C4.5 算法在未知恶意代码识别中的应用
2013-11-12朱立军徐玉芬
朱立军,徐玉芬
(1.沈阳化工大学 计算机科学与技术学院,辽宁 沈阳 110142;2.辽宁兵器工业职工大学,辽宁 沈阳 110045)
目前,主流杀毒软件采用的技术是特征码技术,其原理是在待检测文件中查找二进制代码特征,如果与既有特征码相匹配就判定为病毒程序.其优点是能快速、准确地检测出已知恶意代码;缺点是对变种及未知恶意代码无能为力.文献[1-2]已经证明对计算机病毒的检测不可判定.因此,目前对于未知恶意代码的识别,就是采用近似算法,包括两类:(1)静态启发式扫描技术.其原理是在代码不运行时,通过分析代码中的特征序列来识别恶意代码的方法,如文献[3]通过分析可执行文件静态调用的API 序列来识别已知恶意代码的变种,它的依据是恶意代码和它的变种一定有足够多相似的API 调用序列.文献[4]是提取已知恶意代码中的特征字节序列,采用多重贝叶斯算法建立分类模型.文献[5]提出一种基于加权信息增益的特征选择方法,该方法综合考虑特征频率和信息增益的作用,能够更加准确地选取有效特征,从而提高检测性能.如上静态技术虽然对未知恶意代码识别的误判率和漏报率都较低,但其缺点是无法识别被加壳的恶意代码;(2)基于代码的动态行为分析法.与静态扫描技术不同的是,行为分析技术监控代码运行时的动态行为,由于某些行为是病毒、木马等恶意代码经常出现的行为,而在合法程序中却比较罕见,它们可作为判别应用程序是否非法的依据.文献[6]提出一种基于API 调用为特征向量并采用贝叶斯分类器来识别恶意代码的方法.文献[7]采用一种基于API 调用为特征向量的最小距离分类器来识别恶意代码的方法.这些动态识别方法的优点是简单、高效,可检测出未知恶意代码而不用担心是否该代码被加壳,但缺点是误判率和漏报率较高.
文献[6-7]采用的识别方法误判率和漏报率高的一个主要原因是:由于该方法没有考虑到恶意代码所调用的API 之间实际上还存在着某些密切关联这一事实,鉴于此,本文采用K 长度的滑动窗口来提取API 调用序列作为恶意代码的特征属性,并以此建立起所有训练样本的特征向量,采用决策树C4.5 算法建立一棵决策树,并生成决策规则,这些规则就是判断代码是否为恶意的依据.实验表明,该方法与文献[6-7]所采用的方法相比有着较低的误报率和漏报率.
1 动态恶意代码行为的捕获
1.1 恶意代码的主机行为
目前最为流行、破坏力最大的恶意代码就是Win32 PE 病毒,PE (Portable Executables)是win32 系统中可执行程序的二进制文件形式,它是通过调用操作系统中的API 函数(应用程序接口)来实现各项功能,而这些API 函数则依据功能来自不同的动态链接库(DLL).所以,以PE文件为存在形式的病毒在完成植入、控制和传播等任务时都必须借助API 函数的调用[8].
实践表明:与运行阶段相比,恶意代码病毒在植入、安装阶段会表现出显著的有别于一般合法程序的一系列行为特征,如自删除、自我复制、杀进程、设置自启动、感染EXE 文件等.因此,捕获恶意代码在植入、安装阶段的API 函数调用,就捕获到了相应恶意代码的动态行为.根据对恶意代码和合法程序运行时调用API 函数情况的观察,试验选取141 个较敏感的API 函数作为监控对象,部分API 函数如表1 所示[8].

表1 部分监控API 函数调用表Table 1 Part of API function calls
1.2 特征的生成
把待监测的141 个API 函数编号(1~141),在虚拟机里面运行所有的恶意样本和正常样本,提取所有样本程序在植入、安装阶段调用的相关API 函数.这样每个样本就可表示成一个由一系列数字组成的串,每个数字表示所调用的API 函数编号.因为恶意代码在植入、安装阶段有很多区别于正常代码的行为,这些行为就表现在一些特定的API 函数调用的特殊排列次序上,如典型的病毒在植入、安装阶段的行为次序是:(1)隐藏运行,将自身移动到系统目录;(2)修改注册表相关键值;(3)遍历所有硬盘生成Autorun.inf 文件.相应地调用的API 函数依次为GetSystemDirectory (),CopyFile (),RegOpen-KeyEx(),RegSetValueEx(),RegCloseKey(),RegCreateKeyEx (),RegSetValueEx (),Reg-CloseKey(),SetFileAttributes(),CopyFile().这一按特定次序排列的调用序列就可作为检测代码是否为“恶意”的标志.尽管不同的恶意代码在植入、安装阶段的行为有些差异,但它们很多“恶意行为”仍然很相似,这是能够发现它们蛛丝马迹的依据.为能充分提取代码的行为特征,使用一个K 长度的滑动窗口来提取K 长度的数字串,窗口每次移动一位,这样就可把一个代码样本的特征表示成一系列K 长度的数字串,如图1 所示.综合精度和性能的考虑,选取K 的长度为4.

图1 K=4 的滑动窗口示意图Fig.1 Sliding window schematic diagram of K=4
试验样本共849 个,按照这种方式提取长度为4 的数字串,一共可得9 948 个互不相同的数字串,作为代码的特征属性.
1.3 数据模型的建立
恶意代码检测实际是一个二值分类问题,即恶意代码与合法代码,对这两类样本的特征属性调用统计结果采用二维表形式,如表2 所示.表2 中每个数据元组X=(x1,x2,…,xn,c)记为一个样本的特征向量,其中xi(i=1,2,…,n)表示特征向量中的一个特征属性,xi∈{0,1},0 表示某个特征属性一次都没有被该样本调用过,1 表示某个特征属性被该样本调用过1 次或多次.c表示类别,c∈{0,1},1 代表黑名单样本,0 代表白名单样本.
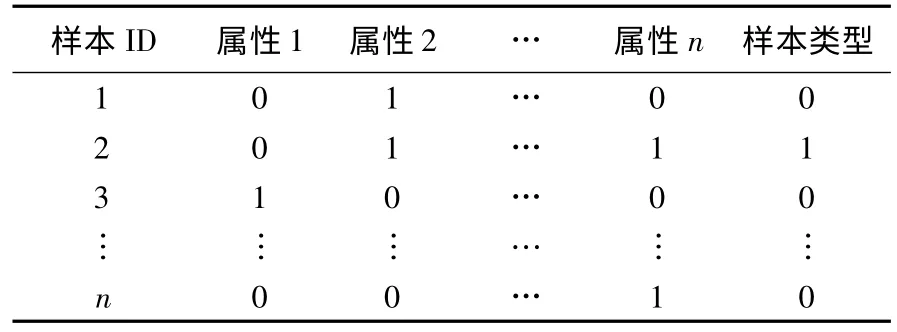
表2 特征向量统计表Table 2 Feature vector of samples
2 基于C4.5 算法的未知恶意代码识别算法
2.1 C4.5 算法概述[9]
C4.5 分类算法是决策树分类算法的一种,是从ID3 决策树分类算法发展而来,其基本思路如下:
设S 是s 个数据样本的集合.假定类标号属性具有m 个不同值,定义m 个不同类Ci(i=1,2,…,m).设si是类Ci中的样本数.对一个给定的样本分类所需的期望信息由公式
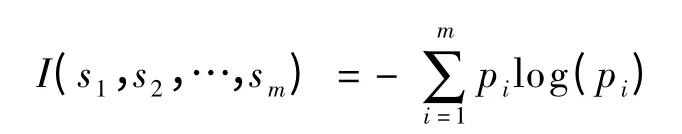
给出.其中,pi是任意样本属于Ci的概率,一般可用si/s 来估计,对数函数以2 为底.设属性A 具有v 个不同值{a1,a2,…,av}.可以用属性A 将S划分为v 个子集{S1,S2,…,SV},其中Sj包含S 中这样一些样本,它们在A 上具有值aj.如果A 作为测试属性(即最好的分裂属性).则这些子集对应于由包含集合S 的结点生长出来的分支.设sij是子集Sj中类Ci的样本数.根据由A 划分成子集的熵E(A)由公式
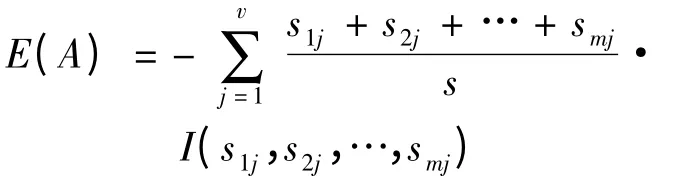
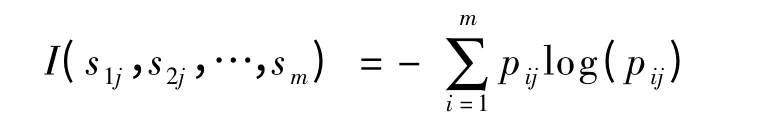
由期望信息和熵值可以得到对应的信息增益比例值.对于在A 上分支将获得的信息增益可由公式

给出.相应地得到 关于属性A 的信息增益比例值由公式

给出.其中,
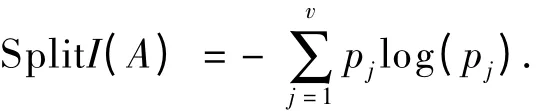
C4.5 算法计算每个属性的信息增益,并选取具有最高增益的属性作为给定集合S 的测试属性.对被选取的测试属性创建一个结点,并以该属性标记,对该属性的每个值创建一个分支,并据此划分样本.以此类推,可以通过计算信息增益和选取当前最大的信息增益属性来扩展树,直到得到最终的决策树.一旦树被建立,就可以把树转换成if-then 规则,一个规则就对应从树根到叶子之间的一个路径,表示依据所给属性进行分类决策的过程.
2.2 基于C4.5 的未知恶意代码识别算法
本算法采用递归方法生成决策树(用C++语言实现).算法主要步骤为:
(1)把训练样本特征属性向量输入到二维数组infor 中.
(2)计算infor 数组中每个属性的信息增益比例,确定具有最大信息增益比例的属性.
(3)创建一个结点node,结点data 域存放当前具有最大信息增益比例属性在infor 数组中的列序号.
(4)在数组infor 中把由第(2)步确定的最大信息增益列的值全部赋成-1,意味着以后计算剩余属性的最大信息增益时不考虑该列.
(5)根据第(2)步确定的最大信息增益列的列值,把infor 数组分成上下2 部分,上部分所有向量该列列值为1,下部分所有向量该列列值为0.
(6)分别对重新划分的2 个子数组重复采用(2)、(3)、(4)、(5)步骤进行递归,分别得到2个子数组中具有最大信息增益比例的属性,分别作为node 结点左右孩子结点date 域的值.
(7)当发现重新划分的子数组中,所有向量全部是白名单样本,则data 域标记为-1,递归结束;如果所有向量全部为黑名单样本,则data域标记为-2,递归结束;如果子数组中只有一列数据可用,则如果该子数组中白名单样本占的比例大,则data 域值为-1,否则为-2,递归结束.
构造好的决策树如图2 所示.
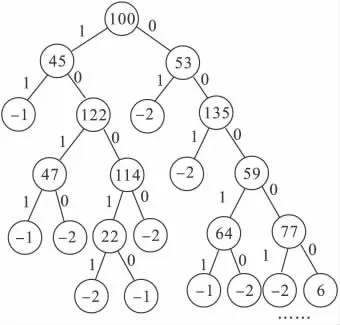
图2 构造的决策树局部示意图Fig.2 Partial schematic diagram of decision tree constructed
非叶子结点中的数表示属性的序列号.叶子结点-1 表示是合法程序,-2 表示的恶意程序.边上的值表示对应结点属性的值.
2.3 决策树规则的生成及对未知样本的分类
从决策树的顶点到叶子结点的一条路径就是一个决策规则,所有从顶点到叶子结点的路径就是该决策树的分类规则.例如:某个样本的特征向量X,其中x100=0,x53=0,x135=0,x59=1,x64=1.则对应分类规则路径是100—53—135—59—64—-1,则该样本为合法代码;如果某个样本的特征向量X,其中x100=1,x45=0,x122=1,x47=0.则对应分类规则路径是100—45—122—47—-2,则该样本为恶意代码.
3 实验结果及分析
为评价算法性能,引入如下相关概念[8]:
真阳性TP:黑样本被检测为黑样本的数目;
假阳性FP:白样本被检测为黑样本的数目;
真阴性TN:白样本被检测为白样本的数目;
假阴性FN:黑样本被检测为白样本的数目;
检出率:TPR=TP/(TP+FN);
误报率:FPR=FP/(FP+TN);
正确率:ACY=(TP +TN)/(TP +TN +FP+FN).
Youden 指数=TPR-FPR,其中Youden 指数的取值范围为(-1,1)之间,其值越接近于+1,就意味着该检测模型的判别准确性越好.
实验样本共849 个,其中白名单-合法程序样本是在Windows XP Professional 操作系统首次安装,能确保在干净的系统环境下选取的操作系统PE 文件404 个;黑名单-恶意代码样本通过网络及其他途径搜集总共445 个.将杀毒软件升级到最新并对这些恶意代码病毒进行查杀,确认都是恶意代码病毒.
为防止恶意代码对系统的破坏,在虚拟机环境下分析恶意代码的动态行为.实验平台操作系统采用Windows XP Professional,虚拟机采用Vmware Workstation 6.0.使用ApiMonitorTrial工具软件对代码运行时API 函数的调用情况进行捕获.
实验采用10 次交叉验证的方法,并与朴素贝叶斯算法和基于标准化欧式距离的最小距离分类器算法进行比较.实验结果如图3 和表3 所示.由图3 可知,基于决策树C4.5 算法的Youden 指数的均值(0.775 4)不但高于朴素贝叶斯(0.303 9)和最小距离分类器(0.408 3)两个算法,且通过计算可知C4.5 算法10 次交叉试验Youden 指数的方差(0.017)远远低于朴素贝叶斯(0.047)和最小距离分类器(0.098)的方差,所以C4.5 算法的稳定性较其他2 种算法也较好.由表3 可知,虽然最小距离分类器的检出率(93.60 %)是最高的,但是它的误报率(52.77 %)也是最高的.从3 者的检出率来看,基于决策树C4.5 算法达到了88.70 %,明显高于其他2 种算法.
综合所述,基于决策树C4.5 分类算法较其他2 种分类算法有较明显的优势.
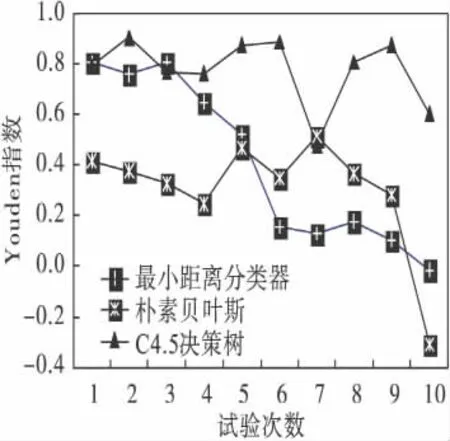
图3 3 种算法10 次交叉验证Youden 指数的比较Fig.3 Three algorithms ten times cross-validation Youden index comparison

表3 3 种分类识别算法10 次交叉验证均值比较Table 3 Ten times cross-validation mean comparison of the three classifications recognition algorithm
4 结论
采用定长的滑动窗口提取代码的特征属性,样本越多,生成的特征属性就相应越多.这样,所有样本的特征向量组成的二维表就是一个列行之比较大的稀疏矩阵,通过对比试验表明:对基于这类稀疏矩阵的二值分类问题,采用决策树C4.5 算法比采用朴素贝叶斯和最小距离分类器算法有着较明显的优势.
[1]Fred Cohen.Computer Viruses:Theory and Experiments[J].Computers&Security,1987,6(1):22-35.
[2]Diomidis Spinellis.Reliable Identification of Bounded-lengh Viruses is NP-complete[J].IEEE Transactions on Information Theory,2003,49(1):280-284.
[3]Xu Jianyun,Sung Andrew H,Mukkamala Srinivas,et al.Obfuscated MaliciousExecutable Scanner[J].Journal of Research and Practice in Information Technology,2007,39(3):181-197.
[4]Schultzm G,Eskin E,Zadok E,et al.DataminingMethodsfor Detection of New Malicious Executables[C]// Proceedings of the 2001 IEEE Symposium on Security and Privacy.Washington:IEEE ComputerSociety,2001:38-49.
[5]张小康,帅建梅,史林.基于加权信息增益的恶意代码检测方法[J].计算机工程,2010,36(6):149-151.
[6]张波云,殷建平,蒿敬波,等.基于多重朴素贝叶斯算法的未知病毒检测[J].计算机工程,2006,32(10):18-21.
[7]张茜,邵堃,刘磊.一种基于最小距离分类器的恶意代码检测方法[J].广西师范大学学报:自然科学版,2009,27(3):183-187.
[8]朱立军.基于动态行为的未知恶意代码识别方法[J].沈阳化工大学学报,2012,26(1):77-80.
[9]毛国君,段立娟,王实,等.数据挖掘原理与算法[M].北京:清华大学出版社,2005:115-123.
