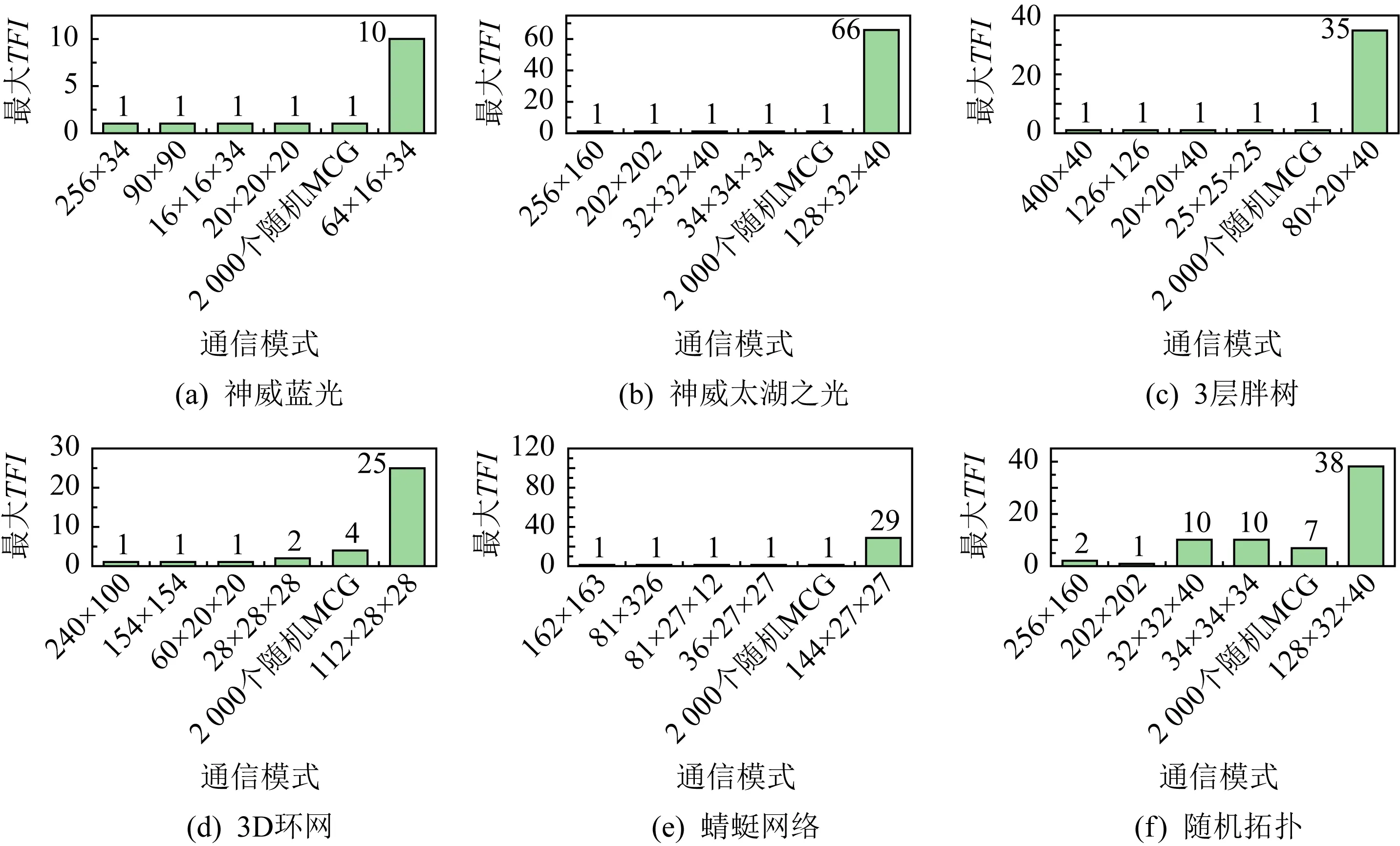
Fig. 10 Maximum TFI for the recommended Ncolor图10 推荐Ncolor下的最大TFI
除了测试TFI指标,我们还记录了每种颜色下的多播树及多播组个数信息.不同拓扑结构、不同通信模式下测试结果会有差异.图11显示了神威太湖之光中Ncolor=128时,128×32×40模式下各颜色下的多播树及多播组个数.该模式下共创建10 496个多播组,最大TFI为66,平均TFI为1.36.可以发现下列现象:1)多播组在各颜色下分布比较均衡;2)阴影标记的颜色下,某些多播组发生了合并;3)有8种颜色下,各有66个多播组,但被合并成了1个虚拟多播组,共用1棵多播树.可以预见,随着多播组个数的增加,合并情况会进一步加剧,严重时可能每种颜色下都只有1棵超级多播树存在.
上述实验表明:MR4LMS在合并多播组时,能够较均匀地选择多播条目号,从而使每个多播条目号下多播组个数大体相等,而不是将所有多播组合并成1棵包含所有节点的多播树.
4.6 算法运行时间
超大规模互连网络中可能存在大量多播组,多播路由算法需要在较短的时间内完成多播路由的计算.本节将对MR4LMS计算多播路由的时间进行测试.
对每种拓扑结构,我们都进行2组对比实验:1)将Ncolor设为无穷大,从而保证不会发生合并;2)测试推荐的Ncolor,分别记录各通信模式下MR4LMS的运行时间.测试结果如图12所示.该时间仅包括计算路由的时间(包括选择树根、构建多播树、为多播树染色),不包括发送加入多播组请求、分发路由等其他步骤的开销.存在3种现象:
1) 算法运行时间跟创建的多播组个数有关,胖树结构、蜻蜓网络平均约5 ms创建1个多播组,3D -Torus、随机网络平均约9 ms创建1个多播组.
2) 除去每个处理器上运行4个进程的通信模式,最长运行时间为40.6 s.每个处理器上运行4个进程的通信模式下,Ncolor无限制时,最长运行时间为48.0 s;推荐Ncolor下,最长运行时间为191.5 s,均在可接受的范围内.
3) 每种通信模式下,推荐Ncolor下的运行时间与Ncolor无限制时相比,最多增加3倍.某些通信模式下,时间开销增加较大,原因是颜色数不够时,需要花费更多的时间在Gcolor中进行广度优先搜索,以及进行合并操作.
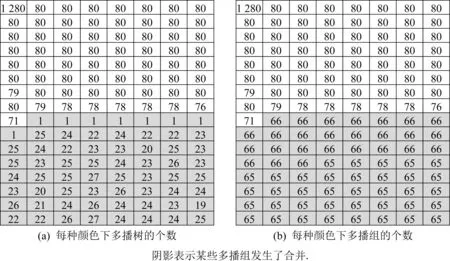
Fig. 11 Count of MCT and MCG for each color图11 每种颜色下的MCT及MCG数
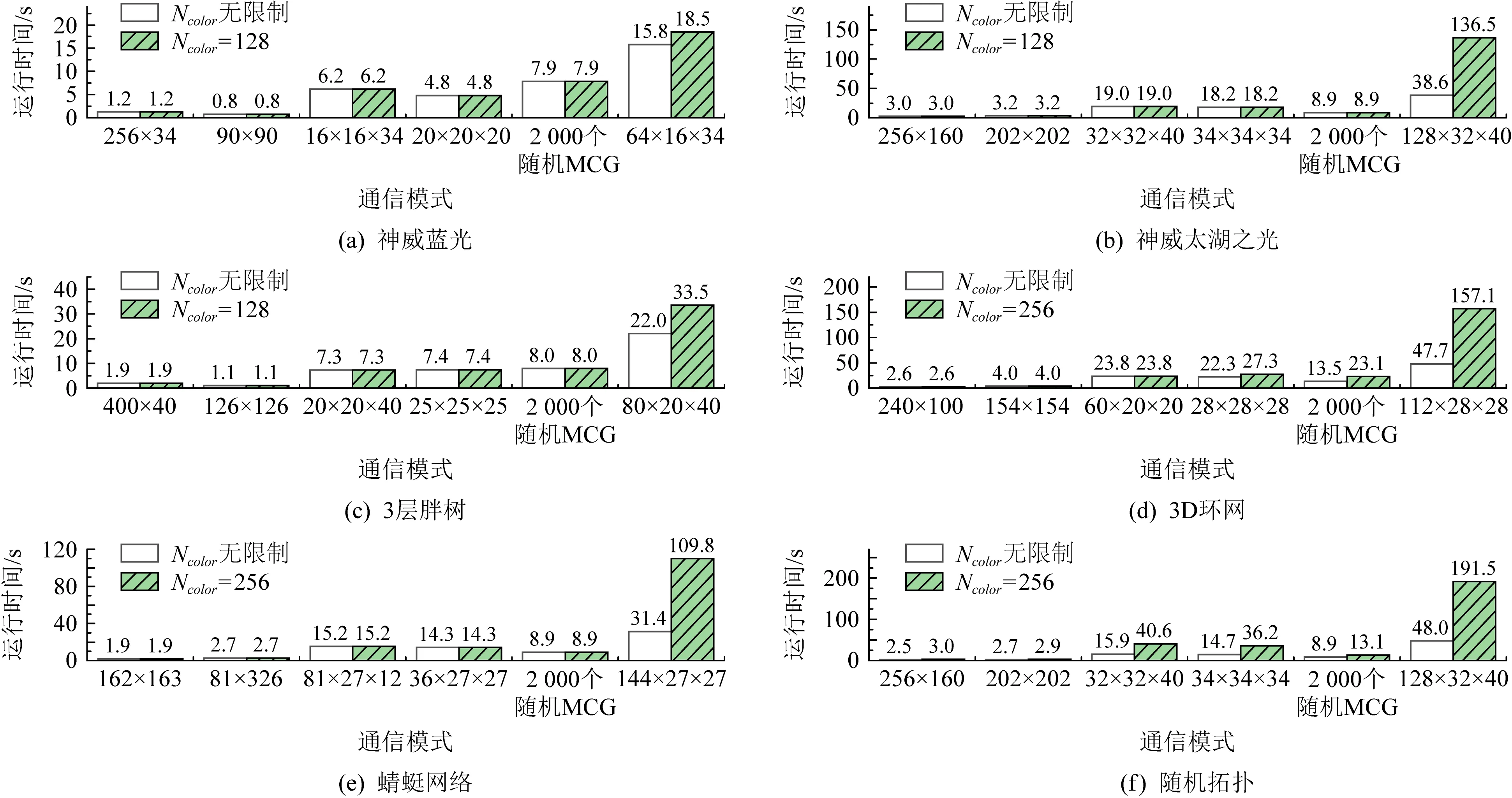
Fig. 12 Runtime of MR4LMS图12 MR4LMS的运行时间
4.7 讨 论
本节将从运行时间、适用范围等方面对MR4LMS算法进行进一步的讨论.
1) 运行时间
大部分应用中,各通信域划分好之后一般不会频繁变动,因此仅在应用程序初始化阶段才需要创建多播组.对那些运行时间超过数小时、甚至数天的应用而言,利用MR4LMS创建多播组的时间一般不超过数十秒,因此MR4LMS的运行时间并不会对应用性能带来严重影响.
当然,当网络拓扑或通信域划分方式频繁变动而需要重算多播路由时,MR4LMS算法的时间开销会给应用程序的性能带来不可忽略的影响.下一步我们将继续对MR4LMS算法进行改进以降低其运行时间,一种可行的思路是针对特定的拓扑结构进行相应优化.
2) 适用范围
MR4LMS并不针对特定的网络拓扑结构.我们在胖树、3D环网、蜻蜓网络、随机网络等常见网络中测试了该算法的性能,都能够获得不错的EFI指标.但该算法并不适用于动态可配置的网络,如光开关控制的网络,因为这些网络的拓扑结构会频繁变动,导致需要频繁计算多播路由;而MR4LMS的运行时间较长,频繁计算多播路由会对应用性能带来影响.
另外,MR4LMS算法适用范围不仅仅局限于InfiniBand,也可用于其他高速互连网络.这需要互连网络提供下列支持:首先该互连网络必须为集合操作提供相应的硬件支持;其次,该互连网络要允许多播链号在同一时刻分配给多个多播组使用,从而允许用户向不同多播组发送消息时可以使用同一个多播链号.
需要指出的是,InfiniBand中每个交换机所有端口共用1份路由表;如果采用每个端口都有1份路由表的设计,则可以进一步降低所需颜色数及链路EFI指数.
5 结 论
本文提出一种面向有限多播表条目数的多播路由算法,在硬件仅支持很小的多播表时,能够支持创建数千甚至数万个多播组.我们采用2种策略来达到此目的:1)构建合适的多播树,使它们使用不同的交换机,从而可以共用同一种颜色;2)使多个多播组共用1棵多播树,从而减少多播树数量.
我们对MR4LMS进行了大量测试,结果表明,通过维护1个较小的多播表即可满足大部分通信模式的需求,从而可以降低硬件设计复杂度,降低功耗及成本.对极少数需要创建大量多播组的情况,通过合并多播组,以牺牲少量性能的代价,满足其需求.我们还对MR4LMS的运行时间进行了测试,结果表明其运行时间在可接受的范围内,能够满足大规模并行应用的需求.
下一步我们将对MR4LMS算法做进一步的改进,优化其时间开销及存储开销.同时,我们还需要对MR4LMS在真实应用课题中的性能进行更全面的评价.
作者贡献声明:陈淑平提出研究思路,设计并实现算法,进行试验并对实验数据进行分析,撰写并修改论文;何王全参与实验数据分析、论文审阅修订;李祎参与算法实现、实验验证、数据分析、论文修订;漆锋滨负责课题监管与指导、论文审阅与修订.
