云存储系统中数据冗余策略优化问题
2013-10-15麻晓珍张海蓉
李 玲,付 园,麻晓珍,张海蓉
(吉林大学 通信工程学院,长春 130012)
0 引 言
云存储系统作为云计算的一个分支受到广大学者的重视[1-3],存储系统数据的有效性和完整性是最受关注的性能指标,为此,云存储系统纷纷引入了冗余机制[4-6]。绝大多数系统采用简单的完全备份[7,8],每个数据块增加几个固定的备份副本并随机地存放在不同节点上,这给系统带来了挑战:
1)引入过多的副本虽然能满足数据有效性要求,但也带来存储成本的增加;
2)副本在云计算集群中放置的不均衡将导致访问扭曲甚至网络拥塞;
3)当所有副本都失效时,数据无法恢复。
针对云存储系统冗余机制的上述前两个问题,文献[9-11]都提出了改进策略,分别给出了各自副本数确定和副本放置的模型,在满足有效性要求的基础上节省了存储空间并实现了负载均衡,但都没有解决数据可恢复性问题。
文献[12,13]提出采用纠删码的方法,以增强云存储系统中数据的可靠性,但当数据更新频繁时,纠删码的编解码过程将带来大量的系统时延。
文献[14]对纠删码和完全备份的优劣势进行对比分析,分别得出了各自的优势。为结合二者的优势,文献[15]提出了将完全备份和RS(Rood-Solomon)纠删码结合的分布式架构REPERA,但并没有给出副本数确定和副本放置以及参数调整的依据,而且REPERA采用的RS编码方法编解码速度慢,增加了系统时延。
因此,笔者提出一种将完全备份与改进的RS纠删码结合的自适应数据冗余策略RIRS,可根据具体应用环境设置RIRS的参数。RIRS在需要随时更新数据的场合下退化为纯粹的完全备份模式时,笔者又给出一个动态副本管理优化模型DRMO,以动态调节副本数和副本位置,节省存储空间和实现负载均衡。
1 完全备份与改进后RS纠删码结合的冗余策略RIRS
Hadoop是目前广泛用于学术研究的典型开源云平台,笔者提出的完全备份与改进后RS纠删码结合的冗余策略也是基于Hadoop的分布式文件系统HDFS(Hadoop Distributed File System)的,下面详细介绍RIRS的实现过程。
1.1 RIRS的数据存储及恢复策略
RIRS对系统中的数据进行存储时采用{r,m,n}策略,先用改进的RS纠删码算法对每n块数据块进行编码,产生(m-n)块冗余码并将其编为一个编码组,然后将每个编码组备份r份,分散地存储在不同的数据节点和机架上。在NameNode上维护一个记录编码任务的数据结构,包括源数据节点的位置,进行冗余块计算的节点位置和存放冗余块的节点位置等信息。RIRS系统中{r,m,n}参数的调整能使该冗余策略满足不同环境的需求,在某些应用场景下完全可以退化成纯粹的完全备份或纠删码方法。
HDFS采用完全备份的方法将每个数据块复制3份,因此其占用的空间为3×n,而RIRS占用的空间为r×m,采用RIRS节省存储空间情况如表1所示。

表1 HDFS与RIRS占用空间
RIRS的数据恢复策略采用备份优先策略[15],只有当所有副本都失效时才采用解码操作恢复数据。
1.2 RIRS中纠删码的选择
纠删码发展至今,已有数十种类型,其中适合分布式存储系统的主要是RS纠删码和LDPC纠删码,下面将通过试验比较得出纠删码选择的依据。
1)RS纠删码。RS纠删码用范德蒙矩阵F与数据矩阵D相乘得到校验矩阵C,编码过程如下
(1)
观察如上矩阵可得,删除矩阵A和矩阵E的对应行,等式依然成立。删除相应行后的矩阵分别用A′,E′表示,得到
A′D=E′
(2)
根据矩阵的性质,可得
D=(A′)-1E′
(3)
根据范德蒙矩阵的性质,可得A中任取p(p≥n)行一定线性独立,则矩阵A一定可逆。故只要数据损坏少于等于m-n个,就一定能恢复原来的n个数据,即容错能力为m-n。
使用Matlab编程实现n=10,m=15的编码结果如图1所示。

图1 RS纠删码编码过程
图2中A0和encode0t分别为A和encode删除对应5行后的结果,Inv为A0在伽罗华域范围上的逆矩阵,可见只要损失的数据不大于5即可成功解码,说明RS编码的容错能力为m-n。

图2 RS纠删码解码过程
2)LDPC纠删码。LDPC纠删码是用稀疏矩阵H与数据矩阵D相乘得校验矩阵C,其中H中只有0,1两个元素,而且1的个数小于0的个数。该矩阵表示信息位到冗余校验位的具体映射关系,所以,校验位只需对数据位进行简单的异或运算就可得到,从而简化了编解码运算的复杂度。
用Matlab实现n=10,m=15的编码结果如图3所示。

图3 LDPC码编码的运行结果
图1和图3,图2和图4比较可得,LDPC码的编解码时延远小于RS码,但由图2和图5可知,LDPC码不能保证解码成功,经过多次运行得到,在损失3个数据的情况下成功解码的概率很高,能达到90%,而在损失4个数据的情况下,则只有50%,所以LDPC码的容错性能较差。

图4 LDPC码损失3个数据时的解码运行结果 图5 LDPC码损失4个数据的解码运行结果
3)改进的RS纠删码。为降低RS码的编解码时延,使用一种新的乘法运算代替伽罗华域中乘法的计算,这种乘法只需用到异或和二进制数的左移右移操作,运算简单。

图6 RS码与其改进算法的解码时间对比
两个整数相乘时,将左边的乘数除以2(右移),右边的乘数乘以2(左移),得到的结果继续重复这种运算,直到左边的乘数变为1。之后将左侧结果为偶数的行删掉,为奇数的行保留,将保留的右侧结果全部相加,得到的即为两数相乘的结果。
改进后的RS编码与原RS码性能比较如图6所示。图6中K为信息位长,N为编码后的数据位长,即码长。
图6表明,改进后的RS码降低了RS码的编解码时延。
4)总结。由上面的实验结果可得,RS码的容错能力,存储空间使用效率都能达到最佳,但编解码时延长; LDPC码有很快的编解码速度,但其随机的特性使其容错能力有限,且存储空间使用效率较低。由于笔者提出的冗余策略是完全备份与纠删码结合的策略,而且数据丢失时采用备份优先的原则恢复数据,只有当所有备份全丢失时才使用解码恢复,所以用到纠删码解码的情况较少,解码时延并不会影响整个系统的性能,而采用该种方法时必然没有数据副本,如果解码失败,丢失的数据将不可恢复。因此选择容错能力最佳的RS纠删码,并对其进行上述改进,以降低解码时延。
1.3 分析小结
RIRS充分发挥了完全备份和纠删码二者的优势,由表1分析可知RIRS能节省系统的存储空间,此外,由于多个副本分散地存储在不同的节点上,用户在访问数据时可以根据自己的地理位置就近访问数据,降低了系统的访问时延。同时,当系统中所有备份都失效时,RISR还可以采用解码操作恢复数据,所以,提高了系统的可靠性和稳定性。
2 动态副本管理优化模型DRMO
DRMO是针对RIRS系统退化为纯粹的完全备份时设计的一个动态副本管理优化模型,该模型通过动态地调节副本数和副本位置改善系统的访问时延和负载均衡,主要包括副本数确定模块、副本位置选择模块和动态副本管理模块。
2.1 副本数确定模块
HDFS中将一个文件分成m个数据块,每个数据块复制rj份,分散地存储在不同的数据节点上,一个数据块只有在所有的副本全失效的情况下才失效,所以数据块的失效率为
(4)
其中fi是数据节点i的故障概率,而一个文件只有在m个数据块都有效的情况下才有效,所以有
(5)
假设用户定义文件F的预期有效性为Aexpect,为满足给定文件有效性的要求,有
(6)
该模型中名字节点将使用式(6)计算最小副本数rmin,以满足平均数据节点故障概率下预期有效性的要求。在数据节点故障和当前数据块的副本数小于rmin的情况下,系统就会增加副本,并将其存入机架内的数据节点上。
2.2 副本位置选择模块
为减少数据节点间访问扭曲现象的发生,进而改善负载均衡和并行度,该模型使用如下数据节点的阻塞率[9]
(7)
作为副本放置的依据。该模型为实现负载均衡将选择阻塞率最小的数据节点存放副本,同时为降低分类和查找数据节点的时延,该模型还采用B+树对数据节点进行排序[9]。笔者对文献[9]进行了改进,考虑了HDFS的机架感知策略。将副本分为主副本,缺省副本和其他副本,HDFS中缺省的副本数为3,包括1个主副本和2个缺省副本,其他副本是指HDFS系统中对热点数据块增加的副本。机架感知策略将主副本和第1个缺省副本存放在同一机架上,第2个缺省副本存放在另一远程机架上; 由于其他副本的创建具有动态性,所以放置其他副本时,应根据文件在各机架中的访问量变化选择访问次数最多的机架作为最佳机架。因此,放置副本时应先判断副本的类别再调用相应算法选择相应机架中的最佳节点进行存放。主副本和缺省副本放置算法实现如图7所示,而其他副本放置时先调用如图8所示的算法选择最佳机架,再调用如图9所示的算法选择机架内最佳节点存放。

图7 主副本和缺省副本的位置选择算法流程图 图8 最佳机架选择算法流程图

图9 机架内最佳节点选择算法流程图
2.3 动态副本管理模块
首先根据上述模型式(7)中参数的动态变化更新最小副本数和阻塞率,然后根据数据块的历史访问记录总结副本访问频率ai的规律进而得出增加、删除和迁移副本的访问阈值tmig,tadd和tdel,以动态调节系统中的副本数和副本位置,其流程图分别如图10和图11所示。
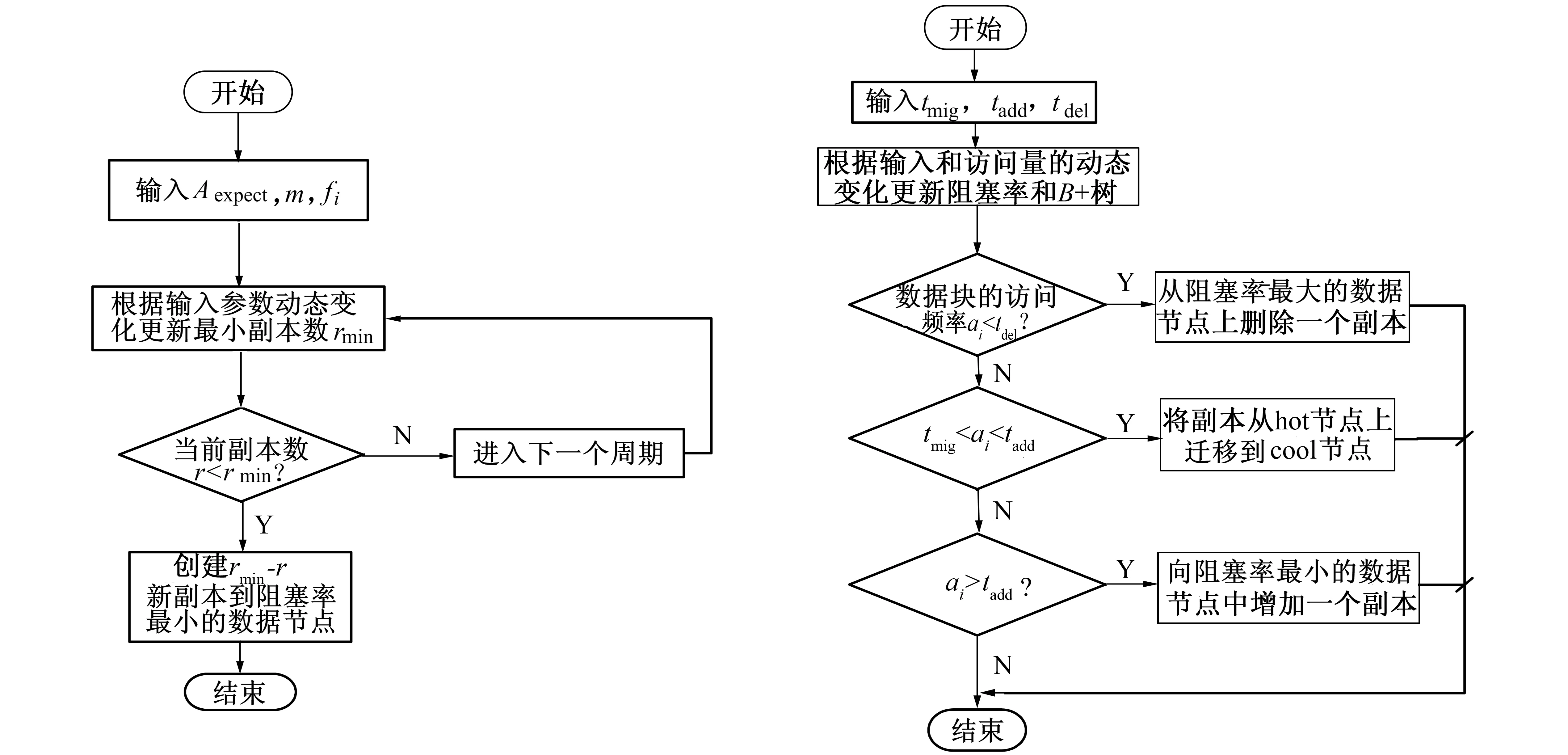
图10 动态副本数调整流程图 图11 动态副本位置调整流程图
2.4 分析小结
DRMO首先将系统中的副本数控制在满足数据有效性要求的最小值,然后根据数据访问热点进行调整,这样保证了系统中的副本数既满足系统要求又避免了因副本数过多而造成的存储空间的浪费。此外,DRMO将副本存放到阻塞率最小的数据节点上并根据访问热点进行迁移调整,实现了负载均衡,降低了访问时延。
3 结 语
笔者为改善云存储系统现有冗余策略的不足,通过实验比较选出了适合云存储系统的最佳纠删码,提出将其与完全备份结合的冗余策略。分析表明,该冗余策略能降低系统存储空间,降低访问时延并增强系统的可靠性和稳定性。同时,笔者提出的动态副本管理优化模型能在该冗余策略退化为完全备份时实现负载均衡。笔者将在今后的研究工作中用该冗余策略具体实现对HDFS的改进,对分析结果进行验证,并通过实验测试给出应用环境的划分阈值。
参考文献:
[1] WU Tin-yu,WEI-TSONG LEE,LIN Yu-san,et al.Dynamic Load Balancing Mechanism Based on Cloud Storage[C]∥Computing,Communications and Applications Conference (ComComAp).Hong Kong:IEEE,2012:102-106.
[2]HWAYOUNG JEONG,JONGHYUK PARK.An Efficient Cloud Storage Model for Cloud Computing Environment[J].Grid and Pervasive Computing Lecture Notes in Computer Science,2012,7296(32):370-376.
[3]YASHASWI SINGH,FARAH KANDAH,ZHANG Wei-yi.A Secured Cost-Effective Multi-Cloud Storage in Cloud Computing[C]∥IEEE Infocom 2011 Workshop on Cloud Computing.Shanghai:IEEE,2011:619-624.
[4]LLUIS PAMIES-JUAREZ,PEDRO GARCIA-LOPEZ,MARC SANCHEZ-ARTIGAS,et al.Towards the Design of Optimal Data Redundancy Schemes for Heterogeneous Cloud Storage Infrastructures[J].Computer Networks,2011,55(5):1100-1113.
[5]HUANG Zhen,YUAN Yuan,PENG Yu-xing.Storage Allocation for Redundancy Scheme in Reliability-Aware Cloud Systems[C]∥Communication Software and Networks (ICCSN),2011 IEEE 3rd International Conference.Xi’an:IEEE,2011:275-279.
[6]MOHAMMED A.ALZAIN,BEN SOH,ERIC PARDEDE.A New Approach Using Redundancy Technique to Improve Security in Cloud Computing[C]∥Cyber Security,Cyber Warfare and Digital Forensic (CyberSec),2012 International Conference.Kuala Lumpur:IEEE,2012:230-235.
[7]SANJAY GHEMAWAT,HOWARD GOBIOFF,SHUNTAK LEUNG.The Google File System[J].ACM SIGOPS Operating Systems Review-SOSP’03 Homepage,2003,37(5):29-43.
[8]KONSTANTIN SHVACHKO,HAIRONG KUANG,SANJAY RADIA,et al.The Hadoop Distributed File System[C]∥2010 IEEE 26th Mass Storage Systems and Technologies (MSST).[S.l.]:IEEE,2012:1-10.
[9]ZENG Ling-fang,FENG Dan,WEI Qing-song,et al.CDRM:A Cost-Effective Dynamic Replication Management Scheme for Cloud Storage Cluster[C]∥IEEE International Conference on Cluster Computing.Heraklion,Crtee:IEEE,2010:188-196.
[10]黑继伟.基于分布式并行文件系统HDFS的副本管理模型[D].长春:吉林大学计算机科学与技术学院,2010.
HEI Ji-wei.The Replication Management Model Based on Distributed Parallel File System HDFS[D].Changchun:College of Computer Science and Technology,Jilin University,2010.
[11]LI Wen-hao,YANG Yun,CHEN Jin-jun,et al.A Cost-Effective Mechanism for Cloud Data Reliability Management Based on Proactive Replica Checking[C]∥12th IEEE/ACM International Symposium on Cluster,Cloud and Grid Computing.Ottawa,ON:IEEE,2012:564-571.
[12]CAO Ning,YU Shu-cheng,YANG Zhen-yu,et al.LT Codes-Based Secure and Reliable Cloud Storage Service[C]∥Proceedings IEEE Infocom Orlando.FL:IEEE,2012:693-701.
[13]HSIAO-YING LIN,WEN-GUEY TZENG.A Secure Erasure Code-Based Cloud Storage System with Secure Data Forwarding[J].IEEE Transactions on Parallel and Distributed Systems,2012,23(6):995-1003.
[14]WEATHERSPOON H,KUBIATOWICZ J D.Erasure Coding vs Replication:A Quantitative Comparison[C]∥IPTPS’01 Revised Papers from the First International Workshop on Peer-to-Peer Systems.London:Springer-Verlag,2002:328-338.
[15]黄晓云.基于HDFS的云存储服务系统研究----分布式架构REPEA设计与实现[D].上海:上海交通大学电子信息与电气工程学院,2010.
HUANG Xiao-yun.Research of Cloud Storage Service System Based on HDFS ---- The Design and Implementation of the Distributed Architec ture REPEA[D].Shanghai:College of Electronic Information and Electrical Engineering,Shanghai Jiaotong University,2010.
