科技项目申请书关键词提取方法
2013-10-17徐小良吕跃华
罗 灏,徐小良,吕跃华
(1.杭州电子科技大学计算机学院,浙江杭州 310018;2.浙江省科技信息研究院网络中心,浙江杭州 310006)
随着我国各类科技计划项目申报数量和经费的逐年递增,科技项目管理服务信息平台建设不健全,导致项目重复申报现象日益突出。为了有效杜绝类似现象,提高科技经费使用效率,针对科技项目申请书信息进行文本相似度计算研究是必要的。关键词是相似度计算、文本检索等应用的基础,因而关键词提取方法的研究是有效实现科技项目相似性检查的关键。
目前关键词提取方法主要分为3类:(1)基于统计特征的方法,如词语频度统计。(2)基于词语网络的方法,如文献[1]根据规则将文档映射为词语共现网络并用计算词语的关键度来提取关键词。(3)基于语义的方法。前两种方法虽然具有简单高效的优点,但由于算法局限于字面匹配、缺乏语义理解而排除了低频率的关键词。针对这个问题,引入语义特征进行关键词提取是目前的主要研究方法,如文献[2]引入《同义词词林》计算词语的语义距离,一定程度上提高了关键词提取的准确度,但没有结合词频因素。另外,科技项目申请书中包含的专业术语通常是项目的关键词,但很多术语没有收录在词典中,因而这类未登录词的识别尤为重要。
本文针对科技项目申请书的特征,利用Apache Lucene[3]和互信息统计相结合的多策略融合的方法进行分词,并采用识别未登录词作为项目关键词的一部分;对于特殊分词进行语义处理,利用知网中丰富的语义关系,分别计算词语之间的语义相似度,依据社会网络理论建立词语语义相似度网络,将词语的“关联度”和词频进行加权获得词语的关键度,并根据所设定的阈值完成关键词的提取。
1 科技项目申请书特征分析
相对于一般的文本,科技项目申请书具有以下特征:(1)科技项目申请书中的文字较精简、规范。(2)科技计划项目涉及各种技术领域,申请书中存在大量的专业术语,这些专业术语往往是项目的关键词。(3)申请书格式较统一,其中存在较多潜在的显性切分标记,例如在填写主要内容和主要技术指标时有(1)(2)(3)……切分标记;在出现领域词的时候会用双引号将词语引起来。(4)对训练语料库研究发现,很多科技项目名称中包含有隐性切分标记。(5)申请书中存在一些特殊词具有具体的语义,如“本系统”、“本课题”,“本项目”等。
2 科技项目申请书关键词提取方法
2.1 关键词提取流程
科技项目申请书关键词提取流程如图1所示,主要分为两部分:(1)对科技项目申请书进行分词并识别未登录词作为关键词的一部分。(2)基于语义的关键词提取,即通过计算词语语义相似度建立语义相似度网络,结合词频计算词语关联度来提取项目其他关键词。
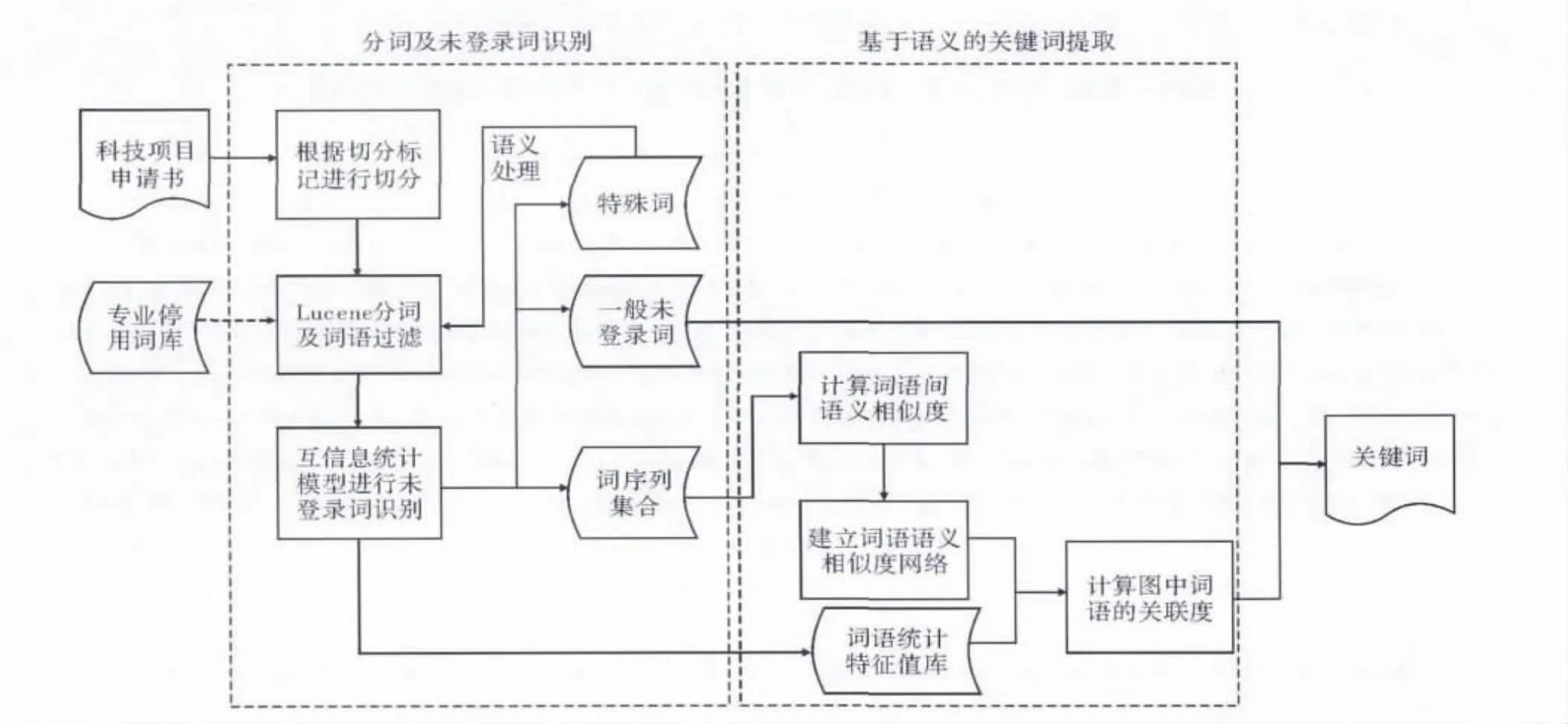
图1 科技项目申请书关键词提取流程
2.2 多策略融合分词及未登录词识别方法
对科技项目申请书中的项目名称、主要内容进行分词:(1)根据申请书中潜在的隐性和显性切分标记,将项目名称、主要内容文本切分成子串序列。(2)在通用停用词库的基础上,针对申请书中的词语特点建立专业停用词库,如技术、开发、研究等专业停用词。对(1)中的子串序列分别利用Apache Lucene进行分词及去停用词处理。最后形成词序列集合,SW={w1,w2,…,wn},其中,wi=(ui,fi);ui表示词;fi表示词频。
研究发现,各个领域的科技项目申请书中存在较多专业词即未登录词。未登录词造成分词精度的损失比其他因素大[4],因此本文融合了互信息统计的未登录词识别策略,考虑文本的上下文信息来提高未登录词的识别率。
概率论中定义了两个随机变量之间的互信息,即计算随机分布中的两个变量之间的互信息
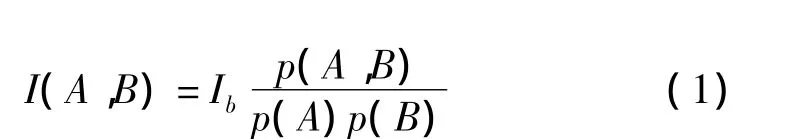
定义1 “未登录词”通常是单字词和其他汉字组成的多字词。因此,本文定义成词的可信度来度量两者之间组成词的可能性。n(i)表示词wi在训练语料中的词频;N表示训练语料中词语的总频数。则它们成词的可信度的计算公式定义为
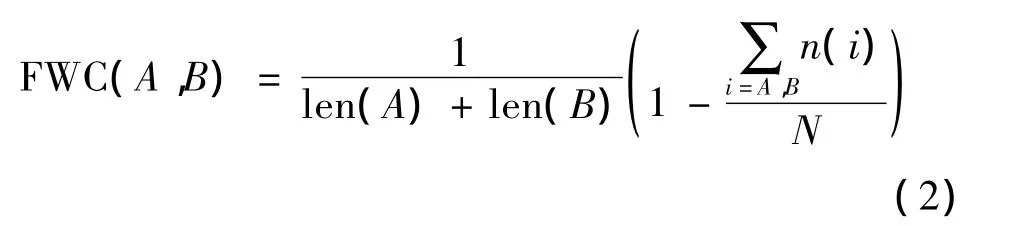
文献[5]提出了较长字串组成新词的可能性小于较短的字串。因此,在计算词A、B成词可信度过程中考虑了A、B的长度len(A)、len(B),这样成词可信度的计算准确度将有一定的提高。
本文将成词可信度融合到词语互信息计算之中,依据式(1)将两词互信息计算公式定义为
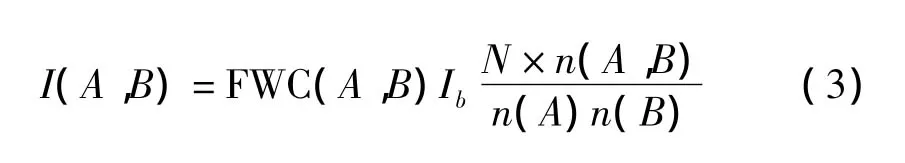
其中,n(A,B)表示训练语料中词A与B相邻出现的频数。
“未登录词”经过分词后被划分成包括单字词的多个词语,首先将划分出来的单字词分别和其前一个词以及后一个词组成两个新词并放入临时词典,然后根据上面给出的互信息统计语言模型计算临时词典中词的成词可信度,最后根据设定的阈值识别出“未登录词”。
对于上述识别出的特殊词将做语义处理,如“本系统”、“本课题”,“本项目”等特殊词将它们替换成项目名称并利用同样的方法进行分词,这样可以提高接下来关键词提取的准确度;对于识别出的未登录词将作为关键词进行提取。
通过对未登录词识别并将未登录词作为项目部分关键词后,词序列集合SW={w1,w2,…,wn}将变为另一个词序列集合SW'={v1,v2,…,vm}(m≤n)进入下一步的关键词提取。
2.3 基于语义相似度网络的关键词提取
2.3.1 词语语义相似度计算
刘群认为两个词语的相似度是它们在不同的上下文中可以互相替换且不改变文本句法语义结构可能性的大小[6],而词语间的语义相似度一般由它们之间的语义距离来衡量,一种比较流行的方法是根据知网语义词典来计算词语义原之间的距离,从而得到词语的语义相似度。
在《知网》的结构中,每个词由多个概念来表达,而每个概念又是由义原来描述;义原根据其属性被组织成不同的树状层次结构,树与树之间存在关系而连接在一起,进而形成网状的知识结构,所以义原的距离是根据义原树结构的相对位置来衡量的。
假设词语w1在知网中有n个概念c11,c12,…,c1n,w2有m个概念c21,c22,…,c2m,则本文中规定词w1与w2的相似度为各个概念相似度的最大值,即
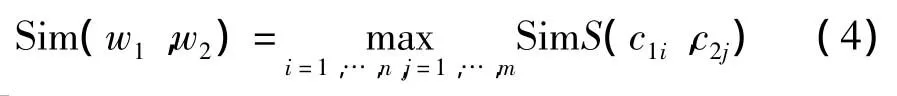
因此,两个词语之间的相似度最终归结到义原的相似度。对于两个义原节点相似度计算,李峰认为主要分为两大类:基于两个节点之间的路径长度和基于两个节点所含有公共信息的大小[7]。对于基于路径长度的计算,吴健认为,对于同样距离的两个义原,它们的相似度是随着它们所在的层次深度总和的增加而增加的,随着它们之间层次深度差的增加而减小[8]。针对以上两人论证的观点,文献[9]基于节点的层次和义原的相对路径长度提出了一种计算两个义原s1,s2相似度。
词序列集合SW'中两词语语义相似度计算过程:首先借助于知网语义词典,计算两词语义原之间的相似度,并取其最大值;再根据式(4)的定义求得了两个词语的语义相似度。
2.3.2 建立词语语义相似度网络图
词语共现网络没有从词语语义上体现它们之间的关联,导致一些没有关联的词语也将被加入共现网络中。因此,本文从词语之间的语义层面出发,建立词语语义相似度网络。
定义2 设W={v1,v2,…,vp}为预处理后得到的词语序列集合,则W对应的语义相似度邻接矩阵Mp定义为
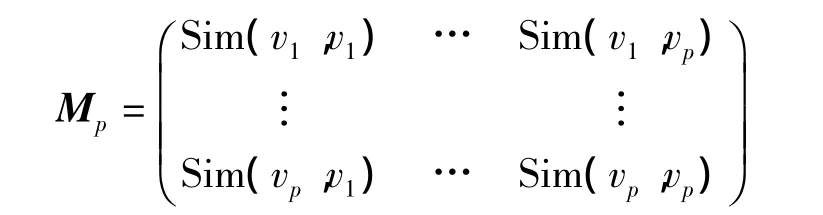
其中,Sim(vi,vj)为词vi和vj的语义相似度,Sim(vi,vi)=1,Sim(vi,vj)=Sim(vj,vi)。
词序列集合SW'={v1,v2,…,vm}经过词语语义相似度计算得到m×(1+m)/2个词语间相似度的值,并对这些值进行递减排序;设定一个阈值β(0<β<1),取出前β×m(1+m)/2的值,假设这些相似度值所对应的词组合成另一词序列集合为SW″={s1,s2,…,sq}(q≤m),并根据它们之间的相似度值生成SW″对应的语义相似度邻接矩阵Mq。
定义3 设SW″为输入的词序列集合,Mq为输入的语义相似度邻接矩阵,则其对应的词语语义相似度网络图定义为G={V,E}。其中,图G为无向加权图;V表示图G中的顶点集;vi表示V中第i个顶点(词);E表示G中的边集;图G边的权值矩阵为Mq,其中Sim(vi,vj)为第i个顶点和第j个顶点之间边的权值,因为是无向图,所以 Sim(vi,vj)=Sim(vj,vi)。
2.3.3 词语语义关联度计算
社会网络是由一群节点以及节点之间的连线所组成的关系集合,节点代表相应的群体,节点之间的连线表示节点间的联结关系。社会网络的实质是个体与个体之间,组织和组织之间为了达到特定的目的进行信息交流和资源利用的关系网[10]。通过对社会网络的分析,可以得到节点间的关系以及每个节点和其他节点的关联度,进而可以分析出节点在整个网络中的重要程度。
将上述建立的图G视为社会网络,图中的边的权重表示相邻两个节点之间的关联度。每个节点在整个社会网络中的重要程度,即删除该节点对整个社会网络的影响程度,则需要计算出该节点对于整个社会网络的关联度。
定义4 设图G为构建的社会网络图,其中G为加权无向图,图中两个顶点之间边的权值为它们之间的语义相似度;vi到vj的最短路径经过的顶点依次为vi,vi+1,…,vj,路径对应的边的权值依次为si,si+1,…,sj-1,则G中顶点vi和vj(i≠j)之间的关联度定义为

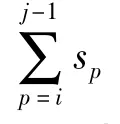
所以对于图G中的顶点vi,它在整个图中的关联度为
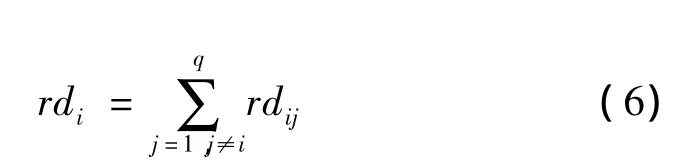
最后得到q个关联度的值,设定一个阈值γ(0<γ<1),取出前γ×q个的值,则这些值所对应的顶点将作为关键词进行提取。
3 实验结果及分析
在相同的相似度计算模型下,关键词提取的准确性直接影响到科技项目相似度计算的效果。本文设计了基于关键词的科技项目相似度计算实验,其中关键词分别采用传统的统计特征方法和本文的新方法来提取,相似度计算算法采用经典的余弦模型如下
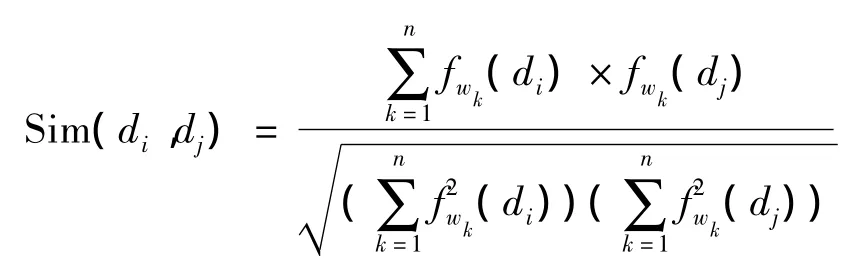
其中,di,dj为两个科技项目申请书;(di)表示关键词wk在申请书di中词频。
针对浙江省科技项目库中的项目1进行相似度计算实验结果如表1所示。
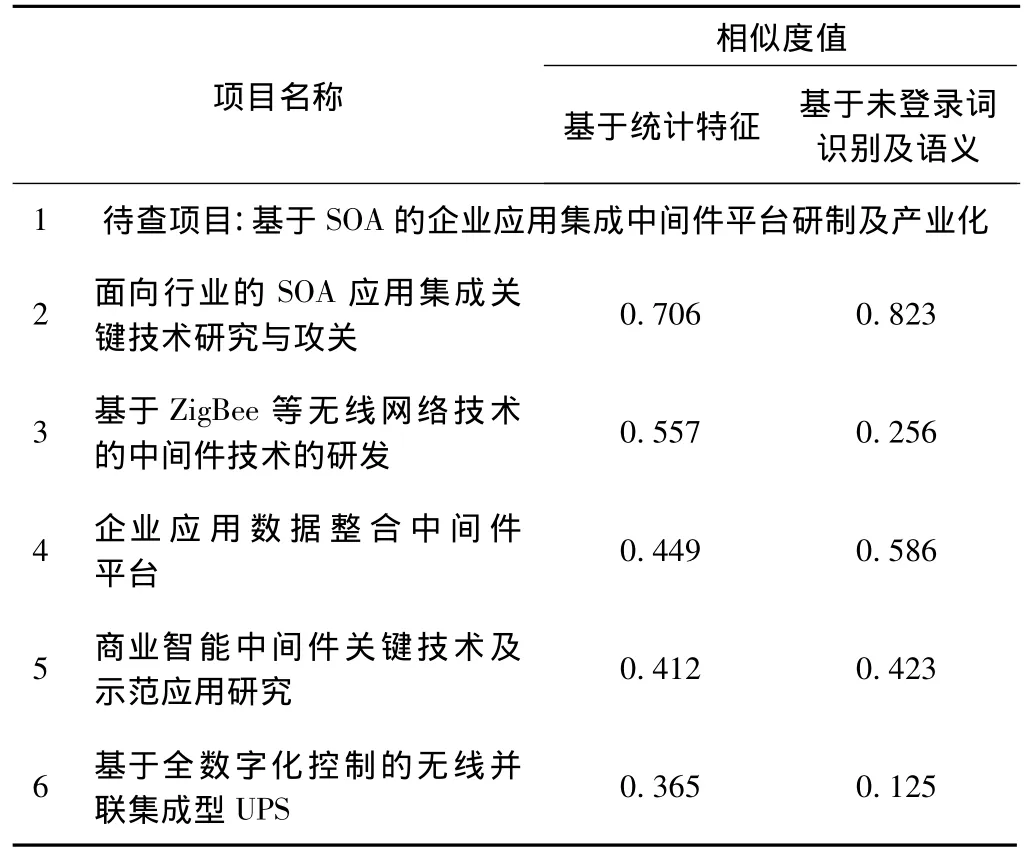
表1 相似度计算结果对比
实际比较可知,待查项目1和项目2研究内容类同,和项目3、6研究内容基本不重复,和项目4、5部分研究内容相似。如表1所示,新方法提高了相似性项目的相似度值,明显降低了不相似项目的相似度值,更有利于准确查找出相似的项目并排除不相似项目的干扰。由此表明,与传统的关键词提取方法相比,本文的关键词提取方法能更准确地提取出项目的关键词。
4 结束语
本文针对科技项目申请书特征,提出了一种基于未登录词识别与语义的科技项目申请书关键词提取方法。利用Apache Lucene和互信息统计的多策略融合方法进行分词并识别未登录词作关键词的一部分,然后通过建立词语语义相似度网络并计算词语的关联度提取其余关键词。实验结果表明,与传统的关键词提取方法相比,基于未登录词与语义的新方法能更准确地提取出项目关键词,改善了科技项目相似性检查的效果。
[1]马力,焦李成,白琳,等.基于小世界模型的复合关键词提取方法研究[J].中文信息学报,2009,23(3):121-128.
[2]王立霞,淮晓永.基于语义的中文文本关键词提取算法[J].计算机工程,2012,38(1):1-4.
[3]The Apache Software Foundation.Apache Lucene[EB/OL].(2010-09-06)[2012-10-12]http://lucene.apache.org.
[4]宋彦,蔡东风,张桂平,等.一种基于字词联合解码的中文分词方法[J].软件学报,2009,20(9):2366-2375.
[5]李振星,徐泽平,唐卫清,等.全二分最大匹配快速分词算法[J].计算机工程与应用,2002,38(11):106-109.
[6]刘群,李素建.基于《知网》的词汇语义相似度的计算[C].台北:第三届汉语词汇语义学研讨会,2002.
[7]李峰,李芳.中文词语语义相似度计算——基于《知网》2000[J].中文信息学报,2007,21(3):99-105.
[8]吴健,吴朝晖,李莹,等.基于本体论和词汇语义相似度的web 服务发现[J].计算机学报,2005,28(4):595-602.
[9]江敏,肖诗斌,王弘蔚,等.一种改进的基于《知网》的词语语义相似度计算[J].中文信息学报,2008,22(5):84-89.
[10]赵红梅.社会网络嵌入性视角下R&D联盟形成动因研究[J].科技管理研究,2009,10(8):426-428.
